
如果你的产品需要更强的编码、computer use 或更重的 agent 行为,就选 GPT-5.4 mini;如果便宜的高吞吐工作比工作流深度更重要,就选 GPT-5.4 nano。
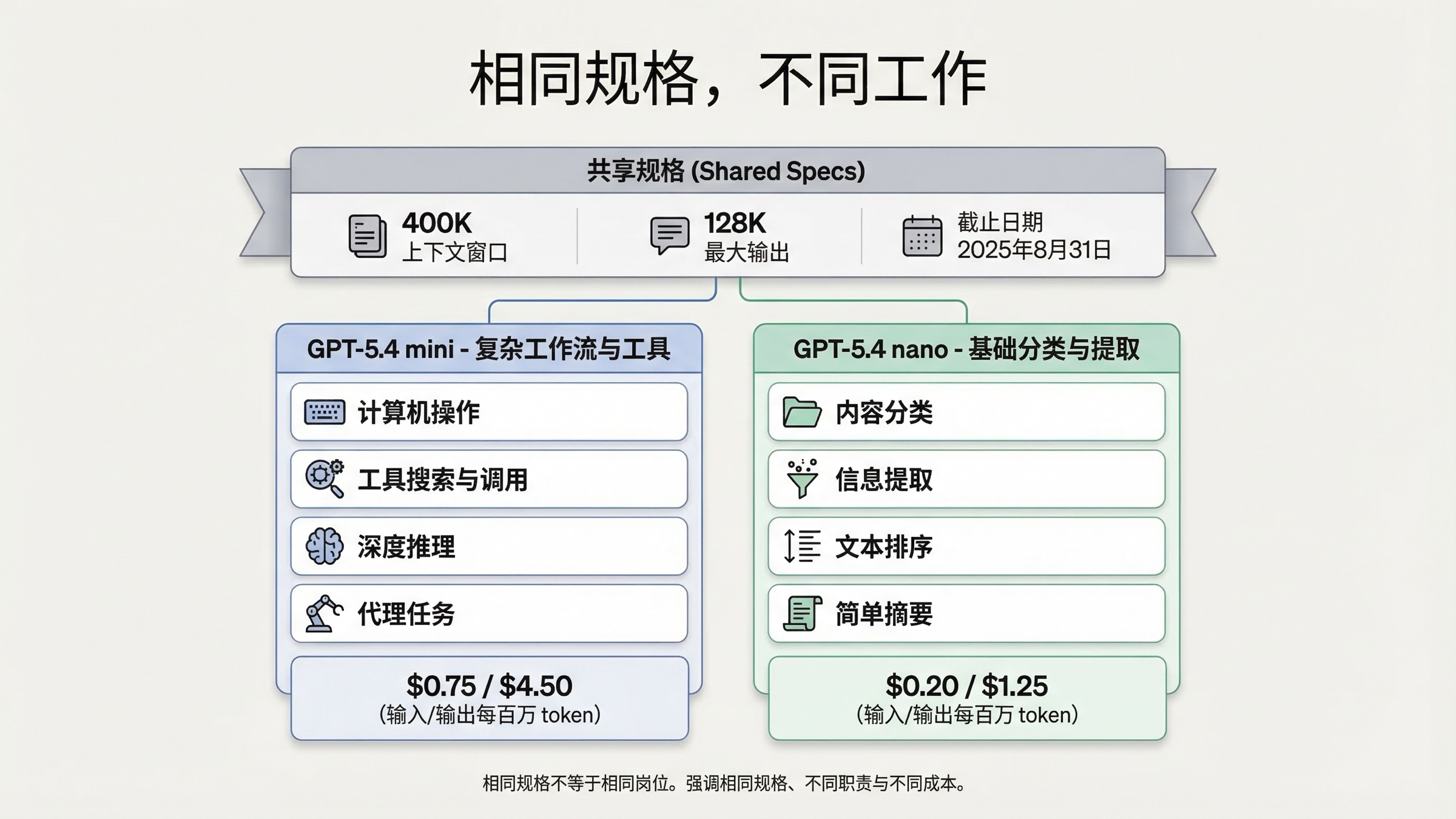
两者都有 400,000 上下文窗口和 128,000 最大输出,所以真正的取舍不是上下文大小,而是 mini 更强的工具面与 benchmark 画像,是否值得你在真实工作流里为它多付钱。
要点速览
如果你只想先拿结论,可以直接用下面这张表:
| 模型 | 最适合的场景 | 主要选择理由 | 主要不选理由 |
|---|---|---|---|
| GPT-5.4 mini | 编码助手、截图密集流程、浏览器/桌面自动化、更重的子代理 | coding、tool use 与 computer use 更强,且支持 computer use 和 tool search | 更贵:每 1M tokens 输入 $0.75 / 输出 $4.50 |
| GPT-5.4 nano | classification、extraction、ranking、廉价 routing、简单子代理 | 更便宜:每 1M tokens 输入 $0.20 / 输出 $1.25,而且与 mini 共享相同上下文和 cutoff | 不支持 computer use 和 tool search,在更重的工具工作流上明显更弱 |
最简单的判断规则:
- 如果模型要读代码、从 tool failure 恢复、操作界面,或作为较强 worker 跑在 agent 系统里,优先 GPT-5.4 mini。
- 如果模型主要做分类、抽取、排序、路由或低成本支持任务,优先 GPT-5.4 nano。
- 如果你在搭建混合系统,最优答案通常不是“二选一”,而是“mini 负责重负载,nano 负责廉价分支”。
- 如果你是根据 ChatGPT 里的显示名称选型,先把 ChatGPT 可见性和 API 选型拆开看。
真正的分界线不是上下文,而是工作流深度
很多比较页会把价格、上下文和 cutoff 放在最前面,因为这些字段最容易整理。但对这个关键词来说,真正有价值的判断恰恰不在那里。
按照当前 OpenAI 官方模型页,GPT-5.4 mini 和 GPT-5.4 nano 都拥有:
- 400K context window
- 128K max output
- 2025-08-31 knowledge cutoff
- text 与 image input 支持
这意味着,决策并不在于“哪个上下文更大”或“哪个更新”。两者在纸面规格上几乎打平。
真正的差异,在于它们要在生产系统里做什么。
