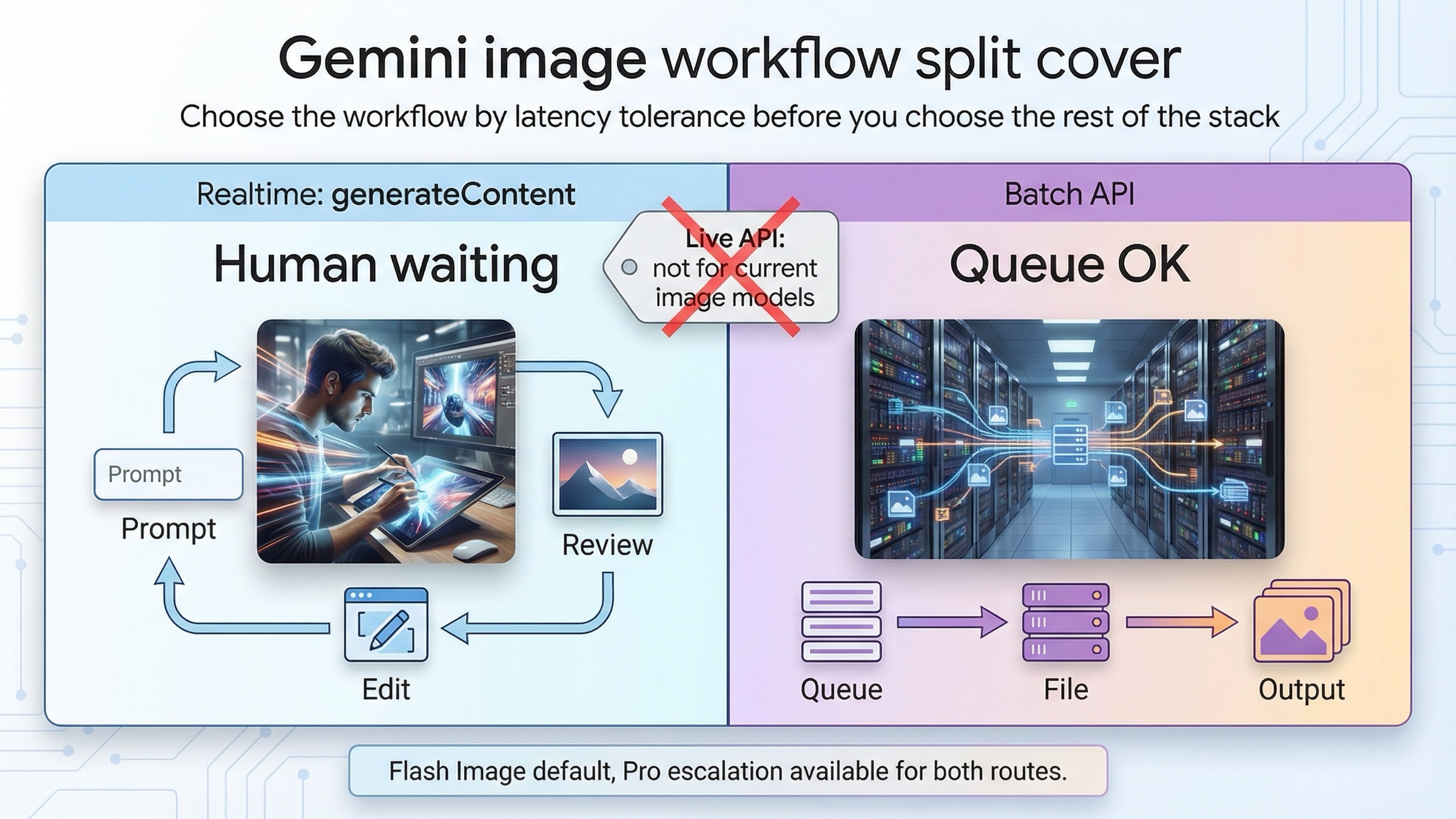
2026년 3월 23일 기준으로 Gemini 이미지 생성의 기본 규칙은 꽤 단순합니다. 사람이 결과를 바로 기다리고 있다면 동기 generateContent, 작업이 대량이고 급하지 않다면 Batch API입니다. 이 질문은 가격표보다 워크플로 분기부터 보는 편이 낫습니다. 지금 필요한 것이 상호작용형 반복인지, 아니면 기다려도 되는 큐 처리인지 먼저 정하면 모델 선택과 비용 판단이 훨씬 쉬워집니다.
