
截至 2026 年 3 月 22 日,Gemini 图片生成代码最稳的默认起点,是原生 Gemini API 配合 gemini-3.1-flash-image-preview。 除非你一开始就知道自己需要更高成本的 gemini-3-pro-image-preview 去处理文字很多的信息图、海报或更高价值的成品,否则先从这条路线开始最稳。
这条建议之所以重要,是因为当前 Gemini 图片栈很容易被搜索结果带偏。Google 有些页面在讲 Gemini App,有些在讲 AI Studio,有些是原始 API 文档,还有不少旧教程仍然围绕 2.5 图片线。对开发者来说,正确的第一步更窄也更实用:先选对当前模型,先跑通一个能真正保存图片的 native request,然后再决定编辑、多轮对话、Pro 或 Batch 会不会改变你的实现。
还有一个 caveat 必须在最前面说清楚。Gemini App、AI Studio 和 Gemini API 彼此相关,但它们并不共享一条简单的“免费或付费”规则。Google 当前的 billing 页面 仍然写着新账号从 Free tier 开始,但 Google 在 2026 年 2 月 26 日 发布的 Nano Banana 2 开发者文章 又明确说,这个模型在 AI Studio 中需要付费 API key。很多人真正调不通代码,不是因为 SDK 有问题,而是一开始就把 surface 和计费前提混在了一起。
要点速览
- 对大多数新项目来说,先用原生 Gemini API,而不是通用兼容层。
imageSize、aspectRatio、多轮编辑和更完整的图片能力都在 native 路线里更清楚。 - 默认先从
gemini-3.1-flash-image-preview开始。只有当图片里的文字质量、信息图效果或失败成本已经明显更高时,再切到gemini-3-pro-image-preview。 - 第一条请求越无聊越好。先生成一张图、先把文件保存下来,再去加编辑、Google Search grounding、Batch 或更复杂的 prompt pipeline。
- 在 Gemini 3 图片模型上,显式设置
imageSize和aspectRatio很重要。当前文档公开了512、1K、2K、4K四档尺寸,以及比 legacy 2.5 线更丰富的比例。 - 把价格、付费 key、关闭日期、速率限制都当成活信息。现在
gemini-2.5-flash-image仍然是官方最便宜的路线,但 Google 的 deprecations 页面 也已经把它的关闭日期写成 2026 年 10 月 2 日。
| 路线 | 最适合什么 | 默认从哪个模型开始 | 为什么这是当前更好的起点 | 主要 caveat |
|---|---|---|---|---|
| JavaScript / Node.js 原生 SDK | Next.js API route、后端服务、worker | gemini-3.1-flash-image-preview | 当前最顺手的 SDK 路径,便于处理 imageSize、aspectRatio 和返回的 inline image data | API key 必须留在服务端,不能放进浏览器 |
| Python 原生 SDK | 批处理、编辑工作流、脚本、内部工具 | gemini-3.1-flash-image-preview | 最适合做图片迭代、本地文件输入和多轮编辑 | 很容易先写成脚本,后来却忘了补重试和日志 |
| 原始 REST / cURL | 调试、看真实 payload、非官方 SDK 语言 | gemini-3.1-flash-image-preview | 最容易看清请求和响应的真实形状 | 样板代码更长,还要自己解码返回的图片 |
