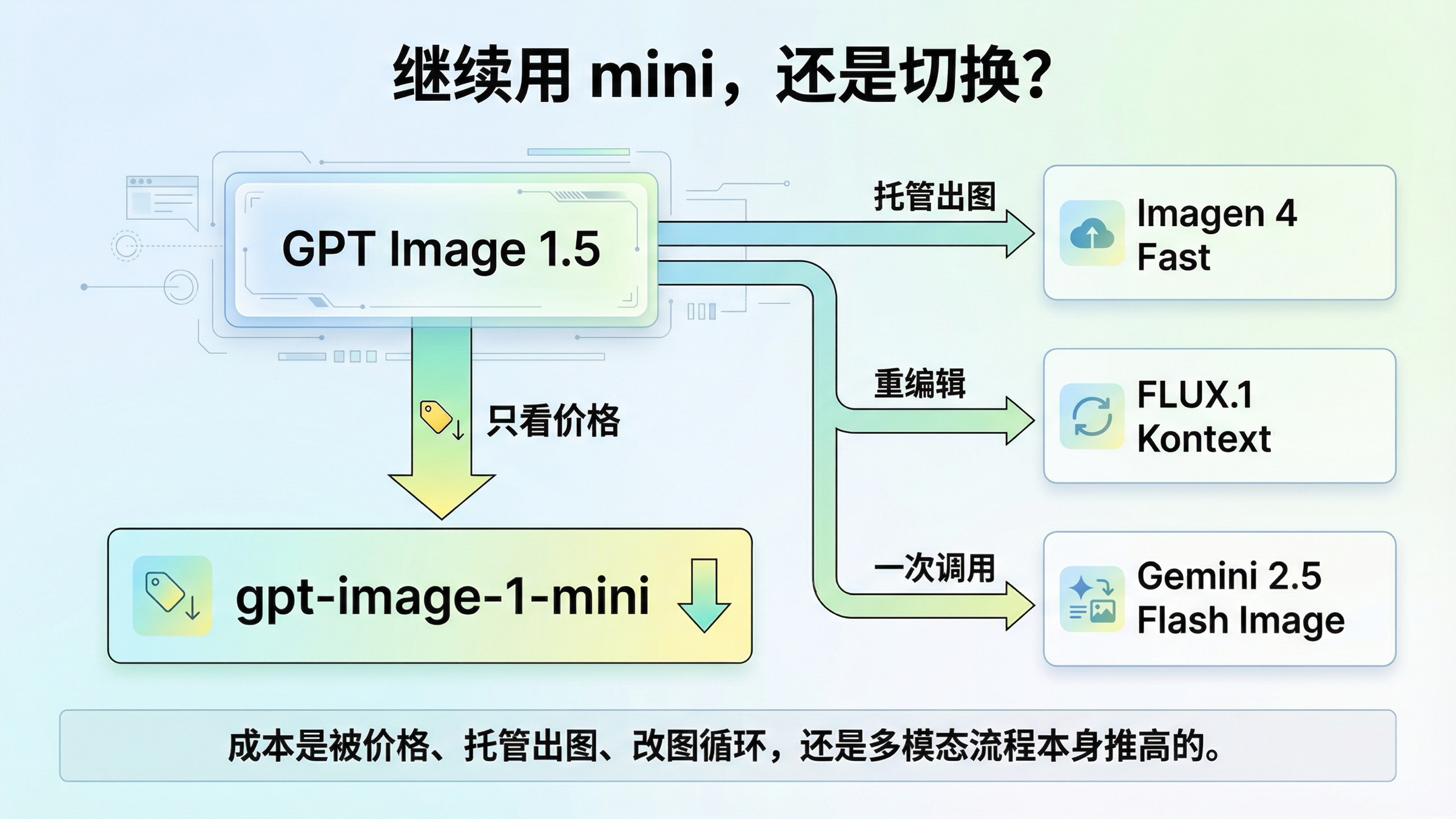
截至 2026 年 3 月 29 日,gpt-image-1.5 cheaper alternative 这类搜索最容易答错的地方,是把“更便宜”自动理解成“必须换供应商”。如果你的问题只是单纯想把账单压低,第一步通常仍是 OpenAI 自家的 gpt-image-1-mini。OpenAI 当前给出的 1024x1024 正方形价格还是 low \$0.005、medium \$0.011、high \$0.036。只有当“更便宜”真正指向另一种工作流时,外部替代方案才成立:想找比 GPT Image 1.5 medium 或 high 更便宜的托管出图,看 Imagen 4 Fast;反复改图拖高了有效成本时,看 FLUX.1 Kontext;一次调用必须同时理解文字再出图时,才看 Gemini 2.5 Flash Image。
