
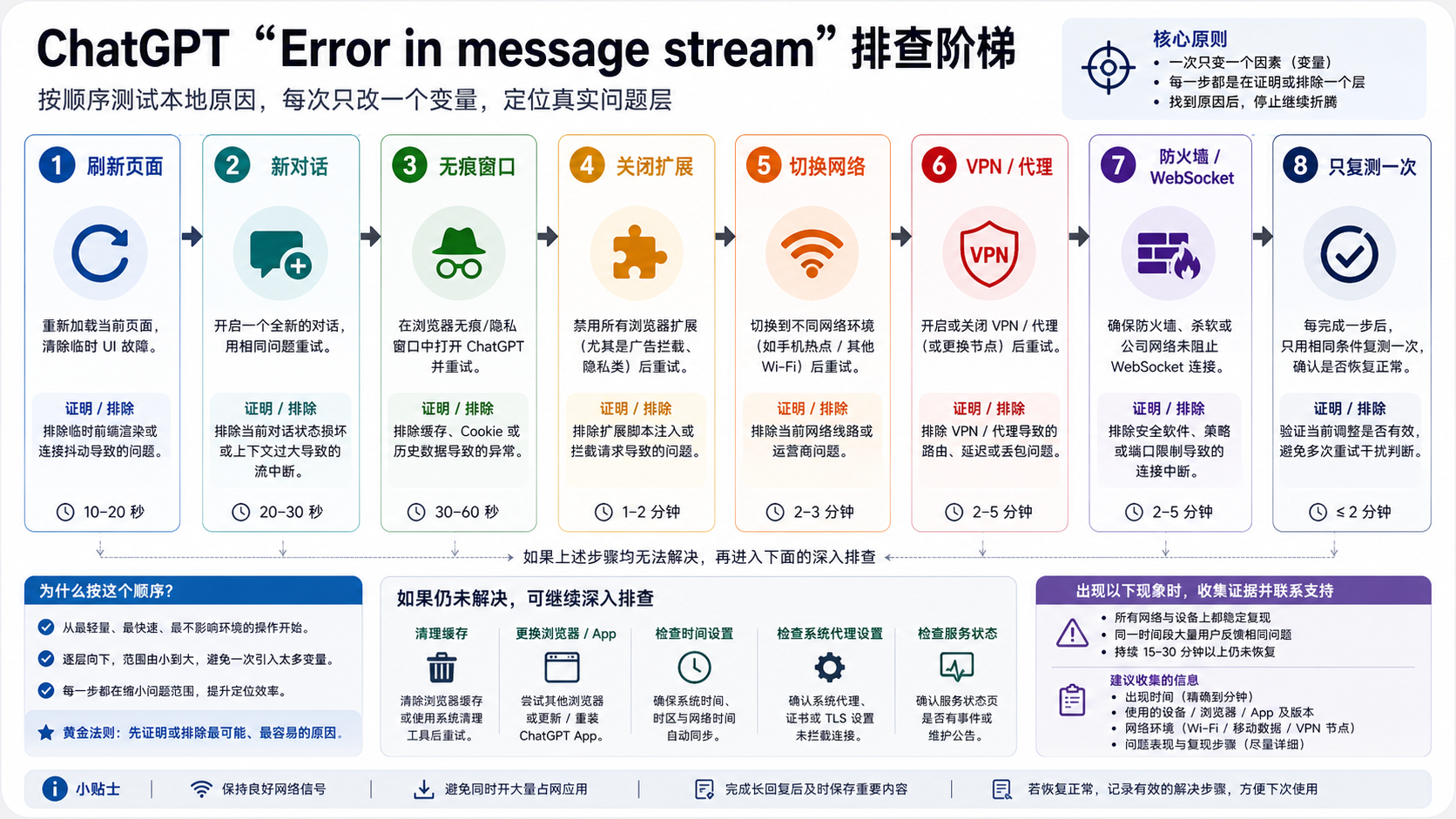
ChatGPT 出现 “Error in message stream” 时,意思通常是回答在流式输出完成前中断了。先复制已经生成的内容和原始提示词,再看 OpenAI Status;如果状态没有解释问题,就用一个干净的新对话逐步测试会话、浏览器、网络、长提示、附件和 API 分支。这样做的目的不是把所有修复动作都试一遍,而是尽快知道应该等待、重开对话、处理本地环境、缩短请求、去掉上传文件,还是收集证据联系支持。
这个错误最容易被误判成两个极端:一种是马上认定 “OpenAI 挂了”,另一种是马上清缓存、关插件、换浏览器、换网络。更稳的做法是先保住当前工作,再让每一步都回答一个问题:状态是否正在影响 ChatGPT?当前对话是否坏了?浏览器或 App 是否还能完成一个短回答?网络是否能保持 WebSocket 或长连接?原请求是不是太长、带附件、或者属于开发者集成?