| 高价值、重文本、信息图类成品 | 海报、图表、带大量文字的成品图 | gemini-3-pro-image-preview | 当文字渲染和成品质量真的会改变业务结果时,Pro 更值 | 官方标准价格明显高于 Flash Image |
如果你想先把 App、AI Studio、API 三个入口分清楚,再决定要不要写代码,可以先读 Gemini 图片生成教程:App、AI Studio 和 API 怎么用。如果你下一步更关心成本,可以直接看 Gemini 图片生成价格指南。如果你真正要做的是编辑现有图片,而不是从零出图,那么更合适的 companion page 是 Gemini 图生图编辑指南。
先选对 Gemini 图片生成代码路线
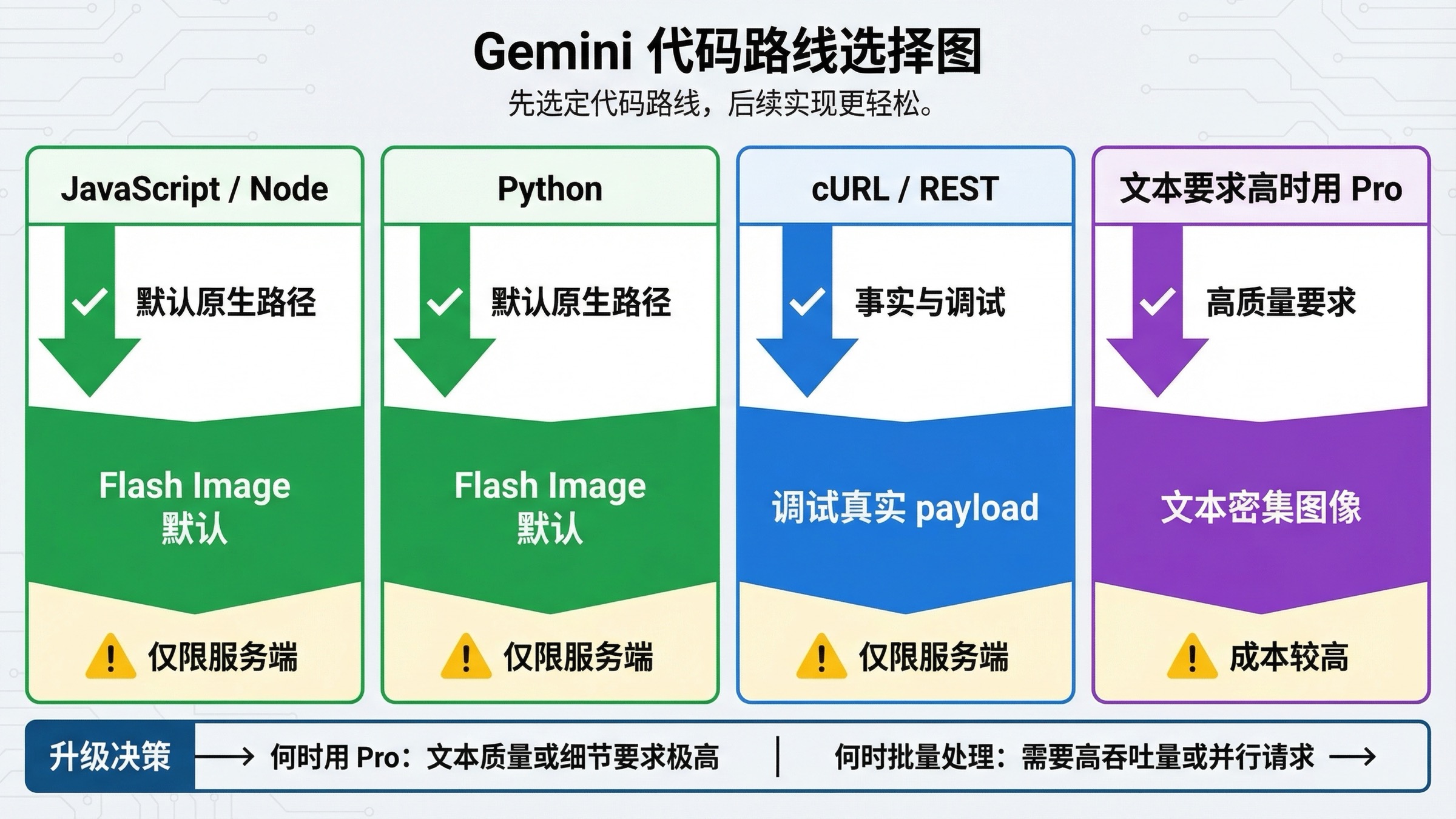
这个主题里最常见的错误,不是 prompt 写得差,而是一开始就站错了 surface。很多开发者搜索“Gemini 图片生成代码示例”时,脑子里已经见过 Gemini App 出图,或者已经在 AI Studio 里点过几次 generate,于是误以为 API 只是把那个界面行为换成代码。现实不是这样。真正进入 API 后,你还得自己选对模型、处理响应、确认计费前提、理解配额和日志,很多“为什么代码和界面体验不一样”的抱怨,都是从这里开始的。
对大多数新代码来说,最好的起点仍然是官方的 Gemini API 图片生成与编辑文档。那一页明确把 Gemini 3.1 Flash Image Preview 放在当前主路线,同时把开发者真正要用到的东西说得很直白:responseModalities、aspectRatio、imageSize、多轮编辑、以及图片相关的模型控制。也正因为如此,这篇文章会坚持 native Gemini 路线,而不是把 OpenAI compatibility 当成默认入口。兼容层对迁移有帮助,但对一个还在快速变化的图片能力栈来说,它不是最清楚的学习入口。
当然,并不是所有 Gemini 图片模型都应该同样对待。Google 当前的 pricing 页面 给出的分工,比很多第三方教程清楚得多。gemini-3.1-flash-image-preview 是当前的默认快车道;gemini-3-pro-image-preview 是更贵的 premium 路线;gemini-2.5-flash-image 仍然活着,也仍然是官方最便宜的一行,但 Google 的 deprecations 页面 已经给出了 2026 年 10 月 2 日 的关闭日期。所以在 2026 年重新写一篇新教程时,“最便宜”与“最值得推荐”已经不是同一个答案。
真正实用的判断其实很简单。如果你是在写新代码,先上 Flash Image。如果你要做的是海报、图表、带大量文字的图片,或者失败一次就会很贵的品牌成品,把 Pro 放进候选路线。如果你决定用 2.5 图片线,那也应该是有意识地选择 legacy 成本路线,而不是被旧搜索结果带进去。
还有一个容易被忽略的决策:AI Studio 可以当 prompt playground,但不要把 AI Studio 误当成你的应用最终契约。Google 自己的 Nano Banana 2 开发者文章已经说了,这个模型在 AI Studio 里需要付费 API key。也就是说,即便你先在 UI 里试 prompt,真正的应用架构、日志、重试、配额判断,仍然应该围绕 API 路线来设计。
JavaScript 示例:当前最短的 Node 或服务端路线