시작부터 하나 더 분명히 해야 할 점이 있습니다. 현재 Gemini 이미지 모델에서 실시간은 Live API를 뜻하지 않습니다. gemini-3.1-flash-image-preview 와 gemini-3-pro-image-preview 모델 페이지에는 둘 다 Batch API 지원, Live API 미지원 이라고 표시되어 있습니다. 반면 현재 이미지 생성 공식 문서는 일반적인 동기 generateContent 요청과 multi-turn 편집을 중심으로 예시를 제공합니다. 즉, 이 주제에서 말하는 realtime은 라이브 이미지 스트림이 아니라, 빠르게 prompt를 고치며 주고받는 request-response형 이미지 생성입니다.
이 구분이 중요한 이유는 문서가 틀려서가 아니라 분산되어 있기 때문입니다. Batch API 문서, image generation 가이드, pricing 페이지, 모델 기능 페이지를 따로 보면 개별 사실은 이해되지만 실제 워크플로 판단은 흐려지기 쉽습니다. 필요한 것은 사실 모음이 아니라, 어떤 상황에서 무엇을 선택해야 하는지 한 번에 정리해 주는 운영 관점의 답입니다.
핵심 요약
짧은 답만 필요하다면 아래 표면 충분합니다.
| 질문 | 현재 가장 좋은 답 | 이유 |
|---|---|---|
| 사람이 이미지나 편집 결과를 기다리고 있나 | 동기 generateContent | 현재 공식 image guide가 prompt 반복과 multi-turn 편집을 동기 흐름으로 설명한다 |
| 작업이 크고, 급하지 않고, 비용이 중요하나 | Batch API | Batch API 문서에서 표준 비용의 50% 와 24시간 목표 처리 시간 을 제시한다 |
| 실시간을 Live API 세션으로 이해하고 있나 | 현재 이미지 모델에는 맞지 않는 이해 | 현행 이미지 모델 페이지에 Live API 미지원 이라고 적혀 있다 |
| 기본으로 시작할 모델은 무엇인가 | gemini-3.1-flash-image-preview | 현재 가장 무난한 효율 레인이고 gemini-2.5-flash-image 의 공식 대체 경로다 |
| 언제 Pro로 올려야 하나 | 텍스트, 레이아웃, 실패 비용이 비싸질 때 | gemini-3-pro-image-preview 가 텍스트 많은 이미지, 다이어그램, 고가치 결과물에 더 맞는다 |
| 가장 저렴한 공식 레인은 무엇인가 | gemini-2.5-flash-image | 다만 2026년 10월 2일 종료 예정인 legacy 라인이다 |
가장 흔한 실수는 Batch API가 더 싸다는 이유만으로 먼저 선택하는 것입니다. 할인은 실제지만, 지연이 워크플로 가치를 깨뜨리면 의미가 없습니다. 아직 prompt를 탐색 중이거나, 리뷰 루프가 있거나, 사용자 대기 시간이 중요한 도구라면 동기 경로가 대체로 맞습니다.
간단한 세 가지 예시는 이렇습니다.
- 사용자가 다음 이미지를 바로 기다리는 제품 기능: 동기
- 하루 안에 prompt를 다듬으며 진행하는 내부 크리에이티브 작업: 먼저 동기, 이후 안정화되면 batch
- 밤새 수천 개 변형을 돌리는 승인된 템플릿 작업: batch
코드 예제가 먼저 필요하다면 Gemini 이미지 생성 코드 예제 쪽이 더 가깝습니다. 비용이 중심이면 Gemini 이미지 생성 API 가격 가이드를 보는 편이 좋습니다. 실제 문제의 중심이 편집이라면 Gemini 이미지 편집 가이드가 더 정확합니다.
