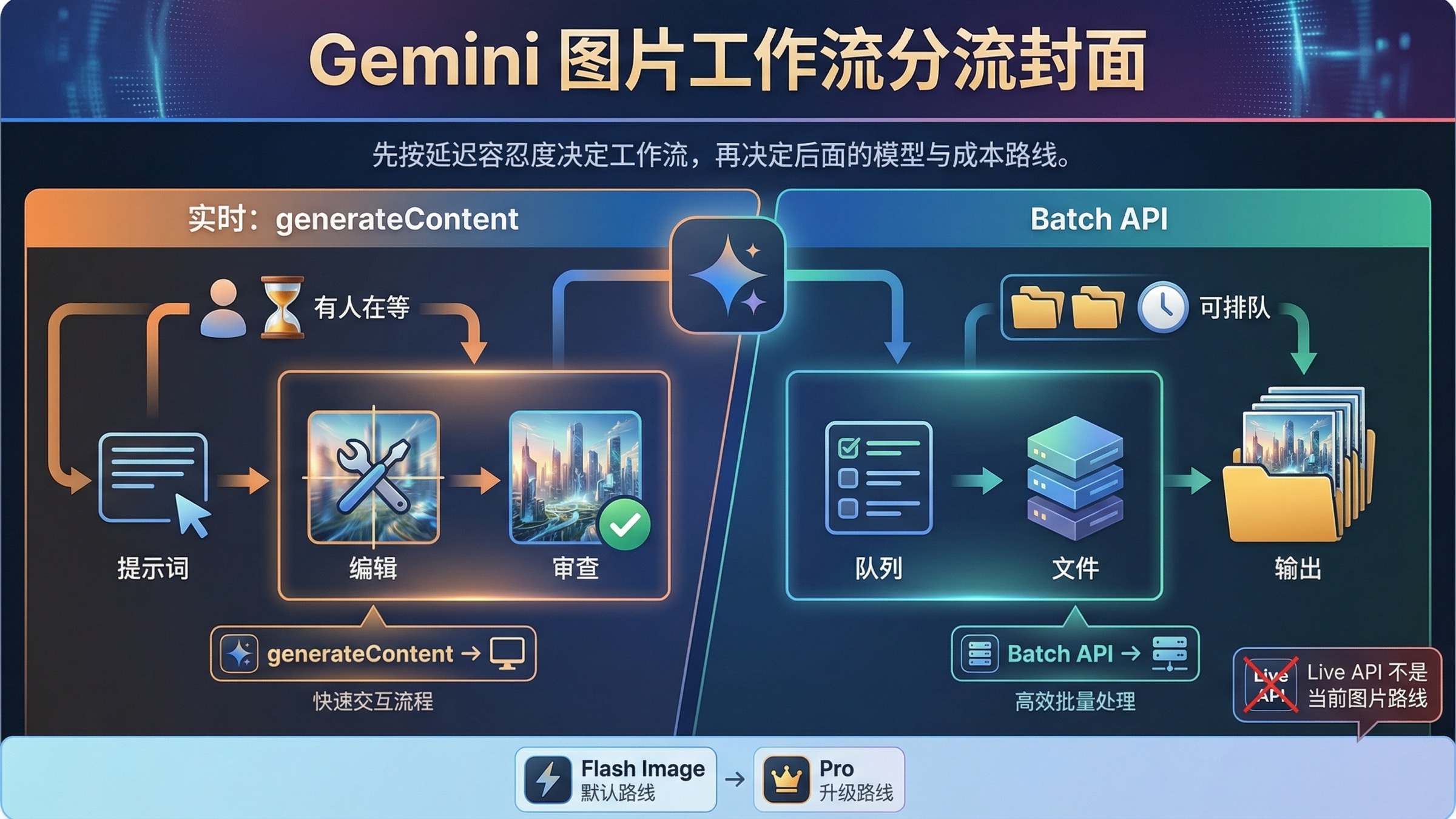
截至 2026 年 3 月 23 日,Gemini 图片生成最值得先记住的一条规则其实很简单:如果有人正在等结果,就用同步 generateContent;如果任务量大、又不要求立刻返回,再用 Batch API。 这类问题最好不要先从价格表开始,因为真正决定路线的第一层,不是每张图多少钱,而是你的工作流到底是“人机来回迭代”,还是“稳定请求的大批量排队执行”。
开头还要先拆掉一个常见误解。对当前 Gemini 图片模型来说,“实时”并不等于 Live API。Google 当前的 gemini-3.1-flash-image-preview 和 gemini-3-pro-image-preview 模型页都明确写着 支持 Batch API、不支持 Live API;同时,当前的图片生成官方文档又一直在用普通同步 generateContent 和多轮编辑来举例。也就是说,这个话题里的 realtime route,真正指的是标准 request-response 生成与编辑,而不是直播式图像输出。
之所以要把这个点放在开头,是因为文档本身没有问题,但信息被拆得太散。你会在一个页面看到 Batch API,在另一个页面看到图片生成,在 pricing 页面看到价格,在 model 页面看到 capability。单独看都对,拼起来却不一定能帮你做出对的工作流判断。所以这篇文章的重点不是重复文档,而是把这些信息重新组合成一个能做决策的操作层答案。
要点速览
如果你现在只想先拿到最短答案,先看这张表。
| 问题 | 当前更好的答案 | 为什么 |
|---|---|---|
| 有人在等这张图或这次编辑结果 | 同步 generateContent | 当前 Gemini 图片文档本身就是按 prompt 调整、结果查看、多轮 refinement 来设计的 |
| 任务量很大、又不着急,成本比延迟更重要 | Batch API | Batch API 文档 直接写了 标准价格的 50% 和 24 小时目标周转时间 |
| 你说的“实时”其实是 Live API 那种图像会话 | 这不是当前图片模型的正确理解 | 当前图片模型页都写着 Live API not supported |
| 大多数新工作流先用哪条模型线 | gemini-3.1-flash-image-preview | 它是当前更高效的默认路线,也是 gemini-2.5-flash-image 的官方替代方向 |
