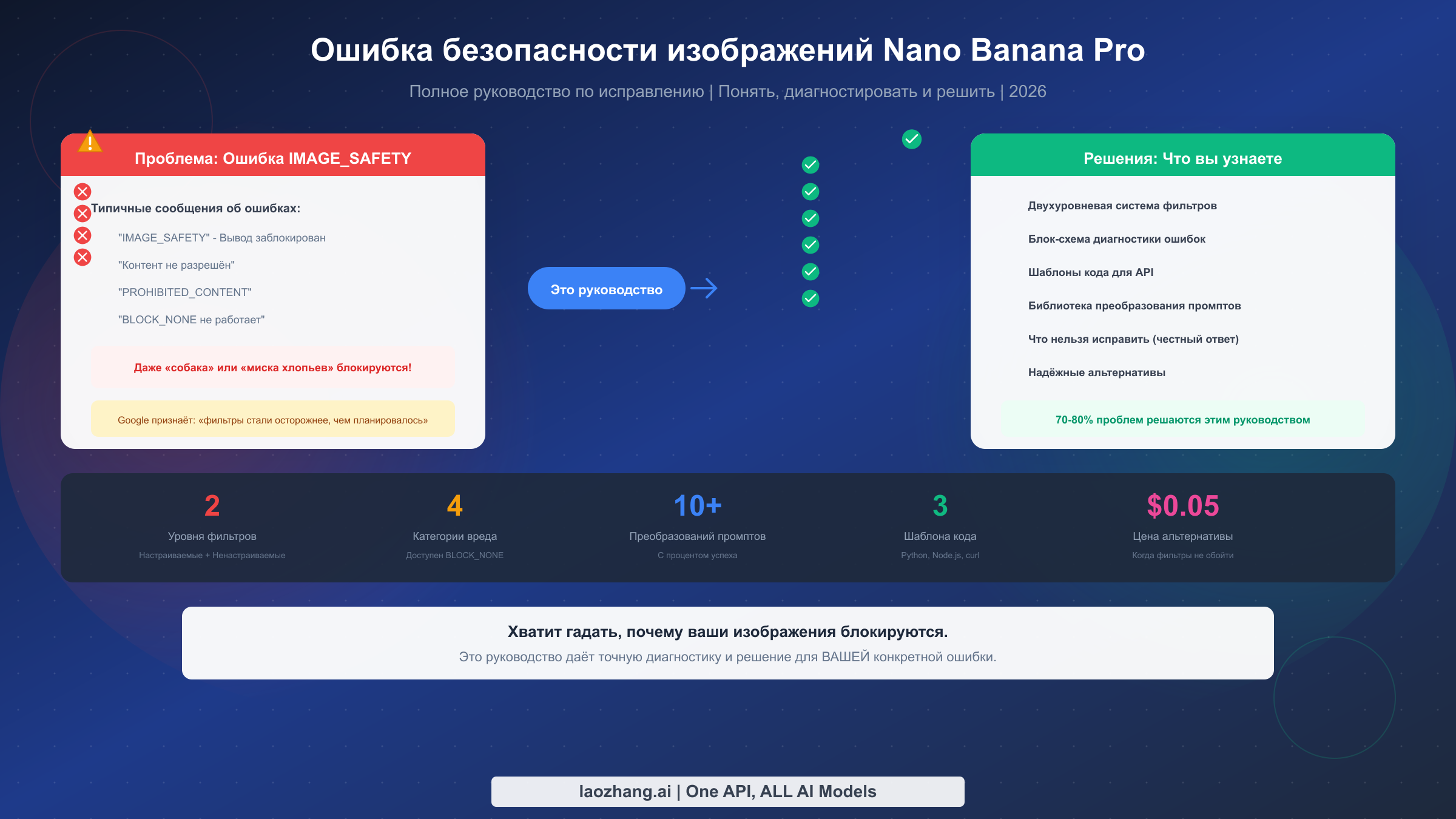
Ошибка IMAGE_SAFETY в Nano Banana Pro возникает, когда фильтры безопасности Google блокируют вывод генерации изображений, даже для совершенно легитимного контента. Это происходит потому, что Gemini имеет два отдельных уровня фильтров: настраиваемые параметры безопасности (на которые влияет BLOCK_NONE) и ненастраиваемые выходные фильтры (которые невозможно отключить через какие-либо настройки API). Google публично признал, что эти фильтры «стали гораздо более осторожными, чем мы планировали», вызывая ложные срабатывания на безобидном контенте, таком как простые запросы «собака» или «миска хлопьев».
Если вы видите сообщения об ошибках типа «IMAGE_SAFETY» или «Ответ не может быть завершён, поскольку сгенерированные изображения могут содержать небезопасный контент», вы не одиноки. Тысячи разработчиков ежедневно сталкиваются с этими ошибками, и разочарование усугубляется кажущейся случайностью возникновения блокировок.
Это руководство предоставляет точную диагностику и решение для ВАШЕЙ конкретной ошибки, с готовым кодом и трансформациями промптов, которые достигают 70-80% успешности для легитимного контента. Вы узнаете критическую разницу между настраиваемыми и ненастраиваемыми фильтрами безопасности, получите готовые шаблоны кода для Python, Node.js и REST API, а также получите доступ к проверенной библиотеке трансформаций промптов с документированными показателями успешности.
Почему ваши изображения блокируются (реальная правда)
Когда ваш невинный запрос на генерацию изображения блокируется с ошибкой IMAGE_SAFETY, естественная реакция — это разочарование. Вы знаете, что ваш промпт совершенно безобиден, но система обращается с ним так, будто вы запрашиваете что-то неуместное. Понимание причин — это первый шаг к решению проблемы.
