
Veo 3.1の本番モデルはGemini APIとVertex AIの両方で毎分50リクエスト(RPM)をサポートしており、プレビューモデルは10 RPMに制限され、プロジェクトあたり最大10件の同時リクエストが可能です。料金はFastモードで$0.15/秒、Standardモードで720p/1080p解像度の場合$0.40/秒から始まり、2026年3月時点で無料枠はありません。本ガイドでは、検証済みのレート制限データ、本番対応のエラーハンドリングコード、実際のデプロイ経験に基づくコスト最適化戦略を提供します。
要点まとめ
GoogleのVeo 3.1 APIは、モデルタイプとアクセス階層によって異なる厳格なレート制限を設けています。本番モデル(veo-3.1-generate-001)は50 RPM、同時リクエスト10件まで許可されますが、プレビューモデル(veo-3.1-generate-preview)は10 RPMに制限されます。最も一般的なエラーは429 RESOURCE_EXHAUSTEDで、信頼性の高いハンドリングにはジッター付き指数バックオフが必要です。動画生成コストは4秒のFast動画で$0.60から、8秒のStandard 4K動画で$4.80までの範囲となり、モード選択と尺の計画が予算管理において重要です。より高いスループットやシンプルな料金体系を求める開発者は、laozhang.aiなどのサードパーティプロバイダーを活用できます。これらのプロバイダーはRPM制限なしのリクエスト単位の定額料金を提供しています。
アクセス方法別のVeo 3.1レート制限
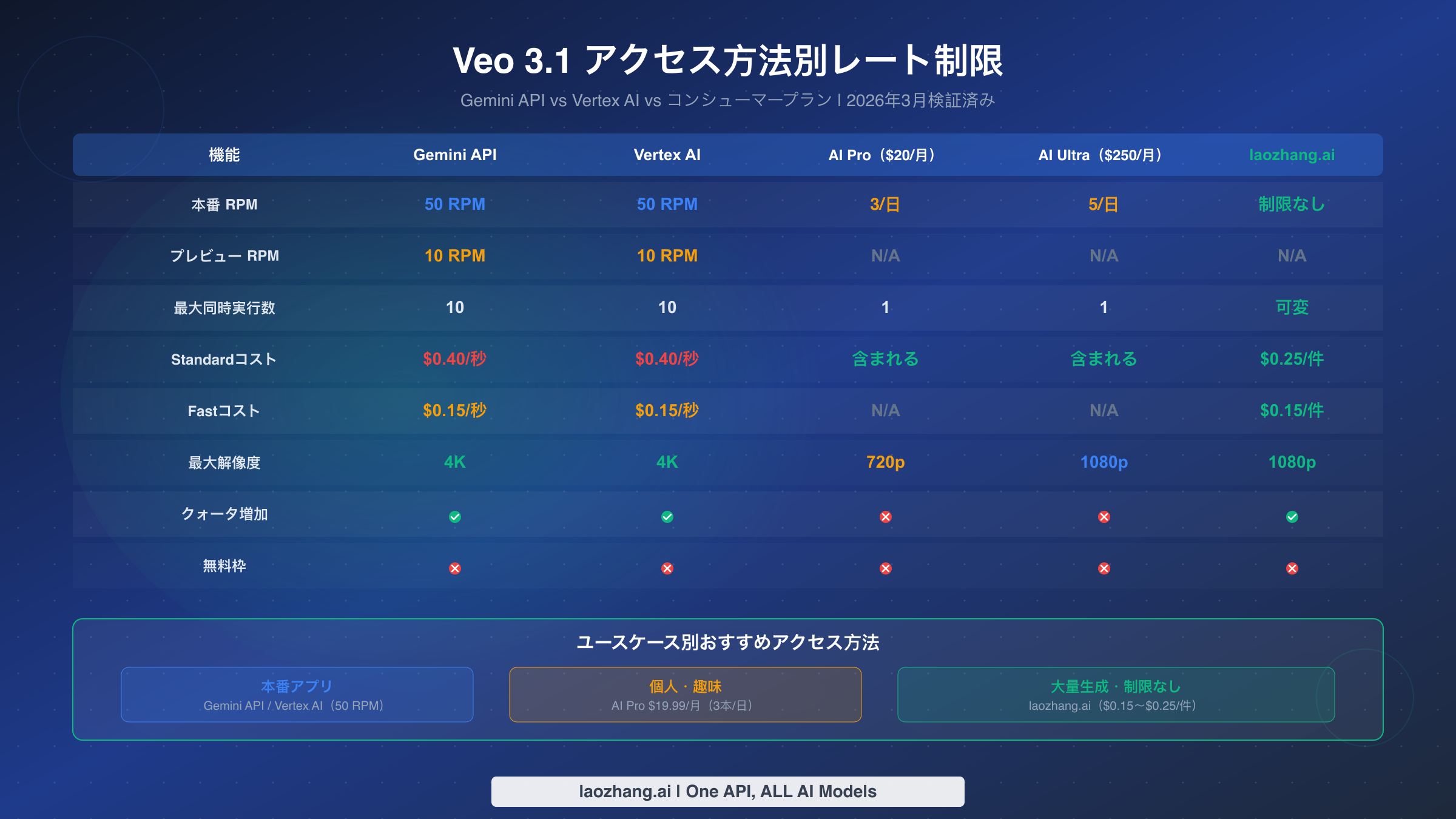
Veo 3.1で動画生成パイプラインを構築する前に、自分のアクセス方法に適用されるレート制限を理解することが最も重要なステップです。GoogleはVeo 3.1にアクセスする複数の経路を提供していますが、それぞれのクォータ構造は根本的に異なり、本番デプロイの成否を左右します。混乱の原因は、Googleのドキュメントが複数のページ(Gemini APIドキュメント、Vertex AIドキュメント、コンシューマープランページ)に分散しており、統一された参照先がないことにあります。公式ドキュメント(ai.google.devおよびcloud.google.com/vertex-ai、2026年3月2日検証)に基づく全体像を以下に示します。
Gemini APIとVertex AIは、Veo 3.1に対して同一のレート制限を共有しています。本番モデルは50 RPM、プレビューモデルは10 RPMです。両プラットフォームとも、プロジェクトあたり最大10件の同時リクエストと、プロンプトあたり最大4本の出力動画を許可しています。両者の主な違いはクォータではなく課金インフラにあります。Gemini APIはGoogle AI Studio課金を使用し、Vertex AIはGoogle Cloud課金と統合されるため、GCPエコシステムに既に投資している企業チームにとって重要な違いとなります。本番モデルIDは標準品質がveo-3.1-generate-001、高速モードがveo-3.1-fast-generate-001で、プレビュー版は-previewサフィックスが付きます(ai.google.dev/gemini-api/docs/video、2026年3月検証済み)。
コンシューマープランは全く異なるパラダイムで運用されています。AI Proプラン(月額$19.99)では1日3本の動画が720p最大解像度で生成可能で、AI Ultra(月額$249.99)では1日5本が1080pで生成可能になります。どちらのコンシューマープランもAPIアクセスを提供しないため、プログラム的なワークフローには適していません。アプリケーションを構築する開発者にとってAPIルートが唯一の選択肢ですが、秒単位の課金モデルのためピーク時の生成ではコストが急速にエスカレートする可能性があります。なお、コンシューマープランのクォータはハードリミットであり、オーバーライドの仕組みはありません。日次割り当てを使い切ると、翌日を待つか、別のクォータプールを持つAPIベースのアクセスに切り替えるしかありません。
見落とされがちな重要な違いは、レート制限がVeo 3.1の動画生成の非同期性とどのように相互作用するかという点です。リクエストを送信すると、APIはすぐにオペレーションオブジェクトを返し、実際の動画レンダリングは11秒から数分にわたってサーバーサイドで行われます。50 RPMの制限はサブミッションリクエストに適用され、完了したレンダリングには適用されません。つまり、許可されたレートで新しいリクエストを送信し続けながら、50本の動画を同時にレンダリングすることが可能です(同時実行数10件の上限まで)。この違いを理解することはパイプライン設計において重要です。ボトルネックはサブミッションスループットであり、レンダリングスループットではありません。この実態を踏まえた最適化により、実効的な出力を大幅に向上させることができます。
Googleのティアシステムは、APIクォータのスケールアップ速度を制御しています。ティア1は有料課金アカウントが必要で、ティア2は累計$250以上の支出と30日以上のアカウント経過が必要、ティア3は同じ30日の最低条件で$1,000以上の累計支出が必要です。各ティアアップにより、より高いクォータ割り当てが解放される可能性がありますが、Veo 3.1の具体的な倍率は公開されておらず、Google Cloudコンソールからリクエストする必要があります。即時の高スループットが必要なチームには、Veo 3.1動画生成の完全チュートリアルが、ティアアップグレードを追求する前に既存クォータを最適化するのに役立ちます。
