Anthropic 为保护服务器资源和确保用户公平访问,对 Claude API 和 Claude Code 实施了多层限流机制。无论你是遇到了恼人的 429 错误,还是想了解如何优化配额使用,本指南都将为你提供从原理到实战的完整解决方案。2026年1月的最新政策显示,Pro 用户每5小时窗口约45条提示,Max 20× 用户最高可达800条,而 API 用户则按层级享有不同的 RPM(每分钟请求数)和 Token 配额。
什么是 Claude 限流?一分钟快速了解
限流(Rate Limiting)是 API 服务的标准保护机制,Claude 通过多维度指标来控制请求频率和资源消耗。理解这些基本概念是解决限流问题的第一步。
Claude 限流的核心目的是什么? Anthropic 官方文档明确指出,限流机制旨在"防止 API 滥用,同时最大限度地减少对常见客户使用模式的影响"。这意味着对于正常使用的开发者,限流通常不会造成严重干扰,但对于高频调用或资源密集型应用,就需要特别关注配额管理。
Claude 的限流体系包含三个核心指标。RPM(Requests Per Minute) 限制每分钟的 API 请求次数,这是最直观的限制维度。ITPM(Input Tokens Per Minute) 限制每分钟输入的 Token 数量,包括提示词、系统消息和上下文。OTPM(Output Tokens Per Minute) 限制每分钟输出的 Token 数量,即模型生成的响应内容。这三个指标相互独立,任何一个达到上限都会触发限流。
特别值得注意的是,Anthropic 使用的是令牌桶算法(Token Bucket),而不是简单的固定窗口计数。这意味着你的配额是持续补充的,而不是在每分钟整点重置。这种机制对突发流量更加友好,但也意味着短时间内的大量请求可能会快速耗尽配额。
配额层级完全解读:从 API 到 Claude Code
Claude 的配额体系分为两个维度:API 使用层级和 Claude Code 订阅层级。前者适用于直接调用 API 的开发者,后者适用于使用 Claude Code CLI 工具的用户。
API 使用层级详解
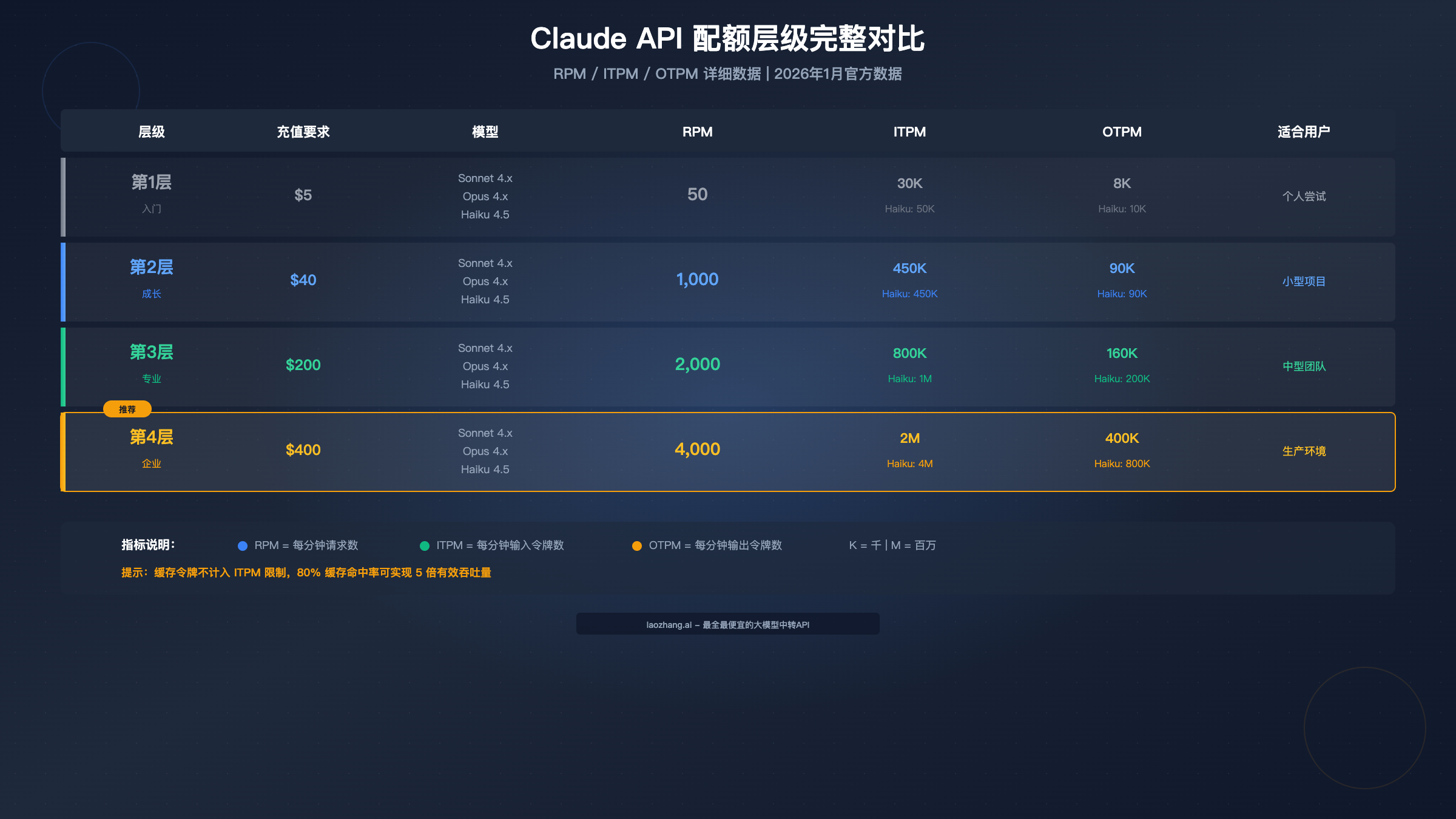
Anthropic 将 API 用户分为四个层级,每个层级的配额随充值金额递增。升级是自动的,当你的累计充值达到阈值时,系统会立即提升你的层级。
第1层(入门级) 需要 $5 起充。这是大多数新用户的起点,配额相对有限:Sonnet 4.x 和 Opus 4.x 模型均为 50 RPM、30,000 ITPM、8,000 OTPM。Haiku 4.5 稍高,有 50,000 ITPM 和 10,000 OTPM。这个层级适合个人学习和小型实验项目。
第2层(成长级) 需要累计充值 $40。配额显著提升到 1,000 RPM,ITPM 和 OTPM 也分别提升到 450,000 和 90,000。这个层级已经能够支持小型商业应用的开发和测试。
第3层(专业级) 需要累计充值 $200。RPM 达到 2,000,Sonnet/Opus 的 ITPM 为 800,000,Haiku 更是达到了 100万。中型团队和正式产品通常需要这个层级的配额。
第4层(企业级) 需要累计充值 $400。这是标准层级的最高等级,RPM 达到 4,000,Sonnet/Opus 的 ITPM 达到 200万,Haiku 更是高达 400万。对于生产环境和高并发应用,这个层级提供了充足的配额空间。
