
Gemini 3 是 Google 于 2025 年底发布的最新旗舰 AI 模型系列,分为推理能力强大的 Pro 版本和响应速度极快的 Flash 版本。对于开发者和企业用户来说,了解 Gemini 3 API 的定价结构和配额限制是做出技术选型决策的关键一步。本文将基于 Google AI Studio 官方数据(2026-02-04 验证),为你提供 Gemini 3 API 价格与配额的完整解析,帮助你在预算范围内最大化 AI 能力的使用价值。
Gemini 3 API 概述
Google 在 AI 模型领域的布局一直以来都强调多模态能力和长上下文处理,而 Gemini 3 则将这两个特点推向了新的高度。作为 Google DeepMind 的最新成果,Gemini 3 不仅延续了前代产品在多模态理解方面的优势,还在推理深度和响应效率上实现了显著提升。
Gemini 3 API 目前通过 Google AI Studio 和 Vertex AI 两个渠道提供服务。Google AI Studio 面向个人开发者和小型团队,提供免费层和按量付费选项;Vertex AI 则针对企业级用户,提供更完善的安全合规和服务保障。两个渠道的定价策略基本一致,但在配额限制和企业功能上存在差异。
从技术架构角度看,Gemini 3 引入了 thinking_level 参数来控制模型的推理深度,这意味着开发者可以根据任务复杂度动态调整模型的"思考强度",在推理质量和响应速度之间找到平衡点。同时,Gemini 3 支持高达 1M tokens 的上下文窗口,这为处理长文档、代码库分析和多轮对话等场景提供了充足的空间。目前 Gemini 3 处于 Preview 阶段,部分功能和定价可能在正式发布时有所调整。
Gemini 3 完整价格详解

理解 Gemini 3 的定价结构需要关注几个关键维度:模型版本(Pro vs Flash)、上下文长度(≤200K vs >200K)以及输入输出类型(文本、图片、音视频)。Google 采用了阶梯式定价策略,上下文长度超过 200K tokens 后价格会相应提高,这与长上下文处理所需的额外计算资源成本相关。
Gemini 3 Pro 定价
Gemini 3 Pro 是面向复杂推理任务的旗舰模型,其定价反映了其强大的能力。根据 Google AI Studio 官方定价页(2026-02-04 验证),Gemini 3 Pro 的具体价格如下:
| 计费项目 | ≤200K tokens 上下文 | >200K tokens 上下文 |
|---|---|---|
| 输入价格(每百万 tokens) | $2.00 | $4.00 |
| 输出价格(每百万 tokens) | $12.00 | $18.00 |
| Google 搜索工具 | $35.00 / 千次请求 | $35.00 / 千次请求 |
Gemini 3 Pro 目前没有免费层,所有 API 调用都需要关联付费结算账号。这一策略与 Pro 模型定位于生产级应用和企业场景相符,确保了服务质量和资源的稳定供应。
