
先说结论: 对大多数开发者来说,GPT-5.4 已经是更值得默认选择的模型。OpenAI 在 2026 年 3 月 5 日 发布 GPT-5.4 时,明确表示它已经吸收了 GPT-5.3-Codex 的前沿编程能力,同时把这些能力放进了更强的主线推理模型里。换句话说,如果你的工作不仅仅是写代码,还包括长上下文分析、工具调用、检索、补丁、系统操作,那么 GPT-5.4 更适合作为“默认路由”。
但这并不意味着 GPT-5.3-Codex 失去价值。GPT-5.3-Codex 于 2026 年 2 月 5 日 发布,它仍然保留两个很实际的优势:第一,输入价格更低;第二,它在 Terminal-Bench 2.0 上依旧高于 GPT-5.4。这意味着如果你的工作明显偏向 shell、CLI、部署脚本、终端调试,或者你的系统本来就很在意 prompt 成本,那么 GPT-5.3-Codex 依旧值得保留。
本文基于 2026 年 3 月 19 日 重新核对的 OpenAI 官方发布页、当前 API 模型文档与价格页来写,不把社区故障贴当作官方事实,也不把基准测试当成唯一答案。真正要回答的是:今天你到底应该把哪个模型设成默认值?
要点速览
如果你只想要一句建议:默认用 GPT-5.4,按需保留 GPT-5.3-Codex。
| 维度 | GPT-5.4 | GPT-5.3-Codex | 实际建议 |
|---|---|---|---|
| 发布时间 | 2026 年 3 月 5 日 | 2026 年 2 月 5 日 | GPT-5.4 更新、更接近主线默认 |
| 产品定位 | 主线推理与 agentic 工作模型 | 编程特化模型 | GPT-5.4 更广,Codex 更窄 |
| 输入价格 | $2.50 / 1M | $1.75 / 1M | GPT-5.3-Codex 更省输入成本 |
| 输出价格 | $15 / 1M | $14 / 1M | 输出价差不大 |
| Cached input | $0.25 / 1M | $0.175 / 1M | 重复上下文场景里 Codex 仍更便宜 |
| 上下文窗口 | 1,050,000 | 400,000 | GPT-5.4 更适合大仓库与长会话 |
| 最大输出 | 128,000 | 128,000 | 基本打平 |
| 工具能力 | 更广,含 computer use 等 | 更偏编程环境 | GPT-5.4 更适合混合型任务 |
| 仍然最强的点 | 更全面 | Terminal-Bench 2.0 | GPT-5.4 赢整体,Codex 赢终端窄项 |
| 更适合谁 | 大多数开发团队默认值 | 终端优先、成本更敏感的路由 | 最优做法通常是两个都留着 |
这组对比真正重要的地方,不是“哪个更新”,而是 GPT-5.4 已经接管默认地位,但 GPT-5.3-Codex 仍然保留了明确的例外价值。
GPT-5.4 相比 GPT-5.3-Codex 到底变了什么

