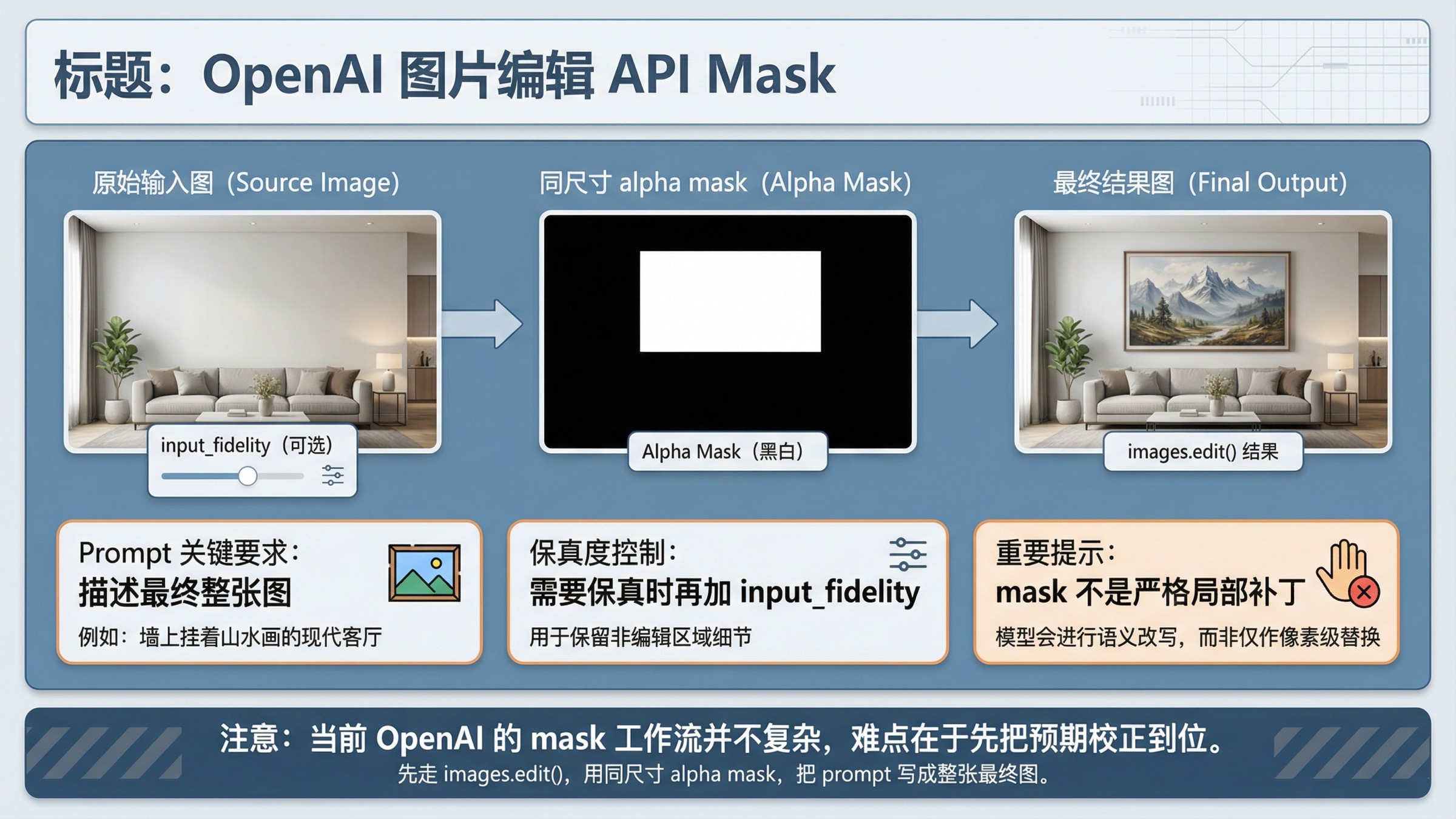
截至 2026 年 3 月 29 日,如果你在做 OpenAI mask edit,最稳的默认路线仍然是直接 images.edit() 配合 gpt-image-1.5,上传一张和原图同尺寸的 alpha mask,再把 prompt 写成“最终整张图应该长什么样”。 这比一上来改用 Responses,或者继续沿用老式 DALL·E inpainting 心智模型,更容易得到可控结果。
这个关键词之所以总让人觉得“明明 mask 传对了,结果还是不听话”,不是因为 OpenAI 完全没写清楚,而是因为当前答案被拆散在多个位置。主 image generation guide 讲了 mask 机械要求,input fidelity 讲了什么时候该把保真拉高,Responses 的图片工具说明 又补了 action=auto|generate|edit 这条支线。你只看其中一页,很容易拿到半个结论。
更关键的是,OpenAI 自己已经写得很明确:GPT Image 的 mask 是 prompt-guided,不保证像老式 Photoshop 局部补丁那样严格按边界执行。 这正是社区里“whole image got rewritten”的真正来源。mask 是聚焦信号,不是像素级硬边界。
要点速览
- 先从直接
client.images.edit()或POST /v1/images/edits开始,不要先套更大的 Responses workflow。 - 先排查 mask 文件本身:同格式、同尺寸、小于
50 MB、并且真的带 alpha channel。 - prompt 不要只写“填这块空白”,而要写成最终整张图的描述,并明确哪些内容必须保持不变。
- 只有当脸、logo、产品细节、包装反光或构图一致性真的重要时,再加
input_fidelity="high"。 - 把这个能力理解成“受约束的语义改写”,不要把它当成“严格局部补丁”。
先走当前最稳的 OpenAI mask edit 路线
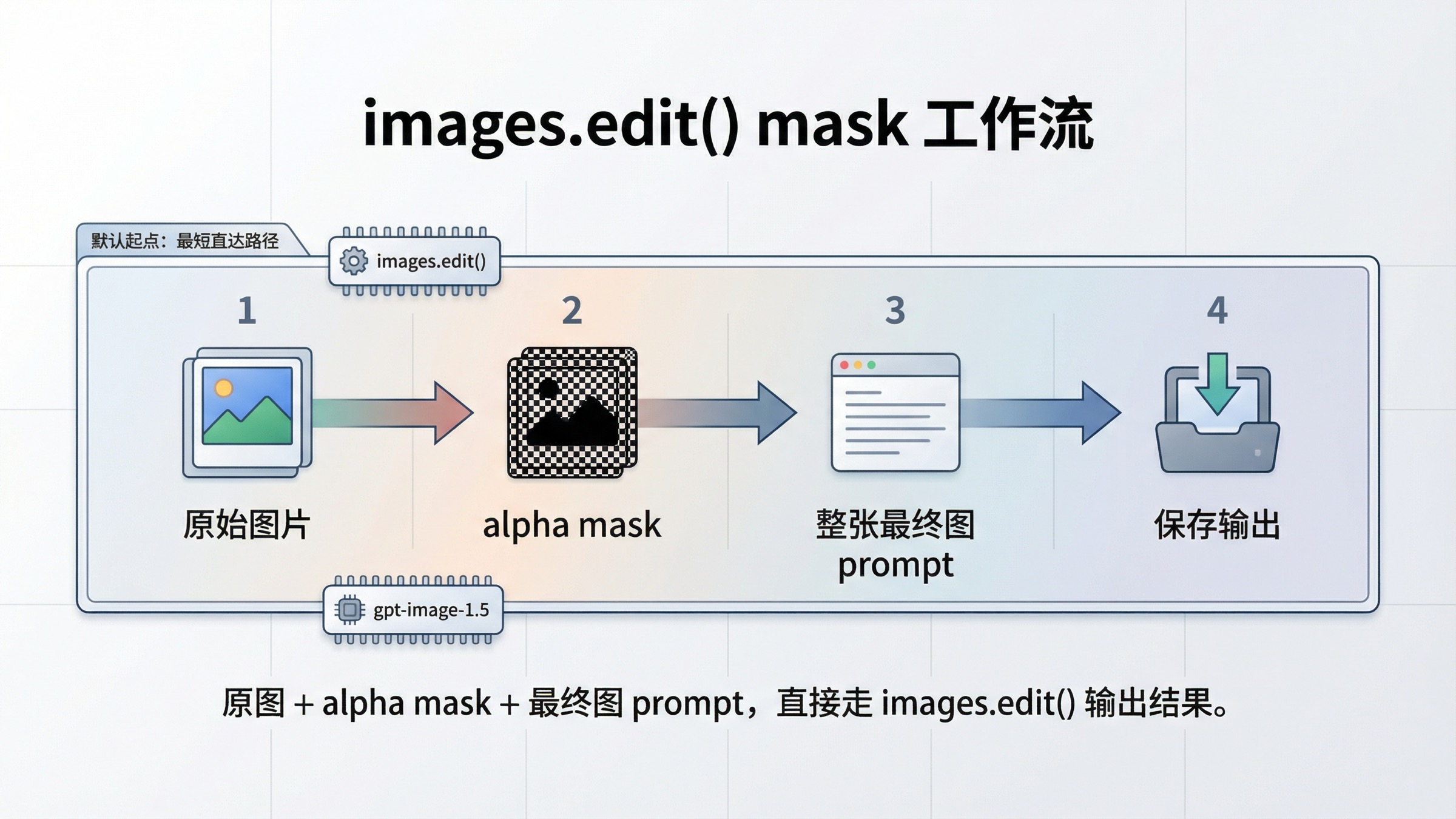
如果你的需求本质上是“我已经有图了,现在想在指定区域做编辑”,那就没有必要先把问题升格成多轮会话。OpenAI 当前文档里,最短、最稳、也最容易 debug 的路线仍然是直接 Images API:上传原图、上传 mask、写最终图 prompt、取回 base64 输出并保存。