Gemini 3 Flash 定价
Gemini 3 Flash 是针对高频、低延迟场景优化的模型,在保持良好性能的同时大幅降低了使用成本。Flash 模型的定价策略更加亲民,并且提供了慷慨的免费层:
| 计费项目 | 免费层 | 付费层(每百万 tokens) |
|---|---|---|
| 文本输入 | ✅ 支持 | $0.50 |
| 文本输出 | ✅ 支持 | $3.00 |
| 音频/视频输入 | ✅ 支持 | $3.00 |
| 图片输入 | ✅ 支持 | 按 token 计费 |
从价格对比来看,Gemini 3 Flash 的输入价格仅为 Pro 的 25%,输出价格也只有 Pro 的 25%,对于大多数不需要极致推理能力的应用场景来说,Flash 提供了极具竞争力的性价比。
Gemini 3 Pro Image 定价
除了文本处理能力,Gemini 3 还提供了图像生成功能,内部代号为 Nano Banana Pro。图像生成采用独立的定价体系,按图片尺寸和复杂度计费:
| 图片操作 | 价格(美元) | 等效 tokens |
|---|---|---|
| 图片输入 | $0.0011/张 | 约 560 tokens |
| 图片输出(1K-2K 尺寸) | $0.134/张 | 约 1,120 tokens |
| 图片输出(最大 4K 尺寸) | $0.24/张 | 约 2,000 tokens |
成本计算示例
为了帮助你更好地预估实际使用成本,这里提供几个典型场景的成本计算:
场景一:智能客服对话 假设平均每轮对话输入 500 tokens、输出 200 tokens,使用 Gemini 3 Flash,每天处理 10,000 轮对话。月度成本计算:输入成本 = 500 × 10,000 × 30 / 1,000,000 × $0.50 = $75;输出成本 = 200 × 10,000 × 30 / 1,000,000 × $3.00 = $180;总计约 $255/月。
场景二:长文档分析 使用 Gemini 3 Pro 分析一份 150K tokens 的技术文档,生成 2,000 tokens 的摘要报告。单次成本 = 150,000 / 1,000,000 × $2.00 + 2,000 / 1,000,000 × $12.00 = $0.30 + $0.024 = $0.324。
场景三:代码生成与审查 开发团队使用 Gemini 3 Pro 进行代码生成,每天平均输入 50K tokens 的上下文和需求描述,输出 20K tokens 的代码。月度成本 = (50,000 × $2 + 20,000 × $12) / 1,000,000 × 30 = $10.20/月。
配额限制与使用层级
配额限制是 Gemini 3 API 使用中最容易被忽视但又至关重要的因素。Google 采用了分层配额体系,根据用户的付费历史和使用规模,提供不同级别的资源访问权限。了解这些限制可以帮助你更好地规划应用架构和资源分配。
