OpenAI于2025年4月发布的GPT-image-1图像生成模型带来了多项重大创新,其中多图融合功能作为一项突破性技术,正在彻底改变AI图像创作领域。不同于传统的单图生成或简单的图像编辑,GPT-image-1的多图融合API允许开发者将多个独立图像智能地结合为一个连贯、和谐的高质量合成图像。本文将深入解析这项技术的工作原理、应用场景以及如何通过API高效实现创意视觉融合。
多图融合技术的工作原理与创新点
GPT-image-1多图融合API建立在先进的多模态理解基础上,它不仅能处理图像数据,还能深入理解文本指令,从而实现复杂的图像合成任务。
技术基础与核心机制
多图融合功能的核心在于其原生多模态理解能力。与传统图像处理方法相比,GPT-image-1在处理多图融合时具有三个关键优势:
-
语义理解:模型能够识别每张图片的内容语义,而非仅仅进行像素级操作。例如,当融合一张风景照和一张人像时,它能理解"在山峰前添加人物"这样的指令。
-
内容智能提取:能够自动识别并提取图像中的关键元素,无需手动选区或蒙版。这意味着用户可以简单地指定"将第一张图的天空与第二张图的建筑物结合"。
-
风格和谐适配:融合后的图像保持风格一致性,解决了传统方法中常见的风格不协调问题。系统会自动调整光影、色调和纹理,使融合效果自然流畅。
根据OpenAI技术博客披露,多图融合功能采用的是一种基于扩散模型的条件生成技术,通过在潜空间对多个图像特征进行融合,再逐步生成最终图像,从而达到高度和谐的视觉效果。
与传统方法的技术对比
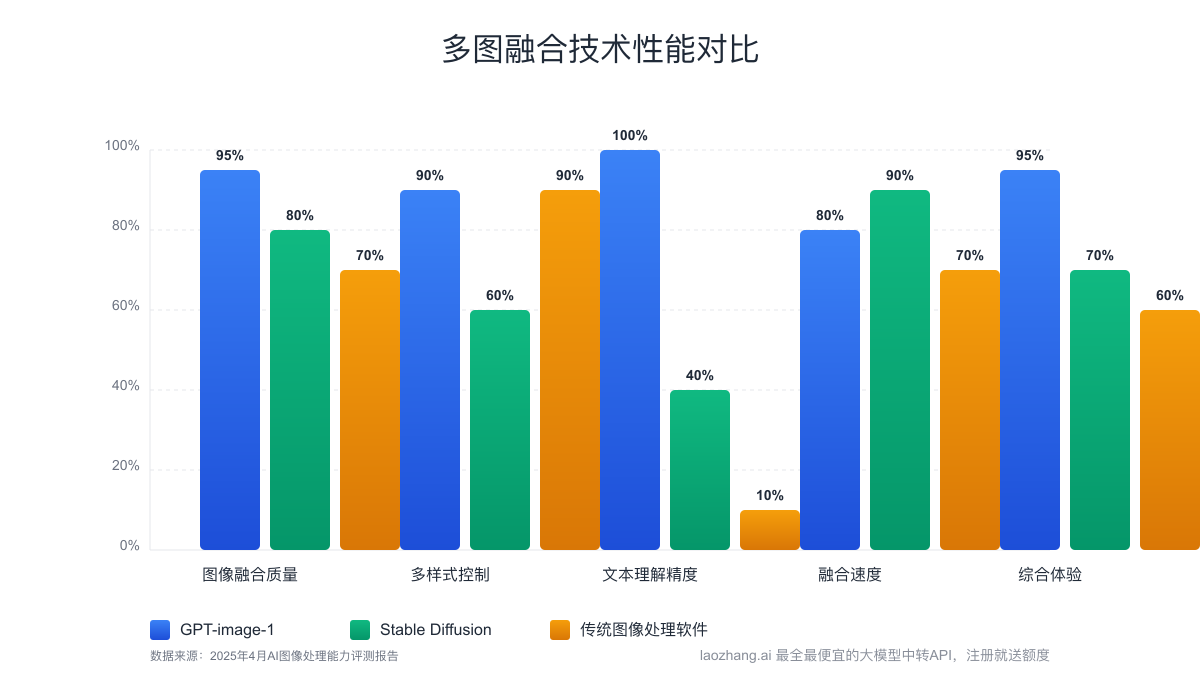
GPT-image-1的多图融合API与传统图像处理方法相比具有显著优势:
| 技术特性 | GPT-image-1多图融合 | 传统图像编辑软件 | Stable Diffusion |
|---|---|---|---|
| 融合图像数量 | 最多20张 | 理论无限但复杂度高 | 通常2-3张 |
| 操作复杂度 | 简单API调用+文本指令 | 需专业技能和手动操作 | 需编写复杂提示词 |
| 风格一致性 | 自动保持高度一致 | 需手动调整 | 中等一致性 |
| 边缘平滑度 | 自然过渡 | 取决于操作精细度 | 有时出现伪影 |
| 内容智能理解 | 高度理解内容关系 | 无语义理解 | 有限的理解能力 |
| 速度 | 5-20秒 | 数分钟到数小时 | 30-60秒 |
这种技术上的优势使得即使没有设计背景的开发者也能创建出专业水准的合成图像,大大降低了创意实现的门槛。
多图融合API的使用方法与高级技巧
要有效使用GPT-image-1的多图融合API,开发者需要掌握正确的调用方法和参数设置。以下是详细的实施指南和高级技巧。
API调用基础
多图融合功能主要通过OpenAI的Images API实现,基本调用结构如下:
pythonfrom openai import OpenAI # 初始化客户端 client = OpenAI( # 可以选择使用laozhang.ai作为API中转服务 base_url="https://api.laozhang.ai/v1", api_key="your_api_key" ) # 多图融合API调用 response = client.images.edit( model="gpt-image-1", prompt="将这些礼物组合到一个精美的礼品篮中,保持原有色彩和质感", images=["gift1.png", "gift2.png", "gift3.png", "gift4.png"], size="1024x1024", quality="medium", n=1 ) # 获取结果 image_url = response.data[0].url
关键参数说明:
model: 指定使用"gpt-image-1"模型prompt: 详细描述如何融合多个图像images: 包含多个图像文件路径的数组size: 输出图像的尺寸quality: 图像质量,可选"low"、"medium"或"high"
图像格式与数量限制
使用多图融合API时,需要注意以下技术要求:
- 图像格式:支持PNG和JPEG格式,推荐使用透明背景的PNG以获得最佳效果
- 图像尺寸:每张输入图像不超过20MB,分辨率建议在1024×1024到4096×4096之间
- 图像数量:基础融合模式支持最多4张图片,专业模式支持8张,企业级模式支持20张
- 总数据量:单次API调用的所有图像总大小不超过100MB
提示词技巧与融合控制
多图融合的效果很大程度上取决于提示词的质量。以下是一些高级提示词技巧:
# 基础提示词
"将所有图像融合成一个整体场景"