OpenAI 的 GPT-5.4 指南 把 GPT-5.4 mini 描述为适合高体量 coding、computer use 与仍然需要强 reasoning 的 agent workflows;同一指南把 GPT-5.4 nano 描述为适合 speed 与 cost 最重要的 simple high-throughput tasks。这个框架比“一个更强、一个更便宜”更贴近真实使用。
因此最有用的心智模型是下面这张表:
| 问题 | 如果答案是是 | 更适合的模型 |
|---|---|---|
| 模型是否需要做真正的 coding 或 codebase 级工作? | 你在意更强编码基准与 agent 可靠性 | GPT-5.4 mini |
| 模型是否需要 built-in computer use 或基于 UI 的任务执行? | 你需要截图驱动或界面驱动的操作 | GPT-5.4 mini |
| 任务是否主要是 extraction、ranking 或 classification,且量很大? | 成本与吞吐优先 | GPT-5.4 nano |
| 你是否在给上层规划模型配简单 supporting worker? | 你想要最便宜但仍可用的小模型 | GPT-5.4 nano |
这也解释了为什么会有这么大的价格差。OpenAI 并不是因为 mini 上下文更大才收费更高,而是因为 mini 被定位成更强的 tool-and-agent worker。
价格、速率限制与工具支持并排看
在看 benchmark 之前,先把价格差摊开。
根据当前官方 GPT-5.4 mini 模型页 和 GPT-5.4 nano 模型页,两者截至 2026 年 3 月 20 日的关键参数如下:
| 参数 | GPT-5.4 mini | GPT-5.4 nano |
|---|---|---|
| 输入价格 | $0.75 / 1M tokens | $0.20 / 1M tokens |
| 缓存输入 | $0.075 / 1M tokens | $0.02 / 1M tokens |
| 输出价格 | $4.50 / 1M tokens | $1.25 / 1M tokens |
| 上下文窗口 | 400K | 400K |
| 最大输出 | 128K | 128K |
| 知识截止 | 2025-08-31 | 2025-08-31 |
| 页面快照 | gpt-5.4-mini-2026-03-17 | gpt-5.4-nano-2026-03-17 |
也就是说,GPT-5.4 mini 的输入价格约是 nano 的 3.75 倍,缓存输入也约是 3.75 倍,输出约是 3.6 倍。这不是小数点级别差异,而是需要明确纳入架构决策的成本。
