
GPT-5.4 nano 通常才是新的低成本 OpenAI API 工作负载的更优默认值。 只有当你最在意的是把 token 成本压到最低,而不是更近的知识截止、更强的推理和更广的工具支持时,才继续选 GPT-5 nano。
真正要看的差别其实很简单:两者都有 400,000 上下文窗口和 128,000 最大输出,所以这不是上下文大小之争,而是你要不要为了最低单价,接受一条更旧的便宜路线。
要点速览
| 模型 | 更适合的场景 | 主要选择理由 | 主要不选理由 |
|---|---|---|---|
| GPT-5 nano | 极度成本敏感的 summarization、轻量 classification,以及“先把最便宜链路跑起来”的任务 | 输入、缓存输入、输出价格都明显更低 | 知识截止更旧,cheap-agent 工具面更薄 |
| GPT-5.4 nano | 新的 extraction、ranking、helper-agent 以及更现代的低成本工作流 | OpenAI 已把大多数新的低成本工作负载默认指向它,而且它更“新”也更“全” | token 价格大约是 GPT-5 nano 的 4 倍 |
如果你只想记一句话:当产品目标是“把账单压到最低”时留在 GPT-5 nano;当产品目标是“做一条现在还能长期用的低成本路线”时,先测 GPT-5.4 nano。
这组比较的真正含义,是“最便宜”对比“当前默认值”
这个关键词最容易误导人的地方,在于两个名字都叫 “nano”。很多人第一反应会是:二者大概只是小版本差异,主要区别应该只在价格。
但 OpenAI 当前文档给出的信号并不是这样。GPT-5 nano 依旧在线、依旧有价格、依旧有明确用途。它不是下线模型,也不是纯历史遗留项。它仍然适合非常简单、非常大量、而且对成本极度敏感的文本任务。问题在于,它已经不再像过去那样是“新的低成本默认路线”。
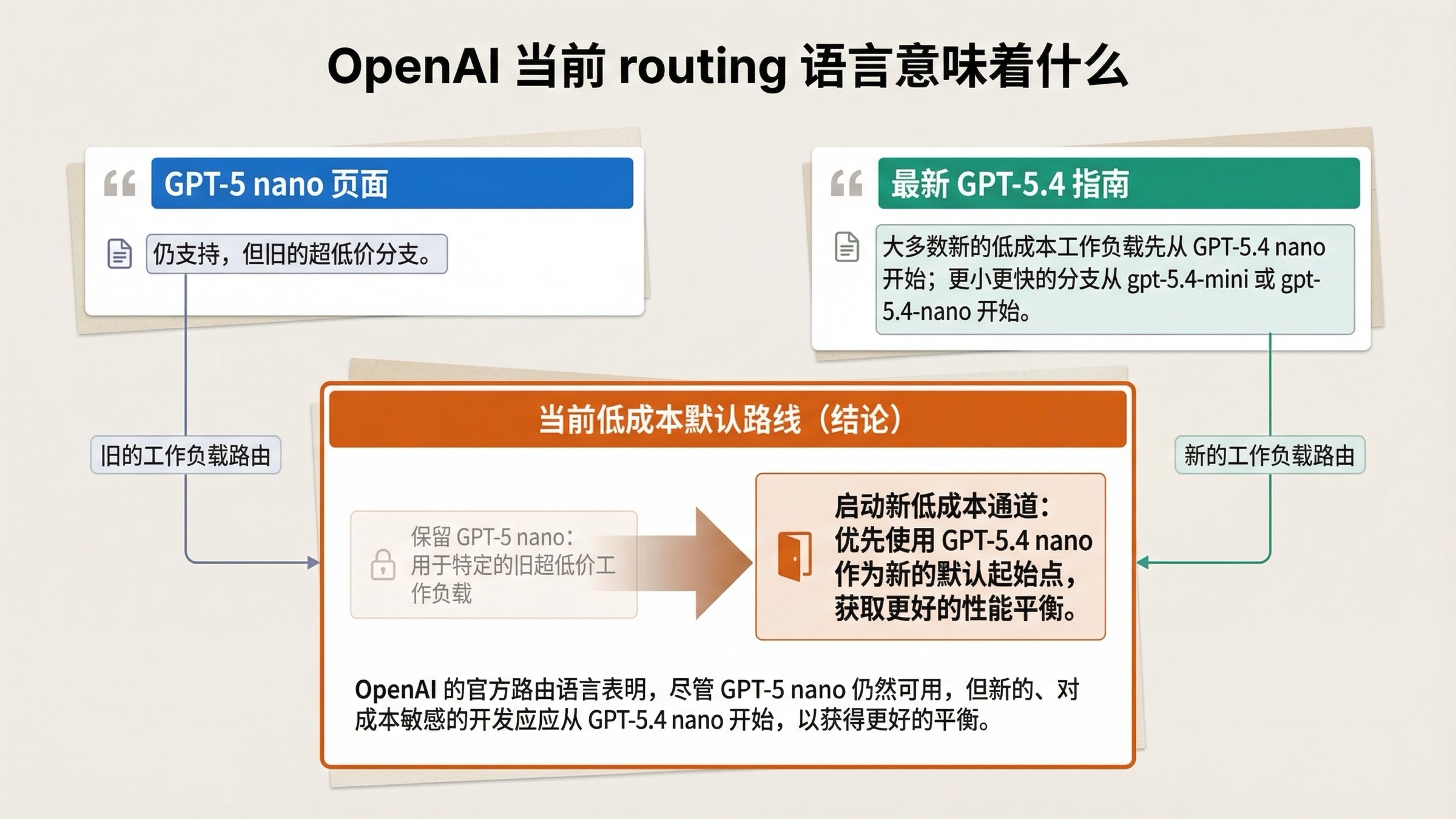
最关键的一句,其实就在 GPT-5 nano 自己的模型页里:对于大多数新的 speed- and cost-sensitive workloads,建议先从 GPT-5.4 nano 开始。 这句话几乎直接改写了这组比较的阅读方式。它说明 GPT-5 nano 仍有位置,但那个位置已经更窄;GPT-5.4 nano 则被 OpenAI 放到了“新的低成本默认起点”上。
