
Claude Opus 4.6 和 GPT-5.3-Codex 在同一天——2026 年 2 月 5 日——同时发布,这场正面交锋堪称自 2024 年初 GPT-4 挑战 Claude 3 以来最具影响力的 AI 模型对决。Anthropic 的新旗舰模型在推理基准测试中表现卓越,GPQA Diamond 获得 1606 Elo,tau-bench 准确率达到 91.9%;而 OpenAI 的编程专精模型则以 77.3% 的 Terminal-Bench 成绩在终端开发领域拔得头筹。但真正的关键不止于基准测试:定价策略、智能体工作流以及实际使用场景才是决定哪款模型更能满足你具体需求的核心因素。本指南提供经过验证的数据、成本优化分析以及具体的选型决策框架,帮助你做出最佳选择。
要点速览 — 快速结论
最简洁的总结:Claude Opus 4.6 是一款恰好在编程方面也很出色的通用型强大模型,而 GPT-5.3-Codex 则是一款为终端开发领域牺牲了广度的编程专精模型。两者都不是在所有维度上都"更好"——正确的选择完全取决于你的工作流。
五个最关键的差异:
- 推理深度:Opus 4.6 在 ARC-AGI 2 上得分 68.8%,而 GPT-5.2 为 54.2%——14.6 个百分点的差距意味着在复杂分析任务、科学研究和多步推理问题上有着显著的性能优势
- 终端编程:GPT-5.3-Codex 在 Terminal-Bench 2.0 上达到 77.3%,超出 Opus 4.6 的 65.4% 近 12 个百分点——这是所有基准类别中最大的差距,使 Codex 成为 CLI 密集型开发工作流的明确赢家
- 定价现实:Opus 标准价格为每百万 token 输入 $5/输出 $25,而 GPT-5.2 为 $1.75/$14,但 Opus 的 Batch API(五折优惠)和 Prompt Caching(输入成本降低 90%)大幅缩小了高用量用户的价格差距
- 上下文窗口:两者都提供 100 万 token 上下文,但 Opus 4.6 的版本处于 Beta 阶段,MRCR v2 长上下文检索准确率为 76%——这仍然是目前能力最强的长上下文实现
- 工作流范式:Opus 4.6 的 Agent Teams 支持多智能体协作(前端 + 后端 + 测试同时进行),而 Codex 的 CLI 集成提供原生终端体验并具备自动调试能力
快速推荐:研究、复杂分析、代码审查和全栈开发选择 Opus 4.6。DevOps、快速原型开发和以终端为中心的工作流选择 GPT-5.3-Codex。混合工作负载可以通过统一 API 同时使用两者。
2 月 5 日的正面对决 — 为什么这次对比至关重要
Claude Opus 4.6 和 GPT-5.3-Codex 于 2026 年 2 月 5 日同时发布,这标志着 AI 发展的一个关键时刻。这是 Anthropic 和 OpenAI 首次在完全相同的日期推出旗舰级竞争模型,迫使整个开发者社区立即进入评估周期。这并非巧合——两家公司一直在朝着相似的能力门槛竞赛,发布时机反映出前沿 AI 实验室之间的差距已经非常接近。