JavaScript 的当前形态可以直接从这一步开始:
jsimport fs from "fs"; import OpenAI, { toFile } from "openai"; const client = new OpenAI(); const result = await client.images.edit({ model: "gpt-image-1.5", image: await toFile(fs.createReadStream("sunlit_lounge.png"), null, { type: "image/png", }), mask: await toFile(fs.createReadStream("mask.png"), null, { type: "image/png", }), prompt: "A sunlit indoor lounge area with a pool containing a flamingo. Preserve the room, lighting, reflections, and camera angle.", input_fidelity: "high", size: "1024x1024", quality: "medium", }); const imageBase64 = result.data[0].b64_json; const imageBytes = Buffer.from(imageBase64, "base64"); fs.writeFileSync("lounge.png", imageBytes);
Python 版同样很直接:
pythonfrom openai import OpenAI import base64 client = OpenAI() result = client.images.edit( model="gpt-image-1.5", image=open("sunlit_lounge.png", "rb"), mask=open("mask.png", "rb"), prompt=( "A sunlit indoor lounge area with a pool containing a flamingo. " "Preserve the room, lighting, reflections, and camera angle." ), input_fidelity="high", size="1024x1024", quality="medium", ) image_base64 = result.data[0].b64_json image_bytes = base64.b64decode(image_base64) with open("lounge.png", "wb") as f: f.write(image_bytes)
