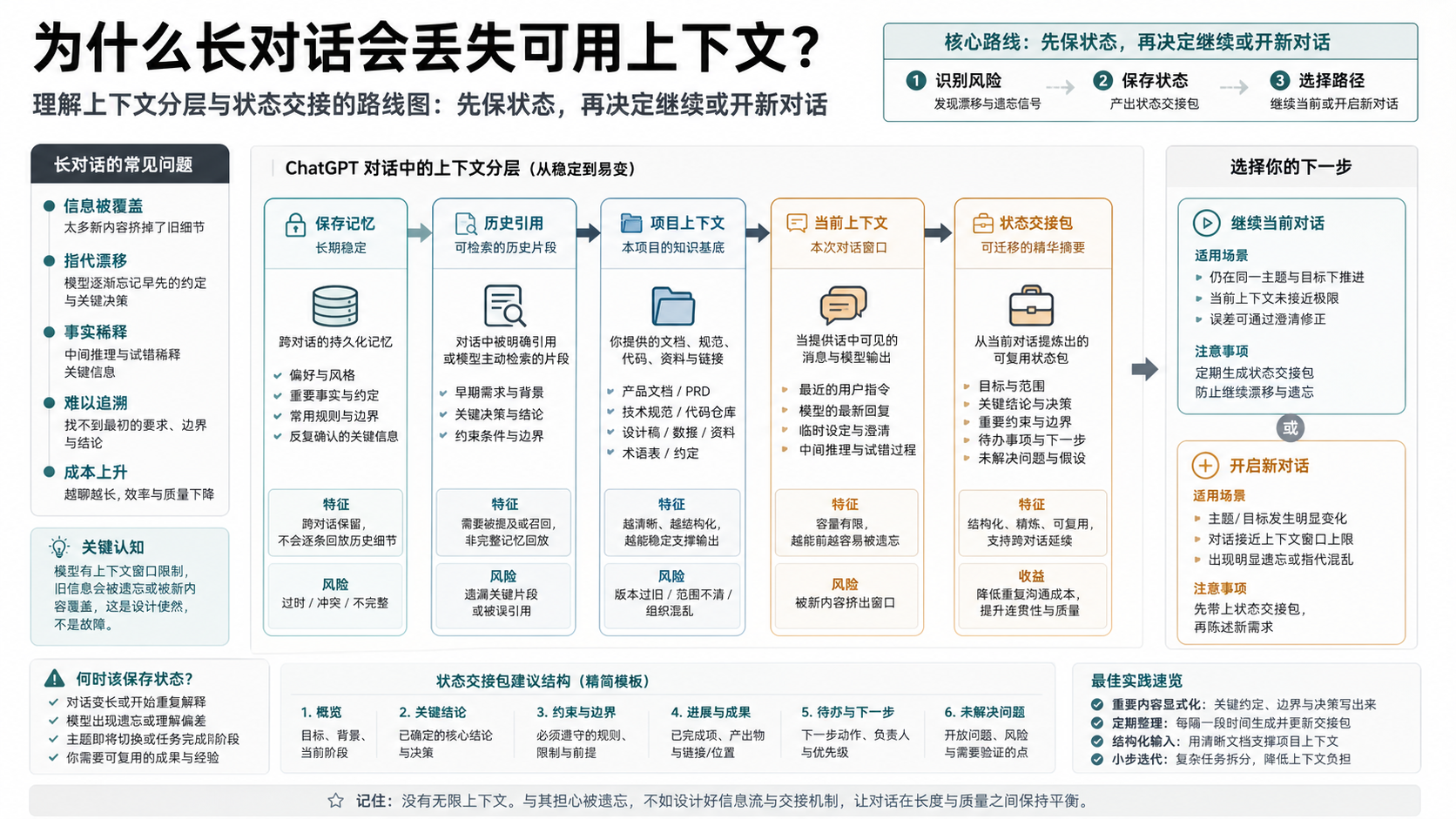
ChatGPT 的长对话变得不听前文,最危险的误判是把它全部归因于“记忆功能不好”。保存记忆能保留长期偏好和部分有用背景,历史引用能在合适时利用过去对话,但它们都不是把旧线程逐字重放给每一次回答。真正需要保护的是当前工作状态:目标、已经定下的方向、不能破坏的约束、还有效的资料、已经排除的方案、没解决的问题、下一步和停止规则。
先用下面的判断表把动作选出来:
| 现在的长对话表现 | 先做什么 | 停止规则 |
|---|---|---|
| 主线还稳定,只漏掉一个小约束 | 留在当前对话,把下一步说窄 | 同一个纠正失败两次就停止 |
| 里面有重要结论、资料、约束或版本选择 | 先做状态检查点,再继续 | 不要在没有检查点时要求大改写 |
| 反复推翻已经确认的方向,或混入旧分支 | 开新对话,用状态交接包接续 | 不要整段复制旧聊天记录 |
这个拆分比问“上下文窗口到底多大”更有用。窗口大小会随模型、套餐、模式和时间变化;而工作流原则更稳定:长期偏好放保存记忆,项目资料放 Project 或文件,当前决策放状态交接包,旧线程只承担短期协作,不要承担唯一档案。
如果你正在做写作、代码、研究或客户交付,最先保存的不是“聊天历史”,而是“接下来不能错的东西”。例如版本选择、明确否掉的方案、外部资料来源、必须保留的语气、不能新增的承诺、仍待确认的证据,这些都应该被写成当前状态。旧线程可以继续作为参考,但不应该继续决定什么是最新真相。
为什么长对话会开始丢上下文

可见聊天记录不是一个永久工作数据库。你在侧边栏里还能看到几十轮旧消息,不代表每一次新回答都会完整读取、理解并优先服从那些旧消息。一次回答真正能使用的是当时被放进工作上下文的材料,可能包括最近几轮、被系统选中的旧信息、保存记忆、项目指令、文件、工具状态和更高优先级的系统要求。旧记录还在,但它不一定都在回答的工作面上。
这就是很多长线程的体感来源。前二十轮里,ChatGPT 可能能记住你的写作风格、项目目标、弃用方案和细小格式要求。再往后,线程里堆进了新的文件、反复修改、旁支讨论、旧版本草稿和临时假设,它就可能重新提起一个已经排除的方案,或者把上一个版本的约束当成当前要求。你看到的是“它忘了”,底层更接近“重要状态只藏在长聊天里,没有被整理成当前回答必须遵守的状态”。
不要靠继续提醒来硬撑一个已经变浑的线程。提醒当然有用,但它只适合小修正。如果你每次都要先写一大段“不要忘了我们之前说过……”才能得到正常输出,当前线程已经不适合作为工作台。更好的做法是把可迁移的状态拿出来,把不可迁移的噪音留在旧线程里。
ChatGPT 记忆功能能修什么,不能修什么
OpenAI 的记忆说明把保存记忆和历史引用分开。保存记忆适合长期偏好、稳定事实和反复出现的个人背景,例如“我喜欢简洁的代码解释”“我的项目用这种命名方式”。历史引用可以让 ChatGPT 使用相关过去对话,但官方说明也明确它不会保留每个细节。这个边界很关键:记忆功能可以改善跨对话个性化,却不等于替你维护一个密集项目日志。
把所有东西都塞进保存记忆也不是好习惯。一次研究过程里的资料列表、十几轮争论后的产品判断、客户临时要求、没有确认的假设、旧版本方案,都不适合成为全账号长期记忆。它们应该进入项目文件、外部文档、任务卡片,或者被整理成只对下一次对话有效的状态交接包。