最新 GPT-5.4 指南 也强化了同样的路线判断。它写得更直接:如果你需要更小、更快的变体,应从 gpt-5.4-mini 或 gpt-5.4-nano 开始。也就是说,GPT-5.4 系列现在才是官方在推的新分支,而 GPT-5 nano 更像一条还保留着的超低价老分支。
所以这篇文章真正要回答的,不是“哪个名字更高级”。真正的问题是:你要的是绝对最低 token 成本,还是一条更符合 2026 年 OpenAI 当前产品方向的低成本链路?
价格、知识新鲜度、工具支持与速率限制并排看
先看最直观也最容易影响决策的价格。
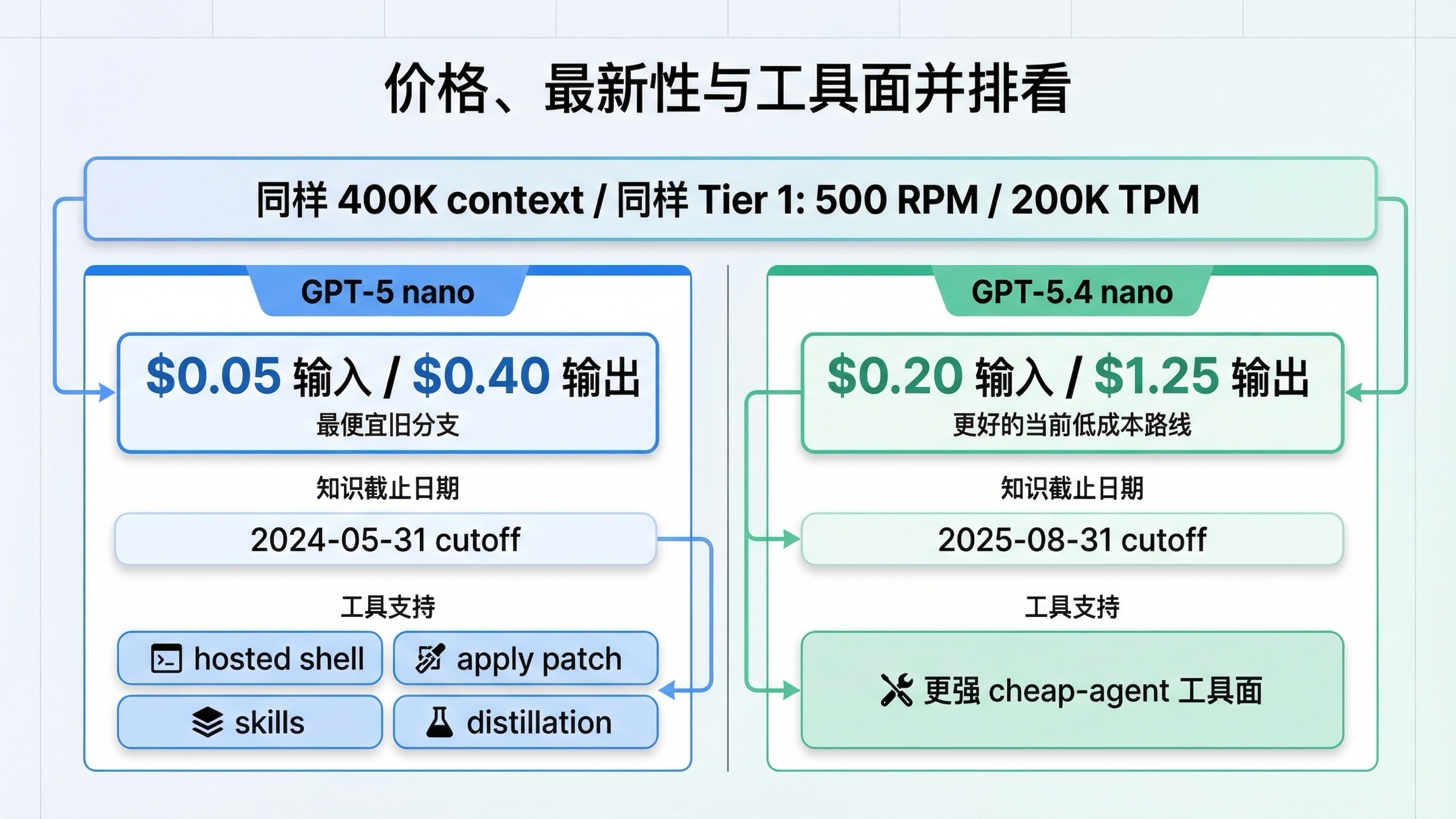
按当前官方模型页,GPT-5 nano 的价格是 输入每 1M tokens $0.05、缓存输入 $0.005、输出每 1M tokens $0.40。GPT-5.4 nano 则是 输入 $0.20、缓存输入 $0.02、输出 $1.25。如果你的低成本链路是大批量短请求,或者系统结构天然就是靠“便宜模型先筛一遍”来控制成本,那么这组差价绝对不是纸面数字,而是会直接体现在账单上的现实差异。
但 GPT-5 nano 节省下来的成本,并不是在“同样新、同样全、只是更便宜”的前提下得到的。两者虽然拥有相同的 context 和相同的当前速率限制,但知识截止差距很大。GPT-5 nano 的官方 cutoff 是 2024-05-31,GPT-5.4 nano 则是 2025-08-31。对会接触新库、新文档、2025 年后产品变化的低成本链路来说,这个差距非常真实。
再看工具面。当前 GPT-5.4 nano 模型页列出了 hosted shell、apply patch、skills、distillation、MCP、image generation 等能力;GPT-5 nano 虽然也支持 MCP 和 image generation,但没有 hosted shell、apply patch、skills 和 distillation。若你的便宜分支只是做文本摘要,这些差距也许不重要。可一旦这条分支开始承担 extraction、ranking、helper-agent 或轻量工具调用,差别就会马上放大。
| 规格 | GPT-5.4 nano | GPT-5 nano |
|---|---|---|
| 输入价格 | $0.20 / 1M tokens | $0.05 / 1M tokens |
| 缓存输入 | $0.02 / 1M tokens | $0.005 / 1M tokens |