진짜 분기는 동기generateContent와 Batch API다
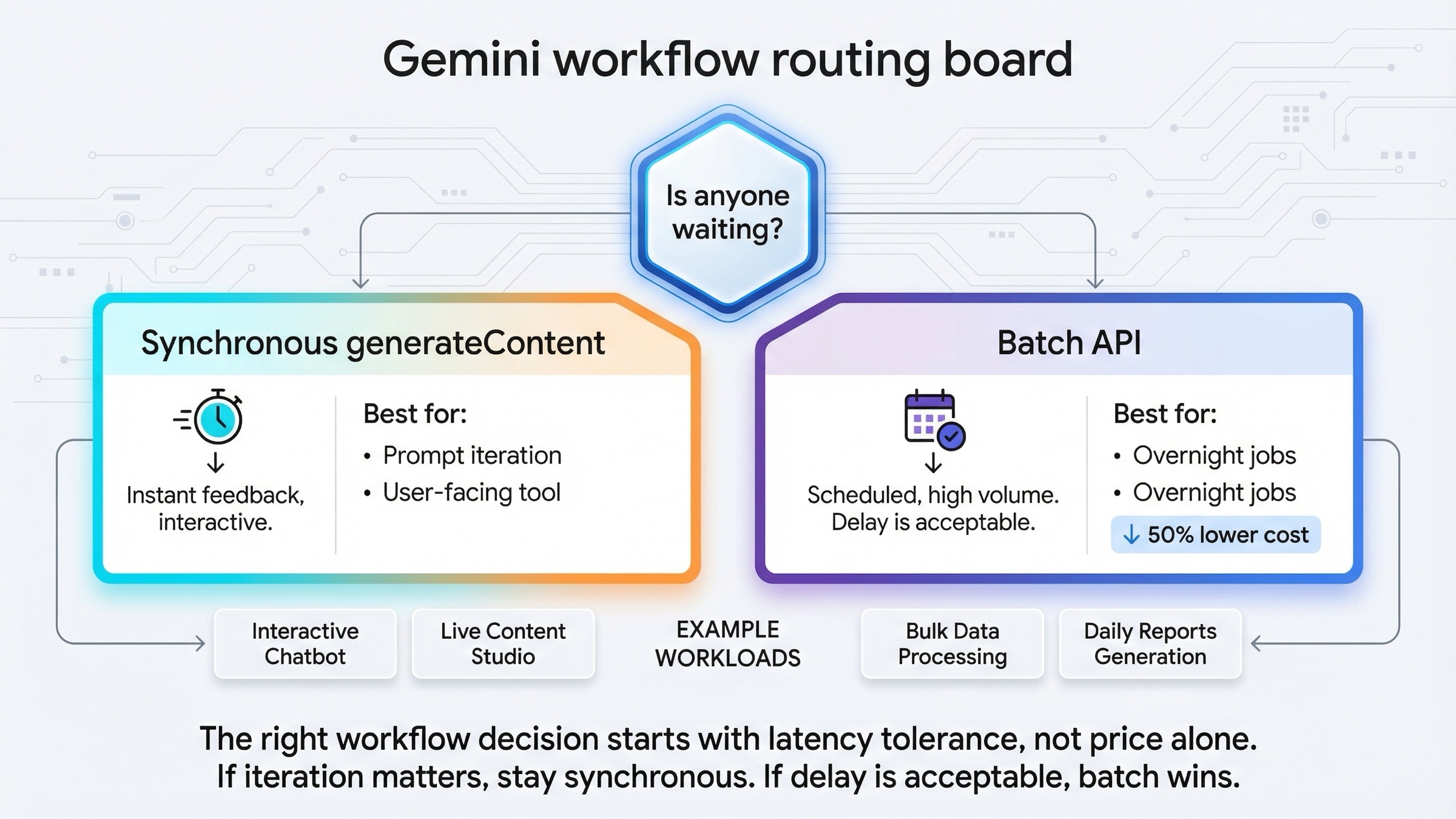
이 키워드로 들어오는 많은 사람들은 기술 질문을 하는 것처럼 보이지만, 사실은 운영 질문을 하고 있습니다. "batch냐 realtime이냐"라고 묻지만, 실제로 알고 싶은 것은 "이 작업을 대화형 루프 안에 둘 것인가, 아니면 안전하게 큐로 보낼 수 있는가"입니다.
그래서 먼저 물어야 하는 것은 가격이나 모델명이 아닙니다. 딱 한 문장입니다.
지금 이 결과를 기다리는 사람이 있는가.
답이 Yes라면 동기 경로에 남아야 합니다. 보통 이런 경우입니다.
- prompt 탐색
- 사용자 대상 이미지 도구
- 사람 검토가 들어가는 루프
- 단계적 이미지 편집
- 첫 결과가 약했을 때 즉시 재시도
답이 No라면 Batch API가 강해집니다. 보통 이런 경우입니다.
- 야간 대량 생성
- queue-driven 자산 파이프라인
- 대규모 카탈로그/변형 작업
- 급하지 않은 백필
- 이미 안정된 prompt 템플릿의 반복 실행
Batch API 문서는 이 trade-off를 명확하게 설명합니다. 대량 요청용 비동기 surface이며, 표준 비용의 50%, 24시간 목표 처리 시간 이라는 장점이 있습니다. 하지만 다음 사람이나 시스템 동작이 즉시 출력에 달려 있다면, 그 저렴함은 잘못된 방향일 수 있습니다.