使用层级说明
Google 将 API 用户分为四个使用层级,每个层级对应不同的配额上限:
| 层级 | 资格条件 | 适用场景 |
|---|---|---|
| 免费层 | 符合条件的国家/地区用户 | 学习测试、原型开发 |
| 第 1 层级 | 关联付费结算账号 | 小规模生产应用 |
| 第 2 层级 | 累计消费 >$250 且 ≥30 天 | 中等规模应用 |
| 第 3 层级 | 累计消费 >$1,000 且 ≥30 天 | 大规模生产部署 |
层级升级不需要手动申请,系统会根据你的消费记录自动调整。但需要注意的是,层级升级有 30 天的等待期,因此在规划大规模部署时需要提前做好准备。
配额维度解释
Gemini 3 API 的配额限制涉及三个核心维度,每个维度都可能成为使用瓶颈:
RPM(Requests Per Minute) 表示每分钟允许的请求数量,这个限制主要影响高并发场景。如果你的应用需要同时处理大量用户请求,RPM 可能成为首要瓶颈。
TPM(Tokens Per Minute) 表示每分钟允许处理的 token 总量,包括输入和输出。对于处理长文档或生成长内容的应用,TPM 限制可能比 RPM 更关键。
RPD(Requests Per Day) 表示每天允许的总请求数,这是一个累积限制。即使 RPM 和 TPM 都满足要求,超过 RPD 后当天将无法继续调用 API。
各模型配额对比
根据 Google AI Studio 官方文档,以下是不同模型在各层级的配额限制(数据来源:Google AI Studio Rate Limits 页面,2026-02-04 验证):
Gemini 3 Pro 配额:
| 层级 | RPM | TPM | RPD |
|---|---|---|---|
| 第 1 层级 | 1,000 | 4,000,000 | 10,000 |
| 第 2 层级 | 2,000 | 8,000,000 | 50,000 |
| 第 3 层级 | 4,000 | 16,000,000 | 100,000 |
Gemini 3 Flash 配额:
| 层级 | RPM | TPM | RPD |
|---|---|---|---|
| 免费层 | 15 | 1,000,000 | 1,500 |
| 第 1 层级 | 2,000 | 4,000,000 | 10,000 |
| 第 2 层级 | 4,000 | 8,000,000 | 50,000 |
| 第 3 层级 | 10,000 | 16,000,000 | 无限制 |
从配额数据可以看出,Flash 模型在免费层的 RPM 限制较为严格(仅 15 RPM),但 TPM 限制相对宽松(100 万 tokens/分钟),适合处理少量但内容较长的请求。升级到付费层后,配额会有显著提升。
如何查看当前配额
