
当结果依赖更强的推理、更少的重试,或者更大的 1.05M** 上下文窗口时,就用 GPT-5.4;当你更想要一个更便宜、更快、更高吞吐的编码、computer use 和 agent 工作流默认值时,就用 GPT-5.4 mini。**
这不是旧版与新版的迁移故事。它们都是当前 GPT-5.4 家族里的现役模型。真正的问题是:你的工作流到底需要多少旗舰级余量,以及这部分余量是否值得多付钱。
要点速览
如果你只想记住一句规则,请记这个:
- GPT-5.4 负责高质量、高风险、长上下文任务
- GPT-5.4 mini 负责更便宜、更高吞吐的大量生产型任务
| 维度 | GPT-5.4 | GPT-5.4 mini | 实际判断 |
|---|---|---|---|
| 发布时间 | 2026 年 3 月 5 日 | 2026 年 3 月 17 日 | 两者都很新,但 mini 的内容 SERP 还更“新鲜” |
| 当前官方定位 | 通用高质量默认模型 | 高体量编码、computer use、Agent 工作流模型 | 这是默认路由拆分,不是主次之争 |
| 输入价格 | $2.50 / 1M | $0.75 / 1M | GPT-5.4 约贵 3.3 倍 |
| Cached input | $0.25 / 1M | $0.075 / 1M | 重复上下文里 mini 更省 |
| 输出价格 | $15 / 1M | $4.50 / 1M | 输出价差也很明显 |
| 上下文窗口 | 1,050,000 | 400,000 | GPT-5.4 在长仓库、长文档任务上明显更强 |
| 最大输出 | 128,000 | 128,000 | 基本一致 |
| 知识截止 | 2025-08-31 | 2025-08-31 | 这不是“新鲜度差异”故事 |
| 当前模型页工具面 | 广泛 Responses API 工具支持 | 同样广泛的工具支持 | mini 不是“阉割工具版” |
| 当前公开高 tier 吞吐 | 15,000 RPM / 40,000,000 TPM | 30,000 RPM / 180,000,000 TPM | mini 更适合高体量生产 |
最关键的不是哪一个绝对更强,而是:你更怕质量不够,还是更怕成本和吞吐跟不上。
真正的分界线:旗舰智能 vs 规模化吞吐
这个比较最容易被误读成“老模型 vs 新模型”。其实不是。两者都在 GPT-5.4 家族内,差异在于它们承担的默认工作不同。
gpt-5.4 的意义,是把更强推理、更大上下文和更高质量输出合在一条主线里。你可以把它理解成“更适合难任务和关键任务的默认模型”。
gpt-5.4-mini 的意义,则是让编码、computer use、subagents 和大规模 worker 请求也能跑在 GPT-5.4 家族里,但成本、吞吐和速度姿态更适合批量生产。
因此,真正该问的是:
- 你的系统主路由,是不是经常要做高难 reasoning 和长上下文分析?
- 你的请求量,是否大到单价和吞吐会比单次质量更重要?
- 你是更需要一个“更稳的总控模型”,还是更需要“更能跑量的 worker 模型”?