先按下面的恢复表选择一个分支。
| 你看到的情况 | 第一动作 | 验证方式 | 停止规则 |
|---|---|---|---|
| OpenAI Status 有相关 ChatGPT 事件 | 保存半截回答,等待事件缓解后用新对话重试 | 状态改善后短问题能正常完成 | 事件期间不要反复清本地设置 |
| 同一个对话连续中断 | 复制提示词和已生成内容,开新对话让它从断点继续 | 新对话能完成,或给出更清晰错误 | 不要在旧线程里连续点 regenerate |
| 无痕窗口、另一个浏览器或手机 App 可以完成 | 只处理当前浏览器配置、扩展、会话或缓存 | 同一个短提示在干净环境能输出完 | 不要在没有证据时重置所有浏览器 |
| 换网络后结果不同 | 检查 VPN、代理、防火墙、TLS 检查、公司网络策略 | 手机热点或家庭网络能完成同一短提示 | 交给网络或 IT 处理,而不是继续改提示词 |
| 长提示、长上下文、文件或图片任务更容易失败 | 先跑一个无附件短提示,再拆分原任务 | 短提示成功,原任务失败 | 把它当成请求复杂度或附件分支 |
| 自己的应用或 API 流式输出失败 | 看错误类型、request ID、日志、超时和重试策略 | ChatGPT 网页与 API 表现不同 | 不要用网页端清缓存来修 API 集成 |
如果一个分支已经给出证据,就停在那个分支继续处理。所有分支都无法定位时,再整理时间、时区、ChatGPT 表面、浏览器或 App、对话链接、截图、控制台或 HAR、附件情况,以及 API request ID。
先看 OpenAI Status,因为它决定该等还是该排查
OpenAI Status 不是文章顶部的装饰动作。它决定你接下来是不是应该继续本地排查。2026 年 5 月 16 日实时核对时,OpenAI Status 返回 All Systems Operational;这仍然不能证明你的具体对话、账号、模型、上传路径或应用集成一定健康。因此,状态信息要带日期理解,并且每次排查都应重新打开实时状态页。
如果状态页正在显示影响 ChatGPT、某个模型、上传、图片或 API 的事件,最安全的动作是保存当前内容,等状态恢复后再用新对话重试。不要在服务事件期间连续刷新旧对话,也不要马上清掉浏览器数据,因为这些动作不能证明本地环境有问题,还可能让半截回答丢失。

如果状态页看起来正常,也不能反过来证明你的账号、模型、工作区、文件上传或当前会话一定正常。状态页是整体信号,不是单个会话诊断书。它只会把你带到下一步:用新对话、干净浏览器、第二网络、短提示和无附件请求做分支测试。
还有一个细节容易被忽略:状态页只适合解释“是否可能有服务端影响”,不适合替你判断“应该清哪一项本地设置”。如果状态页有事件,正确动作通常是少改动、等恢复、保留证据;如果状态页没有事件,正确动作也不是马上做最重的本地修复,而是先做最小可逆测试。这样无论最后是否需要联系支持,都能说明每一步为什么做、证明了什么、还剩哪些未知。
状态页清晰时,最容易犯的错是把所有责任都推给本地环境。更准确的结论只是“公开状态没有给出等待理由”。接下来仍然要用新对话、短提示和第二网络证明问题在哪,而不是直接认定本地设置已经坏掉。
用新对话判断是不是旧线程坏了
当前对话连续报错时,最有价值的动作不是继续点 regenerate,而是把工作搬到一个干净线程里验证。复制原提示词,复制已经生成的可用段落,新开一个对话,然后让 ChatGPT 从保存的内容继续。第一次测试要短,不要把旧线程里所有附件、上下文和复杂要求一次性塞回去。
如果新对话能继续输出,旧线程就是主要分支。长上下文、工具状态、附件状态、过期会话或中途失败的生成状态都可能让一个具体线程变脆。此时应该继续在新对话里恢复工作,只粘贴真正需要的上下文。旧对话可以留作参考,但不要再把它当成可靠生成环境。
如果新对话也出现同样提示,结果更像浏览器、App、网络、请求复杂度、附件或账号侧问题。保留新对话的表现,因为它比旧长线程更适合当证据。向支持说明 “新对话、短提示也失败” 比只说 “原来的聊天坏了” 更容易定位。
迁移到新对话时也不要把所有旧上下文一次性恢复。先让 ChatGPT 继续最小的一段工作,例如完成一个段落、一个函数、一个表格或一个结论。确认新对话稳定后,再逐步补充背景。这样可以避免把旧线程里的长上下文、附件状态或过期工具状态重新带入新线程,导致你以为新对话也坏了。