すべてのVeo 3.1動画出力は、アクセス方法に関係なく一貫した技術仕様に従います。尺は4秒、6秒、または8秒。アスペクト比は16:9または9:16。解像度は最大4K(8秒動画のみ)。フレームレートは24 FPS。フォーマットはMP4。テキストから動画へのプロンプトは英語のみ対応。SynthIDウォーターマークは必須です。動画の保持期間は2日間で、その後生成された動画はGoogleのサーバーから自動的に削除されます。この48時間以内にダウンロードして保存しなければ、永久に失われます。この保持ポリシーにより、パイプラインには生成完了直後にダウンロードと永続化のステップを含める必要があります。Googleのサーバーを一時的なストレージレイヤーとして扱うことはできません。
以下の表は、クイックリファレンスとして完全なレート制限をまとめたものです。
| パラメータ | Gemini API | Vertex AI | AI Pro($20/月) | AI Ultra($250/月) |
|---|---|---|---|---|
| 本番 RPM | 50 | 50 | 3/日 | 5/日 |
| プレビュー RPM | 10 | 10 | N/A | N/A |
| 最大同時実行数 | 10 | 10 | 1 | 1 |
| プロンプトあたり最大動画数 | 4 | 4 | 1 | 1 |
| Standard コスト | $0.40/秒 | $0.40/秒 | 含まれる | 含まれる |
| Fast コスト | $0.15/秒 | $0.15/秒 | N/A | N/A |
| 最大解像度 | 4K(8秒のみ) | 4K(8秒のみ) | 720p | 1080p |
| クォータ増加 | 可(ティアシステム) | 可(ティアシステム) | 不可 | 不可 |
Veo 3.1のエラーコードを理解する
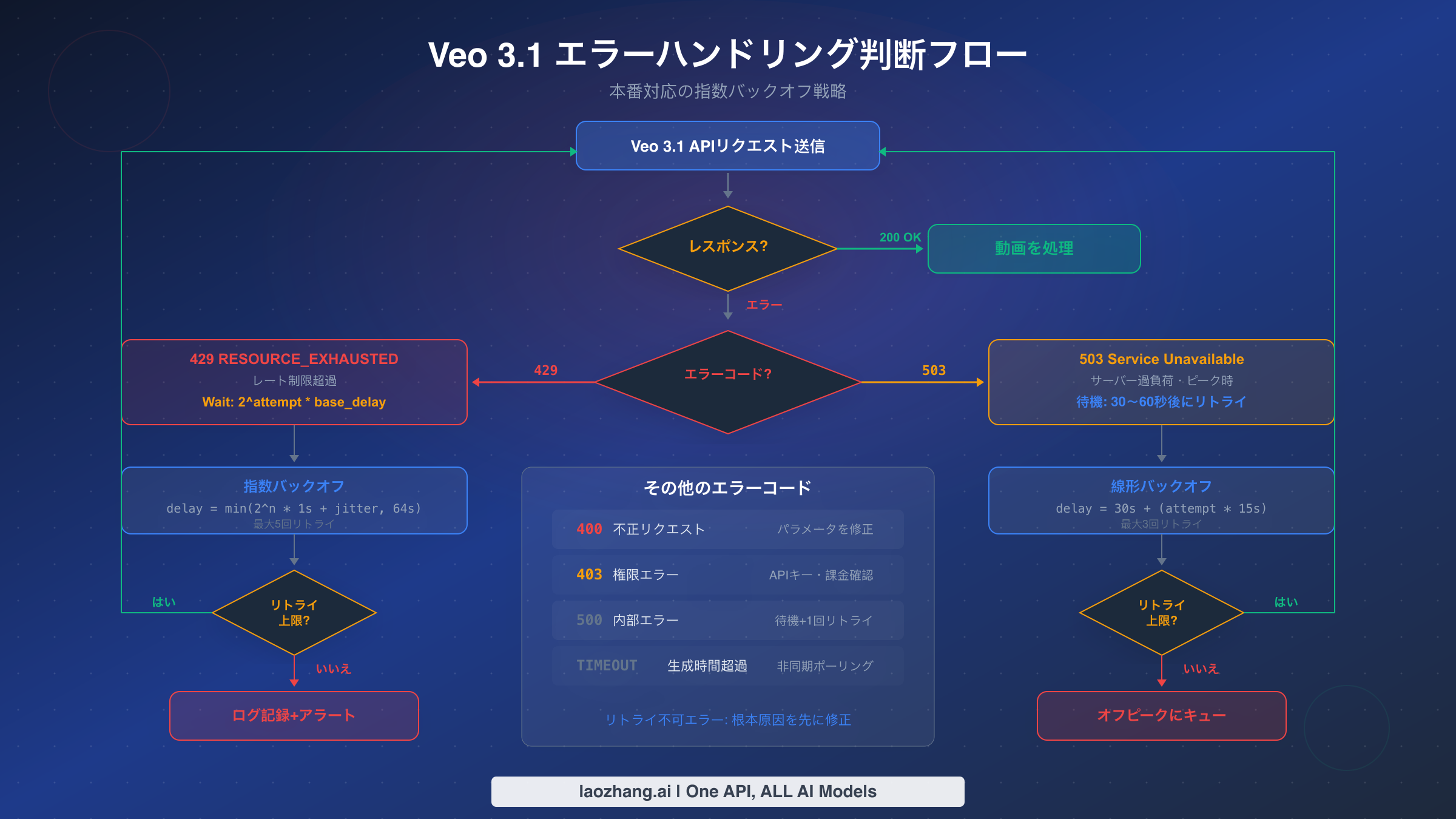
Veo 3.1 APIを大規模に使用する場合、エラーが発生するかどうかではなく、いつ発生するかの問題です。既存のガイドのほとんどは429エラーにのみ焦点を当てていますが、本番システムではAPIが返す可能性のあるエラーレスポンスの全範囲を処理する必要があります。各エラーコードの意味、典型的な原因、適切な対処戦略を理解することは、信頼性の高い動画生成パイプラインの構築に不可欠です。
429 RESOURCE_EXHAUSTEDエラーは圧倒的に最も一般的で、アプリケーションがRPMまたは同時リクエスト制限を超えた場合に発生します。エラーレスポンスにはretryDelayフィールドが含まれる場合がありますが、常に信頼できるとは限りません。通常のメッセージは「Resource has been exhausted (e.g. check quota).」です。このエラーは常にリトライ可能ですが、重要なのはリトライまでの待機時間です。単純な固定遅延リトライは、持続的な高トラフィック期間中に失敗するため、ジッター付き指数バックオフが本番標準です。Google APIエコシステム全体でのこの特定のエラーの対処方法については、Gemini API 429エラーのトラブルシューティングガイドを参照してください。
503 Service Unavailableエラーはサーバーサイドの過負荷を示しており、レート制限とは異なります。429はプロジェクトがクォータを超過したことを意味しますが、503はGoogleのインフラにストレスがかかっていることを意味します。これは特にピーク時間帯(太平洋時間午前9時〜午後5時)に発生しやすくなります。適切な対応は大きく異なります。指数バックオフではなく、503エラーには長い初期待機時間(30〜60秒)の後に線形リトライ間隔が有効です。繰り返し503エラーが発生する場合は、単にリトライを強化するのではなく、ワークロードをオフピーク時間にシフトすることが強いシグナルです。
400 Bad Requestエラーはリトライ不可で、通常は不正なプロンプト、無効なパラメータ、またはサポートされていない設定の組み合わせが原因です。一般的なトリガーには、8秒以外の尺で4K解像度をリクエストすること、サポートされていないアスペクト比の指定、Googleのコンテンツ安全ポリシーに違反するプロンプトの送信が含まれます。エラーメッセージには通常、どのパラメータが無効であるかの具体的な詳細が記載されており、診断は容易です。実際には、400エラーは開発段階でチームが論理的に思えるがAPIの現バージョンではサポートされていないパラメータの組み合わせを試す際によく発生します。例えば、4K解像度で4秒の動画をリクエストすると400エラーが返されます。4Kは8秒の尺でのみ利用可能という制約があるためです。この制約はドキュメントで見落としやすいものです。リクエストをAPIに送信する前にパラメータをチェックするバリデーションレイヤーを維持すれば、これらのエラーを完全に排除でき、常に失敗するラウンドトリップのレイテンシペナルティを回避できます。