在 Google AI Studio 中,你可以通过以下步骤查看当前的配额使用情况:进入 AI Studio 控制台,点击左侧菜单的"配额"选项,系统会显示每个模型的当前层级、已用配额和剩余额度。对于 Vertex AI 用户,配额信息则需要在 Google Cloud Console 的 IAM 与管理部分查看。
Pro vs Flash 怎么选
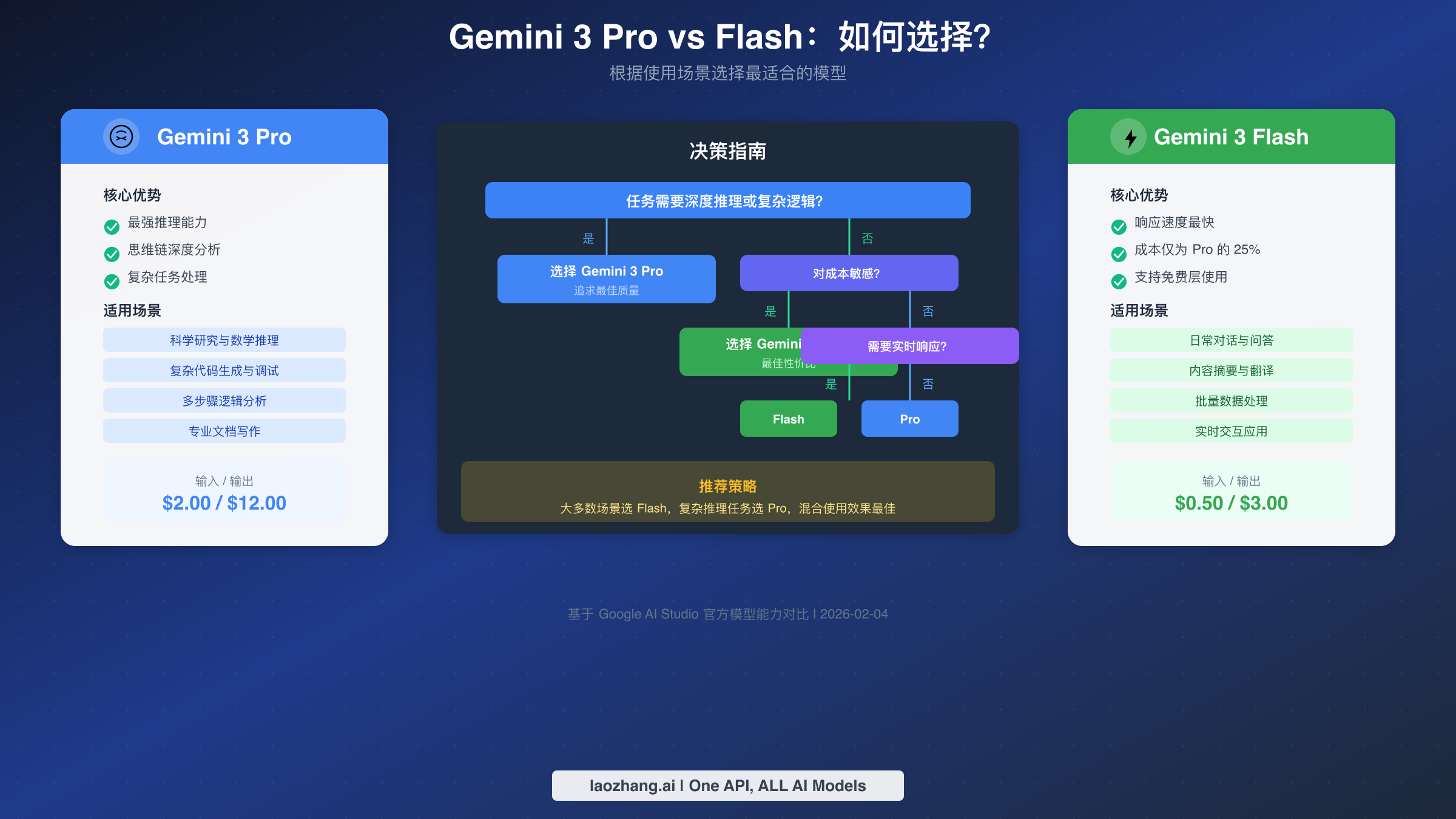
选择 Gemini 3 Pro 还是 Flash 是开发者最常面临的决策问题。两个模型在能力、价格和配额方面都存在显著差异,正确的选择可以帮助你在保证质量的同时大幅降低成本。
能力对比
Gemini 3 Pro 的核心优势在于深度推理能力。它在处理数学问题、逻辑分析、代码生成和复杂指令理解方面表现出色。Pro 模型支持更精细的 thinking_level 控制,可以通过增加"思考深度"来提升复杂任务的完成质量。在基准测试中,Pro 模型在 MATH、HumanEval 和 MMLU 等评测集上的得分明显高于 Flash。
Gemini 3 Flash 则优化了响应速度和成本效率。它的首 token 延迟(TTFT)比 Pro 低 40-60%,整体推理速度也更快。虽然在极端复杂的推理任务上不如 Pro,但对于日常对话、内容摘要、简单代码补全等场景,Flash 的输出质量完全可以满足需求。
价格与性能比
从性价比角度分析,Flash 模型的优势非常明显。完成同样的任务,Flash 的成本仅为 Pro 的约 25%。如果你的应用场景不涉及复杂推理,使用 Flash 可以节省 75% 的 API 费用。
但价格不是唯一考量因素。如果任务完成质量对业务至关重要,Pro 模型带来的质量提升可能值得额外的投入。例如,在法律文档分析或医疗诊断辅助等高风险场景中,Pro 模型更高的准确率可以降低后续人工审核的成本。
场景推荐矩阵
基于能力特点和成本考量,以下是不同使用场景的模型推荐:
| 使用场景 | 推荐模型 | 原因 |
|---|---|---|
| 日常对话与问答 | Flash | 响应快、成本低 |
| 内容摘要与翻译 | Flash | 任务简单,Flash 足够 |
| 数学和科学推理 | Pro | 需要深度逻辑分析 |
| 复杂代码生成 | Pro | 代码质量要求高 |
| 多模态内容理解 | Flash | 两者能力接近,Flash 更经济 |
| 长文档分析 | Pro | 需要理解复杂上下文关系 |
| 批量数据处理 | Flash | 大量请求时成本敏感 |
| 实时交互应用 | Flash | 延迟要求严格 |
实际应用中,最佳策略往往是混合使用两个模型。可以先用 Flash 处理初步筛选和简单任务,再将需要深度分析的内容转交给 Pro 处理,这样既保证了质量又控制了成本。
成本优化实战指南
掌握 Gemini 3 的成本优化技巧可以显著降低 API 使用费用。Google 提供了多种官方的成本优化机制,合理利用这些机制可以在保持服务质量的同时大幅削减开支。
Context Caching 详解
