
先说结论:截至 2026 年 3 月 19 日,Gemini 3.1 Pro 是上限更高的模型,但 Gemini 2.5 Pro 仍然是大量生产场景更稳的默认选择。 这并不矛盾,前提是你把 Google 官方页面放在一起看。Gemini 3.1 Pro 是更新的、强调推理与 Agent 的 Preview 模型;Gemini 2.5 Pro 则是已经 GA 的高能力模型,价格更低、保留免费层、运营不确定性更小。
所以真正的问题不是“纸面参数谁赢”,而是“要不要把 Gemini 2.5 Pro 全量替换,还是把它作为稳定默认盘,只把最难任务升级到 Gemini 3.1 Pro”。多数页面只给参数和榜单,却不给路由决策。本文反过来做:先给决策,再给证据。
要点速览
如果你只想看结论:当你的瓶颈是高难推理、Agent 编码、工具链复杂调用时,用 Gemini 3.1 Pro;当你要的是 GA 稳定性、较低 token 成本、免费层验证能力和更低生产波动时,用 Gemini 2.5 Pro。
2026 年 3 月 19 日的官方对比如下:
| 维度 | Gemini 3.1 Pro | Gemini 2.5 Pro | 含义 |
|---|---|---|---|
| 当前状态 | Preview | Generally available | 3.1 更新,但并不等于“所有生产场景都更安全” |
| Model ID | gemini-3.1-pro-preview | gemini-2.5-pro | 迁移要做显式路由,不能盲替换 |
| 免费层 | 无 | 有 | 2.5 Pro 更适合测试、预发和低风险实验 |
| 标准输入价格 | $2.00 / 1M(200k 以内) | $1.25 / 1M(200k 以内) | 3.1 输入成本高 60% |
| 标准输出价格 | $12.00 / 1M(200k 以内) | $10.00 / 1M(200k 以内) | 3.1 输出成本高 20% |
| 长提示价格 | 超过 200k:$4.00 in / $18.00 out | 超过 200k:$2.50 in / $15.00 out | 长提示场景差距依旧存在 |
| 上下文窗口 | 1M tokens | 1M tokens | 3.1 不占上下文上限优势 |
| 最大输出 | 64K tokens | 64K tokens | 3.1 也不占输出上限优势 |
| 最适合 | 高难 Agent 推理、复杂编码、前沿任务 | 稳定生产默认盘、成本敏感部署、免费层验证 | 3.1 适合做“高端车道”,不应默认全量替换 |
上表直接来自 Gemini Developer API pricing、Gemini API models、Vertex AI models、Gemini 3.1 Pro model card 以及官方 Gemini 2.5 Pro model card PDF。核心点是:Google 并不是让你为了“更大上下文”升级,因为两者都已经是 1M context + 64K output。真正差异在能力上限、价格结构和产品成熟度。
因此可执行建议很简单:
- 高难任务确实能显著减少人工返工时,才把流量路由到 Gemini 3.1 Pro。
- 日常编码与大盘流量,继续以 Gemini 2.5 Pro 为默认盘更稳更省。
- 能做路由就别单选:2.5 兜底,3.1 处理最难请求。
很多团队困惑的根源就在这里:新模型听起来像“全面升级”,但官方价格与状态页给出的其实是“高端车道”,不是“通用替代”。
2.5 Pro 到 3.1 Pro 到底变了什么
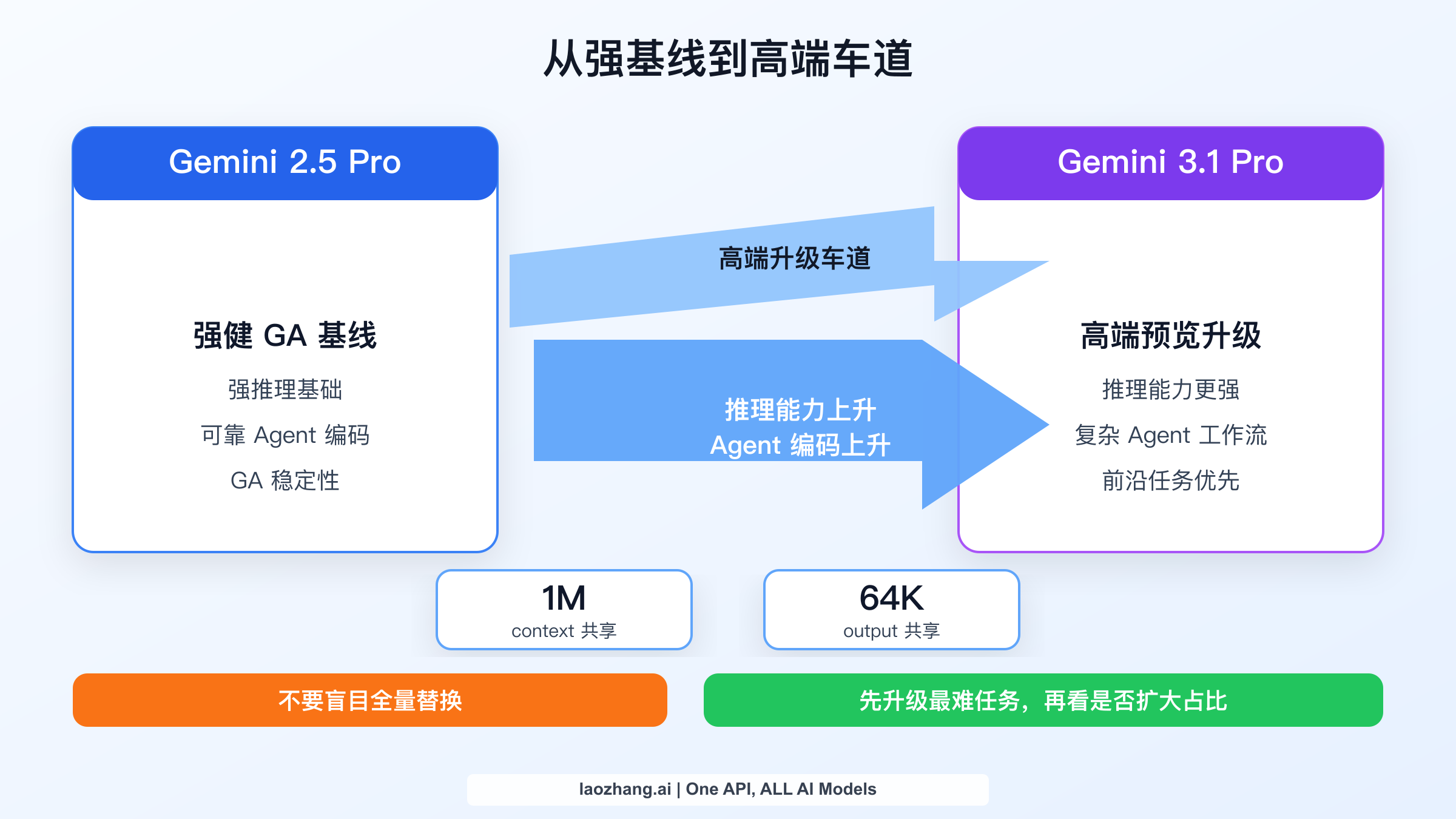
这组对比里最常见的误判,是把 2.5 到 3.1 理解成“更长上下文、更大输出、常规提速”。实际不是。变化更大的是 Google 对模型家族的定位。
