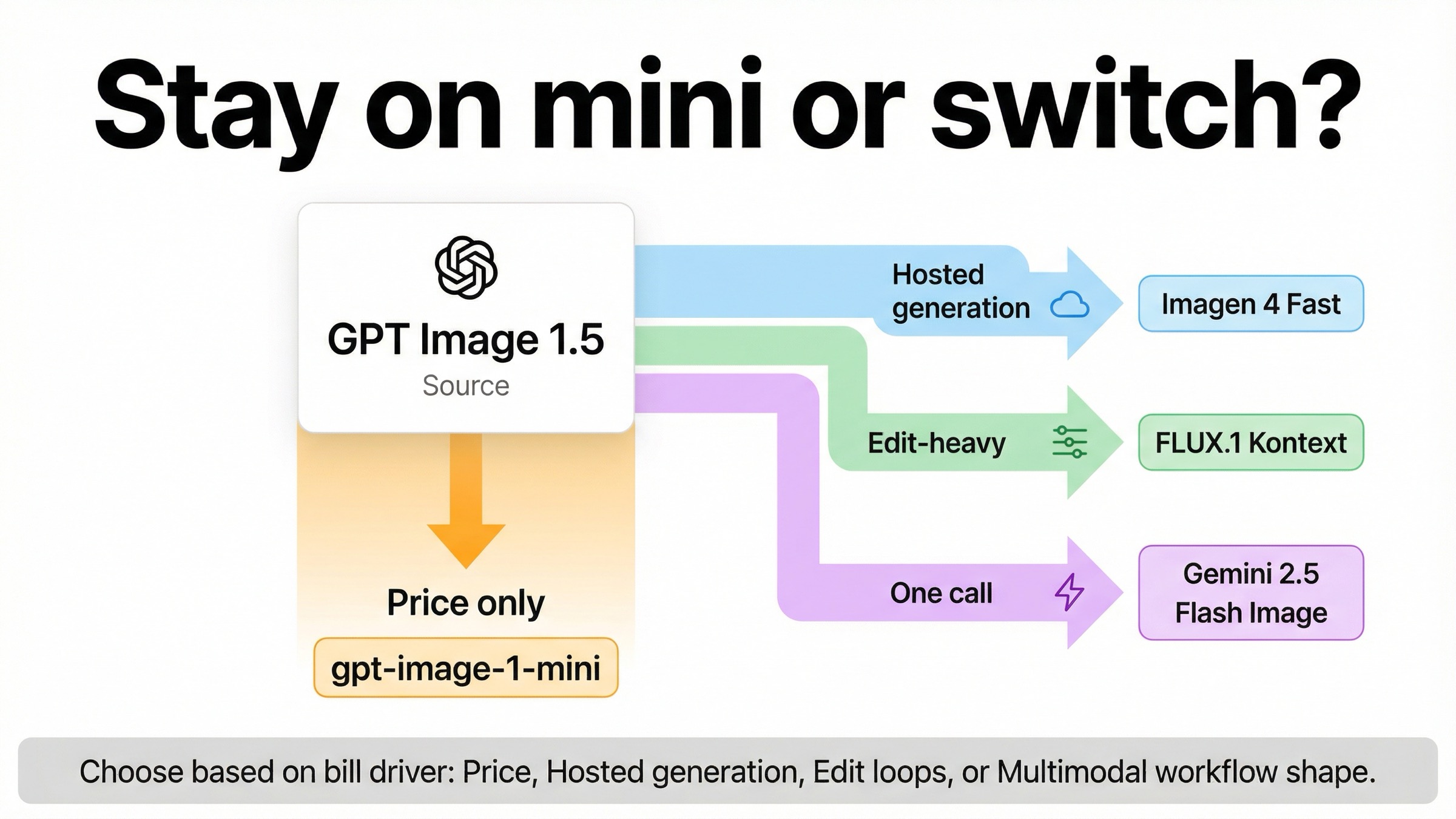
По состоянию на 29 марта 2026 года запрос gpt-image-1.5 cheaper alternative чаще всего ломается в одном месте: слово “cheaper” автоматически превращают в “уйти из OpenAI”. Если боль только в цене, первый рациональный шаг сейчас обычно не migration, а gpt-image-1-mini. OpenAI по-прежнему показывает для квадратного 1024x1024 цены \$0.005, \$0.011 и \$0.036 для low, medium и high. Внешние alternatives становятся правильным ответом только тогда, когда меняется сам cost driver: Imagen 4 Fast нужен как более дешевый hosted generation lane относительно GPT Image 1.5 medium и high, FLUX.1 Kontext нужен тогда, когда bill раздувают edits и retries, а Gemini 2.5 Flash Image нужен только в тех случаях, когда один multimodal call заменяет несколько отдельных шагов.