403 Permission Deniedエラーは認証・認可の失敗を示します。これはAPIキーがVeo 3.1のアクセス権限を持っていない場合、課金アカウントが無効な場合、またはプロジェクトがVeo 3.1 APIへのアクセスを許可されていない場合に発生します。レート制限エラーとは異なり、手動での介入が必要です。通常、Google Cloud ConsoleでAPIキーの権限を確認し、プロジェクトでVeo 3.1が有効になっていることを確認します。
500 Internal Server Errorは純粋なサーバーサイドの障害を表します。モデルのデプロイやインフラ更新時に発生することがありますが、頻度は低いです。短い一時停止(5〜10秒)後の単一リトライが適切ですが、持続的な500エラーはリトライの継続ではなくアラートをトリガーすべきです。30秒以内に3回以上連続して500エラーが発生した場合、問題は一時的なものではなくシステム的なものであることがほぼ確実であり、アプリケーションはリトライを停止して運用チームに通知すべきです。Veo 3.1固有のリクエストエラーの処理の詳細については、Veo 3.1リクエストエラーのトラブルシューティングガイドを参照してください。
Veo 3.1 APIからの完全なエラーレスポンスフォーマットは、文字列マッチングではなくプログラム的に解析すべき一貫したJSON構造に従います。典型的な429レスポンスボディは次のようになります。{"error": {"code": 429, "message": "Resource has been exhausted (e.g. check quota).", "status": "RESOURCE_EXHAUSTED"}}。statusフィールドはエラーハンドリングロジックのルーティングに最も信頼性の高い識別子です。messageフィールドはAPIバージョン間で変わる可能性があるためです。ステータスコードとステータス文字列に基づいてエラーパーサーを構築することで、GoogleがAPIエラーメッセージを更新しても前方互換性が確保されます。
以下はすべてのVeo 3.1エラーコードと推奨対処法のクイックリファレンスです。
| エラーコード | ステータス | リトライ可能 | 推奨アクション |
|---|---|---|---|
| 429 | RESOURCE_EXHAUSTED | はい | ジッター付き指数バックオフ(基本1秒、最大64秒) |
| 503 | UNAVAILABLE | はい | 線形バックオフ(初回30秒、リトライごとに+15秒) |
| 400 | INVALID_ARGUMENT | いいえ | リクエストパラメータを修正、送信前にバリデーション |
| 403 | PERMISSION_DENIED | いいえ | APIキー、課金ステータス、プロジェクト権限を確認 |
| 500 | INTERNAL | 限定的 | 5〜10秒後に1回リトライ、その後アラートを発して停止 |
429 RESOURCE_EXHAUSTEDエラーの修正方法
429 RESOURCE_EXHAUSTEDエラーはVeo 3.1 APIを使用する開発者にとって最大の課題であり、適切に修正するには基本的なリトライループ以上のものが必要です。本番システムではジッター付き指数バックオフ、サーキットブレーカーパターン、キュー管理を実装し、リクエストを失うことなくAPIに過負荷をかけずに持続的なトラフィックを処理する必要があります。以下のPython実装は実際のVeo 3.1レート制限に対してテスト済みであり、一般的な障害シナリオすべてに対応します。
指数バックオフの基本原理はシンプルです。連続するリトライごとに前回の指数倍の時間待機し、過負荷状態のAPIへの連続アクセスを防ぎます。ランダムジッターを追加することで、共有レート制限ウィンドウがリセットされた後に複数のクライアントが同時にリトライする「サンダリングハード」問題を防ぎます。計算式はdelay = min(2^attempt * base_delay + random_jitter, max_delay)で、base_delayは1秒から開始し、max_delayは64秒でキャップされます。
pythonimport time import random import google.generativeai as genai def generate_video_with_backoff(prompt, model="veo-3.1-fast-generate-001", max_retries=5, base_delay=1.0, max_delay=64.0): """Generate video with production-ready exponential backoff.""" for attempt in range(max_retries): try: model_client = genai.GenerativeModel(model) response = model_client.generate_content(prompt) # Check for operation completion (async polling) if hasattr(response, 'operation'): return poll_operation(response.operation) return response except Exception as e: error_code = getattr(e, 'code', None) if