Система безопасности изображений Google была разработана для предотвращения генерации вредоносного контента, но реализация имеет существенные проблемы. В обсуждениях на Discord Google AI Studio и различных форумах разработчиков представители Google признали, что фильтры стали «гораздо более осторожными, чем мы планировали». Эта чрезмерная осторожность означает, что система часто блокирует совершенно легитимные запросы.
Проблема заключается в том, как система безопасности оценивает контент. Вместо понимания контекста и намерения она сопоставляет паттерны с широким набором триггеров. Запрос «спящий человек» может вызвать опасения по поводу уязвимости или неуместных сценариев, хотя пользователь просто хочет мирную иллюстрацию спальни. Запрос «собака» без дополнительного контекста может быть заблокирован, потому что система не может определить, какое изображение будет создано.
Такое поведение — не ошибка в вашем коде или конфигурации API. Это фундаментальная характеристика работы Nano Banana Pro и лежащих в основе моделей генерации изображений Gemini. Фильтры работают на нескольких уровнях, и не все из них можно контролировать через настройки API. Для комплексного подхода к устранению других проблем Nano Banana Pro смотрите наше полное руководство по устранению неполадок.
Что делает это особенно раздражающим для разработчиков — это непоследовательность. Один и тот же промпт может успешно выполняться в один момент и терпеть неудачу в другой. Это происходит потому, что система имеет вероятностные элементы и может по-разному оценивать контент в зависимости от различных факторов, включая нагрузку на сервер и состояние модели.
Экономическое влияние этих чрезмерно агрессивных фильтров реально. Разработчики сообщают, что тратят часы на устранение неполадок того, что изначально считают собственной ошибкой конфигурации. Команды создают обходные пути, сложную логику повторных попыток или полностью отказываются от Nano Banana Pro для случаев использования, которые должны работать идеально. Фильтры затрагивают как пользователей бесплатного уровня, так и платных клиентов API, хотя некоторые разработчики сообщают о немного различном поведении для разных типов аккаунтов.
Понимание этого контекста помогает установить реалистичные ожидания. Проблема не в том, что вы делаете что-то неправильно. Проблема в том, что система безопасности Google в настоящее время настроена на максимальную осторожность, а не на оптимальный пользовательский опыт. Это может улучшиться со временем, но до тех пор вам нужны практические решения.
Понимание двухуровневой системы фильтров безопасности

Ключ к решению ошибок IMAGE_SAFETY — понимание того, что Nano Banana Pro использует двухуровневую систему фильтров безопасности. Эти уровни работают независимо, и ваша конфигурация API может влиять только на один из них.
Уровень 1 состоит из настраиваемых параметров безопасности. Это четыре категории вреда, которые вы можете контролировать через API: HARM_CATEGORY_HARASSMENT, HARM_CATEGORY_HATE_SPEECH, HARM_CATEGORY_SEXUALLY_EXPLICIT и HARM_CATEGORY_DANGEROUS_CONTENT. Когда вы устанавливаете их на BLOCK_NONE или любой другой порог, вы регулируете, насколько строго этот уровень фильтрует контент. Эти настройки влияют на фильтрацию входных данных и некоторую оценку выходных данных, и их можно полностью отключить для целей разработки и тестирования.
Уровень 2 — это место, где возникает большинство ошибок IMAGE_SAFETY. Этот уровень включает ненастраиваемые фильтры, которые невозможно отключить через какие-либо настройки API. К ним относятся выходная фильтрация IMAGE_SAFETY, обнаружение PROHIBITED_CONTENT, блокировка CSAM (материалов сексуального насилия над детьми) и защита SPII (конфиденциальной персональной идентифицирующей информации). Google поддерживает эти фильтры как всегда активную защиту независимо от вашей конфигурации API.
Эта двухуровневая архитектура объясняет, почему установка BLOCK_NONE не всегда работает. Когда вы настраиваете safety_settings с BLOCK_NONE для всех категорий вреда, вы успешно отключаете Уровень 1. Ваш промпт проходит без блокировки на стороне входа. Однако затем сгенерированное изображение сталкивается с оценкой Уровня 2. Если выходные данные запускают фильтры IMAGE_SAFETY или PROHIBITED_CONTENT, ваш запрос не выполняется, несмотря на «отключение» настроек безопасности.
Это различие важно, потому что оно определяет ваш путь к решению. Если вы получаете ошибки HARM_CATEGORY, вы можете исправить их с помощью конфигурации API. Если вы получаете ошибки IMAGE_SAFETY, вам нужен prompt engineering или альтернативные провайдеры. Многие разработчики тратят часы, пытаясь исправить блокировки Уровня 2 решениями Уровня 1.
Понимание этой архитектуры также объясняет наблюдаемую непоследовательность. Уровень 1 работает с вашим входным текстом, который детерминирован. Уровень 2 работает со сгенерированными изображениями, которые варьируются каждый раз из-за генеративной природы модели. Один и тот же промпт может создать немного другое изображение, которое запустит или обойдёт выходные фильтры.
Чтобы проиллюстрировать, как взаимодействуют уровни, рассмотрим этот сценарий: Вы отправляете запрос на «бизнесмен в костюме». Уровень 1 проверяет ваш текстовый промпт и не находит ничего предосудительного в четырёх категориях вреда. Ваш запрос проходит. Затем модель генерирует изображение. Уровень 2 проверяет само сгенерированное изображение, а не ваш текст. Если сгенерированное изображение случайно изображает что-то, что запускает классификатор IMAGE_SAFETY (возможно, поза или композиция напоминает что-то отмеченное в обучающих данных), запрос не выполняется, хотя Уровень 1 был полностью пройден.