Именно эту развилку страница выдачи до сих пор часто размывает. Одни материалы отвечают на вопрос “что дешевле именно GPT Image 1.5”, другие незаметно отвечают на вопрос “что дешевле OpenAI вообще”. Это разные вопросы, потому что внутри OpenAI уже есть существенно более дешевый budget lane, и он меняет стартовую рекомендацию для большого числа команд.
Есть и третья группа запросов, которые только звучат как price problem. Иногда пользователь говорит “GPT Image 1.5 слишком дорогой”, а реальная проблема сидит в 429, verification, route confusion или в том, что mini вообще не был протестирован как baseline. В такой ситуации vendor switch легко становится не cost optimization, а заменой одного setup issue на другой.
Краткое содержание

Если нужен короткий routing answer, достаточно этой таблицы.
| Если ваша реальная проблема в том, что... | Более дешевый или более уместный ответ | Почему это сейчас лучший ход | Главный tradeoff |
|---|---|---|---|
| вам просто нужен более низкий официальный price floor | gpt-image-1-mini | OpenAI по-прежнему держит его ниже GPT Image 1.5 во всех square tiers | Вы отказываетесь от flagship ceiling |
| нужен более дешевый hosted generation lane, чем GPT Image 1.5 medium / high | Imagen 4 Fast | Google сейчас показывает \$0.02 за изображение | Это уже другая provider stack |
| деньги утекают в edits, retries и revision loops | FLUX.1 Kontext | Effective cost может упасть за счет меньшего числа restart attempts | По headline price это не самый дешевый row |
| одному вызову нужно и понять текст, и вернуть картинку | Gemini 2.5 Flash Image | Один multimodal surface может заменить несколько model steps | Цена хуже сводится к одной цифре за изображение |
| боль в access, verification или tier state | Остаться на OpenAI и сначала починить setup | Vendor switch не решает account-state problem | Придется сначала довести route до рабочего состояния |
Самое короткое честное правило такое: если проблема только в цене, сначала тестируйте mini. Только когда дорогим становится уже не сам per-image row, а hosted lane, retry loop или multimodal orchestration, внешние варианты начинают реально выигрывать.
Что сейчас реально дешевле GPT Image 1.5?

Чтобы ответить на этот keyword без путаницы, нужно сначала развести price surfaces. На текущей странице модели GPT Image 1.5 OpenAI показывает для square 1024x1024 \$0.009, \$0.034 и \$0.133 в low, medium и high. На текущей странице gpt-image-1-mini OpenAI показывает \$0.005, \$0.011 и \$0.036. Уже это ломает половину слабых alternatives pages: если вам нужен более дешевый путь внутри OpenAI, искать надо сначала не outside vendors, а mini.
Внешние alternatives важны, но они отвечают на более узкие cost questions. На текущей Vertex AI pricing page Google показывает Imagen 4 Fast за \$0.02 за изображение, и это уже явный price win относительно GPT Image 1.5 medium и high. На текущей pricing page Black Forest Labs показывает FLUX.1 Kontext [pro] за \$0.04, что не дешевле GPT Image 1.5 medium с \$0.034, но все еще может оказаться дешевле в edit-heavy workflow. А текущая документация по Gemini 2.5 Flash Image говорит, что одно сгенерированное изображение использует 1290 image output tokens. В сочетании с текущими ценами Vertex на \$30 / 1M image output tokens это дает примерно \$0.0387 только по output-image cost. Это расчет из официальных цифр, а не flat per-image card от Google.
Именно поэтому этот keyword нельзя хорошо закрыть generic leaderboard'ом. Здесь нужна decision table.
| Вариант | Текущая price surface | Что он бьет по цене | Лучший fit | Почему это не универсальный ответ |
|---|---|---|---|---|
| GPT Image 1.5 | \$0.009 / \$0.034 / \$0.133 | только baseline | flagship image work | Вы уже платите за premium lane |
gpt-image-1-mini | \$0.005 / \$0.011 / \$0.036 | дешевле GPT Image 1.5 во всех square tiers | volume-heavy drafts, prototypes, low-stakes visuals | Не решает every quality or edit complaint |
| Imagen 4 Fast | \$0.02 за изображение | дешевле GPT Image 1.5 medium и high | hosted generation outside OpenAI | Не дешевле mini |
| FLUX.1 Kontext [pro] | \$0.04 за изображение | иногда выигрывает по effective cost, не по headline row | repeated edits, text fixes, consistency workflows | Сила в меньшем числе retries, не в минимальном прайсе |
| Gemini 2.5 Flash Image | около \$0.0387 по output image cost до input tokens | выигрывает только если workflow compression экономит больше | text+image reasoning and rendering in one call | Плохо сравнивается как simple image generator |
Если вам нужен чистый OpenAI cost math, дальше логично идти в GPT Image 1.5 API pricing и GPT Image 1.5 cost per image. Эта статья отвечает на другой вопрос: когда надо менять сам route.
