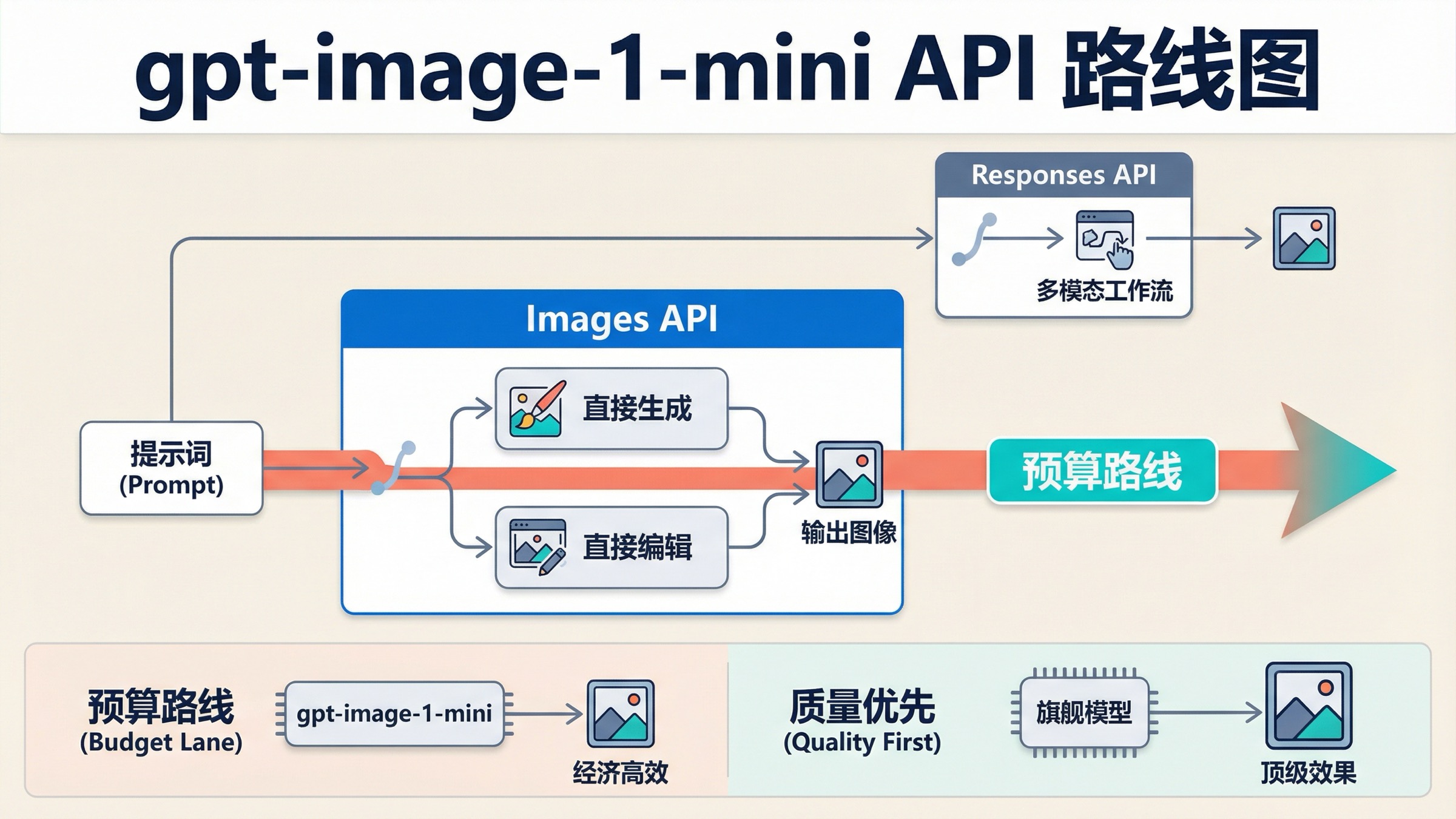
截至 2026 年 3 月 27 日,如果你要接入 gpt-image-1-mini,最稳的默认答案很简单:直接生成或直接编辑先走 OpenAI 的 Images API;只有当图片生成只是更大多模态工作流里的一个工具时,才切到 Responses API。 这正是当前精确关键词结果页最容易让人自己拼答案的地方。
这个关键词之所以比它本身看起来更绕,不是因为 OpenAI 没给答案,而是因为答案被分散在几张不同的官方页面上。gpt-image-1-mini 模型页负责当前价格、endpoints 和 rate limits。image generation guide 负责最关键的 route rule:如果你只需要根据一个 prompt 直接生成或编辑一张图,Image API 是更好的选择;如果图片生成属于更大的可编辑对话体验,则 Responses 更合适。images and vision guide 又展示了 Responses 侧的工具用法。只读其中一页,很容易一开始就选错抽象层。
这也是为什么很多精确命中 gpt-image-1-mini api 的页面看起来像是有答案,其实只是重复了“这是 OpenAI 当前更便宜的图片模型”,却没有告诉你到底该先接哪条 API 路线。这篇文章会比更大的 OpenAI 图片 API 教程 更窄,只解决一个问题:当你已经确定要看 gpt-image-1-mini 时,第一步到底该怎么做。
要点速览
- 直接生成图片、直接编辑图片,先用 Images API。
- 图片生成只是更大 assistant / multimodal workflow 的一个步骤时,再用 Responses API。
gpt-image-1-mini是预算路线,不是默认旗舰路线。- 在怀疑 SDK 样例之前,先确认 tier access 和 organization verification。
先从当前最稳的 direct route 开始