在当前 Vertex AI models 页面 里,Gemini 3.1 Pro 位于 Preview 区,描述为面向复杂 Agent 工作流与编码的最新推理型模型;Gemini 2.5 Pro 位于 GA 区,描述为面向复杂推理和编码的高能力稳定模型。这个措辞非常关键:3.1 是前沿增量,2.5 是稳定基线。
Gemini 3.1 Pro 模型卡进一步强化了这个信号。它发布于 2026 年 2 月 19 日,明确 3.1 Pro 是当时 Google 最先进的复杂任务模型,并确认 1M context、64K output,以及在 Gemini app、Vertex AI、AI Studio、Gemini API、Google Antigravity、NotebookLM 等多渠道分发。
但较早的 Gemini 2.5 Pro 模型卡(2025 年 6 月 27 日更新)解释了为什么 2.5 仍难以被淘汰。它明确 2.5 Pro 已 GA,且同样给出 1M context 与 64K output。换句话说,很多团队升级 3.1 不是买更大上下文,而是为更高智能支付溢价。
再看 3.1 发布前 2.5 的最后一波官方叙事:Google 在 2025 年 5 月 6 日的文章 "Build rich, interactive web apps with an updated Gemini 2.5 Pro" 里重点强调了编码与 Web 应用生成能力、并引用 WebDev Arena 表现。这让 2.5 Pro 成为许多开发者心中的“实战基线”。所以当 3.1 出来时,它面对的不是弱前代,而是已经很能打的 2.5。
后文都应基于这个心智模型:
- Gemini 2.5 Pro 不是“旧且弱”;
- Gemini 3.1 Pro 不是“同价无痛升级”;
- 真正对比是:高端 Preview 车道 vs 稳定 GA 默认盘。
2026-03-19 的价格、免费层与模型状态

选型真正落地,关键在价格和状态,而不是口号。官方 Gemini Developer API pricing 在 2026 年 3 月 19 日给出的信息非常清晰。
Gemini 3.1 Pro Preview:
- 无免费层
- 200k 提示以内:输入
\$2.00/ 1M tokens - 200k 提示以内:输出
\$12.00/ 1M tokens - 200k 提示以上:输入
\$4.00、输出\$18.00 - Batch 价格约为标准价格 5 折
Gemini 2.5 Pro:
- 有免费层
- 200k 提示以内:输入
\$1.25/ 1M tokens - 200k 提示以内:输出
\$10.00/ 1M tokens - 200k 提示以上:输入
\$2.50、输出\$15.00 - Batch 价格约为标准价格 5 折
标准付费差距并不小:
- 输入成本:3.1 比 2.5 高 60%
- 输出成本:3.1 比 2.5 高 20%
- 免费层:3.1 直接没有
如果你是高价值、高难请求,3.1 的能力提升可能覆盖掉这部分溢价;但如果你跑的是日常编码辅助、大盘流量或预发验证,价格差和免费层缺失都会变成真实成本。
举一个可落地的月度例子:假设每月输入 5000 万 token、输出 1000 万 token,且大多在 200k 提示以内。
Gemini 2.5 Pro 约为:
- 输入:50 x $1.25 =
\$62.50 - 输出:10 x $10 =
\$100 - 合计:
\$162.50
Gemini 3.1 Pro 约为:
- 输入:50 x $2.00 =
\$100 - 输出:10 x $12 =
\$120 - 合计:
\$220
在这个样例里,成本增幅约 35%。而且这还没算上 2.5 免费层能承担的低量验证流量。