速率限制其实比很多人想象得更接近。按 OpenAI 当前的 compare models 页面,主要差异集中在较低付费层,而不是整条产品线都拉开:
| Tier | GPT-5.4 mini TPM | GPT-5.4 nano TPM |
|---|---|---|
| Tier 1 | 500,000 | 200,000 |
| Tier 2 | 2,000,000 | 2,000,000 |
| Tier 3 | 4,000,000 | 4,000,000 |
| Tier 4 | 10,000,000 | 10,000,000 |
| Tier 5 | 180,000,000 | 180,000,000 |
因此,很多生产环境里的关键分歧并不在 TPM,而是在单位成本与任务适配性。
更重要的是工具差异:
| 能力项 | GPT-5.4 mini | GPT-5.4 nano |
|---|---|---|
| Web search | Yes | Yes |
| File search | Yes | Yes |
| Image generation tool | Yes | Yes |
| Code interpreter | Yes | Yes |
| Hosted shell | Yes | Yes |
| Apply patch | Yes | Yes |
| Skills | Yes | Yes |
| Computer use | Yes | No |
| MCP | Yes | Yes |
| Tool search | Yes | No |
这部分往往比价格更值得盯住。
nano 并不是很多人想象中的“阉割版玩具模型”。它依然支持 hosted shell、apply patch、skills 和 image generation,也就是说,它在很多狭窄 agent 任务里仍然是一名可用 worker。
但 mini 保留了两项最能区分“更重的 agent 工作流”和“更简单的廉价工作”的能力:computer use 与 tool search。这两项不是装饰。若模型要靠截图理解界面,或者要在更大工具生态里动态选工具,它们会直接改变可行架构。
所以,严肃的对比不该简化成“更便宜 vs 更强”。真正的问题是:这些额外工作流能力值不值得你付 mini 的成本。
真正影响判断的 benchmark 差距
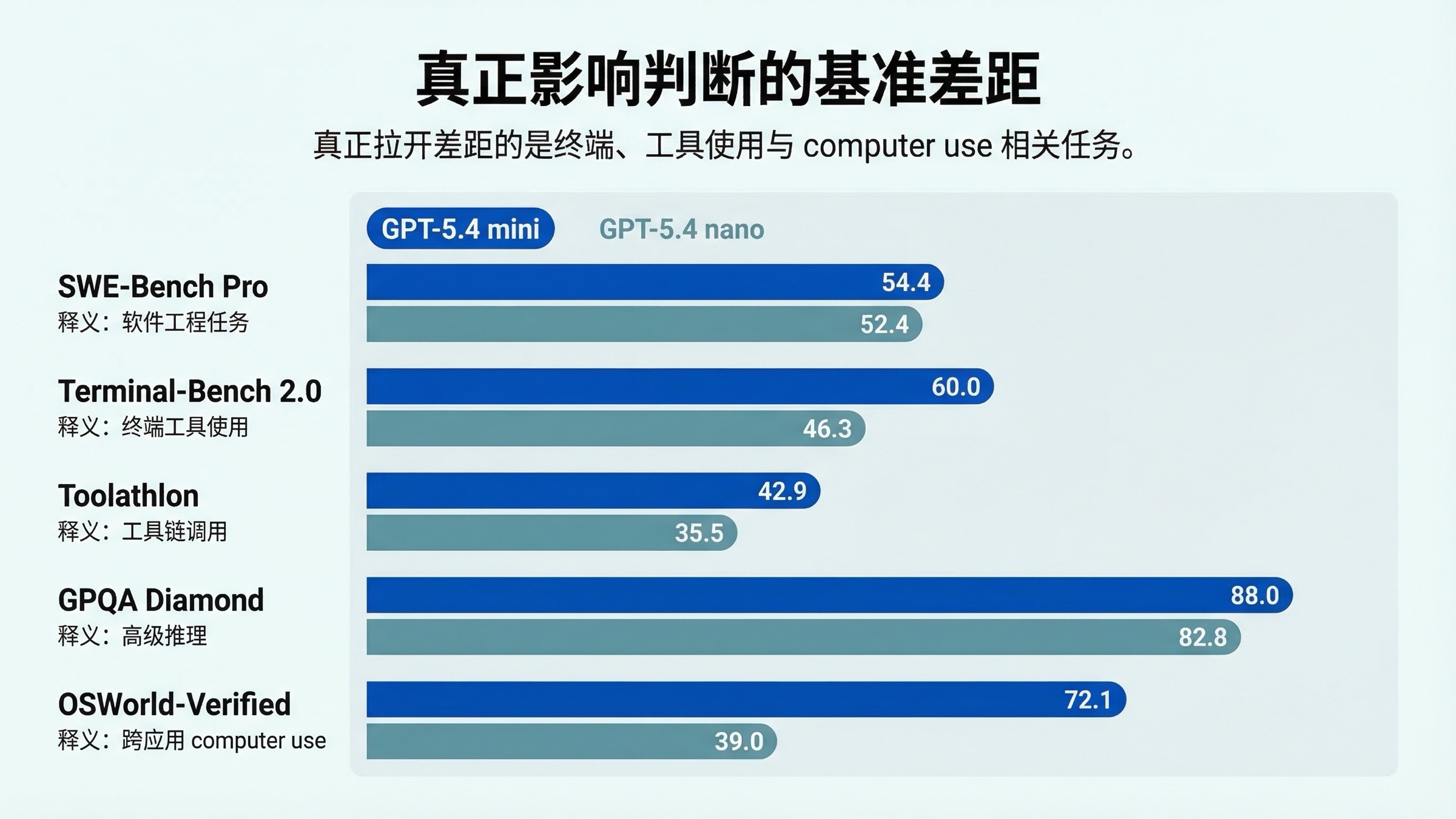
OpenAI 在 2026 年 3 月 17 日的发布文里,给出了最干净的一组 mini vs nano 官方对比:
| 发布文中的 benchmark | GPT-5.4 mini | GPT-5.4 nano | 它真正说明了什么 |
|---|---|---|---|
