
Короткий ответ по состоянию на 18 марта 2026 года: 429 RESOURCE_EXHAUSTED в Gemini API обычно означает проблему с квотой, tier или скоростью запросов и во многих случаях требует паузы и повторной попытки; 400 INVALID_ARGUMENT обычно означает, что запрос, версия endpoint, выбранная модель или предусловие billing заданы неверно, поэтому запрос нужно исправить до нового вызова; 500 INTERNAL чаще всего указывает либо на нестабильность со стороны Google, либо на слишком большой входной контекст, и тогда самая быстрая мера — сократить входные данные, включить ограниченный exponential backoff и при необходимости временно перейти с Pro на Flash.
Главный вопрос здесь не в том, "что означает код ошибки", а в том, "что делать в следующую минуту". Именно это большинство страниц в SERP по Gemini до сих пор объясняют слабо. Ошибка 429 в 2026 году — это уже не просто "слишком много запросов": нужно учитывать изменение квот, вступившее в силу 7 декабря 2025 года, мартовские изменения billing и usage tiers, а также повторяющиеся сообщения пользователей о 429 на платных проектах с низким фактическим потреблением. Ошибка 400 тоже не является одним и тем же случаем: иногда это неверное тело запроса, иногда несовпадение /v1 и /v1beta, а иногда FAILED_PRECONDITION, связанный с регионом или billing. Наконец, 500 — это не всегда "подождите и попробуйте позже": сама официальная документация говорит, что слишком длинный контекст тоже может приводить к 500.
Краткое содержание
Если вы уже смотрите логи или алерты, начните с этой таблицы. Самая дорогая ошибка в отладке Gemini — реагировать на 429, 400 и 500 одинаково.
| Ошибка | Что она чаще всего означает в 2026 году | Повторять сейчас? | Первое действие |
|---|---|---|---|
429 RESOURCE_EXHAUSTED | Реальный лимит RPM / TPM / RPD, задержка применения billing или странное состояние квоты | Обычно да | Проверить tier и лимиты проекта, затем повторять с backoff |
400 INVALID_ARGUMENT | Неверный payload, модель, параметры или версия endpoint | Обычно нет | Остановить ретраи и проверить форму запроса |
400 FAILED_PRECONDITION | Проект не удовлетворяет предусловию по региону или billing | Нет | Включить billing или сменить путь использования |
500 INTERNAL | Сбой на стороне Google или слишком длинный контекст | Да, но осмысленно | Уменьшить контекст, повторить и проверить Flash |
Есть три свежих факта, которые меняют практику отладки. Во-первых, FAQ Firebase AI Logic прямо пишет, что квоты Gemini Developer API для Free Tier и Paid Tier 1 были скорректированы с 7 декабря 2025 года, и это может приводить к неожиданным 429. Во-вторых, официальная страница Billing для Gemini API говорит, что ошибки 400 и 500 не тарифицируются, но всё равно расходуют квоту. В-третьих, в марте 2026 года Google изменил usage tiers и spend caps, а с 1 апреля 2026 года вступает в силу применение tier spend caps. Поэтому советы времён начала 2025 года уже не дают полной картины.