반대도 마찬가지입니다. 동기 생성은 작은 테스트용 도구가 아닙니다. 빠른 반복에서 가치가 생기는 일이라면 동기가 본선입니다. 현재 이미지 생성 문서가 generation, editing, multi-turn refinement를 동기 예제로 보여주는 것도 이 때문입니다. 이미지 작업은 보통 "한 번의 prompt, 한 번의 결과, 한 번의 수정, 다음 턴"에서 가장 빨리 좋아집니다.
정리하면 규칙은 이것입니다.
- 상호작용형이고, 사람이 루프 안에 있고, 제품 경험과 직결되는 일은 동기
- 큐에 넣을 수 있고, 양이 많고, 급하지 않고, 단가 최적화가 중요한 일은 batch
이 관점은 흔한 설계 실수도 막아줍니다. 나중에 결국 큐가 필요하다는 사실이, 처음부터 큐로 시작해야 한다는 뜻은 아닙니다. 대부분은 먼저 동기로 prompt와 출력 처리를 검증한 뒤, 안정된 요청만 batch로 넘기는 편이 더 빠르고 안전합니다.
어떤 Gemini 이미지 모델을 각 워크플로 뒤에 두어야 하나
워크플로 선택과 모델 선택은 연결되어 있지만 같은 질문은 아닙니다. Batch는 모델이 아니고, 실시간도 모델이 아닙니다. 같은 이미지 모델을 동기 경로에도, batch 경로에도 둘 수 있습니다.
지금 새로 시작하는 대부분의 작업에서는 gemini-3.1-flash-image-preview 를 기본 답으로 두는 것이 합리적입니다. Google은 이를 현재의 고효율 이미지 레인으로 위치시키고 있고, deprecations 페이지에서는 gemini-2.5-flash-image 의 대체 경로로 다루고 있습니다.
| 모델 | 2026년 3월 23일 기준 위치 | Batch API | Live API | 가격 신호 | 잘 맞는 용도 |
|---|---|---|---|---|---|
gemini-3.1-flash-image-preview | 현재 기본 preview | 지원 | 미지원 | $0.067 / 1K image, batch $0.034 | 대부분의 신규 interactive workflow와 queue workflow |
gemini-3-pro-image-preview | 현재 premium preview | 지원 | 미지원 | $0.134 / 1K 또는 2K, batch $0.067 | 텍스트 많은 이미지, 다이어그램, 고품질 자산 |
gemini-2.5-flash-image | 아직 살아 있는 legacy 라인 | 지원 | 미지원 | $0.039 standard, $0.0195 batch | 지금 가장 싼 공식 레인이 필요할 때 |
이 표에서 중요한 것은 세 가지입니다.
첫째, 현재 Gemini 이미지 모델은 Batch API는 지원하지만 Live API는 지원하지 않습니다. 즉 이 주제를 live session 아키텍처처럼 다룰 필요가 없습니다.
둘째, gemini-3.1-flash-image-preview 가 지금의 default answer 라는 점입니다. 속도, 최신성, 유연성의 균형이 좋아 동기와 batch 둘 다에서 시작점으로 삼기 쉽습니다.
셋째, 가장 싼 레인과 가장 좋은 기본 레인은 다릅니다. gemini-2.5-flash-image 는 실제로 더 저렴하지만, Google은 여기에 2026년 10월 2일 종료일도 달아 두었습니다. 새 시스템을 이 모델로 시작한다면 중장기 표준이 아니라 의식적인 legacy 절약 선택이어야 합니다. 모델군 전체의 맥락을 더 보고 싶다면 Nano Banana 2, Pro, Imagen 4 비교가 더 적절합니다.
프롬프트 반복과 편집에 가장 좋은 실시간 워크플로
사람이 결과를 기다린다면 가장 좋은 워크플로는 여전히 동기 generateContent 입니다. backend, 내부 도구, 채팅형 product UI 어디든 이 답은 크게 바뀌지 않습니다.
이유는 단순히 속도가 아닙니다. 반복의 질입니다.
좋은 Gemini 이미지 작업은 보통 다음과 같은 짧은 루프로 좋아집니다.
- 명확한 prompt를 보낸다
- 첫 이미지를 본다
- 한 가지 지점만 수정한다
- 다음 턴을 보낸다
특히 editing에서는 이것이 더 중요합니다. 현재 image generation docs가 Gemini 이미지 작업을 대화형, multi-turn으로 설명하는 이유도 같습니다. 두 번째 지시는 첫 번째 이미지가 무엇을 잘했고 무엇을 틀렸는지에 따라 달라지기 때문입니다. Batch에서는 그 피드백이 너무 늦게 옵니다.
