2026년 3월 19일 기준으로, 최고 성능만 보면 Gemini 3.1 Pro가 앞서지만 운영 기본값으로는 여전히 Gemini 2.5 Pro가 더 맞는 팀이 많습니다. 이 글은 API 운영 의사결정에 필요한 공식 정보만 기준으로 범위를 한정합니다. 그리고 "전면 교체"가 아니라 "기본 라인과 승격 라인 분리"라는 실제 선택지를 끝까지 판단할 수 있게 설계했습니다.
핵심 질문은 단순한 우열 비교가 아닙니다. "Gemini 2.5 Pro를 전부 3.1 Pro로 바꿀 것인가, 아니면 2.5 Pro를 기본으로 유지하고 고난도 요청만 3.1 Pro로 올릴 것인가"가 진짜 질문입니다. 현재 비교 글 다수는 벤치마크 캡처나 스펙 나열에서 멈추지만, 이 글은 반대로 의사결정부터 제시하고 그 결론을 뒷받침하는 공식 근거를 연결합니다.
핵심 요약
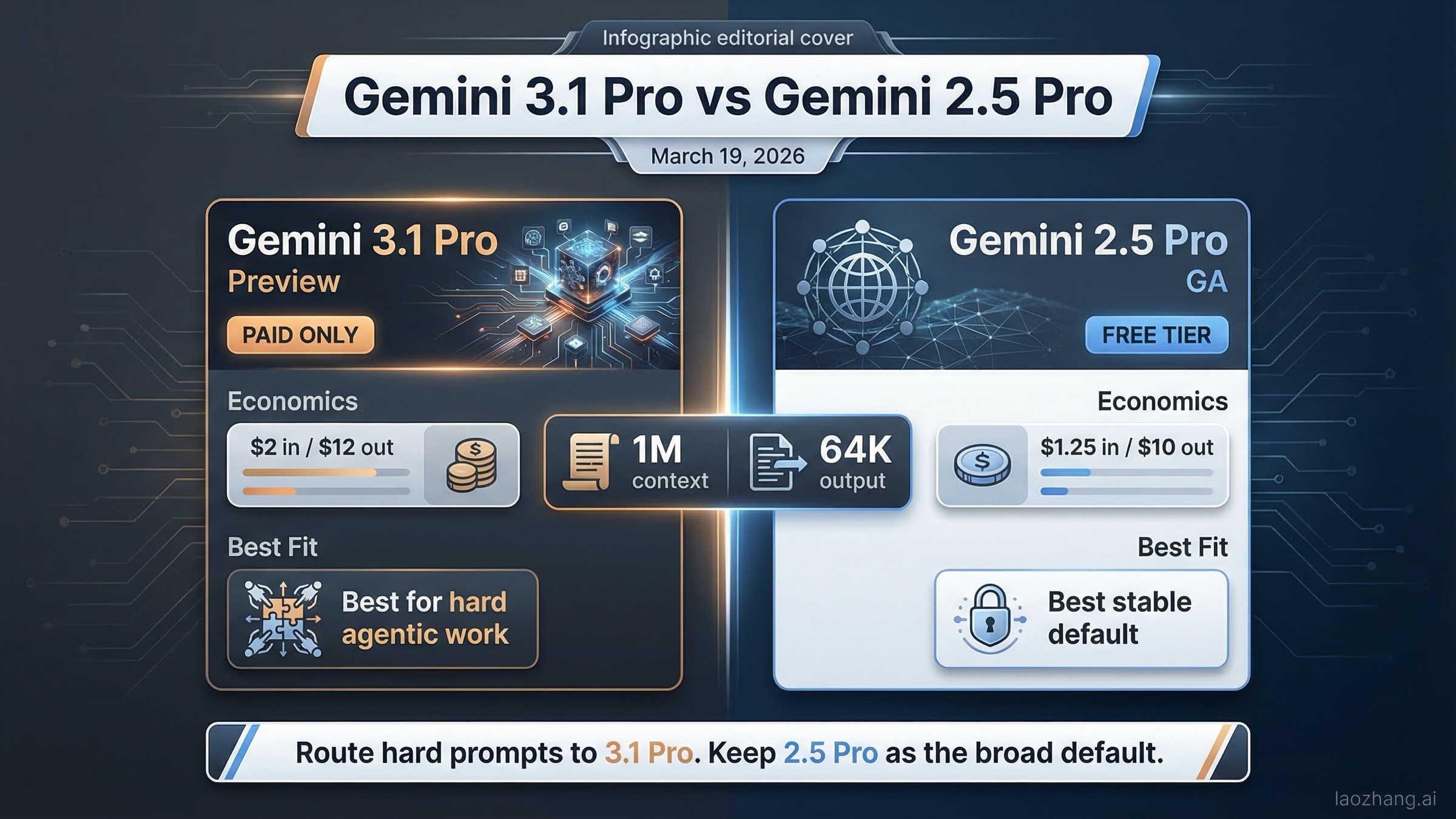
지금 바로 결론만 필요하다면 이렇게 보시면 됩니다. 고난도 추론, 에이전트 코딩, 툴 호출이 많은 작업에서 상단 성능이 우선이면 Gemini 3.1 Pro를 쓰고, 운영 안정성·비용·무료 티어 실험 경로가 중요하면 Gemini 2.5 Pro를 기본값으로 두는 것이 맞습니다.
