
OpenAI と Claude の prompt caching は、どちらも長い入力を繰り返すときのコストを下げます。ただし、請求のされ方は同じではありません。2026-05-19 に確認した公式料金では、OpenAI の標準 GPT-5.5、GPT-5.4、GPT-5.4 mini は cached input を通常 input の 10 分の 1 として扱い、別の cache write 料金はありません。一方 Claude は cache read が基礎 input の 0.1 倍ですが、最初にキャッシュを作る cache write が別料金です。5 分 TTL の書き込みは 1.25 倍、1 時間 TTL の書き込みは 2 倍です。
そのため、判断軸は「どちらの割引率が大きいか」ではありません。安定した system prompt、tools、長い参照データ、コードベース要約、few-shot 例を繰り返すなら、OpenAI は自動キャッシュで低摩擦に検証しやすい選択肢です。Claude は、どこまでをキャッシュし、どの TTL で再利用するかを明示的に管理したい場合に強くなります。どちらを使う場合も、OpenAI では usage.prompt_tokens_details.cached_tokens、Claude では cache_read_input_tokens、cache_creation_input_tokens、input_tokens をログに出すまで、節約を前提にした予算は組まない方が安全です。
| ワークロード | 先に見る候補 | 理由 | 必ず見るログ |
|---|---|---|---|
| 長い固定プレフィックスが毎回同じ | OpenAI | 自動キャッシュで write premium がない | cached_tokens |
| cache breakpoint や TTL を制御したい | Claude | 書き込みと読み取りを明示できる | cache_creation_input_tokens / cache_read_input_tokens |
| 数回しか再利用しない | どちらも過大評価しない | 書き込み、miss、output が節約を消す | hit rate と出力比率 |
| 冒頭に動的データが入る | 先に prompt layout を直す | 前方の差分は miss の原因になる | prefix hash |
| Batch、長コンテキスト、クラウド経由 | 別計算 | 基本料金だけでは足りない | 最新の公式料金 |
まず結論:安い方は再利用パターンで変わる