| SWE-Bench Pro (Public) | 54.4% | 52.4% | mini 在真实软件问题修复上更强,但差距不是悬殊 |
| Terminal-Bench 2.0 | 60.0% | 46.3% | terminal 风格工具工作一旦更复杂,mini 优势明显 |
| Toolathlon | 42.9% | 35.5% | mini 的 tool use 可靠性更高 |
| GPQA Diamond | 88.0% | 82.8% | mini 在更难推理上有更高天花板 |
| OSWorld-Verified | 72.1% | 39.0% | computer-use 型工作流上 mini 是明显更强的一档 |
比表格本身更重要的是三点。
第一,mini 的领先不是每个方向都同样重要。SWE-Bench 的差距真实存在,但没有大到“任何 coding 任务都必须上 mini”。若你的任务只是简单辅助修改、轻量支持型 subagent,nano 仍可能是更划算的解。
第二,mini 真正拉开差距的地方是 terminal-heavy、tool-heavy 和 computer-use-heavy 工作。这与工具支持表指向的是同一个结论:mini 更适合重工作流。
第三,nano 其实并不弱。认真看表会发现,它更像是便宜路线的能力地板已经不低,但 OpenAI 很明确地把它放在“更简单 supporting tasks”的 lane 上。
这正是当前很多页面没有讲清楚的地方:它们会贴表,却不会告诉你该怎么围绕这些数字做预算分配。
简单经验法则是:
- 当 tool failure、错误恢复慢、computer use 失误会直接伤害用户体验时,为 mini 付费通常值得。
- 当任务本身便宜、窄、重复,且 mini 的额外能力大概率会被浪费时,nano 才是正确答案。
什么时候 GPT-5.4 mini 值得这笔钱
当模型做的工作更像“较强的执行型 worker”,而不是“廉价分类器”时,GPT-5.4 mini 才真正值钱。
最典型的场景是 coding assistants。OpenAI 本来就把 mini 定位在 coding workflow 上,benchmark 也支持这一点。如果模型要在 codebase 里导航、检查多文件、从失败的 tool call 中恢复、理解 diff,或在 coding harness 内持续工作,mini 是更稳妥的默认值。
第二类是 computer use 或 screenshot-heavy workflow。这里也是 mini 拉开最明显差距的地方。如果系统需要读 UI、通过软件界面执行操作,或在结构化循环里理解高信息密度截图,mini 不只是“略强一点”,而是这组对比里唯一支持 built-in computer use 的那一个。