这正是当前很多搜索结果没有分清的地方。有些页面在回答“有什么比 GPT Image 1.5 更便宜”,有些页面其实在回答“有什么比 OpenAI 整体更便宜”。这两个问题不一样,因为 OpenAI 自己已经有一条明显更低的预算路线,而这一个事实就足以改变大部分读者的第一步。
还有一类搜索,其实也不是真正的价格决策。有人觉得 GPT Image 1.5 “太贵”,但真实问题可能是 429、组织验证、调用路径写错,或者根本还没有把 mini 跑成一个像样的基准。那种情况下,换平台并不会自动解决成本感受,它只会把一种排错变成另一种排错。
要点速览
如果你只想先拿到结论,先看这张表。
| 你真正嫌贵的是…… | 更便宜或更合适的路线 | 为什么这是当前最可信的降本动作 | 主要代价 |
|---|---|---|---|
| 只是想把 GPT Image 1.5 的单价压低 | gpt-image-1-mini | OpenAI 当前公开价格在三个正方形档位都低于 GPT Image 1.5 | 你放弃的是旗舰路线的更高上限 |
| 想找比 GPT Image 1.5 medium / high 更便宜的托管出图 | Imagen 4 Fast | Google 当前把它列成 \$0.02/张,对比 GPT Image 1.5 medium 与 high 有明确价格优势 | 它不是 OpenAI 同一接口里的预算档 |