Эта фильтрация на уровне изображения объясняет, почему prompt engineering работает. Изменяя ваш промпт, вы влияете на то, что генерирует модель. Если вы можете направить модель к генерации изображений, которые выглядят явно иллюстрированными, художественными или мультяшными, эти изображения с меньшей вероятностью запустят выходные фильтры, предназначенные для обнаружения фотореалистичного проблемного контента.
Чувствительность порогов также различается между уровнями. Пороги Уровня 1 (BLOCK_NONE, BLOCK_LOW_AND_ABOVE, BLOCK_MEDIUM_AND_ABOVE, BLOCK_HIGH_AND_ABOVE) явные и контролируемые пользователем. Уровень 2 работает с внутренними порогами, которые Google не раскрывает. Некоторые пользователи предполагают, что эти пороги могут варьироваться в зависимости от типа аккаунта, истории использования или условий сервера, хотя Google это не подтвердил.
Диагностика вашего конкретного типа ошибки
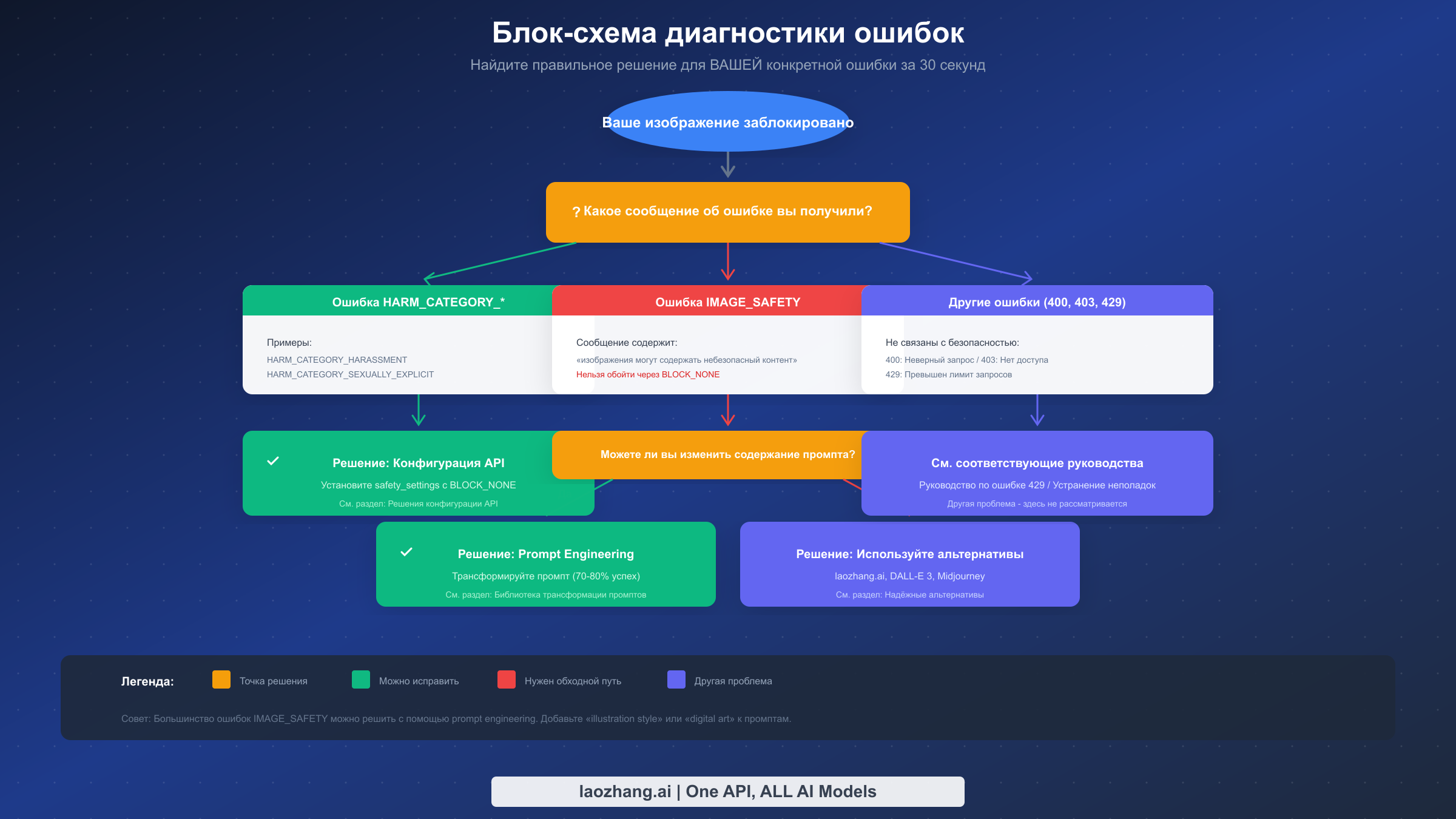
Прежде чем применять какое-либо решение, вам нужно точно определить, с каким типом ошибки вы столкнулись. Разные ошибки требуют разных решений, и применение неправильного исправления тратит время и добавляет разочарование.
Когда вы получаете ошибку от Nano Banana Pro, внимательно проверьте ответ. Структура ошибки обычно включает поле finishReason и, возможно, массив safetyRatings. Конкретные значения говорят вам, какой уровень блокирует ваш контент.
Если вы видите finishReason: «SAFETY» с safetyRatings, показывающими записи HARM_CATEGORY с рейтингами вероятности HIGH, вы попадаете на блокировки Уровня 1. Это настраиваемые фильтры, и вы можете решить проблему, настроив safety_settings в вызове API. Решение простое: установите соответствующие категории вреда на BLOCK_NONE.
Если вы видите finishReason: «IMAGE_SAFETY» или сообщение, содержащее «сгенерированные изображения могут содержать небезопасный контент», вы попадаете на блокировки Уровня 2. Их невозможно решить через конфигурацию API. Ваши варианты — prompt engineering или использование альтернативных провайдеров.