需要特别说明的是,这些限制在所有模型之间是独立计算的。这意味着你可以同时使用 Sonnet 和 Haiku,各自消耗各自的配额,而不是共享一个总配额。
Claude Code 订阅层级对比
与 API 不同,Claude Code 使用基于订阅的配额模型,采用5小时滚动窗口和周配额双重限制。
Free 免费版 每天约40条消息,不支持完整的 Claude Code 功能。这个层级适合偶尔尝试的用户。
Pro 版($20/月) 解锁完整功能,每5小时窗口约45条提示,周活跃时长约40-80小时(Sonnet 模型)。这是个人开发者最常用的订阅等级。
Max 5× 版($100/月) 提供 Pro 版5倍的配额,每5小时窗口约225条提示。适合重度使用者和小型团队。
Max 20× 版($200/月) 提供 Pro 版20倍的配额,每5小时窗口可达800条提示,周活跃时长可达480-800小时。这是当前消费级订阅的最高配置。
值得注意的是,Claude Code 的限制是跨所有接入点统一计算的。无论你通过浏览器、CLI 还是 IDE 插件使用,配额都是共享的。
Claude Code 专项:5小时窗口与周配额详解
对于 Claude Code 用户,理解其独特的限流机制至关重要。与传统的每分钟限流不同,Claude Code 采用了更复杂的双层控制系统。
5小时滚动窗口是如何工作的? 当你发送第一条提示时,一个5小时的计时器开始运行。在这5小时内,你可以使用的提示次数取决于你的订阅层级。窗口是滚动的,这意味着当第一条消息超过5小时后,它所占用的配额会被释放。
实际体验中,Pro 用户反馈的平均数据是每5小时约45条提示。但这个数字会因为提示的复杂度、上下文长度和使用的模型而有所变化。如果你的提示包含大量代码文件或长上下文,每条提示消耗的配额会更多。
周配额限制是 Anthropic 在2025年8月新增的限制措施。官方解释是少数用户"通过低成本订阅消费了价值数千美元的计算资源"。这一政策主要针对那些7×24小时运行 Agent 任务的高频用户。对于普通开发者,周配额通常不会成为瓶颈。
当你触发限流时,Claude Code 界面会显示明确的错误信息和重置时间。遗憾的是,目前没有手动覆盖的选项,你只能等待配额恢复或升级订阅。如果你正在使用 Claude Code 进行开发,建议参考我们的 Cursor 与 Claude Code 详细对比 了解不同工具的限流策略差异。
实用技巧:如何延长配额使用时间? 首先,选择合适的模型至关重要。日常编码任务使用 Sonnet 比 Opus 消耗的配额更少。其次,定期清理上下文可以减少每次请求的 Token 消耗。在 Claude Code 中使用 /compact 命令可以压缩对话历史,使用 /clear 可以完全重置上下文。最后,避免在对话中保留大量无关的文件引用,因为每个引用的文件内容都会被计入 Token 消耗。
429 vs 529:两种错误的诊断与解决
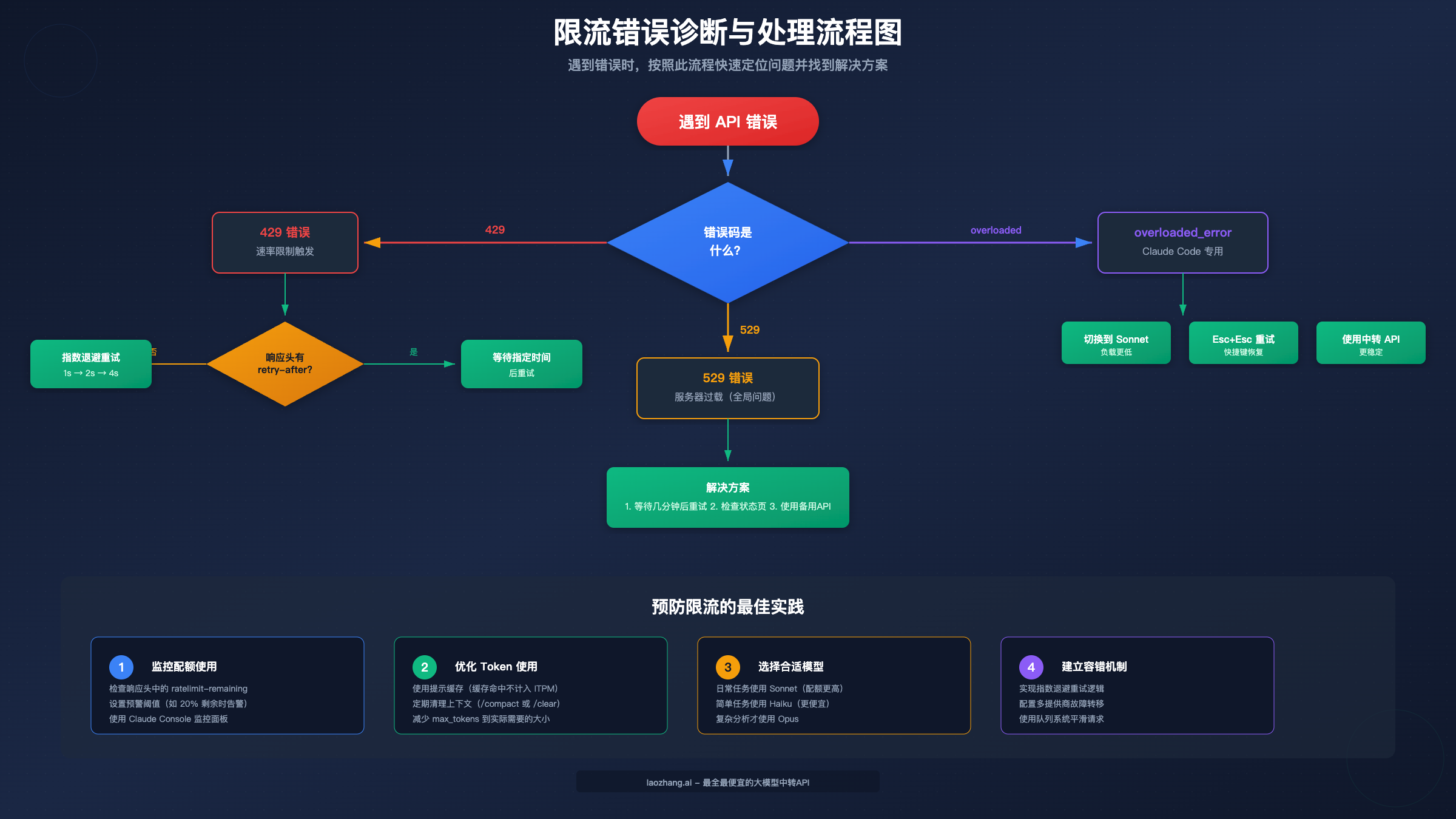
遇到限流错误时,首先需要区分是 429 错误还是 529 错误,因为它们的成因和处理方式截然不同。
429 错误:速率限制触发
429 Too Many Requests 表示你的账户或组织触发了速率限制。这是一个可控的错误,意味着通过调整你的请求策略可以解决问题。