| 真正贵的是反复改图、返工和文字修订 | FLUX.1 Kontext | 它的价值在于减少“重来一次”的次数,降低有效成本 | 标出来的单张价格并不是最低 |
| 一次交互需要先理解文本,再返回图像 | Gemini 2.5 Flash Image | 一个多模态调用可能替代多个分开的模型步骤 | 它是 token 计费,不是最好算的单图价格 |
| 你现在被 429、验证或权限状态卡住 | 先留在 OpenAI,把配置修好 | 这类问题不是换供应商就能直接解决 | 你仍要先把接入路线跑通 |
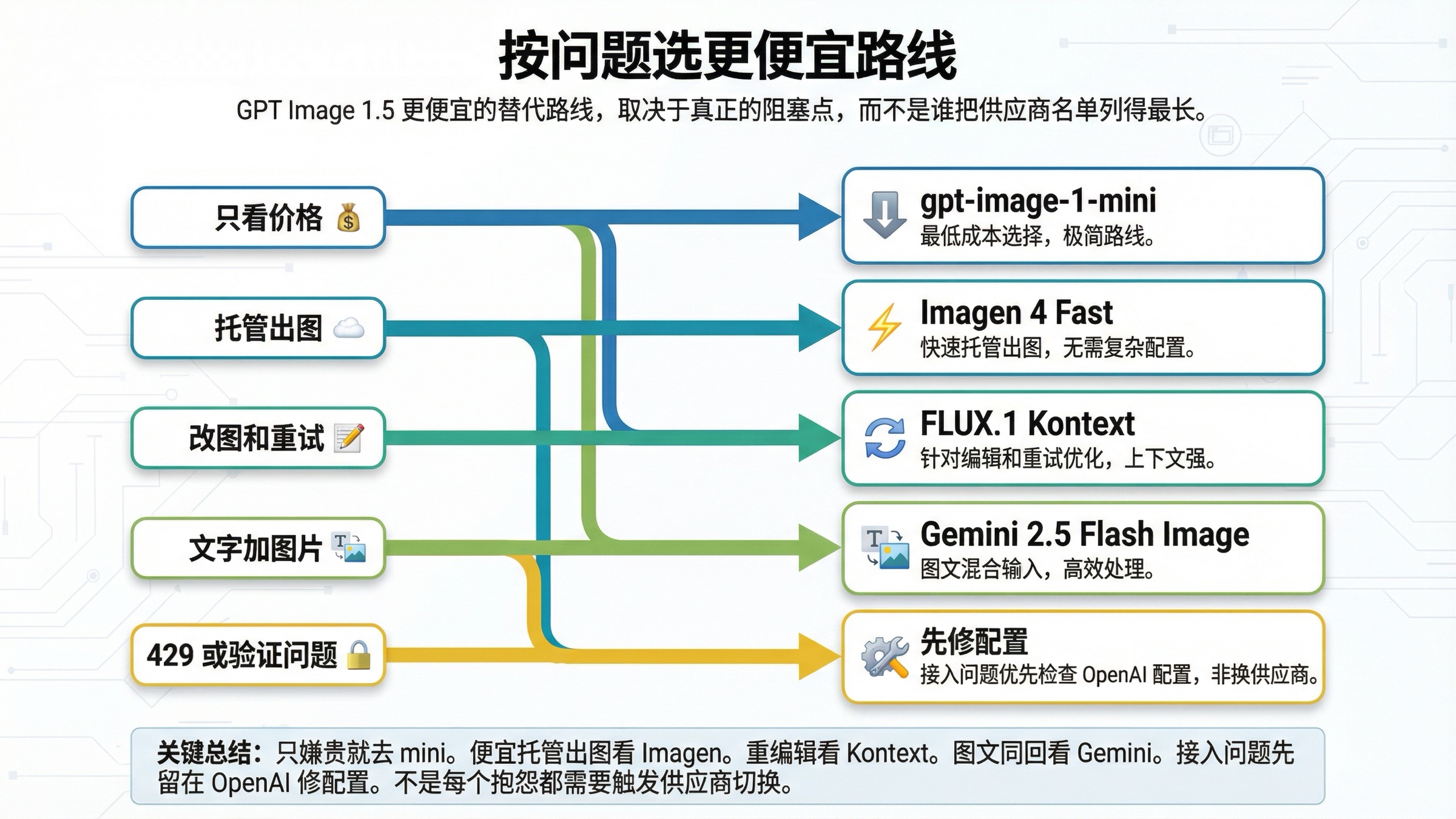
最短的判断规则其实很简单。如果价格就是全部问题,先留在 OpenAI 并下调到 mini。只有当“贵”的根源来自托管出图路线、重编辑循环,或多模态编排本身时,外部替代方案才真的成立。
现在到底什么比 GPT Image 1.5 更便宜?

