
如果 Claude API 返回 HTTP 500,并且响应体里的 error.type 是 api_error,先把它当成一次已经到达 Claude 服务端、但在服务内部失败的请求处理。不要马上换 key、改 prompt、切模型或重启整条链路。第一步是打开 Claude Status,保存响应里的 request_id 或响应头 request-id,再保持同一模型、端点、认证主体、SDK 或网关路径、网络出口和请求形状,用很小的预算重试。
2026 年 5 月 19 日查看 Claude Status 时,公开状态页显示各系统正常,同时还能看到近期已经解决的错误率升高事件。这个状态只是一条带日期的分支证据:它能帮助你判断是否可能撞上公开事故,但不能证明你的账号、模型、地区、网关、代理或负载一定没有问题。
先用下面这张恢复表把分支固定下来,再动代码或配置。
| 你手里的现象 | 第一动作 | 验证方式 | 停止规则 |
|---|---|---|---|
HTTP 500,错误类型是 api_error | 保存 request_id、时间、模型、端点、base URL 和调用路径,然后查 Claude Status | 同一路径在小预算重试后恢复,或继续返回同一分支 | 不要无限循环;连续复现后准备升级证据 |
529 overloaded_error | 按容量压力处理,降低并发,减少重试风暴,等待或错峰 | 降压后错误消退,或分支变化 | 不要把它当成参数校验或本地网络问题 |
429 rate_limit_error | 查配额、速率、并发、token 量和批处理节奏 | 限流调整后恢复 | 不要用“换 key”替代限流治理 |
504 timeout_error 或长请求超时 | 缩短请求、改流式、拆批,检查超时设置 | 小请求或流式请求在同一账号下完成 | 不要在没有返回 500 响应时套用 500 处理法 |
| DNS、代理、TLS、SDK timeout,根本没有 API 响应 | 单独检查网络、代理、防火墙、base URL 和 SDK timeout | 一个已知的小请求能到达 API 并返回正常响应或更明确错误 | 不要把连接失败写成 Claude 内部错误 |
| 同一路径反复返回干净的 500 | 组装证据包:request_id、状态时间、重试时间线、路径和脱敏请求形状 | 平台或支持团队能按同一失败路径关联日志 | 不发送密钥、完整 prompt、认证头或用户隐私 |
一旦某个分支有证据,就停止大范围改动。真正危险的不是一次 500,而是一边没有保存 request_id,一边同时换模型、换代理、改请求、重试十几次,最后连哪一步让问题消失都说不清。
干净的 500 api_error 到底说明了什么