状态同样关键。Gemini API models 与 Vertex AI models 都在强调同一件事:3.1 仍是 Preview,2.5 已是 GA。Preview 不等于不能上生产,但确实意味着你要预留更多变化风险。
所以你该问的不是“3.1 我付不付得起”,而是“2.5 已覆盖主流任务时,3.1 的能力增益是否大到值得为 Preview 和更高成本买单”。很多业务流量下,答案仍然是“默认盘先用 2.5”;最难的推理任务才是 3.1 的价值区。
为什么 API 团队和 Gemini App 用户的结论不同
这个关键词之所以容易“搜着搜着变混乱”,是因为它把两类读者揉到了一起:一类在做 API 生产选型,另一类在看 Gemini App 里能不能选到某模型。两者相关,但不是一个决策问题。
Google 当前 SERP 也反映了这点。API 视角的核心页面是 pricing、models、Vertex AI models 与模型卡;App 视角则会出现 Gemini Apps limits and upgrades 这类支持文档,因为用户本质在问“我这个套餐能不能用、能用多少”。
对 API 团队,3.1 vs 2.5 的核心是五件事:
- 高难任务质量
- token 成本
- 免费层可用性
- 生产成熟度
- 缓存 / 批处理 / grounding 等工具侧经济性
对 Gemini App 用户,关注点更偏:
- App 里是否可见该模型
- 订阅等级是否解锁
- 使用频率限制
- 主观体验是否更好
这就是为什么“新模型更贵”这种一句话判断在 API 场景不够用。因为你实际付的,不止输入输出 token。
以 pricing 页面 为例,3.1 Pro Preview 除了本体更贵,周边能力也更贵。200k 提示以内:
- 3.1 Pro Preview context caching:
\$0.20/ 1M tokens - 2.5 Pro context caching:
\$0.125/ 1M tokens - 两者 storage 都是
\$4.50 / 1,000,000 tokens per hour
超过 200k 提示后:
- 3.1 context caching 升到
\$0.40 - 2.5 context caching 升到
\$0.25
如果你大量复用长上下文、超长 system prompt 或检索文档,这个差距会持续放大。它不是“主 token 之外可忽略的小头”。
Batch 也是类似逻辑。页面顶部写明 Batch 可降本 50%。对比 200k 提示以内的每模型表格:
- 3.1 Pro Preview Batch:输入
\$1.00,输出\$6.00 - 2.5 Pro Batch:输入
\$0.625,输出\$5.00
即使开了 Batch,3.1 仍是更贵车道。Batch 能同时降两边成本,但不会消除价格梯度。
grounding 成本也要细读。3.1 Pro Preview 目前写的是 Search/Maps grounding 每月前 5,000 prompts 免费,之后 \$14 / 1,000 search queries。2.5 Pro 写的是 grounding 1,500 RPD 免费,之后 Search \$35 / 1,000 grounded prompts、Maps \$25 / 1,000 grounded prompts。计费单位不完全一致,不能强行做假等价换算;但可以得出实操结论:一旦你重度依赖工具,选模型就会同步改变工具账单结构。
这也是为什么免费层比看上去更重要。对很多团队,免费层不是“省点试玩钱”,而是低成本保留验证车道:
- 预发 prompt 验证
- 新模板 A/B
- 低风险回归测试
- 路由变更的 smoke test
2.5 Pro 仍能承接这个角色,3.1 Pro Preview 不行。
所以成熟团队通常不会说“3.1 更强,直接全迁”。更常见的说法是:“2.5 继续做低摩擦验证和默认盘,3.1 作为高价值难题车道,以 ROI 证明自己。”