OpenAI は、長く安定したプレフィックスが自然に繰り返される API に向いています。対応モデルではキャッシュは自動で試され、プロンプトが 1024 tokens 以上になると対象になり、同じ前方部分が再利用されると cached input として安くなります。最初の miss は通常 input として請求されますが、後続の hit では cached input の料金行を使います。実装側はまず安定部分を前に置き、cached_tokens を記録し、実際に hit しているかを見るだけでも判断を始められます。
Claude は、キャッシュを設計対象として扱うときに強くなります。tools、system、messages の階層と cache breakpoint を使い、どのブロックをどの TTL で再利用するかを明示できます。5 分 TTL は同じ会話や短い agent loop に向き、1 時間 TTL は事前に温めた長い文脈を複数リクエストで使うときに向きます。ただし初回の書き込みが高くなるため、読み取り回数が少ないと、見かけの 0.1x read は全体の節約になりません。
「入力トークンが 90% 安い」「OpenAI は 50%」「Claude は cache token が安い」といった短い表現だけでは、予算判断には足りません。これらは一部の行だけを切り出した説明です。現在の OpenAI 標準行では 10 分の 1 の cached input があり、古い 50% 表現はそのまま使えません。Claude は read が安くても write が先にあります。出力トークンはどちらも割引対象外です。
料金の言葉を分ける
OpenAI の cached input は、命中した入力部分に使われる料金行です。現在の標準行では、最初にキャッシュを書き込むための追加料金は見えません。リクエストが対象になり、前方の安定部分が一致すると、後続リクエストの該当部分が cached input として計上されます。
Claude では、cache write と cache read を分けて考えます。cache write はキャッシュを作る、または更新するための入力です。cache read は後続リクエストが既存のキャッシュを読めたときの入力です。ここに通常 input と output tokens が加わるので、総額は「read が 0.1x だから全部 90% 安い」という式にはなりません。
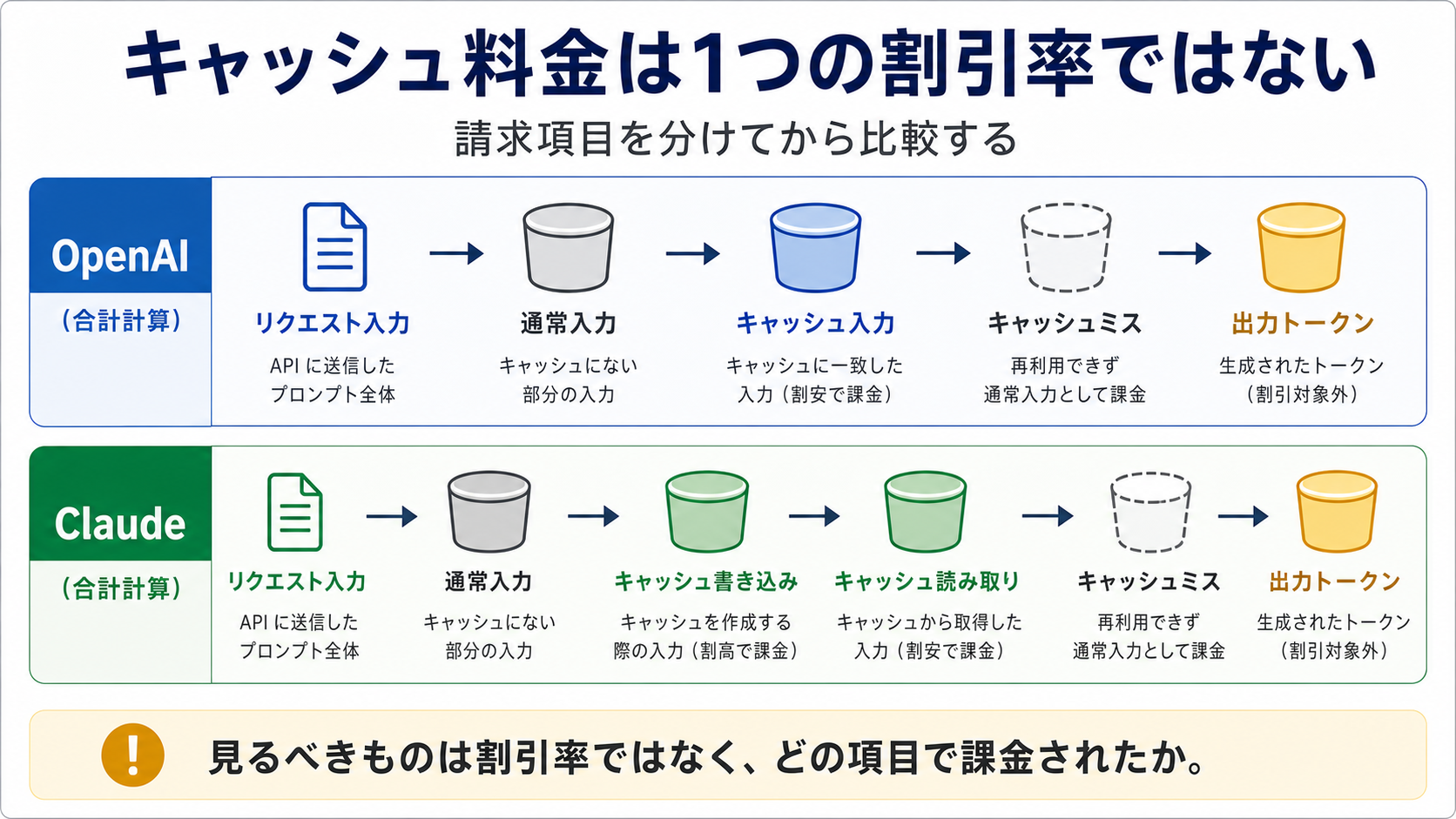
| 請求項目 | OpenAI | Claude | 意味 |
|---|---|---|---|
| 通常入力 | miss、対象外、新規入力 | 新規入力、miss | 毎回発生しうる |
| 書き込み | 追加 premium はない | 5 分 1.25x、1 時間 2x | Claude の初回コスト |
| 読み取り | cached input | cache read 0.1x | hit したときだけ安い |
| miss | 通常 input に戻る | 通常 input または再 write | 予算ずれの主因 |