浏览器和 App 只在控制测试失败后再动
清缓存、禁扩展、重装 App 是常见动作,但不应该是第一动作。它们会改变太多变量。更好的本地测试是先在同一个浏览器的新对话里发一个短问题,例如:
text用三句话解释为什么流式回答可能在完成前中断。
如果这个短问题能完成,说明基础会话还能流式输出,原问题更可能出在旧对话、长提示、附件或特定任务。此时继续折腾浏览器没有太大收益。应该回到原任务,把提示拆短、先不要带附件、让 ChatGPT 从保存的断点继续。
如果短问题在同一浏览器也失败,再试无痕窗口或另一个浏览器。无痕窗口能工作时,常见原因是扩展、脚本拦截、隐私工具、缓存站点数据、登录会话、VPN 或代理工具。只处理当前浏览器画像,不要同时改网络、账号和提示词。桌面 App 失败但网页可用时,先用网页恢复工作,再回头处理 App;网页失败但手机 App 可用时,也先把输出救回来。
网络和 WebSocket 分支要单独测试
ChatGPT 页面能打开,不等于长回答一定能稳定传完。流式回答依赖更长时间的连接,网络代理、防火墙、TLS 检查、企业安全网关、VPN、DNS 和空闲超时都可能让正常网页加载与流式输出表现不同。OpenAI 的网络建议也把安全 WebSocket、代理和防火墙列为需要关注的路径。
最简单的证据是第二网络。同一个账号、同一个浏览器、同一个短提示,在办公室 Wi-Fi 上失败,在手机热点上成功,就不要继续把问题归因于提示词。更可能是公司网络、代理、防火墙、内容过滤、TLS 检查或长连接空闲超时。反过来,家庭网络失败而公司网络成功,也说明路线差异值得记录。
VPN 既可能修复,也可能制造问题。不要只说 “开 VPN” 或 “关 VPN”。分别测试 VPN 开、关、换节点后的短提示流式输出,并记录哪条路线能完成。公司环境中,如果长回答总是在固定秒数后中断,可以把时间点、网络、浏览器、控制台错误和 OpenAI 相关域名需求发给 IT,而不是继续刷新 ChatGPT。
长提示和长上下文要拆成可恢复的任务
很多 “Error in message stream” 发生在长提示、长上下文、文件密集、代码重构、长文写作或多步骤分析里。即便服务正常,一个庞大的请求也会让诊断变困难,因为它同时包含会话状态、上下文长度、生成时间、工具状态和附件路径。短提示测试能告诉你基础输出是否还活着。
如果短提示成功,原提示失败,就把任务拆开。先要提纲,再要一节;先让它继续上一个完整段落,不要要求重写全文;代码任务先让它处理一个文件或一个函数;数据分析先让它确认输入结构,再要结论。恢复半截回答时,可以粘贴最后一个完整段落或最后一个完整代码块,并明确说 “从这里继续,不要重写前文”。
这里的停止规则很关键:短提示能完成、完整长提示失败时,不要再把它当作全站故障。应该减少变量,而不是继续刷新。一次只改变一个条件:去掉附件、缩短上下文、换新对话、拆成章节、降低一次输出长度。这样才能知道哪一步让流式输出恢复。
附件、图片和文件失败要走独立分支
文件、图片、表格和 PDF 可能让同一个可见错误背后变成另一条链路。文件可能过大、格式不合适、上传状态失效、工作区策略拦截、额度或存储限制触发,也可能是图片生成或编辑表面的问题,而不是普通文字对话坏了。
先跑一个无附件短提示。如果它能完成,再移除文件,用同一个需求的文字版试一次;然后再换一个已知正常的小文件或小图片。只有无附件成功、带附件失败时,才进入附件分支。此时要看文件类型、大小、账号额度、工作区策略、上传次数提示、是否有 storage 或 cap 信息,以及失败上传是否可能消耗上传窗口。

如果问题其实是图片生成或图片上传,就不要让它吞掉普通 message stream 排查。图片生成失败可以看本地的 ChatGPT 图片生成排查;图片不能被 ChatGPT 接收时,看 ChatGPT 图片上传排查。先用无附件控制测试证明归属,再进入对应页面,读者不会在通用清单里绕圈。
开发者和 API 流式错误不要套用网页端修法
自己的应用里出现流式输出中断,和 ChatGPT 网页对话中断不是同一个诊断表面。开发者需要看的不是浏览器缓存,而是错误类型、request ID、endpoint、model、日志、超时、代理、重试策略、SSE 或 WebSocket 处理、服务器缓冲、客户端断开、以及最小复现请求。