使这次对比格外微妙的是两者在定位上的根本差异。Anthropic 将 Opus 4.6 定位为其在所有维度上能力最强的模型——推理、编程、长上下文理解和智能体任务完成。该模型在 Artificial Analysis 综合排名中获得第一名(artificialanalysis.ai,2026 年 2 月),被多位评测者形容为"第一个能作为数字企业团队成员运作的模型"。其 Agent Teams 功能支持协调多个 AI 智能体同时处理项目的不同部分,代表着 AI 辅助开发的全新范式。
OpenAI 对 GPT-5.3-Codex 采取了不同的策略,全力聚焦于编程卓越性。该模型被描述为"最强大的智能体编程模型",专注于原生终端工作流、自动调试能力和交互式引导。值得注意的是,OpenAI 透露 GPT-5.3-Codex 是"第一个参与创建自身的模型"——这是 AI 辅助 AI 开发的一个里程碑。该模型比前代 GPT-5.2-Codex 快 25%,并引入了专为开发者工作流而非通用智能设计的功能特性。
理解这种定位差异对于理解后续的基准测试结果至关重要。当 every.to 的评测发现 Opus 在其 LFG 编程基准上得分 9.25/10,而 Codex 为 7.5/10 时,这个结果让许多人感到意外——他们原本预期编程专精模型会占据主导。原因在于复杂度:Opus 擅长需要深度推理的多文件、多步骤编程任务,而 Codex 则在快速终端执行场景中表现突出。关于上一代模型的对比情况,可以参考我们的上一代模型对比文章——这一代两者的差距已经明显缩小。
基准测试详解 — 数字背后的真实含义
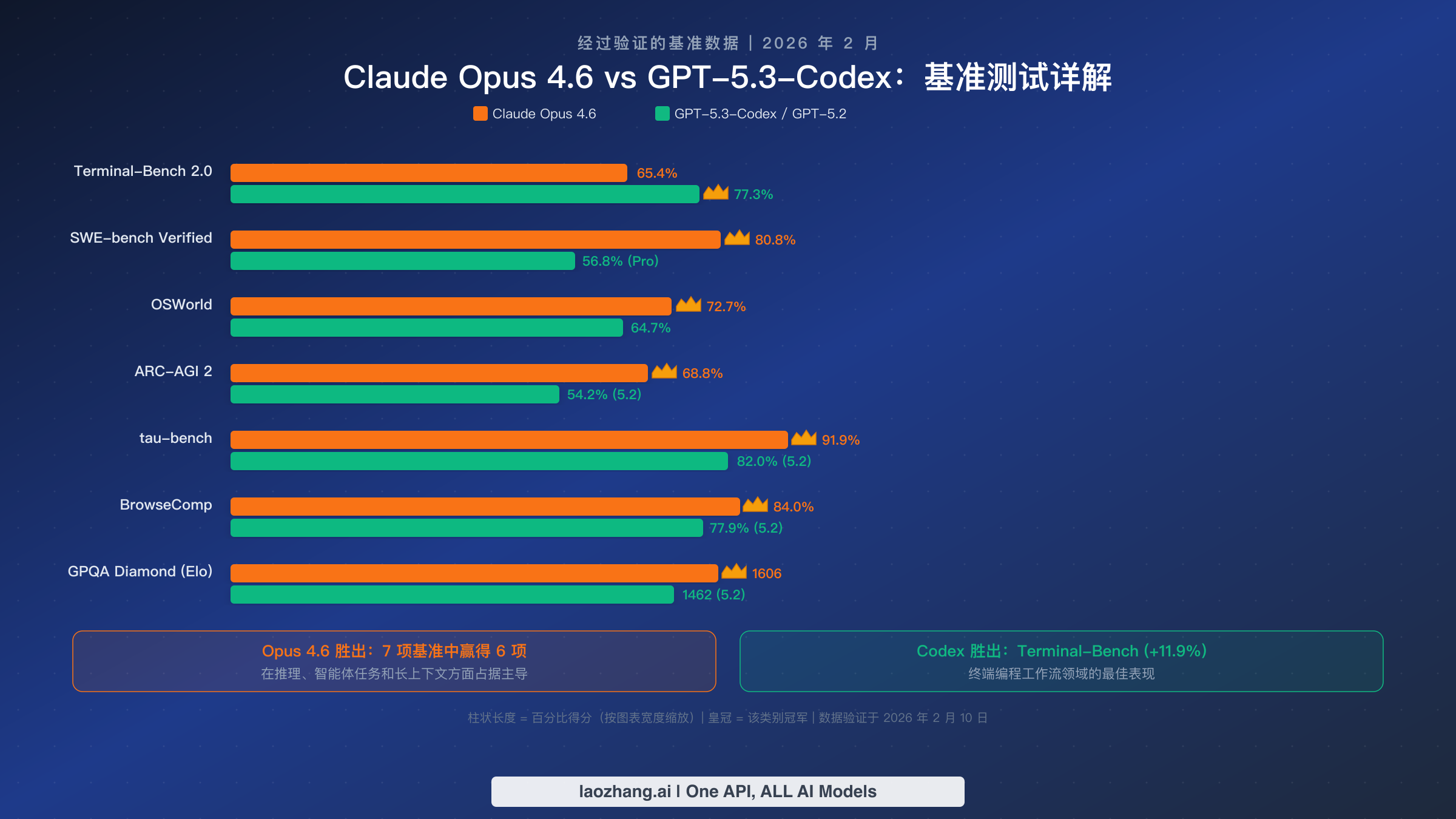
原始基准数字只能说明部分事实。理解每个基准实际测量什么——以及哪些基准对你的具体使用场景真正重要——远比知道谁"赢了"更多类别有价值。以下是完整的验证数据和实用解读。
Terminal-Bench 2.0 衡量模型在终端环境中完成复杂任务的能力,包括系统管理、调试和多步命令序列。GPT-5.3-Codex 的 77.3% 对比 Opus 4.6 的 65.4%,是本次对比中单一基准最大的差距。如果你的日常工作涉及大量终端交互——DevOps、基础设施管理、Shell 脚本编写——这个基准能直接预测实际工作表现。11.9 个百分点的优势在多项独立评测中保持一致。
SWE-bench Verified 测试模型解决热门开源项目真实 GitHub Issue 的能力。Opus 4.6 的 80.8% 得分是有史以来最高分之一,表明其在理解复杂代码库、定位根本原因和生成正确补丁方面具备卓越能力。GPT-5.3-Codex 在更难的 SWE-Bench Pro 变体上得分 56.8%,该变体使用不同的评分方法——两个基准不能直接比较,但都展示了强大的编程能力。对于在大型代码库上工作的企业开发团队来说,SWE-bench 性能可以说是最能预测实际效用的指标。
ARC-AGI 2 和 GPQA Diamond 分别衡量抽象推理和科学知识水平。Opus 4.6 在这两项上的优势——ARC-AGI 2 上 68.8% 对比 54.2%,GPQA Diamond 上 1606 对比 1462 Elo——意义重大,因为它们表明模型在需要全新问题解决方法的任务上具有更优异的表现。这些基准对研究、数据分析以及任何需要模型推理训练数据中未出现过的问题的任务最为关键。
智能体性能基准
tau-bench(91.9% 对比 82.0%) 衡量在真实智能体场景中的多轮任务完成能力。Opus 4.6 近 10 分的领先直接转化为更可靠的自主任务执行——更少的失败步骤、更好的错误恢复以及更连贯的多步骤规划。如果你正在构建 AI 智能体或使用模型进行复杂的自动化工作流,这是最需要关注的基准测试。