当收到 429 响应时,首先检查响应头中的 retry-after 字段。这个字段告诉你需要等待多少秒才能重试。如果响应头中包含这个字段,最简单的处理方式就是等待指定时间后重试。
更专业的处理方式是实现指数退避重试。基本逻辑是:第一次重试等待1秒,第二次等待2秒,第三次等待4秒,以此类推。为了避免多个客户端同时重试造成的"惊群效应",通常还会加入随机抖动(jitter)。
429 错误的常见原因包括:短时间内发送过多请求、单个请求的 Token 数量过大、组织内多个应用共享同一配额。排查时,可以检查响应头中的 anthropic-ratelimit-* 系列字段,它们会告诉你当前的配额使用情况。
如果你之前遇到过 ChatGPT 的限流问题,可以参考我们的 ChatGPT 限流错误解决指南,很多处理思路是相通的。
529 错误:服务器过载
529 Overloaded 与 429 有本质区别。529 表示 Anthropic 的整体基础设施正在承受压力,这是一个不可控的全局问题,与你的个人配额无关。
遇到 529 错误时,不要立即疯狂重试。正确的做法是:等待几分钟后重试,检查 Anthropic 状态页面确认是否有已知故障,考虑使用备用 API 服务。由于 529 是全局问题,大量用户同时重试只会加剧服务器压力。
overloaded_error:Claude Code 专用
在 Claude Code 中,你可能会遇到 overloaded_error 这个专用错误类型。这通常意味着你当前使用的模型服务器负载较高。
处理 overloaded_error 的有效策略是切换模型。如果你正在使用 Opus,尝试切换到 Sonnet,因为 Sonnet 的服务器容量通常更大。在 Claude Code 中,你还可以使用 Esc+Esc 快捷键尝试中断当前请求并重试,或者使用 Ctrl+C 强制终止当前任务后重新开始。
如何选择:升级订阅 vs 中转API vs 多账号
当你频繁遭遇限流时,有三种主要的解决路径:升级订阅层级、使用中转 API 服务、或采用多账号策略。每种方案都有其适用场景和成本考量。
升级订阅的优势和适用场景。对于个人开发者,从 Pro 升级到 Max 5× 意味着配额提升5倍,月费从 $20 增加到 $100。如果你的主要痛点是配额不足,而且对官方服务的稳定性和合规性有要求,升级是最直接的选择。升级后你可以继续使用所有官方功能,包括最新的模型版本和功能更新。
中转 API 的价值。对于预算有限但需要高配额的用户,中转 API 服务是一个值得考虑的选择。以 laozhang.ai 为例,其价格与官方保持一致,同时支持 Claude、GPT、Gemini 等多模型切换。对于需要同时使用多个 AI 模型的项目,这种聚合服务可以简化集成工作。中转服务通常还提供更高的并发限制和更稳定的国内访问体验。
如果你对 API 购买流程不熟悉,可以参考我们的 Claude API 完整购买指南 了解详细步骤。
多账号策略的考量。虽然使用多个账号可以获得多份配额,但这种做法存在风险。Anthropic 的服务条款明确禁止账号共享和滥用行为,违规可能导致账号被封禁。此外,管理多个账号也会增加运营复杂度。对于企业用户,更推荐的做法是申请企业 API 账户,获得定制化的配额和专业支持。
决策建议:如果你是个人开发者,月使用量稳定在 Pro 配额的2-3倍以内,升级到 Max 5× 是最简单的选择。如果你需要更高的灵活性和多模型支持,或者在中国大陆需要稳定的访问,中转 API 服务值得考虑。如果你是企业用户,建议直接联系 Anthropic 销售团队获取企业方案。