OpenAI 开发者错误文档把连接错误、超时、内部服务错误、速率限制和请求错误分开处理。连接错误可能是网络或代理,超时可能需要拆请求或调整客户端超时,速率限制需要退避和配额判断,bad request 要修 payload,内部服务错误则要结合状态和重试。把这些问题统一写成 “ChatGPT message stream error” 会让排查更慢。
开发者可以用两个问题分界:同一个账号在 ChatGPT 网页能不能完成一个短回答?同一个模型或 endpoint 在应用里是否带着 request ID 和错误类型失败?网页正常、应用失败时,应调试集成。网页和 API 都在相关状态事件中失败时,保留日志并等待恢复。只有最小请求也失败,才继续向服务侧升级。
最后收集证据,而不是继续猜
当状态、新对话、浏览器、App、网络、短提示、附件和 API 分支都没有给出明确答案时,证据包比继续尝试更有用。普通用户至少应记录时间和时区、ChatGPT 表面、浏览器或 App、模型或模式、状态页是否有事件、对话链接、截图、哪个分支成功或失败、是否涉及上传或图片。
网页端持续失败时,控制台错误或 HAR 可以帮助支持判断,但不要把私人提示词、客户文件、敏感截图、token、cookie 或业务数据随意发出。开发者应额外提供 request ID、endpoint、model、错误类、客户端库、超时设置、重试策略和最小可复现请求。证据越短、越可复现,越容易得到有效回应。
如果你在团队或公司环境里排查,还要把个人账号和受管理账号分开记录。同一设备、同一网络、同一短提示在个人账号正常,在工作区账号失败,说明管理员策略、数据控制、模型权限或文件权限可能参与了问题。不要为了验证而把客户资料或内部文件转到个人账号;用无敏感内容的短提示和小测试文件完成对比即可。
证据包也要保留失败前后的顺序。先状态、再新对话、再浏览器、再网络、再附件或 API,这个顺序本身就是诊断价值。如果记录只剩下一堆已做动作,支持人员很难判断哪一步改变了结果;如果记录有顺序,就能看出问题是在服务恢复后消失、在无痕窗口消失、在第二网络消失,还是只在附件加入后出现。
预防也很实际。长任务分段输出,重要内容定期保存到聊天外部,文件任务先用小样本确认上传链路,公司网络先记录一条可工作的路线。下一次同样错误出现时,你就不需要重新猜一遍。
常见问题
“Error in message stream” 是什么意思?
它表示 ChatGPT 的回答在流式输出完成前中断。它是用户界面里的可见症状,不是稳定的官方错误码。可能原因包括服务状态、旧对话损坏、浏览器或 App 状态、网络或 WebSocket 中断、长请求、附件、图片或开发者 API 集成。
看到这个提示要不要刷新?
先保存半截回答和提示词,再考虑刷新。刷新可能有用,但如果它删除了唯一一份未完成内容,就会让恢复更麻烦。保存后先看 OpenAI Status,再用新对话和短提示判断问题分支。
怎么判断是不是 ChatGPT 服务故障?
打开 OpenAI Status,查看 ChatGPT、模型、上传、图片或 API 是否有相关事件。有事件时等待和稍后重试通常更合理。状态清晰时,继续测试新对话、浏览器、网络、短提示、附件和 API。
为什么无痕窗口能解决?
无痕窗口减少了扩展、缓存站点数据、脚本拦截、隐私工具和部分登录状态的影响。如果无痕窗口能完成同一个短提示,问题更可能在当前浏览器画像,而不是 ChatGPT 全局服务。
长提示会触发这个错误吗?
会。长提示、长上下文、多附件和长输出会把一次请求变得更脆。短提示成功而完整请求失败时,应该拆任务、从断点继续、减少附件或缩短输出,而不是继续刷新。
图片上传或图片生成也按这个流程处理吗?
先用无附件短提示确认。如果文字对话正常,只有文件、图片或生成任务失败,就进入上传或图片分支。这样能避免把文件大小、额度、工作区策略或图片工具问题误判成普通对话流式错误。
API 开发者应该先看什么?
先看错误类型、request ID、日志、endpoint、model、超时、重试和传输层。ChatGPT 网页端的刷新、清缓存和无痕窗口不能直接修复 APIConnectionError、APITimeoutError、RateLimitError、BadRequestError 或服务端内部错误。
什么时候联系支持?
当状态、新对话、浏览器或 App、第二网络、短提示、附件和开发者分支都无法定位时,再联系支持。附上时间、时区、表面、浏览器或 App、对话链接、截图、分支测试结果、控制台或 HAR 证据,以及 API request ID。