새 워크플로에서 첫 요청은 오히려 지루한 편이 낫습니다.
javascriptimport { GoogleGenAI } from "@google/genai"; import * as fs from "node:fs"; const ai = new GoogleGenAI({ apiKey: process.env.GEMINI_API_KEY }); const response = await ai.models.generateContent({ model: "gemini-3.1-flash-image-preview", contents: "Create a clean 16:9 product hero image of a matte black coffee grinder on a soft gray background with premium ecommerce lighting.", config: { responseModalities: ["IMAGE"], imageConfig: { aspectRatio: "16:9", imageSize: "2K" } } }); for (const part of response.candidates[0].content.parts) { if (part.inlineData) { fs.writeFileSync("coffee-grinder.png", Buffer.from(part.inlineData.data, "base64")); } }
첫 호출의 목적은 멋진 결과를 뽑아내는 것이 아니라, 모델 지정, 이미지 크기, response handling이 기대대로 동작하는지 확인하는 것입니다. 이 baseline이 안정된 후에야 editing과 refinement로 가는 편이 낫습니다.
동기 경로에서 특히 효과적인 습관은 두 가지입니다.
- 키워드만 던지지 말고 장면을 설명하기
- 편집에서는 바뀌어도 되는 부분과 유지해야 하는 부분을 함께 적기
Google의 오래된 prompt guide도 이 지점에서는 여전히 유효합니다. Gemini는 무엇을 바꿀지뿐 아니라 무엇을 지켜야 하는지도 알려 주면 훨씬 안정적으로 반응합니다. 그래서 interactive한 이미지 작업은 먼저 동기 경로에서 시작하는 편이 합리적입니다.
AI Studio에서 먼저 시험하는 것은 괜찮습니다. 다만 그것을 production contract와 혼동하면 안 됩니다. Google의 2026년 2월 26일 Nano Banana 2 개발자 글에는 이 모델을 AI Studio에서 쓰려면 paid API key가 필요하다고 적혀 있습니다. AI Studio는 학습 surface이지 최종 워크플로 정의 자체는 아닙니다.
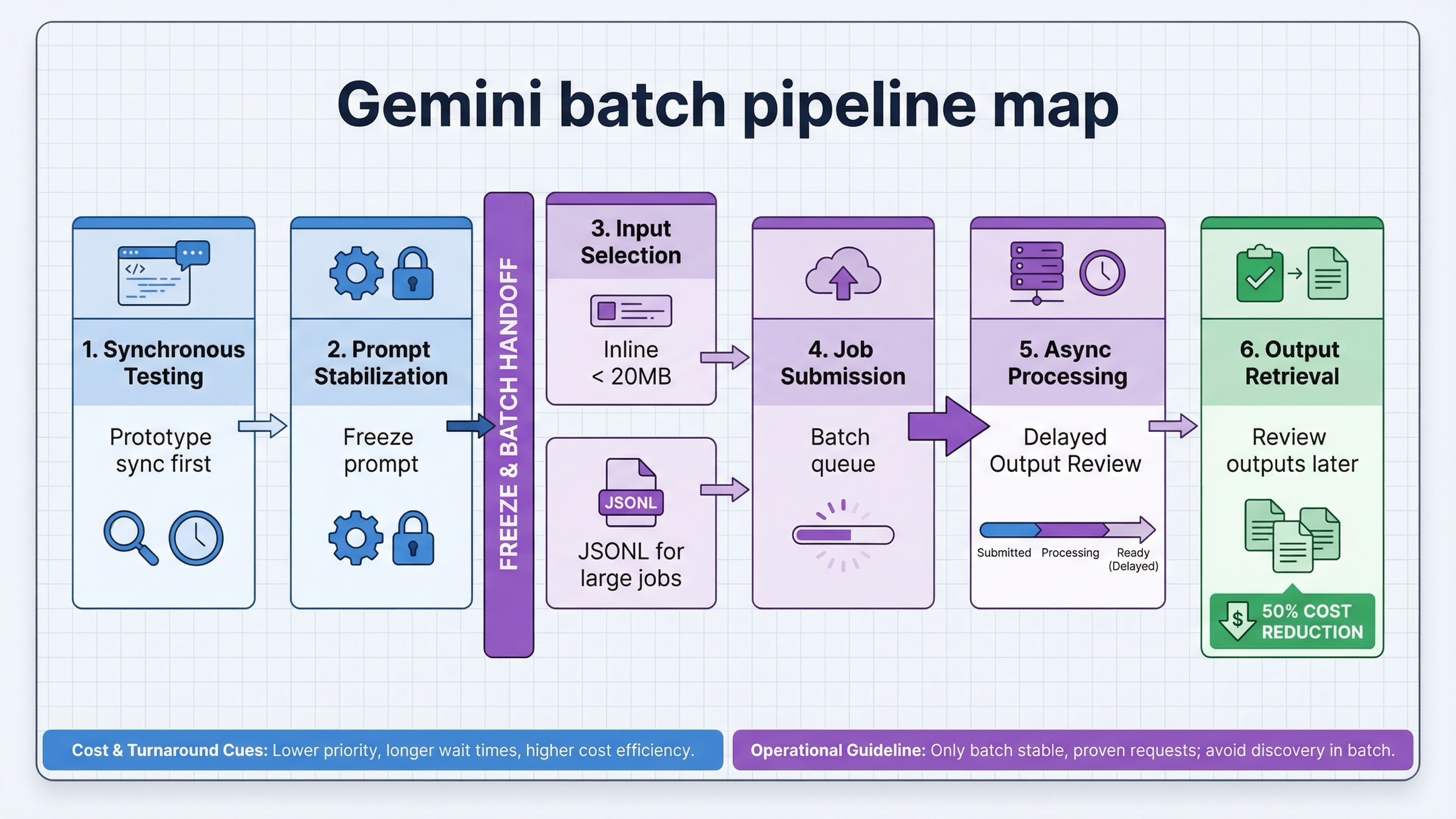
큐 처리와 야간 생성에 가장 좋은 Batch 워크플로
Batch API가 강한 시점은 작업이 진짜로 크고, 반복적이며, 급하지 않을 때입니다. 실무에서는 보통 아래 셋 중 하나와 연결됩니다.
- 총비용을 낮추고 싶다
- 일정한 처리량으로 큐를 굴리고 싶다
- 요청 접수와 결과 전달을 분리하고 싶다
Google 문서에 따르면 작은 작업은 inline request, 큰 작업은 JSONL 파일 입력이 적합합니다. 이미지 생성에서는 특히 파일 기반 경로가 장기적으로 더 다루기 쉽습니다. 재실행, 감사, 교체가 편하기 때문입니다.