| 什么情况下才值得上 Pro | 当文字、排版和失败成本已经明显变贵时 | gemini-3-pro-image-preview 更适合文本多、版式敏感、成品价值高的图像任务 |
| 官方最便宜的 Gemini 原生图片路线 | gemini-2.5-flash-image | 但它已经是 legacy 线,Google 标的关闭日期是 2026 年 10 月 2 日 |
这类决策最容易犯的错,就是因为 Batch API 更便宜,就先把它当默认答案。便宜当然重要,但前提是“等得起”。如果你的工作流还处在 prompt 探索、人工 review、编辑修正或者用户前台交互阶段,那么同步路线通常仍然更强。
可以用三个很短的例子记住:
- 用户正在等下一张图:同步
- 团队还在当天来回改 prompt:先同步,稳定后再 batch
- 晚上批量生成几千个已经定型的版本:batch
如果你下一步更关心代码,而不是工作流分流,直接看站内的 Gemini 图片生成代码示例。如果你更关心价格,再去看 Gemini 图片生成 API 定价。如果你的真实问题已经变成“图生图编辑该怎么做”,那篇 Gemini 图像编辑指南 会更对路。
真正的分界线:同步 generateContent 还是 Batch API
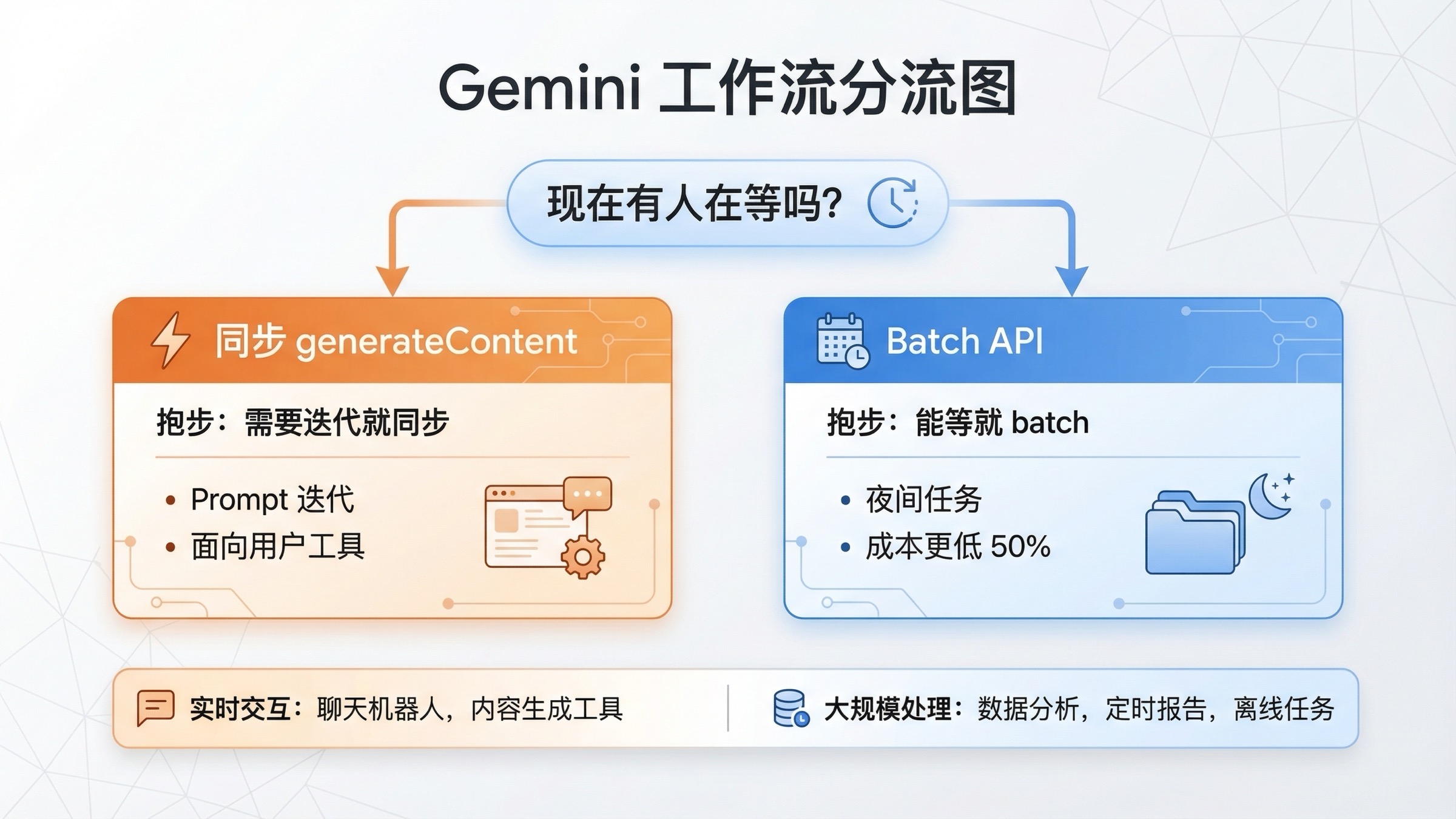
很多人问“batch 还是 realtime”,表面上像是在问一个技术接口问题,实际上是在问一个工作流问题。真正应该问的不是“哪条 API 更高级”,而是:
现在有没有人正在等这个输出。
如果答案是有,那就留在同步路径。这通常覆盖:
- prompt 试错和探索
- 面向用户的图片工具
- 人工 review 回路
- 多轮编辑
- 第一张图不够好后的快速重试
如果答案是没有,Batch API 就会变得很有吸引力。这通常覆盖:
- 夜间批量生成
- 队列驱动的素材流水线
- 大规模商品图或变体图任务
- 不着急的 backfill
- 已经验证完 prompt 的重复性生产
Google 当前的 Batch API 文档 把权衡写得很直接:它面向大批量请求,异步执行,价格是 标准成本的 50%,目标完成窗口是 24 小时。这个折扣对大规模工作很有意义,但只要你的下一步动作依赖“现在就得拿到图”,它就不再是最优路线。