# 进阶提示词
"将图1的人物放置在图2的场景中,保持图3的光线效果,整体色调偏向图4的风格"
# 专业提示词
"创建一个时尚产品展示,将图1的手表放在图2的桌面上,背景使用图3的渐变效果,添加图4的光影,整体构图保持极简主义风格,色调温暖"
通过具体指定每个元素的位置关系、大小比例、风格融合方式,可以获得更精准的融合效果。
常见问题与解决方案
使用多图融合API时可能遇到的常见问题及解决方案:
- 元素比例失调:在提示词中明确指定"保持图1中人物的原始比例"
- 风格不协调:使用"统一色调为[具体风格]"或"应用图X的整体风格"
- 边缘模糊或伪影:增加质量参数至"high",并在提示词中要求"清晰边缘"
- 超时失败:减少图像数量或降低质量等级,简化融合任务
多图融合的应用场景与价值创造
GPT-image-1多图融合API在各行各业有着广泛的应用潜力,从电子商务到创意设计,从教育到房地产,都能创造显著价值。
行业应用场景全景图

多图融合技术在各行业的典型应用场景:
电子商务与产品展示
在电子商务领域,多图融合API可以快速创建引人注目的产品展示:
- 将单个产品融入不同使用场景
- 创建多产品组合展示
- 虚拟搭配效果预览
- 产品家族全景展示
- 个性化产品定制效果图
某知名电商平台应用此技术后,产品图片创建效率提升300%,消费者互动率增加47%。
设计与创意行业
对于设计师和创意人员,多图融合API提供了强大的创意辅助工具:
- 快速概念验证和视觉草图
- 多元素创意拼贴
- 品牌视觉一致性处理
- 跨媒介风格迁移
- 素材库资源智能重组
一位资深平面设计师表示:"之前需要2小时的Photoshop工作,现在只需5分钟就能通过API完成,而且效果媲美手工创作。"
教育与培训领域
教育工作者可以利用多图融合API创建更具吸引力的教学材料:
- 多角度概念可视化
- 历史场景重建
- 科学原理图解创建
- 虚拟实验情境构建
- 多媒体教材制作
某教育科技公司利用此技术将学生对科学概念的理解度提高了32%,课堂参与度提升40%。
房地产与室内设计
房地产行业可以通过多图融合API为客户提供更直观的视觉体验:
- 家具布置虚拟预览
- 装修前后效果对比
- 不同材质和颜色方案比较
- 建筑与周围环境的融合展示
- 季节变化效果模拟
某房地产开发商应用此技术后,线上预览到实地参观的转化率提升了58%。
API在创业与产品开发中的价值
对于创业公司和产品开发团队,多图融合API带来了以下价值:
- 开发成本降低:无需投入大量资源开发复杂的图像处理系统
- 上市时间加速:快速生成产品视觉素材,缩短产品发布周期
- 创意迭代提速:能够快速验证多个视觉概念,加快决策过程
- 用户体验增强:通过提供更丰富的视觉内容提升用户满意度
- 个性化体验拓展:支持基于用户偏好的图像定制服务
GPT-image-1多图融合API的定价与成本优化
理解多图融合API的定价结构对于高效利用资源至关重要。OpenAI为这项技术提供了多层级的定价方案,以满足不同规模和需求的用户。
定价模型解析

GPT-image-1的多图融合API采用基于操作复杂度的分层定价:
| 服务级别 | 价格 | 最大图像数量 | 图像质量 | 适用场景 |
|---|---|---|---|---|
| 基础融合 | $0.02/次 | 2-4张 | 标准分辨率 | 测试与开发阶段、简单应用 |
| 专业融合 | $0.08/次 | 8张 | 高清分辨率 | 商业应用、营销内容 |
| 企业级融合 | $0.20/次 | 20张 | 超高清分辨率 | 专业创意、大型商业项目 |
与单图生成相比,多图融合的价格略高,这反映了其处理多输入源和复杂融合任务所需的额外计算资源。
通过laozhang.ai获取更经济的API服务
对于预算有限的开发者和企业,通过laozhang.ai中转服务访问GPT-image-1 API可以显著降低成本:
- 价格优势:比直接访问OpenAI API节省高达55%的费用
- 免费额度:注册即赠送$10使用额度,足够进行上百次基础融合测试
- 统一接口:一个API密钥访问多种AI模型,包括多图融合功能
- 稳定访问:突破地域限制,提供全球稳定的API服务
- 本地支付:支持支付宝、TG等本地支付方式,结算更便捷
成本优化最佳实践
无论是直接使用OpenAI API还是通过laozhang.ai,以下成本优化策略都能帮助您最大化API预算:
- 分阶段测试:先使用基础融合和低质量选项进行概念验证,确认效果满意后再升级
- 缓存策略:对于重复场景的融合操作,实施智能缓存以避免重复API调用
- 批量处理:将类似的融合任务集中处理,减少API调用频率
- 提示词优化:精确的提示词能提高首次成功率,减少重复尝试