2026년 3월 19일 기준 공식 비교를 표로 정리하면 다음과 같습니다.
| 항목 | Gemini 3.1 Pro | Gemini 2.5 Pro | 해석 |
|---|---|---|---|
| 현재 상태 | Preview | Generally available | 3.1은 더 최신이지만 운영 기본값으로 즉시 고정하기엔 리스크가 더 큼 |
| 모델 ID | gemini-3.1-pro-preview | gemini-2.5-pro | 마이그레이션은 자동 교체가 아니라 명시적 라우팅이 필요 |
| 무료 티어 | 없음 | 있음 | 2.5 Pro가 테스트·스테이징·저위험 실험에 유리 |
| 표준 입력 단가 | 200k 이하 기준 1M 토큰당 $2.00 | 200k 이하 기준 1M 토큰당 $1.25 | 3.1 입력 단가가 약 60% 높음 |
| 표준 출력 단가 | 200k 이하 기준 1M 토큰당 $12.00 | 200k 이하 기준 1M 토큰당 $10.00 | 3.1 출력 단가가 약 20% 높음 |
| 장문 프롬프트 단가 | 200k 초과 시 입력 $4.00 / 출력 $18.00 | 200k 초과 시 입력 $2.50 / 출력 $15.00 | 긴 프롬프트에서도 비용 격차 유지 |
| 컨텍스트 윈도우 | 1M tokens | 1M tokens | 문맥 길이 자체는 3.1이 우위가 아님 |
| 최대 출력 | 64K tokens | 64K tokens | 출력 상한도 동일 |
| 권장 용도 | 고난도 추론·에이전트 작업·프런티어 성능 | 안정 운영 기본 라인·비용 민감 트래픽·무료 티어 실험 | 3.1은 프리미엄 레인, 2.5는 기본 레인으로 분리 운용 권장 |
위 표는 Gemini Developer API 가격 페이지, Gemini API 모델 페이지, Vertex AI 모델 카탈로그, Gemini 3.1 Pro 모델 카드, Gemini 2.5 Pro 모델 카드 PDF를 기준으로 구성했습니다. 핵심은 "한도 확장"이 아니라 "품질·비용·성숙도"의 교환이라는 점입니다.
실무 결론은 간단합니다.
- 추론 난도가 높아 리뷰 비용이 크게 줄어드는 구간만 Gemini 3.1 Pro로 올립니다.
- 일상 코딩 보조와 넓은 운영 트래픽은 Gemini 2.5 Pro를 기본값으로 둡니다.
- 라우팅이 가능하다면 단일 모델 고정 대신 2.5 기본 + 3.1 승격 구조를 택합니다.
많은 팀이 헷갈리는 이유도 여기 있습니다. "새 모델 = 전면 교체"로 보이지만, 공식 가격과 상태 정보는 그렇게 말하지 않습니다. 3.1 Pro는 범용 대체재보다 프리미엄 레인에 가깝습니다.
