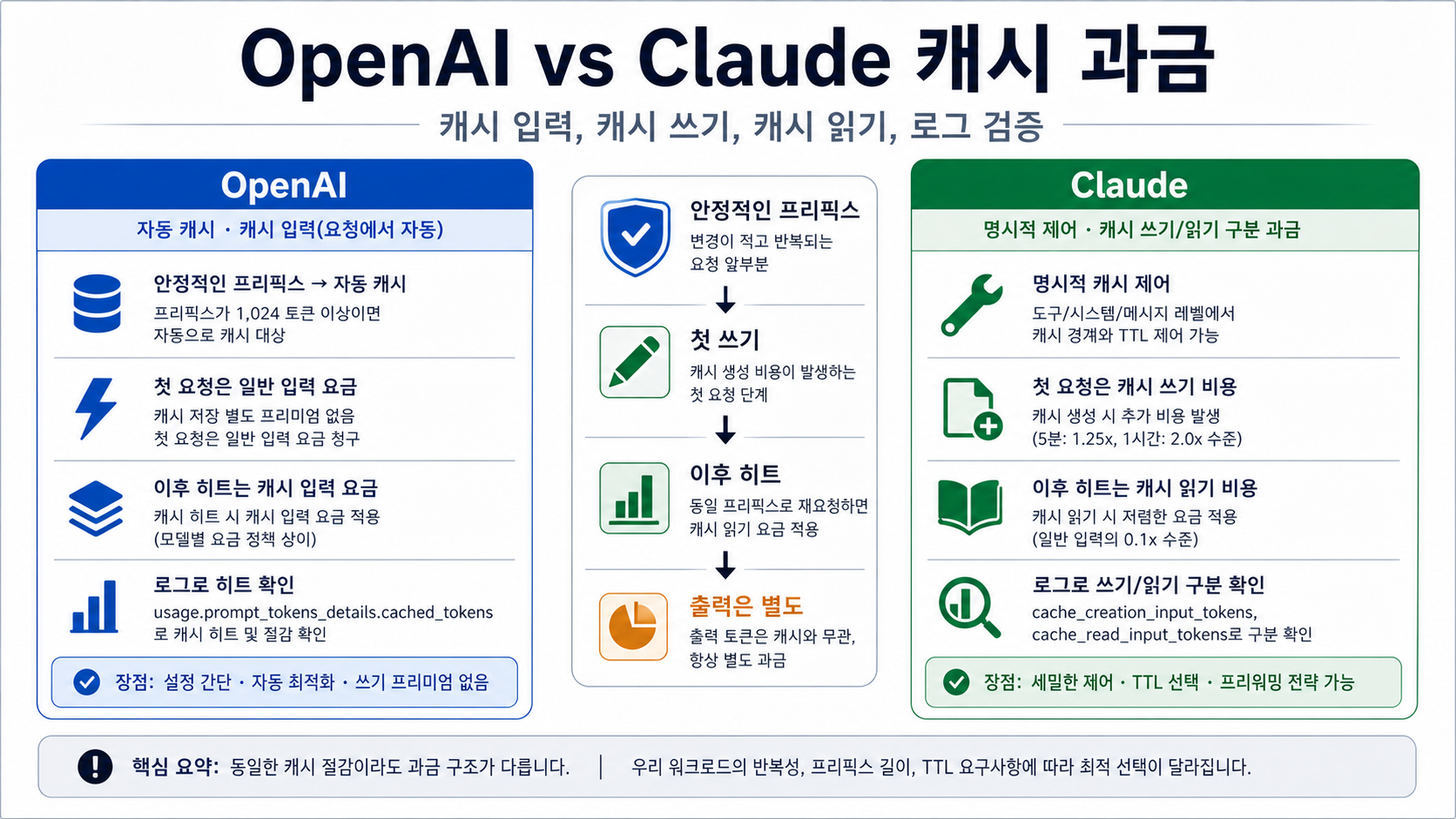
OpenAI와 Claude 모두 반복되는 긴 프롬프트 앞부분을 더 싸게 만들 수 있습니다. 하지만 같은 방식으로 청구되는 것은 아닙니다. 2026-05-19에 확인한 공식 가격 기준으로, OpenAI의 표준 GPT-5.5, GPT-5.4, GPT-5.4 mini 행은 cached input을 일반 input의 10분의 1로 표시하며 별도의 캐시 쓰기 프리미엄은 없습니다. Claude는 캐시 읽기가 기본 input의 0.1배이지만, 캐시를 처음 만들 때 쓰기 비용이 따로 있습니다. 5분 TTL 쓰기는 1.25배, 1시간 TTL 쓰기는 2배입니다.