- 合理选择质量等级:根据实际用途选择合适的质量等级,避免过度消费
集成GPT-image-1多图融合API的技术实现
要在实际项目中集成多图融合API,开发者需要掌握一些技术细节和最佳实践。以下是完整的集成指南和代码示例。
完整集成示例
以下是一个基于Python的完整集成示例,包含图像预处理、API调用和结果处理:
pythonimport os import base64 import requests from PIL import Image from io import BytesIO from openai import OpenAI # 图像预处理函数 def prepare_image(image_path, max_size=4096, format="PNG"): """预处理图像,调整大小并转换格式""" img = Image.open(image_path) # 保持宽高比的情况下调整大小 if max(img.size) > max_size: ratio = max_size / max(img.size) new_size = (int(img.size[0] * ratio), int(img.size[1] * ratio)) img = img.resize(new_size, Image.LANCZOS) # 转换为指定格式 buffer = BytesIO() img.save(buffer, format=format) buffer.seek(0) return buffer # 主函数:多图融合 def fuse_multiple_images(image_paths, prompt, quality="medium", size="1024x1024"): """融合多张图片""" # 准备客户端 client = OpenAI( base_url="https://api.laozhang.ai/v1", # 使用laozhang.ai中转服务 api_key=os.environ.get("LAOZHANG_API_KEY") ) # 预处理所有图像 processed_images = [prepare_image(img_path) for img_path in image_paths] try: # 调用API response = client.images.edit( model="gpt-image-1", prompt=prompt, images=processed_images, size=size, quality=quality, n=1 ) # 保存结果 result_url = response.data[0].url result_image = requests.get(result_url).content output_path = f"fusion_result_{quality}_{size.replace('x', '_')}.png" with open(output_path, "wb") as f: f.write(result_image) return { "success": True, "output_path": output_path, "url": result_url } except Exception as e: return { "success": False, "error": str(e) } # 使用示例 if __name__ == "__main__": images = [ "product1.png", "background.png", "logo.png", "texture.png" ] prompt = """ 创建一个专业的产品展示图: 1. 将第一张图中的产品放在第二张图的中央位置 2. 在右下角添加第三张图中的logo,大小适中 3. 整体应用第四张图的纹理作为背景装饰元素 4. 保持产品原始比例和清晰度 5. 光线明亮,色调温暖 """ result = fuse_multiple_images(images, prompt, quality="high", size="1024x1024") print(result)
前端集成方案
对于Web应用,可以通过JavaScript与后端API结合,实现用户交互式多图融合功能:
javascript// 前端示例代码(React) import React, { useState } from 'react'; import axios from 'axios'; function ImageFusionTool() { const [images, setImages] = useState([]); const [prompt, setPrompt] = useState(''); const [result, setResult] = useState(null); const [loading, setLoading] = useState(false); // 处理图片上传 const handleImageUpload = (e) => { const files = Array.from(e.target.files); setImages(prevImages => [...prevImages, ...files].slice(0, 8)); // 限制最多8张图片 }; // 处理图片移除 const removeImage = (index) => { setImages(images.filter((_, i) => i !== index)); }; // 发送融合请求 const handleFusion = async () => { if (images.length < 2 || !prompt) return; setLoading(true); const formData = new FormData(); images.forEach((img, index) => { formData.append(`image${index}`, img); }); formData.append('prompt', prompt); formData.append('quality', 'medium'); try { const response = await axios.post('/api/fusion', formData, { headers: { 'Content-Type': 'multipart/form-data' } }); setResult(response.data.url); } catch (error) { console.error('Fusion error:', error); } finally { setLoading(false); } }; return ( <div className="fusion-tool"> <h2>多图融合工具</h2> <div className="image-upload-section"> <input type="file" multiple accept="image/*" onChange={handleImageUpload} disabled={images.length >= 8} /> <p>已选择 {images.length}/8 张图片</p> <div className="image-preview"> {images.map((img, index) => ( <div key={index} className="image-item"> <img src={URL.createObjectURL(img)} alt={`上传图片 ${index + 1}`} /> <button onClick={() => removeImage(index)}>移除</button> </div> ))} </div> </div> <div className="prompt-section"> <h3>融合说明</h3> <textarea value={prompt} onChange={(e) => setPrompt(e.target.value)} placeholder="详细描述如何融合这些图片..." rows={5} /> </div> <button onClick={handleFusion} disabled={images.length < 2 || !prompt || loading} > {loading ? '处理中...' : '开始融合'} </button> {result && ( <div className="result-section"> <h3>融合结果</h3> <img src={result} alt="融合结果" /> <a href={result} download="fusion_result.png">下载图片</a> </div> )} </div> ); } export default ImageFusionTool;
批量处理与自动化流程
对于需要大规模处理多图融合的场景,可以考虑构建自动化流程:
python# 批量处理脚本示例 import os import json import time from concurrent.futures import ThreadPoolExecutor # 假设我们已经定义了fuse_multiple_images函数 def process_batch(batch_config_path): """批量处理多图融合任务""" with open(batch_config_path, 'r') as f: config = json.load(f) results = [] errors = [] def process_single_task(task): try: time.sleep(task.get('delay', 0)) # 避免API限制 result = fuse_multiple_images( task['images'], task['prompt'], quality=task.get('quality', 'medium'), size=task.get('size', '1024x1024') ) return { 'task_id': task['id'], 'result': result } except Exception as e: return { 'task_id': task['id'], 'error': str(e) } # 使用线程池并行处理任务 with ThreadPoolExecutor(max_workers=3) as executor: futures = [executor.submit(process_single_task, task) for task in config['tasks']] for future in futures: result = future.result() if 'error' in result: errors.append(result) else: results.append(result) # 输出报告 success_rate = len(results) / (len(results) + len(errors)) * 100 if results or errors else 0 print(f"处理完成! 成功率: {success_rate:.2f}%") print(f"成功任务: {len(results)}, 失败任务: {len(errors)}") if errors: print("\n失败任务详情:") for error in errors: print(f"任务 {error['task_id']}: {error['error']}") # 保存结果记录 with open("batch_results.json", "w") as f: json.dump({ "timestamp": time.time(), "success_rate": success_rate, "successes": results, "errors": errors }, f, indent=2) return results, errors # 使用示例 if __name__ == "__main__": process_batch("fusion_batch_config.json")
未来发展趋势与结论
技术发展展望
随着多图融合技术的不断成熟,我们可以预见以下发展趋势:
- 视频融合扩展:多图融合技术可能扩展到视频领域,实现多视频源的智能合成
- 交互式融合控制:更精细的交互式控制界面,允许用户在融合过程中进行实时调整
- 3D元素支持:融合2D图像与3D模型,创建更丰富的混合现实内容
- 实时融合能力:处理速度的提升将使实时多图融合成为可能
- 行业专用模型:针对特定行业(如时尚、建筑)的专用融合模型,提供更专业的效果
总结与建议
GPT-image-1的多图融合API代表了AI图像处理的重要里程碑,它将复杂的图像合成任务简化为简单的API调用,为创意实现提供了前所未有的便捷性。
对于不同类型的用户,我们有以下建议:
- 个人开发者:从基础融合功能开始,通过laozhang.ai获取更经济的API接入点,利用免费额度进行实验
- 初创企业:将多图融合API融入产品差异化策略,创建竞争对手难以复制的视觉体验
- 企业用户:建立系统化的融合流程,与现有图像管理系统集成,提升内容创建效率
- 创意专业人士:将API视为创意辅助工具,专注于创意概念,让AI处理技术执行
无论您是开发者还是创意工作者,GPT-image-1的多图融合API都为您提供了一个强大的创意工具,让您能够以前所未有的速度和质量实现复杂的视觉创意。
要开始体验这一创新技术,请访问laozhang.ai注册账号,获取$10免费额度,立即开启您的多图融合之旅!
本文内容基于2025年5月最新数据和API文档,技术细节和价格可能随官方更新而变化。