反过来也一样。同步图片生成并不是玩具模式,也不只是少量测试时才用。只要价值来自快速迭代,它就是正路。当前的 图片生成文档 本身就是这么组织的:生成、编辑、多轮 refinement 都是同步思路,因为图片工作真正高效的时刻,往往发生在“一条 prompt、一张结果、一个修正、下一轮补充”这种短回路里。
所以这篇文章最重要的判断,可以压缩成两行:
- 交互式、人还在 loop 里、用户正在等结果:同步
- 排队型、量大、重成本、不着急:batch
这个问题一旦先想明白,后面的模型和价格就会容易得多。也正因为如此,很多团队最容易踩的坑,是明明知道以后可能会需要队列,就从第一天开始把所有东西都做成队列。事实上,你以后可能需要 queue,并不意味着你今天就该从 queue 起步。更稳的路线通常是先用同步工作流把 prompt、参数和输出处理跑顺,再决定哪些请求值得单独抽成 batch 分支。
各种工作流后面,应该接哪条 Gemini 图片模型线
工作流决策和模型决策有关,但不是同一件事。Batch 不是模型,realtime 也不是模型。你完全可能在同步路径和批处理路径后面,都用同一条图片模型线。
对大多数新项目来说,当前默认答案仍然应该是 gemini-3.1-flash-image-preview。Google 把它摆在更高效的当前图片路线位置上,而且在 deprecations 页面 里也把它列成 gemini-2.5-flash-image 的替代方向。
| 模型 | 2026 年 3 月 23 日的状态 | Batch API | Live API | 当前价格信号 | 更适合什么 |
|---|---|---|---|---|---|
gemini-3.1-flash-image-preview | 当前默认 preview 路线 | 支持 | 不支持 | $0.067 / 1K,batch $0.034 | 大多数新的交互式与排队式图片工作流 |
gemini-3-pro-image-preview | 当前高阶 preview 路线 | 支持 | 不支持 | $0.134 / 1K 或 2K,batch $0.067 | 文本多、图表多、成品价值高的图像任务 |
gemini-2.5-flash-image | 仍在线但已偏 legacy | 支持 | 不支持 | $0.039 standard,$0.0195 batch | 只想拿到当前官方最便宜路线时 |
这里最值得记住的是三点。