그래서 “어느 쪽이 더 할인율이 큰가”만으로 예산을 잡으면 위험합니다. 안정적인 system prompt, tools, 제품 정책, 긴 참조 문서, 코드베이스 요약, few-shot 예시를 계속 재사용한다면 OpenAI는 자동 캐시로 먼저 검증하기 쉽습니다. 반대로 어떤 블록을 캐시할지, TTL을 어떻게 둘지, 긴 agent 컨텍스트를 어떻게 예열할지 제어해야 한다면 Claude가 더 맞을 수 있습니다. 어느 쪽이든 로그에 OpenAI의 usage.prompt_tokens_details.cached_tokens 또는 Claude의 cache_read_input_tokens, cache_creation_input_tokens, input_tokens가 보이기 전에는 절감을 확정하면 안 됩니다.
| 상황 | 먼저 볼 선택지 | 이유 | 확인할 로그 |
|---|---|---|---|
| 긴 고정 프리픽스가 매 요청 반복 | OpenAI | 자동 캐시, 별도 쓰기 프리미엄 없음 | cached_tokens |
| cache breakpoint와 TTL을 설계해야 함 | Claude | 쓰기와 읽기를 명시적으로 제어 | cache_creation_input_tokens, cache_read_input_tokens |
| 재사용이 1-2회뿐 | 둘 다 과대평가 금지 | 쓰기, miss, output이 절감을 줄임 | hit rate와 output 비중 |
| 요청 앞부분이 자주 바뀜 | prompt layout부터 수정 | 앞부분 변화는 miss를 만듦 | prefix hash |
| Batch, 장문 컨텍스트, 클라우드 경로 | 별도 계산 | 기본 가격표와 다를 수 있음 | 최신 공식 가격 |
결론: 할인율보다 재사용 구조가 먼저다
OpenAI는 안정적인 긴 프리픽스를 자주 보내는 API에서 단순합니다. 지원 모델에서는 캐싱이 자동으로 시도되고, 프롬프트가 1024 tokens 이상이어야 자격이 생기며, 앞부분이 일치하면 그 부분이 cached input으로 잡힙니다. 첫 요청에서 miss가 나면 일반 input으로 청구되고, 이후 hit가 나면 cached input 가격 행을 씁니다. 시스템 프롬프트와 도구 정의가 거의 변하지 않는 서비스라면, 먼저 로그를 켜고 실제 cached_tokens가 늘어나는지 보는 방식이 현실적입니다.
Claude는 캐시를 설계해야 하는 워크로드에 강합니다. tools, system, messages 계층과 cache breakpoint를 기준으로 어떤 부분을 저장할지 결정할 수 있고, 5분 또는 1시간 TTL을 선택할 수 있습니다. 하지만 이 제어력은 무료가 아닙니다. 첫 쓰기 비용이 있고, TTL이 지나면 다시 쓰거나 일반 input으로 돌아갈 수 있습니다. 읽기 횟수가 충분히 많지 않으면 0.1x read 가격은 전체 비용을 크게 낮추지 못합니다.
“캐시 토큰 90% 절감”, “OpenAI 50% 할인”, “Claude 캐시 입력이 저렴” 같은 표현만으로는 예산을 잡기 어렵습니다. 이 표현들은 특정 시점 또는 특정 청구 항목만 설명합니다. 현재 OpenAI 표준 행은 10분의 1 cached input을 보여주고, 오래된 50% 설명은 그대로 쓰면 안 됩니다. Claude는 읽기가 싸지만 쓰기가 먼저 있습니다. 출력 토큰은 두 공급자 모두 별도로 청구됩니다.