좋은 batch workflow의 모양은 대체로 이렇습니다.
- 먼저 동기 경로에서 prompt와 파라미터를 확정한다
- request format을 고정한다
- jobs를 JSONL이나 작은 inline group으로 직렬화한다
- 기다려도 품질이 더 좋아지지 않는 시점에 batch로 보낸다
- 출력 수집과 retry 정책은 나중에 별도로 처리한다
여기서 흔한 실수는, 싸다는 이유로 batch 안에서 prompt discovery를 시작하는 것입니다. 장당 비용은 낮아져도 전체 학습 속도는 느려집니다. prompt discovery는 interactive 작업이고, batch는 안정된 요청의 반복 실행용입니다.
가격 차이는 요청이 안정되면 꽤 크게 느껴집니다. 2026년 3월 23일 기준으로 gemini-3.1-flash-image-preview 로 10,000 장의 1K 이미지를 만들면 대략 $670 이 표준 비용, $340 정도가 batch 비용입니다. gemini-3-pro-image-preview 라면 같은 볼륨이 약 $1,340 과 $670 수준입니다. 그래서 승인된 템플릿의 대량 생성, localization run, scheduled asset generation에서는 batch의 의미가 커집니다.
또한 Batch API는 단순 할인 기능이 아니라 별도의 운영 surface입니다. rate limits 페이지에는 100 concurrent batch requests, 2GB input file limit, 20GB file storage, 그리고 모델별 enqueued tokens 관리가 적혀 있습니다. 즉, 동기 트래픽은 멀쩡해도 batch 쪽만 다른 압력에 걸릴 수 있습니다.
request의 형태도 중요합니다. 공식 문서에서는 전체 payload가 20MB 미만이면 inline, 그보다 큰 작업은 업로드된 JSONL 파일을 권장합니다. 실제 운영에서는 후자가 더 안정적인 경우가 많습니다.
json{"key":"shoe-0001","request":{"contents":[{"parts":[{"text":"Create a clean white-background ecommerce image of a running shoe in side profile."}]}],"generation_config":{"response_modalities":["IMAGE"]}}} {"key":"shoe-0002","request":{"contents":[{"parts":[{"text":"Create a clean white-background ecommerce image of a black leather loafer in side profile."}]}],"generation_config":{"response_modalities":["IMAGE"]}}}
이 예시는 의도적으로 단순합니다. batch file의 목표는 예쁨이 아니라 재현성입니다. JSONL에 넣을 시점이면 prompt와 설정은 이미 동기 경로에서 충분히 검증되어 있어야 합니다.