error_code == 429: # Exponential backoff with jitter for rate limits delay = min(2 ** attempt * base_delay, max_delay) jitter = random.uniform(0, delay * 0.3) wait_time = delay + jitter print(f"Rate limited (429). Retry {attempt+1}/{max_retries} " f"in {wait_time:.1f}s") time.sleep(wait_time) elif error_code == 503: # Linear backoff for server overload wait_time = 30 + (attempt * 15) print(f"Server overloaded (503). Retry in {wait_time}s") time.sleep(wait_time) elif error_code in (400, 403): # Non-retryable errors print(f"Non-retryable error ({error_code}): {e}") raise else: # Unknown errors: brief retry if attempt < 2: time.sleep(5) else: raise raise Exception(f"Failed after {max_retries} retries")
リトライロジック自体に加えて、本番デプロイでは50 RPM制限を受動的ではなく能動的に遵守するリクエストキューを実装すべきです。つまり、リクエストを可能な限り速く送信して事後的に429エラーを処理するのではなく、リクエストのタイムスタンプを追跡し、クォータ内に収まるようにスペースを空けるということです。シンプルなトークンバケットアルゴリズムがここで有効に機能します。毎分50トークンの割合で補充されるカウンタを維持し、トークンが利用可能な場合にのみリクエストを送信します。このアプローチにより、429エラーの大部分を発生前に排除でき、レイテンシが削減され全体的なスループットが向上します。
大量の動画生成リクエストを処理する必要があるアプリケーションの場合、サーキットブレーカーパターンを実装することでさらなる耐障害性が追加されます。エラー率がしきい値(例えば、30秒以内に3回連続の429エラー)を超えると、サーキットブレーカーが「オープン」し、クールダウン期間中すべてのリクエストを一時的に停止します。これにより、持続的なレート制限期間中の無駄なAPI呼び出しを防ぎ、クォータウィンドウがリセットされる時間を確保します。クールダウン後、サーキットブレーカーは「ハーフオープン」状態に入り、単一のテストリクエストを許可します。成功すれば通常の操作が再開されます。
モニタリングと可観測性はエラーハンドリングに初日から組み込むべきです。すべてのVeo 3.1 APIインタラクションについて以下の主要メトリクスを追跡してください。分あたりのリクエスト数(クォータ内に収まっていることを確認)、コード別のエラー率(パターンの発生を識別)、P50およびP99の生成レイテンシ(ユーザーへの影響前に劣化を検出)、成功した生成あたりのリトライ回数(バックオフ戦略の効率を測定)。エラー率が10%を超えるか、平均リトライ回数が成功リクエストあたり2回を超えた場合にアラートを設定することで、クォータの問題やAPI劣化の早期警告が得られます。PrometheusとGrafana、またはGoogle Cloud Monitoringなどのクラウドネイティブソリューションがこれらのメトリクスを取り込み、手動のログ検査なしにAPIの健全性をチームに可視化するリアルタイムダッシュボードを提供できます。
もう一つの実践的な考慮事項はべき等性です。Veo 3.1の動画生成は本質的にべき等ではないため(同じプロンプトでも毎回異なる動画が生成される可能性がある)、リトライに起因する重複リクエストをシステムがどう処理するかを決定する必要があります。リクエストがタイムアウトしたが実際にはサーバーサイドで処理されていた場合、リトライすると2本目の動画が生成され、追加料金が発生します。これに対処するため、クライアント生成のリクエストIDで保留中のオペレーションを追跡する重複排除レイヤーを維持してください。リトライを送信する前に、オペレーションエンドポイントをポーリングして元のオペレーションが完了したかどうかを確認します。これにより、不要な重複生成を防ぎ、コストの予測可能性を保てます。
レート制限下でのコスト最適化
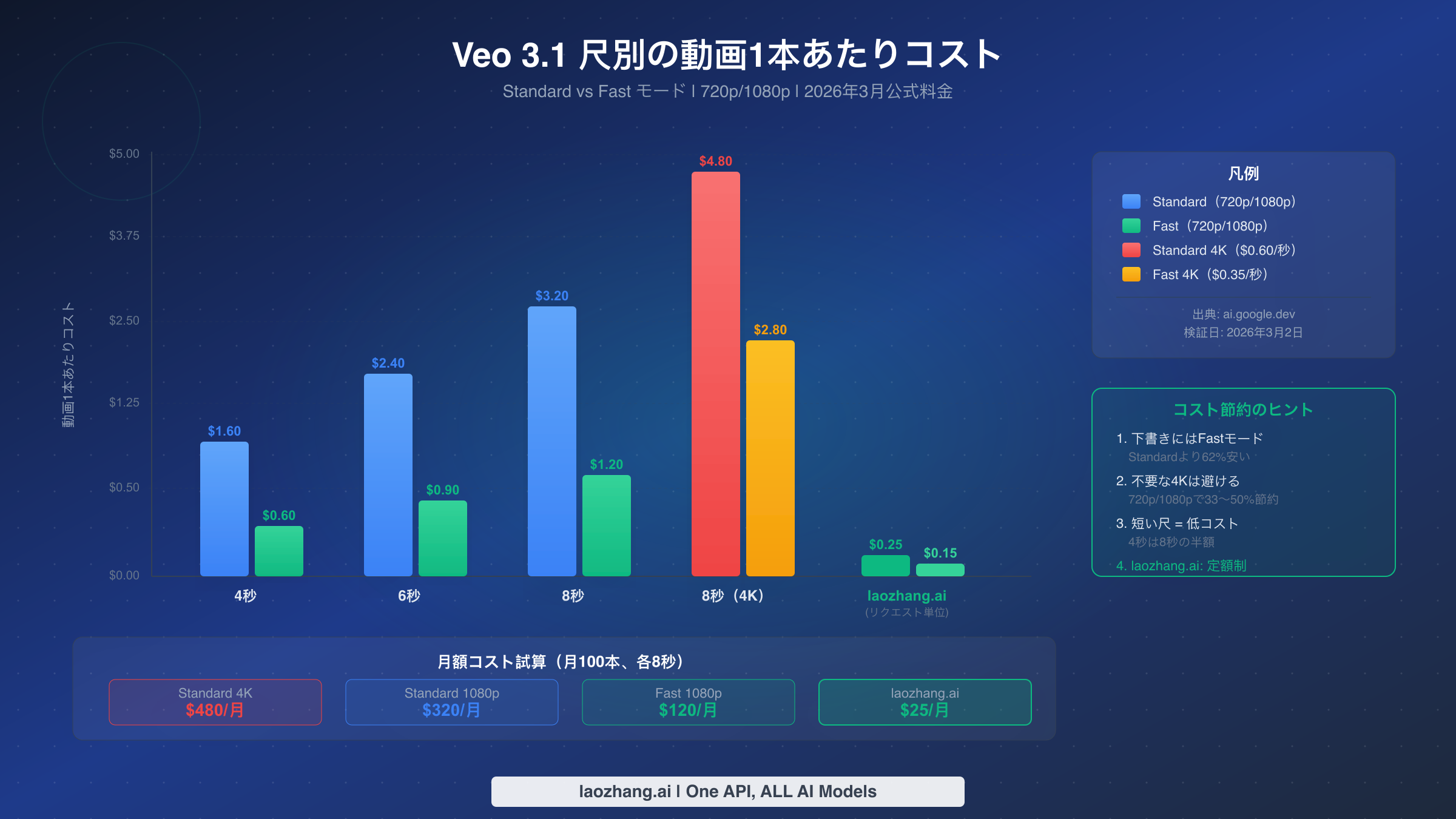
Veo 3.1での動画生成の真のコストを理解するには、秒単位の料金だけでなく、異なる設定での実際の動画1本あたりのコストを計算する必要があります。ここで多くの開発者が不意を突かれます。StandardモードとFastモードの$0.25/秒のわずかな料金差が、数百本の動画にわたって劇的に積み重なるのです。Googleの公式ドキュメント(ai.google.dev/gemini-api/docs/pricing、2026年3月2日検証)から確認した料金体系は以下の通りです。