如果你已经在 Next.js、Node.js 或任何后端 JavaScript 环境里工作,当前最干净的路径就是 @google/genai。把 client 留在服务端,从环境变量读取 GEMINI_API_KEY,然后把返回的 inlineData 保存到磁盘或对象存储。
这也是最适合当第一段示例的原因。它刚好覆盖了后面最容易坏掉的那些点:当前包名、当前模型名、显式图片控制、以及响应解析方式。你不需要在第一天就把整条生产链路全部做完。你的目标只是确认一件事:我真的能拿到一张图,而且返回大小和比例符合预期。
javascriptimport { GoogleGenAI } from "@google/genai"; import fs from "node:fs"; const ai = new GoogleGenAI({ apiKey: process.env.GEMINI_API_KEY }); const prompt = ` Create a clean 16:9 product hero image of a matte black travel mug on a light concrete surface. Use soft studio lighting, crisp texture, and calm negative space on the right for marketing copy. `; const response = await ai.models.generateContent({ model: "gemini-3.1-flash-image-preview", contents: prompt, config: { responseModalities: ["IMAGE"], imageConfig: { aspectRatio: "16:9", imageSize: "2K", }, }, }); for (const part of response.candidates[0].content.parts) { if (part.inlineData) { const buffer = Buffer.from(part.inlineData.data, "base64"); fs.writeFileSync("travel-mug-hero.png", buffer); } }
这里有四个细节值得记住。第一,模型名是 gemini-3.1-flash-image-preview,不是旧教程里的 2.5 时代默认值。第二,responseModalities: ["IMAGE"] 的作用,是让你在不需要解释文本时直接拿到图片。Google 文档说默认行为是文字加图片,这对会话式编辑很有用,但对“先把图保存出来”的第一步来说,纯图片返回更干净。第三,真正有价值的 Gemini-native 控制都在 imageConfig 里。如果你在意输出比例和尺寸,就应该显式告诉模型。第四,这段代码应该待在服务端。示例短,不代表 API key 可以放进前端。
当这段代码先跑通之后,下一个才值得考虑的 JavaScript 决策,是你到底需要纯图片输出,还是需要文字加图片的混合响应。如果你是在后端 worker 里批量产图,纯图片更方便;如果你是在做一个创作者工具,用户希望同时看到 Gemini 解释自己改了什么、下一步还能怎么改,那么保留文字响应反而更有价值。native Gemini 图片流的一个优势,正是在这里体现出来的:它不是纯粹的 fire-and-forget endpoint,而是可以被当作一段会话来用。
JavaScript 也是很多团队最容易过早复杂化的地方。你的第一条请求不需要 Google Search grounding,不需要 chat state,也不需要一长串 prompt orchestration。真正有效的进度顺序通常很无聊:先出一张图,再做编辑,再做存储,再做重试,再做配额,再考虑 grounding。