第三类是更重的 subagent 任务。OpenAI 的发布文明确提到 Codex 式委派:较大模型负责规划,较小模型并行执行子任务。若这些子任务仍需要较强 coding 判断、较复杂工具选择或更稳的 tool behavior,mini 才是更合适的 worker。
第四类是工具生态更复杂的系统。tool search 很容易被忽略,但一旦你的系统需要在很多 tools、namespaces 或 MCP surface 之间选择,mini 就比 nano 更安全。nano 更适合工具面小而固定的系统。
当下面这些条件大多成立时,优先 GPT-5.4 mini:
- 模型要做真实编码工作,而不是很浅的编辑。
- 模型需要 computer use 或截图驱动理解。
- tool failure 会转化成延迟、重试成本或用户信任损耗。
- 它是 agent 系统中的 worker,但任务本身并不简单。
- 相比模型单价,工程补救成本更高。
最后这一点非常关键。很多团队把模型价格看成系统唯一成本,但真实产品里,重试、fallback、prompt 复杂度、人工介入和用户等待时间也都在烧钱。mini 的意义往往在于降低这些隐性成本。
什么时候 GPT-5.4 nano 反而是更好的默认值
GPT-5.4 nano 并不只是“预算不够时才选的模型”。当任务本来就应该在廉价分支上运行时,它反而是更正确的默认值。
OpenAI 直接把 nano 推荐给 classification、data extraction、ranking 和更简单的 coding subagents。把它翻译成常见生产任务,大概就是:
- 用户意图分类或工单分类
- 从文本里抽结构化字段
- 对候选结果做排序或筛选
- 把请求路由给后续系统
- 在较大 planner 下做简单支持性子任务
这类场景里,产品常常更受益于更低单价和更高吞吐,而不是更高 benchmark 天花板。
nano 在另一类场景也很适合:整个产品很复杂,但这一个子任务本身很浅。比如上层系统用大模型或更强 worker 处理难题,但把这些事情交给 nano:
- 先总结 tool 输出再交回 planner
- 过滤或优先排序候选文档
- 为下游规则引擎抽取字段
- 做低成本验证或 routing
因此,更准确的理解不是“nano 是较弱的通用模型”,而是“nano 是更便宜的简单任务专用 worker”。
当下面这些条件大多成立时,优先 GPT-5.4 nano:
- 任务窄、重复、结构化。
- 你更在意单位成本,而不是边缘复杂场景的能力。
- 模型不需要 built-in computer use。
- 模型不需要在更大工具面里做 tool search。
- 你在给更大协调模型配一个支持性 worker。