| 输出价格 | $1.25 / 1M tokens | $0.40 / 1M tokens |
| Context window | 400,000 | 400,000 |
| Max output | 128,000 | 128,000 |
| Knowledge cutoff | 2025-08-31 | 2024-05-31 |
| 模型页推理定位 | High | Average |
| 当前 snapshot | gpt-5.4-nano-2026-03-17 | gpt-5-nano-2025-08-07 |
| Hosted shell | Yes | No |
| Apply patch | Yes | No |
| Skills | Yes | No |
| Distillation | Yes | No |
| MCP | Yes | Yes |
| Image generation | Yes | Yes |
| Tier 1 限额 | 500 RPM / 200,000 TPM | 500 RPM / 200,000 TPM |
| Tier 5 限额 | 30,000 RPM / 180,000,000 TPM | 30,000 RPM / 180,000,000 TPM |
这张表里最值得你注意的,不是最上面的价格行,而是最下面的速率限制行。因为它告诉你:这不是“便宜但吞吐差”对比“贵但吞吐强”的经典取舍。 当前官方页面写得很清楚,这两条线在 context 和当前 rate limits 上并没有拉开差距。真正拉开差距的是新鲜度、推理定位和工具能力。
OpenAI 当前的 routing 语言,到底意味着什么
OpenAI 并没有发布一张完美的官方 head-to-head benchmark 表,把 GPT-5.4 nano 和 GPT-5 nano 在所有维度上逐行直接对打。对这件事,文章必须诚实。GPT-5.4 nano 更适合大多数新项目的最强依据,不是“某张我自己拼出来的基准结论”,而是 OpenAI 自己在当前文档里的 routing 语言,再加上两张模型页上的事实差异。
最重要的一句已经提过一次,但值得再说一次:GPT-5 nano 页面自己写着,大多数新的 speed- and cost-sensitive workloads 应先从 GPT-5.4 nano 开始。如果 OpenAI 仍把 GPT-5 nano 当成新项目的默认低成本起点,这句话根本不会出现。