第一,当前 Gemini 图片模型支持 Batch API,但不支持 Live API。所以不要把这个话题理解成“其实应该走 Live API 只是我还没找到入口”。当前图片线不是这么设计的。
第二,gemini-3.1-flash-image-preview 仍然是最稳的默认答案。无论你最后走同步还是 batch,它都是最适合先试的一条线。
第三,最便宜和最该默认选,并不是同一个答案。gemini-2.5-flash-image 的确便宜,但 Google 也已经给它挂上 2026 年 10 月 2 日 的关闭日期。现在如果要新建工作流,把它当成短期省钱的 legacy 选择可以,但不该把它当成新系统的中性默认值。如果你真正想看的是更大范围的模型路线比较,可以继续读 Gemini 图片生成器:Nano Banana 2、Pro 还是 Imagen 4?。
适合 prompt 迭代、review 和编辑的实时工作流
如果有人在等结果,那么最好的 workflow 仍然是普通同步 generateContent。这对 backend service、内部图片工具、聊天式产品界面都成立。
原因不只是速度,而是迭代质量。
Gemini 图片工作里最有效的一类循环,通常是这样的:
- 先发一条清楚的 prompt
- 看第一张图
- 只修正一件事
- 再发下一轮
对编辑来说尤其如此。当前图片生成文档强调 conversational 和 multi-turn,这个理解到现在都很正确。因为第二轮到底怎么改,几乎总是取决于第一张图哪里做对了、哪里做错了。Batch 不适合这种回路,因为你会太晚才知道问题在哪里。
下面这种同步请求,仍然是几乎所有新工作流都该先跑通的一类 baseline:
javascriptimport { GoogleGenAI } from "@google/genai"; import * as fs from "node:fs"; const ai = new GoogleGenAI({ apiKey: process.env.GEMINI_API_KEY }); const response = await ai.models.generateContent({ model: "gemini-3.1-flash-image-preview", contents: "Create a clean 16:9 product hero image of a