2.5 Pro에서 3.1 Pro로 바뀐 핵심은 무엇인가
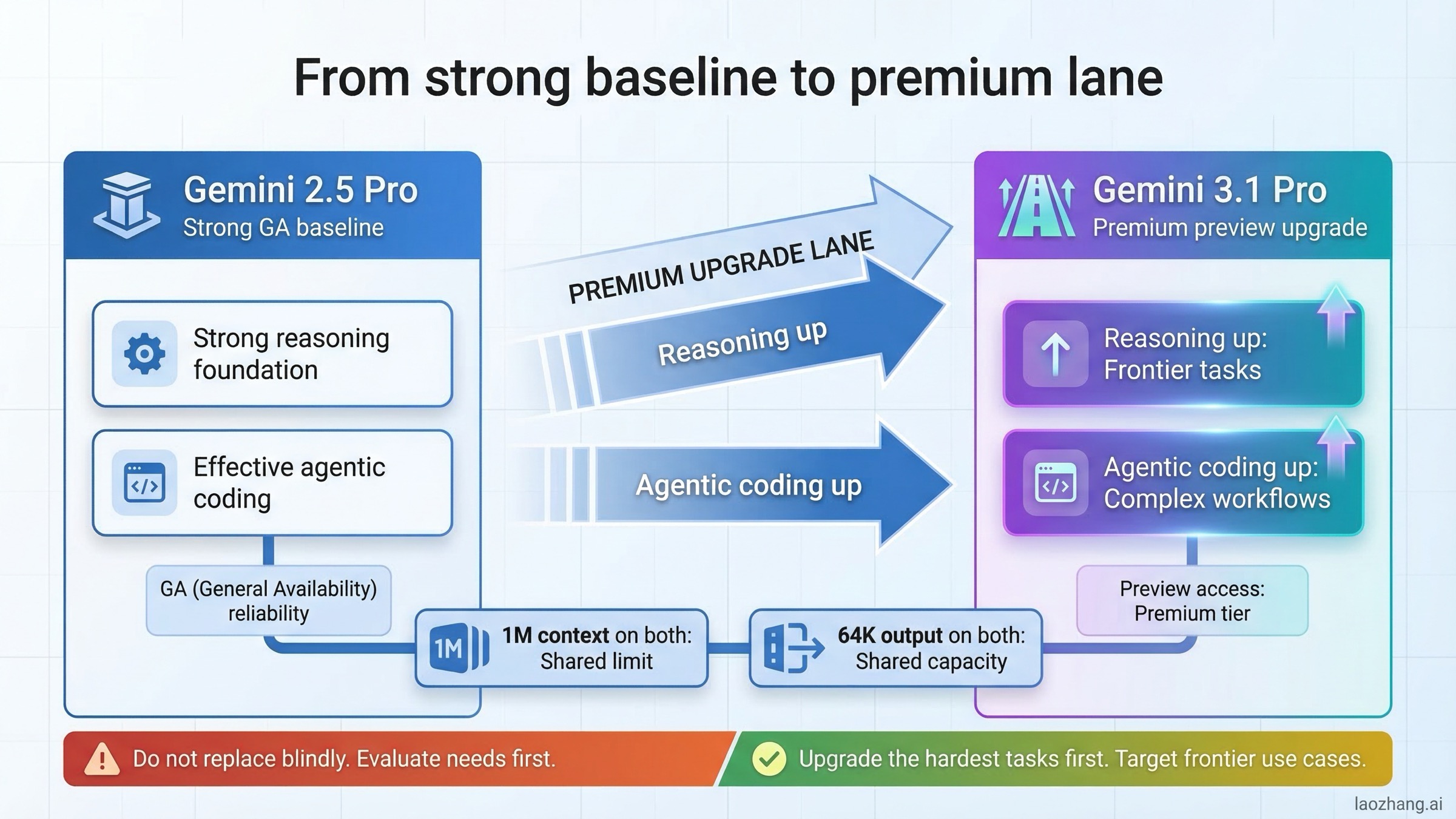
이 비교에서 가장 흔한 오해는 "3.1로 가면 컨텍스트가 커지고 출력도 늘어난다"는 가정입니다. 실제로 가장 큰 변화는 한도 숫자가 아니라 Google의 제품 포지셔닝입니다.
Vertex AI 모델 페이지를 보면 Gemini 3.1 Pro는 Preview 구간에서 최신 추론 중심 모델로 설명되고, Gemini 2.5 Pro는 GA 구간의 고성능 표준 모델로 정리됩니다. 즉, Google이 스스로도 3.1을 프런티어 레인, 2.5를 안정 기본 레인으로 구분하고 있다는 뜻입니다.
Gemini 3.1 Pro 모델 카드는 이 메시지를 더 강화합니다. 2026년 2월 19일 공개 시점 기준으로 3.1 Pro를 복잡한 작업에 가장 진보한 모델로 제시했고, 1M 컨텍스트·64K 출력과 함께 Gemini 앱, Vertex AI, AI Studio, Gemini API, Google Antigravity, NotebookLM 배포 채널을 명시합니다.
반면 Gemini 2.5 Pro 모델 카드는 2025년 6월 27일 업데이트에서 2.5 Pro의 GA 전환을 명확히 보여줍니다. 동시에 1M 컨텍스트·64K 출력이 동일하게 유지되므로, 3.1로 이동한다고 해서 대부분 팀이 "더 넓은 박스"를 얻는 것은 아닙니다. 더 비싼 비용으로 더 영리한 모델을 사는 구조에 가깝습니다.
3.1 출시 직전의 2.5 포지션을 보면 이 차이는 더 선명해집니다. Google의 2025년 5월 6일 게시물 "Build rich, interactive web apps with an updated Gemini 2.5 Pro"는 웹앱 생성과 코딩 성능 개선, WebDev Arena 지표를 강조했습니다. 그래서 실제 사용자 입장에서는 3.1이 약한 전작을 대체한 것이 아니라, 이미 현업에서 검증된 2.5를 넘어서는지 검증하는 구도입니다.
이 글 전체를 이해하는 프레임은 아래 세 줄이면 충분합니다.
- Gemini 2.5 Pro는 "구형이라 약한 모델"이 아닙니다.
- Gemini 3.1 Pro는 "동일 기능의 무료 업그레이드"가 아닙니다.
- 핵심 비교축은 프리미엄 프리뷰 vs 안정 GA입니다.
2026년 3월 19일 기준 가격·무료 티어·모델 상태

가격 구간에서 의사결정이 가장 현실적으로 갈립니다. 벤치마크 서사만 보면 교체가 쉬워 보이지만, Gemini Developer API 가격 페이지를 보면 조건이 분명합니다.