| output | 別料金 | 別料金 | 長い出力は節約率を下げる |
この分け方をしておくと、実装の優先順位が変わります。料金表を眺める前に、プロンプトの前方部分が安定しているか、TTL 内に再利用されるか、ログで hit を証明できるかを確認する必要があります。
2026-05-19 時点の料金をどう読むか
OpenAI の現行料金表では、標準短コンテキストの GPT-5.5 が input $5.00、cached input $0.50、output $30.00 / 1M tokens でした。GPT-5.4 は $2.50、$0.25、$15.00、GPT-5.4 mini は $0.75、$0.075、$4.50 です。ここで大事なのは数字を暗記することではなく、cached input の比率と、別の write premium がないという会計構造です。Pro 系の行や長コンテキスト行は別途確認する必要があります。
Claude の料金表は、最初から cache write と cache read が分かれています。Opus 4.7、4.6、4.5 は input $5、5 分 write $6.25、1 時間 write $10、read $0.50、output $25 / 1M tokens。Sonnet 4.6、4.5 は $3、$3.75、$6、$0.30、$15。Haiku 4.5 は $1、$1.25、$2、$0.10、$5 でした。Claude では「初回が高く、後続が安い」という時間軸を予算表に入れる必要があります。
料金は変わります。モデル名、対応モデル、長コンテキスト、Batch、データレジデンシー、クラウド経由、企業契約、rate limit の扱いはすべて更新されます。記事や設計書に金額を書くなら、必ず確認日を添えるべきです。
繰り返しプレフィックスの簡単な計算
100k tokens の安定したプレフィックスを 10 回連続で使うとします。出力と新規入力は一旦別にします。OpenAI GPT-5.4 では input が $2.50 / 1M、cached input が $0.25 / 1M です。最初の 100k が miss なら約 $0.25。後続 9 回が hit すれば 1 回あたり約 $0.025、合計約 $0.225。10 回分の繰り返し入力は約 $0.475 になります。
Claude Sonnet 4.6 の 5 分キャッシュでは、input が $3 / 1M、write が $3.75 / 1M、read が $0.30 / 1M です。最初に 100k を write すると約 $0.375。後続 9 回が read なら 1 回あたり約 $0.03、合計約 $0.27。合計は約 $0.645 です。1 時間 TTL を選ぶと初回 write はさらに高くなりますが、長い再利用窓が必要なら意味があります。