如果你更关心裸 HTTP 形态,那当前最短 multipart 版本依然是:
bashcurl -s -X POST "https://api.openai.com/v1/images/edits" \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -F "model=gpt-image-1.5" \ -F "mask=@mask.png" \ -F "image[]=@sunlit_lounge.png" \ -F 'prompt=A sunlit indoor lounge area with a pool containing a flamingo'
这一步有两个现实意义。第一,它能最快确认你的项目、key、model ID 和返回值处理是不是本来就没问题。第二,它能把问题压缩到“mask、prompt、保真、预期”四个维度里,而不是一开始就混进 Responses 的状态管理、工具链和会话上下文。
还有一个当前值得知道的新点:/v1/images/edits 不再只是本地 multipart 文件路线。当前契约还允许用 application/json,通过 images 和可选 mask 传 image_url 或 file_id。这意味着就算你的资源已经提前上传,也不一定要为了“避免本地文件上传”而跳到 Responses。
先把 API 真能接受的 mask 做对
这个关键词最常见的时间浪费,是在 mask 根本无效的时候去改 prompt。OpenAI 当前 mask requirements 很明确,机械要求只有几条,但每一条都是真正的硬门槛:
- 原图和 mask 必须是相同格式
- 原图和 mask 必须是相同像素尺寸
- 请求体必须小于
50 MB - mask 必须真的带 alpha channel
这一节里最容易被忽略的不是“PNG”两个字,而是 alpha。很多设计工具导出的看起来像黑白 mask,但本质上只是一个不透明的灰度图。OpenAI 文档甚至专门给了把黑白 mask 转成 RGBA 并把灰度值写进 alpha 的示例,原因就在这里。