Temporary Chat 也要放在正确位置。它适合你不想使用或写入记忆的一次性问题、敏感探索或隔离测试;如果目标是延续一个长期任务,它通常不是正确入口。Project 则更适合重复工作:项目指令、相关文件、同一主题下的多个聊天可以聚在一起,但这仍然不代表每个旧回合都会被完整重放。
可以按这个表放状态:
| 状态类型 | 放哪里更合适 | 原因 |
|---|---|---|
| 长期偏好和稳定个人事实 | 保存记忆 | 应该影响很多未来对话 |
| 项目级规则、资料、角色和常用文件 | Project 或外部文件 | 应该跟任务绑定,而不是跟账号全局绑定 |
| 当前决定、约束、排除方案、下一步 | 状态交接包 | 新对话最需要马上遵守 |
| 敏感或一次性问题 | Temporary Chat | 需要隔离,不需要延续 |
| 整段旧聊天记录 | 通常不要搬运 | 噪音、旧方案和有效状态混在一起 |
继续、检查点,还是开新对话

判断标准不是“这个聊天已经有多少轮”,而是“下一步对状态准确性的要求有多高”。如果下一步只是把一段回答换成更短的版本,当前线程仍然服从主线,那就留在同一对话里,把请求写窄:只改示例,不改结构;只检查术语,不改结论;只输出下一段,不重写全文。
如果下一步会影响最终稿、代码方案、商业判断或客户交付,就先做检查点。检查点不是“总结一下我们聊了什么”,而是请模型提取当前仍有效的工作状态。生成后要人工检查,删掉旧分支,补上文件名、链接、版本、明确决策和不确定项。模型在长线程里已经开始混乱时,不能让它独自决定哪些信息是当前真相。
当同一个纠正失败两次、旧方案反复复活、文件版本被混用、回答前半段和后半段互相矛盾,或每次输出前都需要长提醒,就该开新对话。新对话的优势是干净,不是神奇。你必须在第一条消息里给它一个短而硬的状态包,否则它只是从空白处重新猜。
还有一个实用信号:如果你已经开始在每条提示前粘贴同一段防错说明,说明这段说明应该从聊天里移到状态包或项目指令里。反复提醒会让当前线程更长,也会把“纠正旧错误”变成新的噪音。把规则移出去,反而能让下一次回答更清晰。
如果你不确定该选哪条路,就先做检查点。检查点的成本低于重开工作流,也低于在错误线程里继续追加十几轮。它不会强迫你马上离开当前对话,却能在后面必须切换时保住核心状态。
对团队协作也是一样。交接包可以贴给同事、放进工单,或作为下一轮评审输入;一条超长聊天记录很难承担这种共享职责。开新对话不是放弃旧工作,而是把仍然有效的部分升级成可检查、可复制、可复用的当前状态。
这一步做对了,后续无论继续写、继续调试还是继续研究,都不再依赖某个已经变重的聊天窗口。它让上下文从“可能被想起”变成“必须被遵守”:先把状态拿稳,再让模型继续工作。否则,越聊越长只会让错误更难定位。
用状态交接包,不要只要一个总结

普通总结会讲故事,状态交接包只保留下一步必须执行的事实和规则。前者容易把旧讨论顺序带进新对话,后者把任务重置到一个可执行的当前状态。
可以在旧对话里这样要求:
text请为一个新的 ChatGPT 对话生成状态交接包。 只保留当前仍有效的信息: 1. 目标:我们要完成什么。 2. 当前决定:最新确认的方向。 3. 约束:必须遵守的风格、限制、排除项和边界。 4. 资料来源:仍然有效的文件、链接、数据、例子或引用。 5. 已排除方案:除非我重新要求,否则不要再打开的路径。 6. 待确认问题:仍不确定、需要证据或需要我选择的点。 7. 下一步:新对话第一件该做的事。 8. 停止规则:新对话不能擅自假设、扩写或改变的内容。 不要加入旧争论、重复纠正、过期草稿或废弃分支。 不确定的项目必须标注为不确定。