Python 示例:最适合编辑和迭代的当前路径
Python 往往是学习 Gemini 图片生成最顺手的环境。官方文档里的 Python 例子清晰,当前 SDK 足够紧凑,而图像编辑的思路也非常适合写成脚本或内部工具。这使得 Python 对很多团队来说,都是做图片自动化、编辑管线和运营工具时最自然的起点。
Python 在这个主题里最舒服的地方,在于你可以从“生成一张图”的思路,很顺地过渡到“围绕一张已有图片做受控编辑”。Gemini 当前的文档,本身就把图片生成和图片编辑放在同一个 generate_content 心智模型下:输入内容不同,但调用模式没有被拆成完全不同的产品。这比一些旧的 text-to-image API 更贴近真实的图片工作流。
pythonfrom google import genai from google.genai import types from PIL import Image client = genai.Client() base_image = Image.open("living-room.png") prompt = """ Using the provided image of a living room, change only the blue sofa to a vintage brown leather chesterfield sofa. Keep the pillows, lighting, coffee table, and room layout unchanged. """ response = client.models.generate_content( model="gemini-3.1-flash-image-preview", contents=[prompt, base_image], config=types.GenerateContentConfig( response_modalities=["TEXT", "IMAGE"], image_config=types.ImageConfig( aspect_ratio="4:3", image_size="2K", ), ), ) for part in response.parts: if part.text is not None: print(part.text) elif part.inline_data is not None: image = part.as_image() image.save("living-room-edit.png")
这段示例里真正起作用的,是两个判断。第一是 prompt discipline。如果你要做局部编辑,就必须把哪些地方不能动说得非常清楚。Gemini 的 instruction following 很强,但你不把边界讲明,模型也不会替你脑补“只改沙发,不动光线和布局”。第二是 base image 本身作为 contents 数组的一部分进入请求。当前 Gemini 图片编辑真正该记住的心智模型,就是“带着上下文做修改”,而不是切换到一个完全独立的“编辑 endpoint”。
也是从这里开始,多轮工作流会比一口气塞进超长 prompt 更有价值。Google 的 image generation 文档 明确建议用 conversational 或 multi-turn editing 去迭代图片。这一点在真实项目里非常重要。最好的生产级 prompt,常常不是最大的一段提示词,而是一次明确生成、一次返回结果、再加一次只改 delta 的 follow-up。如果第一张已经对了 80%,最好的动作通常不是推倒重来,而是让上下文继续活着。