Оставайтесь на gpt-image-1-mini, если проблема только в цене
Это главный раздел в статье, потому что именно его чаще всего не хотят усиливать другие pages про alternatives. В текущем image generation guide OpenAI прямо пишет, что gpt-image-1-mini лучше подходит для сценариев, где image quality не является главным приоритетом. Для большого числа покупателей это уже и есть правильный answer.
Если ваш workload состоит из высокочастотных drafts, внутренних mockups, disposable variants, идейных concept images и просто бюджетных iteration cycles, mini почти всегда должен быть первым benchmark. Он позволяет остаться внутри той же API family, не ломать billing relationship и не переносить интеграцию на другого провайдера, при этом заметно опуская visible price floor. На square generation mini начинается с \$0.005 против \$0.009 у GPT Image 1.5 low, \$0.011 против \$0.034 на medium и \$0.036 против \$0.133 на high. Это уже не “чуть дешевле”, а другая cost lane.
Именно здесь current SERP особенно легко уводит читателя в сторону. Команда говорит “GPT Image 1.5 слишком дорогой”, а страницы про alternatives переводят это в “уходите из OpenAI”. Но budget problem не обязательно означает provider problem. Часто это lane-selection problem: люди просто начали не с того OpenAI route.
Это не делает mini ответом на все жалобы. Если реальная боль сидит в fidelity, brand-safe outputs, text rendering, more reliable premium results или в ситуациях, где каждая неудачная генерация запускает дорогой retry loop, flagship premium может оставаться рациональным. Но именно поэтому trustworthy page обязана сначала сказать читателю, когда не надо уходить.
Если вам нужен более широкий взгляд на open-market comparison внутри этой темы, полезно перейти в OpenAI image generation API cheaper alternative и gpt-image-1-mini pricing. Здесь мы держим фокус именно на switch rule.
Используйте Imagen 4 Fast, если нужен более дешевый hosted generation lane
Если вы уже уверены, что проблема именно в GPT Image 1.5, а не в OpenAI mini, то Imagen 4 Fast становится самым чистым mainstream answer.
Текущая Vertex AI pricing page показывает Imagen 4 Fast за \$0.02 за изображение`, а текущая документация Imagen 4 описывает его как dedicated image-generation route с поддержкой нескольких output images на один prompt. Это важно, потому что здесь вы сравниваете generation-first product с generation-first product, а не пытаетесь свести multimodal chat surface к той же самой cost logic.
Это лучший выбор в сценарии “я по-прежнему хочу managed image generation, но GPT Image 1.5 medium и high слишком дорогие для моего объема”. В этой ситуации Imagen проще объяснить, проще бюджетировать и проще внедрять как именно price-down route. Ему не нужно доказывать ценность через workflow compression или через reduced retries. Он выигрывает именно как понятный hosted generation lane.
Но я бы не называл Imagen 4 Fast самым дешевым answer в целом дереве решений. Он не дешевле mini и не решает edit-heavy или multimodal use cases лучше всех. Его ценность уже и чище: дешевле GPT Image 1.5 medium / high, но все еще остается mainstream hosted image route.
Поэтому правило здесь очень узкое и полезное. Если реальное сравнение идет против GPT Image 1.5, смотрите на Imagen. Если реальное сравнение идет против mini, сначала оставайтесь внутри OpenAI.
Используйте FLUX.1 Kontext, когда дорогими становятся retry и edits
Иногда команды переплачивают не потому, что первая картинка стоит слишком дорого. Они переплачивают потому, что вторая, третья и четвертая правка заставляют почти начинать заново.
Это и есть лучший аргумент в пользу FLUX.1 Kontext. В текущем Kontext overview Black Forest Labs делает акцент на image editing, character consistency, text editing и style transformation. Иными словами, модель позиционируется не как “самая дешевая генерация”, а как более сильный edit-preservation route.