matte black coffee grinder on a soft gray background with premium ecommerce lighting.", config: { responseModalities: ["IMAGE"], imageConfig: { aspectRatio: "16:9", imageSize: "2K" } } }); for (const part of response.candidates[0].content.parts) { if (part.inlineData) { fs.writeFileSync("coffee-grinder.png", Buffer.from(part.inlineData.data, "base64")); } }
第一条请求最好故意写得朴素一点。它的任务不是炫技,而是确认模型、尺寸、返回格式和落盘逻辑在你的环境里都工作正常。等这条链路稳了,再去做更复杂的编辑、多轮 refinement 和高价值 prompt。
同步路径里,有两个习惯特别能提高质量:
- 不要只扔关键词,要把场景说出来
- 做编辑时,不仅要说改什么,也要说哪些部分不能动
Google 较早的 prompt 指南虽然面向更早的模型线,但这个原则到现在仍然成立。Gemini 对“该保留什么”这类约束反应得更好。所以真正的人机协作型图片工作,通常应该先放在同步路径里打磨,而不是一开始就塞进 batch。
如果你前期先在 AI Studio 里试,这没有问题。但不要把测试界面当成生产契约本身。Google 在 2026 年 2 月 26 日 的 Nano Banana 2 开发者文章里写得很清楚:这个模型在 AI Studio 里需要 付费 API key。AI Studio 适合更快摸 prompt,不等于它替代了后面的生产工作流设计。
适合排队或夜间批量生成的 Batch 工作流
Batch API 真正发挥价值的场景,是任务真实存在、量够大,而且不急。通常这意味着下面三类需求之一:
- 你真的在意总成本
- 你需要稳定吞吐的队列
- 你希望把请求接入和结果交付拆成两个阶段
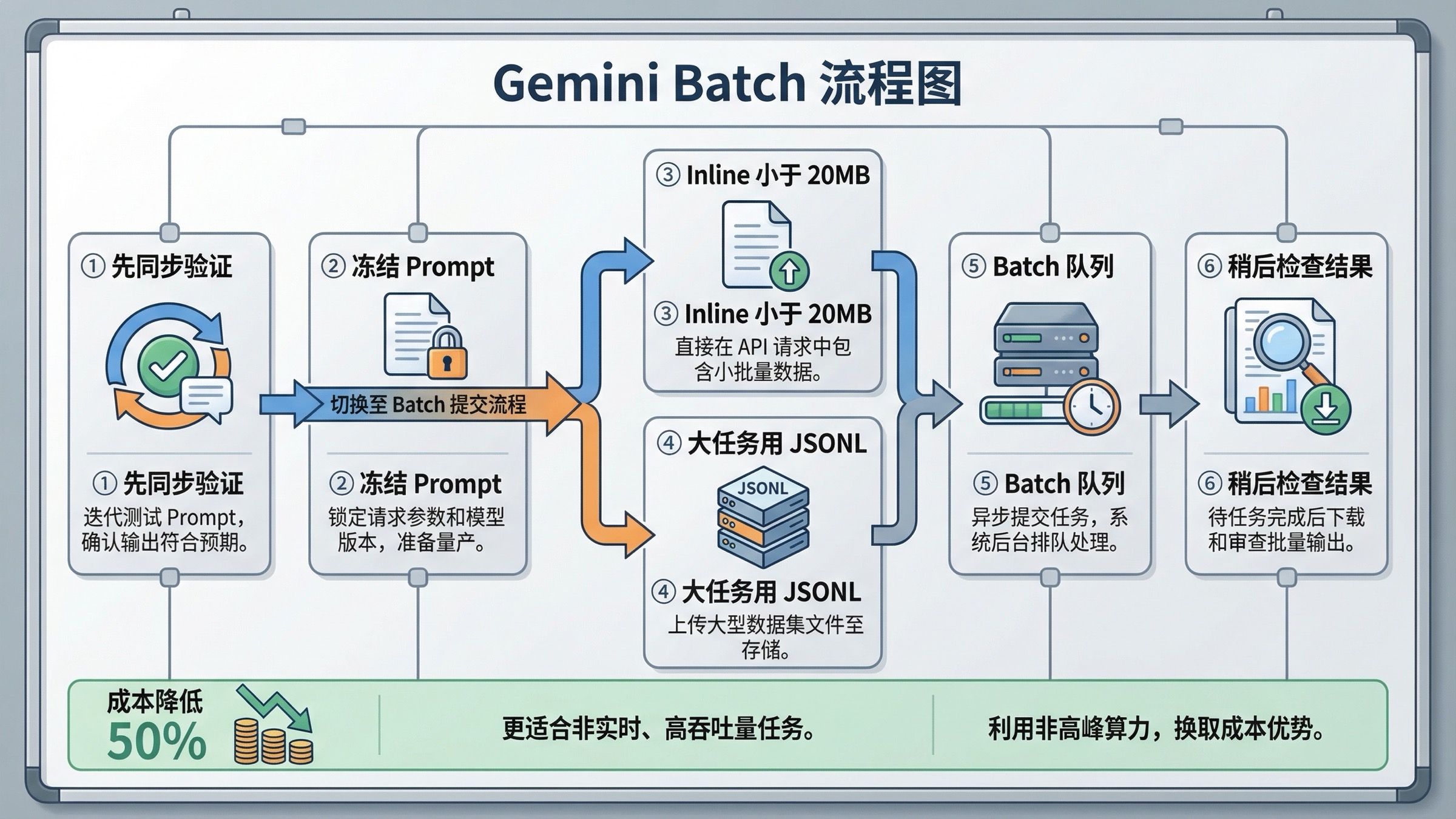
Google 当前文档说得很直接:小任务可以用 inline requests,大任务可以走 JSONL 文件输入。对图片生成来说,后者往往更像真正能跑进生产的路径,因为它更容易重放、审计和批量管理。