生成后再做一次人工修订。把“我们讨论了很多方案”改成“已排除方案:不要再走 A/B/C”。把“可能需要看看资料”改成“待确认问题:X 数据缺失,需要先查 Y 文件”。把“继续写”改成“下一步:只写第二节,保留表格,不新增产品推荐”。新对话需要的不是情绪化回忆,而是能立刻执行的状态。
检查交接包时,尤其要看三类错误。第一是把旧分支写成当前决定,例如“可以考虑使用插件”这种句子没有说明是否已经被排除。第二是把不确定项写得像事实,例如“这个限制应该是因为窗口满了”,如果没有证据,就要改成“可能原因,需复测”。第三是没有停止规则,导致新对话又开始自由扩写、换标题、补充未经确认的功能说明。一个好的交接包应该让新对话少猜,而不是让它继续解释旧线程为什么混乱。
如果任务很重要,可以把交接包复制到外部文档,再把文档当成后续唯一真相。这样做有两个好处:你可以在 ChatGPT 之外审阅它,也可以在新对话犯错时直接指出“以这个状态包为准”。长线程里最糟糕的情况不是丢掉所有信息,而是同时保留了正确结论、旧结论和临时假设,模型无法判断哪个版本优先。外部状态包能把优先级重新变清楚。
团队场景里,这个外部状态包还应该记录负责人、文件版本和最后确认时间。否则,新对话虽然干净,同事接手时仍然不知道哪些判断已经锁定、哪些只是旧线程里的临时想法。把这些字段写清楚,状态包才真正从“聊天总结”变成可交付的工作输入。
一个紧凑版本可以这样写:
text目标: - 完成一份解释 ChatGPT 长对话漂移及交接方法的实用内容。 当前决定: - 核心不是记忆开关,而是保存记忆、项目上下文、当前上下文和状态交接的分层。 约束: - 不能说 Memory 会重放每个旧回合。 - 不写固定上下文窗口数字,除非有当天官方来源。 - 不推荐第三方浏览器扩展。 资料来源: - OpenAI Memory FAQ。 - OpenAI Projects 帮助。 - 需要模型窗口数字时再查当前模型帮助。 已排除方案: - 泛泛的记忆设置教程。 - 只建议“重新开一个聊天”。 - 工具清单或扩展清单。 待确认问题: - 如果用户症状是回答中断或报错,先检查是否属于故障分支。 下一步: - 写“继续、检查点、开新对话”的判断部分。 停止规则: - 不把主题改成模型排行榜。 - 不加没有当前来源的功能或套餐承诺。
Memory、Project、文件和当前线程各放什么
保存记忆适合跨很多对话都成立的个人上下文。写作偏好、常用语言、长期项目身份、稳定术语风格可以放进去。客户隐私、一次性数据、未确认结论、密集项目决策不适合放进去,因为它们不应该影响所有未来聊天。
Project 更像任务容器。如果你经常围绕同一个代码库、内容集群、产品发布、研究包工作,Project 指令和文件会比一个超长对话更可靠。它把资料和规则放在任务范围内,而不是让它们漂在全局记忆里。
外部文件仍然是重要工作的最稳来源。仓库文件、需求文档、表格、工单、研究包、版本说明都能被人检查、回滚和引用。只存在于聊天记录里的“真相”很脆弱,一旦长线程开始混淆,你就很难判断哪一轮才是最新。
当前线程适合即时协作:下一段改写、下一次对比、下一步 debug、下一轮头脑风暴。它不适合承担档案职责。只要它开始背负太多旧状态,就应该把当前状态移出去,让新线程只拿必要信息。