最新 GPT-5.4 指南则从另一边补上了同样的结论。它把小而快的分支默认指向 gpt-5.4-mini 和 gpt-5.4-nano。这并不等于 GPT-5 nano 已失效,而是说明 GPT-5 nano 不再是官方优先推动的新 cheap lane。
2026 年 3 月 17 日的 GPT-5.4 mini and nano 发布文 也很关键。它把 GPT-5.4 nano 定位成 classification、data extraction、ranking、simpler subagents 的当前低成本工具。这种表述传递的是“它可以承担真实工作流”,而不是“它只是一个便宜占位模型”。
与之对应,2025 年 8 月的 GPT-5 for developers 发布文 则告诉你 GPT-5 nano 为什么仍然重要:它原本就是为最低成本而存在的 nano 分支。今天它依然保留这个角色,只是这个角色已经更偏向“极致低价旧分支”,而不是“新项目默认起点”。
什么时候 GPT-5 nano 仍然更合适
如果你的低成本链路目标极其明确,就是“把单位请求成本压到最低”,那 GPT-5 nano 依然可能是更对的选择。
最典型的场景,是高量级 summarization、轻量 classification,或者那些 prompt 非常稳定、失败代价也不高的文本型任务。在这些情况下,GPT-5 nano 输入价是 GPT-5.4 nano 的四分之一,输出价也明显更低。只要任务复杂度本来就不高,你完全可能宁愿保住更低账单,而不是为更高的新鲜度与更宽工具面多付钱。
第二类场景,是“便宜链路只负责粗筛”的系统架构。比如先用最低价模型做预处理、归类、简单总结,再把难题升级给更强模型。此时如果这条最前面的链路并不需要 agent 能力,也不依赖更新的世界知识,GPT-5 nano 依旧有存在价值。
第三类场景,是存量系统的工程现实。团队往往不是从零开始设计,而是在现有 prompt、监控、成本和行为边界的基础上演进。若 GPT-5 nano 已经跑得稳定,而且业务也接受这条便宜链路的输出质量,那么继续保留它是合理的。只是这必须是“已经测过所以保留”,而不是“名字熟所以保留”。
更适合继续留在 GPT-5 nano 的情况,大致是这些:
- 任务主要是 summarization、light classification 或其他非常明确的文本任务。
- 绝对最低 token 成本比更新 cutoff 和更强工具面更重要。
- 这条链路不需要 hosted shell、apply patch、skills 或 distillation。