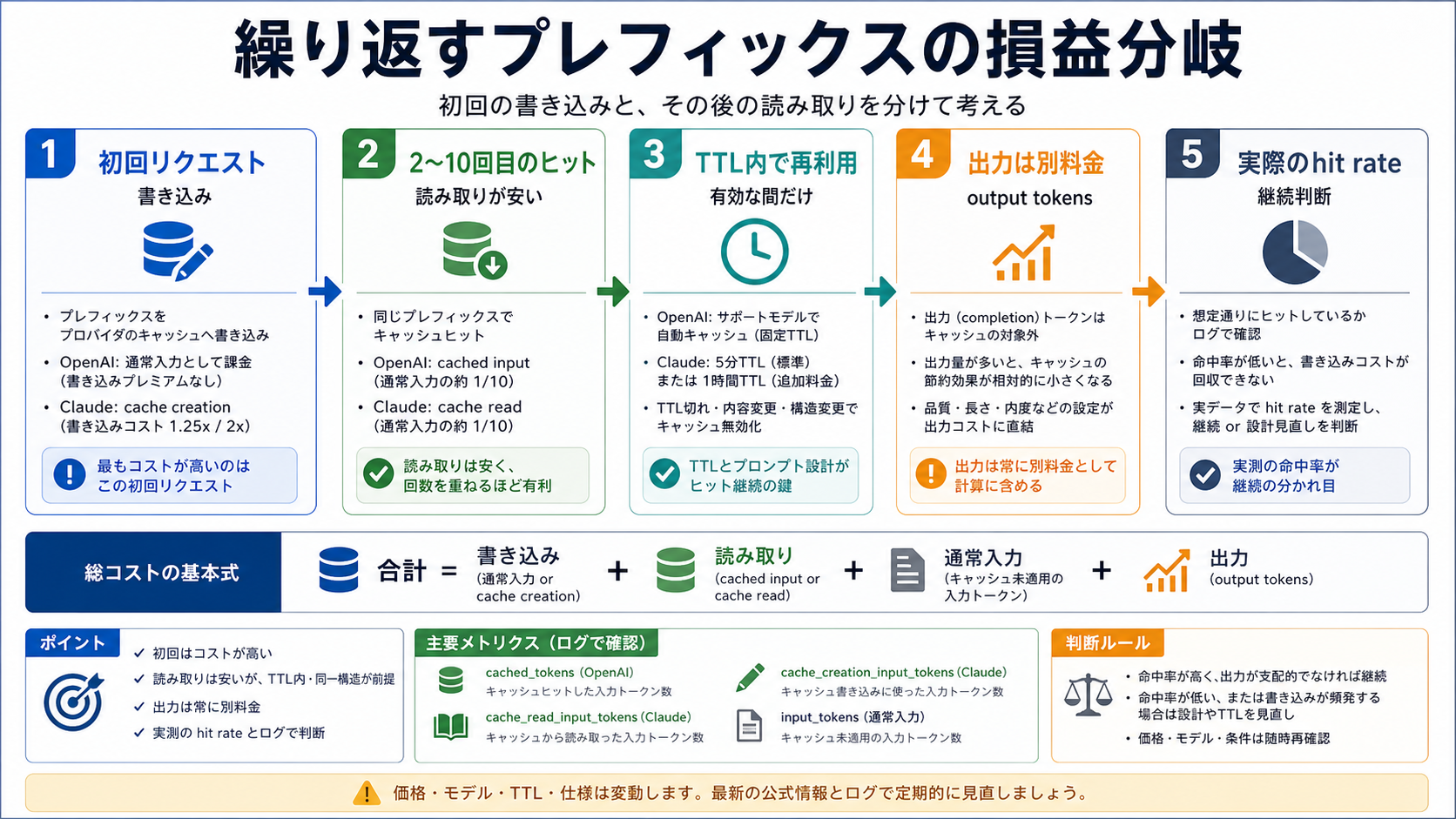
この計算は勝者を固定するものではありません。OpenAI は自動で簡単、Claude は制御しやすい。どちらも hit rate、TTL 内の再利用回数、出力の長さ、miss の頻度を入れないと、本番の請求には近づきません。
Prompt layout が hit を決める
キャッシュは「意味が似ている」だけでは効きません。OpenAI では、同じ前方部分が再利用されることが重要です。system prompt、tools、固定ポリシー、スキーマ、長い参照データ、few-shot 例はなるべく前に置き、ユーザー入力、時刻、trace id、外部取得データ、セッション固有値は後ろに寄せます。prompt_cache_key は hit 率を助けることがありますが、乱れた前方部分を補う魔法ではありません。
Claude では、tools、system、messages の階層と cache breakpoint が重要です。前の階層が変わると、その後のキャッシュも壊れやすくなります。安定した tools と system を早い層に置き、変わる user content は後ろに置く。これだけで write が減り、read が増えます。
実装では prefix hash を記録してください。system prompt の版、tools の版、endpoint、model、region、cache policy を一緒に残すと、hit rate が落ちた理由を追えます。hash が変わっているなら、請求が増えた原因は料金表ではなくリクエスト形状かもしれません。
ログを見てから節約を信じる
OpenAI では usage.prompt_tokens_details.cached_tokens が最初の確認項目です。ここが 0 のリクエストを cached input として見積もるべきではありません。最低限、model、endpoint、request_id、prefix_hash、input tokens、output tokens、prompt_cache_key の有無を保存します。
Claude では cache_creation_input_tokens、cache_read_input_tokens、input_tokens を同時に見ます。creation が大きいなら書き込みコストが発生しています。read が大きいならキャッシュを読めています。input は新規入力や未キャッシュ部分です。3 つを分けて初めて、hit、write、miss を分類できます。
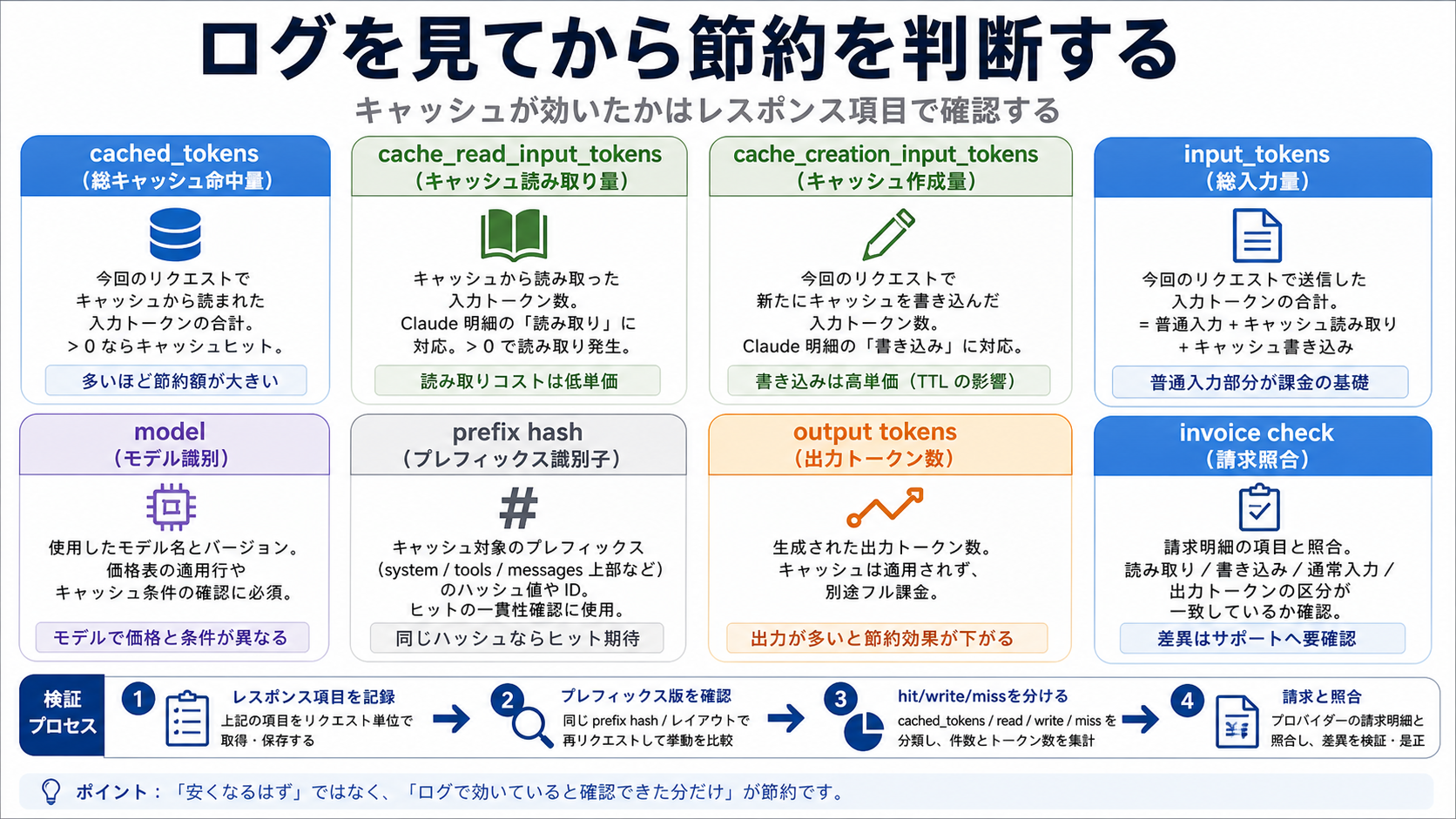