要把这个关键词答清楚,必须先把“价格表面”分开看。OpenAI 当前的 GPT Image 1.5 模型页 把 1024x1024 正方形生成列为 \$0.009、\$0.034、\$0.133,分别对应 low、medium、high。OpenAI 当前的 gpt-image-1-mini 模型页 则列出 \$0.005、\$0.011、\$0.036。仅这两组数字,就足以说明一个经常被省略的事实:如果你的问题只是“我要不要继续留在 OpenAI,但换一条更便宜的图像路线”,那第一答案仍然是 OpenAI 自己。
外部替代方案当然重要,但它们成立的条件更窄。Google 当前的 Vertex AI 定价页 把 Imagen 4 Fast 列成 \$0.02/张,因此它确实是一个“比 GPT Image 1.5 medium 和 high 更便宜”的主流托管出图答案。Black Forest Labs 当前的 定价页 把 FLUX.1 Kontext [pro] 列成 \$0.04/张,这并不比 GPT Image 1.5 medium 的 \$0.034 更低,但在多轮编辑流程里,它仍可能通过减少返工而变得更便宜。Google 当前的 Gemini 2.5 Flash Image 文档 说明一张生成图片会消耗 1290 个 image output tokens;结合 Vertex AI 当前 \$30 / 1M image output tokens 的价格,单看输出图片部分,大约可以推算出每张图 \$0.0387 的输出成本。这是根据官方数字推导出的近似值,不是 Google 单独发布的一张“固定每图价”。
所以这里更适合用决策表,而不是品牌排行榜。
| 选项 | 当前价格表面 | 它比谁便宜 | 最适合的工作 | 为什么它不是通用答案 |
|---|---|---|---|---|
| GPT Image 1.5 | \$0.009 / \$0.034 / \$0.133 | 只作为参考基线 | 旗舰图像质量与更稳的高质量输出 | 你已经在支付旗舰溢价 |
gpt-image-1-mini | \$0.005 / \$0.011 / \$0.036 | 在三个正方形档位都低于 GPT Image 1.5 | 大量原型、低风险出图、成本优先场景 | 不能替代所有高要求质量与编辑诉求 |
| Imagen 4 Fast | \$0.02/张 | 明确低于 GPT Image 1.5 medium 和 high | 想找更便宜的主流托管出图路线 | 它并不比 mini 更便宜 |
| FLUX.1 Kontext [pro] | \$0.04/张 | 更多是“有效成本更低”,而不是 headline 更低 | 反复改图、保留主体、改文字、做变体 | 价值来自少返工,不是最低标价 |
| Gemini 2.5 Flash Image | 输出图像约 \$0.0387,尚未含输入 token | 只有当工作流压缩本身省钱时才成立 | 一次调用要同时理解文本与产图 | 很难用“每张图多少钱”直接比较 |
这也是为什么我会把这篇文章和 GPT Image 1.5 API 定价、GPT Image 1.5 每张图成本 分开写。前两篇更适合解释官方价格本身,这篇文章真正回答的是“什么时候该切换路线”。