Диагностика 429, 400 и 500 в Gemini API за 30 секунд
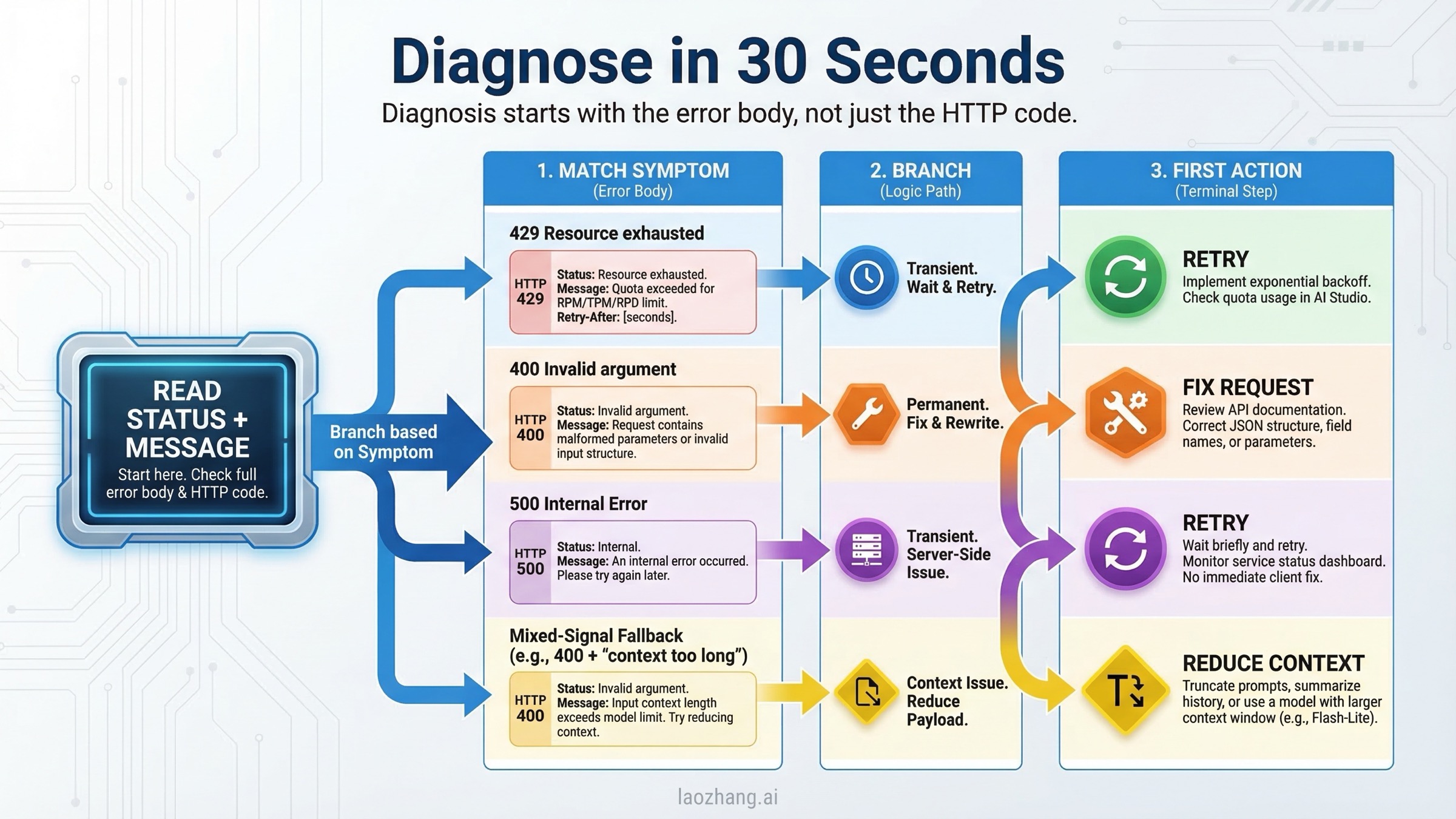
Самая полезная привычка — читать не только HTTP-код, но и весь ответ об ошибке. На практике вам нужны status, message, детали вроде QuotaFailure и RetryInfo, а также сведения о модели и версии endpoint. Если в логах есть только "500" или "429", вы почти наверняка потеряете время на неверной гипотезе.
Официальное руководство по troubleshooting Gemini остаётся лучшей точкой входа, но в рабочем процессе удобнее переводить его в более короткую схему. 429 означает: backend считает, что нужно снизить скорость или что состояние квоты / tier не совпадает с вашими ожиданиями. 400 INVALID_ARGUMENT означает: запрос отвергнут именно как запрос. 400 FAILED_PRECONDITION означает: сама форма запроса может быть верной, но регион или billing не удовлетворяют необходимому условию. 500 означает: аутентификация и базовая валидация прошли, а сбой произошёл уже во время обработки на стороне Google.