Python 对这些 follow-up 特别友好,因为它很容易和你现有的资产管线、审核逻辑、后处理流程结合起来。但这也藏着一个真实风险:很多团队先用 notebook 或脚本把概念验证做通了,后来却忘了给这段脚本补上重试、日志、使用统计和 quota 观察。只要这条图片流将来会进生产,这些“无聊部分”迟早都得补。
cURL 与原始 REST 示例:适合低层调试和多语言集成
如果 SDK 让你摸不清真实请求长什么样,或者你的运行环境根本不是 Python / Node,那么 raw REST 仍然是最好的真相来源。cURL 不是最舒服的应用开发方式,但它是最适合看清 Gemini API 请求结构的路径。这对调试模型选择、请求序列化、代理层行为,以及 AI Studio 与你自己的代码到底差在哪里,非常有帮助。
bashcurl -s -X POST \ "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent" \ -H "x-goog-api-key: $GEMINI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "contents": [{ "parts": [ { "text": "Create a 16:9 studio photo of a white sneaker on a soft gray background with crisp side lighting and premium ecommerce styling." } ] }], "generationConfig": { "responseModalities": ["IMAGE"], "imageConfig": { "aspectRatio": "16:9", "imageSize": "2K" } } }'
保留一段 cURL 示例的最大价值,不是因为 cURL 好写,而是因为它能去掉不确定性。如果这段请求在 cURL 能成功、在 SDK 里却失败,那问题大概率在 client 版本、wrapper、或者你的响应解析逻辑;如果 cURL 也失败,那么问题更可能在 API 契约、项目计费、速率限制,或者你选错了模型。
对于 Go、Rust、PHP 或内部平台语言来说,raw REST 也是最清楚的起点。你可能最终不会直接用 cURL,但你几乎一定需要先知道 wire 上真正发出去的 payload 长什么样。它会逼你真正看到 generateContent、contents、generationConfig、responseModalities 和 imageConfig,这在你后面要自建 wrapper、接代理、或向别的团队解释请求形状时非常重要。
缺点当然也很明显。你要自己处理返回的图片数据,自己做 base64 解码,也没有 SDK 帮你处理 file inputs、parts 或 chat helpers。所以 cURL 更像 truth source 与 debugging tool,而不是默认开发舒适区。
会真正改变代码结构的编辑、多轮流程与更高分辨率选项
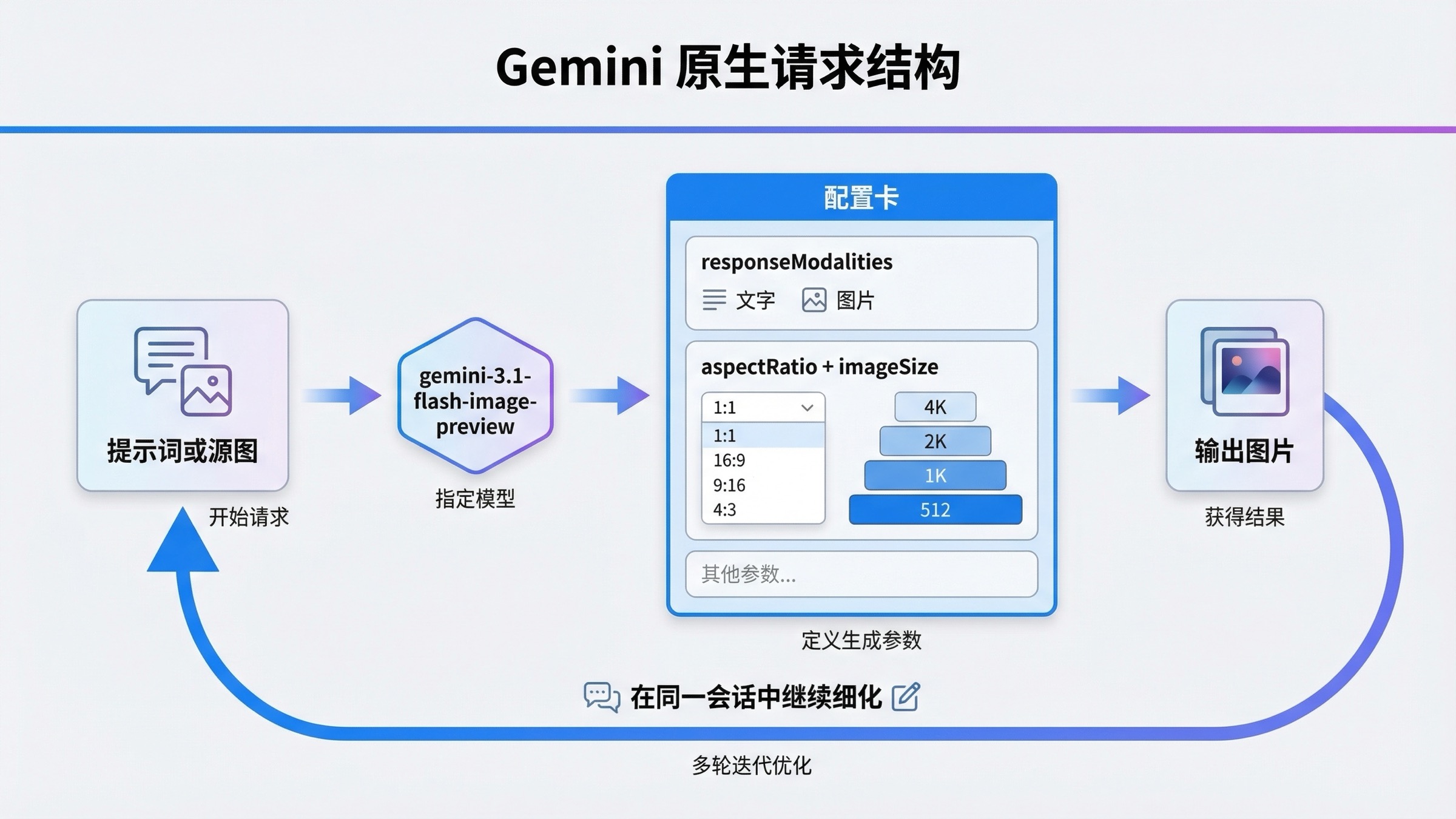
真正把 Gemini-native 图片生成和浅层教程拉开差距的地方,就在这里。很多页面只展示一次 text-to-image 调用,这对 demo 没问题,但并不是大多数真实产品的价值所在。真实工作流通常要处理局部编辑、参考图、输出尺寸、长宽比,以及在上一轮结果不错的情况下继续做 refine。