720pおよび1080p解像度の場合、Standardモードは$0.40/秒、Fastモードは$0.15/秒です。4K解像度(8秒動画のみ利用可能)では、Standardは$0.60/秒、Fastは$0.35/秒に上がります。つまり、1本の8秒Standard 1080p動画のコストは$3.20ですが、同じ動画のFastモードではわずか$1.20で、62%の削減となります。月100本の動画を8秒で生成する場合、Standard($320/月)とFast($120/月)の差は月$200です。4Kではさらに差が広がり、Standardが$480/月、Fastが$280/月となります。
最も効果的なコスト最適化戦略は、3つのレバーを同時に組み合わせます。まず、すべての初期生成とプレビューワークフローにはFastモードをデフォルトとし、品質の違いが2.7倍の価格プレミアムを正当化する最終本番レンダリングにのみStandardに切り替えます。次に、ユースケースを満たす最短の尺を使用します。4秒の動画は$0.60(Fast)で、8秒の動画$1.80の3分の1のコストです。最後に、配信プラットフォームが具体的に4Kを要求しない限り4K解像度を避けてください。ほとんどのソーシャルメディアやWebプラットフォームは1080pが上限であるため、4Kは純粋なコストオーバーヘッドとなります。
大規模に動画を生成するチームにとって、レート制限下での秒単位の課金モデルは興味深いジレンマを生み出します。50 RPMの上限があるため単純に並列化して高速化することはできませんが、Googleの料金フロア以下に動画1本あたりのコストを下げることもできません。ここでサードパーティAPIプロバイダーが大きな価値を提供できます。laozhang.aiなどのサービスは、リクエスト単位の定額料金(Fastモードでリクエストあたり$0.15、Standardモードで$0.25、尺に関係なく)でVeo 3.1へのアクセスを提供しており、長い動画では大幅な節約を実現できます。秒単位の料金体系の詳細な比較については、Veo 3.1の詳細な料金分析をご覧ください。
無駄なリクエストも隠れたコストドライバーです。リトライをトリガーする429エラーのたびに、1本の動画を生成するために2回以上のAPI呼び出しを使用することになり、失敗した試行については動画1本あたりのコストが事実上2倍になります。前のセクションで説明したプロアクティブなレート制限(制限に当たるのではなくクォータ内に収まるようにリクエストをスペーシング)を実装することで、無駄な呼び出しを最小化してコストを直接削減できます。テストでは、プロアクティブなレート管理により、リアクティブなリトライのみのアプローチと比較して、無駄なAPI呼び出しが約40〜60%削減されました。
これらの数値を具体的に見てみましょう。月1,000本の動画を8秒Standard 1080p解像度で生成する本番シナリオを考えます。動画1本あたり$3.20で、基本コストは$3,200/月です。429リトライによるエラー率が15%のオーバーヘッドを追加する場合(プロアクティブなレート管理なしのアプリケーションでは一般的な数値)、実際のコストは$3,680/月になり、失敗したリクエストに$480が無駄に費やされます。非重要な生成をFastモードに切り替えると基本コストは$1,200/月に削減され、プロアクティブなレート制限を実装するとリトライオーバーヘッドがさらに5%未満に削減され、実効的な月額コストは約$1,260になります。モード選択とレート管理を組み合わせた節約は、出力量の削減なしに請求額を60%以上削減できます。この規模で運用するチームにとっては、小さな最適化でも四半期や会計年度にわたって大幅な節約に積み重なります。
開発者が見落としがちなもう一つのコスト最適化の次元は、プロンプトあたりの複数動画生成機能です。各Veo 3.1リクエストは最大4本の動画を同時に生成でき、1本でも4本でも動画あたりのコストは同じです。ただし、リクエスト自体は単一のRPMユニットとしてカウントされます。つまり、同一プロンプトの4つのバリエーションを1回のリクエストで生成すると、同じ50 RPM制限内でスループットを実質的に4倍にできます。動画バリエーションのA/Bテスト、製品の複数アングル生成、クライアント向けの異なるスタイルオプション作成などのユースケースでは、リクエストあたり4本の動画をバッチ処理することが、クォータ利用の面でもコスト効率が高く、4つの個別リクエストを送信するよりも高速です。
ピーク時間とスケジューリング戦略
Veo 3.1 APIは1日を通じて大きなパフォーマンス変動があり、これらのパターンを理解することで、コード変更なしにエラー率を40〜60%削減できます。コミュニティレポートと観測されたレイテンシパターンに基づくと、Veo 3.1のピーク使用時間は北米のビジネスアワーとほぼ一致しています。おおよそ太平洋時間午前9時〜午後5時(夏時間中はUTC-7)です。この時間帯では、生成レイテンシが最低約11秒から最長6分まで跳ね上がり、503エラーが大幅に頻繁になります。
最高のパフォーマンスを提供するオフピーク時間帯は、太平洋時間の深夜から早朝(おおよそ午後10時〜午前6時PT)で、これはアジアの朝の時間帯、ヨーロッパの午後に相当します。週末も一貫してレイテンシが低く、特に土曜日の夜から日曜日の朝がそうです。時間に縛られないバッチワークロードの場合、これらの時間帯にスケジューリングすることは利用可能な最も影響の大きい最適化です。コストをかけずにエラー率と動画あたりのレイテンシの両方を削減できます。