В момент инцидента полезнее думать не по коду, а по сообщению:
| Что видно в ответе | Какая ветка вероятнее | Что это обычно означает | Следующий шаг |
|---|---|---|---|
RESOURCE_EXHAUSTED, quota, per minute, RetryInfo | 429 | Реальный лимит или странное состояние billing / quota | Backoff, затем проверка tier и проекта |
Request contains an invalid argument | 400 INVALID_ARGUMENT | Неправильный payload, параметры или endpoint | Перестать повторять и исправить запрос |
free tier is not available in your country или похожее billing-сообщение | 400 FAILED_PRECONDITION | Не выполнено региональное или тарифное предусловие | Включить billing или перейти на поддерживаемый вариант |
An internal error has occurred | 500 | Ошибка на стороне Google или слишком длинный контекст | Уменьшить контекст, повторить, проверить другой модельный путь |
Чтобы реально экономить время, сохраняйте в логах хотя бы четыре вещи: модель, версию endpoint, примерный размер запроса и ответ на вопрос "тот же payload проходит на другой Gemini-модели или нет". Эти четыре параметра обычно быстрее отделяют локальный баг от platform incident, чем любые догадки по stack trace.
Как исправить 429 RESOURCE_EXHAUSTED: реальная квота, применение billing и «ghost 429»

Официальное объяснение 429 звучит просто: вы превысили лимит. Проблема в том, что для 2026 года это слишком грубое описание. На странице rate limits Google напоминает две вещи. Во-первых, активные лимиты смотрятся в AI Studio и могут меняться со временем. Во-вторых, компания прямо пишет, что опубликованные ограничения не являются гарантированной фиксированной пропускной способностью. Если вы ориентируетесь на старую таблицу из блога, то легко принять неверное решение.
Самый важный недавний сдвиг — корректировка квот с 7 декабря 2025 года. Документация Firebase AI Logic подтверждает эту дату и предупреждает, что изменения могут вызывать неожиданные 429 как на Free Tier, так и на Paid Tier 1. Именно этим объясняется ситуация, когда код почти не менялся, а частота 429 резко выросла.
Вторая деталь, которую систематически путают, — лимиты применяются на уровне проекта и billing account, а не отдельного API key. Billing-документация Gemini прямо говорит, что ключ наследует состояние проекта и счёта. Поэтому создание нового ключа в том же проекте не создаёт новую квоту. Если проект ограничен, неправильно связан с billing или находится в промежуточном состоянии после смены tier, новый ключ обычно повторит ту же проблему.
Практически 429 удобно делить на три сценария:
| Сценарий 429 | Как выглядит | Что делать в первую очередь |
|---|---|---|
| Реальный лимит | Всплески трафика, высокая конкуррентность, большие prompts | Backoff, очередь, уменьшение токенов и пиков |
| Billing только что включили | Tier 1 уже активировали, но поведение похоже на free tier | Проверить проект и подождать несколько минут |
| «Ghost 429» | На панели низкое потребление, но 429 идёт почти сразу | Проверить проект, billing account и quota details в ошибке |
Форум Google AI Developers добавляет важную оговорку: несколько платных проектов сообщали о persistent 429 даже при низком потреблении, а в некоторых ответах всплывали free-tier quota metric. Это не значит, что любой 429 — проблема платформы. Но это означает, что нельзя автоматически отвечать "вы просто слишком быстро шлёте запросы". Если low-traffic проект с включённым billing почти сразу начинает сыпать 429, гипотеза о рассинхронизации tier или quota-state вполне обоснована.
Когда 429 действительно вызван лимитом, исправления остаются приземлёнными, но рабочими: уменьшить burst-трафик, объединять мелкие запросы, урезать ненужный контекст, выстроить очередь и добавить exponential backoff с jitter. Если нужна большая устойчивость, официальный путь — перейти на Tier 1 и выше. Документация rate limits отдельно уточняет: переход с Free на Tier 1 обычно происходит сразу, а более высокие переходы занимают около 10 минут. Если вы давно включили billing, но поведение всё ещё выглядит как free tier, думайте в первую очередь о конфигурации и распространении состояния, а не о неправильной математике нагрузки.