如果只是价格问题,继续用 gpt-image-1-mini
这是整篇文章最重要的一段,因为它决定了页面是否真正值得信。OpenAI 当前的 image generation guide 直接说明:如果图像质量不是首要目标,gpt-image-1-mini 是更有成本优势的选择。这个提示不是边角料,它其实就是很多团队的默认答案。
如果你的工作负载主要是高频试稿、内部草图、概念图、大量低风险变体,或者你本来就在做一轮又一轮的便宜探索,那 mini 往往比“换供应商”更像正确的第一步。你可以继续留在同一套 OpenAI 接口、账单体系和权限体系里,不必马上改云路线、不必马上重写接入层,却能把可见单价明显压下来。对于 square 1024x1024,mini 的 low、medium、high 分别是 \$0.005、\$0.011、\$0.036,而 GPT Image 1.5 对应是 \$0.009、\$0.034、\$0.133。这不是小折扣,而是另一条价格层。
很多“更便宜替代方案”页面的问题就在这里。它们看到用户嫌贵,就直接把建议导向“离开 OpenAI”。但预算问题不一定是供应商问题,它可能只是路线选择问题。团队以为自己在证明 GPT Image 1.5 太贵,实际上证明的可能只是“我们一开始就不该上旗舰路线”。
当然,这也不代表 mini 是一切降本问题的万能解。若你的痛点是更稳定的高质量、文字渲染、品牌一致性、客户可交付成片,或者一旦出错就会造成更大返工,那 GPT Image 1.5 的旗舰溢价可能依然合理。可正因为如此,靠谱的文章必须先告诉读者:什么时候不该离开。
如果你想把 OpenAI 自家的成本面再看深一点,可以继续读 OpenAI 图像生成 API 更便宜的替代方案 和 GPT Image 1 Mini 定价。这两篇更适合把 OpenAI 内部的预算路线单独拆开讲透。
想找更便宜的托管出图路线时,用 Imagen 4 Fast
如果你已经确认,自己真正觉得贵的是 GPT Image 1.5 本身,而不是 OpenAI 的预算路线,那么 Imagen 4 Fast 是最清晰的主流外部答案。
Google 当前的 Vertex AI 定价页 把 Imagen 4 Fast 列为 \$0.02/张,而当前的 Imagen 4 文档 也把它定位成更偏纯图像生成的一条产品线,并支持一个 prompt 返回多张图。这一点很重要,因为它说明你比较的是“图像生成路线对图像生成路线”,而不是把多模态聊天模型硬塞进同一种价格对比里。
这条路线最适合下面这种判断:“我仍然需要一个托管图像生成服务,但 GPT Image 1.5 medium 或 high 对我的量级太贵了。”在这种情况下,Imagen 4 Fast 的优势很干净。价格表面更容易理解,产品形态也更接近原始工作,不必先解释多模态 token 账本,也不必用“有效成本”把读者带进太复杂的推理里。
但我不会把 Imagen 4 Fast 描述成整个决策树里的最低价答案。它的优势非常具体:它比 GPT Image 1.5 的中高档位更便宜,是一个主流、清晰、按图片计费的托管出图替代路线。 可它仍然不是 mini 的替代,更不是对所有图文工作流都最优的路线。