BrowseComp(84.0% 对比 77.9%) 评估网页浏览和信息综合能力。Opus 的优势对于研究自动化、竞争分析以及任何涉及从多个网络来源提取和综合信息的工作流都很重要。
OSWorld(72.7% 对比 64.7%) 测试在真实桌面环境中的计算机使用能力。尽管 GPT-5.3-Codex 被定位为更"实操"的工具,Opus 4.6 在通用计算机使用场景中仍以 8 分的优势胜出。这表明 Codex 的优势专门在终端环境,而非更广泛的计算机交互场景。
编程与智能体工作流 — 真实使用体验
基准测试数字描绘了清晰的画面,但实际使用这些模型的开发体验存在数字无法捕捉的差异。根本区别在于工作流理念:Opus 4.6 作为管理复杂性的编排者运作,而 GPT-5.3-Codex 作为在特定范围内快速执行的加速器运作。
Agent Teams 是 Opus 4.6 在开发领域的标志性创新。 不再是单个 AI 助手按顺序处理请求,Agent Teams 允许你启动多个专业化智能体同时处理项目的不同方面。在实践中,这意味着你可以让一个智能体处理前端 React 组件,另一个管理后端 API 端点,第三个编写数据库迁移——所有这些都由一个主导智能体协调,确保一致性。Anthropic 的早期基准测试显示,这种方法可以将复杂项目完成时间缩短 40-60%。该功能是 Opus 4.6 独有的,利用了其自适应思维能力,可根据任务复杂度动态分配推理资源。
GPT-5.3-Codex 的终端原生方式提供了另一种效率。 Codex 不是协调多个智能体,而是通过交互式引导(在模型工作时提供实时指导)、自动调试(自动识别和修复自身输出中的错误)以及基于你的 Shell 历史和项目结构的上下文感知建议,直接集成到你的终端工作流中。对于生活在终端中的开发者——编写部署脚本、调试生产问题、管理基础设施——这种紧密集成消除了在 AI 界面和实际工作环境之间切换的认知负担。
安全维度值得特别关注。 Anthropic 报告称 Opus 4.6 在评估期间在开源代码中发现了超过 500 个零日漏洞。这一能力对代码审查工作流有直接影响:Opus 4.6 能识别传统静态分析工具遗漏的细微安全问题——竞态条件、注入漏洞、逻辑错误。对于将代码安全视为优先事项的团队,这代表着任何基准测试都无法完全量化的显著实际优势。
各模型在实践中的优势场景
Opus 4.6 在需要深度理解大型代码库的场景中一贯表现更优。当面对重构一个 50,000 行应用程序的任务时,Opus 的 100 万 token 上下文窗口(Beta 版)和卓越的推理能力使其能够在整个代码库中保持连贯性,识别出短上下文模型可能遗漏的依赖关系和副作用。其 SWE-bench Verified 80.8% 的得分反映了这一能力——该基准专门测试在复杂项目中修复真实 Bug 的能力。
GPT-5.3-Codex 则在快速迭代周期中表现出色。相比 GPT-5.2-Codex 提速 25%,再加上自动调试功能,意味着在终端驱动的工作流中你能更快地获得可用代码。对于搭建 CI/CD 流水线、编写 Shell 脚本或调试容器配置等任务,Codex 的 Terminal-Bench 优势直接转化为节省的时间。交互式引导功能在这里特别有价值——你可以实时纠正方向,而不是等待完整响应后再请求修改。