对这个关键词来说,最有价值的第一件事,不是列完所有参数,而是先拿到一个最短、最容易排查的成功请求。OpenAI 当前 guide 已经写得很明确:当你只需要根据一个 prompt 直接生成或编辑一张图时,Image API 是更好的选择。这一点很重要,因为不少开发者先看到的是 Responses 样例,于是误以为“更通用的新接口”天然就是更适合的起点。对这个 exact query 来说,通常不是。
如果你的需求就是“给我一个 prompt,返回一张图”,那最稳的第一步仍然是这样的 direct call:
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.generate({ model: "gpt-image-1-mini", prompt: "Create a clean editorial illustration of a robot photographer in a bright studio", size: "1024x1024", quality: "medium", output_format: "jpeg", output_compression: 80, }); const imageBase64 = result.data[0].b64_json; fs.writeFileSync( "gpt-image-1-mini-demo.jpg", Buffer.from(imageBase64, "base64") );
Python 版本也同样直接:
pythonfrom openai import OpenAI import base64 client = OpenAI() result = client.images.generate( model="gpt-image-1-mini", prompt="Create a clean editorial illustration of a robot photographer in a bright studio", size="1024x1024", quality="medium", output_format="jpeg", output_compression=80, ) image_base64 = result.data[0].b64_json with open("gpt-image-1-mini-demo.jpg", "wb") as f: f.write(base64.b64decode(image_base64))