中国用户特别指南:网络优化与替代方案
对于中国大陆用户,Claude 的使用面临额外的网络挑战。除了标准的限流问题,网络延迟和连接稳定性也是需要解决的问题。
网络诊断的基本步骤。当遇到连接问题时,首先确认是网络问题还是限流问题。可以使用 claude doctor 命令进行诊断,这个命令会检查 CLI 的配置状态和网络连接。如果诊断显示网络超时,问题可能出在代理配置或网络环境上。
代理配置最佳实践。Claude Code 支持通过环境变量配置代理。在终端中设置 HTTPS_PROXY 环境变量后,所有 API 请求都会通过指定的代理服务器。需要注意的是,代理服务的稳定性直接影响 Claude Code 的使用体验,选择低延迟、高可用的代理服务非常重要。
中转 API 的优势。对于中国用户,使用中转 API 服务可以避免直连海外服务器的网络问题。laozhang.ai 等服务提供了国内优化的网络线路,通常能提供更稳定的连接和更低的延迟。同时,这类服务通常不会因为 IP 地区问题导致账号风险。如果你需要了解更多访问方案,可以参考 Claude API 中国访问方案对比。
成本对比分析。官方 API 第4层需要累计充值 $400,获得 4,000 RPM 的配额。中转服务通常按使用量计费,没有最低充值门槛,对于用量波动较大的项目更加灵活。但需要注意的是,中转服务可能无法访问最新发布的模型功能,存在一定的功能延迟。
代码实战:限流处理最佳实践
理论知识需要转化为可执行的代码。以下是处理 Claude API 限流的生产级代码示例。
Python 指数退避重试实现:
pythonimport time import random from anthropic import Anthropic, RateLimitError, APIStatusError def call_claude_with_retry(client, messages, max_retries=5): """带指数退避重试的 Claude API 调用""" base_delay = 1 max_delay = 60 for attempt in range(max_retries): try: response = client.messages.create( model="claude-sonnet-4-20250514", max_tokens=1024, messages=messages ) return response except RateLimitError as e: # 检查 retry-after 头 retry_after = getattr(e, 'retry_after', None) if retry_after: wait_time = int(retry_after) else: # 指数退避 + 随机抖动 wait_time = min(base_delay * (2 ** attempt) + random.uniform(0, 1), max_delay) print(f"触发限流,等待 {wait_time:.1f} 秒后重试...") time.sleep(wait_time) except APIStatusError as e: if e.status_code == 529: # 服务器过载,等待更长时间 wait_time = min(30 * (2 ** attempt), 300) print(f"服务器过载 (529),等待 {wait_time} 秒...") time.sleep(wait_time) else: raise raise Exception("达到最大重试次数,请稍后再试")