Context Caching(上下文缓存)是 Gemini 3 最强大的成本优化工具,可以节省高达 90% 的输入 token 费用。它的工作原理是将频繁使用的上下文内容缓存在服务端,后续请求引用缓存内容时只需支付极低的缓存读取费用,而不是重新计算全部输入 token。
Context Caching 特别适合以下场景:需要反复分析同一份长文档的应用,如法律文档审查系统;使用固定系统提示词的聊天机器人;需要持续参考知识库内容的问答系统。要启用 Context Caching,你需要在创建缓存时指定缓存内容和过期时间,然后在后续请求中通过 cached_content 参数引用该缓存。
缓存的存储费用按小时计算,因此需要根据使用频率决定缓存时长。如果某段内容每小时被调用数十次,长时间缓存是划算的;如果调用频率较低,短期缓存或不使用缓存可能更经济。
Batch API 使用指南
Batch API(批量处理接口)提供 50% 的价格折扣,代价是放弃实时响应能力。批量请求会在系统资源空闲时处理,通常在提交后 24 小时内完成。这种模式非常适合不需要即时结果的任务,如日志分析、内容审核、批量翻译等。
使用 Batch API 时需要注意几点:首先,批量作业没有严格的 SLA 保证,处理时间可能波动;其次,单个批量作业有请求数量上限;最后,批量请求的错误处理需要额外的逻辑,因为你无法在请求失败时立即重试。
中转平台选择
对于国内开发者来说,直接访问 Google API 可能面临网络稳定性问题。API 中转平台提供了一个可靠的替代方案,它们通过在海外部署代理节点,将 API 请求转发到 Google 服务器,同时提供稳定的国内访问接口。
选择中转平台时需要关注几个因素:价格是否与官方一致或更优惠、响应延迟是否可接受、是否支持所有 Gemini 3 功能、以及平台的稳定性和技术支持质量。像 laozhang.ai 这样的平台不仅提供 Gemini API 的稳定访问,还聚合了 Claude、GPT-4o 等主流模型的 API,方便开发者在一个平台上管理多个 AI 服务。API 文档可参考:https://docs.laozhang.ai/
成本监控最佳实践
有效的成本监控是避免账单意外的关键。建议在项目初期就建立完善的监控体系:设置每日和每月的预算告警阈值;记录每个功能模块的 API 调用量和费用;定期分析调用模式,识别优化机会;使用 token 计数器在请求前预估成本。
Google Cloud 提供了内置的预算告警功能,可以在费用达到预设阈值时发送通知。对于更精细的成本分析,可以在应用层面记录每次 API 调用的 token 数量和费用,生成详细的成本报告。
与 Claude/GPT-4o 价格对比
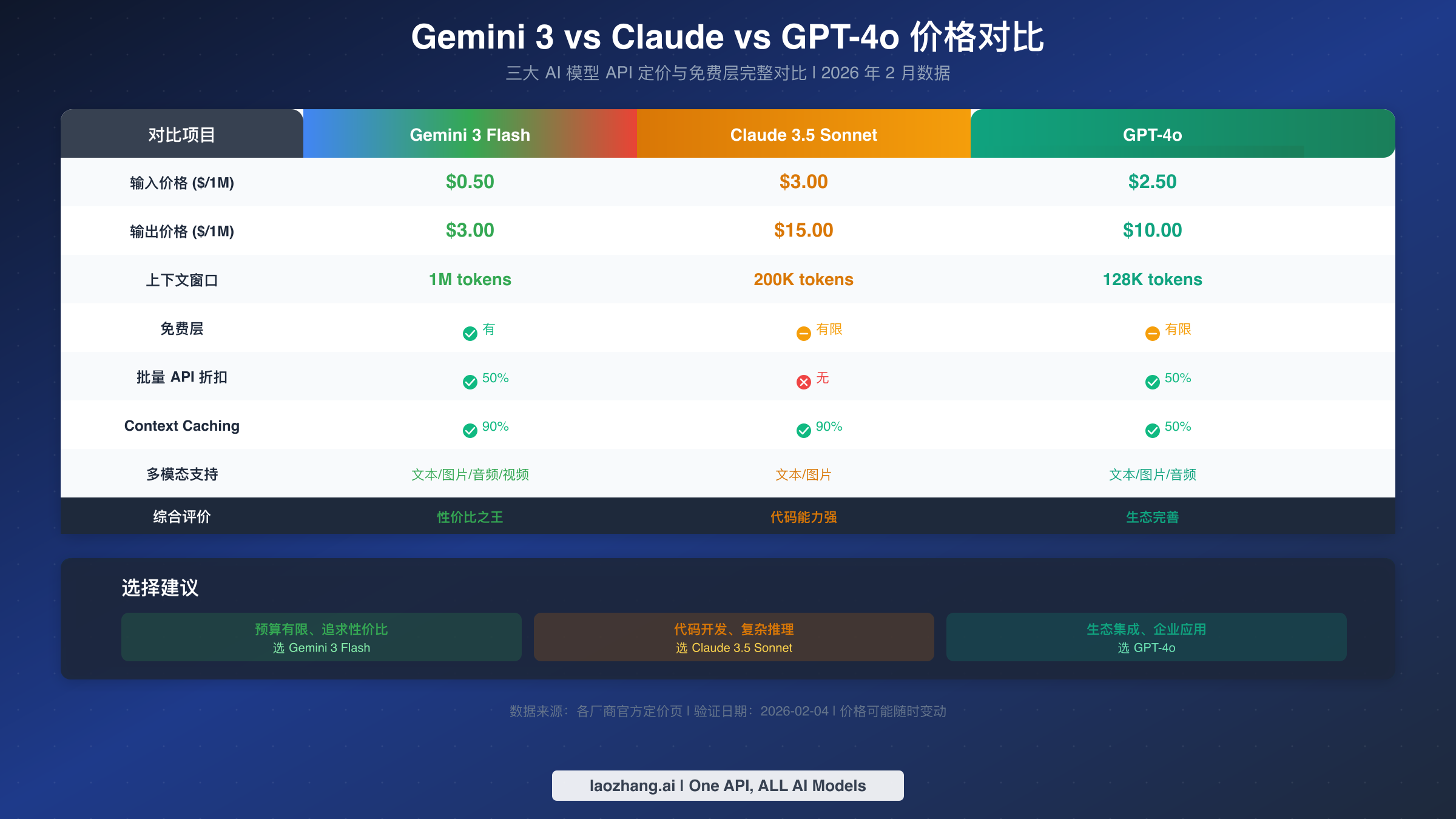
在选择 AI API 服务时,了解市场上主流模型的价格差异可以帮助你做出更明智的决策。这里将 Gemini 3 Flash 与 Anthropic Claude 3.5 Sonnet 和 OpenAI GPT-4o 进行对比,这三个模型在能力上处于同一梯队,是目前最受欢迎的 AI API 选择。