真正会让人误判的是后半句。OpenAI 同时又写明:透明区域是替换区域,但 GPT Image 的 mask 仍然是 prompt-based,不保证严格按 mask 形状逐像素执行。也就是说,机械有效和行为严格是两回事。一个 mask 可以完全符合上传规则,同时仍然在结果层面给你“改多了”的感觉。
比较稳的生产前检查顺序是:
- 在导出前先把原图和 mask 统一到同一套最终尺寸
- 优先输出带 alpha 的 PNG,而不是肉眼看起来像 mask 的任意图片
- 检查你想修改的区域是否真的透明,而不是画成了白色但仍然不透明
- mask 区域能小就小,不要一上来圈太大
如果你在做多图编辑,还要记住另一个容易踩坑的当前规则:mask 只作用在第一张输入图上。 这意味着第一张图应该是“基底场景”,后面的图是补充参考,而不是多个都能被局部 mask。
Prompt 要写整张最终图,不要只写空白区域
当前 OpenAI 文档里最关键的一句,其实不是参数名,而是 prompt 方法论:描述最终整张图,而不只是被挖空的区域。 这是很多“mask 看起来没坏,但结果还是错”的真正分水岭。
原因很简单。模型并不是在做死板的“填洞”,而是在生成一张新的、语义上自洽的最终图,只是 mask 在告诉它哪里最值得改。于是 prompt 至少要同时完成三件事:
- 说清楚你要改什么
- 说清楚哪些内容必须保持不变
- 说清楚最终画面的整体状态
不够用的 prompt:
textPut a flamingo in the pool.
更好的写法:
textA sunlit indoor lounge area with a pool containing a flamingo. Preserve the pink room walls, the pool tile pattern, the reflections, the furniture, and the camera angle. Do not redesign the rest of the room.
如果是标签、logo、包装这种更容易漂移的工作,保留约束要写得更硬:
textReplace only the blank label area on the bottle with a clean gold logo. Preserve the bottle shape, cap, glass reflections, lighting, shadows, background, and camera framing. Do not change any other packaging detail.