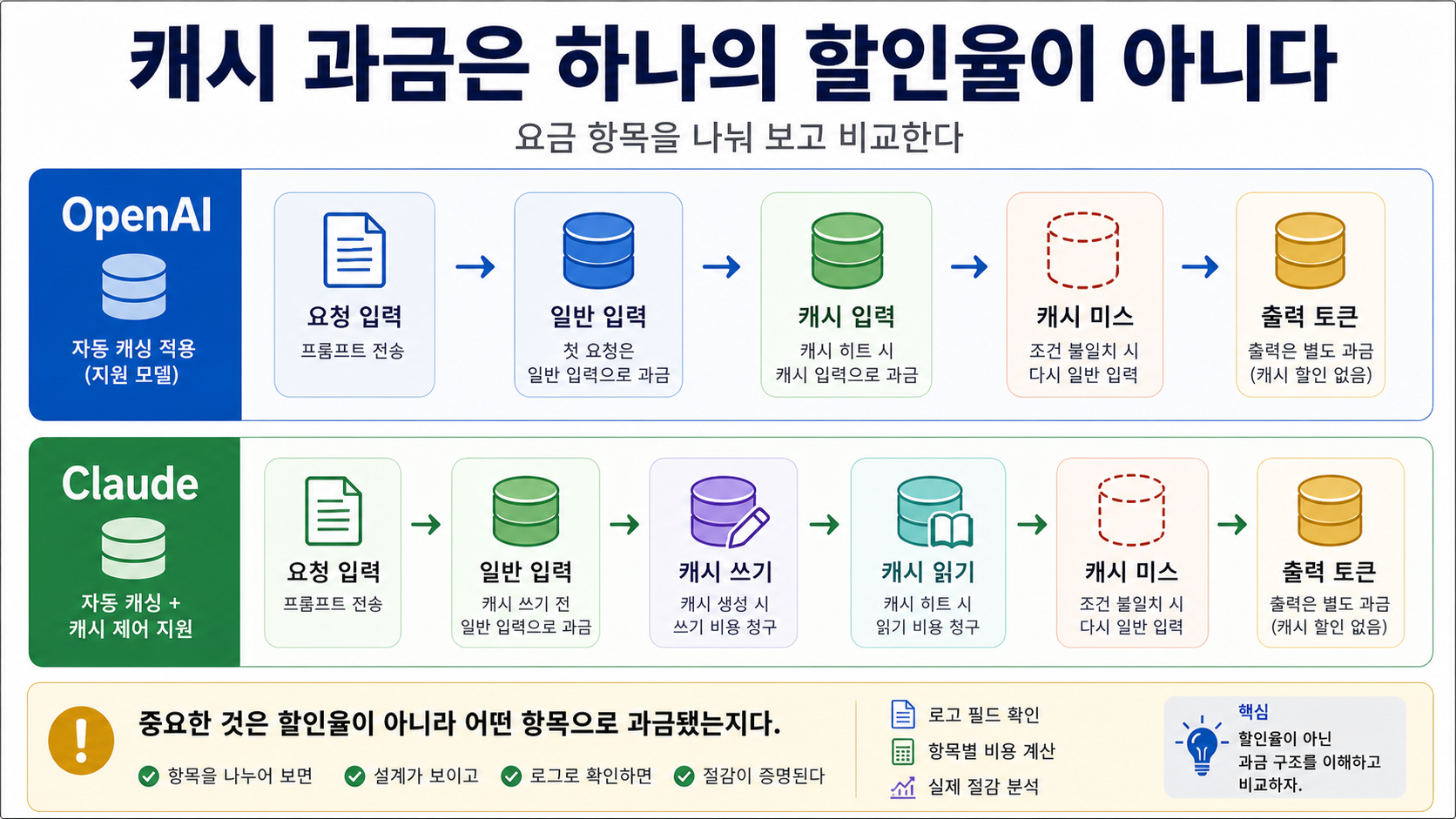
청구 항목을 먼저 분리한다
OpenAI의 cached input은 hit가 난 입력 부분에 적용되는 가격 행입니다. 현재 표준 모델 설명에서는 캐시를 만들기 위한 별도 쓰기 프리미엄이 보이지 않습니다. 요청이 자격을 갖추고 안정적인 프리픽스가 반복되면, 후속 요청의 해당 부분이 cached input으로 잡힙니다.