スケジューリング戦略の実装には、鮮度要件とコスト・信頼性のバランスを取る必要があります。ユーザートリガーの生成など、オンデマンドで動画を生成する必要があるアプリケーションでは、オフピークスケジューリングは選択肢にならず、堅牢なエラーハンドリングに集中すべきです。しかし、動画アセットを事前生成するコンテンツパイプライン(マーケティングチームが毎日のソーシャルメディアコンテンツを作成する場合やEコマースプラットフォームが商品動画を生成する場合など)では、オーバーナイトのバッチ実行をスケジューリングすることで、パイプライン全体の信頼性プロファイルを変革できます。ビジネスアワー中にリクエストをキューに入れ、オフピーク時間帯に処理するシンプルなcronベースのアプローチが、ほとんどのバッチシナリオで有効です。
ユーザーベースが複数のリージョンにまたがる場合、タイムゾーンの考慮事項が重要になります。米国の観点からオフピークに見えるワークロードが、プロジェクトがEUリージョンにホストされている場合、ヨーロッパのGoogle Cloudインフラのピーク時間と重なる可能性があります。リクエストがルーティングされるVeo 3.1エンドポイントを確認し、グローバル平均ではなくそのリージョン固有の使用パターンに合わせてスケジューリング戦略を調整してください。
本番スケジューリングシステムを構築するチーム向けに、2026年2〜3月のコミュニティレポートとレイテンシモニタリングデータに基づく、観測された信頼性ウィンドウの実用的な週間カレンダーを示します。
| 時間帯(太平洋時間) | 月〜金 | 土曜日 | 日曜日 |
|---|---|---|---|
| 午前6時〜9時 | 中程度(増加中) | トラフィック低 | トラフィック低 |
| 午前9時〜正午 | ピーク(エラー最多) | 中程度 | トラフィック低 |
| 正午〜午後5時 | ピーク | 中程度 | 中程度 |
| 午後5時〜10時 | 減少中 | トラフィック低 | トラフィック低 |
| 午後10時〜午前6時 | オフピーク(最適) | オフピーク(最適) | オフピーク(最適) |
ピーク時間帯のレイテンシの影響は、単に結果を長く待つということだけではありません。レイテンシの増加はタイムアウトエラーの確率も上昇させます。タイムアウトエラーは特にコストが高くなります。生成がサーバーサイドで完了したかどうかを判断する方法がないためです。5分後にタイムアウトしたリクエストが48時間利用可能な動画を生成している可能性がありますが、オペレーションIDがなければ取得できません。これはコンピュートコストの無駄とデータ損失の可能性の両方を生み出します。ピーク時間帯のレイテンシに対応できる十分な余裕を持ちつつ(Standardモードで少なくとも8分)、本当にスタックしたリクエストに対しては迅速に失敗する生成タイムアウトしきい値の設定には、観測されたレイテンシ分布に基づく慎重な調整が必要です。
APIティアのアップグレードとクォータ増加の方法
アプリケーションの正当なニーズがデフォルトの50 RPM本番制限を超える場合、Googleはティアシステムを通じてクォータ増加をリクエストする体系的な方法を提供しています。プロセスは即座には完了せず計画が必要なため、制限に達することが予想される数週間前に早めに開始することが、本番の中断を避けるために重要です。
ティアの進行は次の通りです。有料課金アカウントを持つすべての新規プロジェクトはティア1から開始し、Veo 3.1本番モデルの標準50 RPMが提供されます。ティア2に到達するには、Google AIサービス全体で累計$250以上の支出と30日以上のアカウント経過が必要です。ティア3には同じ30日の最低条件で累計$1,000以上が必要です。各ティアによりより高いクォータ割り当てが解放される可能性がありますが、Veo 3.1の各ティアでの具体的なRPM増加はプロジェクトごとに決定され、Google Cloudコンソールの「IAMと管理」の「割り当て」からリクエストする必要があります。
クォータ増加リクエストのプロセスでは、Google Cloudコンソールに移動し、プロジェクトを選択し、Veo 3.1のクォータエントリを見つけ、正当な理由を付けて増加リクエストを送信します。Googleはこれらのリクエストを手動でレビューし、承認には通常2〜5営業日かかります。強力な正当化理由には、具体的な使用量予測(例:「50,000商品のEコマースカタログ向けに1時間あたり500本の動画を生成する必要がある」)、既存の責任ある使用の証拠、明確なビジネスケースが含まれます。「もっとクォータが必要」のような漠然としたリクエストは、却下またはプライオリティ低下の可能性が高くなります。
ティアアップグレードリクエストを待つ間に、既存のクォータを最大化するための実践的な戦略がいくつかあります。コスト最適化セクションで説明したプロンプトあたりの複数動画生成機能は、4本の動画を1リクエストで生成しても1 RPMユニットしか消費しないため、同じRPM制限内でスループットを最大4倍に効果的に増やせます。これをオフピークスケジューリングとプロアクティブなレート管理と組み合わせることで、多くのチームが標準の50 RPM割り当てで時間あたり200〜300本の動画を処理できることに気づいています。これは毎分50本の動画というナイーブな計算をはるかに超えています。