- 你已经掌握它的提示词行为和失败模式,迁移收益暂时不够大。
这仍然是一批真实需求,只是它们更接近“超低价旧链路”,而不是“新项目默认路线”。
什么时候该为 GPT-5.4 nano 多付这笔钱
当你的低成本链路虽然仍然要便宜,但已经不能只看“最便宜”,而要看“现在能不能好用”时,GPT-5.4 nano 通常更值得。
第一类强场景,是 extraction、ranking、helper-agent 之类结构化任务。OpenAI 明确把 GPT-5.4 nano 定位到这些使用场景,这说明它不是为了省钱而牺牲太多能力的模型,而是一条能承担真实低成本工作流的当前分支。
第二类强场景,是 cheap lane 需要更好的工具面。hosted shell、apply patch、skills、distillation 这些能力,对纯文本摘要链路来说可能无关紧要;但对轻量 agent、自动化辅助流程、代码相关辅助任务来说,它们会直接改变一条便宜分支“能不能接进去”。
第三类,是对知识新鲜度敏感的低成本任务。2024-05-31 和 2025-08-31 之间不是小差异。任何会碰到近一年 API 变化、库更新、产品规则调整的低成本链路,都更容易从 GPT-5.4 nano 的 cutoff 里受益。
第四类,是新架构本身。如果你是今天开始做新的 cheap lane,而不是在维护已有系统,那么最稳的默认动作通常就是先顺着 OpenAI 当前路线走:把 GPT-5.4 nano 当默认起点,再看是否有足够强的成本理由退回 GPT-5 nano。
更适合先测 GPT-5.4 nano 的情况,大致是这些:
- 你在设计新的低成本链路,而不是维护旧链路。
- 任务包含 extraction、ranking、subagents 或其他结构化 helper work。
- 更新的 cutoff 能直接降低产品风险。
- 这条分支会因为 hosted shell、apply patch、skills 或 distillation 受益。
- 你想让低成本路线符合 OpenAI 当前产品方向,而不是继续停在旧 nano 分支。
如果你的“便宜分支”已经重到这里都不够用了,那真正该比较的对象往往就不是 GPT-5.4 nano 对 GPT-5 nano,而是 GPT-5.4 mini 对比 GPT-5.4 nano。
你的系统到底该怎么选
真正实用的判断方法,其实可以先回到一个非常简单的问题:这条链路的第一目标,到底是最低账单,还是更好的当前低成本能力?