Claude는 cache write와 cache read를 분리합니다. cache write는 캐시를 만들거나 갱신할 때의 입력입니다. cache read는 후속 요청이 기존 캐시를 읽을 때의 입력입니다. 여기에 일반 input과 output tokens가 더해집니다. 따라서 Claude 비용은 “read가 0.1배이니 전체가 90% 싸다”가 아니라 “처음에 얼마나 썼고, 이후 몇 번 읽었는가”로 계산해야 합니다.
| 항목 | OpenAI | Claude | 의미 |
|---|---|---|---|
| 일반 입력 | miss, 새 입력, 비대상 부분 | 새 입력, miss | 항상 존재 가능 |
| 캐시 쓰기 | 별도 premium 없음 | 5분 1.25x, 1시간 2x | Claude의 초기 비용 |
| 캐시 읽기 | cached input | cache read 0.1x | hit가 있어야 발생 |
| 캐시 미스 | 일반 input으로 회귀 | 일반 input 또는 새 write | 예산 오차 원인 |
| 출력 토큰 | 별도 청구 | 별도 청구 | 긴 출력은 절감률을 낮춤 |
이렇게 나누면 “어디가 싸다”보다 “우리 요청이 어느 항목에 들어갔는가”가 중요해집니다. 프리픽스가 안정적인지, TTL 안에 반복되는지, 실제 hit가 로그에 남는지 먼저 확인해야 합니다.
2026-05-19 기준 가격 읽기
OpenAI 가격표에서 표준 short context 기준 GPT-5.5는 1M tokens당 input $5.00, cached input $0.50, output $30.00이었습니다. GPT-5.4는 $2.50, $0.25, $15.00이고, GPT-5.4 mini는 $0.75, $0.075, $4.50입니다. 핵심은 이 표준 행에서 cached input이 input의 10분의 1이고, 별도 쓰기 비용이 없다는 점입니다. Pro 행이나 long context 행은 같은 규칙이라고 가정하지 말고 현재 가격표에서 따로 확인해야 합니다.
Claude 가격표는 처음부터 쓰기와 읽기를 보여줍니다. Opus 4.7, 4.6, 4.5는 input $5, 5분 write $6.25, 1시간 write $10, read $0.50, output $25입니다. Sonnet 4.6, 4.5는 $3, $3.75, $6, $0.30, $15입니다. Haiku 4.5는 $1, $1.25, $2, $0.10, $5입니다. 이 구조 때문에 Claude는 첫 요청과 이후 요청을 반드시 분리해서 계산해야 합니다.
가격은 자주 바뀝니다. 모델명, 지원 모델, 최소 토큰, 데이터 거주지, Batch, long context, 클라우드 마켓플레이스, 기업 계약, rate limit 정책은 모두 최신 문서를 봐야 합니다. 금액을 문서화할 때는 확인 날짜를 같이 적는 것이 안전합니다.
반복 프리픽스의 손익분기 계산
100k tokens의 안정적인 프리픽스를 10번 연속 사용한다고 가정합니다. 새 입력과 출력은 일단 제외합니다. OpenAI GPT-5.4는 input이 $2.50 / 1M, cached input이 $0.25 / 1M입니다. 첫 요청이 miss이면 100k 프리픽스가 약 $0.25입니다. 이후 9번 hit가 나면 각 요청은 약 $0.025이고, 9번 합계는 약 $0.225입니다. 반복 프리픽스 입력만 보면 10번 합계는 약 $0.475입니다.
Claude Sonnet 4.6의 5분 캐시에서는 input이 $3 / 1M, write가 $3.75 / 1M, read가 $0.30 / 1M입니다. 첫 100k write는 약 $0.375입니다. 이후 9번 read는 각 $0.03, 합계 $0.27입니다. 반복 프리픽스 기준 합계는 약 $0.645입니다. 1시간 TTL을 쓰면 첫 쓰기는 더 비싸지만, 긴 시간 동안 같은 컨텍스트를 재사용할 수 있습니다.