Google 当前的图片文档在这方面其实写得不错。它不只是演示“生成一张图”,还明确鼓励 multi-turn image editing,并给出在同一个会话里修改信息图文字的例子。这背后的重点不是示例本身,而是心智模型:Gemini 图片生成不是一个只返回像素的接口,它更像一个可以保留上下文的对话式图片系统。后续编辑可以继续依赖前一轮的有效结果,而不是每次都重新从零开始。
javascriptimport { GoogleGenAI } from "@google/genai"; import fs from "node:fs"; const ai = new GoogleGenAI({ apiKey: process.env.GEMINI_API_KEY }); const chat = ai.chats.create({ model: "gemini-3.1-flash-image-preview", config: { responseModalities: ["TEXT", "IMAGE"], }, }); await chat.sendMessage({ message: "Create a vibrant infographic that explains photosynthesis like a colorful kids cookbook.", }); const response = await chat.sendMessage({ message: "Update this infographic to be in Spanish. Do not change any other elements.", config: { responseModalities: ["TEXT", "IMAGE"], imageConfig: { aspectRatio: "16:9", imageSize: "2K", }, }, }); for (const part of response.candidates[0].content.parts) { if (part.inlineData) { fs.writeFileSync( "photosynthesis-es.png", Buffer.from(part.inlineData.data, "base64") ); } }
到这里,imageSize 与 aspectRatio 就不再是可有可无的 trivia。Gemini 3 图片模型的 官方文档 公开了 512、1K、2K、4K 四档尺寸,以及 16:9、9:16、21:9、4:1、1:4 等更宽的比例范围。这直接改变了你的代码应该怎么写。如果你做的是电商头图、横幅、广告位、社媒裁切或 App Store 素材,输出控制越明确,后面补裁切、补重绘、补人工修正的成本就越低。也正因为如此,很多“只改模型字符串就能迁移”的泛泛建议,对图片工作流其实没有什么帮助。
Pro 路线也应该在这里理解,而不是把它当作一个笼统的高级版。Google 当前的 pricing 页面 和 Gemini App 帮助页,从不同角度讲的是同一件事:Flash Image 是快、便宜、当前默认;Pro 是在文字质量、信息图、品牌成品、或者更高价值输出上更值得考虑的路线。也就是说,Pro 不应该是第一段示例里的默认模型,但当你的任务本身听起来像海报、图表、图文混排资产时,你就应该在代码层面尽早把它列入候选。
还有一个值得单独指出的能力边界。当前价格页把 Google Search grounding 和 image-based grounding 的成本单独列了出来,而图片文档也展示了 search-grounded 的视觉流程。这意味着某些高级图片工作流已经不再只是“prompt in,image out”。它们还能带着检索上下文去生成或修改图片。这很强,但绝对不是 day-one requirement。先把基础请求跑通,只有在产品真的需要时再引入 grounding。
