2026年3月29日時点で、gpt-image-1-mini examples を探しているなら、最初に取るべき route はかなり明確です。one-shot generation は Images API、direct edit も Images API、Responses は multi-turn image workflow が本当に必要になったときだけ。 この順番こそが current docs から素直に読める判断ですが、exact-query の SERP はそこをあまり整理してくれません。
この順番には理由があります。OpenAI の current image generation guide は、1回の prompt で1回の生成または編集だけが必要なら Image API が向いていると説明しています。一方で Responses API は conversation や multi-step flow に image generation を組み込みたいときの route です。さらに gpt-image-1-mini の model page では mini が cost-efficient version of GPT Image 1 と位置づけられていて、best-experience default だとは書かれていません。
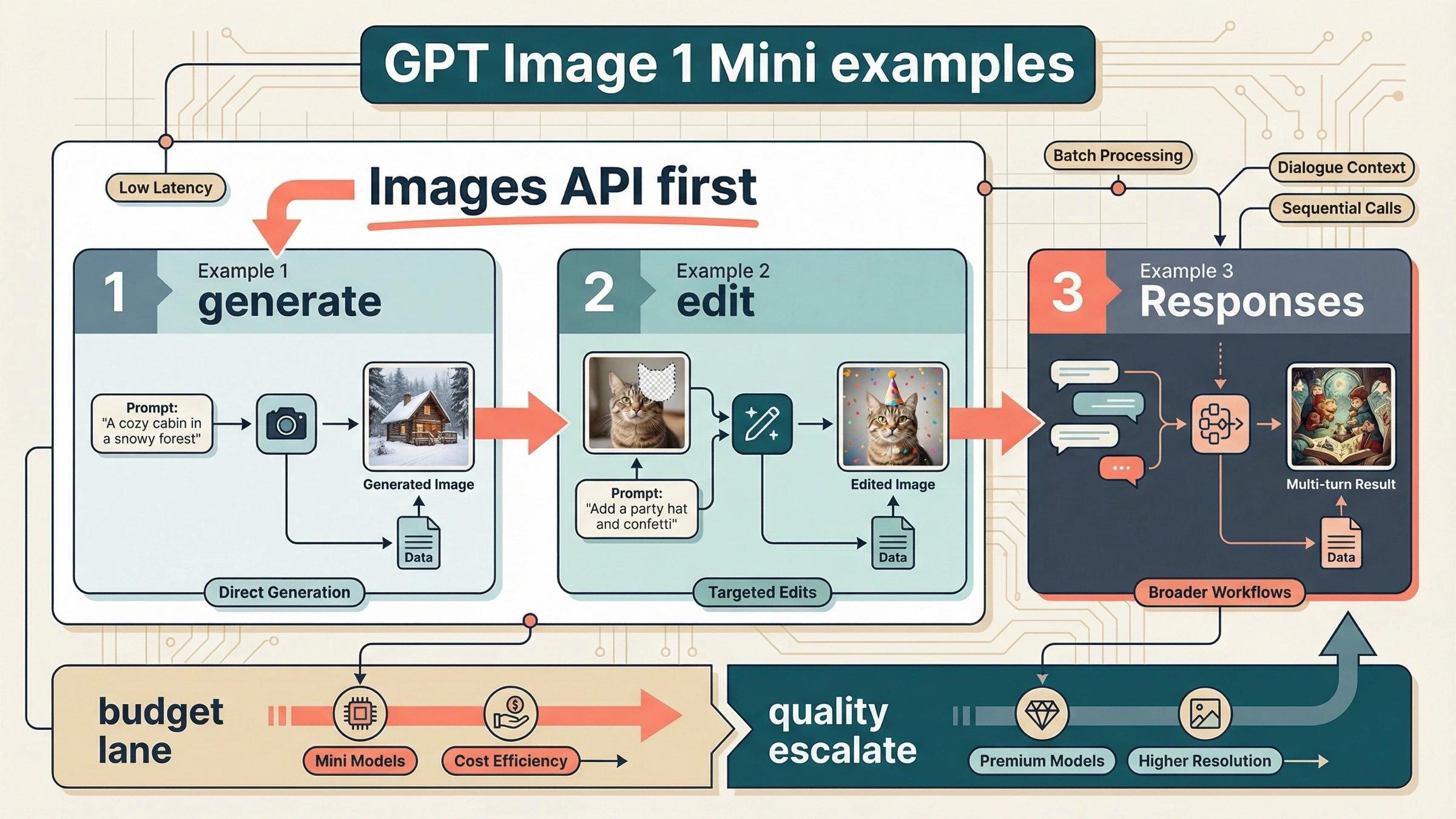
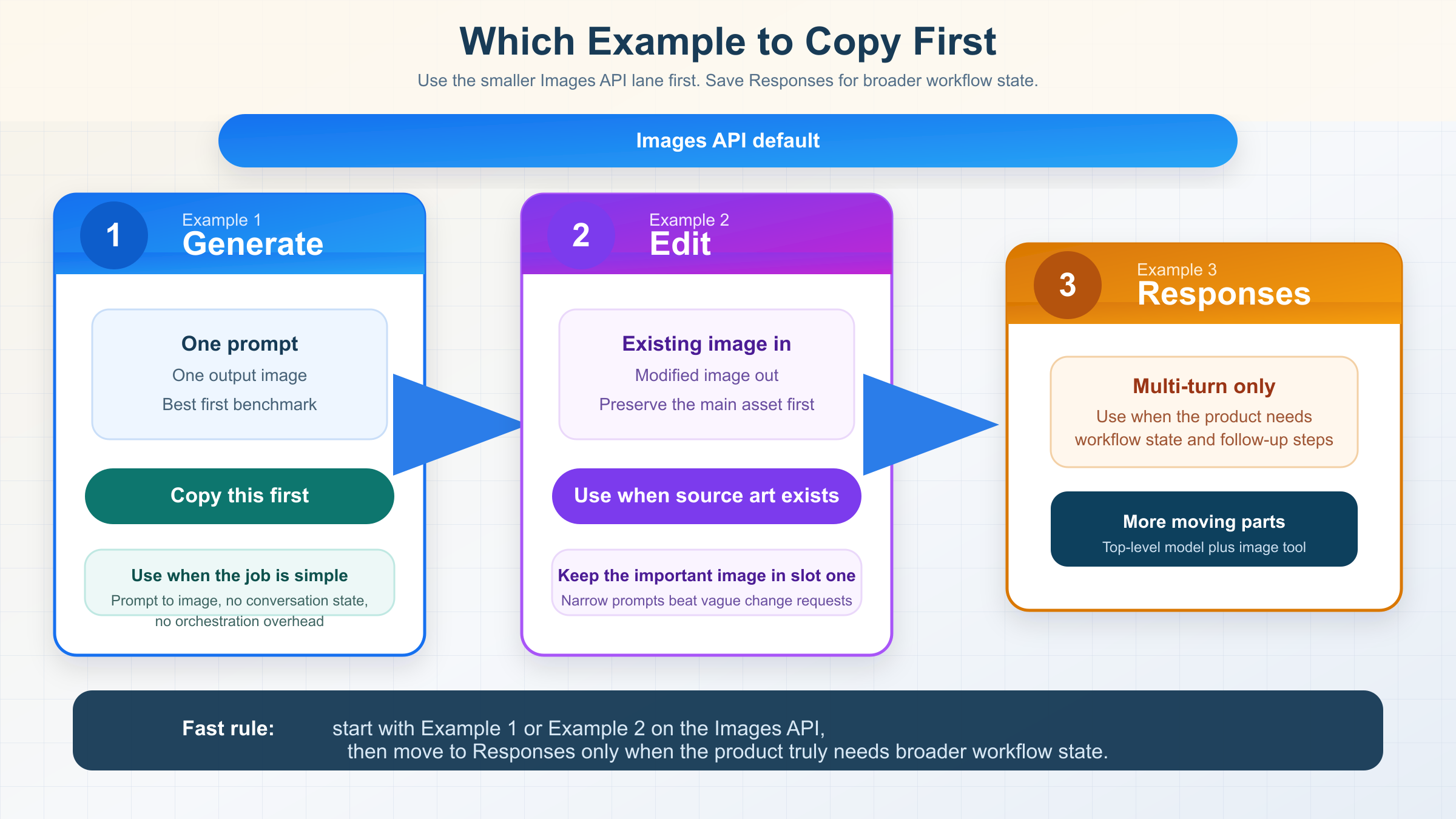
だから、このページで一番大事なのは prompt gallery を増やすことではなく、どの example を最初にコピーすべきか を決めることです。prompt-to-image だけなら Example 1。既存画像を編集したいなら Example 2。画像を複数ターンで育てる product なら Example 3。この順番で十分です。
要点まとめ
- one-shot generation と direct edit は、まず Images API から始めるのが安全です。
- Responses は multi-turn workflow や conversation state が本当に必要なときだけ使います。
- cost first なら mini、quality first なら GPT Image 1.5 を先にコピーする判断が基本です。
最初にコピーすべき gpt-image-1-mini の例 3つ
この query の page one には、model directory、example gallery、gateway playground が混ざっています。どれも無意味ではありませんが、共通する弱点があります。最初の一手を決める判断 をほとんど与えてくれないことです。下の表が、その不足を最短で埋めます。