이 예시는 승자를 고정하지 않습니다. OpenAI는 자동과 단순함이 강점이고, Claude는 경계와 TTL 제어가 강점입니다. 실제 비용은 hit rate, TTL 내 반복 횟수, 출력 길이, 새 입력량, miss 빈도까지 같이 계산해야 합니다.
Prompt layout이 hit를 만든다
캐시는 “의미가 비슷한 요청”에 적용되는 것이 아닙니다. OpenAI에서는 같은 앞부분이 반복되는 것이 중요합니다. system prompt, tools, 고정 정책, 스키마, 긴 참조 데이터, few-shot 예시는 앞에 두고, 사용자 입력, 시간, trace id, 외부 조회 데이터, 세션별 값은 뒤에 둡니다. prompt_cache_key는 라우팅과 hit rate에 도움을 줄 수 있지만, 불안정한 프리픽스를 대신 안정화해 주지는 않습니다.
Claude는 계층이 더 중요합니다. tools, system, messages 순서와 cache breakpoint 앞부분이 바뀌면 뒤쪽 캐시도 깨질 수 있습니다. 따라서 변하지 않는 tools와 system을 먼저 고정하고, 자주 바뀌는 user content를 뒤쪽에 둬야 합니다. 이 원칙을 지키면 반복 write가 줄고 read가 늘어납니다.
운영 로그에는 prefix hash를 넣는 것이 좋습니다. system prompt 버전, tools 버전, model, endpoint, region, cache policy를 같이 기록하면, 어느 변경 때문에 hit rate가 떨어졌는지 추적할 수 있습니다. hash가 바뀌었다면 비용 상승 원인은 가격표가 아니라 요청 형태일 수 있습니다.
로그로 절감을 검증한다
OpenAI에서 가장 먼저 볼 필드는 usage.prompt_tokens_details.cached_tokens입니다. 이 값이 0이면 해당 요청에서는 cached input 절감을 주장하면 안 됩니다. model, endpoint, request_id, total input, output, prefix_hash, prompt_cache_key 사용 여부도 같이 저장해야 합니다.
Claude에서는 cache_creation_input_tokens, cache_read_input_tokens, input_tokens를 함께 봅니다. creation이 크면 쓰기 비용이 발생한 것입니다. read가 크면 기존 캐시를 실제로 읽은 것입니다. input은 새 입력 또는 캐시되지 않은 부분입니다. 세 값을 분리해야 hit, write, miss를 제대로 분류할 수 있습니다.