为什么第一步要故意保守?因为你真正要验证的是四件事:当前 model ID 是否可用、当前 project / org 是否对、当前 access 是否已开通、以及输出处理是否正常。越早把请求写成“大而全的 workflow”,越容易把真正的问题埋在错误的层里。
这也是为什么第一条请求应该故意“无聊”。你不是在第一分钟里就证明自己会所有参数,而是在最短路径里确认账号、项目、模型与返回结果这四个基础层都没有偏掉。OpenAI 文档当然也列出了 quality、size、透明背景、编辑输入等更多能力,但这些都应该建立在最简单的 direct generation 已经确认成功之上。
Images API vs Responses for gpt-image-1-mini
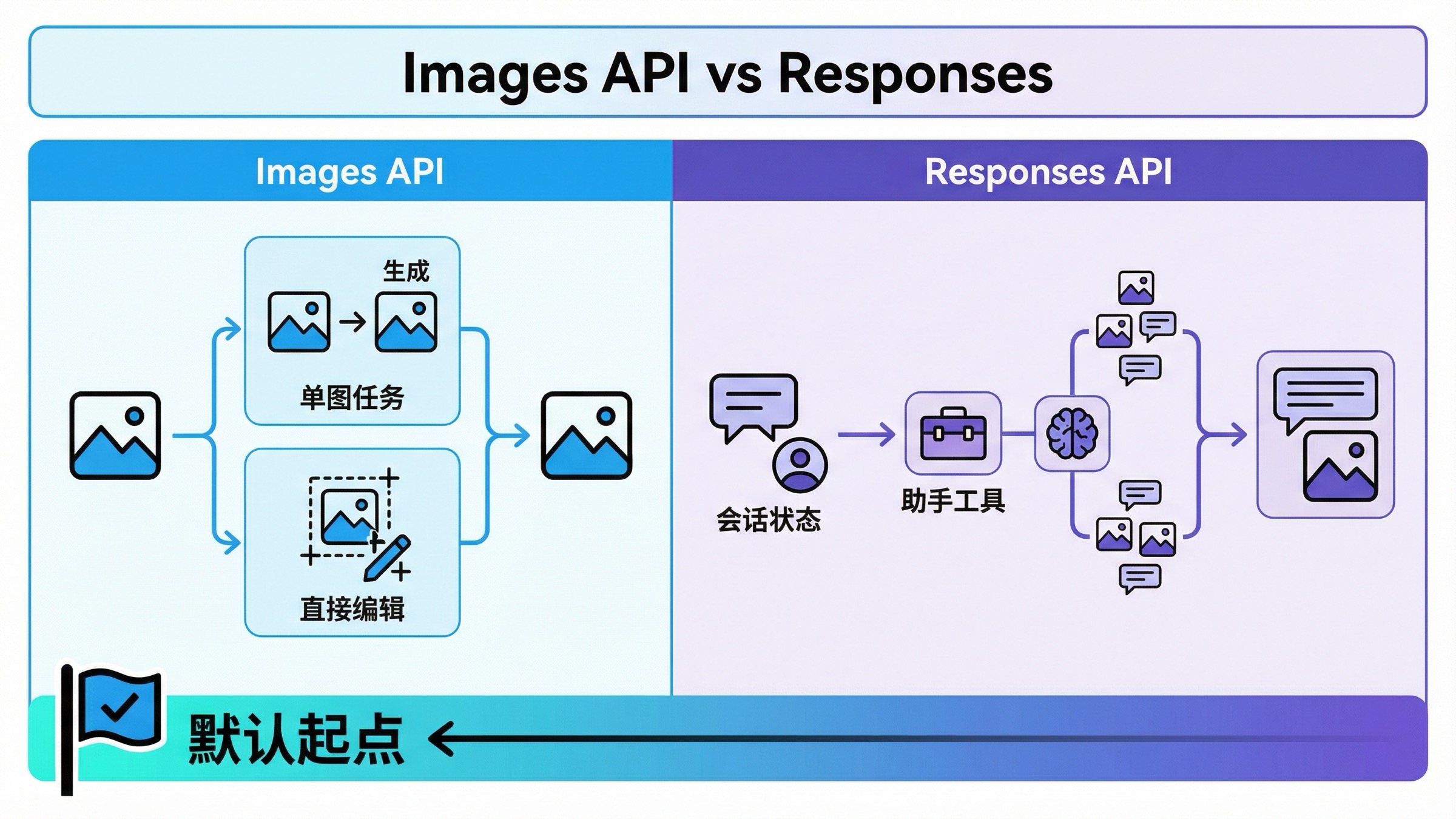
这个关键词最值得记住的一张表,其实就够了:
| 场景 | 更好的默认值 | 为什么 |
|---|---|---|
| 你只想发一个 prompt 直接生成一张图 | Images API | 路径最短、model choice 最清晰、最好排查 |
| 你只想直接编辑一张或几张输入图片 | Images API | 同一条 direct route,不需要额外 orchestration |
| 你在做一个偶尔会产图的 multimodal assistant | Responses API | 图片生成只是更大 flow 里的一个 tool |
| 你需要 conversation state、其他 tools、推理步骤和图片在同一个 request 里协同 | Responses API | 这里真正决定路线的是外层 workflow,而不是图片本身 |
| 你在做最短 onboarding 或快速验证 exact model | Images API | moving parts 更少,不会过早调试错层 |