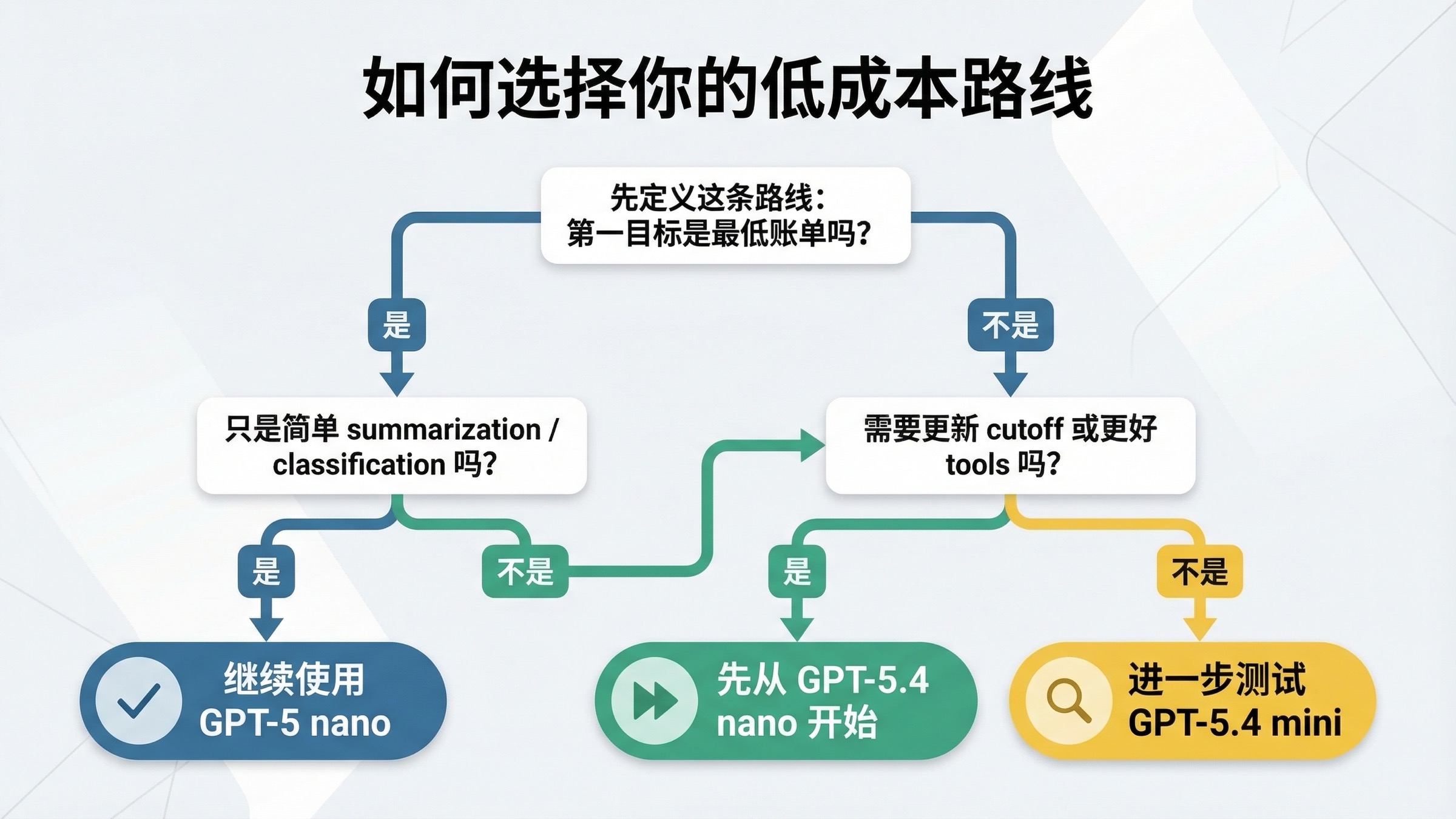
如果答案是最低账单,那就从 GPT-5 nano 开始,只有在错误率或效果损失变得昂贵时,再往上测。
如果答案是更好的当前低成本能力,那就从 GPT-5.4 nano 开始,只有在价格压力真的压过效果收益时,再往回退。
我更建议按下面这个顺序决策:
- 当链路是简单文本任务且成本极度敏感时,优先留在 GPT-5 nano。
- 当链路仍然要便宜,但已经需要更新知识和更好的工具时,优先从 GPT-5.4 nano 开始。
- 如果 GPT-5.4 nano 仍显得不够,就不要再纠结 GPT-5 nano,而该直接去看 GPT-5.4 mini 对比 GPT-5.4 nano。
如果你还在准备 API 接入环境,当前没有这篇内容的中文同文,可先补充英文版的 OpenAI API key guide。如果你真正纠结的是“新的 nano 分支”和“旧的 mini 分支”谁更合理,那么下一篇更应该看 GPT-5.4 nano 对比 GPT-5 mini。
FAQ
GPT-5 nano 已经被弃用了吗?
没有。至少在 2026 年 3 月 21 日复核时,它仍然有当前模型页、当前价格和当前限额。问题不在于它是否还在,而在于它已经不再是 OpenAI 推荐给大多数新低成本工作负载的默认起点。
GPT-5.4 nano 贵 4 倍,就一定值 4 倍吗?
不能这样理解。OpenAI 没有给出一张直接证明“贵 4 倍就强 4 倍”的 head-to-head 表。更准确的说法是:GPT-5.4 nano 用更高价格换来更近的知识截止、更高的推理定位,以及更完整的 cheap-agent 工具面,而且并没有在 context 和当前 rate limits 上让你吃亏。
继续保留 GPT-5 nano 最强的理由是什么?
最强理由仍然是价格。如果你的任务非常简单、量非常大,而且系统结构天然偏向“先用最便宜模型处理一层”,那么 GPT-5 nano 的低价优势就是最现实的工程理由。
什么时候最该转向 GPT-5.4 nano?
当你需要一条更符合 2026 年 OpenAI 当前产品方向的低成本路线时。特别是当你的便宜分支已经开始接结构化任务、更新知识需求、或轻量工具工作流时,GPT-5.4 nano 通常更值得先测。
最短结论就是:GPT-5 nano 仍然赢在“最便宜”,而 GPT-5.4 nano 更常赢在“现在更该先用”。