这也是为什么当前 GPT Image 1.5 prompting guide 比很多第三方教程更有用。它真正想告诉你的不是“写得越长越好”,而是“把要变的部分和要保留的部分都显式写出来,并且每次只修一个变量”。你越把第一次请求写成“大而全的愿望清单”,模型就越容易把整张图重新解释一遍。
如果第一轮结果已经接近目标,第二轮不要整段重写。像“保持其他内容不变,只把 logo 再放大一点”这样的单变量迭代,通常比重新发一个新长 prompt 更稳。
什么时候 input_fidelity=high 真的会改变结果

mask 和 input_fidelity 解决的不是同一个问题。mask 管的是“改哪里”,input_fidelity 管的是“多努力保住输入图的细节”。 这两个概念一旦混在一起,团队就会把“位置控制失败”和“保真压力不够”误判成同一个 bug。
OpenAI 当前 input fidelity 文档 写得很直白:默认值是 low;当输入图里有脸、logo、产品细节这类必须准确保留的元素时,high 特别有用;如果你用的是 gpt-image-1.5,前 5 张输入图都能得到更高保真保留。
最实用的判断规则可以压成下面这张表:
| 场景 | 只靠 mask 一般够吗 | 建议加 input_fidelity="high" 吗 | 为什么 |
|---|---|---|---|
| 休闲场景里替换一个简单物体 | 大多够 | 通常不用 | 位置问题更大,细节保留成本不高 |
| 编辑区域靠近人脸 | 不一定 | 多半要加 | 脸部漂移代价高,官方也明确把它列为高保真场景 |
| 把 logo 放到包装、衣服、招牌上 | 很少够 | 通常要加 | mask 只能告诉模型“放在这里”,保真决定 logo 和底物像不像原件 |
| 改产品主图但要保持品牌识别 | 很少够 | 要加 | 产品几何、材质反光和构图一致性比速度更重要 |
| 希望严格局部补丁、不能有任何外溢 | 不够 | 加了也不够完全解决 | 高保真会帮你保住细节,但不会把 GPT Image 变成机械图层编辑器 |
这也是为什么“mask 传对了,为什么 logo 还是漂”通常不是 mask 问题,而是 preservation 问题。高保真会增加 image input token 成本,所以不要默认全部打开;但一旦工作流是品牌图、脸部图、SKU 主图、包装 mockup,这个参数通常比继续微调 mask 更值得先试。
如果你需要更广的模型路线判断,可以继续看 OpenAI 图片生成模型指南。但就这个关键词本身,结论更窄也更实用:mask 决定位置,高保真决定保留压力。
为什么 masked edit 还是会改动超出预期
OpenAI 文档其实已经把这件事说透了,只是很多页不会把它翻译成工程判断。mask section 一边说透明区域会被替换,一边又说 GPT Image 的 mask 仍然是 guidance,不保证严格按形状执行。把这两句话合在一起,你就得到这个关键词真正的核心结论:当前的 masked edit 更接近“受约束的语义改写”,而不是“严格局部补丁”。