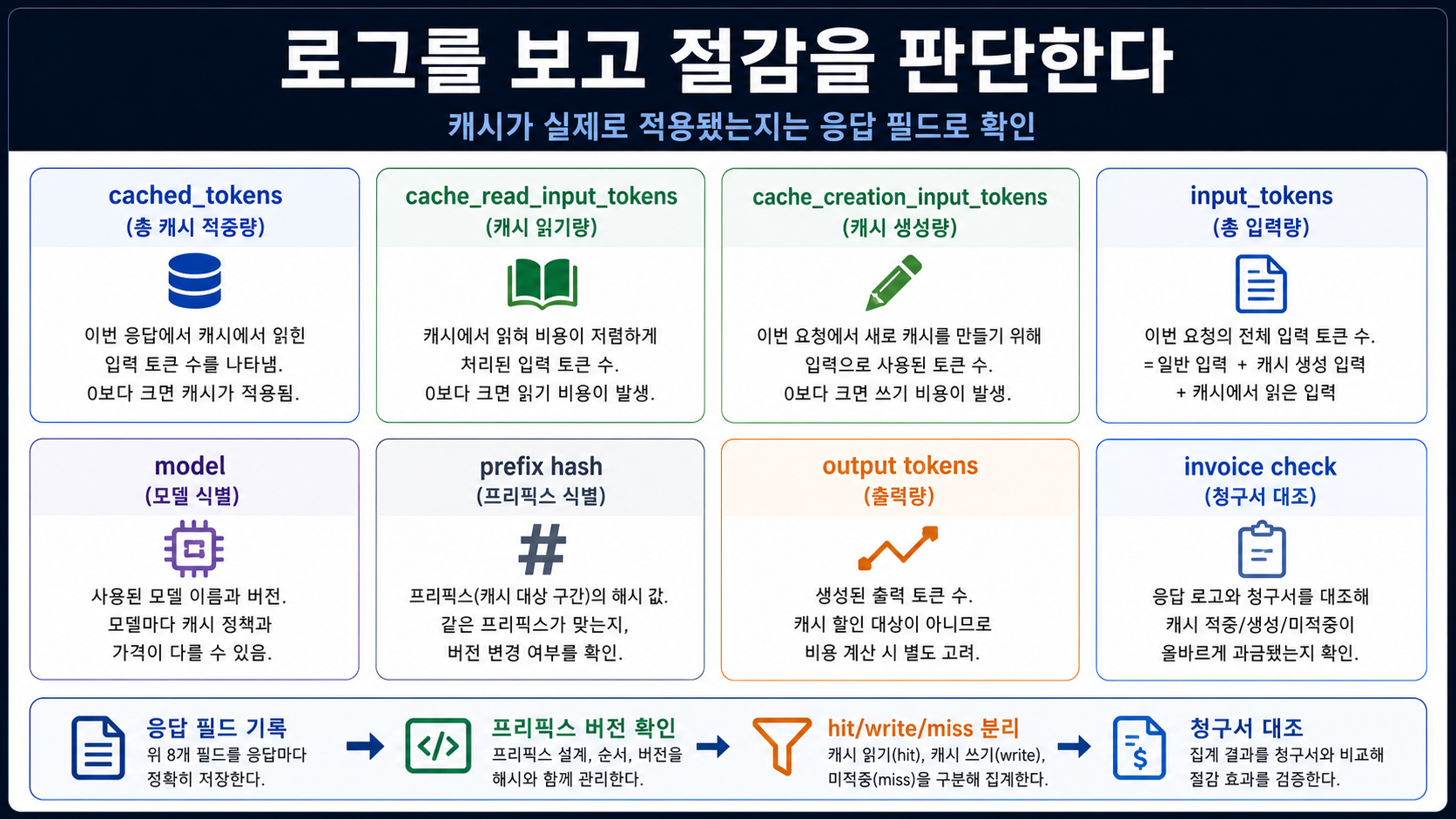
최소 로그 테이블에는 provider, model, endpoint, request_id, prefix_hash, cache policy, cached/read/creation/input/output tokens, retry, latency, invoice period가 들어가야 합니다. 하루 정도의 작은 샘플만 있어도 캐시를 위해 prompt layout을 바꿀 가치가 있는지 볼 수 있습니다.
가격 수정 항목은 따로 둔다
Batch, Scale Tier, long context, 데이터 거주지, 클라우드 마켓플레이스, 기업 계약은 기본 계산과 다를 수 있습니다. Claude의 1시간 TTL은 긴 재사용 창을 만들지만 write가 비쌉니다. OpenAI의 확장 보존 정책과 지원 모델도 계속 바뀔 수 있습니다. 이런 요소를 기본 손익분기 예시에 섞으면 설명은 간단해지지만 예산은 부정확해집니다.
rate limit도 공급자마다 다릅니다. OpenAI 문서는 cached tokens가 TPM에 포함된다고 설명합니다. Claude 문서에는 특정 캐시 사용이 rate limit 활용에 다른 영향을 줄 수 있다는 설명이 있습니다. 비용 모델 옆에는 capacity 모델도 있어야 합니다. 요청 수, input, cache read, output, retry, error를 함께 봐야 합니다.
OpenAI를 먼저 볼 때
OpenAI는 안정적인 긴 프리픽스가 있고, 여러 cache segment를 세밀하게 제어할 필요가 없을 때 먼저 테스트하기 좋습니다. 고객지원 봇, 고정 정책 질의응답, 동일 schema 분석, 매번 같은 tools를 가진 agent, 긴 system prompt 기반 서비스가 여기에 들어갑니다. 변경이 작고 로그로 확인하기 쉽습니다.
하지만 OpenAI 자동 캐시가 모든 반복 비용을 줄여 주는 것은 아닙니다. 입력이 짧거나, 모델이 지원하지 않거나, 앞부분이 자주 바뀌거나, output이 매우 길면 절감은 작아집니다. OpenAI를 선택하는 근거는 “자동이라서”가 아니라 “우리 트래픽에서 cached_tokens가 실제로 잡혀서”여야 합니다.