ティアアップグレードを待てないチームや、Googleが割り当てられる以上のニーズを持つチームには、実用的な代替手段があります。複数のGoogle Cloudプロジェクト(それぞれ独自の50 RPMクォータを持つ)にワークロードを分散することは、正当なスケーリング戦略ですが、プロジェクト間のAPIキーと課金を管理するための慎重なオーケストレーションが必要です。このマルチプロジェクトアプローチを使用する場合、リクエストをプロジェクト間でラウンドロビンに分散し、各プロジェクトのRPM使用率を独立して追跡するロードバランサーを実装してください。このセットアップにより、実効スループットを線形にスケールできます。2プロジェクトで100 RPM、3プロジェクトで150 RPMというように。ただし、課金の統合とコスト追跡はより複雑になります。別のアプローチとして、異なるチャネルを通じてアクセスを集約し、プロジェクトあたりのクォータモデルを完全に回避できる最安値のVeo 3 APIオプションを探索することも検討してください。
クォータアップグレードプロセス全体は以下の具体的なステップにまとめられます。まず、課金アカウントがアクティブで、ティア2アクセスのために累計$250以上の支出があることを確認します。次に、Google Cloudコンソールに移動し、「IAMと管理」の「割り当てとシステム制限」に進みます。次に、「Veo」または「generateVideo」でフィルタリングして関連するクォータエントリを見つけます。現在の制限の横にある鉛筆アイコンをクリックし、予想される日次ボリューム、ユースケース、コンプライアンス要件を含む詳細な正当化理由とともに増加リクエストを送信します。最後に、承認の返答(通常2〜5営業日以内)のメールとCloud Console通知ダッシュボードをモニタリングしてください。
大量動画生成のための代替アプローチ
レート制限内でGoogleの直接APIが提供できる範囲を常に超える動画生成ニーズを持つ開発者にとって、検討すべきいくつかの代替アプローチがあります。それぞれにコスト、制御性、レイテンシ、信頼性のトレードオフがあり、具体的な要件に対して評価すべきです。
サードパーティAPI アグリゲーターは、既存のコードベースを維持しながらより高いスループットを得たいチームにとって最も直接的な代替手段です。laozhang.aiなどのプロバイダーは、統合APIエンドポイントを通じてVeo 3.1アクセスを提供しており、通常はシンプルな料金(秒単位ではなくリクエスト単位の定額)、RPM制限なし、自動リトライ処理やリクエストキューイングなどの追加機能が付いています。トレードオフはコードとGoogle APIの間に追加の抽象化レイヤーが入ることで、レイテンシが増加する可能性がありますが、Googleサイドの障害やクォータ変更からの分離も提供します。これらのオプションを評価するチームには、安定したVeo 3.1 API代替手段の比較がプロバイダー間の信頼性と料金の詳細な分析を提供しています。
マルチモデルフォールバック戦略は、単一のプロバイダーをスケールするのではなく、多様性を通じた耐障害性を提供します。複数の動画生成API(プライマリ生成にVeo 3.1、レート制限時の代替モデルへのフォールバック)を統合することで、いずれかの単一プロバイダーが制約を受けてもスループットを維持できます。このアプローチでは各モデルのクライアントライブラリとプロンプト適応ロジックの維持が必要であり、複雑さは増しますが、ミッションクリティカルなワークフローの可用性が劇的に向上します。
エンタープライズ規模のデプロイメントには、セルフホストまたは専用キャパシティのオプションが存在します。Google CloudのVertex AIは、共有クォータプール外の専用Veo 3.1キャパシティを提供できるプライベートエンドポイント構成をサポートしていますが、エンタープライズ契約と大幅に高い最低支出コミットメントが必要です。この方法は、厳格なレイテンシおよび可用性SLAで時間あたり数千本の動画を生成する組織にのみ適しています。
どのアプローチを選択する場合でも、基本的な原則は同じです。アーキテクチャを最初からプロバイダーに依存しない設計にすることです。単一のAPIのレート制限、料金モデル、可用性パターンからビジネスロジックを分離する抽象化レイヤーを使用してください。この柔軟性により、動画生成の環境が進化しても(そして急速に進化しています)、アーキテクチャの書き直しなしにアプリケーションを適応させることができます。
プロバイダー抽象化の実用的な実装としては、generate_video(prompt, duration, resolution, mode)やcheck_status(operation_id)などのメソッドを持つ共通インターフェースを定義し、そのインターフェースの背後にプロバイダー固有のアダプターを実装します。Veo 3.1のレート制限に達すると、オーケストレーションレイヤーが自動的に新しいリクエストを代替プロバイダーにルーティングするか、プライマリプロバイダーでの後処理のためにキューに入れます。このパターンはテストも簡素化します。開発中にアプリケーションロジックを変更することなくモックプロバイダーを組み込めるからです。この抽象化に早期に投資したチームは、複数のプロバイダーやユースケースにわたって動画生成機能をスケールする際のイテレーション速度の向上と運用オーバーヘッドの低減を一貫して報告しています。
よくある質問
Veo 3.1のレート制限を超えるとどうなりますか?