定价深度分析 — 每个模型的真实成本

定价是这次对比中真正复杂的部分,因为标价讲述了一个具有误导性的故事。按标准费率看,Claude Opus 4.6 似乎比 GPT-5.2 贵很多——但 Anthropic 激进的优化功能可以极大地改变高用量用户的成本计算。
标准 API 定价(2026 年 2 月 10 日验证,来自官方定价页面):
| 模型 | 输入 | 输出 | 缓存命中 | 批量输入 | 批量输出 |
|---|---|---|---|---|---|
| Claude Opus 4.6 | $5.00/MTok | $25.00/MTok | $0.50/MTok | $2.50/MTok | $12.50/MTok |
| GPT-5.2 | $1.75/MTok | $14.00/MTok | $0.175/MTok | 暂无 | 暂无 |
| GPT-5.3-Codex | 待定 | 待定 | 待定 | 待定 | 待定 |
一个关键注意事项:截至 2026 年 2 月 10 日,GPT-5.3-Codex 的 API 定价尚未公布。该模型目前仅通过 Codex 应用、CLI 和 IDE 扩展提供,OpenAI 称 API 访问"即将推出"。这意味着目前无法对 Codex 模型进行直接价格比较——我们使用 GPT-5.2 定价作为参考基准。
成本优化策略使 Opus 4.6 比标价看起来更具竞争力。 Batch API 对输入和输出 token 均提供五折优惠,有效定价降至 $2.50/$12.50 每百万 token。对于可以容忍异步处理的工作负载(代码审查批处理、文档生成、数据分析管道),这使得 Opus 4.6 仅略贵于 GPT-5.2 标准定价,同时提供明显更强的推理性能。关于 Anthropic Prompt Caching 机制的详细解读,请参阅我们的 Prompt Caching 优化指南。
Prompt Caching 在输入成本上带来更显著的节省。当你重复发送相似的提示词时——这在对同一代码库进行迭代的开发工作流中很常见——缓存的输入 token 仅需 $0.50 每百万 token,比标准定价降低 90%。以典型开发会话 80% 缓存命中率计算,有效输入成本降至约 $1.40 每百万 token,接近 GPT-5.2 的标准输入费率。关于 Claude 完整定价详情,我们的 Claude Opus 4.6 定价详解 涵盖了所有层级和折扣结构。
每月 1000 万输出 token 的成本估算(典型中等用量场景):
| 配置方案 | 月费用 | 备注 |
|---|---|---|
| GPT-5.2 标准 | ~$140 | 基线对比 |
| Opus 4.6 标准 | ~$250 | 比 GPT-5.2 贵 78% |
| Opus 4.6 Batch API | ~$125 | 实际比 GPT-5.2 标准价更便宜 |
| Opus 4.6 Batch + Cache | ~$125 | Opus 的最低有效成本 |
核心洞察:使用 Batch API 后,Opus 4.6 的成本与 GPT-5.2 标准定价持平甚至更低,同时在大多数基准测试中提供更优质的推理质量。对于已经深入使用 Anthropic 生态系统的团队来说,这些优化功能实际上消除了定价上的劣势。