这组对比里最容易被讲错的地方,是很多文章只会说“GPT-5.4 更强了”,却不解释强在哪里,以及为什么 Codex 这个型号还没有被彻底淘汰。
根据 OpenAI 的 GPT-5.4 发布页,GPT-5.4 是第一个吸收 GPT-5.3-Codex 前沿编程能力的主线推理模型。这个说法很关键,因为它意味着 OpenAI 并不是把“编程”放回一个普通模型里,而是把 GPT-5.3-Codex 的核心优势并入了更大的主线能力栈里。对于开发者来说,这种变化比单纯的基准提升更重要。
而 GPT-5.3-Codex 的发布页 所强调的是另一套价值:速度、agentic coding、终端环境中的实际执行,以及“更像开发者工具而不是通用模型”的使用感。这就是为什么很多开发者在 GPT-5.4 发布之后仍然愿意保留 GPT-5.3-Codex。它的价值不在于“更新”,而在于“更专”。
当前的 OpenAI 模型总览文档 也给出了很清晰的产品信号:如果你要做复杂推理、编程、agentic 工作,官方已经把 GPT-5.4 放到更靠前的位置;而 GPT-5.3-Codex 则更像是仍然保留给 Codex 风格环境的专业化选项。
OpenAI 在 2026 年 3 月 5 日 的 GPT-5.4 发布页里,还补充了一个很多对比文章没有讲清楚的点:GPT-5.4 Thinking 当天开始向 ChatGPT Plus、Team、Pro 推出,GPT-5.4 Pro 面向 Pro 和 Enterprise,而 Codex 里的 GPT-5.4 提供的是 实验性 1M 上下文支持。同一页也明确写到,在 Codex 里超出标准 272K 上下文 的请求会按 2 倍使用率 计入。这恰好解释了为什么“默认推荐已经改变”与“不同表层体验仍然不完全一致”会同时成立。
所以最准确的理解方式是:GPT-5.4 取代了 GPT-5.3-Codex 的“默认推荐地位”,但没有完全取代它的“专业化存在意义”。
还要注意一个常见误区:很多讨论把 ChatGPT 模型选择器、Codex 产品界面 和 API 模型目录 混成一回事。其实这三个面向用户的表层并不总是同步更新,也不一定会同时出故障。因此,做决策时应该以官方发布页和当前模型文档为准,把 Reddit 或 GitHub 上的故障讨论当成“运营噪音”,而不是产品方向本身。
哪些基准差异对真实编程工作最重要
很多对比文章喜欢把所有数字堆在一起,但对真实开发者来说,真正重要的是这些数字分别映射到什么工作流。
| 基准 | GPT-5.4 | GPT-5.3-Codex | 对实际工作的意义 |
|---|---|---|---|
| GDPval | 83.0% | 70.9% | GPT-5.4 在复杂指令、混合任务上更稳 |
| SWE-Bench Pro | 57.7% | 56.8% | GPT-5.4 在高难软件工程任务上略强 |
| OSWorld-Verified | 75.0% | 74.0% | GPT-5.4 在系统操作型任务上更全面 |
| Toolathlon | 54.6% | 51.9% | GPT-5.4 的工具工作流能力更强 |