Когда проблема уже не в одной ошибке, а в устойчивости production API-маршрута, разговор меняется. Для команд, которым нужен единый OpenAI-совместимый вход в несколько моделей и провайдеров, laozhang.ai может быть уместен как relay-вариант, но только если реальная боль — routing, стабильность и отказоустойчивость, а не просто неверный request.
Для более широкой картины посмотрите нашу полную инструкцию по ошибкам Gemini API, гайд по повышению квоты Gemini API и обзор бесплатного уровня Google Gemini API.
Как исправить 400: различайте INVALID_ARGUMENT и FAILED_PRECONDITION
400 — это та семья ошибок, на которой команды чаще всего теряют время, потому что обрабатывают её как один и тот же случай. На самом деле нет. Официальная документация Gemini явно разделяет INVALID_ARGUMENT и FAILED_PRECONDITION, а значит, и действия должны быть разными.
Сначала — INVALID_ARGUMENT. Google пишет, что ошибка возникает, когда тело запроса сформировано неверно, отсутствует обязательное поле или вы используете возможность более новой версии API через более старый endpoint. Это критически важное замечание. Ваш JSON может быть синтаксически валидным, но если вы идёте в /v1 с функцией, которая существует только в /v1beta, или если выбранная модель не поддерживает текущую комбинацию параметров, backend всё равно вернёт INVALID_ARGUMENT.
На практике самые частые причины такие: устаревшее или уже отключённое имя модели, параметры вне поддерживаемого диапазона, неверный nesting в payload, неподходящий поток работы с файлами или endpoint, который не поддерживает нужную вам возможность. Поэтому правильный порядок починки 400 — не "давайте ещё раз попробуем". Правильный порядок — "проверить модель, endpoint, payload и только потом заново вызвать API".
| Тип 400 | Самая частая причина | Первый фикс |
|---|---|---|
INVALID_ARGUMENT без деталей | Неверный JSON или структура полей | Сверить payload с официальным свежим примером |
INVALID_ARGUMENT после включения новой функции | Неподходящая версия endpoint или модель | Согласовать /v1 или /v1beta с реальной поддержкой |
INVALID_ARGUMENT при файлах / крупных запросах | Неправильный upload flow или слишком сложный request | Перенести файл в правильный поток, упростить payload |
FAILED_PRECONDITION | Не выполнено требование billing или региона | Включить billing или поменять путь использования |
FAILED_PRECONDITION особенно часто толкает команды чинить не тот слой. Если бесплатный tier Gemini API недоступен в вашей стране, а billing не включён, то проблема не в JSON. Проблема в том, что проект не удовлетворяет предусловию доступа. Пока вы не исправите план или регион, любые косметические правки payload ничего не изменят.
При этом полезно помнить и про ещё один реалистичный сценарий. В community-thread'ах встречались случаи, когда один и тот же поток запросов без изменений внезапно начинал отдавать 400 INVALID_ARGUMENT, а потом сам восстанавливался. Правильный вывод здесь не в том, что 400 теперь "можно ретраить", а в том, что если неизменный payload ломается только на одной модели, стоит проверить его ещё на соседней модели, прежде чем полностью переписывать рабочую логику.
Как исправить 500 INTERNAL: длинный контекст, нестабильность модели и безопасные ретраи
Официальная Gemini-документация прямо указывает, что 500 INTERNAL может означать неожиданный сбой на стороне Google, но также может быть вызван слишком длинным входным контекстом. Официальная рекомендация — уменьшить контекст или временно переключиться на другую модель, например с Gemini 2.5 Pro на Gemini 2.5 Flash.