ログ表には provider、model、request_id、prefix_hash、cache policy、cached/read/creation/input/output tokens、retry、latency、invoice period を入れます。1 日分の小さなサンプルでも、設計変更の価値はかなり見えます。
料金修飾項は別に扱う
Batch、Scale Tier、長コンテキスト、データレジデンシー、クラウド市場、企業契約は、基本計算とは別に扱います。Claude の 1 時間 TTL は読み取り窓を広げますが write が高くなります。OpenAI の拡張保持や対象モデルも更新されます。基本の損益分岐表にこれらを混ぜると、説明は短くなりますが予算は危険になります。
rate limit も同じではありません。OpenAI の cached tokens は TPM に数えられるという扱いがあります。Claude の一部ドキュメントでは cache hit が rate limit 利用に与える効果が別に説明されます。コスト表と容量表は分けて持つべきです。
OpenAI を先に試す場面
安定した長い前置きがあり、複数 cache segment を細かく管理する必要がないなら、OpenAI を先に試す価値があります。問い合わせ bot、固定ポリシー QA、同じ schema の分析、毎回同じ tools を持つ agent、長い system prompt を持つ API などです。変更は小さく、ログで確認しやすいからです。
ただし、低い hit rate、短い入力、頻繁な prefix 変更、長い output は節約を小さくします。OpenAI を選ぶ理由は「自動だから」ではなく、「自分の prefix が実際に cached input になっているから」であるべきです。
Claude を先に試す場面
Claude は、cache boundary と TTL を設計できるチームに向いています。長い tools、固定 system、コードベース要約、複数 step の agent、同じ文脈を事前に温めて何度も使う処理では、明示的な制御が効きます。どこを 5 分で再利用し、どこを 1 時間で保つかを設計できます。
一方で、動的データが早い階層に混ざる、TTL が切れる、read が少ない、creation を見ていない、という状態ではコストは読みにくくなります。Claude は強い道具ですが、ログなしに安い道具ではありません。
実装チェックリスト
- 安定した system/tools/context を前に置く。
- 動的な user content、時刻、trace id は後ろに置く。
- prefix hash と prompt version を保存する。
- OpenAI は
cached_tokens、Claude は creation/read/input を保存する。 - 最初の request と後続 hit を同じテストで比較する。