社区里从 2025 年 4 月 27 日 起就一直有人抱怨 valid mask 也会让整张图发生比预期更大的变化。这不等于 API 挂了,而是因为很多团队把当前 GPT Image 的 edit 能力,错当成了以前那种像素级 inpainting。
通常会出现 whole-image drift 的原因有四类:
- prompt 只写了新增物体,没有把原场景必须保持的部分写清楚
- 编辑内容碰到了脸、logo、产品细节、反光、布局这些高敏感区域,却没有加
input_fidelity="high" - mask 区域太大,模型为了让结果合理,只能重解释周边上下文
- 团队预期仍然停留在“mask = 未遮罩区域绝对不会变”
所以正确修法不是“以后别用 mask”,而是换一个更符合当前模型的工作方式:
- 能缩小编辑范围时先缩小
- prompt 里明确写 preserve list
- 只有在保真真的重要时才上
input_fidelity="high" - 如果产品要求极度局部控制,就先做裁剪、分割或预处理,而不是把所有责任都压给 mask
一旦你的业务要求是“除了这几像素,别的地方绝对不能动”,这其实已经不是单纯的 prompt 微调问题,而是产品需求和当前模型能力之间的适配问题。这才是很多团队真正需要早点认清的分叉点。
Images API 和 Responses,mask-heavy workflow 该怎么选
Responses 当然有用,但多数 mask-first 工作流切过去都太早。当前 image generation guide 和 tool options 文档 的信号很一致:如果你在 Responses 里用 gpt-image-1.5 或 chatgpt-image-latest,可以额外设置 action=auto|generate|edit,而 OpenAI 推荐默认保留在 auto,让模型自己判断是生成还是编辑。
这意味着,只有在下面这些场景里,Responses 的价值才真正超过直接 Images API:
- 你的编辑步骤本来就在一个多轮会话里
- 你需要把编辑作为更大 assistant / agent workflow 的一个 tool
- 你希望复用 file IDs、上下文状态和多模态历史
如果你的需求只是:
- 取一张图
- 用一个 mask 改它
- 保存输出
- 如果不满意,再用更窄的 prompt 重试
那么直接 Images API 仍然是最稳的默认值。
还有一个现实上的新变化,也让“为了上传资产方便就跳 Responses”这条理由变弱了:当前 /v1/images/edits 已经支持 JSON 形态的 image_url 和 file_id。所以你并不需要为了“资源已经上传了”而自动切到另一条更大的 surface。
如果你真正想比较两条 surface 的完整职责边界,可以继续读 OpenAI Image API 教程。但对这个关键词来说,答案还是一句话:先用最短的 direct edit 路线把事情做对,再考虑更大的编排层。
排错:为什么 mask 还是失败或改太多
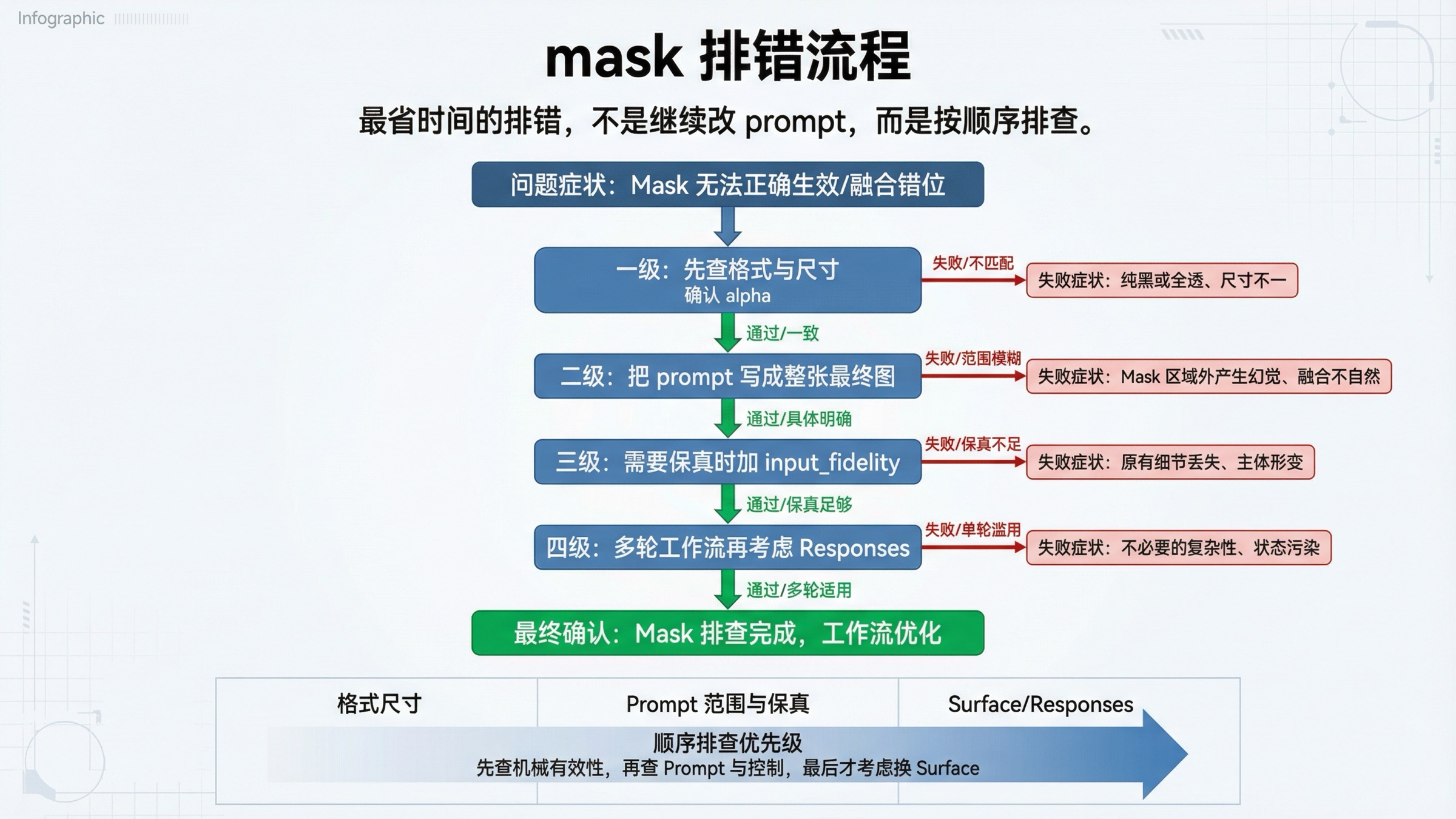
最省时间的排错顺序,不是继续反复改 prompt,而是按这个顺序往下走:
-