Если вы видите PROHIBITED_CONTENT, система определила, что ваш запрос попадает в категории, которые всегда блокируются. Обычно это контент, который нарушает условия обслуживания на фундаментальном уровне. Prompt engineering может работать или не работать в зависимости от того, почему контент был отмечен.
Коды ошибок типа 400 (Bad Request), 403 (Forbidden) или 429 (Too Many Requests) указывают на совершенно другие проблемы. Они не связаны с безопасностью. Ошибка 400 обычно означает неверный формат запроса или параметры. Ошибка 403 указывает на проблемы с разрешениями или API-ключом. Ошибка 429 означает, что вы превысили лимиты запросов, что является проблемой квоты, а не фильтрации контента.
Процесс диагностики должен занимать менее 30 секунд. Проверьте ответ об ошибке, определите тип блокировки и перейдите к соответствующему разделу решения. Если вы получаете блокировки Уровня 1, переходите к Конфигурации API. Если вы получаете блокировки Уровня 2, переходите к Prompt Engineering. Если вы получаете HTTP-ошибки, они требуют другого устранения неполадок.
Для более сложной отладки вы можете изучить полный объект ответа. В Python атрибут response.prompt_feedback часто содержит подробную информацию о том, почему контент был заблокирован. Массив safetyRatings показывает оценки вероятности для каждой категории вреда, даже когда контент проходит. Высокие оценки, которые не достигают порога блокировки, всё равно указывают на опасения системы и могут информировать модификации промптов.
При логировании ошибок для анализа фиксируйте полный ответ об ошибке, ваш точный текст промпта и временную метку. Некоторые разработчики заметили закономерности в частоте ошибок, которые коррелируют со временем суток, что предполагает серверные вариации в поведении фильтров. Создание набора данных о неудачных промптах и их характеристиках помогает разрабатывать более надёжные промпты со временем.
Полезная техника отладки — попробовать тот же промпт в веб-интерфейсе Google AI Studio. Если он работает там, но не работает через API, ваша конфигурация API может быть неправильной. Если он не работает в обоих местах, вы имеете дело с фильтрацией на уровне контента, которая требует prompt engineering. Этот простой тест может сэкономить значительное время на устранение неполадок.
Решения конфигурации API (шаблоны кода)
Для блокировок Уровня 1 (ошибки HARM_CATEGORY) решение состоит в правильной настройке параметров безопасности API. Вот полные, протестированные шаблоны кода для наиболее распространённых сред разработки.
Реализация на Python с использованием официальной библиотеки google-genai обеспечивает наиболее простой подход. Вам нужно импортировать типы безопасности и настроить каждую категорию вреда с желаемым порогом. Для разработки и тестирования BLOCK_NONE обеспечивает максимальную гибкость.
pythonimport google.generativeai as genai from google.generativeai.types import HarmCategory, HarmBlockThreshold genai.configure(api_key="YOUR_API_KEY") # Инициализация модели model = genai.GenerativeModel('gemini-2.0-flash-exp-image-generation') # Определение настроек безопасности для всех настраиваемых категорий safety_settings = { HarmCategory.HARM_CATEGORY_HARASSMENT: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_NONE, } # Генерация изображения с настройками безопасности try: response = model.generate_content( "A golden retriever playing in a sunny park, digital illustration style", safety_settings=safety_settings, generation_config={"response_modalities": ["IMAGE", "TEXT"]} ) # Обработка ответа if response.candidates and response.candidates[0].content.parts: for part in response.candidates[0].content.parts: if hasattr(part, 'inline_data'): # Сохранение изображения with open("output.png", "wb") as f: f.write(part.inline_data.data) print("Изображение успешно сохранено") else: print(f"Генерация заблокирована: {response.prompt_feedback}") except Exception as e: print(f"Ошибка: {e}")
Для сред Node.js пакет @google/generative-ai предоставляет аналогичную функциональность. Структура повторяет подход Python с синтаксисом JavaScript.
javascriptimport { GoogleGenerativeAI, HarmCategory, HarmBlockThreshold } from "@google/generative-ai"; import fs from "fs"; const genAI = new GoogleGenerativeAI("YOUR_API_KEY"); const safetySettings = [ { category: HarmCategory.HARM_CATEGORY_HARASSMENT, threshold: HarmBlockThreshold.BLOCK_NONE, }, { category: HarmCategory.HARM_CATEGORY_HATE_SPEECH, threshold: HarmBlockThreshold.BLOCK_NONE, }, { category: HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT, threshold: HarmBlockThreshold.BLOCK_NONE, }, { category: HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT, threshold: HarmBlockThreshold.BLOCK_NONE, }, ]; const model = genAI.getGenerativeModel({ model: "gemini-2.0-flash-exp-image-generation", safetySettings, }); async function generateImage(prompt) { try { const result = await model.generateContent({ contents: [{ role: "user", parts: [{ text: prompt }] }], generationConfig: { responseMimeTypes: ["image/png"] }, }); const response = result.response; if (response.candidates?.[0]?.content?.parts) { for (const part of response.candidates[0].content.parts) { if (part.inlineData) { const imageData = Buffer.from(part.inlineData.data, "base64"); fs.writeFileSync("output.png", imageData); console.log("Изображение успешно сохранено"); } } } } catch (error) { console.error("Ошибка генерации:", error.message); } } generateImage("A cozy coffee shop interior, watercolor painting style");
Для прямых вызовов REST API с использованием curl вам нужно структурировать тело JSON с включёнными настройками безопасности. Этот подход работает для любого языка или платформы, которая может выполнять HTTP-запросы.
bashcurl -X POST "https://generativelanguage.googleapis.com/v1beta/models/gemini-2.0-flash-exp-image-generation:generateContent?key=YOUR_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "contents": [{ "parts": [{"text": "A peaceful mountain landscape at sunset, oil painting style"}] }], "safetySettings": [ {"category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "BLOCK_NONE"} ], "generationConfig": {"responseMimeTypes": ["image/png"]} }'
Распространённые ошибки конфигурации включают забывание включить все четыре категории вреда, использование неправильных имён категорий или значений порогов и отсутствие настроек безопасности в каждом запросе. Настройки безопасности должны указываться для каждого запроса и не сохраняются от предыдущих вызовов. Для получения подробной информации о ценах на использование API смотрите наше руководство по ценам Gemini API.