实际使用时,可以把这四个位置当成分工,而不是互相替代。保存记忆回答“我长期是什么偏好”;Project 回答“这个任务长期有哪些资料和规则”;文件回答“可审计的事实在哪里”;状态交接包回答“下一次对话从哪个状态继续”。如果把这些都压进一个长聊天里,任何一次分支讨论都可能污染后续回答。如果把它们分开,哪怕某个聊天开始漂移,你仍然有干净的资料、明确的项目规则和可复制的当前状态。
这也解释了为什么“让 ChatGPT 总结一下旧对话”经常不够。总结会倾向于保留叙事连续性,甚至把已经废弃的探索写得很重要;状态交接包则要保留执行连续性。前者像会议纪要,后者像交班单。长对话开始不稳定时,你需要的是交班单。
什么时候不是正常的上下文漂移
如果 ChatGPT 是回答中途断掉、出现 stream error、生成失败,优先走错误恢复分支,而不是继续研究记忆功能。可以转到 ChatGPT 消息流错误恢复,先保留部分回答、缩短输入、隔离网络和浏览器因素。
如果问题出现在图片、文件、附件之后,也不要马上把它归因于长对话。按钮不见、上传被拒、图片被忽略、文件限制、工作区设置,属于上传和文件链路。对应的分支是 ChatGPT 图片上传故障排查。
如果你怀疑是产品故障,先查状态,再决定是否等待、换浏览器、缩短请求或开新对话。状态页不能证明你的单个线程健康,但能改变下一步动作:先保存工作,再复测。上下文漂移的特征是产品还能正常回答,只是不再稳定服从旧决策;故障的特征是跨干净对话、设备或网络也出现失败。
还有一种容易混淆的情况是“旧线程太重导致界面慢”。页面滚动卡顿、输入延迟、切换消息很慢,可能和浏览器渲染、附件、插件、网络或客户端状态有关;模型在回答内容上忘记约束,则更接近状态问题。你可以用一个小测试分开它们:把当前任务压缩成状态交接包,开一个干净对话,只要求完成一个小步骤。如果新对话能稳定执行,旧线程就不该继续承担主工作台;如果干净对话也失败,再看账号、网络、状态或文件链路。
常见问题
ChatGPT Memory 会记住长对话里的所有内容吗?
不会。保存记忆能保留长期偏好和一些稳定事实,历史引用能使用相关过去对话,但它们都不应该被当成旧线程逐字回放。长对话仍然可能因为当前上下文有限、旧分支太多或状态没有结构化而漂移。
ChatGPT 开始忘前文时要不要直接开新对话?
不要空着开。先判断当前线程是否还能服从主线;如果还能,只做窄修正。如果重要状态不能丢,先做检查点。如果重复纠正仍失败,再把状态交接包贴进新对话。
Project 能替代状态交接包吗?
不能完全替代。Project 适合长期资料、指令和同一任务范围内的上下文,但当前决定、已排除方案、下一步和停止规则仍然要写清楚。Project 是容器,状态交接包是下一次对话的执行起点。
状态交接包应该多长?
短到可以一屏读完,具体到足以执行下一步。最重要的是目标、当前决定、约束、资料来源、已排除方案、待确认问题、下一步和停止规则。不要把旧争论、情绪评价和过期草稿搬进去。
更大的上下文窗口能彻底解决吗?
更大的窗口会有帮助,但不会消除状态管理需求。长线程仍会积累旧分支、互相冲突的指令和过期草稿。窗口数字也会随模型、套餐和模式变化,不能当成长期工作流的核心保障。
这会不会只是 ChatGPT 出故障?
如果回答失败、停止、报错,或者干净对话和不同设备上也异常,要先按故障处理。如果产品能正常输出,只是老线程越来越难服从早先决定,通常更像上下文漂移。两种问题的动作不同,先分支诊断再重建工作流。