Это отлично сочетается с модельной документацией. У Gemini 2.5 Pro лимит ввода составляет 1 048 576 токенов, что идеально для сложных задач, кода и документов, но одновременно подталкивает разработчиков думать: "если укладываюсь в максимум, значит всё должно быть стабильно". На практике это не так. Чем тяжелее совокупный запрос — длиннее история, больше файлов, сложнее системная инструкция, — тем выше риск 500 даже при теоретически допустимом размере.
Поэтому первое правило для 500 очень скучное, но очень полезное: сначала уменьшите вход. Уберите дублирующиеся инструкции, сократите историю, уменьшите число retrieval-chunks и перестаньте отправлять всё подряд только потому, что модель "формально может принять". Часто этого уже достаточно, чтобы запрос начал проходить.
Вторая форма 500 — модельная нестабильность. На форуме Google AI Developers были периоды, когда Gemini 2.5 Pro широко отдавал 500, а Flash продолжал работать. В такой ситуации самый полезный тест — отправить тот же payload в Flash. Если Flash проходит, а Pro нет, то самый быстрый operational fix — временно перейти на Flash, а не часами искать проблему в своём коде.
Практический порядок действий для 500 обычно такой:
- Проверить, не слишком ли большой и тяжёлый текущий запрос.
- Включить bounded backoff с jitter.
- Если использовался Pro, прогнать тот же payload через Flash.
- Если ошибка повторяется даже на более компактном запросе и затрагивает несколько случаев, считать это platform incident и не тратить всё время только на локальную отладку.
Для частного случая перегрузки сервиса можно посмотреть нашу статью о Gemini 3 Pro Image 503 overloaded.
Troubleshooting-процесс для повторяющихся сбоев Gemini API
Когда один и тот же тип ошибки возвращается снова и снова, перестаньте чинить каждую отдельную попытку и переведите ситуацию в процесс. Это лучший способ не бегать хаотично между логами, AI Studio, Cloud Console и кодом.
Зафиксируйте один failing payload и, если возможно, один successful payload. Сравните модель, endpoint, размер контекста, параметры и наличие файлов. Если отличие прежде всего в объёме трафика — думайте о 429. Если отличие в форме payload — о 400. Если тот же payload работает на одной модели и падает на другой — о модельной или платформенной нестабильности.
Ключевой вопрос очень простой: время помогает или нет? Для 429 и многих 500 — да. Для детерминированного 400 — почти никогда. Если вы уже три раза подряд повторили один и тот же INVALID_ARGUMENT, вы не стали ближе к решению, вы просто сожгли часть квоты.
| Шаг | Что проверить | Зачем это нужно |
|---|---|---|
| 1 | Полный error-body и модель | Не спутать provider incident с локальным багом |
| 2 | /v1 или /v1beta | Быстро раскрывает многие 400 по версии |
| 3 | Размер prompt и файлов | Проясняет большое число 500 и часть 400 |
| 4 | Проект и billing account | Убирает огромную долю путаницы вокруг 429 |
| 5 | Тот же payload на другой модели | Отделяет ошибку запроса от нестабильности модели |
Для production есть ещё одно правило: никогда не оставляйте в логах только строку "Gemini API returned error". Сохраняйте модель, endpoint version, примерный размер и нормализованный тип ошибки. Со временем именно это даёт реальное понимание, где ломается система.
Production-шаблон ретраев: что повторять, а что завершать сразу
В логике повторных запросов важнее не точная формула ожидания, а граница между retriable и non-retriable ошибками. Для Gemini практическое правило такое: повторяйте 429, 500, 503 и 504 с bounded backoff; 400, 401, 403 и 404 завершайте сразу, если между попытками вы реально ничего не меняли.