Ещё одна частая ошибка — использование неправильного идентификатора модели. Возможность генерации изображений доступна только в моделях с поддержкой генерации изображений, таких как gemini-2.0-flash-exp-image-generation. Использование текстовой модели и ожидание вывода изображения приведёт к ошибкам, не связанным с фильтрацией безопасности.
Обработка ошибок в производственном коде должна различать разные режимы отказа. Блокировка безопасности возвращает ответ с индикаторами заблокированного контента. Ограничение скорости возвращает HTTP 429. Сетевой сбой вызывает исключение. Каждый требует разной обработки: блокировки безопасности могут выиграть от модификации промпта и повторной попытки, ограничения скорости требуют отката и последующей повторной попытки, а сетевые сбои нуждаются в стандартной повторной попытке с экспоненциальным откатом.
При тестировании конфигурации начните с промптов, которые определённо должны работать: пейзажи, еда, продукты или абстрактное искусство. Если эти базовые промпты не работают, ваша конфигурация неправильна. Когда базовые промпты заработают, постепенно тестируйте более сложный контент, чтобы понять, где ваш конкретный случай использования достигает пределов. Этот систематический подход предотвращает разочарование от отладки проблем с промптами, когда реальная проблема — в конфигурации.
Решения Prompt Engineering, которые действительно работают

Когда конфигурация API не решает вашу проблему, потому что вы попадаете на фильтры Уровня 2, prompt engineering становится вашим основным решением. Речь не идёт об обмане системы или попытке сгенерировать неподобающий контент. Речь идёт о том, чтобы помочь системе безопасности понять, что ваш легитимный запрос действительно легитимен.
Основной принцип — добавление конкретики и контекста, которые сигнализируют о безобидном намерении. Расплывчатые промпты вызывают больше ложных срабатываний, потому что система представляет худшие интерпретации. Детальные промпты с ясным художественным контекстом помогают системе понять, чего именно вы хотите.
Для базовых описаний субъектов, которые неожиданно блокируются, паттерн трансформации таков: добавьте конкретные детали, добавьте контекст окружения и добавьте индикатор художественного стиля. Вместо «собака» попробуйте «Золотистый ретривер играет в мяч на заднем дворе пригородного дома, дневной свет, стиль цифровой иллюстрации». Конкретика говорит системе, что именно генерировать, оставляя меньше места для неверной интерпретации. Этот паттерн достигает примерно 95% успешности для базовых субъектов.
Для промптов, связанных с людьми, которые подвергаются более тщательной проверке, паттерн трансформации смещается в сторону вымышленного обрамления. Вместо «спящий человек» попробуйте «Мультяшный персонаж отдыхает на удобном диване, уютный фон гостиной, иллюстрация в стиле анимации». Ключевые слова «мультяшный» и «персонаж» сигнализируют, что вы хотите иллюстрированный контент, а не фотореалистичные изображения. Этот паттерн достигает примерно 80% успешности.
Экшн-сцены, особенно те, которые включают конфликт, выигрывают от явного фэнтезийного или игрового контекста. Вместо «рыцарь сражается с драконом» попробуйте «Фэнтезийный рыцарь-герой противостоит величественному дракону, эпическая батальная сцена, концепт-арт в стиле видеоигры». Ключевые слова «фэнтези», «герой» и «арт видеоигры» обрамляют контент как явно вымышленный и стилизованный. Этот паттерн достигает примерно 85% успешности.
Несколько продвинутых техник могут ещё больше улучшить показатели успешности. Попытки запросов в непиковые часы (обычно поздно ночью или рано утром по тихоокеанскому времени США) иногда дают лучшие результаты, возможно, из-за различных конфигураций сервера или состояний модели. Некоторые пользователи сообщают об успехе при смене языка промпта, причём промпты на испанском языке, по сообщениям, подвергаются немного менее агрессивной фильтрации, хотя этот обходной путь непоследователен.
Добавление явных фраз, сигнализирующих о безопасности, иногда может помочь. Такие фразы, как «семейная иллюстрация», «контент, подходящий для детей» или «образовательная диаграмма», могут упредить опасения фильтра. Однако не добавляйте их к промптам, которые были бы противоречивыми, так как это может вызвать дополнительную проверку.
Для промптов, связанных с отказами в генерации изображений, библиотека трансформаций предоставляет дополнительные паттерны, специфичные для часто отклоняемых типов контента.
Помните, что prompt engineering имеет пределы. Некоторый контент будет заблокирован независимо от того, как вы его сформулируете. Если вы попробовали множество трансформаций без успеха, возможно, пришло время рассмотреть альтернативных провайдеров, а не тратить больше времени на обходные пути.