对于需要同时使用两个模型的团队——或者希望在真实工作负载上进行比较后再做决定——统一 API 方案可以简化这一过程。laozhang.ai 等服务提供单一 API 端点,可路由到 Anthropic 和 OpenAI 的模型,无需管理多个 API 密钥和账单关系,同时通过聚合用量定价可能提供更低的费率。
快速上手 — API 集成指南
使用任一模型只需几分钟即可上手。以下是两个模型的可运行代码示例,以及面向需要灵活切换团队的统一接入方案。
Claude Opus 4.6 API
pythonimport anthropic client = anthropic.Anthropic(api_key="your-api-key") message = client.messages.create( model="claude-opus-4-6", max_tokens=4096, messages=[ {"role": "user", "content": "Analyze this codebase for security vulnerabilities..."} ] ) print(message.content[0].text)
启用 100 万上下文窗口 Beta 版时,添加以下 header:
pythonmessage = client.messages.create( model="claude-opus-4-6", max_tokens=4096, extra_headers={"anthropic-beta": "context-1m-2025-08-07"}, messages=[...] )
GPT-5.2 API(GPT-5.3-Codex API 即将推出)
pythonfrom openai import OpenAI client = OpenAI(api_key="your-api-key") response = client.chat.completions.create( model="gpt-5.2", messages=[ {"role": "user", "content": "Write a deployment script for..."} ] ) print(response.choices[0].message.content)
由于 GPT-5.3-Codex 的 API 访问尚未开放,GPT-5.2 是目前通过 API 可用的最接近的模型。Codex 特有的功能(自动调试、交互式引导)目前仅能通过 Codex 应用和 CLI 工具使用。
统一 API 方案
对于希望通过单一集成使用两个模型的团队,laozhang.ai 提供兼容 OpenAI 格式的端点,可路由到多个供应商:
pythonfrom openai import OpenAI client = OpenAI( api_key="your-laozhang-key", base_url="https://api.laozhang.ai/v1" ) # 推理任务使用 Opus opus_response = client.chat.completions.create( model="claude-opus-4-6", messages=[{"role": "user", "content": "Analyze this research paper..."}] ) # 成本敏感任务使用 GPT-5.2 gpt_response = client.chat.completions.create( model="gpt-5.2", messages=[{"role": "user", "content": "Generate test cases for..."}] )