Публичная цена это маскирует. На текущей pricing page BFL показывает FLUX.1 Kontext [pro] за \$0.04. Эта строка не выглядит like obvious cheap win: она выше GPT Image 1.5 medium и тем более выше mini. Если остановиться на headline price, Kontext выглядит слабым ответом на cheaper-alternative query.
Но cheaper для edit-heavy workflow не измеряется первой генерацией. Ключевой вопрос другой: сколько стоит одна usable image, которую можно реально оставить? Если команда снова и снова делает такие операции, как “оставь персонажа, поменяй фон”, “не трогай композицию, исправь текст”, “сохрани почти все, сделай пару campaign variants”, “измени один локальный элемент”, тогда effective cost начинает зависеть от того, насколько модель умеет сохранять уже удачную часть результата.
Именно здесь Kontext становится сильным. Его надо рассматривать как effective-cost alternative, а не как universal cheapest-per-image option. Поэтому я бы не советовал его как default replacement for GPT Image 1.5. Но если бюджет утекает именно в endless revision loops, Kontext быстро становится гораздо интереснее, чем кажется по первой строке прайс-листа.
Используйте Gemini 2.5 Flash Image только тогда, когда один вызов должен и думать, и рисовать
Google должен появляться в этой статье дважды, потому что продает две принципиально разные вещи. Imagen 4 Fast это hosted generation lane. Gemini 2.5 Flash Image это workflow alternative для тех, кому один вызов должен принять text и image context, продолжить reasoning и отдать картинку. Эти продукты не надо смешивать в одну и ту же cost story.
В текущей документации по Gemini 2.5 Flash Image сказано, что модель принимает text и image inputs, возвращает text и image outputs, а также поддерживает multi-turn image editing. Это уже другой продуктовый shape. Его покупают не ради самой простой цены за картинку, а ради того, чтобы убрать часть orchestration между отдельными text model и image model calls.
Поэтому Gemini редко бывает лучшим answer, если вопрос сформулирован как “какая image model просто дешевле”. По image-output math alone он не бьет mini и не выглядит чистым price win against GPT Image 1.5 medium. Его смысл появляется там, где сама схема workflow дорогая: сначала text reasoning, потом image rendering, потом extra routing logic для связки состояния.
В таких случаях cheaper уже означает не “самый низкий price row”, а “меньше платных шагов в цепочке”. И это как раз то место, которое слабые roundup pages почти всегда теряют. Они видят Google image product и ставят его рядом с другими generators, хотя главный reason to buy здесь другой. Gemini 2.5 Flash Image разумен только тогда, когда одна surface должна одновременно think, answer and render.
Когда проблема в setup, а не в цене
Семейство таких запросов притягивает много frustration, которое звучит как cost complaint, но по сути является access complaint. В текущей статье OpenAI про API model availability by usage tier and verification status говорится, что доступность gpt-image-1 и gpt-image-1-mini зависит от usage tier, а часть доступа все еще может упираться в organization verification. Это означает, что один плохой старт еще не доказывает, будто модель слишком дорогая или чужой провайдер автоматически лучше.
Это важно, потому что setup friction меняет субъективное ощущение стоимости. Один 429, один access failure или одна неправильная route choice легко делают каждую попытку “дорогой”, хотя вы еще даже не добились чистого benchmark. В этот момент vendor switch может стать просто переносом боли, а не реальной экономией.
Поэтому здесь тоже полезно держать очень простой rule. Если проблема в tier, verification, route confusion или account state, сначала исправьте это. Только если workflow уже реально работает и после этого все равно проигрывает по economics, имеет смысл возвращаться к migration question.