如果把问题放在这个层面,决策就清晰很多。
哪些基准差异真正会影响决策
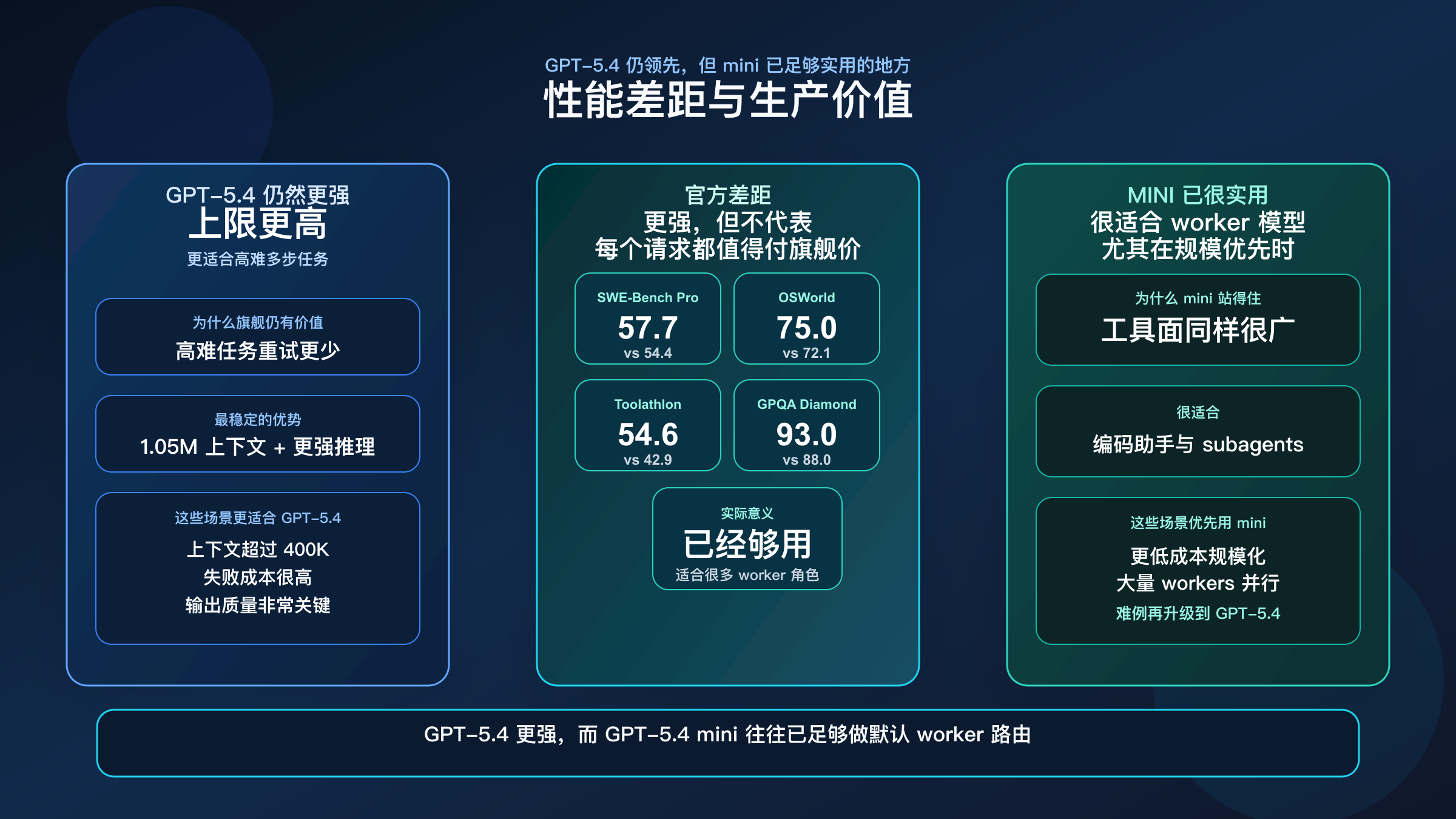
OpenAI 在 2026 年 3 月 17 日的 GPT-5.4 mini 与 nano 发布页 给出了最值得参考的一组官方对比:
| 基准 | GPT-5.4 | GPT-5.4 mini | 实际含义 |
|---|---|---|---|
| SWE-Bench Pro | 57.7% | 54.4% | GPT-5.4 更强,但 mini 已经很接近 |
| Terminal-Bench 2.0 | 75.1% | 60.0% | 长链工具和终端类任务,旗舰优势更明显 |
| Toolathlon | 54.6% | 42.9% | 多工具编排稳定性上,GPT-5.4 仍然更强 |
| GPQA Diamond | 93.0% | 88.0% | 高难推理 headroom 仍在 GPT-5.4 一侧 |
| OSWorld-Verified | 75.0% | 72.1% | computer use 上 mini 已经足够接近,适合很多 worker 场景 |
这组数据最值得注意的地方有三个。
第一,GPT-5.4 的确更强,但 GPT-5.4 mini 并没有差到只能当低端备选。它在 coding 和 computer use 上已经接近到足以支撑很多生产路线。
第二,GPT-5.4 的优势主要体现在高难、多步、失败成本高的任务上。也就是说,它更适合“出一次错就要返工很多”的工作,而不只是“写得更漂亮”。
第三,GPT-5.4 mini 的价值并不来自“便宜但弱”,而是来自“已经足够强,同时更容易大规模使用”。这才是它能成为默认 worker 路由的原因。
如果你还想看 GPT-5.4 在 OpenAI 编码路线里相对专用模型的定位,可以继续看 GPT-5.4 vs GPT-5.3-Codex。
价格、上下文和公开吞吐到底差在哪
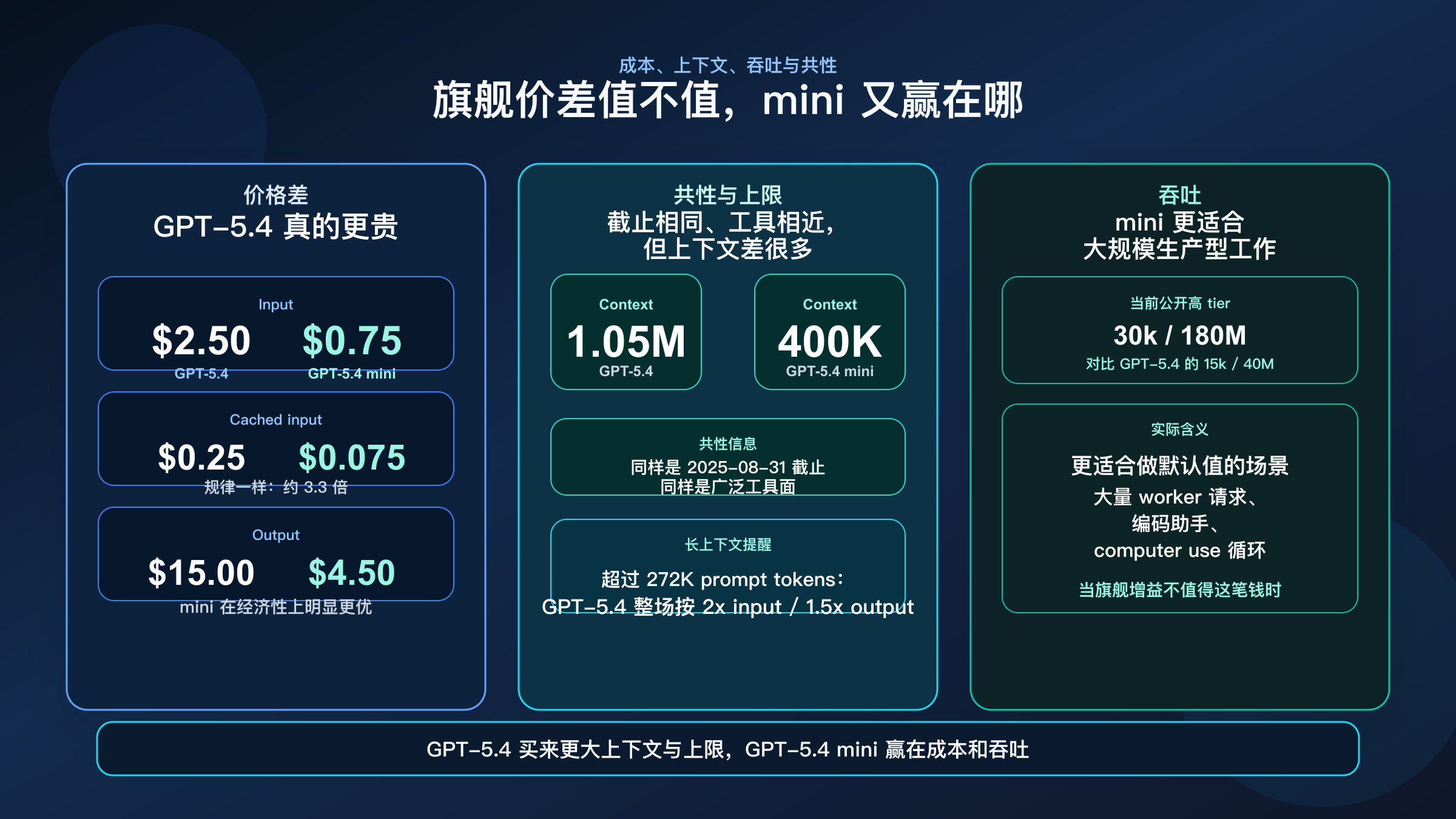
真正会改变预算决策的,不是“5.4 更强”这句话,而是它的强到底值多少钱。