Anthropic 的 API 错误文档把 HTTP 500 对应到 api_error。这意味着调用方收到了 Claude API 返回的内部服务器错误分支;响应中可能有 error.type、error.message 和响应级 request_id,API 响应头也可能带 request-id。所以第一反应应该是保存证据,而不是靠经验猜“是不是 key 坏了”。
它不等于“你的代码绝对没问题”。一个短暂的服务内部异常、某个模型路径的临时波动、上游依赖问题、网关转发层包了一层错误,都可能在调用方这里表现成 500。更有用的问题是:同一请求路径能不能复现,公开状态和时间窗口是否吻合,改变本地变量后到底改变了哪个分支。
也不要把 500 默认解释成 prompt 无效。请求格式、权限、认证、账单、限流、过载通常会落在更具体的 4xx、429、529 或连接层分支。prompt 和 payload 当然可能间接影响失败概率,尤其是超长上下文、复杂工具调用、附件或非幂等链路,但那是保存状态和 request_id 之后再检查的第二层。
Claude Code 也要单独看一眼。中文开发者讨论里经常把 API、Claude Code、第三方转发和聊天网页混在一起。Claude Code 可能把原始 5xx 响应体直接显示在终端里,这说明终端只是暴露了同一个 API 错误分支,不代表问题一定来自本机 CLI。你仍然要保存原始错误体、命令上下文、版本号和是否能在 Workbench 或直接 API 中复现。
先分清分支,再决定修复动作
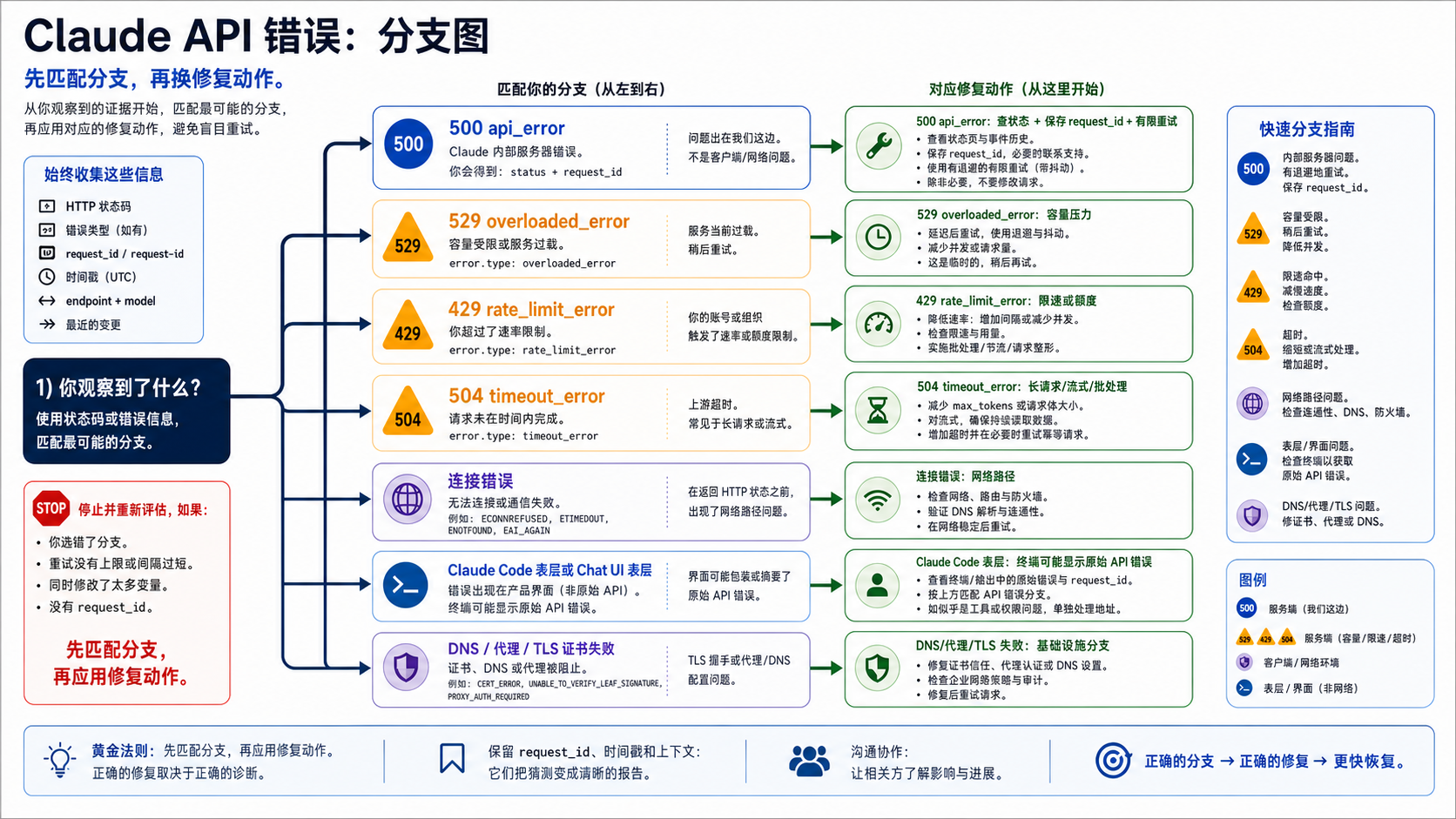
排查 500 最容易走错的地方,是把所有失败都叫“Claude 挂了”。对工程团队来说,分支比情绪判断更重要。同一个业务动作可能被 500、529、429、504、代理超时、CLI 登录状态、第三方网关错误打断,但每一类错误的动作不同。
看到返回的 HTTP 状态是 500,响应体又明确是 api_error,就按内部服务器错误分支处理:记录状态、request_id、模型、端点、调用路径和请求形状。这个分支先做状态页和有限重试,不先做配额计算。
看到 529 overloaded_error,说明更接近容量或过载压力。这个分支应该减少并发、延长退避、避免重试风暴。如果错误已经变成 529,可以转到 Claude 529 Overloaded Error 这一类处理思路,重点从“内部错误证据”转为“容量压力和流量控制”。
看到 429 rate_limit_error,要查组织或账号的速率限制、并发、token 用量、批处理和调用节奏。限流不是等待公开事故就会自动好的问题,也不应该靠轮换密钥掩盖。轮换 key 只适合认证、泄露或权限类分支。
看到 504 timeout_error 或长请求耗尽超时,要检查请求形状和执行方式。流式返回、Message Batches、更小的上下文、拆分任务、客户端 timeout 都可能比重试 500 更有效。如果根本没有收到 Claude 的 500 响应,不要把超时直接归到 api_error。