价格直接对比
| 对比项 | Gemini 3 Flash | Claude 3.5 Sonnet | GPT-4o |
|---|---|---|---|
| 输入价格($/1M) | $0.50 | $3.00 | $2.50 |
| 输出价格($/1M) | $3.00 | $15.00 | $10.00 |
| 上下文窗口 | 1M tokens | 200K tokens | 128K tokens |
| 免费层 | ✅ 有 | ⚠️ 有限 | ⚠️ 有限 |
| Batch 折扣 | 50% | 无 | 50% |
| 缓存折扣 | 90% | 90% | 50% |
从纯价格角度看,Gemini 3 Flash 的定价最具竞争力,输入价格仅为 Claude 的六分之一、GPT-4o 的五分之一。输出价格方面,Gemini 3 Flash 也是最低的,只有 Claude 的五分之一、GPT-4o 的 30%。
免费层对比
三大平台的免费层策略各有特点。Gemini 3 Flash 的免费层最为慷慨,提供每分钟 15 次请求和每天 1,500 次请求的配额,对于个人开发者和学习测试来说已经相当充足。Claude 和 GPT-4o 的免费层限制更严格,主要通过网页聊天界面提供,API 访问通常需要付费。
各自优势场景
虽然 Gemini 3 Flash 在价格上占优,但不同模型在特定任务上各有擅长。Gemini 3 Flash 在多模态处理(支持音频、视频输入)和超长上下文(1M tokens)方面领先;Claude 3.5 Sonnet 在代码生成和长文本写作方面表现出色,其"Artifacts"功能对开发者特别友好;GPT-4o 拥有最成熟的生态系统,第三方工具和集成最为丰富,企业级功能也更完善。
对于预算敏感的项目,Gemini 3 Flash 是性价比最高的选择;对于代码密集型应用,Claude 3.5 Sonnet 可能值得额外投入;对于需要与现有工具链深度集成的企业应用,GPT-4o 的生态优势可能更重要。使用 laozhang.ai 这样的聚合平台可以方便地在不同模型之间切换测试,找到最适合自己需求的方案。
常见问题与错误处理
在使用 Gemini 3 API 的过程中,配额相关的问题是开发者最常遇到的困扰。理解错误原因并掌握处理方法,可以帮助你构建更健壮的应用。
429 错误的原因与处理
HTTP 429 状态码表示"请求过多",是配额超限的标准响应。触发 429 错误的常见原因包括:RPM 超限(短时间内请求过于密集)、TPM 超限(处理的 token 总量超过限制)、RPD 超限(当天总请求数达到上限)。
处理 429 错误的标准方法是实施指数退避重试策略。具体做法是:第一次重试等待 1 秒,第二次等待 2 秒,第三次等待 4 秒,以此类推,最大等待时间不超过 60 秒。同时,应该在响应头中检查 Retry-After 字段,如果存在则使用该值作为等待时间。