定价、Batch 模式,以及什么时候值得上 Pro
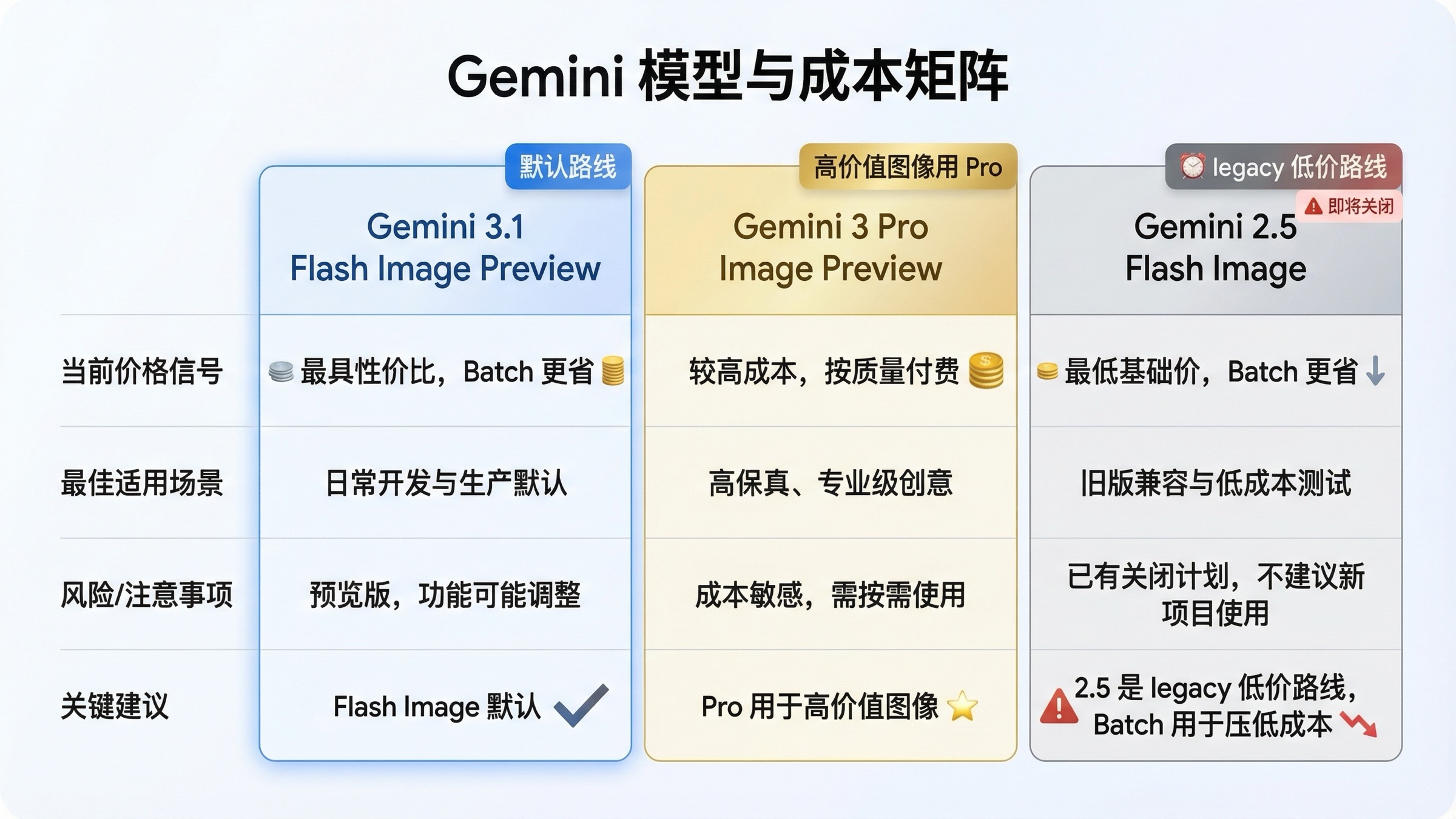
对代码示例文章来说,价格不该压倒一切,但也绝对不能不讲,因为模型选择和输出尺寸本身就是实现决策的一部分,而不是采购层面的附录。
Google 当前价格页给出的信号很明确。Gemini 3.1 Flash Image Preview 在标准模式下,0.5K 大约 $0.045,1K 大约 $0.067,2K 大约 $0.101,4K 大约 $0.151。同一页里,Gemini 3 Pro Image Preview 大约是 1K / 2K $0.134,4K $0.24。对于 legacy 的 Gemini 2.5 Flash Image,官方仍然列着标准模式约 $0.039、Batch 约 $0.0195。这几行不只是财务信息,它们直接决定了你在教程里应该把谁当成默认示例。
| 模型 | 当前状态 | 当前官方价格信号 | 最适合什么代码场景 | 需要提醒什么 |
|---|---|---|---|---|
gemini-3.1-flash-image-preview | 当前默认路线,发布于 2026 年 2 月 26 日 | 0.5K 约 $0.045,1K 约 $0.067,2K 约 $0.101,4K 约 $0.151 | 大多数新项目的默认起点 | 仍然带 preview 标记,配额通常比稳定文本模型更紧 |
gemini-3-pro-image-preview | 当前 premium 路线,发布于 2025 年 11 月 20 日 | 1K / 2K 约 $0.134,4K 约 $0.24 | 信息图、重文本海报、更贵的品牌成品 | 价格跳升明显,不要无条件当默认 |
gemini-2.5-flash-image | legacy 低价路线,关闭时间已确定 | 标准约 $0.039,Batch 约 $0.0195 | 对成本极敏感、又接受 retirement 风险的旧流程 | 2026 年 10 月 2 日 会关闭,不是未来默认路线 |
那什么时候 Pro 真的值得?最简单的判断是:如果图片失败一次的代价,已经高于模型差价,Pro 才值得认真考虑。典型例子包括信息图、海报、图中带大量文字的营销素材、以及你已经知道 Flash Image 在这个任务上反复返工也很贵的场景。反过来说,如果你做的是快速尝试、资产变体、批量探索,或者更关心吞吐和预算,那么 Flash Image 仍然是更好的默认路线。
第二个会改变架构的价格相关决策,是 Batch。Google 价格页已经把经济性讲得足够清楚:如果你的图片任务量很大,而且允许延迟返回,那么 Batch 往往能明显降低成本,尤其是在 legacy 2.5 线和 Flash Image 线。它不会改变你第一段示例代码的核心形状,但它会改变你从“本地脚本”走向“计划任务和积压任务”时的建议。
这里也必须诚实地对待 2.5 图片线。它仍然有用,仍然官方支持,也仍然更便宜。但如果你今天要写一篇新的代码示例文章,就必须明确告诉读者:这是一个带着退场倒计时的低价 legacy 分支,而不是未来两年都最值得下注的默认路径。要继续深挖价格、免费层与 API 成本,下一步更该读的是 Gemini 图片生成价格指南 与 Gemini 图片 API 免费额度。
故障排查:Gemini 图片生成代码示例里最常见的错误
第一个错误,是直接复制旧的 2.5 图片教程,然后默认它仍然代表当前最佳起点。现在已经不是这样了。当前文档、价格页和发布信息,都把开发者的默认路线推向 Gemini 3 图片线。你如果还在用 gemini-2.5-flash-image,应该是因为你明确选择了 legacy 低价路线,而不是因为搜索结果把你带到了旧世界。