根据当前 GPT-5.4 模型页,GPT-5.4 目前公开价格是:
- 输入 $2.50 / 1M tokens
- Cached input $0.25 / 1M tokens
- 输出 $15.00 / 1M tokens
- 上下文窗口 1,050,000
根据当前 GPT-5.4 mini 模型页,GPT-5.4 mini 目前公开价格是:
- 输入 $0.75 / 1M tokens
- Cached input $0.075 / 1M tokens
- 输出 $4.50 / 1M tokens
- 上下文窗口 400,000
这意味着:无论 input、cached input 还是 output,GPT-5.4 的单价都大约是 mini 的 3.3 倍。这不是“多一点点”,而是非常真实的生产成本差。
但 GPT-5.4 也不是白白更贵。它买来的最核心差异,是 1.05M 上下文。如果你的任务经常需要整仓库、多份规范、长文档和历史过程一起放进一个会话里,那 400K 和 1.05M 的差异会非常实际。
不过,当前 GPT-5.4 模型页还明确写了一个很多比较文章会漏掉的 caveat:如果 prompt 超过 272K input tokens,整场会话会按 2 倍 input、1.5 倍 output 计费。也就是说,GPT-5.4 的大上下文是真优势,但也是要谨慎使用的高价优势。
另一个很多文章没解释清楚的点,是公开吞吐上限差异。当前模型页可见的高 tier 数据里,GPT-5.4 mini 明显更适合高体量请求,这就是为什么它更适合做 worker 路由。
还有一个容易被误解的事实:两者当前模型页都写着 2025-08-31 的知识截止。也就是说,这不是“旗舰更新得多、mini 旧很多”的差别。真正差异还是:质量天花板、上下文、成本和吞吐。
工具支持:mini 并不是“工具弱化版”
很多人一看到 mini,就会默认把它理解成“便宜一些、工具少很多、能力也打折”的分支。当前官方模型页并不支持这种理解。
根据目前的 GPT-5.4 和 GPT-5.4 mini 模型页,两者都列出了广泛的 Responses API 工具支持,包括:
- web search
- file search
- image generation
- code interpreter
- hosted shell
- apply patch
- skills
- computer use
- MCP
- tool search
这点非常关键。因为它说明这个比较并不是“有工具的旗舰”对“没工具的小模型”,而是:
- GPT-5.4:在更难任务上有更高质量和更大上下文天花板
- GPT-5.4 mini:在相似产品表面上,提供更好的成本和吞吐位置
也正因为两者工具面接近,才更需要认真做路由,而不是拍脑袋选贵的或便宜的。
什么时候应该多付钱上 GPT-5.4
当任务的失败成本高于 token 差价时,GPT-5.4 就值得。
以下场景更适合直接让 GPT-5.4 负责:
- 超过 400K 的长上下文仓库分析
- 更复杂的多步 reasoning 和决策
- 更高风险的客户可见输出
- 长时间、跨多个步骤的 agent 执行
- 需要尽量少返工、少重试的关键链路
一句更实用的话是:如果 mini 做错一次,后续返工、补救和人工检查会比多花这点 token 更贵,那就直接用 GPT-5.4。
什么时候 GPT-5.4 mini 才是更聪明的默认值
如果你的问题是“系统怎么更大规模、更便宜地稳定运转”,那 GPT-5.4 mini 往往更适合。
这些场景里,mini 更像正确默认值:
- 大量 subagent / worker 并行执行
- 编码助手的大规模调用
- screenshot-heavy 的 computer use 循环
- 背景批处理、审查、分类、工具调度
- 你已经确认旗舰收益不足以覆盖 3 倍以上成本
也就是说,GPT-5.4 mini 并不是“能力不够才退一步用它”,而是当规模化生产本身就是核心目标时,它反而更像正解。
如果你还在比较 mini 与旧的 budget 分支,可以继续看 GPT-5.4 mini vs GPT-5 mini 和 GPT-5.4 mini vs GPT-5.3-Codex。
API / Codex 结论和 ChatGPT 表层现实不是一回事