Gemini 3.1 Pro Preview:
- 무료 티어 없음
- 200k 이하 프롬프트: 입력 1M 토큰당
\$2.00, 출력 1M 토큰당\$12.00 - 200k 초과 프롬프트: 입력
\$4.00, 출력\$18.00 - 배치 요금은 표준 토큰 요금 대비 50% 수준
Gemini 2.5 Pro:
- 무료 티어 있음
- 200k 이하 프롬프트: 입력 1M 토큰당
\$1.25, 출력 1M 토큰당\$10.00 - 200k 초과 프롬프트: 입력
\$2.50, 출력\$15.00 - 배치 요금은 표준 토큰 요금 대비 50% 수준
표준 유료 구간만 봐도 차이는 분명합니다.
- 입력 단가: 3.1 Pro가 약 60% 높음
- 출력 단가: 3.1 Pro가 약 20% 높음
- 무료 티어: 3.1 Pro는 실험용 온램프 자체가 없음
실운영에서 이 차이는 "치명적"이라기보다는 "무시 불가"에 가깝습니다. 고난도 구간에서 재시도·수정 비용을 크게 줄여주면 3.1 프리미엄은 정당화됩니다. 반대로 일상 트래픽에서는 단가 상승과 무료 티어 부재가 빠르게 체감됩니다.
예를 들어 월간 입력 5,000만 토큰, 출력 1,000만 토큰(대부분 200k 이하 프롬프트) 파이프라인이라면:
- Gemini 2.5 Pro: 입력
\$62.50+ 출력\$100= 총\$162.50 - Gemini 3.1 Pro: 입력
\$100+ 출력\$120= 총\$220
대략 35% 비용 증가입니다. 그리고 여기에 무료 티어 실험 슬롯 상실까지 더해지면, 운영 정책 차이는 단순한 토큰 가격표 이상으로 커집니다.
모델 상태도 동일하게 중요합니다. Gemini API 모델 페이지, Vertex AI 카탈로그 모두 3.1은 Preview, 2.5는 GA로 유지됩니다. Preview가 곧 "사용 불가"를 뜻하진 않지만, 기본 라인으로 깔기 전에 변경 리스크를 더 엄격히 평가해야 한다는 신호입니다.
그래서 실무 질문은 "3.1을 감당할 수 있나?"보다 "2.5가 이미 커버하는 구간을 버리고도 3.1의 추가 가치를 계속 회수할 수 있나?"가 더 정확합니다.
API 팀과 Gemini 앱 사용자는 같은 기준으로 고르지 않는다
이 키워드가 헷갈리는 이유는 서로 다른 의사결정자를 같은 검색어 아래에 묶기 때문입니다. 어떤 사용자는 프로덕션 API 모델을 고르고, 어떤 사용자는 Gemini 앱에서 어떤 모델이 보이는지 확인합니다. 비슷해 보이지만 의사결정 기준은 다릅니다.
Google의 실제 SERP 구성도 이 분리를 반영합니다. API 사용자에게는 가격표·모델 카탈로그·모델 카드가 핵심 소스이고, 앱 사용자에게는 Gemini Apps limits and upgrades 같은 도움말 문서가 자주 노출됩니다. 즉, 앱 쪽은 "내 요금제로 이 모델이 보이나?"가 우선이고, API 쪽은 "이 모델을 기본 라인으로 써도 되나?"가 우선입니다.
API 팀의 체크포인트:
- 고난도 작업 품질
- 토큰 단가
- 무료 티어 가용성
- 모델 성숙도(Preview vs GA)
- 캐시·배치·그라운딩을 포함한 전체 툴 비용
Gemini 앱 사용자의 체크포인트:
- 모델 노출 여부
- 구독 플랜 조건
- 사용 한도
- 체감 품질
API 운영 관점에서는 추가 비용의 형태도 단순하지 않습니다. 현재 가격 페이지 기준으로 3.1 Pro Preview는 본문 토큰뿐 아니라 주변 기능 단가도 더 높은 경우가 많습니다.
200k 이하 프롬프트 구간 예시:
- 3.1 Pro Preview 컨텍스트 캐시: 1M 토큰당
\$0.20 - 2.5 Pro 컨텍스트 캐시: 1M 토큰당
\$0.125 - 캐시 저장: 두 모델 모두
\$4.50 / 1,000,000 tokens per hour
200k 초과 시:
- 3.1 Pro Preview 캐시:
\$0.40 - 2.5 Pro 캐시:
\$0.25
배치 단가도 같은 방향입니다.
- 3.1 Pro Preview 배치: 입력
\$1.00, 출력\$6.00 - 2.5 Pro 배치: 입력
\$0.625, 출력\$5.00
즉 배치 할인 이후에도 3.1이 더 비싼 레인이라는 사실은 유지됩니다.
그라운딩 과금은 단위 표현이 동일하지 않아 단순 비교가 위험하지만, 운영에서 중요한 포인트는 분명합니다. Search/Maps를 많이 쓰는 구조에서는 모델 선택이 동시에 툴 과금 정책 선택이 됩니다.
무료 티어도 단순 "공짜" 문제가 아닙니다. 실무에서는 아래 용도로 무료 레인이 유용합니다.
- 스테이징 프롬프트 점검
- 템플릿 A/B 테스트
- 회귀 테스트
- 라우팅 정책 스모크 테스트
이 레인을 2.5 Pro는 제공하고 3.1 Pro는 제공하지 않습니다. 그래서 성숙한 팀은 보통 "전면 교체"보다 "2.5 검증 레인 + 3.1 프리미엄 레인"으로 시작합니다.