실무적으로는 많은 팀에게 하이브리드 운영이 가장 강합니다.
- prompt 설계, 첫 승인, editing은 동기
generateContent - 안정된 반복 작업만 Batch API로 이동
- 24시간 목표 처리 시간을 받아들일 수 있는 일만 batch에 배치
이렇게 나누면 사람의 판단이 필요한 부분과 값싸게 대량 반복할 수 있는 부분이 분리되어 전체 시스템이 더 건강해집니다.
워크플로가 아니라 모델을 바꿔야 답이 달라지는 경우
pricing table만 보면 모든 이야기가 Flash 대 batch처럼 보일 수 있습니다. 하지만 실제로는 그렇지 않습니다. 워크플로는 그대로 두고 모델만 바꿔야 하는 경우가 분명히 있습니다.
그때 gemini-3-pro-image-preview 가 의미를 가집니다.
Pro가 합리적이 되는 순간은, 실패 비용이 모델 차액보다 커질 때입니다. 대표적으로 이런 경우입니다.
- 실제 텍스트가 많이 들어가는 다이어그램과 인포그래픽
- 품질 민감도가 높은 광고나 상품 자산
- 실패가 비싼 고객 제출물
- 라벨과 레이아웃 정확성이 중요한 시각화
- 첫 결과의 완성도를 높이고 싶은 고가치 출력
여기서 중요한 점은 워크플로 답 자체는 그대로일 수 있다는 것입니다. 사람이 기다리면 Pro여도 동기, 급하지 않은 대량 출력이면 Pro여도 batch가 가능합니다. workflow choice와 model choice를 분리해 두는 편이 훨씬 명확합니다.
실무적으로는 네 가지 레인으로 정리할 수 있습니다.
- Flash + 동기: 대부분의 interactive 이미지 작업
- Flash + batch: 대량이면서 비용 민감한 안정 작업
- Pro + 동기: 고품질이 필요한 상호작용형 작업
- Pro + batch: 고가치지만 급하지 않은 대량 출력
즉, 먼저 워크플로를 결정하고, 그 다음에 실패 비용으로 모델을 올릴지 판단하는 편이 맞습니다.
잘못된 워크플로를 선택했는지 확인하는 법
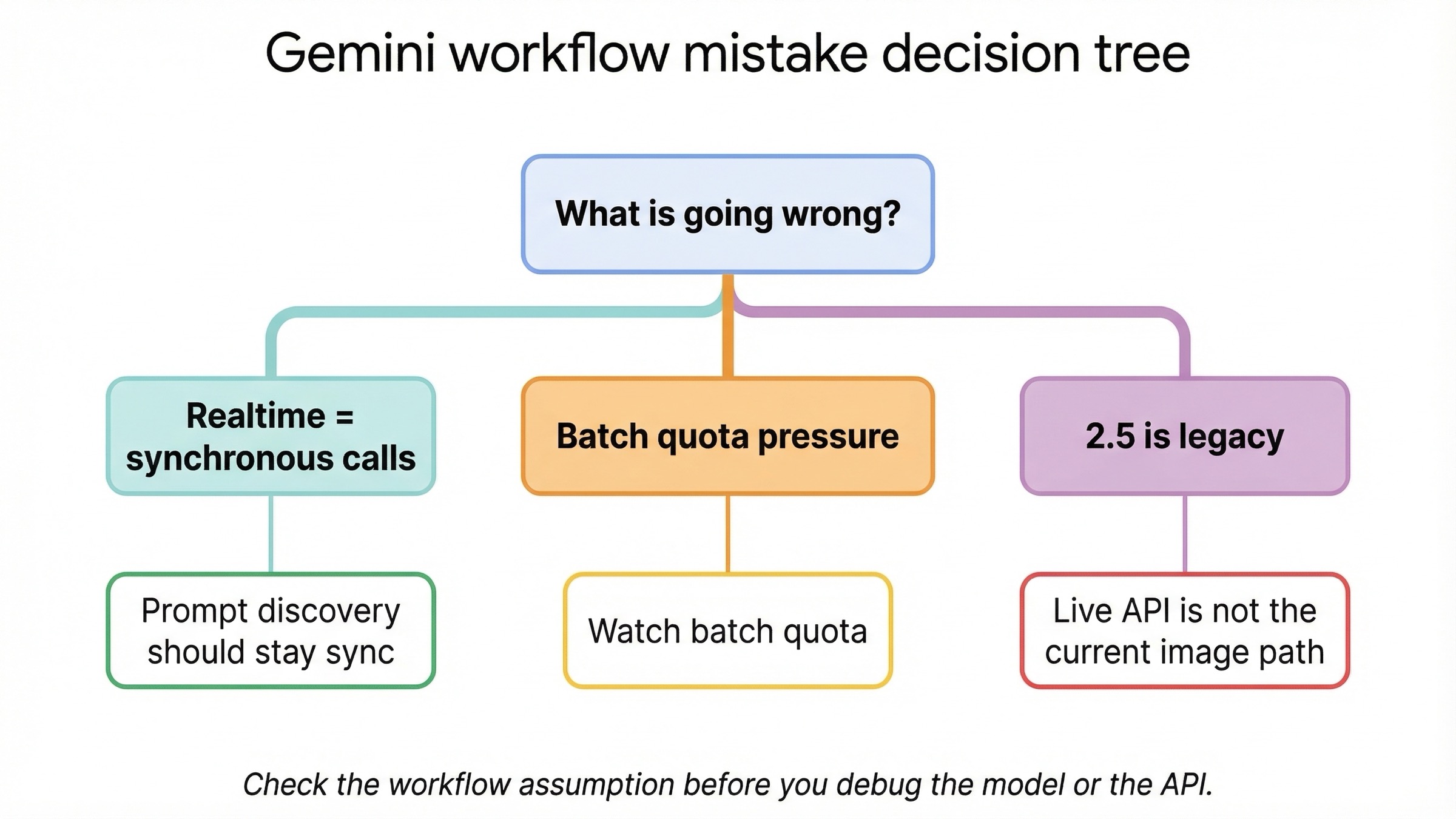
이 주제의 문제 대부분은 API 자체의 오류보다 워크플로 선택 오류에서 시작합니다.
실시간이라는 말을 너무 넓게 쓰고 있다. 현재 Gemini 이미지 모델에서 실시간은 동기 request-response를 뜻합니다. Live API 이미지 출력이 아닙니다. 이 구분 없이 시작하면 아키텍처가 처음부터 빗나갑니다.