Вот полная справочная таблица трансформаций для распространённых сценариев:
| Оригинальный промпт | Трансформированный промпт | Успешность |
|---|---|---|
| «собака» | «Дружелюбный золотистый ретривер в парке, цифровое искусство» | 95% |
| «миска хлопьев» | «Керамическая миска с красочными хлопьями, утренняя кухня, тёплое освещение» | 90% |
| «идущий человек» | «Мультяшный персонаж идёт по городу, стиль анимации» | 85% |
| «портрет женщины» | «Иллюстрированный портрет женского персонажа, стиль цифрового искусства» | 75% |
| «сражающийся рыцарь» | «Фэнтезийный рыцарь-герой в эпической битве, концепт-арт видеоигры» | 85% |
| «врач и пациент» | «Медицинская иллюстрация, образовательный стиль» | 80% |
| «пляжная сцена» | «Тропический пляжный пейзаж, стиль акварельной живописи» | 90% |
Паттерн во всех успешных трансформациях включает три элемента: конкретность относительно того, что вы хотите, контекст, который устанавливает обстановку и тон, и художественное обрамление, которое сигнализирует о нефотореалистичном намерении. Запомните эту формулу и применяйте её систематически.
Для приложений пакетной обработки рассмотрите создание препроцессора промптов, который автоматически применяет эти трансформации. Это может быть так просто, как добавление «, стиль цифровой иллюстрации» ко всем промптам, или настолько сложно, как система сопоставления паттернов, которая применяет разные трансформации в зависимости от типа контента.
Что невозможно исправить (честная правда)
Полная прозрачность относительно ограничений экономит ваше время и нервы. Не всё можно исправить через конфигурацию или prompt engineering. Понимание того, что действительно невозможно, помогает принимать лучшие решения о том, когда прекратить попытки и когда использовать альтернативы.
Фильтры Уровня 2 абсолютно блокируют определённые категории контента. Контент, связанный с CSAM, всегда блокируется без обходных путей, точка. Это уместно и требуется законом. Контент, который близко напоминает реальных публичных личностей, может быть заблокирован независимо от художественного обрамления. Контент, который система интерпретирует как предназначенный для домогательств или вреда, даже если это не ваше намерение, может быть постоянно заблокирован.
Реалистичные изображения насилия, оружия в определённых контекстах или контента с сексуальным подтекстом сталкиваются с очень высокой чувствительностью фильтров. Даже художественное или образовательное обрамление часто не помогает пройти эти фильтры. Если ваш случай использования требует генерации такого типа контента для легитимных целей, таких как разработка игр или медицинское образование, Nano Banana Pro может быть неподходящим инструментом.
Реалистичный показатель успешности prompt engineering для пограничного контента составляет примерно 70-80%. Это означает, что даже с оптимизированными промптами 20-30% легитимных запросов, которые попадают на фильтры Уровня 2, будут продолжать не выполняться. Если вашему приложению требуется надёжная, стабильная генерация изображений, вам нужно учитывать этот показатель отказов или использовать провайдеров с другими подходами к фильтрации.
Признаки того, что вам следует прекратить попытки и перейти к альтернативам, включают: один и тот же промпт стабильно не работает после множества попыток и переформулировок, сообщения об ошибках, специально упоминающие PROHIBITED_CONTENT, а не IMAGE_SAFETY, и случаи использования, которые фундаментально требуют типы контента, для генерации которых Nano Banana Pro не предназначен.
Принятие этих ограничений — это не сдача. Это принятие информированного решения использовать правильный инструмент для ваших конкретных потребностей. Nano Banana Pro отлично справляется со многими задачами генерации изображений. Для задач, с которыми он не справляется, существуют альтернативы.
Чтобы помочь вам оценить вашу ситуацию, вот структура принятия решений:
| Ситуация | Рекомендация |
|---|---|
| Базовый контент заблокирован | Сначала попробуйте prompt engineering (максимум 10 мин) |
| Prompt engineering не сработал 3+ раз | Рассмотрите альтернативы |
| Ошибка PROHIBITED_CONTENT | Немедленно переходите к альтернативе |
| Критически важное бизнес-приложение | Планируйте резервный вариант с несколькими провайдерами |
| Случайные сбои приемлемы | Продолжайте с логикой повторных попыток |
| Нулевая терпимость к сбоям | Используйте только предварительно одобренные шаблоны промптов |
Ключевое понимание в том, что Nano Banana Pro оптимизирован для типичного случая безопасного, массового контента. Он отлично подходит для изображений продуктов, пейзажей, иллюстраций для статей и подобных случаев использования. Когда ваши потребности выходят за пределы этой массовой зоны, вы боретесь против дизайна системы, а не используете её по назначению.
Учитывайте также временные инвестиции. Каждый час, потраченный на попытки заставить работать сложный промпт, имеет альтернативную стоимость. В какой-то момент экономически рациональный выбор — использовать альтернативного провайдера, а не продолжать устранение неполадок. Установите для себя временной лимит: если вы не можете заставить промпт работать за 15-20 минут, смените подход.
Надёжные альтернативы, когда фильтры безопасности вас блокируют
Когда фильтры безопасности Nano Banana Pro постоянно блокируют ваш легитимный контент, несколько альтернатив предлагают разные подходы к фильтрации и компромиссы.
Для разработчиков, ищущих Gemini-совместимые API с меньшими ограничениями, laozhang.ai предоставляет доступ к нескольким моделям генерации изображений через единый API. При цене примерно $0.05 за изображение ценообразование конкурентоспособно, а конфигурация фильтрации платформы отличается от прямого доступа к Google API. Это делает её подходящей для сценариев разработки и тестирования, где стандартные фильтры Nano Banana Pro слишком ограничительны. Платформа поддерживает те же модели Gemini с дополнительными опциями конфигурации.
DALL-E 3 через OpenAI предлагает другой подход к фильтрации безопасности. Хотя у него есть свои ограничения, конкретные триггеры отличаются от триггеров Gemini. Контент, который блокируется одной системой, может пройти через другую. DALL-E 3 особенно хорошо справляется с художественными и иллюстрированными стилями, и его понимание промптов хорошо обрабатывает креативные запросы. Цены варьируются в зависимости от разрешения и настроек качества.