换句话说,Imagen 4 Fast 回答的是“有没有比 GPT Image 1.5 更便宜、而且仍然像传统 hosted image generation 的路线”,不是“有没有比所有 OpenAI 图像选项都更便宜”。
当重试和改图才是真正成本中心时,用 FLUX.1 Kontext
有些团队并不是第一张图太贵,而是第二次、第三次、第四次修改把总成本拉高了。那时,真正昂贵的已经不是“出图”,而是“为了保住已经对的部分而不断重来”。
这正是 FLUX.1 Kontext 该被放进这篇文章的原因。Black Forest Labs 当前的 Kontext 概览页 把重点放在 image editing、character consistency、text editing、style transformation 这些能力上。它卖的不是更低的首图标价,而是更强的“保留已经对的内容,只改局部”的能力。
这也是它最容易被误读的地方。BFL 当前的 定价页 把 FLUX.1 Kontext [pro] 列成 \$0.04/张。这行数字显然不是全场最低,也并不低于 GPT Image 1.5 medium 的 \$0.034。如果你只看第一行表,它看起来像一个不够“便宜”的答案。
但这正是错误的读法。更关键的问题不是“第一张多少钱”,而是“为了拿到一张真正能保留的图,我总共要付几次钱”。如果你的团队经常在做这些事:
- 保留角色,只换背景
- 保留构图,只改图上的字
- 保留产品主体,只做不同活动版本
- 保留大部分画面,只改一个局部元素
那么你的成本中心其实是返工次数。在这种场景下,一个能更好保留前一轮结果的模型,即使首图单价更高,也可能比每次都接近重画的路线更便宜。FLUX.1 Kontext 更像“有效成本更低”的答案,而不是“公开价格最低”的答案。
这也是为什么我不会把它放成默认第一推荐。只有当钱真正漏在改图循环里时,它才会从“看起来不便宜”变成“实际更省钱”。
只有当一次调用必须同时思考和出图时,才用 Gemini 2.5 Flash Image
Google 在这篇文章里要出现两次,因为它提供的是两种完全不同的答案。Imagen 4 Fast 是更便宜的托管出图路线。Gemini 2.5 Flash Image 则是“一个调用同时理解文本、接收图像上下文、继续对话,再生成图像”的多模态路线。它们不该被混在一起讨论。
Google 当前的 Gemini 2.5 Flash Image 文档 明确写到,这个模型支持 text 和 image input,并返回 text 和 image output,还支持 多轮图像编辑。这意味着你购买它,往往不是为了拿到最简单的一张图价格,而是为了把原本要拆开的文本理解、图像生成、流程编排压进同一个表面。
因此,它不适合作为“纯出图谁最便宜”的默认答案。单看图像输出成本,它不如 mini 那么低,也不是一个足够干净的“比 GPT Image 1.5 medium 更便宜”的 headline 胜利。Gemini 成立的场景,是工作流本身昂贵,而不是图片单价本身昂贵。比如你原来需要一个文本模型来理解需求,再接一个图像模型来画图,中间还要维护上下文和业务 glue,那么 Gemini 可能通过减少模型数和编排成本,让总账更省。