一个更稳的 batch workflow 通常长这样:
- 先用同步流程把 prompt 和参数跑稳定
- 冻结 request 格式
- 把任务序列化成 JSONL 或小批量 inline 组
- 只有在“继续等待也不会让结果更好”时再交给 batch
- 后续结果收集和 retry 单独处理
这里最容易出错的地方,是因为 batch 更便宜,就把 prompt discovery 也搬进去。这样看起来每次调用单价更低,但整体学习速度反而更慢。Prompt discovery 本质上是交互式工作;Batch 的价值在于稳定请求的大规模重复。
一旦请求已经稳定,价格差会变得非常明显。按 2026 年 3 月 23 日 的当前价格看,gemini-3.1-flash-image-preview 做 10,000 张 1K 图片,大约是 $670 的标准成本和 $340 的 batch 成本;如果换成 gemini-3-pro-image-preview,则大约是 $1,340 和 $670。这也是为什么 catalog refresh、固定模板批量出图、scheduled asset generation 这类任务,很值得走 batch 分支。
但 Batch API 不只是一个折扣功能,它还是一套不同的运维 surface。rate limits 页面 里写着 100 个并发 batch 请求、2GB 输入文件大小上限、20GB 文件存储,以及按模型统计的 enqueued tokens。也就是说,普通同步流量没问题,不代表 batch 一定没压力。
请求的形状也重要。Google 现在明确说,inline requests 适合总 payload 低于 20MB 的情况,规模更大的工作应该转去上传后的 JSONL 文件。在真实生产里,JSONL 路线通常更稳,因为 batch create 本身更轻,也更方便回放。
json{"key":"shoe-0001","request":{"contents":[{"parts":[{"text":"Create a clean white-background ecommerce image of a running shoe in side profile."