没有 API 响应时,先走连接层:DNS、代理、TLS、企业防火墙、VPN、base URL、SDK timeout、证书检查和出口网络。一个很小的已知正常请求能不能返回,是连接层排查里比 Claude Status 更有用的第一步。
按有界恢复循环处理
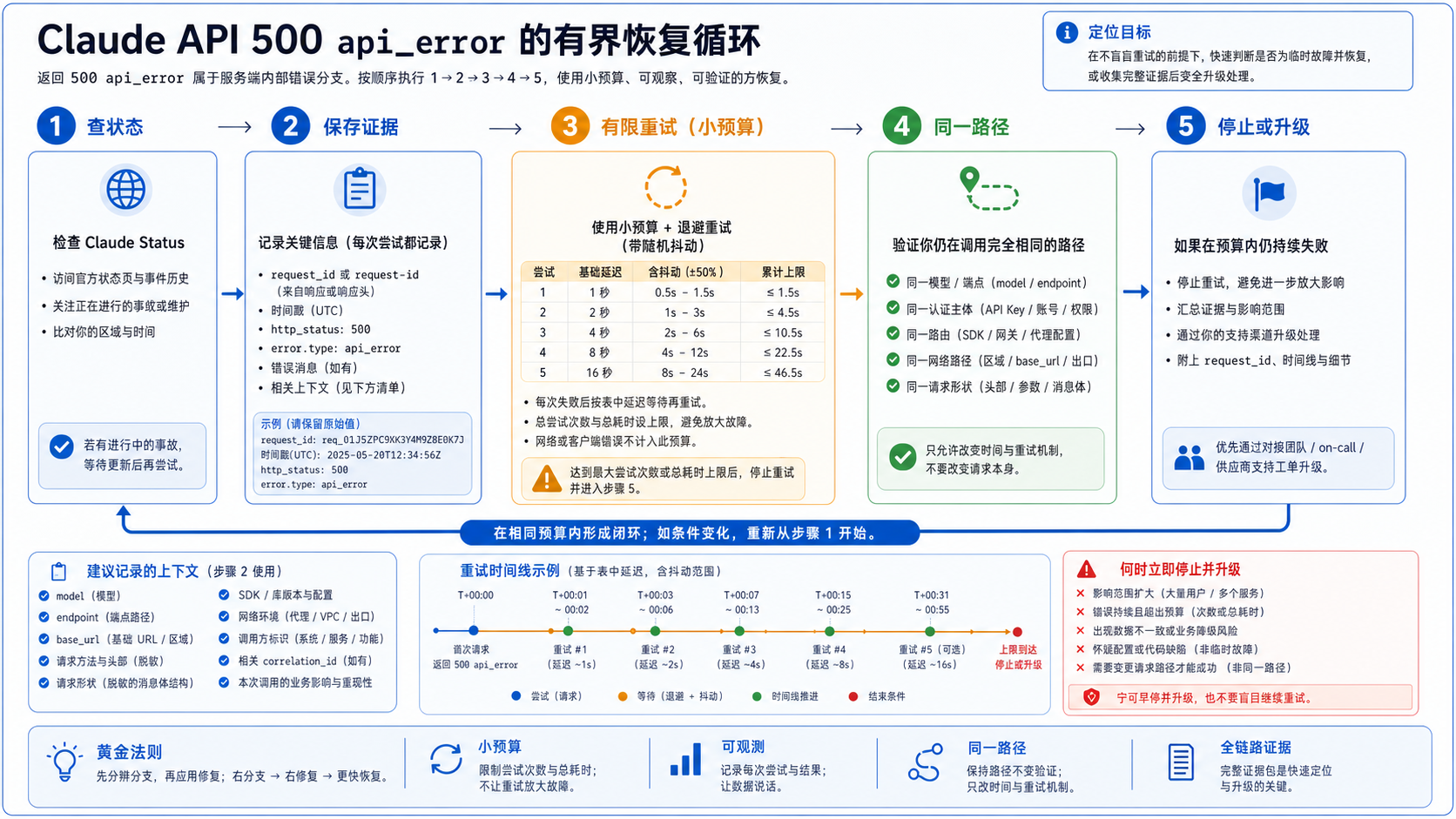
500 的恢复循环应该短而可审计:查状态,保存证据,有限重试,同一路径验证,停止或升级。每一步都在防止一个常见错误。
第一步查 Claude Status 并记录查看时间。状态页如果有活动事故,下一步就是保护用户体验、降低重复压力、等待恢复,并把日志波峰和事故窗口对应起来。状态页如果是绿色,也不要立刻断言问题在本地;它只意味着你更需要同一路径复现证据。
第二步保存标识符。直接 API 调用里,保存响应体的 request_id 和响应头的 request-id。SDK 抛异常时,保存异常类、HTTP 状态、error.type、模型、端点、base URL、SDK 版本、网关路径和自己的 correlation ID。Claude Code 或内部工具暴露原始响应体时,也一并保留。
第三步只用小预算重试。很多 SDK 可能已经在底层做了一到几次重试;如果应用层再套无限循环,就会放大副作用,也可能加重服务端压力。一个保守做法是两到三次应用层尝试,带退避和 jitter,并设置总耗时上限。
第四步验证“同一路径”。这里的同一路径不是“同一个功能大概又点了一次”,而是同一模型、同一端点、同一认证主体、同一 SDK 或网关、同一 base URL、同一网络出口、同一关键请求形状。你可以脱敏 payload,但不要同时换掉多个变量。
第五步决定停止还是升级。如果一次小预算重试成功,并且业务动作是幂等的,记录事件继续观察。如果同一路径连续返回干净的 500,就停止改请求,整理证据包。此时继续“试试看”只会降低日志可信度。
重试之前先确认副作用安全
重试只有在重复执行安全时才安全。只读问答、摘要、分类、分析任务通常比较容易重试;会付款、写数据库、发消息、更新工单、执行工具、创建文件的链路,必须先有幂等保护。
用户产品里尤其要区分“模型调用失败”和“业务副作用是否已经发生”。如果数据库写入发生在模型调用之前,写入要能去重。如果工具调用会发邮件或下单,不要因为最后一个模型响应是 500 就把整条链路重跑。更稳的做法是保存 job ID,在重放时查重,并向用户展示明确的降级状态。
重试策略也要让值班同事看得懂。至少写清四个数字:最大尝试次数、初始等待、退避形状、最大总耗时。没有这些数字,“加重试和退避”就会变成每个工程师各写一套。
下面的示例不是让你原样复制,而是展示分支边界:只重试干净的 500 api_error,先记录证据,再等待,最后一定停止。