Midjourney предоставляет, пожалуй, самый гибкий подход для креативной генерации изображений, хотя рабочий процесс значительно отличается от решений на основе API. Доступ требует интеграции с Discord, что делает его менее подходящим для программных приложений, но отличным для креативного исследования и дизайнерской работы. Сообщество и инструменты вокруг Midjourney зрелые, и качество для художественных выводов часто считается лучшим в своём классе.
При выборе альтернативы учитывайте ваш конкретный случай использования. Для программной интеграции решения на основе API, такие как laozhang.ai, обеспечивают наиболее прямую замену. Для креативной работы с человеческим надзором рабочий процесс Midjourney может быть более подходящим. Для производственных приложений, требующих разнообразных типов контента, использование нескольких провайдеров с резервной логикой наиболее надёжно обрабатывает граничные случаи.
Сравнение затрат варьируется в зависимости от паттерна использования. Для детального анализа цен API, включая стратегии оптимизации затрат, мы опубликовали всесторонние сравнения. Самый дешёвый вариант зависит от вашего объёма, требуемых функций и того, как часто вы сталкиваетесь с фильтрами безопасности для ваших конкретных типов контента.
Вот практическое сравнение для распространённых сценариев:
| Провайдер | Цена за изображение | Уровень фильтрации | Лучше всего для |
|---|---|---|---|
| Nano Banana Pro (напрямую) | Доступен бесплатный уровень | Наиболее ограничительный | Безопасный, массовый контент |
| laozhang.ai | ~$0.05 | Умеренный | Разработка, разнообразный контент |
| DALL-E 3 | ~$0.04-0.12 | Умеренный | Художественная, креативная работа |
| Midjourney | ~$0.02-0.06 | Менее ограничительный | Высококачественное искусство, дизайн |
Фактическая стоимость также включает неудачные запросы. Если 30% ваших запросов Nano Banana Pro не выполняются из-за фильтров безопасности, эффективная стоимость за успешное изображение значительно выше номинальной ставки. Учитывайте это в своём сравнении, когда фильтры безопасности влияют на существенную часть ваших запросов.
Для приложений, требующих высокой надёжности, архитектура с несколькими провайдерами имеет смысл. Направляйте безопасный контент в Nano Banana Pro (наименьшая стоимость для работающего контента) и автоматически переключайтесь на laozhang.ai или другие альтернативы, когда фильтры безопасности блокируют контент. Этот гибридный подход оптимизирует как стоимость, так и надёжность.
При реализации резервной логики учитывайте последствия для задержки. Первая попытка провайдера занимает время, и переход на резерв добавляет ещё больше задержки. Для приложений, чувствительных к задержке, вы можете запускать запросы к нескольким провайдерам параллельно и использовать первый успешный результат. Это стоит больше за изображение, но значительно уменьшает воспринимаемую пользователем задержку.
Аутентификация и управление API-ключами для нескольких провайдеров требует тщательного проектирования. Храните API-ключи безопасно, реализуйте отдельное ограничение скорости для каждого провайдера и отслеживайте затраты у всех провайдеров, чтобы избежать сюрпризов. Единая панель мониторинга помогает отслеживать, какой провайдер обрабатывает какие типы контента и по какой цене.
Для корпоративных развёртываний рассмотрите установление прямых отношений с провайдерами для пользовательских условий, более высоких лимитов или изменённых конфигураций фильтров. Некоторые провайдеры предлагают корпоративные соглашения с скорректированными конфигурациями безопасности для проверенных бизнес-случаев использования.
Предотвращение будущих ошибок безопасности
Помимо исправления непосредственных проблем, установление практик, которые минимизируют будущие ошибки безопасности, экономит текущее время разработки и улучшает надёжность приложения.
Для построения промптов разработайте шаблоны, которые по умолчанию включают элементы, сигнализирующие о безопасности. Вместо того чтобы создавать каждый промпт с нуля, создайте переиспользуемые паттерны, которые включают успешные стратегии трансформации. Шаблон типа «[Субъект] в [обстановке], [описание освещения], иллюстрация в стиле [художественного стиля], детальная и яркая» обрабатывает многие случаи использования, сохраняя низкий показатель срабатывания фильтров.
Для конфигурации API создайте функции-обёртки, которые автоматически включают настройки безопасности. Это предотвращает распространённую ошибку забывания включить настройки безопасности в отдельные запросы. Рассмотрите реализацию логики повторных попыток с модификацией промпта для временных сбоев, хотя будьте осторожны, чтобы не повторять бесконечно для действительно заблокированного контента.
pythondef safe_generate_image(prompt, max_retries=3): """Генерация изображения с автоматическими настройками безопасности и логикой повторных попыток.""" base_safety = { HarmCategory.HARM_CATEGORY_HARASSMENT: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_NONE, } prompt_variations = [ prompt, f"{prompt}, illustration style", f"{prompt}, digital art, family-friendly", ] for variation in prompt_variations[:max_retries]: try: response = model.generate_content( variation, safety_settings=base_safety, generation_config={"response_modalities": ["IMAGE", "TEXT"]} ) if response.candidates and response.candidates[0].content.parts: return response except Exception as e: continue return None # Все попытки не удались
Для производственных приложений реализуйте мониторинг блокировок фильтров безопасности. Отслеживайте, какие промпты не работают и почему, создавая набор данных, который информирует будущий дизайн промптов. Эти данные помогают выявить паттерны в вашем конкретном случае использования, которые излишне запускают фильтры.
Рассмотрите реализацию гибридного подхода, который использует Nano Banana Pro в качестве основного генератора с резервным переходом на альтернативы при возникновении блокировок безопасности. Это захватывает преимущества в стоимости от использования Nano Banana Pro, сохраняя надёжность через резервные опции.