对于生产环境,建议在应用层面实现请求限流,主动控制请求频率在配额范围内,而不是依赖 429 错误后的被动重试。可以使用令牌桶算法或滑动窗口算法实现平滑的请求限流。
配额超限的应对策略
当配额限制成为业务瓶颈时,有几种应对策略可以考虑。首先,确认当前的使用层级并评估是否可以通过增加消费来升级层级,层级升级后配额会有显著提升。其次,优化应用架构,使用 Context Caching 减少重复的 token 消耗,合并相似请求以减少总请求数。
对于 RPD 超限的情况,可以考虑创建多个 Google Cloud 项目,每个项目都有独立的配额。但需要注意的是,这种做法应该在 Google 服务条款允许的范围内使用,滥用可能导致账号被限制。
计费常见问题
开发者经常对计费细节存在疑问。首先,关于免费层数据使用,Google 明确表示免费层的 API 调用数据可能用于模型改进,而付费层的数据则受到更严格的隐私保护。其次,关于 token 计算,Gemini 使用的 tokenizer 与 GPT 系列不同,同样的文本在不同模型上的 token 数可能有差异,建议在成本预估时使用 Google 官方提供的 token 计数工具。
另一个常见问题是关于 thinking tokens 的计费。当使用 thinking_level 参数增强推理深度时,模型生成的"思考过程"也会计入输出 token,这部分内容通过 thought_signatures 字段返回。在成本敏感的场景下,需要权衡思考深度与费用支出。
总结与下一步
通过本文的详细解析,你应该已经对 Gemini 3 API 的价格体系和配额限制有了全面的了解。简单回顾核心要点:Gemini 3 Pro 定价 $2/$12(输入/输出,每百万 tokens),无免费层,适合复杂推理任务;Gemini 3 Flash 定价 $0.50/$3,有慷慨的免费层,是大多数场景的性价比首选;善用 Context Caching 可节省 90% 输入成本,Batch API 可享 50% 折扣;配额通过使用层级管理,消费满足条件后自动升级。
对于不同类型的用户,这里给出针对性的建议。个人开发者和学习者可以充分利用 Gemini 3 Flash 的免费层进行探索和原型开发,在需要深度推理时临时切换到 Pro 模型。初创团队和小型项目建议以 Flash 为主力模型,建立成本监控机制,在确认 ROI 后再逐步引入 Pro 模型处理高价值任务。企业级用户应该考虑通过 Vertex AI 获取更完善的企业功能和技术支持,同时评估 Context Caching 和 Batch API 的优化潜力。
如果你准备开始使用 Gemini 3 API,下一步可以访问 Google AI Studio 创建账号并获取 API Key,参考我们的 Gemini 3 API Key 获取指南 了解详细步骤。对于国内开发者,也可以考虑使用 laozhang.ai 等中转平台获得稳定的访问体验。无论选择哪种方式,希望本文提供的价格和配额信息能帮助你做出明智的技术决策。