tsasync function callClaudeWith500Budget(runClaude: () => Promise<unknown>) { const maxAttempts = 3; const baseDelayMs = 800; for (let attempt = 1; attempt <= maxAttempts; attempt += 1) { try { return await runClaude(); } catch (error: any) { const status = error?.status || error?.statusCode; const type = error?.error?.type || error?.type; if (status !== 500 || type !== "api_error") { throw error; } recordClaude500Evidence({ attempt, requestId: error?.request_id || error?.headers?.["request-id"], status, type, }); if (attempt === maxAttempts) { throw error; } const jitter = Math.floor(Math.random() * 400); await sleep(baseDelayMs * 2 ** (attempt - 1) + jitter); } } }
真正重要的不是 800 毫秒还是 1 秒,而是处理器不会把所有错误都当成可重试错误,不会在睡眠前丢掉 request_id,也不会让一次服务端内部错误变成无限外层循环。
把直接 API、Claude Code 和网关路径分开
真实排障场景里能看到几类混杂现象:有人在直接 API 里遇到 500,有人在 Claude Code 里看到终端报错,也有人通过第三方网关或路由器看到 fetch failed、internal_error 或包了一层的 JSON 错误。它们都可能最后显示成“Claude 500”,但排查边界不同。
直接 Anthropic API 调用里,服务响应由 Anthropic 路径返回,你的团队负责请求构造、重试策略、幂等保护和日志字段。Claude Code 里,终端可能显示原始 5xx 响应,但本地认证状态、CLI 版本、工具执行、MCP 服务和命令参数也会叠加一层排查面。网关路径里,base URL、认证转交、供应商选择、网关日志和网关预重试都可能改变最终现象。
所以同一路径验证必须包含“这次到底走了哪条路径”。直接 API 失败而网关成功,不等于 Claude 一定健康或一定不健康;它只说明两条路径结果不同。你要把 Anthropic request_id、网关 trace ID、base URL、地区、时间戳分开保存,让每一层的负责人能按自己的日志定位。
不要把切换供应商当成第一修复动作。生产系统当然可以有降级或备用路线,但那应该是业务连续性策略,而不是没有保存第一批 request_id 之后的慌乱点击。先保留原失败,再决定是否需要临时 fallback。