最实用的判断规则其实很简单:如果图片生成本身就是功能面,先上 Images API;如果图片生成只是更大 assistant workflow 里的一个环节,再上 Responses。
这也是当前官方文档最稳的读法。image-generation guide 先给了 route rule;更宽的 images-and-vision guide 再去解释 Responses 侧的 tool 用法。也就是说,Responses 不是因为“更现代”就更适合,而是因为外层产品形态真的更复杂时才更适合。
如果你的团队里有人因为“Responses 看起来更新”就想统一全部新项目,也最好先把产品问题问清楚:这个请求里真的需要 conversation state、多个 tools、或者混合文本与图片输出吗?如果真实答案是否定的,那么先选更大的抽象层只会把第一版接入做得更重,而不会让 gpt-image-1-mini 更容易成功。
真正需要 Responses 时,它应该长什么样
避免 Responses 混淆的最好办法,不是抽象解释,而是把它放回它真正合适的场景里。当前 OpenAI 文档展示 Responses 的方式,本来就是“图片生成作为一个工具嵌在更大的请求里”,而不是拿它替换所有 images.generate()。
一旦换成 Responses,你的 mental model 就会变:
- 顶层 request 是一个更大的 multimodal / assistant-style request
- 图片生成只是其中一个 tool
- 你之所以选它,是因为外层 workflow 需要它,而不是因为
gpt-image-1-mini这个模型名强迫你换 endpoint
最小化的模式大概是这样:
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const response = await client.responses.create({ model: "gpt-4.1-mini", input: "Generate a