앱 사용자 관점과 API 운영 관점을 분리하면 판단이 훨씬 단순해집니다.
- 앱 중심: 모델 노출 여부와 체감 품질 위주
- API 중심: 기본 라인/승격 라인 분리 + 비용 구조 전체
이 글이 API 의사결정에 초점을 맞추는 이유도 여기 있습니다.
벤치마크 해석: 3.1이 앞서는 구간과 주의해야 할 구간
모델 비교 글에서 벤치마크는 종종 과도하게 단정적으로 소비됩니다. 특히 이 주제에서는 주의가 더 필요합니다. 공식 Gemini 3.1 Pro 모델 카드와 Gemini 2.5 Pro 모델 카드는 동일 날짜·동일 하네스의 완전한 1:1 표를 제공하지 않기 때문입니다.
공식 카드 기준 방향성은 아래와 같습니다.
| 벤치마크 | Gemini 3.1 Pro 공식 수치 | Gemini 2.5 Pro 공식 수치 | 안전한 해석 |
|---|---|---|---|
| Humanity's Last Exam | 44.4% | 21.6% | 프런티어 추론 성능에서 3.1 우위 근거가 강함 |
| GPQA Diamond | 94.3% | 86.4% | 과학·전문 추론에서 3.1 우세 신호 |
| SWE-Bench Verified | 80.6% | 59.6% | 방향성은 3.1 우위, 단 카드 간 완전 동일 조건 비교는 아님 |
| Terminal-Bench 2.0 | 68.5% | 2.5 GA 카드에 미기재 | 에이전트형 코딩 강화 포지셔닝과 일치 |
| APEX-Agents | 33.5% | 2.5 GA 카드에 미기재 | 장기 에이전트 성능 강화 신호 |
| Context / output | 1M / 64K | 1M / 64K | 한도 지표에서는 우위 없음 |
따라서 가장 안전한 결론은 다음입니다. 3.1 Pro는 Google의 프런티어 추론·에이전트 서사를 분명히 끌어올렸지만, 모든 줄을 실험실급 완전 비교로 간주하면 안 됩니다.
그럼에도 운영 관점에서 패턴은 명확합니다. 3.1 Pro는 아래 작업에서 가치가 큽니다.
- 도구 호출이 길고 복합적인 작업
- 추론 품질 차이가 결과를 직접 바꾸는 작업
- 단순 자동완성보다 에이전트 실행 성격이 강한 작업
- 첫 응답 실패 시 인력 검수 비용이 큰 작업
2.5 Pro는 아래에서 여전히 강합니다.
- 고품질이 필요하지만 프런티어 난도는 아닌 작업
- 반복 빈도가 높고 규모가 큰 작업
- 비용 민감 트래픽
- 넓은 운영 기본 라인
그래서 벤치마크는 "전면 교체 근거"가 아니라 "라우팅 기준 강화"로 쓰는 편이 맞습니다.
지연 시간·롱컨텍스트·운영 안정성
공식 문서는 성능 서사를 명확히 보여주지만, 실제 운영 질문까지 해결해주진 않습니다. "새 모델이 내 트래픽에서도 안정적으로 동작하나?"는 별도로 검증해야 합니다.
이 지점에서 SERP에는 공식 문서 외에 사용자 마찰 신호도 함께 보입니다. 예를 들어 Google AI Developers Forum의 "Gemini 3 significantly worse thant 2.5 Pro at long context. Temperature likely to blame" 같은 스레드는 공식 스펙 근거는 아니지만, 실제 사용자가 무엇을 불안해하는지 보여줍니다.
핵심은 "동일 한도"가 "동일 경험"을 보장하지 않는다는 점입니다. 두 모델 모두 1M 컨텍스트·64K 출력을 제공해도 운영에서는 아래 질문이 남습니다.
- 내 프롬프트 분포에서 어느 모델이 더 예측 가능한가
- 어느 모델이 재시도/수정 비용을 덜 유발하는가
- 어느 모델이 장애 대응 로직을 덜 복잡하게 만드는가
- 어느 모델이 단가 프리미엄을 실제 품질 개선으로 상쇄하는가
많은 팀에서 2.5 Pro가 여전히 안정적인 이유는 단순합니다. GA 상태, 더 낮은 단가, 무료 티어, 축적된 운영 경험이 동시에 작동하기 때문입니다.
여기서는 능력 리스크와 제품 리스크를 분리해서 보는 게 유효합니다.
- 능력 측면: 고난도 구간은 3.1 Pro가 유리할 가능성이 큼
- 제품 측면: 넓은 기본 라인은 2.5 Pro가 안전한 경우가 많음
그래서 실제로는 전면 교체보다 점진 승격 라우팅이 더 안전합니다. 2.5를 기본 라인으로 유지하고, 진짜로 어려운 요청만 3.1으로 올린 뒤 성과가 누적될 때 확장합니다.