}]}],"generation_config":{"response_modalities":["IMAGE"]}}} {"key":"shoe-0002","request":{"contents":[{"parts":[{"text":"Create a clean white-background ecommerce image of a black leather loafer in side profile."}]}],"generation_config":{"response_modalities":["IMAGE"]}}}
这个例子故意写得很普通,因为 batch 文件最重要的不是优雅,而是可重现。到 JSONL 这一步时,你的 prompt、参数和结果预期都应该早就在同步路径上验证过了。
对很多团队来说,最实用的其实是混合路线:
- prompt 设计、首轮审批、编辑修正走同步
generateContent - 只有稳定、重复、可批量的部分才交给 Batch API
- 能接受 24 小时 目标周转的任务才进 batch
这个混合路线通常比“所有东西一开始都做成 batch”更强,因为它把需要人判断的环节和适合廉价重复的环节拆开了。
有时候该变的不是工作流,而是模型
看完 pricing table 后,最容易产生的误解,是把这个话题看成 Flash 对 Batch 的二选一。其实不是。很多时候,工作流不需要变,需要变的是模型。
这里 gemini-3-pro-image-preview 就会开始有意义。
当“生成失败一次的代价”已经高过模型差价时,Pro 就变得合理。典型场景包括:
- 真实文字很多的图表和信息图
- 排版要求高的成品图
- 对外客户素材
- 需要更强 label 与 layout 准确性的可视化
- 不希望一稿失败率太高的高价值输出
请注意,这里面没有一条是在说“工作流必须改”。如果人还在等结果,那即便是 Pro,也还是同步;如果任务仍然是高价值但不着急的大批量输出,那即便是 Pro,也仍然可能走 batch。工作流问题和模型问题,最好拆开看。
这样一来,实际可用的不是两条路,而是四条:
- Flash + 同步:大多数交互式图片工作
- Flash + batch:量大、稳定、重成本的重复生成
- Pro + 同步:高价值、要反复改的高级工作
- Pro + batch:不着急但品质要求高的大批量任务
所以真正好用的顺序不是先问“谁更强”,而是先问“失败的代价有多高”。
怎么判断自己选错了工作流
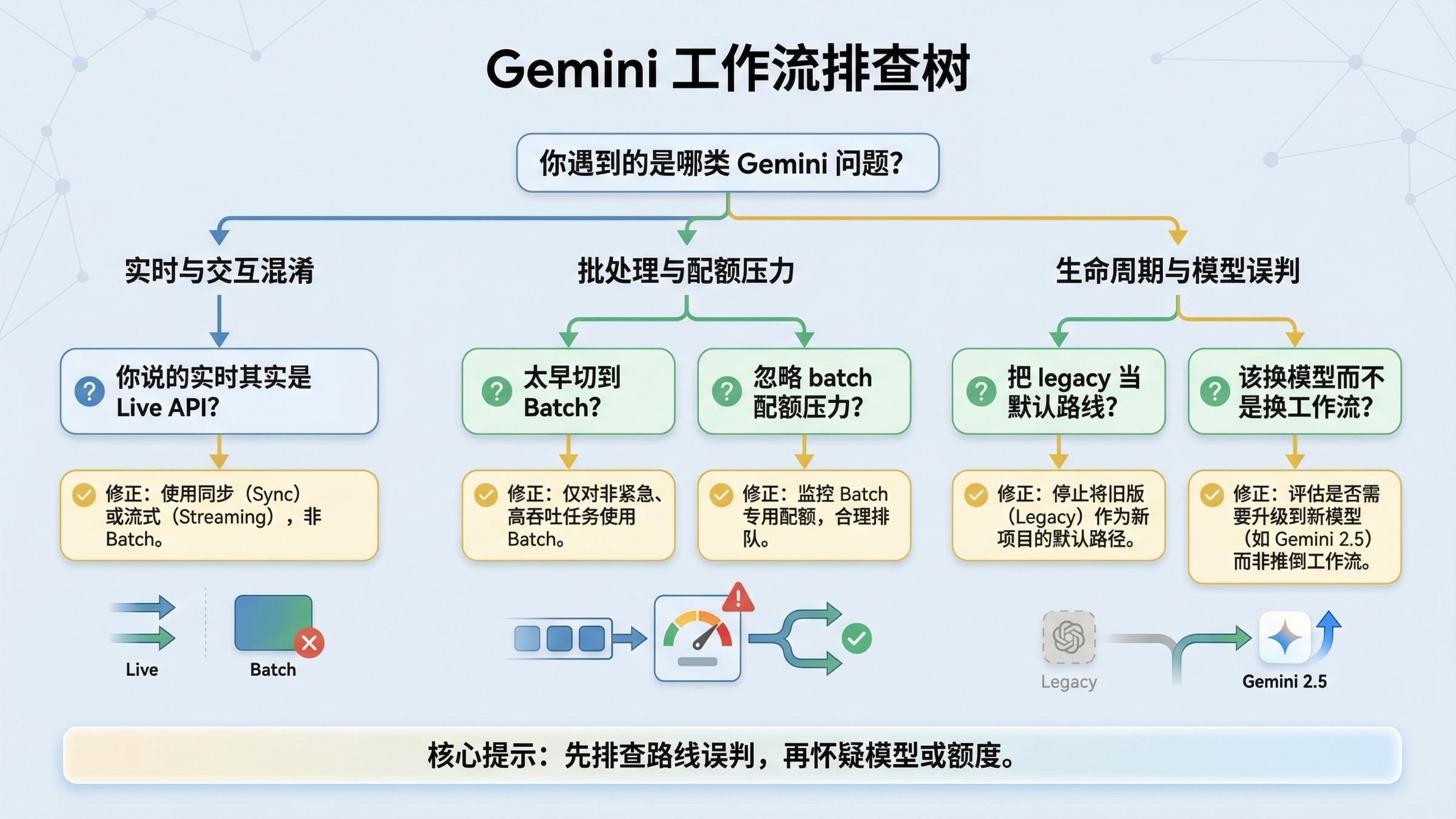