换句话说,当你的真实问题不是“哪个更强”,而是“最便宜但足够完成这项工作的是哪个”时,nano 才是默认值。
很多时候,最好的架构不是二选一,而是两者都用
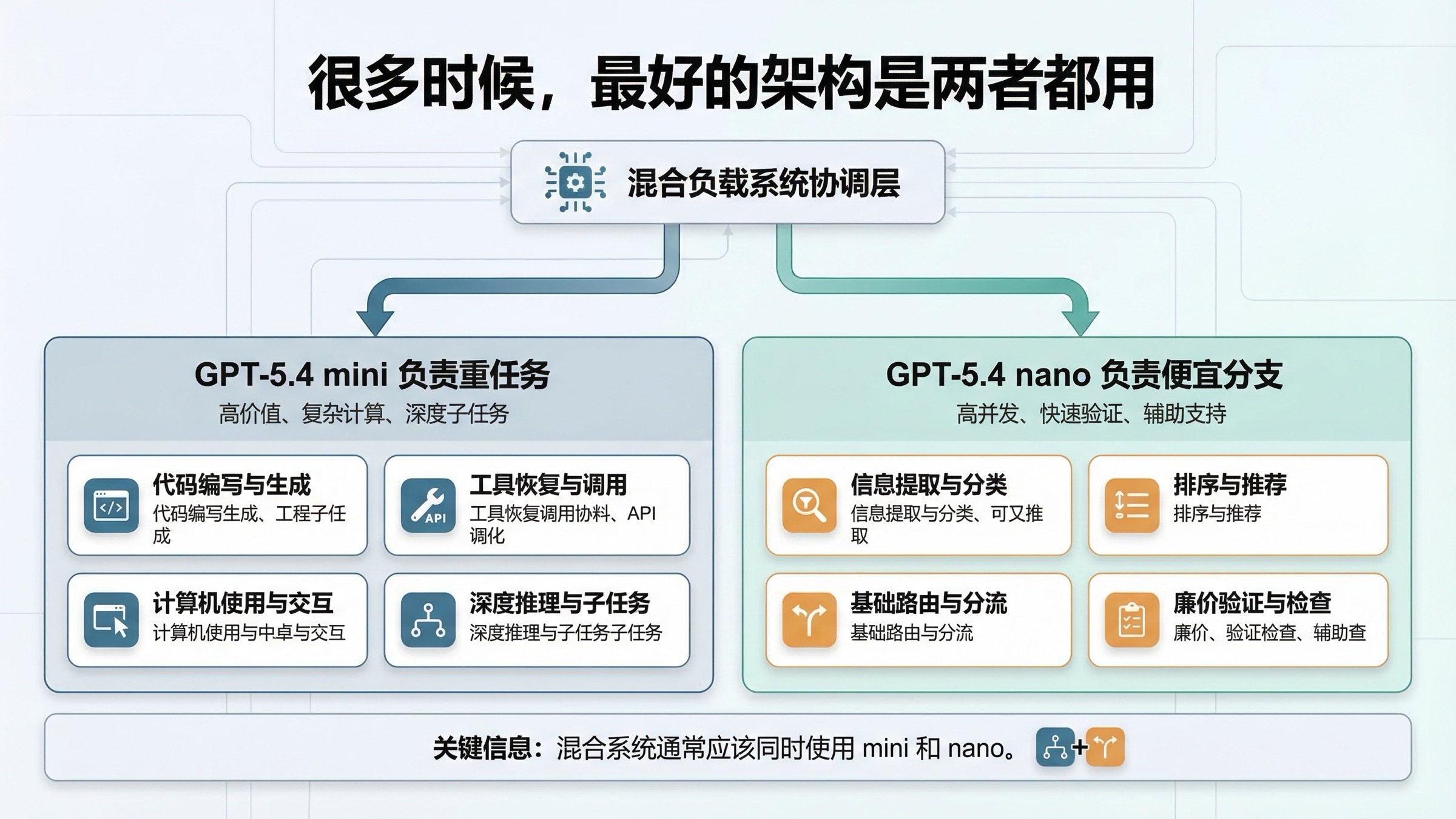
这一段恰恰是很多比较页完全跳过,但在真实产品里最有价值的部分。
如果你的产品只有一种请求类型,那当然可以直接二选一。但大多数真实系统至少有两条 lane:
- 一条较重的 lane,里面是 coding、tool recovery、截图理解或更深的 reasoning。
- 一条较便宜的 lane,里面是 extraction、ranking、classification 或支持任务。
如果这两类任务差异很大,强行让同一个模型全包,往往不如按 lane 分开。
最实用的拆法通常像这样:
| Lane | 更适合的模型 | 为什么 |
|---|---|---|
| 规划器旁边的较强 worker | GPT-5.4 mini | coding 深度、tool reliability、computer use 更强 |
| 廉价 helper 或支持 worker | GPT-5.4 nano | 对窄而重复的任务,单位经济性更好 |
这其实正是 OpenAI 发布文里关于 subagents 的潜台词。mini 可以承担更强的执行 worker,而 nano 则可以承担更便宜的 utility lane,只要这些子任务真的足够简单。
因此,如果你的团队一直在问“我们应该统一到 mini 还是统一到 nano”,更好的答案可能是:先统一路由逻辑,再决定哪个 lane 由谁负责。
API、Codex 和 ChatGPT:不要混为一谈
这个关键词会引发大量混淆,因为搜索者其实来自不同产品表面。
对 API 来说,官方答案很简单:
- GPT-5.4 mini 在 API 中可用。
- GPT-5.4 nano 在 API 中可用。
对 Codex 来说,发布文写得更明确:GPT-5.4 mini 覆盖 Codex app、CLI、IDE extension 和 web,且 Codex 可以把一些子任务委派给 GPT-5.4 mini subagents。GPT-5.4 nano 并没有被同样地描述成 Codex 主工作面模型。
对 ChatGPT 来说,就更容易误读。发布文确实说 GPT-5.4 mini 会出现在部分 ChatGPT 路径中,但当前 Help Center 文章 同时又说明:登录用户的默认主线是 GPT-5.3,付费用户手动选择的是 GPT-5.4 Thinking。也就是说,ChatGPT 里的体验,并不能直接映射到 API 的模型推荐。
如果你真正要决定的是“API 里应该买哪个模型”,请以模型页和发布文为准;如果你要决定的是“ChatGPT 里能看到什么”,请以 Help Center 为准。名字有重叠,但产品决策面并不相同。