- output tokens を必ず別に計算する。
- 価格表、model、endpoint、TTL、cloud route が変わったら再計算する。
OpenAI、Claude、Gemini の全体的な API コスト比較を見たい場合は、複数プロバイダーの API コスト比較 が近い入口です。prompt caching の請求構造は、モデル品質、推論能力、tool use の比較とは分けて読んでください。
よくある質問
OpenAI の prompt caching は今も 50% 割引ですか?
普遍的な説明としては使えません。50% は古い GPT-4o / o1 時代の説明でよく見かけます。2026-05-19 に確認した標準 GPT-5.5、GPT-5.4、GPT-5.4 mini の行では cached input は通常 input の 10 分の 1 でした。必ず現在の料金表を確認してください。
Claude の write cost はなぜ必要ですか?
Claude はキャッシュを作る入力と、キャッシュを読む入力を分けて課金します。write は初回または更新時のコストで、read は後続の hit 時の安いコストです。明示的に制御できる代わりに、初回の負担を損益分岐に入れる必要があります。
output tokens も安くなりますか?
なりません。Prompt caching は繰り返し入力のコストを下げる仕組みです。出力が長いタスクでは、入力側の節約率より総額の節約率は小さくなります。
1024 tokens 未満でもキャッシュされますか?
OpenAI は prompt caching の対象として 1024 tokens 以上を示しています。Claude はモデルごとに最小 token 数が異なります。閾値はモデルと時期で変わるため、一般論ではなく現在のドキュメントで確認する必要があります。
Claude は手動キャッシュだけですか?
いいえ。現在の Claude ドキュメントには自動の top-level cache control と明示的な block-level cache control の両方があります。ただし、どの層が安定しているかを理解する設計は依然として重要です。
予測より請求が高いときは何を見ますか?
prefix hash、model、endpoint、TTL、miss、Claude の write 回数、OpenAI の cached tokens、output tokens、価格修飾項を順に見ます。合計 token だけを見ると原因が分かりません。
キャッシュ料金だけでプロバイダーを変えるべきですか?
実測 hit rate が高く、繰り返し回数が多く、output が支配的でなく、ログで節約を確認できる場合だけです。先に layout とログを整え、その後に OpenAI と Claude の実コストを比較してください。