transparent sticker-style icon of a paper airplane", tools: [{ type: "image_generation", quality: "medium" }], }); const imageBase64 = response.output .filter((item) => item.type === "image_generation_call") .map((item) => item.result)[0]; fs.writeFileSync("paper-airplane.png", Buffer.from(imageBase64, "base64"));
这条路线适合什么场景?适合你本来就在做更大的 assistant flow,需要 conversation state、tool orchestration 或 mixed outputs 的时候。它不适合什么场景?不适合你真正的任务只是“给我一张图,存成本地文件”时还硬把第一版接入做复杂。
也正因为如此,很多 exact-match 结果页才会让开发者产生错觉:仿佛是在两个同样合理的 abstraction 之间做偏好选择。实际上,对这个关键词的大多数读者来说,问题并不是“更喜欢哪个接口风格”,而是“我要不要在第一版里给自己增加不必要的系统复杂度”。
先确认 access,再去排查代码
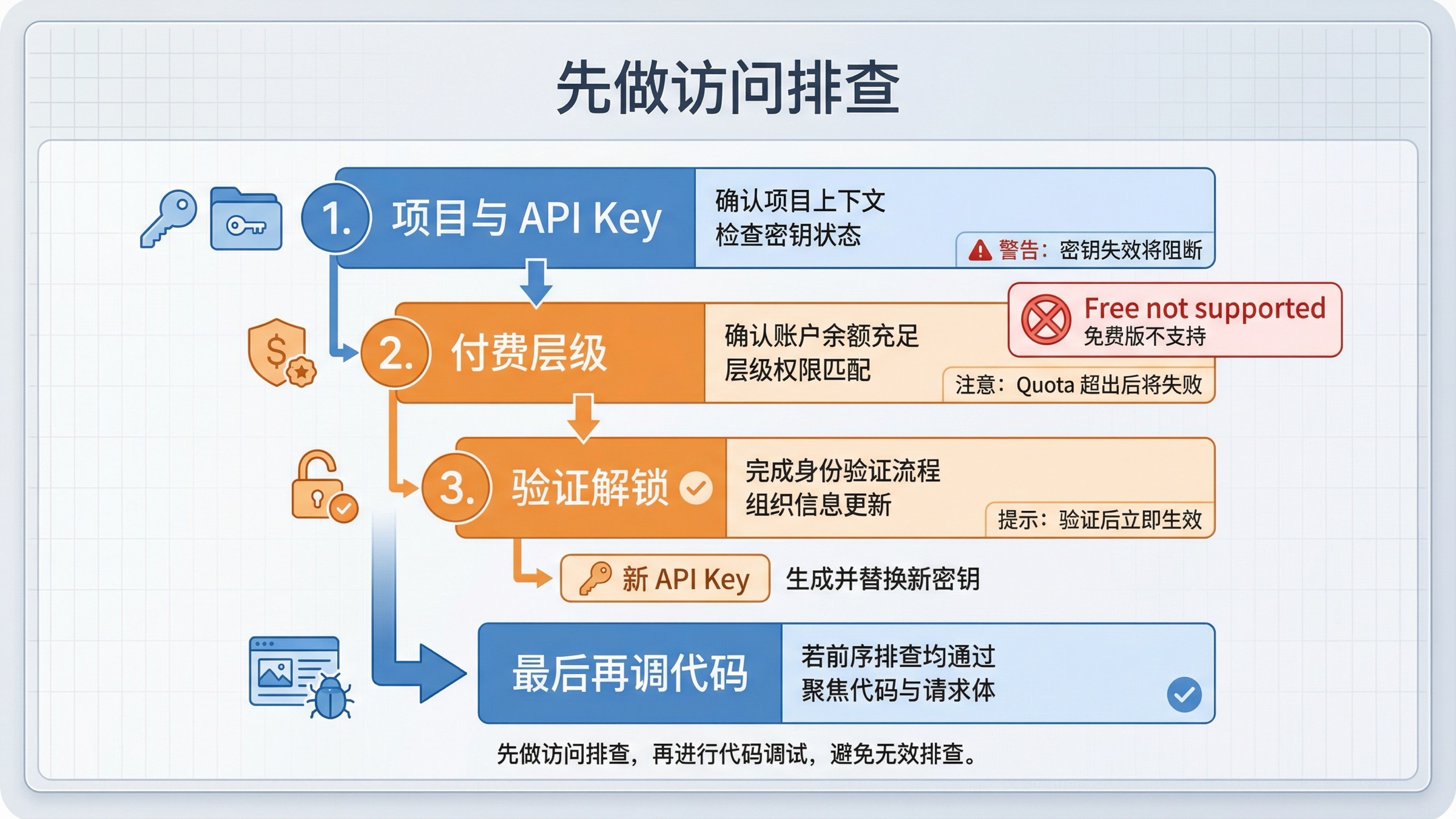
这是 exact-query 结果页另一个最浪费读者时间的地方。很多页面先给样例,再很晚才承认“你的账号可能根本还没 ready”。
OpenAI 当前的 API model availability 说明 写得很直接:GPT-image-1 和 GPT-image-1-mini 面向 Tier 1 到 Tier 5 的 API 用户开放,但部分访问仍然受 organization verification 影响。 当前 gpt-image-1-mini 模型页 也明确标了 Free not supported,并且 Tier 1 从 100,000 TPM 与 5 IPM 起。