这种方案在评估期间特别有价值——你可以将相同的提示词同时路由到两个模型并比较结果,然后再确定主力供应商。它还支持"两全其美"的策略,将推理密集型任务发给 Opus,快速迭代任务发给 GPT-5.2(或待 API 上线后的 GPT-5.3-Codex)。
你该选哪个? — 选型决策框架
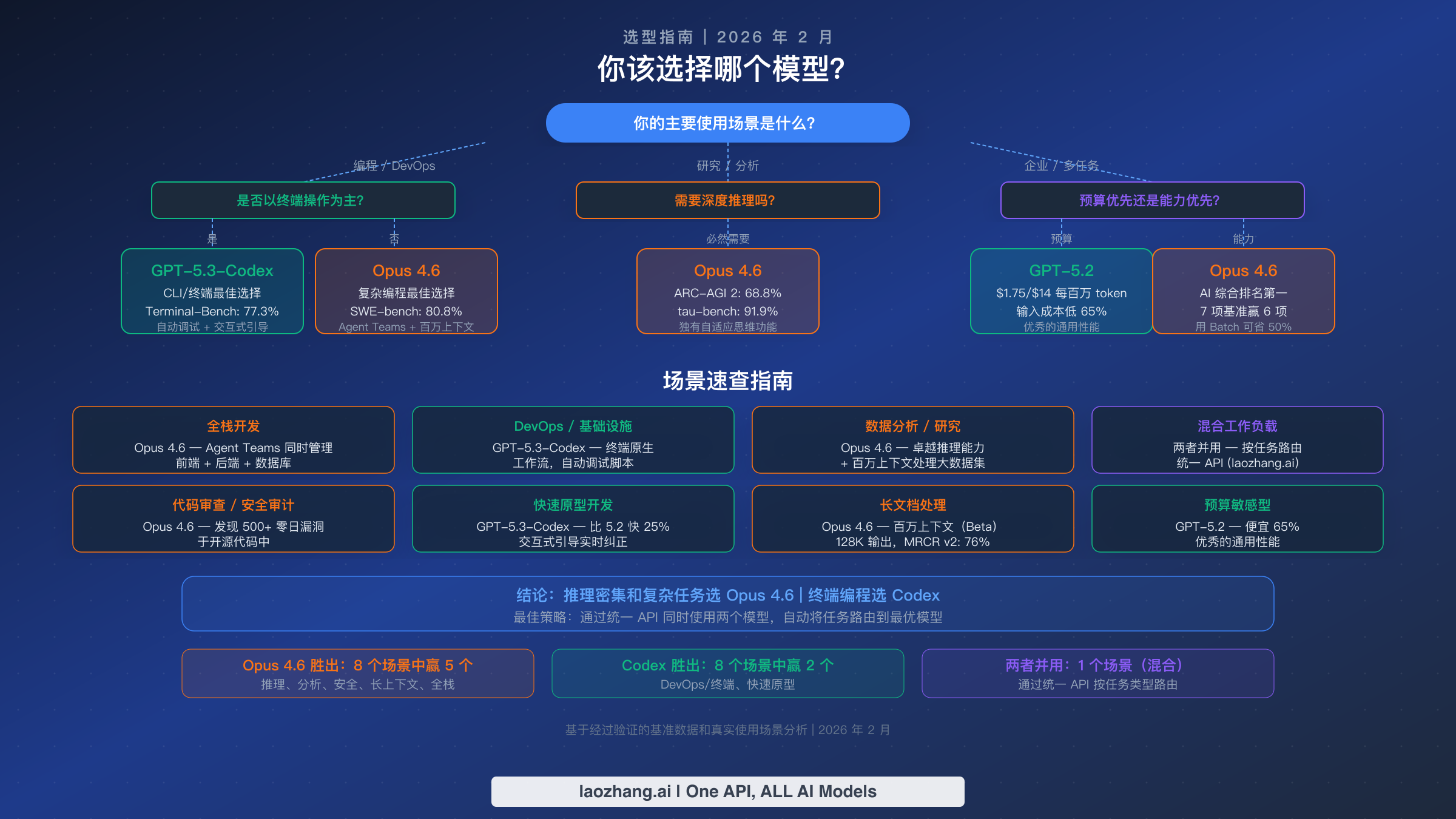
在分析了基准测试、定价和工作流之后,以下是按真实场景组织的实用决策框架。目标不是宣布一个赢家,而是将每个模型匹配到它能提供最大价值的具体场景。
全栈应用开发倾向于 Opus 4.6。Agent Teams 功能可以在前端、后端和数据库层并行工作,100 万 token 上下文窗口能够处理整个代码库。SWE-bench Verified 的 80.8% 确认了其在复杂多文件编程任务上的卓越性能。更高的成本被减少的迭代次数和复杂重构操作中更少的错误所抵消。
DevOps 和基础设施管理倾向于 GPT-5.3-Codex。Terminal-Bench 2.0 的 77.3% 得分直接衡量了部署脚本、容器管理和 CI/CD 流水线配置所需的技能。自动调试功能在 Shell 脚本错误传播之前就能捕获它们,交互式引导让你能够实时指导模型完成复杂的基础设施变更。这是 Codex 最强的竞争优势。
研究和数据分析强烈倾向于 Opus 4.6。ARC-AGI 2 达到 68.8%、tau-bench 达到 91.9%、BrowseComp 达到 84.0%,Opus 在所有与研究工作流相关的基准测试中都占据主导。100 万 token 上下文窗口支持在单次传递中处理完整的研究论文、数据集和文档。自适应思维能力可以动态地为复杂分析问题分配更多推理资源——这是 Opus 4.6 独有的功能,GPT 系列中没有对应的等价物。
快速原型开发和脚本编写倾向于 GPT-5.3-Codex。相比 GPT-5.2-Codex 提速 25% 意味着更快的迭代周期,终端原生工作流最大限度地减少了 IDE 和 AI 工具之间的上下文切换。对于构建快速概念验证、自动化脚本或一次性工具,Codex 的速度优势比 Opus 的推理深度更为重要。
代码安全审计强烈倾向于 Opus 4.6。在开源代码中发现 500 多个零日漏洞展示了其他模型未曾公开匹配的安全分析能力水平。对于负责安全审查、合规审计或维护关键基础设施的团队来说,仅此一项能力就可能足以证明更高的每 token 成本是合理的。
预算敏感的通用场景倾向于 GPT-5.2。以 $1.75/$14 每百万 token 的价格,GPT-5.2 以比 Opus 标准定价低 65% 的输入成本提供强大的通用性能。对于不需要 Opus 的峰值推理能力或 Codex 的终端集成的团队来说,GPT-5.2 提供最佳的性价比。
长文档处理倾向于 Opus 4.6。100 万 token 上下文窗口(Beta),加上 128K 最大输出 token,支持在其他模型无法匹配的规模上进行内容处理和生成。MRCR v2 的 76% 准确率意味着即使在极端的上下文长度下,模型仍能保持合理的检索准确性。