从 API 和 Codex 的角度看,路线很清楚:
- GPT-5.4 是通用高质量默认模型
- GPT-5.4 mini 是更小、更快、更便宜的高体量工作路线
但从 ChatGPT 的角度看,现实更复杂。
OpenAI 当前的 ChatGPT release notes 里写到:2026 年 3 月 18 日 起,GPT-5.4 mini 在 ChatGPT 中上线。当前说明里,GPT-5.4 mini 主要以两种方式出现:
- Free 和 Go 用户通过 Thinking 功能使用
- 大多数付费用户在 GPT-5.4 Thinking 触发限额后作为 fallback 出现
同时,文档还明确指出 GPT-5.4 mini 不是普通模型选择器里的标准可选项。这意味着:你不能把 ChatGPT 的可见模型体验,直接等同于 API 模型选型结论。
如果你的团队讨论的其实是 ChatGPT 配额而不是 API 路由,那么中文环境下可以参考 ChatGPT Plus 与免费版 GPT-5 速度和配额差异。
团队该怎么路由最省事
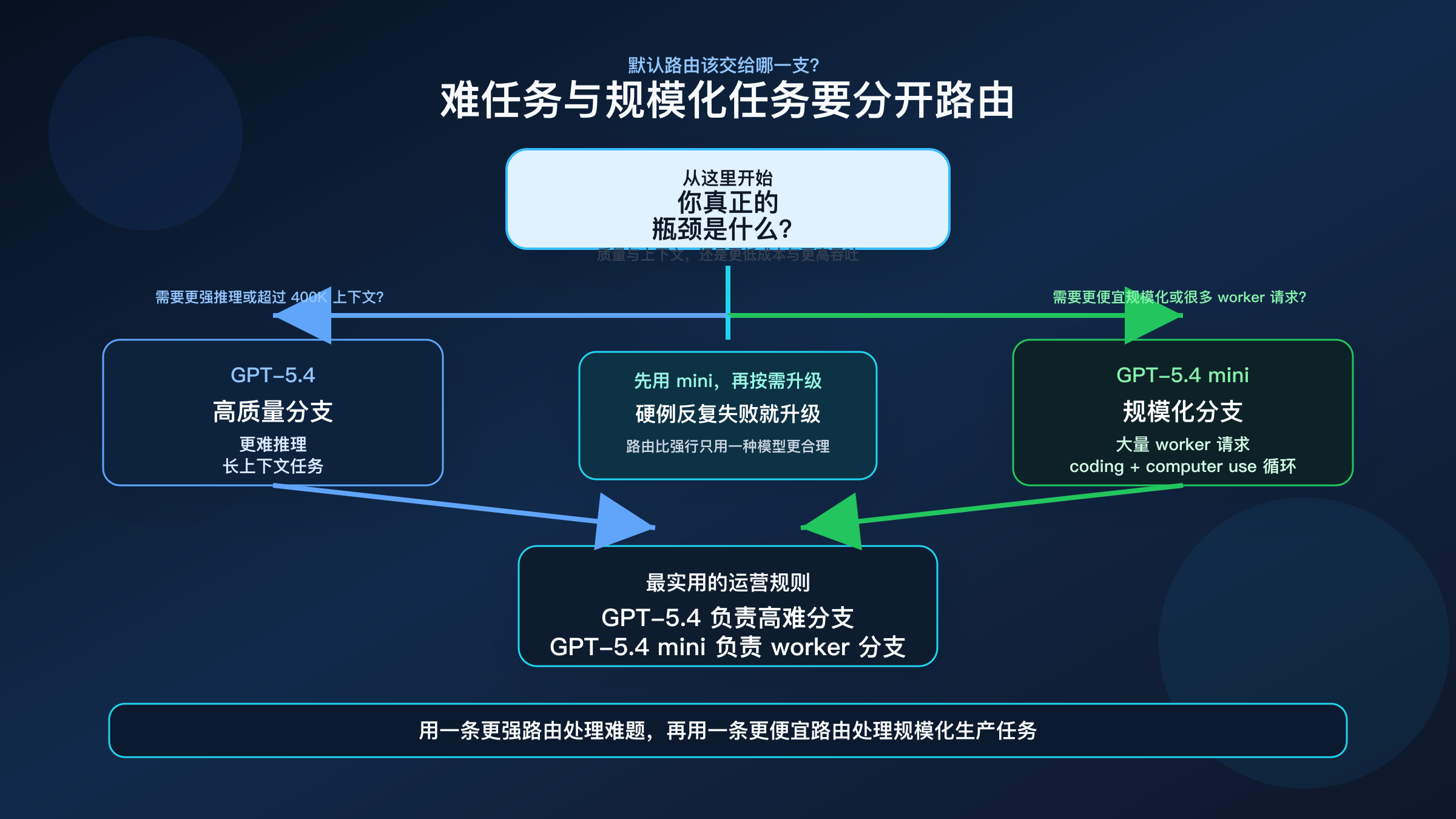
如果你想要一个可以直接写进团队规范里的简化方案,可以这样用:
| 工作类型 | 默认模型 | 原因 | 什么时候升级 / 降级 |
|---|---|---|---|
| 长上下文仓库分析 | GPT-5.4 | 上下文更大,推理更稳 | 只有在 400K 内且非常看重成本时才考虑 mini |
| Planner / 主控 Agent | GPT-5.4 | 更适合高难多步决策 | 如果 planner 很轻且预算极紧,可测试 mini |
| Worker / Subagent | GPT-5.4 mini | 更便宜、吞吐更高 | 碰到高失败成本分支再升级到 GPT-5.4 |
| 编码助手大规模调用 | GPT-5.4 mini | 成本和吞吐位置更合理 | 高难 review 或复杂修复时升级 |
| 关键输出链路 | GPT-5.4 | 更高质量天花板 | 只有在结果非常接近且预算压力很大时再降级 |