所以最稳的排查顺序不是“多试几次 prompt”,而是:
- 确认 API key 属于正确的 project 和 organization。
- 确认账号已经处于支持该模型的付费 tier。
- 如果 access 看起来还是不对,确认是不是 organization verification 才是真正阻塞点。
- 只有在这些都排完之后,才去怀疑 prompt、SDK 代码或输出解析。
OpenAI 当前的 organization verification 帮助文档 还补了一层很关键的操作信息:verification 可以解锁 image generation capability;状态同步可能要等到 30 分钟;如果还提示 not verified,重新生成 API key 经常能立即解决。这不是 model-selection 问题,而是 account-state 问题。
如果你真正卡住的是权限、验证或组织状态,下一篇更适合看的是 OpenAI 图片 API 验证问题排查,而不是再找一个长得差不多的样例。
这一点值得单独强调一次,因为很多开发者会在 access 未确认时直接改 prompt、切 SDK 版本、甚至整个改走 Responses。那样做通常只是扩大排查面。对 gpt-image-1-mini 来说,先确认账号状态,再怀疑代码,几乎总是更快的路线。
什么时候 gpt-image-1-mini 是正确默认值,什么时候不是
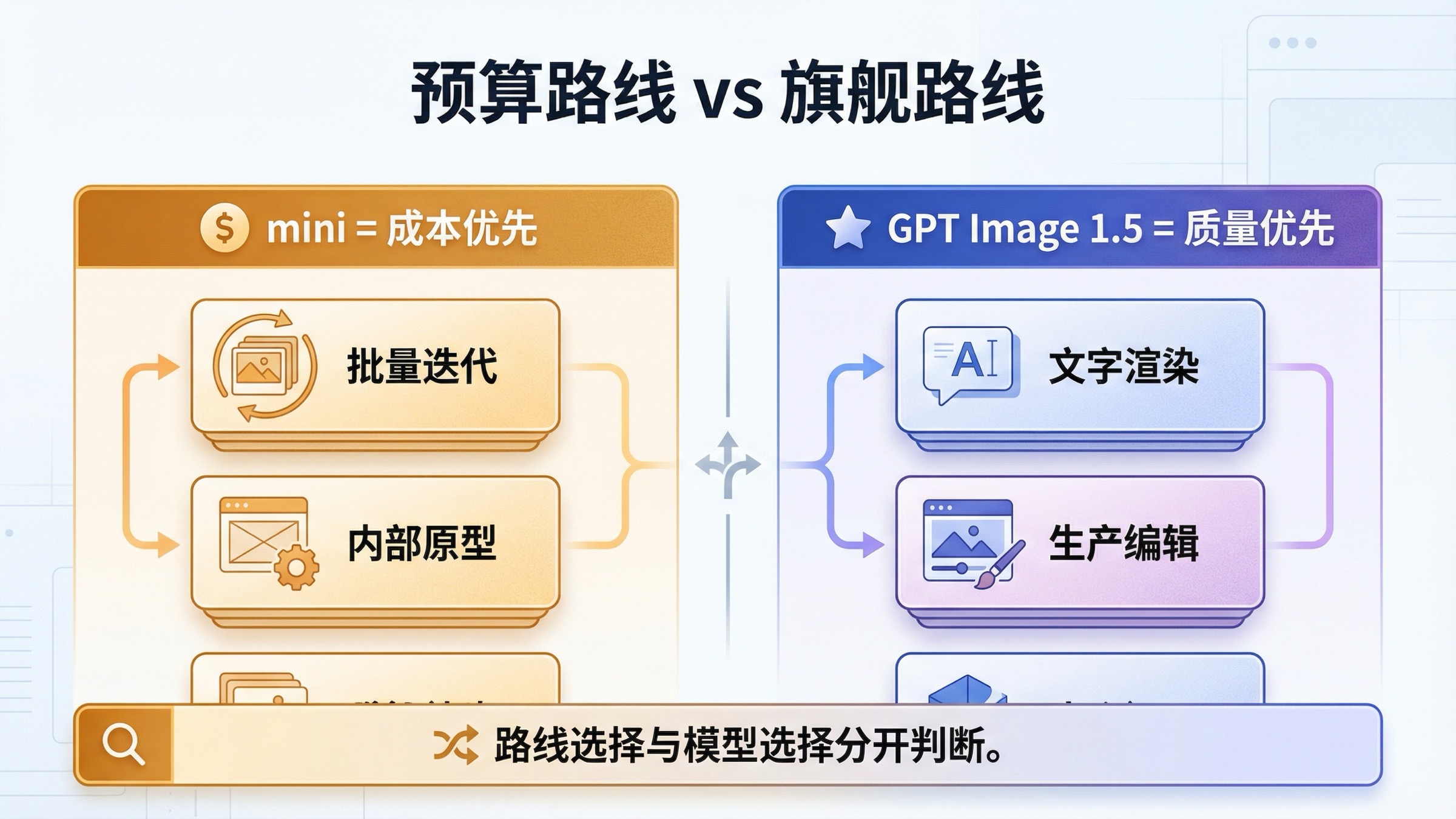
这部分最需要说实话。gpt-image-1-mini 是预算路线,不是通用路线。 当前 image-generation guide 的表述很明确:最佳体验优先看 GPT Image 1.5;如果 image quality 不是首要问题,而 cost 更重要,再看 mini。当前 mini 模型页给出的价格也把这个分工写得很清楚:截至 2026 年 3 月 27 日,1024x1024 low / medium / high 是 $0.005、$0.011、$0.036。
这在哪些工作流里会非常有价值?