Python
pythonimport random import time from google import genai from google.genai import errors client = genai.Client(api_key="YOUR_GEMINI_API_KEY") RETRYABLE = {429, 500, 503, 504} FAIL_FAST = {400, 401, 403, 404} def generate_with_retry(model: str, contents, max_retries: int = 5): for attempt in range(max_retries): try: return client.models.generate_content(model=model, contents=contents) except errors.ClientError as exc: status = getattr(exc, "code", None) message = str(exc) if status in FAIL_FAST: raise RuntimeError( f"Non-retryable Gemini error {status}: {message}" ) from exc if status in RETRYABLE and attempt < max_retries - 1: delay = min(2 ** attempt, 30) jitter = random.uniform(0, delay * 0.2) time.sleep(delay + jitter) continue raise RuntimeError( f"Retry budget exhausted after Gemini error {status}: {message}" ) from exc
Node.js
tsimport { GoogleGenAI } from "@google/genai"; const client = new GoogleGenAI({ apiKey: process.env.GEMINI_API_KEY! }); const retryable = new Set([429, 500, 503, 504]); const failFast = new Set([400, 401, 403, 404]); export async function generateWithRetry(model: string, contents: string) { for (let attempt = 0; attempt < 5; attempt += 1) { try { return await client.models.generateContent({ model, contents }); } catch (error: any) { const status = error?.status ?? error?.code ?? 0; if (failFast.has(status)) { throw new Error(`Non-retryable Gemini error ${status}: ${error.message}`); } if (retryable.has(status) && attempt < 4) { const delayMs = Math.min(1000 * 2 ** attempt, 30000); const jitterMs = Math.random() * delayMs * 0.2; await new Promise((resolve) => setTimeout(resolve, delayMs + jitterMs)); continue; } throw error; } } }
Суть этого кода не в количестве секунд, а в дисциплине. Если вы автоматически ретраите INVALID_ARGUMENT, вы множите бесполезные ошибки. Если вы не ретраите 429 и 500 вообще, вы преждевременно отказываетесь от запросов, которые часто проходят после небольшой паузы.
Почему старые советы больше не работают: изменения 2026 года
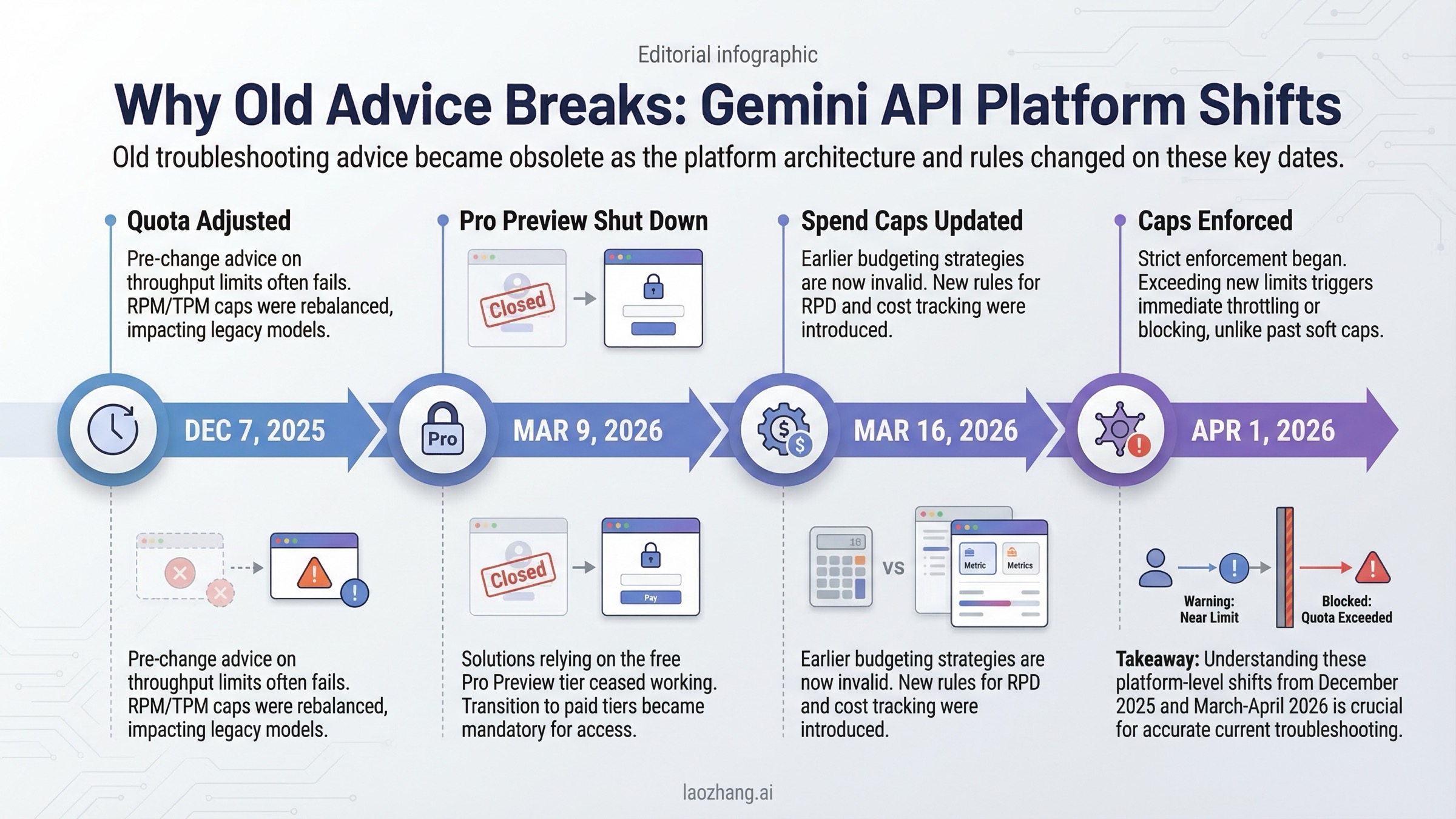