对很多团队来说,最稳定也最容易解释的做法就是:
- 高难主线默认走 GPT-5.4
- 大量 worker 和规模化任务默认走 GPT-5.4 mini
- mini 失败成本明显上升时,再升级到 GPT-5.4
这比“所有任务统一一条模型路线”更符合当前 OpenAI 家族的实际分工。
FAQ
GPT-5.4 mini 够不够做严肃的编码 Agent?
很多场景下是够的。官方对比里,它在 SWE-Bench Pro 和 OSWorld-Verified 上已经相当接近 GPT-5.4,同时单价和公开吞吐都更适合大规模使用。
GPT-5.4 mini 的工具是不是比 GPT-5.4 少很多?
按当前模型页看,不是。两者都列出了 web search、file search、image generation、code interpreter、hosted shell、apply patch、skills、computer use、MCP 和 tool search。真正差异更多在质量天花板、上下文和成本位置。
GPT-5.4 的 1.05M 上下文是不是最主要的选择理由?
它是很重要的理由之一,但不是唯一理由。GPT-5.4 同时在更难 reasoning 和工具链任务上也有更强 headroom。如果你的任务长期都在 400K 以内,那上下文优势的重要性就会下降。
对于 Codex 风格 subagents,到底该选哪个?
很多 subagent 场景下,GPT-5.4 mini 反而更像默认值,因为它更便宜,也明确面向高体量 coding / agent workflows。把 GPT-5.4 留给更难的 planner 和升级路径,通常更合理。
ChatGPT 里的表现能不能直接代表 API 结论?
不能。API 和 Codex 的模型选型逻辑,与 ChatGPT 的 fallback、Thinking 和 model picker 可见性,不是同一层面的事情。
一句话总结:GPT-5.4 负责更难、更贵但更关键的任务;GPT-5.4 mini 负责更便宜、更高吞吐的大量任务。 如果你把团队的默认路由按这个方式拆开,这个关键词背后的决策就已经足够清楚了。