FAQ
GPT-5.4 mini 一定比 GPT-5.4 nano 更好吗?
它确实更强,但不一定更适合。对简单高吞吐任务,nano 往往是更好的答案,因为 OpenAI 本来就把它放在更廉价的 utility lane 上。
做 coding 应该选哪一个?
如果是较真实的 coding 工作,选 mini。若只是更大 coding 系统里的简单 supporting subagent,nano 也可能够用。任务越复杂、工具流越深,答案越偏向 mini。
做 extraction 和 ranking 应该选哪一个?
OpenAI 直接推荐 nano 做 classification、data extraction 和 ranking。所以默认应从 nano 开始测,除非你的实际任务比它看起来更复杂。
GPT-5.4 nano 支持 tools 吗?
支持。nano 依然支持 web search、file search、image generation、code interpreter、hosted shell、apply patch、skills 和 MCP。与 mini 最关键的差异,是它没有 computer use 和 tool search。
新团队应该从 mini 还是 nano 开始?
从真实工作类型开始,而不是从名字开始。如果是 coding-heavy 或 agent-heavy 工作,从 mini 开始;如果是廉价高吞吐工作,从 nano 开始;如果产品明显同时存在两条 lane,就按 lane 分开。
最终建议
如果你只带走一句话,可以用这句:对于更重的 coding 与 agent workflow,GPT-5.4 mini 是正确的小模型默认值;对于廉价高吞吐 utility work,GPT-5.4 nano 才是正确默认值。
这个判断建立在 2026 年 3 月 20 日复核的五个事实上:
- 两者拥有相同的上下文窗口、最大输出和知识截止。
- nano 价格显著更低。
- mini 在 coding、tool use 与 computer use 场景上的 benchmark 更强。
- mini 支持 computer use 和 tool search,而 nano 不支持。
- OpenAI 直接把 nano 推荐给 classification、extraction、ranking 和更简单的 supporting subagents。
所以真正的问题从来不是“哪个更强”。更强的是 mini。真正的问题是:你的任务是否复杂到需要 mini,还是足够简单,以至于继续为 mini 付费会浪费预算。在很多生产系统里,正确答案其实是让两个模型各自负责不同 lane。