Google 생태계 의존도가 높은 팀이라면 운영 이슈도 함께 확인하는 것이 좋습니다. 관련 참고:
- Gemini 3.1 Pro output limit guide (영문)
- Gemini 3.1 Pro timeout guide (영문)
- Gemini API error troubleshooting guide
실제 운영에서는 이런 주변 이슈가 모델 선택의 성패를 좌우합니다.
코딩·에이전트·리서치·비용 통제별 추천
전체 우승 모델을 찾기보다 워크로드별 기본값을 정하는 편이 실무에 맞습니다.
| 워크로드 | 더 나은 기본 선택 | 이유 |
|---|---|---|
| 일상 코딩 보조 | Gemini 2.5 Pro | 단가가 낮고 GA라 운영 마찰이 적음 |
| 고난도 에이전트 코딩 | Gemini 3.1 Pro | 공식 포지셔닝과 벤치마크 방향성이 에이전트 성능 강화와 일치 |
| 리서치/고난도 분석 | Gemini 3.1 Pro | 프런티어 추론 지표 개선이 뚜렷 |
| 대규모 롱컨텍스트 문서 작업 | 2.5 Pro 우선, 3.1 Pro 선택 승격 | 한도는 동일하고 2.5가 비용·안정성에서 유리 |
| 무료 티어 기반 실험 | Gemini 2.5 Pro | 3.1에는 무료 티어가 없음 |
| 대규모 운영 트래픽 | Gemini 2.5 Pro | GA + 낮은 단가 조합이 기본 라인에 유리 |
| 프리미엄 폴백 레인 | Gemini 3.1 Pro | 전 요청이 아니라 일부 고난도 구간에서 가치가 큼 |
소규모 팀이라면 2.5 기본 + 3.1 승격 정책만으로도 충분합니다.
대규모 팀이라면 라우팅 계층이 이미 있다면 3.1을 고난도 전용 레인으로 붙이는 것이 자연스럽습니다.
리서치 중심 팀이라면 3.1 가중치를 높게 둘 수 있지만, 단가와 안정성을 무시하면 안 됩니다.
비용 민감 서비스라면 2.5 기본 전략이 아직도 가장 강합니다.
이 비교는 결국 "모델 충성도"가 아니라 "트래픽 분류와 비용 구조" 문제이기도 합니다. 라우팅·폴백·과금 최적화가 핵심인 팀이라면 laozhang.ai 같은 멀티모델 게이트웨이 접근도 실무 옵션이 될 수 있습니다.
3.1 Pro를 기본값으로 승격하기 전에 반드시 벤치마크할 것
가장 흔한 실수는 3.1 Pro로 몇 개의 인상적인 프롬프트를 돌려본 뒤 곧바로 기본값을 바꾸는 것입니다. 이 주제는 가격·성숙도 트레이드오프가 크기 때문에, "호기심 테스트"가 아니라 "운영 테스트"로 접근해야 합니다.
먼저 업무를 가치 생성 단위로 버킷화합니다.
| 평가 버킷 | 예시 | 실제로 답해야 하는 질문 |
|---|---|---|
| 루틴 코딩/편집 | 소규모 리팩터링, 간단 테스트, 일반 버그 수정 | 공통 업무에서 3.1 프리미엄을 정당화할 만큼 차이가 나는가 |
| 고난도 에이전트 코딩 | 다단계 코드 수정, 툴 연쇄 호출, 긴 실행 체인 | 3.1이 1차 실패율을 줄여 검수 시간을 절감하는가 |
| 롱컨텍스트 분석 | 장문 문서, 긴 로그/트랜스크립트, 다파일 추론 | 프롬프트가 복잡해져도 3.1 우위가 유지되는가 |
| 그라운딩/툴 활용 | 검색 결합 응답, 외부 도구 오케스트레이션 | 툴 비용을 포함해도 3.1의 이득이 남는가 |
| 비용 민감 대량 트래픽 | 반복성 높은 대규모 요청 | 2.5 기본 라인을 바꿀 실익이 실제로 있는가 |
한 버킷만 보면 거의 항상 잘못된 결론이 나옵니다. 3.1이 고난도 버킷에서 크게 이겨도 대량 트래픽 버킷에서는 과투자일 수 있습니다.
둘째, 출력 품질만 보지 말고 승인된 결과 비용을 측정해야 합니다. 중요한 지표는 "어느 모델이 더 똑똑해 보였나"가 아니라 "재시도·수정·검수까지 포함했을 때 어떤 모델이 더 싸게 합격 결과를 냈나"입니다.
최소 추적 지표:
- 1차 응답 승인율
- 인력 수정 시간
- 재시도율
- p95 지연 시간
- 토큰 비용
- 캐시 비용(사용 시)
- 그라운딩 비용(사용 시)
- 폴백 비율
셋째, 비교 조건을 고정해야 합니다.
- 테스트 기간 동안 프롬프트 템플릿 고정
- 동일 툴셋 사용
- 가능한 범위에서 동일 추론/temperature 설정
- 장난감 데이터 대신 실제 트래픽 샘플 사용
- 쉬운 요청과 어려운 요청을 분리 평가
넷째, 정확도만이 아니라 운영 행동을 봐야 합니다. 1M/64K가 동일한 상황에서는 아래가 더 자주 차이를 만듭니다.