SERP 里支持文档的存在也在佐证这一点:很多用户真正缺的不是“再看一张榜单图”,而是“访问路径澄清”。App 用户在问可见性和套餐;API 团队在问成本和工程策略。两者只部分重叠。
拆开看以后,结论就清楚了:
- App 视角:新模型可用就试,按主观体验选。
- API 视角:默认盘与高端车道分离,价格与稳定性优先级更高。
后续分析都按 API 视角展开,因为这才是更严格、也更容易踩坑的生产决策。
基准测试:3.1 真正领先在哪里,哪里不能硬比
AI 对比最容易犯的错误,是把“方向性领先”写成“精确可比领先”。在这组对比里尤其如此:官方 Gemini 3.1 Pro 模型卡和官方 Gemini 2.5 Pro 模型卡,并不是同一日期、同一实验框架下的一张统一对照表。数字依旧有价值,但阅读方式必须保守。
两份官方模型卡给出的方向性结果如下:
| Benchmark | Gemini 3.1 Pro 官方值 | Gemini 2.5 Pro 官方值 | 安全解读 |
|---|---|---|---|
| Humanity's Last Exam | 44.4% | 21.6% | 3.1 在前沿推理上的提升信号很强 |
| GPQA Diamond | 94.3% | 86.4% | 3.1 在科学推理上有明显优势 |
| SWE-Bench Verified | 80.6% | 59.6% | 方向上 3.1 更强,但两卡并非同日统一评测 |
| Terminal-Bench 2.0 | 68.5% | 2.5 GA 卡未给出 | 3.1 明确强调 Agent 编码能力 |
| APEX-Agents | 33.5% | 2.5 GA 卡未给出 | 3.1 在长链 Agent 任务上更有优势信号 |
| Context / output | 1M / 64K | 1M / 64K | 3.1 在上限规格上无优势 |
最稳妥的结论是:Gemini 3.1 Pro 在 Google 官方叙事下,确实把前沿推理与 Agent 能力推到了更高水平;但你不应该把两份模型卡的每一行都当作“实验室级、无偏差的完美横比”。
即便保守解读,趋势仍很清晰。3.1 更适合:
- 多步骤、工具调用密集任务
- 难度足够高、推理链质量直接影响结果的任务
- 接近 Agent 编码而非普通补全的任务
- 首答失败代价很高、人工复核成本昂贵的任务
2.5 仍然更适合:
- 高质量但非前沿难题
- 大规模重复型请求
- 成本敏感场景
- 以稳定吞吐为目标的大盘流量
因此,基准测试的正确用途是“优化路由”,不是“推动全量替换”。如果你最难的 5% 请求价值极高,3.1 的溢价很可能划算;如果你 95% 都是稳定中等难度任务,2.5 的 GA 成熟度和价格优势仍非常有竞争力。
还要注意一个细节:两者都已是 1M context + 64K output,这让“能力差”比“规格差”更重要。你买的不是更大容器,而是更聪明的大脑。这会迫使你做更细粒度的任务分层。
延迟、长上下文与生产稳定性
官方页面能说明能力上限,但不能自动回答一个更关键的问题:在真实生产流量下,新模型到底有多稳定。
这也是 SERP 里官方文档之外还会出现社区摩擦帖的原因。例如 Google AI Developers Forum 线程 "Gemini 3 significantly worse thant 2.5 Pro at long context. Temperature likely to blame"。这类帖子不是官方规格,不应拿来当“平台定论”;但它能反映真实用户焦虑:很多人不是按发布会叙事评估模型,而是按“长提示实测是否稳定”来评估。
问题的关键在于:两份官方模型卡都写了 1M context 和 64K output。纸面相同,不代表体验相同。真正该问的是:
- 你的真实 prompt 分布下,谁更可预测?