响应头监控示例:
pythondef check_rate_limit_status(response): """检查响应头中的配额状态""" headers = response.headers status = { 'requests_remaining': headers.get('anthropic-ratelimit-requests-remaining'), 'tokens_remaining': headers.get('anthropic-ratelimit-tokens-remaining'), 'tokens_reset': headers.get('anthropic-ratelimit-tokens-reset'), } # 如果剩余配额低于 20%,发出警告 if status['requests_remaining']: remaining = int(status['requests_remaining']) if remaining < 10: print(f"警告:剩余请求配额仅 {remaining} 次") return status
令牌桶客户端限流器:
pythonimport threading import time class TokenBucket: """客户端令牌桶限流器""" def __init__(self, tokens_per_second, max_tokens): self.tokens_per_second = tokens_per_second self.max_tokens = max_tokens self.tokens = max_tokens self.last_refill = time.time() self.lock = threading.Lock() def _refill(self): now = time.time() elapsed = now - self.last_refill new_tokens = elapsed * self.tokens_per_second self.tokens = min(self.tokens + new_tokens, self.max_tokens) self.last_refill = now def acquire(self, tokens=1): with self.lock: self._refill() if self.tokens >= tokens: self.tokens -= tokens return True return False def wait_for_token(self, tokens=1): while not self.acquire(tokens): time.sleep(0.1) rate_limiter = TokenBucket(tokens_per_second=50/60, max_tokens=50) def rate_limited_request(client, messages): rate_limiter.wait_for_token() return client.messages.create(...)