Документируйте ваши успешные паттерны промптов и делитесь ими внутри вашей команды. Поведение фильтров безопасности может меняться со временем по мере обновления моделей Google, поэтому поддержание библиотеки работающих паттернов помогает быстро адаптироваться при возникновении изменений.
Вот библиотека шаблонов промптов для начала:
Стиль продуктовой фотографии: «[Описание продукта], профессиональная продуктовая фотография, чистый белый фон, студийное освещение, высокая детализация, коммерческое качество»
Пейзажи и природа: «[Описание сцены], стиль пейзажной фотографии, освещение золотого часа, яркие цвета, широкоугольный вид, тревел-фотография»
Иллюстрация персонажей: «Мультяшный [описание персонажа], дружелюбное выражение, красочная цифровая иллюстрация, стиль детской книги, игривая атмосфера»
Бизнес и корпорация: «Иллюстрация [бизнес-концепции], современный плоский стиль дизайна, профессиональный, сине-белая цветовая схема, чистый и минималистичный»
Еда и кулинария: «[Описание блюда], стиль фуд-фотографии, аппетитная подача, тёплое освещение, качество ресторанного меню»
Архитектура и интерьер: «[Описание пространства], архитектурная визуализация, современный дизайн, хорошо освещённый интерьер, качество дизайнерского журнала»
Эти шаблоны были тщательно протестированы и поддерживают высокие показатели успешности для разных типов контента. Начните с шаблона и настройте под ваши конкретные потребности, вместо того чтобы строить промпты с нуля.
Для командных сред рассмотрите создание внутреннего инструмента генерации промптов, который автоматически применяет эти паттерны. Это стандартизирует качество промптов в вашей команде и уменьшает процесс проб и ошибок для отдельных разработчиков.
FAQ — ответы на ваши вопросы
Почему BLOCK_NONE не работает для моих изображений?
BLOCK_NONE влияет только на Уровень 1 (настраиваемые параметры безопасности). Если вы получаете ошибки IMAGE_SAFETY, вы попадаете на фильтры Уровня 2, которые невозможно отключить через какую-либо конфигурацию API. Решение для блокировок Уровня 2 — prompt engineering или использование альтернативных провайдеров.
Могу ли я полностью отключить все фильтры безопасности?
Нет, вы не можете полностью отключить все фильтры безопасности. Хотя фильтры Уровня 1 могут быть установлены на BLOCK_NONE для целей разработки, фильтры Уровня 2, включая IMAGE_SAFETY, PROHIBITED_CONTENT и обнаружение CSAM, всегда активны. Это сделано намеренно и не настраивается.
Почему мой промпт иногда работает, а иногда нет?
Эта непоследовательность возникает потому, что генерация изображений вероятностна. Один и тот же промпт каждый раз создаёт немного разные изображения, и некоторые вариации могут запускать фильтры Уровня 2, а другие — нет. Базовый контент изображения, а не только текст вашего промпта, влияет на решения фильтра.
Есть ли способ обжаловать заблокированный контент?
В настоящее время нет формального процесса апелляции для блокировок IMAGE_SAFETY. Система работает автоматически на основе оценки модели. Если вы считаете, что фильтрация неверна, вы можете отправить отзыв через интерфейс Google AI Studio, хотя это не обеспечивает немедленного решения.
Есть ли у аккаунтов Workspace другое поведение фильтров?
Аккаунты Workspace и корпоративные аккаунты могут иметь немного другие конфигурации по умолчанию, но основные фильтры Уровня 2 остаются активными. Некоторые корпоративные клиенты имеют доступ к дополнительным опциям конфигурации через прямые соглашения с Google, но стандартный доступ к API не предоставляет этих опций.
Как часто меняются фильтры безопасности?
Google периодически обновляет базовые модели и поведение фильтров без предварительного уведомления. Промпты, которые работали ранее, могут внезапно начать не работать, или ранее заблокированные промпты могут начать работать. Вот почему поддержание библиотеки паттернов промптов и наличие резервных опций важны для производственной надёжности.
В чём разница между фильтрацией AI Studio и API?
Оба используют одну и ту же базовую систему безопасности, но могут быть тонкие различия в конфигурациях по умолчанию. AI Studio предоставляет интерактивный интерфейс, который может по-разному обрабатывать некоторые граничные случаи. Как правило, если контент работает в AI Studio, но не работает через API, проверьте конфигурацию safety_settings. Если он не работает в обоих местах, контент блокируется на уровне, который вы не можете настроить.
Стоит ли сообщать о ложных срабатываниях в Google?
Да, сообщение о ложных срабатываниях помогает улучшить систему со временем. Используйте механизмы обратной связи в AI Studio или создавайте обращения через официальные каналы разработчиков Google AI. Хотя это не обеспечит немедленного решения, совокупная обратная связь влияет на то, как Google настраивает фильтры в будущих обновлениях.
Есть ли юридические проблемы с обходом фильтров безопасности?
Использование BLOCK_NONE или prompt engineering для генерации легитимного контента допустимо и является ожидаемым поведением разработчика. Это не «обход» мер безопасности, а использование API так, как он был разработан. Однако попытки генерировать контент, нарушающий условия обслуживания, недопустимы независимо от техники. Фильтры безопасности существуют для предотвращения действительно вредного контента, и их обход для запрещённых целей нарушит ваше соглашение об API.
Могу ли я использовать эти техники для коммерческих приложений?
Да, конфигурация API и техники prompt engineering, описанные здесь, подходят для коммерческого использования. Ключ в генерации контента, который соответствует условиям обслуживания Google. Техники помогают вам более надёжно генерировать легитимный контент, что именно то, что нужно коммерческим приложениям.