- 谁更少触发高成本返工?
- 谁更少依赖复杂 fallback 逻辑?
- 谁能把“单次更贵”换成“整体更省人工”?
对不少团队来说,2.5 仍然是更稳答案,因为它已 GA 且更便宜。Preview 不等于不稳定,但足以让你在没有实测之前,避免把 3.1 直接推成全量默认盘。
这里也要区分 能力风险 和 产品风险。3.1 可能在最难任务上能力更强;2.5 往往在大盘部署上产品风险更低,因为它:
- 是 GA,不是 Preview
- 有免费层
- 成本更低
- 团队已有长期使用经验
因此,大规模场景最安全的打法通常是 渐进式分流 而非一次性替换:2.5 继续跑主路,3.1 只接最难请求。若 3.1 确实显著降低重试与复核,再逐步放量;反之,你不会为追新标签把整个系统带偏。
如果你已经深度使用 Google 生态,也建议同步看这些相关运维议题:
Gemini 3.1 Pro 输出上限详解、Gemini 3.1 Pro 超时问题排查、Gemini API 错误排查指南。很多时候,能否稳定生产,卡点不在“谁更聪明”,而在“谁更可运维”。
编码、Agent、研究、控成本分别该选谁
让这篇对比真正有用的方法,是停止追问“绝对赢家”,改为“按任务分配赢家”。
| 任务类型 | 更优默认盘 | 原因 |
|---|---|---|
| 日常编码辅助 | Gemini 2.5 Pro | 更便宜、GA、能力对主流编码场景已足够 |
| 高难 Agent 编码 | Gemini 3.1 Pro | 官方定位和基准趋势都指向更强 Agent 表现 |
| 研究型推理分析 | Gemini 3.1 Pro | 官方前沿推理信号更强,溢价更容易被价值覆盖 |
| 大规模长上下文处理 | 先 2.5,按需升级 3.1 | 同为 1M context,2.5 默认更省更稳 |
| 免费层实验验证 | Gemini 2.5 Pro | 3.1 没有免费层 |
| 广泛生产流量 | Gemini 2.5 Pro | GA 与成本优势更适合作为大盘默认 |
| 高阶兜底车道 | Gemini 3.1 Pro | 不必每个请求都用新模型,把它用在高价值边缘场景 |
对 个人开发者/小团队,最稳妥方案通常是:先用 2.5 做默认,保留 3.1 处理最难请求,等高端车道 ROI 跑出来再加权。
对 中大型工程团队,这会变成架构问题:如果你已经有路由层,3.1 做高智力车道、2.5 跑大盘非常自然。很多组织真正的坏决策不是“还在用旧模型”,而是“把所有流量都塞进更贵的 Preview 模型,无论是否必要”。
对 研究和评测驱动团队,3.1 值得更高权重;但也要看成本约束。更强不等于无限预算。
对 成本敏感生产,2.5 仍是极难替代的默认盘:GA、免费层、低单价三者叠加,让它在大多数请求的单位经济上更有优势。若你无法证明 3.1 能显著提升业务指标,2.5 仍是理性选择。
当你的问题不只是“二选一”,而是“如何在同一代码栈里做模型分流”,像 laozhang.ai 这类聚合网关会更相关,因为此时核心难点是流量治理、成本控制和故障回退,而不是单模型忠诚度。
把 3.1 提升为默认盘前,必须先测什么
读完对比后最常见的工程错误是:拿几条“高光 prompt”试了 3.1,感觉更聪明,就全量切默认。这不是严肃评估流程。这里的价格与成熟度差异,足以要求你用“运营者标准”做验证,而不是“体验者标准”。
先按业务价值拆任务桶。一个实用默认模板:
| 评测桶 | 常见样本 | 你真正要回答的问题 |
|---|---|---|