- 재시도 1회 추가가 얼마나 자주 발생하는지
- 긴 체인에서 툴 오케스트레이션 안정성이 유지되는지
- 롱컨텍스트 일관성이 유지되는지
- 후처리 가능한 출력 구조를 안정적으로 주는지
- 주간 변동성이 관리 가능한지
다섯째, 승격 기준은 결과를 보기 전에 정의해야 합니다. 예시 기준:
- 고난도 버킷에서 3.1이 2.5를 의미 있는 폭으로 상회
- 지연 시간 증가가 SLA 범위 내
- 승인 결과당 비용이 합의된 프리미엄 범위 내
- Preview 변동성이 다일/다주 테스트에서 허용 범위 내
- 대량 트래픽 버킷은 2.5 유지 또는 이동 근거 명확
이 기준을 통과한 구간만 승격하면 됩니다. 통과하지 못하면 3.1을 특수 레인으로 유지하는 것이 맞고, 그 역시 성공적인 결론입니다.
실무에서 잘 먹히는 운영 패턴은 다음입니다.
- 요청 난도를 low/medium/high로 분류
- low와 대부분 medium은
gemini-2.5-pro - high 또는 검수비용이 높은 요청은
gemini-3.1-pro-preview - 주간 모니터링 + 월간 승격 기준 재검토
한 줄 요약: 프리미엄 레인은 호기심이 아니라 수정비 예산을 기준으로 평가해야 합니다.
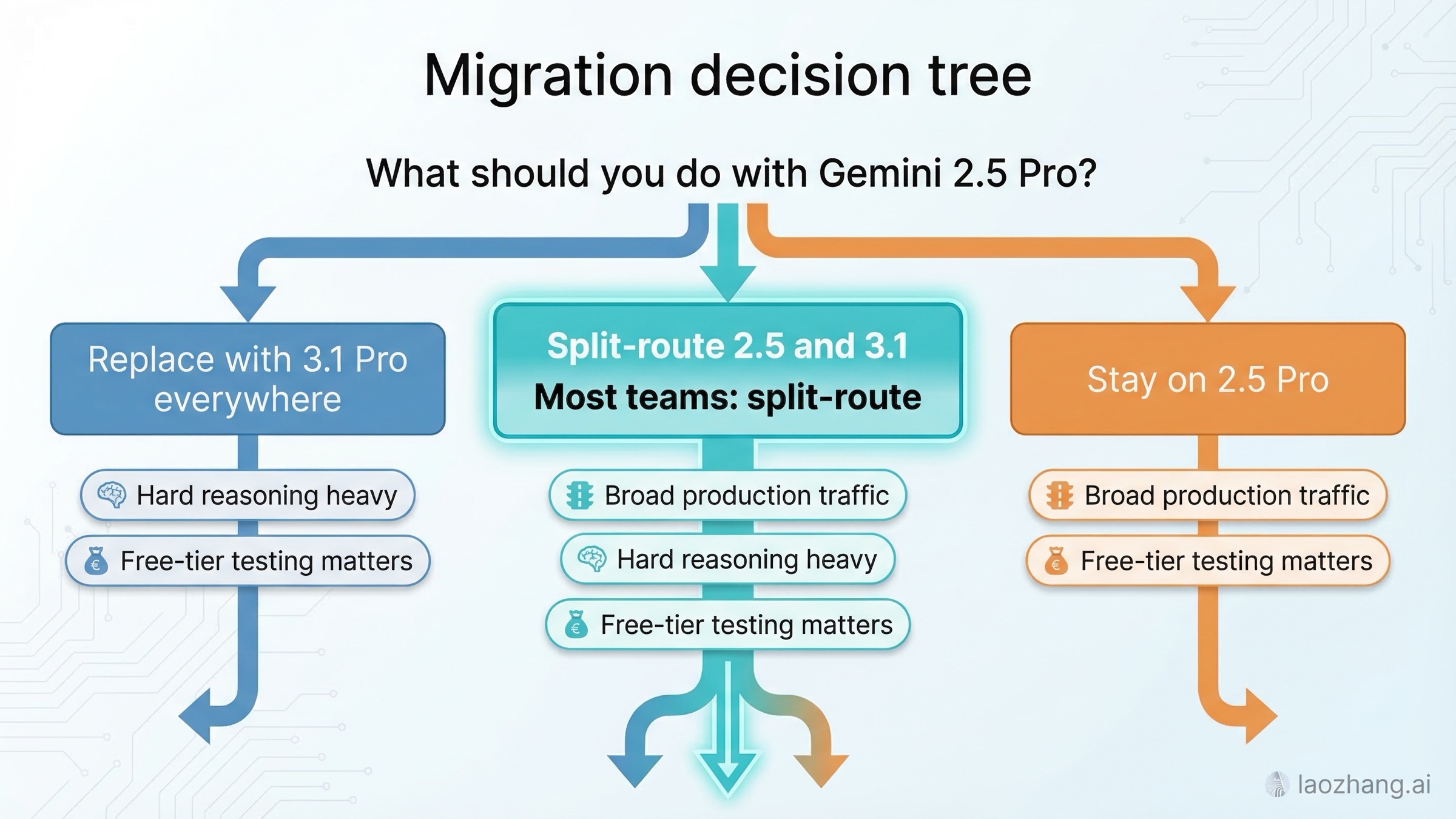
마이그레이션 전략: 전면 교체, 분할 라우팅, 현상 유지
대부분의 팀은 아래 세 가지 패턴 중 하나를 선택하면 됩니다.