- 批量 prompt 试错
- 内部原型图
- 大量草稿图
- 低风险变体生成
- 成本敏感比顶级输出质量更重要的功能
但错误的读法是:“既然 mini 最便宜,那以后都默认 mini。” 正确的读法是:当成本是第一约束时,mini 是你该先 benchmark 的当前官方路线。
如果你的工作流更依赖高质量输出、复杂编辑、更稳的文字渲染,或者一次失败的返工成本很高,那么你真正该比较的往往不是“mini vs Responses”,而是“mini vs GPT Image 1.5”。这时更适合继续看 OpenAI 图像生成 API 定价 或 GPT Image 1.5 API 定价详解,因为问题已经不只是 route,而是更便宜的模型是不是也能带来更便宜的总工作流成本。
这也是 exact query 页面最容易遗漏的诚实结论。很多页面会把“单张价格更低”直接包装成“产品决策更优”,但真正的生产成本往往还包括失败重试、输出不达标导致的人工返工,以及为了补质量差距而增加的二次处理。mini 的价格优势是真实的,但它不是对所有工作流都同样成立的总成本优势。
直接 edit 也还是同一条 route
这里有一个经常被包装页说得过度复杂的点:你不需要为 edit 再建立第二套 API 世界观。当前 mini 模型页本身就列出了 v1/images/generations 和 v1/images/edits。也就是说,如果你的生成路线已经在 Images API 上,那么 edit 通常也继续留在同一条 direct route 上。
最小 edit 请求可以像这样写:
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.edit({ model: "gpt-image-1-mini", image: fs.createReadStream("room.png"), prompt: "Turn this room into a bright Nordic living room with pale oak shelves and soft morning light.", size: "1024x1024" }); const imageBase64 = result.data[0].b64_json; fs.writeFileSync("room-nordic.png", Buffer.from(imageBase64, "base64"));
同样的 route rule 依然成立:如果你做的是 direct edit,先留在 Images API。只有当编辑只是更大对话式或多工具系统的一部分时,再考虑切到 Responses。
排错:薄包装页不会帮你解决的问题
一个真正有用的 exact-match 页面,不只是告诉你“模型存在”,而是帮你避开第一次成功请求之后仍然会踩的坑。
第一个坑是 太早走 Responses。如果你的功能只是“生成一张图”或“编辑一张图”,更大的抽象只会让你更容易调试错层。当前官方文档其实已经给了你先走更小路线的理由。
第二个坑是 把 mini 当成所有工作负载的统一答案。官方文档并不是这样定位它的。它把 mini 放在 cost-efficient branch,把 GPT Image 1.5 放在 best-experience branch。如果你把这个分工抹平,最后就会在错误的基线上做预算和选型。
第三个坑是 在 access 没确认前就开始重写代码。help center 已经写得很清楚,tier access 和 organization verification 都可能阻塞 image capability。账号状态没 ready,再多一个样例也救不了。
第四个坑是 把“精确关键词文章”误读成“只要做成模型卡就够了”。其实很多读者不是要看一页 product summary,而是要看“到底先做什么、什么情况下不要继续沿着这个默认值走下去”。这也是为什么这篇文章不再重复更宽的 OpenAI image tutorial,而是把 exact query 真正缺的那层 workflow judgment 补上。
还有三个非常常见、值得直接点名的失败分支。如果第一条请求就报 access 风格的错误,最可能的原因通常不是 sample 过期,而是 tier、project 或 verification 没准备好。如果请求能成功但图片质量不够,那问题通常也不是 endpoint 选错,而是 mini 本身不适合这个生产任务。最后,如果团队坚持用 Responses,只因为“官方现在更多地方在展示它”,那就回到产品层面问一句:我们真的需要同一个 request 里同时承载会话状态、推理步骤和图片工具吗?
FAQ
gpt-image-1-mini 能直接做 edit 吗?
可以。当前官方模型页同时列出了 v1/images/generations 和 v1/images/edits,所以 direct edit 仍然可以走 Images API,不需要因为 edit 就默认切到 Responses。
gpt-image-1-mini 有 free tier 吗?
按 2026 年 3 月 27 日当前模型页的写法,没有。页面明确标了 Free not supported,真正起步是付费 Tier 1。
什么时候应该直接改看 GPT Image 1.5?
当你的工作流更看重输出质量、稳定文字渲染、复杂编辑,或者一次失败会带来更高返工成本时,就不该只盯着 mini 的单张价格。那时更应该把 GPT Image 1.5 一起 benchmark。
最后的建议
如果你今天要接 gpt-image-1-mini,先走 Images API。 第一张生成图这样做,第一张 edit 图也这样做,并且把请求保持在足够容易排查的范围里。只有当图片生成只是更大 multimodal workflow 里的一个环节时,才去用 Responses。
然后再把第二个问题单独拿出来判断:mini 到底是不是这个工作负载的正确模型? 如果成本是第一约束,它是很合理的第一 benchmark;如果质量、文字渲染、复杂编辑更重要,就不要让“最便宜”替你做完整决策。这个关键词真正应该记住的,就是 route choice 和 model choice 是两件事。