这个主题里的很多问题,并不是 API 本身坏了,而是工作流选错了。
你把“实时”这个词用得太宽。 对当前 Gemini 图片模型来说,实时几乎总是普通同步 request-response,不是 Live API 图像输出。如果这里不先讲清楚,很容易一开始就设计错方向。
你在 prompt 还没稳定时就上了 batch。 折扣是真的,但这并不意味着 batch 适合做 prompt 学习。Prompt 要先在同步路径里打磨,批处理适合的是“已经稳定的重复执行”。
你把工作流问题和生命周期问题混在一起。 gemini-2.5-flash-image 便宜没错,但它也已经有 2026 年 10 月 2 日 的关闭日期。如果选它,应该是有意识地用一条 legacy 省钱线,而不是把它当成新系统默认答案。
你只看普通配额,没有单独看 batch 压力。 Batch 有自己的 enqueued-token 压力,这会影响监控和容量预估。
你把 AI Studio 误当成整个产品故事。 AI Studio 当然适合试 prompt,但你的真实应用最终运行在 API 合约、模型能力和实际 pricing 上。AI Studio 里跑通,并不自动代表工作流选型是对的。
你在用工作流切换,去解决本来是模型问题的事情。 有时真正要改的不是 batch 还是同步,而是 Flash 还是 Pro。特别是文本多、布局敏感的任务里,这个判断很关键。
如果你下一步已经转向 legacy 迁移判断,而不是工作流选择,接着读 Gemini 2.5 Flash Image 替代指南 会更顺。
结论
关于 Gemini 图片生成该选 batch 还是 realtime,当前最实用的答案并不是一句抽象 API 对比,而是一条很朴素的路由规则。
如果有人在等结果,就留在同步 generateContent。如果任务量大、不着急、而且 prompt 学习阶段已经结束,再切到 Batch API。大多数新工作流先从 gemini-3.1-flash-image-preview 起步;当文本质量、排版要求或失败成本明显提高时,再升级到 gemini-3-pro-image-preview。gemini-2.5-flash-image 则只适合被理解成“还在线但偏 legacy 的便宜路线”,并且要记住它的关闭日期是 2026 年 10 月 2 日。
顺序很重要:先按延迟容忍度选工作流,再按失败成本选模型。这样最不容易走偏。