| 常规编码编辑 | 小改造、补测试、常规修 bug | 3.1 是否强到足以覆盖普遍流量的成本溢价? |
| 高难 Agent 编码 | 多步仓库修改、工具链联动修复、长执行链 | 3.1 是否显著减少首轮失败与人工复核? |
| 长上下文分析 | 大文档、长 transcript、多文件推理 | 上下文变复杂后,3.1 的优势是否仍稳定? |
| grounding / 工具调用 | 搜索增强回答、工具编排、外部检索 | 工具调用收益能否覆盖模型与 grounding 成本? |
| 成本敏感大盘流量 | 高频中等难度请求 | 是否有足够业务理由不把 2.5 作为默认盘? |
只测一个桶,结论通常会错。3.1 可能在“高难 Agent 桶”明显更优,但在“成本敏感大盘桶”完全不该做默认。
第二条原则:评估 可接受结果成本,不是只看“模型输出质量”。关键问题不是“哪条回答更好看”,而是“算上重试、修正、复核后,哪条链路更便宜地产出可用结果”。
至少跟踪这些指标:
- 首轮通过率
- 人工修正分钟数
- 重试率
- p95 延迟
- token 成本
- 缓存成本(若使用)
- grounding 成本(若使用)
- fallback 到其他模型/流程的比例
没有这些数据,你无法判断 3.1 在业务层面到底是“更贵”还是“更省”。更贵模型也可能更省总成本;更聪明模型也可能只在 3% 高难请求上有意义,却把其余 97% 流量都抬价。
这也是很多团队会遇到的现实:benchmark winner 不一定是 default winner。
为了减少偏差,比较条件应尽量固定:
- 在测试周期内冻结 prompt 模板。
- 两个模型使用同一工具集合。
- 在 API 允许范围内保持温度与推理配置一致。
- 用真实生产样本,不用公开玩具题。
- 简单任务和困难任务分桶统计,不做粗暴平均。
第 5 点最关键。混平均会把高难任务上的真实收益冲掉;反过来,只抽“英雄题”又会高估高端车道价值。两种都在误导决策。
第三条原则:要测 运营行为,不仅是“答对没答对”。因为两者都已经 1M/64K,真实差异会体现在:
- 是否更容易“一次成功”
- 多步工具链是否更稳
- 长上下文是否更少漂移
- 输出结构是否更易后处理
- 周级别表现是否可预测
这也是 Preview 风险的实质。Preview 完全可以上生产,但把 Preview 升为“全量默认盘”时,你同时也在放大变化风险,所以晋级门槛必须更高。
一个更稳的 3.1 晋级流程通常是:
- 收集过去 2 到 4 周的真实请求样本。
- 按任务类型和业务重要性打标签。
- 同样样本分别跑 2.5 与 3.1。
- 能盲评就做盲评。
- 质量与延迟一起看。
- 比较“每个可接受结果成本”,而不只比 token 单价。
- 连续观测足够长,避免“发布期光环”偏差。
如果流量体量足够,别停在离线测试。应做线上小流量对照:
- 2.5 保持默认盘;
- 只把最难切片流量导到 3.1;
- 对比业务指标;
- 只有在效果稳定时才扩容。
这跟产品定位是一致的:2.5 是稳定主路,3.1 是需要“以效果证明份额”的高端支路。
第四条原则:测 工具侧成本行为,不止测模型本体。若你的系统依赖长提示、缓存、Batch、grounding,升级决策本质上也是基础设施经济决策:
- caching 更贵时,3.1 仍是否划算?
- 异步任务里,Batch 能否保住毛利?
- grounding 单位成本在你的量级下是否可接受?
- 没有免费层会不会拖慢实验迭代?