这些代码示例覆盖了最常见的限流处理场景。在实际项目中,建议将这些逻辑封装成独立的模块,并结合日志系统进行监控。
FAQ:10个限流常见问题解答
Q1:429 错误和 529 错误有什么区别?
429 表示你的账户触发了速率限制,是个人配额问题;529 表示 Anthropic 服务器整体过载,是全局问题。429 可以通过等待或优化请求策略解决,529 只能等待服务恢复。
Q2:如何查看我当前的配额使用情况?
API 用户可以在 Claude Console 的使用页面查看配额图表,也可以通过检查 API 响应头中的 anthropic-ratelimit-* 字段实时监控。Claude Code 用户在触发限流时会看到剩余时间提示。
Q3:缓存令牌是否计入配额?
对于大多数新模型,缓存读取的令牌(cache_read_input_tokens)不计入 ITPM 限制。这意味着善用提示缓存可以显著提升有效吞吐量。
Q4:为什么我的配额比官方文档说的少?
实际可用配额可能受到多种因素影响:组织内多个应用共享配额、工作区设置了更低的限制、账户存在加速限制等。建议在 Console 中检查具体的限制设置。
Q5:Claude Code 的5小时窗口是什么意思?
从你发送第一条消息开始计时,5小时内可用的提示次数有上限。窗口是滚动的,5小时后最早的消息会释放配额。
Q6:升级订阅后配额立即生效吗?
是的,API 层级升级和 Claude Code 订阅升级都是立即生效的。升级后你可以立即享受更高的配额。
Q7:中转 API 服务安全吗?
选择信誉良好的中转服务通常是安全的。但需要注意:不要在中转服务中使用包含敏感信息的提示词,了解服务商的数据处理政策,确认服务商有合法的运营资质。
Q8:多账号使用会被封禁吗?
Anthropic 禁止账号共享和滥用行为。如果被检测到异常使用模式,可能会导致账号被限制或封禁。建议通过正规渠道获取所需配额。
Q9:企业用户如何获得更高配额?
企业用户可以通过 Claude Console 联系销售团队,获取定制的配额方案。企业方案通常包括更高的限制、优先支持和专属的服务等级协议。
Q10:限流错误会影响我的账户状态吗?
正常的限流错误不会对账户产生负面影响。但如果持续触发大量限流错误而不进行优化,可能会被系统标记为异常使用,建议遵循最佳实践避免频繁触发限流。
总结与资源
Claude 的限流机制虽然复杂,但理解其原理后就能有针对性地优化使用策略。记住以下核心要点:区分 429(个人配额)和 529(全局过载)错误;善用提示缓存提升有效吞吐量;根据使用场景选择合适的模型;实现健壮的重试逻辑应对临时故障。
对于持续遭遇限流的用户,评估升级订阅或使用中转服务的成本效益。对于企业用户,建议直接联系 Anthropic 获取定制方案。
如果你需要更多关于 AI API 使用的技术支持和成本优化方案,可以访问 laozhang.ai 文档 了解多模型聚合 API 服务的详细信息。
希望本指南能帮助你解决 Claude Code 的限流问题,实现更流畅的 AI 编程体验。如果你有其他问题或发现了新的解决方案,欢迎在评论区分享交流。