Многие старые статьи про Gemini предполагают, что платформа остаётся неизменной. Для 2026 года это уже неверно. На текущую отладку влияют как минимум такие даты:
| Дата | Что изменилось | Почему это влияет на отладку |
|---|---|---|
| 2025-12-07 | Скорректированы квоты Free Tier и Paid Tier 1 | Объясняет рост 429 без изменения кода |
| 2026-03-09 | Отключён Gemini 3 Pro Preview | Старые model names и aliases внезапно ломают запросы |
| 2026-03-12 | В AI Studio появились project spend caps | Бюджетные ограничения вошли в troubleshooting |
| 2026-03-16 | Обновлены usage tiers и billing caps | Старые предположения о квоте устарели |
| 2026-04-01 | Начинается применение tier spend caps | Ограничение расходов может выглядеть как случайный простой |
Именно поэтому многие старые "полные гиды" сегодня ощущаются недостаточными: они не привязаны к датам и не помогают отличить устойчивые правила от уже устаревших предположений.
FAQ
Тарифицируются ли неуспешные запросы?
Обычно нет, если ошибка относится к 400 или 500. Официальный billing FAQ говорит, что такие запросы не оплачиваются по токенам, но продолжают расходовать квоту.
Лимиты Gemini считаются по ключу или по проекту?
Думайте в терминах проекта и billing account. Ключ наследует состояние проекта; новый ключ внутри того же проекта не создаёт новую квоту.
Сколько занимает активация billing?
Google пишет, что переход с Free на Tier 1 обычно происходит мгновенно, а последующие upgrade'ы — примерно в течение 10 минут. Если прошло больше, а проект всё ещё ведёт себя как free tier, проверяйте связку проекта, key и billing account.
Когда стоит переключаться с Gemini 2.5 Pro на Gemini 2.5 Flash?
Когда тот же payload работает на Flash и падает на Pro, когда 500 явно связан с огромным контекстом, или когда важнее быстро восстановить сервис, чем сохранить максимальный уровень reasoning.
Есть ли одна официальная страница, которая решает все ошибки Gemini?
Нет. Официальный troubleshooting guide — лучший старт, но в 2026 году его нужно дополнять страницами rate limits, billing, pricing и release notes. Для более широкой картины посмотрите нашу полную инструкцию по ошибкам Gemini API.