| BrowseComp | 82.7% | 77.3% | GPT-5.4 更适合检索、证据整合与浏览 |
| Terminal-Bench 2.0 | 75.1% | 77.3% | GPT-5.3-Codex 仍是终端优先场景里的更强路线 |
这张表说明的不是“GPT-5.4 全面碾压”,而是 GPT-5.4 在大多数维度上更适合作为默认值。如果你的工作经常涉及大型代码仓库、复杂上下文、多工具调用、资料检索、补丁修改,那么 GPT-5.4 的优势会直接转化成更少的模型切换、更少的工作流断裂,以及更稳定的整体体验。
但 GPT-5.3-Codex 仍然保留了一个不能忽视的优势点:Terminal-Bench 2.0。这个基准比很多人想象中更重要,因为它和真实的 CLI 工作非常接近。对于经常做 shell 脚本、文件操作、构建流水线、部署修复、日志排障的人来说,这一项比通用推理分数更接近“体感差异”。
也正因为如此,真正合理的判断不是“只看谁分高”,而是:
- 如果你的工作主要是终端优先的工程操作,GPT-5.3-Codex 仍然有现实理由保留;
- 如果你的工作更像混合型开发任务,GPT-5.4 更适合做统一默认模型。
如果你还想看 GPT-5.3-Codex 在其他旗舰编程模型前的定位,可以参考我们已经写好的 GPT-5.3 Codex 与 Claude Opus 4.6 对比。
价格、上下文窗口与工具覆盖:真正的取舍点

一旦你不再只盯着 benchmark,真正决定默认值的往往是三件事:价格、上下文、工具面。
| 项目 | GPT-5.4 | GPT-5.3-Codex | 应该怎么理解 |
|---|---|---|---|
| 输入价格 | $2.50 / 1M | $1.75 / 1M | Codex 更便宜,尤其适合 prompt 很重的场景 |
| Cached input | $0.25 / 1M | $0.175 / 1M | 重复上下文工作流里 Codex 更省 |
| 输出价格 | $15 / 1M | $14 / 1M | 输出价差不构成主要决策因素 |
| 上下文窗口 | 1,050,000 | 400,000 | GPT-5.4 对大仓库、长会话优势非常明显 |
| 长上下文说明 | 超过 272K prompt,整场按 2x input 与 1.5x output 计费 | 无同类公开说明 | GPT-5.4 的大窗口是真升级,但高位成本也是真成本 |
| 工具能力 | web search、hosted shell、apply patch、MCP、computer use 等 | 更偏 Codex 风格编程定位 | GPT-5.4 更适合作为统一工作模型 |
很多人一看到 1.05M 上下文窗口,就会得出“GPT-5.4 当然更值”的结论;也有人一看到输入价格,就直接觉得“Codex 更划算”。其实两个判断都过于简单。
GPT-5.4 的上下文提升确实很大。对于代码仓库理解、架构梳理、跨模块追踪、长时间 agentic 工作,这个提升是能被体感到的。你可以更少地拆 prompt,更少地人工切分上下文,也更容易让模型维持同一个任务视角。