升级前准备证据包

升级不是把整段私有 prompt 粘给支持团队。一个好的证据包能让平台或内部网关负责人关联到失败请求,同时不泄露密钥、认证头、用户隐私、原始文件或业务机密。
最小证据包可以这样组织:
| 字段 | 为什么需要 |
|---|---|
| 状态页查看时间 | 判断失败是否落在公开事故或绿色状态窗口 |
request_id 或 request-id | 让平台按具体响应关联日志 |
HTTP 状态和 error.type | 确认这是 500 api_error,不是 429、529、504 或连接层失败 |
| 模型和端点 | 区分模型路径、端点路径和账号路径 |
| SDK、网关、base URL、地区 | 标出是否经过包装、转发或代理 |
| 重试时间线 | 证明小预算退避后是否仍复现 |
| 同一路径复现说明 | 说明没有同时更换多个变量 |
| 脱敏请求形状 | 展示请求大小、是否流式、工具调用、附件类型,不暴露正文 |
| 影响范围和频率 | 区分一次噪声和生产降级 |
如果问题发生在 Claude Code,补充 Claude Code 版本、命令形状、终端是否显示原始 5xx、同一任务在 Workbench 或直接 API 是否复现、是否同时出现登录或授权问题。如果问题经过内部服务或网关,补充内部 trace ID 和任何能传出的 Anthropic request_id。
证据包越短越好读,越结构化越容易关联。推荐用时间线写:第一次失败时间、状态页检查时间、尝试次数、同一路径复现结果、当前影响、最近变更。不要用长篇叙述代替字段。
团队如何把 500 变成可运营事件
依赖 Claude 的团队不应该在事故时才临时决定 500 怎么处理。第一层控制是结构化日志。每次失败都保留 status、error type、request_id、模型、端点、调用路径、耗时、attempt number 和自己的 correlation ID。没有这些字段,复盘只能靠聊天记录。
第二层是熔断和降级。如果干净的 500 在短时间内明显升高,暂停高量非关键任务,限制外层重试,给用户明确的降级提示,并把告警指向具体路径。目标不是一次内部错误就放弃 Claude,而是不要把服务端问题放大成自己的流量风暴。
第三层是幂等任务设计。能等待的任务进队列,能重放的任务做去重,不可重复的动作在模型调用前后都要标记状态。模型调用如果只是大流程中的一步,不能让整个流程在 500 后无条件自动重跑。
第四层是路径隔离。直接 API、Claude Code、Workbench、内部网关、公司代理和浏览器产品最好在仪表盘里分开看。一条路径正常不应该掩盖另一条路径异常;一条路径异常也不应该让团队误判全部 Claude 服务都不可用。