패턴 1: Gemini 3.1 Pro 전면 교체
고난도 추론 비중이 매우 높고, Preview 모델을 기본값으로 운영할 준비가 된 팀에서만 의미가 있습니다. 품질·지연·비용 검증 없이 실행하면 실패 확률이 가장 높은 경로입니다.
패턴 2: 2.5/3.1 분할 라우팅(권장)
2.5 Pro를 기본 라인으로 유지하고, 아래 조건에서만 3.1 Pro로 승격합니다.
- 요청 중요도가 높고 검수 비용이 큰 경우
- 2.5의 1차 실패율이 처리량 병목을 만드는 경우
- 단발성 응답보다 에이전트형 다단계 작업인 경우
- 비용 절감보다 추론 품질이 더 중요한 경우
간단한 정책 예시는 아래처럼 구성할 수 있습니다.
tsfunction chooseGeminiModel(task: { requiresAgenticCoding: boolean; reasoningDifficulty: "low" | "medium" | "high"; costSensitive: boolean; needsFreeTierFallback: boolean; }) { if (task.needsFreeTierFallback || task.costSensitive) { return "gemini-2.5-pro"; } if (task.requiresAgenticCoding || task.reasoningDifficulty === "high") { return "gemini-3.1-pro-preview"; } return "gemini-2.5-pro"; }
패턴 3: 2.5 Pro 유지
이 전략은 소극적 선택이 아니라, 현재 품질이 충분하고 무료 티어 실험 슬롯이 중요하며 3.1 추가 성능이 비즈니스 성과로 연결되지 않을 때의 합리적 선택입니다.
권장 체크리스트:
- 인터넷 예제가 아니라 자사 프롬프트로 두 모델 비교
- 토큰 비용만이 아니라 출력 품질과 수정 시간 동시 측정
- 3.1이 운영 검증을 통과할 때까지 2.5 폴백 유지
- "최신 모델"이라는 이유만으로 전면 교체 금지
- 측정된 개선이 단가와 리스크를 상쇄하는 구간만 승격
핵심은 하나입니다. Gemini 3.1 Pro는 "증거 기반 승격" 대상이지, "레이블 기반 기본값"이 아닙니다.
FAQ
Gemini 3.1 Pro가 Gemini 2.5 Pro보다 무조건 좋나요?
고난도 추론·에이전트 작업에서는 3.1 Pro가 유리한 신호가 강합니다. 하지만 실무 전체 기준으로 보면 2.5 Pro는 더 낮은 단가, GA 상태, 무료 티어라는 강점이 있어 여전히 기본값으로 유효합니다.
Gemini 3.1 Pro로 바꾸면 컨텍스트나 출력 한도가 커지나요?
아니요. 2026년 3월 19일 기준 공식 문서에서 두 모델 모두 1M 컨텍스트와 64K 출력을 지원합니다. 차이는 한도가 아니라 품질·비용·모델 상태입니다.
Gemini 3.1 Pro가 더 비싼가요?
네. 공식 가격 페이지 기준으로 3.1 Pro는 200k 이하 구간에서 입력 \$2.00, 출력 \$12.00이고, 2.5 Pro는 입력 \$1.25, 출력 \$10.00입니다. 또한 2.5 Pro는 무료 티어가 남아 있습니다.
2.5 Pro 트래픽을 전부 3.1 Pro로 옮겨야 하나요?
대부분의 팀은 아니오입니다. 2.5 Pro를 기본 라인으로 유지하고, 고난도 요청만 3.1 Pro로 올리는 구조가 더 안전하고 비용 효율적입니다.
벤치마크 숫자는 완전한 1:1 비교라고 봐도 되나요?
아니요. 공식 수치이지만 단일 날짜·단일 하네스의 완전 통합 표는 아닙니다. 방향성 지표로 해석하고, 가격·상태·워크로드 적합성과 함께 판단해야 합니다.
Gemini 앱 사용자와 API 사용자에게 이 비교의 의미가 같나요?
같지 않습니다. 앱 사용자는 플랜 접근성과 모델 노출을, API 사용자는 무료 티어·토큰 단가·배치/캐시/그라운딩 비용·라우팅 정책을 더 우선해서 봐야 합니다.
결론
고난도 추론·에이전트 성능이 핵심이면 Gemini 3.1 Pro가 맞습니다. 안정성과 비용 효율이 중요한 넓은 운영 기본값은 여전히 Gemini 2.5 Pro가 유리합니다. 라우팅이 가능하다면 두 모델을 함께 쓰고, 요청 난도에 따라 승격하는 전략이 가장 실용적입니다.