第二个错误,是把 App、AI Studio、Gemini API 当成一个统一产品契约。它们不是。Gemini Apps 帮助页适合理解 Nano Banana 2 与 Nano Banana Pro 在消费级入口里的行为;AI Studio 适合调 prompt;但真正决定你代码怎么写、怎么记日志、怎么判断付费 key 与 quota 的,是 API 契约。Google 的 billing 页面、launch post 与 image docs 都已经足够说明这一点。
第三个错误,是不显式写图片控制。如果你在意输出比例,就设置 aspectRatio;如果你在意输出大小,就设置 imageSize。不要假设默认值正好适合你的产品。Google 的 image docs 明确说,如果不指定,模型可能会沿用输入图大小,或者生成默认正方形输出。实验时这可以接受,但生产里通常不够好。
第四个错误,是把图片生成当成一次性 endpoint,而不是把它看成多轮编辑工作流。Gemini 当前的图片能力,在保留上下文、对已有结果继续 refine 时往往最好用。如果第一轮已经对了大半,保留对话上下文通常比把 prompt 写得越来越长更快、更稳,也更便宜。
第五个错误,是忽略项目级配额。Google 的 rate limits 页面 明确写着限制是按 project 生效,而不是按 API key 生效;requests per day 则按 Pacific time 午夜重置。这也是为什么很多开发者明明感觉“今天没怎么用”,却还是会撞到 429。真正该做的,不是背某一张截图里的神奇数字,而是把 quota 看作项目状态,并在 AI Studio 或 Google 控制面中确认它。
第六个错误,是把“最便宜的一行”误当成“最值得当默认示例的一行”。在 Gemini 图片能力的早期阶段,这样想还勉强说得过去;但到 2026 年,这样写教程已经不够负责。对新读者最合理的顺序应该是:先教当前默认,再解释 legacy 成本分支,最后再谈 premium Pro 分支。这样能帮读者先做出正确的起步判断,而不是过早优化。
第七个错误,是忘了所有生成图片都带有 SynthID watermark。它不一定会破坏你的工作流,但它是产品特性的一部分,一篇认真面向实现的文章就应该说出来,而不是让读者上线以后才发现。如果你真正卡住的不是“该复制哪段代码”,而是“为什么今天又限额了”“免费和付费到底差在哪里”,那么更应该继续看 Gemini 图片额度何时重置 和 Gemini 图片免费额度。
结论
2026 年最好的 Gemini 图片生成代码示例,不是最花哨的那一段,而是最能帮你做出下一个实现决策的那一段。
先从原生 Gemini API 开始。对大多数新工作流来说,默认先用 gemini-3.1-flash-image-preview。先在 JavaScript、Python 或 cURL 里真的保存出一张图,再加别的东西。只要输出形状开始重要,就显式加上 aspectRatio 和 imageSize。只有当图片里文字很多、信息图密度很高、或者失败成本明显升高时,再把 gemini-3-pro-image-preview 拉进默认路线。至于 gemini-2.5-flash-image,把它当作便宜但带退场时间的 legacy 分支,而不是未来默认答案。
一旦你在最前面把这些路线判断做对,后面的实现通常会清晰很多。真正难的地方往往不是代码本身,而是在搜索结果、旧教程和产品表面差异都很混杂的时候,仍然能先相信正确、当前、而且适合自己工作流的那条路。