Claude를 먼저 볼 때
Claude는 캐시 경계와 TTL을 설계할 수 있는 팀에 적합합니다. 긴 tools, 안정적인 system layer, 코드베이스 요약, 여러 단계의 agent, 같은 컨텍스트를 예열해 여러 번 쓰는 워크로드에서는 명시적 제어가 유리합니다. 어떤 블록을 5분만 유지하고 어떤 블록을 1시간 유지할지 선택할 수 있습니다.
반대로 동적 데이터가 앞쪽 계층에 섞이거나, TTL이 자주 만료되거나, read 횟수가 적거나, creation/read 로그를 보지 않으면 Claude 비용은 예측하기 어렵습니다. Claude는 강력하지만 로그 없이 저렴한 선택지는 아닙니다.
구현 체크리스트
- 안정적인 system/tools/context를 요청 앞쪽에 둔다.
- user input, 시간, trace id, 외부 조회 데이터는 뒤쪽으로 보낸다.
- prefix hash와 prompt version을 기록한다.
- OpenAI는
cached_tokens, Claude는 creation/read/input 필드를 기록한다. - 첫 요청과 이후 hit를 같은 테스트에서 비교한다.
- output tokens는 별도 비용으로 계산한다.
- model, endpoint, TTL, 가격표, cloud route가 바뀌면 다시 계산한다.
OpenAI, Claude, Gemini의 전체 API 가격 비교가 필요하면 여러 API 제공자 비용 비교를 함께 보세요. prompt caching 과금 구조는 모델 품질, 추론 성능, tool use 선택과 분리해서 판단하는 것이 좋습니다.
자주 묻는 질문
OpenAI prompt caching은 아직 50% 할인인가요?
일반 규칙으로 쓰면 안 됩니다. 50%는 오래된 GPT-4o / o1 시기 설명에서 자주 나옵니다. 2026-05-19에 확인한 표준 GPT-5.5, GPT-5.4, GPT-5.4 mini 가격 행은 cached input을 일반 input의 10분의 1로 표시했습니다. 현재 가격표를 기준으로 다시 확인해야 합니다.
Claude에는 왜 write cost가 있나요?
Claude는 캐시를 만드는 입력과 캐시를 읽는 입력을 분리해서 청구합니다. write는 처음 만들거나 갱신할 때 발생하고, read는 이후 hit에서 낮은 가격으로 적용됩니다. 제어가 가능한 대신 손익분기에 첫 write를 반드시 넣어야 합니다.
Output tokens도 할인되나요?
아니요. Prompt caching은 반복되는 입력 프리픽스를 줄이는 방식입니다. 출력이 길면 전체 청구액에서 절감률은 입력 할인율보다 낮아집니다.
1024 tokens보다 짧아도 캐시가 적용되나요?
OpenAI는 prompt caching 자격을 1024 tokens 이상으로 설명합니다. Claude는 모델별 최소 토큰 수가 다릅니다. 임계값은 모델과 시점에 따라 바뀔 수 있으므로 현재 문서를 확인해야 합니다.
Claude는 수동 cache_control만 지원하나요?
아니요. 현재 Claude 문서에는 자동 top-level cache control과 명시적 block-level cache control이 모두 있습니다. 다만 복잡한 워크로드에서는 어떤 블록이 안정적인지 설계하는 일이 여전히 중요합니다.
예상보다 청구가 높을 때 무엇을 봐야 하나요?
prefix hash, model, endpoint, TTL, miss, Claude write 횟수, OpenAI cached_tokens, output tokens, 특수 가격 조건을 순서대로 봐야 합니다. 총 token만 보면 원인을 찾기 어렵습니다.
캐시 과금만 보고 공급자를 바꿔도 되나요?
긴 안정 프리픽스, 높은 hit rate, 충분한 반복 횟수, 통제 가능한 output, 로그 기반 검증이 있을 때만 고려하세요. 먼저 layout과 로그를 개선한 뒤 실제 비용으로 OpenAI와 Claude를 비교하는 것이 안전합니다.