这些问题会直接决定“谁应该升级”。高价值研究团队可能愿意为 3.1 付溢价;中等难度的大规模消费流量则往往更适合把 3.1 作为升级车道,而非默认盘。
第五条原则:在看结果前先定义晋级门槛,避免“结果导向改规则”。一个可执行门槛示例:
- 3.1 在高难桶上对 2.5 有显著且稳定提升;
- 延迟增幅仍在 SLA 预算内;
- 每个可接受结果成本在可接受溢价区间内;
- Preview 行为在多日/多周观测中稳定;
- 大盘桶若迁移,必须有明确业务收益;否则继续留在 2.5。
达标就升,未达标就保持专用车道。这同样是成功评估。评测的目标不是“强行迁移”,而是“让路由更聪明”。
实操中,一个非常稳妥的模式是:
- 按难度把请求分为 low / medium / high;
gemini-2.5-pro承担 low 和大部分 medium;- high 难度或高复核成本请求路由到
gemini-3.1-pro-preview; - 每周复盘高难桶,每月重评晋级规则。
这样可以拿到 3.1 的核心收益,同时避免把全系统绑到更贵的 Preview 模型上。
这一节只记一句话就够:不要拿好奇心给高端车道背书,要拿纠错预算给它背书。 只有当 3.1 在“最贵的错误场景”里持续降本增效,它才有资格成为更大范围默认盘。
迁移策略:全量替换、分流并行,还是继续留在 2.5
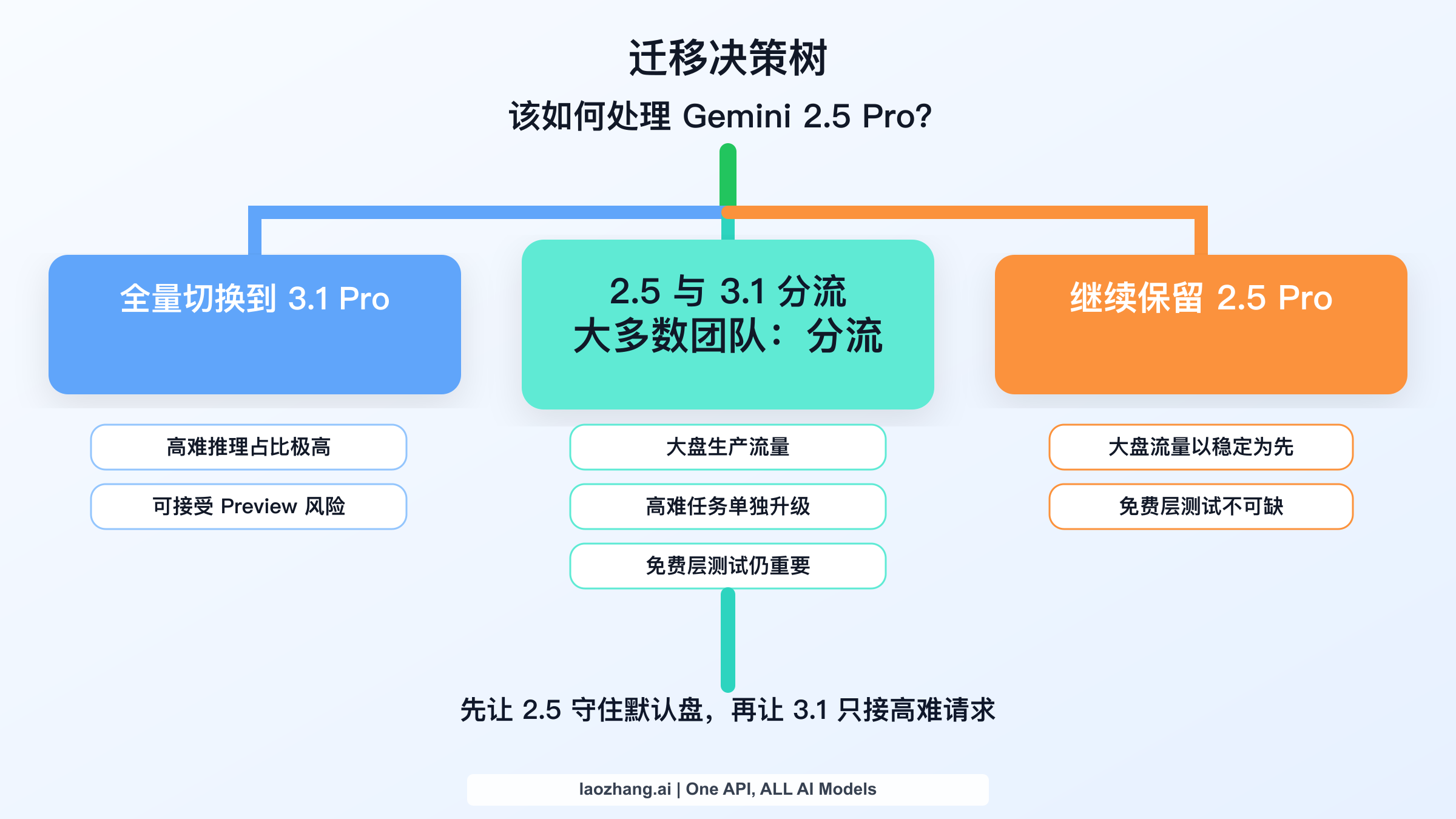
大多数团队最终会落到三种迁移模式之一。
模式 1:全量替换到 Gemini 3.1 Pro。 只在一种情况下成立:你的流量高度集中在高难推理/Agent 编码任务,且你愿意让 Preview 做默认盘。这是最激进路径;如果你还没做真实流量评测,翻车概率也最高。
模式 2:2.5 与 3.1 分流并行。 这是最通用、也最稳的答案。2.5 继续默认盘,满足以下任一条件时再升级到 3.1:
- 请求高价值,人工复核成本高;
- 2.5 的首轮失败率已经明显影响吞吐;
- 任务本质是多步 Agent,而不是单步问答;
- 对推理上限的需求明显高于成本约束。
一个简单路由策略就足够落地:
tsfunction chooseGeminiModel(task: { requiresAgenticCoding: boolean; reasoningDifficulty: "low" | "medium" | "high"; costSensitive: boolean; needsFreeTierFallback: boolean; }) { if (task.needsFreeTierFallback || task.costSensitive) { return "gemini-2.5-pro"; } if (task.requiresAgenticCoding || task.reasoningDifficulty === "high") { return "gemini-3.1-pro-preview"; } return "gemini-2.5-pro"; }