Как я бы проверил переключение за один день
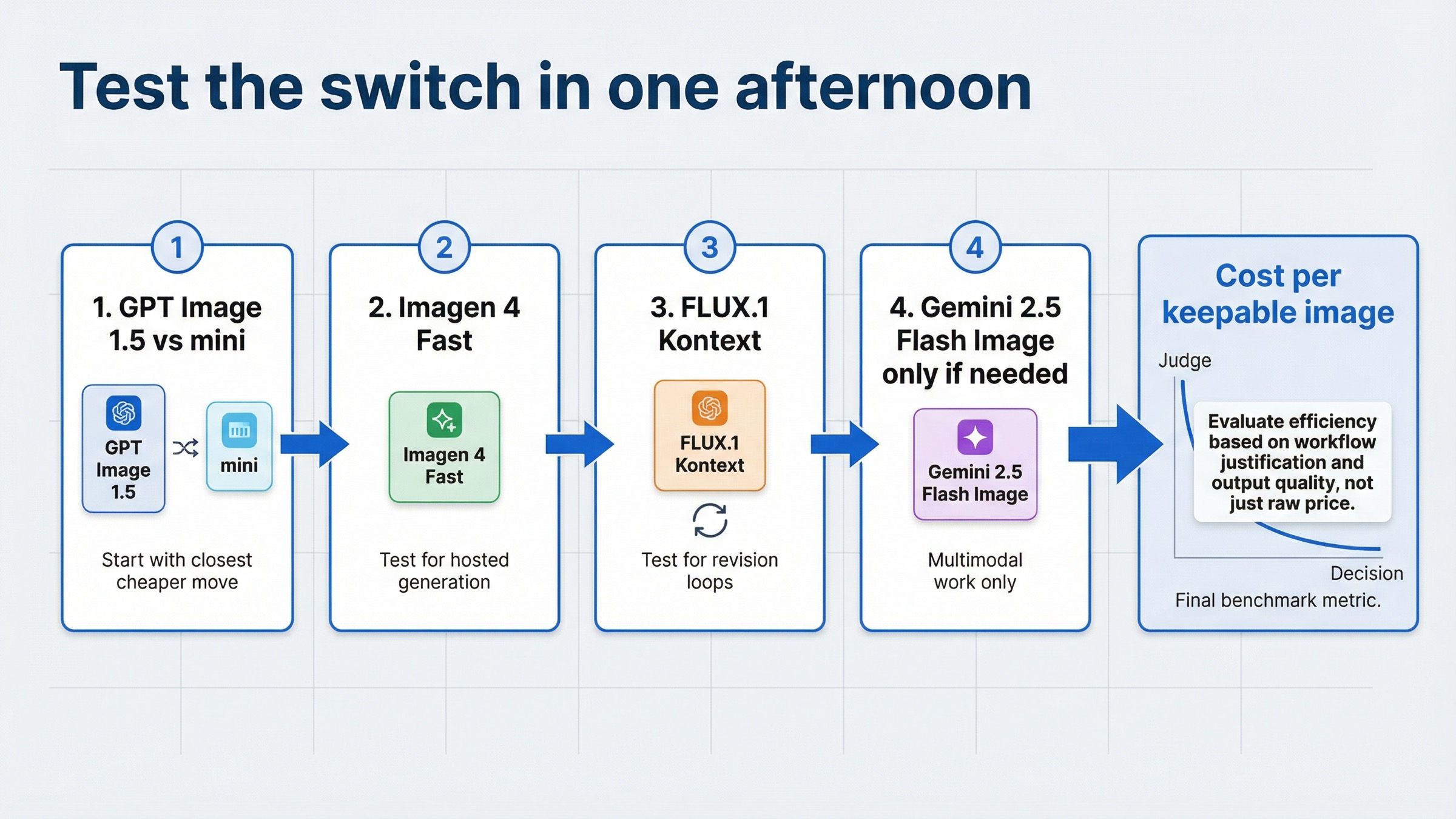
Лучший способ избежать плохой migration decision это тестировать не бренды, а реальный failure mode.
- Сначала прогоните один и тот же prompt set на GPT Image 1.5 и
gpt-image-1-mini. Если mini уже достаточен, stop here. - Затем сделайте generation-first benchmark с Imagen 4 Fast и посмотрите, выигрывает ли hosted generation economics относительно GPT Image 1.5 medium / high.
- Затем сделайте revision-loop benchmark для FLUX.1 Kontext на задачах с сохранением сцены, заменой текста и локальными правками.
- Добавляйте Gemini 2.5 Flash Image только тогда, когда продукт действительно требует unified multimodal workflow.
- В конце сравнивайте не “кто дешевле по первой строчке”, а сколько стоит одна keepable image вместе с операторским effort и retry spend.
Этот порядок специально узкий. Слабые comparison pages любят делать broad market tour. На практике же лучший benchmark почти всегда начинается с самого близкого, самого дешевого и наименее болезненного switch.
Итог
Лучшая более дешевая альтернатива GPT Image 1.5 это не один универсальный winner. Это самый дешевый move, который решает именно ту причину, по которой GPT Image 1.5 кажется дорогим в вашем workflow.
Если проблема только в цене, начинайте с gpt-image-1-mini. Если нужен более дешевый hosted generation lane, чем GPT Image 1.5 medium / high, смотрите на Imagen 4 Fast. Если bill раздувают edits и retries, смотрите на FLUX.1 Kontext. Если одному вызову нужно и думать, и рисовать, смотрите на Gemini 2.5 Flash Image. А если боль сидит в access, verification или route choice, сначала почините OpenAI setup и только потом решайте, нужен ли вам вообще vendor switch.