但另一方面,OpenAI 当前文档也清楚说明:当 prompt 超过 272K input tokens 时,GPT-5.4 会按更高倍率计费。这意味着它适合作为“有需要时能上大窗口”的默认模型,而不意味着你应该把所有大 prompt 无脑塞进去。
工具面则是决定默认模型最容易被忽视的一环。GPT-5.4 之所以更适合作为默认选择,不只是因为它会写代码,而是因为它更适合承担编程以外的附带动作:查资料、调用工具、打补丁、管理长上下文、处理系统级任务。只要你的工作不是纯代码生成,而是“代码 + 其他动作”的复合型开发流,GPT-5.4 的默认地位就更稳。
如果你还在梳理 OpenAI API 的整体账号和费用逻辑,可以结合阅读这篇 OpenAI API Key 与替代方案对比 来看更完整的成本与接入路径。
不同工作流到底该选哪个模型
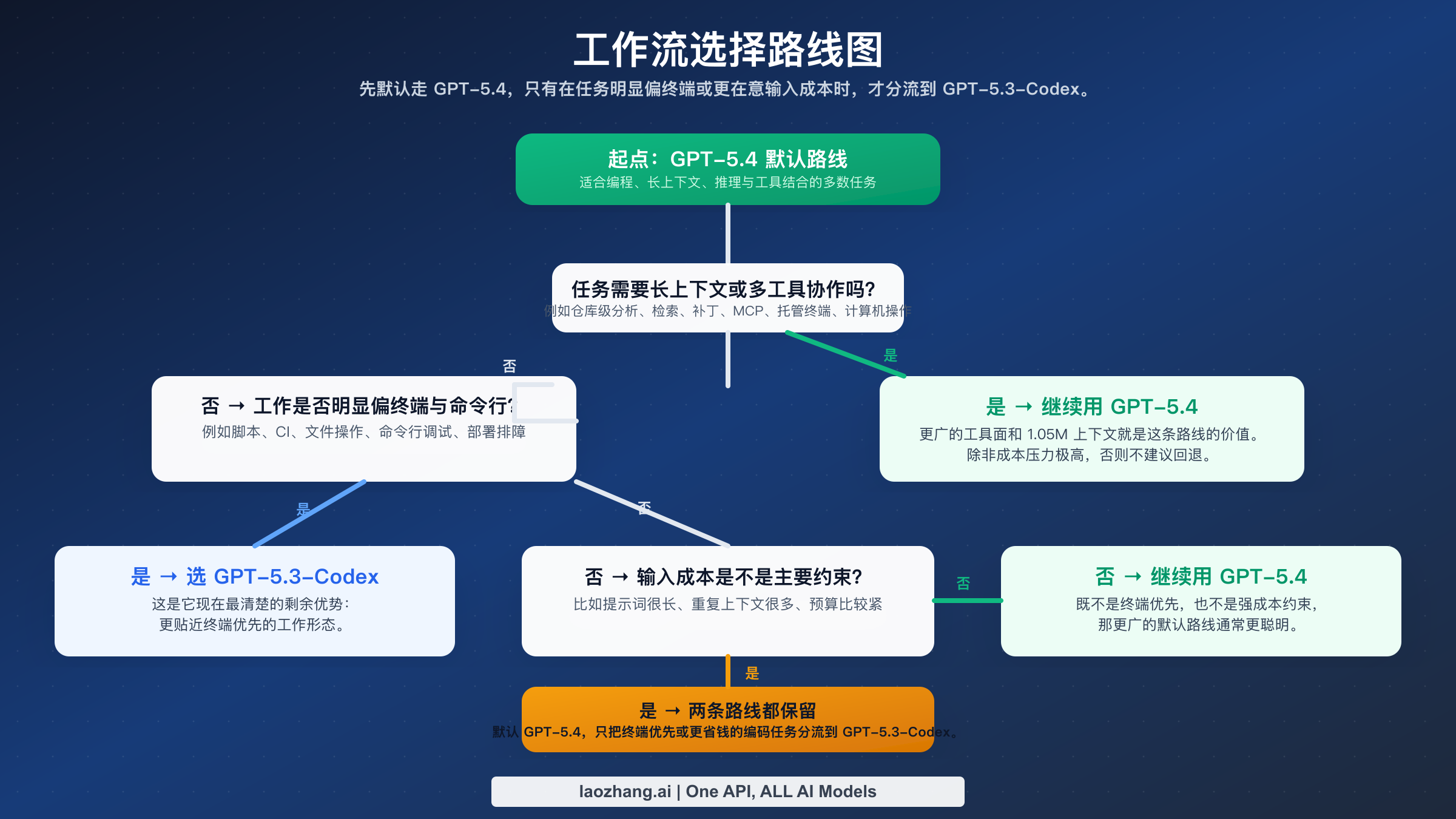
这一节才是真正应该放在大多数对比文章前面的内容,因为它直接回答“我该选哪个”。
| 工作流 | 更推荐 GPT-5.4 | 更推荐 GPT-5.3-Codex | 解释 |
|---|---|---|---|
| 团队默认编程模型 | 是 | 否 | GPT-5.4 更适合作为统一默认值 |
| 终端优先、CLI 密集型任务 | 视情况 | 是 | Codex 在这个窄场景里仍更强 |
| 大仓库、长上下文分析 | 是 | 很少 | GPT-5.4 的大窗口优势明显 |
| 多工具 agentic 工作 | 是 | 很少 | GPT-5.4 的工具面更完整 |
| 极度在意输入成本的编程场景 | 视情况 | 是 | Codex 更适合成本敏感路由 |
| 混合型专业工作(代码 + 推理 + 检索) | 是 | 否 | GPT-5.4 更适合作为工作主力 |
如果你是普通开发者或小团队,最简单的做法是:默认先上 GPT-5.4。它减少了你在模型之间来回切换的必要,也更符合 OpenAI 当前的产品方向。
如果你是平台工程、运维、基础设施或终端工作特别多的工程师,答案就没那么绝对。只要你的日常工作确实大量发生在 shell、部署脚本、CI、日志、命令行调试里,那么 GPT-5.3-Codex 仍然可能给你更好的速度感和性价比。
如果你是Staff/Tech Lead/架构型角色,GPT-5.4 更值得作为主力,因为你的任务通常不只是“把代码写出来”,而是“理解、推理、决策、协调多个上下文”。这恰好是 GPT-5.4 更占优的区域。
如果你的系统本来就支持模型路由,那么最优做法通常不是二选一,而是两个都保留:GPT-5.4 做默认路由,GPT-5.3-Codex 做终端优先或更便宜的专用路由。
GPT-5.3-Codex 还在哪些场景值得保留
很多人一看到 GPT-5.4 已经“吸收”了 GPT-5.3-Codex 的能力,就会自然得出“那 Codex 这个型号没用了”的结论。但对真实工程环境来说,这个结论太粗糙。