prompt discovery 단계에서 batch로 가고 있다. 할인은 분명하지만, batch는 프롬프트를 배우는 장소가 아닙니다. 먼저 동기 경로에서 prompt를 잡고, 그 뒤에 반복 실행으로 옮겨야 합니다.
워크플로 질문과 lifecycle 질문을 섞고 있다. gemini-2.5-flash-image 는 싸지만 2026년 10월 2일 종료 예정입니다. 이를 선택한다면 새 기본값이 아니라, 의식적인 legacy 절약 전략으로 봐야 합니다.
일반 쿼터만 보고 batch 고유 압력을 놓치고 있다. batch는 enqueued-token pressure를 별도로 가집니다. 모니터링도 batch 전용 시각이 필요합니다.
AI Studio를 제품 전체의 답으로 보고 있다. AI Studio는 테스트와 실험에는 좋지만, 실제 앱은 API contract, model capability, pricing 위에서 돌아갑니다. AI Studio에서 잘 된다고 워크플로 선택이 자동으로 정답이 되는 것은 아닙니다.
워크플로를 바꾸면 품질 문제가 해결된다고 생각한다. 실제로는 batch가 아니라 Pro 모델이 필요한 경우도 많습니다. 특히 텍스트가 많고 레이아웃이 중요한 작업에서는 그렇습니다.
legacy 라인 대체 판단을 더 보고 싶다면 다음으로는 Gemini 2.5 Flash Image 대체 가이드가 잘 이어집니다.
결론
Gemini 이미지 생성에서 batch vs realtime이라는 질문에 대한 가장 실무적인 답은 API 비교 자체가 아니라 라우팅 규칙입니다.
사람이 결과를 기다리면 동기 generateContent 에 남습니다. 작업이 크고, 급하지 않고, 빠른 반복이 끝난 상태라면 Batch API로 보냅니다. 대부분의 새 구현은 gemini-3.1-flash-image-preview 에서 시작합니다. 텍스트, 레이아웃, 실패 비용이 높아지면 gemini-3-pro-image-preview 로 올립니다. gemini-2.5-flash-image 는 2026년 10월 2일 종료를 감안한 legacy 절약 선택으로만 취급합니다.
순서는 이것이면 충분합니다. 먼저 latency tolerance로 워크플로를 고르고, 그다음 실패 비용으로 모델을 고릅니다.