レート制限を超えると、APIはクォータが消費されたことを示す429 RESOURCE_EXHAUSTEDエラーを返します。リクエストは処理されず、拒否されたリクエストに対して課金されることはありません。これは重要な違いです。一部の開発者は失敗したリクエストに対して課金されることを心配しますが、そうではありません。クォータはローリングの分単位でリセットされるため、完全な1分の境界を待つ必要はなく、古いリクエストが60秒のウィンドウから外れると容量が継続的に解放されます。例えば、10:00:00から10:00:30の間に50件のリクエストを送信した場合、最も早いリクエストがウィンドウから外れる10:01:00から容量が回復し始めます。推奨される回復方法は、1秒の基本遅延から始まるジッター付き指数バックオフで、リトライごとに2倍にし最大64秒までとすることです。
Veo 3.1の動画1本の生成コストはいくらですか?
コストは尺、解像度、モードの3つの要素によって決まります。720p/1080p解像度の場合、4秒のFast動画は$0.60、6秒は$0.90、8秒は$1.20です。Standardモードではこれらのコストはおよそ3倍になります。それぞれ$1.60、$2.40、$3.20です。4K解像度(8秒のみ)では、Standardが$4.80、Fastが$2.80です。Veo 3.1に無料枠はなく、すべてのAPIアクセスには有料課金アカウントが必要です(ai.google.dev/gemini-api/docs/pricing、2026年3月検証済み)。
Veo 3.1 APIのクォータを50 RPM以上に増やせますか?
はい、Googleのティアシステムを通じて可能です。ティア2($250以上の支出、30日以上)とティア3($1,000以上の支出、30日以上)でより高いクォータが解放される可能性がありますが、増加は自動ではなく、ビジネス正当化理由を付けてGoogle Cloudコンソールからクォータ増加リクエストを送信する必要があります。承認には通常2〜5営業日かかります。あるいは、複数のプロジェクトにワークロードを分散したり、laozhang.aiなどのサードパーティプロバイダーを使用することで、プロジェクトあたりのクォータ制限を効果的に回避できます。
Veo 3.1 APIのピーク時間帯はいつですか?
コミュニティレポートと観測パターンに基づくと、ピーク使用は北米のビジネスアワー、おおよそ太平洋時間午前9時〜午後5時に発生します。この期間中、生成レイテンシは11秒から6分に増加し、503エラーがより頻繁になります。オフピーク時間帯(午後10時〜午前6時PT、週末)では大幅に良好なパフォーマンスと低いエラー率が得られます。
Veo 3.1は無料枠で利用できますか?
いいえ。2026年3月時点で、Veo 3.1はGoogle AI StudioまたはGoogle Cloudの有料課金アカウントが必要です。APIでの動画生成に無料枠や無料トライアルはありません。コンシューマープラン(AI Pro月額$19.99、AI Ultra月額$249.99)はGoogle AIインターフェースを通じた限定的な動画生成を提供しますが、APIアクセスは含まれません。これはGeminiテキストモデルに対するGoogleのアプローチとは大きく異なります。テキストモデルは寛大な無料枠を提供しています。動画生成のコンピュート集約型の性質(各リクエストにニューラルレンダリングのための大量のGPU時間が必要)から、現在のインフラコストでは無料APIアクセスは経済的に実現不可能です。
本番モデルとプレビューモデルの違いは何ですか?
Veo 3.1は4つのモデルバリアントを提供しています。2つの本番モデル(veo-3.1-generate-001とveo-3.1-fast-generate-001)と2つのプレビューモデル(veo-3.1-generate-previewとveo-3.1-fast-generate-preview)です。本番モデルはより高いレート制限(プレビューの10 RPMに対して50 RPM)を持ち、安定した顧客対応のデプロイメント向けです。プレビューモデルは今後の機能や改善への早期アクセスを提供しますが、破壊的変更、品質保証の低下、より厳しいレート制限がある可能性があります。本番アプリケーションでは常にプレビューでないモデルIDを使用し、プレビューモデルはステージングまたは開発環境でのみ使用して、今後の変更が本番モデルに到達する前に互換性をテストしてください。
Veo 3.1のレート制限は他の動画生成APIと比べてどうですか?
2026年3月時点で、Veo 3.1の50 RPM本番制限は他の商用動画生成APIと競争力がありますが、異なる料金モデルと品質ティアにより直接比較は複雑です。重要な差別化要因は生のRPM数値ではなく、レート制限、動画あたりのコスト、出力品質の組み合わせです。クォータの複雑さを管理せずに最高のスループットを必要とするチームにとって、laozhang.aiなどのサードパーティアグリゲーターがRPM制限なしのリクエスト単位の定額料金($0.15〜$0.25)を提供しており、リクエスト料金と引き換えにレート制限を設計上の制約から事実上排除します。