GPT-5.3-Codex 至少还在四种场景里值得保留。第一,终端优先任务。只要你的工作重心明显偏 CLI,它仍然有现实理由存在。第二,输入成本更敏感的系统。如果你的请求量大、prompt 重、缓存多,那么更低输入价就是实际优势。第三,更窄、更专的编程工作流。如果你根本不需要 GPT-5.4 那些更广的工具能力,那么用 Codex 作为专用路线可能更高效。第四,做故障兜底。保留第二条强编程路线,本身就是系统韧性的一部分。
社区里 2026 年 3 月关于 GPT-5.4 与 GPT-5.3-Codex 的访问故障讨论,说明的是“表层体验可能仍然不稳定”,并不等同于“官方产品方向已经反转”。因此比较稳妥的策略是:把 GPT-5.4 设成主路线,把 GPT-5.3-Codex 设成例外路线。
从 GPT-5.3-Codex 迁移到 GPT-5.4 的实用清单
如果你的团队已经把 GPT-5.3-Codex 当成默认值,迁移时最好的做法不是一下子全部切掉,而是有节奏地迁。
- 把 GPT-5.4 设为新的默认模型,优先承接长上下文、复杂推理和多工具型任务。
- 保留 GPT-5.3-Codex 作为终端优先与低输入成本场景的备选路由。
- 对长 prompt 加上成本监控,尤其是超过 272K input tokens 的 GPT-5.4 会话。
- 重新测试三类高价值任务:长仓库分析、终端工作流、多工具任务,而不是只看 benchmark。
- 为表层访问故障准备 fallback 规则,避免把“临时故障”误判为“模型选型问题”。
如果你的团队里还有人主要在 ChatGPT 层面理解 GPT-5 访问方式,而不是 API 或 Codex 层面,可以顺手看这篇 ChatGPT Plus 与免费版 GPT-5 速度和配额差异。
FAQ
GPT-5.4 是不是已经全面强于 GPT-5.3-Codex?
不是。更准确地说,GPT-5.4 在整体上更适合做默认值,但 GPT-5.3-Codex 依然在 Terminal-Bench 2.0 上领先,而且输入价格更低。所以如果你做的是终端优先或成本敏感的编程工作,GPT-5.3-Codex 仍然有保留价值。
GPT-5.4 更贵,这个升级值不值?
多数情况下值得,前提是你真的会用到它的更大上下文和更广工具面。如果你的任务只是短编码、快修复、CLI 工作,那价差未必值得;但如果你的任务会扩展成长会话、多工具、跨文件理解,那么 GPT-5.4 的额外成本通常是合理的。
GPT-5.4 是否已经实质上取代了 GPT-5.3-Codex?
从 OpenAI 的产品定位来看,是的,GPT-5.4 已经接过了默认推荐的位置;但从工作流选择来看,不是。GPT-5.3-Codex 仍然适合被保留为一条窄而专业的路线。
最近社区里关于 Codex 故障或访问异常的讨论,会不会影响结论? 需要关注,但不应该过度放大。这类帖子说明当前表层体验可能仍有波动,却不足以推翻官方发布页和当前模型文档所表达的长期方向。真正决定你是否迁移的,仍然应该是官方事实和你的实际工作流。