模式 3:暂时继续留在 2.5 Pro。 这不是“保守怕新技术”,而是当下最理性的工程决策:当前质量已达标、你依赖免费层验证、或者 3.1 的增益不足以转化为业务收益时,不迁移就是更优策略。模型升级只有在关键流程变好时才算“升级”。
最干净的迁移检查清单:
- 用你自己的真实 prompt 评测,不用公共样例替代。
- 同时跟踪输出质量和人工修正时间,不只看 token 单价。
- 在 3.1 证明稳定前,保留 2.5 fallback。
- 不要因为模型卡更亮眼就假设 3.1 必然全面更优。
- 只在“收益明确覆盖溢价与 Preview 风险”的场景提升 3.1 权重。
这五条就是本文核心:Gemini 3.1 Pro 需要“证据晋级”,而不是“按新旧标签晋级”。
FAQ
Gemini 3.1 Pro 一定比 Gemini 2.5 Pro 更好吗?
在高难推理和 Agent 任务上,按 Google 当前官方定位与 3.1 模型卡,通常是的;但如果你问“是否在所有生产维度都更好”,答案是否定的。2.5 仍更便宜、已 GA、且有免费层,因此在很多团队里依然是更好的默认盘。
Gemini 3.1 Pro 的上下文或输出上限更大吗?
不是。以 2026 年 3 月 19 日官方文档为准,两者都是 1M context 与 64K output。差异主要在模型能力上限、价格和成熟度,而不是规格上限。
Gemini 3.1 Pro 更贵吗?
是。官方 pricing 页面显示,3.1 在 200k 以内为输入 \$2.00、输出 \$12.00(每 1M tokens);2.5 在同区间为输入 \$1.25、输出 \$10.00,且保留免费层。
应该把所有流量从 2.5 全迁到 3.1 吗?
通常不建议。更稳方案是:2.5 继续跑大盘,3.1 只接最难请求。只有当 3.1 的能力提升在你的业务指标上持续兑现,且能覆盖更高成本与 Preview 风险时,才考虑扩大范围。
这些 benchmark 能做严格苹果对苹果比较吗?
不能完全这么说。它们是官方数据,但并非来自同一份统一、同日、同协议的完整对照文档。正确做法是“方向性解读 + 价格/状态/任务匹配联合判断”,而不是逐行做绝对结论。
这个对比对 App 用户和 API 用户同样重要吗?
不完全一样。App 用户更关心套餐可见性和模型选择器;API 用户更关心免费层、token 价格、Batch/grounding 成本和路由逻辑。本文重点放在 API 生产决策,同时保留了 App 访问路径的关键提醒。
一句话结论
如果你追求最强的高难推理和 Agent 工作流能力,选 Gemini 3.1 Pro。
如果你要稳定、可控、性价比更高的生产默认盘,选 Gemini 2.5 Pro。
如果你能做任务级路由,最优解通常是两者并用:2.5 跑大盘,3.1 接高难。