第五层是责任人。谁查状态页,谁开支持工单,谁能降并发,谁能启用备用路线,谁负责对用户说明,都要提前定好。最糟糕的处理方式是五个人同时改五个变量,却没有人保存最早的 request_id。
还有一个容易忽略的控制是样本分层。值班时不要只看“今天 500 次数变多了”,要把失败按模型、端点、账号、地区、网关、SDK 版本和请求类型切开。只有某个模型和某条路径同时异常时,处理动作会和全量 500 峰值不同;只有大 payload 或工具调用失败时,也不应该把小请求一起降级。
常见问题
Claude API 500 是不是说明 prompt 写错了?
通常不是。HTTP 500 加 api_error 是内部服务器错误分支;prompt 格式、JSON 校验、认证、权限和账单问题一般会有更具体的 4xx 或权限类错误。先保存 request_id 和响应,再检查请求大小、工具调用和 payload 形状。
需要马上换 API key 吗?
不建议把换 key 当成默认动作。换 key 属于认证、权限或密钥泄露分支。干净的 500 api_error 先保存 request_id、状态时间和同一路径证据,否则换 key 会制造第二个变量。
重试几次比较安全?
用小预算,不用无限循环。很多场景可以从两到三次应用层尝试开始,并确认 SDK 是否已经内置重试。非幂等链路要更保守;同一路径持续返回 500 时应该升级,而不是继续加次数。
Claude Status 是绿色,就一定是我本地问题吗?
不是。绿色状态只是带日期的公开状态信号,不覆盖你的具体账号、模型、地区、网关、代理或请求形状。它只能告诉你不要默认归因到公开事故,接下来仍然要保存同一路径复现证据。
500 api_error 和 529 overloaded_error 是一回事吗?
不是。二者都可能让用户感觉“服务端失败”,但官方分支不同。500 api_error 是内部服务器错误分支,529 overloaded_error 更接近容量或过载压力。看到 529 时,重点应该转向降并发、退避和防止重试风暴。
Claude Code 里的 API Error 500 也按这个处理吗?
可以先按同一 API 分支处理,但要补充 Claude Code 自己的上下文。保存原始错误体、版本号、命令形状、request_id、是否能在 Workbench 或直接 API 复现,同时排除本地登录、工具执行和 MCP 层问题。
什么时候需要联系支持或内部升级?
当同一路径在小预算退避后仍连续返回干净的 500,或已经影响用户流程时,就该升级。证据包里放状态页时间、request_id、模型端点、调用路径、重试时间线、脱敏请求形状和影响范围,不要放密钥或完整私有 prompt。
可以直接切到别的供应商吗?
生产系统可以有备用路线,但不要在保存原失败证据之前切。先保留 request_id、状态时间和同一路径复现结果,再按业务连续性策略决定是否临时 fallback。否则问题恢复后,你无法判断是 Claude 恢复了、路径变了,还是请求变量变了。