也正因为如此,弱一点的 roundup 页面很容易把 Gemini 写错。它们看到一个 Google 图像模型,就把它和其他生成器放在同一行里比较单价,却忽略了它真正的购买理由。Gemini 2.5 Flash Image 只有在“一个调用必须既能想、又能说、又能画”时,才是合理的 cheaper alternative。
真正的问题是配置,不是价格时怎么办
这个关键词里还混着一大类“看起来像价格问题,实际是接入问题”的搜索。OpenAI 当前关于 API 模型可用性、usage tier 与组织验证状态 的帮助文档说明,gpt-image-1 和 gpt-image-1-mini 都可能受到 usage tier 和组织验证状态的影响。这意味着一次糟糕的初次接入体验,并不能自动证明“这个模型太贵”或者“外部供应商一定更好”。
这很关键,因为接入摩擦会改变人们对价格的主观感受。一次 429、一次权限失败、一次路由写错,就足以让每次尝试都显得“很贵”,哪怕你还没有跑出一个有意义的成本基准。此时如果你直接换平台,很可能只是把一种排错变成另一种排错,而不是把预算问题真正解决掉。
所以这里的判断规则也应该很简单。如果问题在账号状态、验证、tier、路由或接入路径,先把这些修好。只有当接入已经稳定,工作流真实跑通之后,价格比较才有意义。 这也是为什么我会把“先留在 OpenAI 修好配置”单独当成一个有效答案,而不是默认把所有抱怨都导向迁移。
我会怎样用一个下午完成切换测试
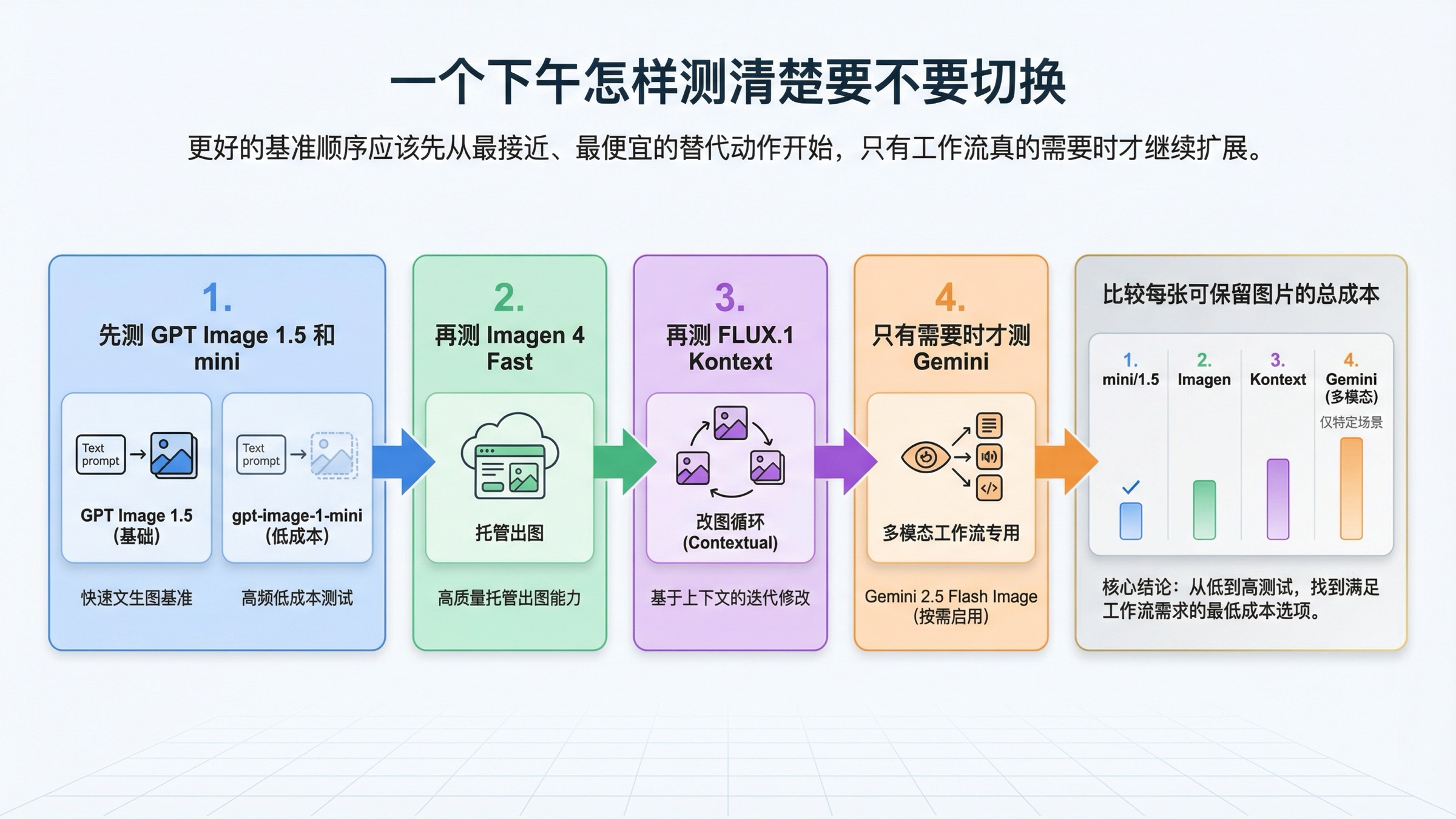
真正能避免错误迁移的方法,不是看更多品牌名,而是针对真实问题做一个足够窄的测试。
- 先用同一组 prompt 比较 GPT Image 1.5 和
gpt-image-1-mini。如果 mini 已经够用,就先停在这里。 - 再做一组纯生成基准,把 Imagen 4 Fast 放进来,专门比较“托管出图成本能不能明显低于 GPT Image 1.5 medium 或 high”。
- 再做一组重编辑基准,让 FLUX.1 Kontext 处理“保留主体、换局部、改文字、做变体”这类任务,测它能不能减少返工。
- 只有当产品真的需要一轮同时返回文字和图片时,才加测 Gemini 2.5 Flash Image。
- 最后比较的不是第一张图价格,而是“拿到一张真正能保留的图,总共花了多少钱和多少操作成本”。
这个顺序是故意收窄的。很多较弱的比较页面喜欢先做大盘点,而更有效的测试顺序,应该永远从最接近当前栈、最便宜、迁移摩擦最低的那个候选项开始。
最后结论
GPT Image 1.5 更便宜的替代方案,并不是一个统一赢家,而是一条与你真实问题匹配的更便宜路线。
如果你只是觉得价格高,先用 gpt-image-1-mini。如果你想找一条比 GPT Image 1.5 medium 或 high 更便宜、而且仍然像传统托管出图的路线,看 Imagen 4 Fast。如果真正拖高成本的是改图和返工,看 FLUX.1 Kontext。如果一轮调用必须同时理解文本并生成图片,再看 Gemini 2.5 Flash Image。如果你现在主要被 429、验证或路由问题卡住,先把 OpenAI 的接入修好,再判断是否真的需要迁移。