混合企业工作负载最适合同时使用两个模型。将推理密集型任务(分析、代码审查、战略规划)路由到 Opus 4.6,将执行密集型任务(部署、脚本编写、终端操作)路由到 GPT-5.3-Codex 或 GPT-5.2。统一 API 端点简化了这种路由,无需为每个供应商维护单独的集成。
常见问题
Claude Opus 4.6 比 GPT-5.3-Codex 更好吗?
这取决于评估维度。Opus 4.6 在 7 项主要基准中赢得 6 项,包括推理(ARC-AGI 2:68.8% 对比 54.2%)、智能体任务(tau-bench:91.9% 对比 82.0%)和通用编程(SWE-bench:80.8%)。然而,GPT-5.3-Codex 在 Terminal-Bench 2.0 上以近 12 个百分点领先(77.3% 对比 65.4%),使其成为以终端为中心的开发工作流的明确选择。对于大多数通用场景,Opus 4.6 是更强的模型,但在专业终端编程方面,Codex 有着显著的优势。
Claude Opus 4.6 和 GPT-5.3-Codex 的价格对比如何?
Opus 4.6 标准费率为每百万 token 输入 $5/输出 $25。GPT-5.3-Codex 的 API 定价尚未公布——目前仅通过 Codex 应用、CLI 和 IDE 扩展提供。以 GPT-5.2($1.75/$14 每百万 token)作为参考,Opus 标准价格看起来贵 2-3 倍。但是,Opus 的 Batch API(五折)将输出成本降至 $12.50/MTok,Prompt Caching 可将输入成本降低 90% 至 $0.50/MTok。通过这些优化,高用量的 Opus 使用成本实际上可以低于 GPT-5.2 标准定价(Anthropic 官方定价,2026 年 2 月 10 日验证)。
Opus 4.6 能否替代 GPT-5.3-Codex 用于编程?
对于大多数编程任务来说,可以——Opus 4.6 的 SWE-bench Verified 80.8% 得分和 Agent Teams 功能使其在复杂开发工作中表现出色。Codex 保持明确优势的唯一领域是终端原生工作流:如果你的开发流程高度依赖 CLI 工具、Shell 脚本和终端调试,Codex 的专用功能(自动调试、交互式引导、77.3% Terminal-Bench)提供更好的体验。对于全栈开发、代码审查和多文件重构,Opus 4.6 是更强的选择。
Opus 4.6 的自适应思维是什么?
自适应思维是 Opus 4.6 独有的功能,可根据任务复杂度动态分配推理资源。模型不再对每个请求使用固定量的"思考",而是自动为复杂的分析问题增加推理深度,为简单任务降低推理深度。这意味着你在简单查询上获得 GPT-5.2 级别的速度,在困难问题上获得扩展推理能力——无需手动切换模型或配置思考参数。目前没有其他模型提供同等功能。
我是否应该等待 GPT-5.3-Codex 的 API 开放?
如果以终端为中心的编程是你的主要用例,等待 Codex API 开放值得考虑——Terminal-Bench 的优势确实很大。但如果你现在就需要 API 方案,GPT-5.2 以有竞争力的价格提供可靠的编程能力,而 Opus 4.6 在大多数维度上提供更优异的性能。你可以先使用其中一个或两者,待 Codex API 可用后再添加,尤其是在使用支持多供应商的统一 API 服务的情况下。