API 直接拒绝 mask,或者像完全没识别到 mask。
先看格式、尺寸、大小和 alpha。只要这四个条件没过,后面所有调参都没有意义。 -
模型改到了大致正确的位置,但整张图风格或布局也跟着变了。
这通常是 prompt 只说了“改什么”,没说“其余哪些必须保持不变”。把 prompt 改写成最终整张图描述,并显式列出 preserve list。 -
编辑明显越界,超过 mask 区域。
这在 GPT Image 里并不罕见,尤其当被改区域和周边上下文强相关时。先缩小 mask,减少单次请求中的变化量,再把 preserve 约束写得更具体。 -
脸、logo、品牌包装、产品主图还是漂。
这更像是保真问题,不是定位问题。先上input_fidelity="high",再把“哪些识别特征不能变”写进 prompt。 -
你需要多轮迭代、缓存资产、复用上下文。
到这一步,再考虑 Responses 或 JSON 版/v1/images/edits。不要太早跳 surface。 -
业务要求是真正的像素级局部可靠性。
先尽早验证这个要求是否超过当前模型的 edit 行为边界。如果是,就应该加裁剪、分割或前置图像处理,而不是继续逼 mask 一个人承担所有约束。
这也是为什么当前 page one 仍然有空间。很多页面能解释某一个点,但很少能把“文件有效性 -> prompt 范围 -> 保真控制 -> route 选择”这整条排错链一次说清。
FAQ
透明区域是不是就一定代表只有这些像素会变?
不是。当前 OpenAI 文档明确说透明区域是替换区域,但 GPT Image 的 mask 仍然是 prompt-based guidance,不保证严格按边界执行。更接近“受约束改写”,不是“机械局部补丁”。
mask edit 默认该先用 Responses 还是 images.edit()?
默认先用 images.edit()。只有当图片编辑本身就是更大多模态工作流里的一个 tool,或者你真的需要会话状态和多轮上下文时,再考虑 Responses。
mask 明明没问题,为什么 logo 或脸还是漂?
因为 mask 管的是位置,不是保真。遇到脸、logo、产品细节这种 case,先试 input_fidelity="high",并在 prompt 里明确要求哪些识别特征必须保持不变。
最后的建议
当前 OpenAI mask edit 的默认路线其实并不复杂:先用 gpt-image-1.5 跑直接 Images API,把 mask 的机械要求做对,把 prompt 写成最终整张图,再只在需要的时候加 input_fidelity="high"。 这个组合,比一上来上更大的框架或继续微调错误预期,更能解决真实工作流里的问题。
如果结果仍然比你想要的“改多了”,不要先怀疑上传失败。先确认是不是业务预期本身比当前 GPT Image 的 mask 行为更严格。如果是,那真正的分叉点不在 prompt,而在前置裁剪、分割和工作流设计。更广的编辑路线可以继续读 OpenAI 图片编辑 API 指南;如果你在上线前还要确认当前 access 和能力是否就绪,下一篇更实用的是 OpenAI 图片生成 API 验证指南。