| したいこと | 最初にコピーする example | API surface | ここから始める理由 |
|---|---|---|---|
| 1つの prompt で 1枚の画像を生成する | Example 1 | Images API | もっとも小さい official route で、first success を作りやすい |
| 既存画像を直接編集する | Example 2 | Images API | current docs でも one-shot edit はこの route が自然で、mini 特有の fidelity rule もここで効く |
| 会話の中で何度も画像を作り直す | Example 3 | Responses API | workflow state や follow-up turns が必要なときだけ、大きい抽象化が意味を持つ |
追加で覚えておくと useful なのは、current tool guide が image prompt に draw や edit のような direct verb を勧めていることです。小さな差ですが、これを説明しない example page は「動く snippet」より「見た目だけ親切」になりがちです。
もっと broad に OpenAI image API example を探しているなら、次は OpenAI image generation API example の方が向いています。このページは deliberately narrow で、mini の start-here decision だけに絞っています。
Example 1: Images API で1回生成する
最初に走らせる mini example は、たいてい一番 boring なものです。1つの prompt を送り、base64 の image bytes を受け取り、保存する。conversation state も、tool orchestration もありません。だからこそ failure surface が小さく、mini が今の workload に合うかどうかを一番素直に見られます。
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.generate({ model: "gpt-image-1-mini", prompt: "Draw a clean editorial illustration of a robot street photographer in bright morning light.", size: "1024x1024", quality: "medium", output_format: "jpeg", output_compression: 80, }); const imageBase64 = result.data[0].b64_json; fs.writeFileSync( "gpt-image-1-mini-generate.jpg", Buffer.from(imageBase64, "base64") );
Python 版も同じ形です。
pythonfrom openai import OpenAI import base64 client = OpenAI() result = client.images.generate( model="gpt-image-1-mini", prompt="Draw a clean editorial illustration of a robot street photographer in bright morning light.", size="1024x1024", quality="medium", output_format="jpeg", output_compression=80, ) image_base64 = result.data[0].b64_json with open("gpt-image-1-mini-generate.jpg", "wb") as f: f.write(base64.b64decode(image_base64))
raw cURL は次の形になります。
bashcurl https://api.openai.com/v1/images/generations \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-image-1-mini", "prompt": "Draw a clean editorial illustration of a robot street photographer in bright morning light.", "size": "1024x1024", "quality": "medium", "output_format": "jpeg", "output_compression": 80 }' \ | jq -r '.data[0].b64_json' \ | base64 --decode > gpt-image-1-mini-generate.jpg
この example を first default に置くべき理由は二つあります。第一に、OpenAI の current route rule と一致していること。第二に、mini が本当に今の workload に十分かどうかを、最も早く判断できることです。OpenAI は current guide で GPT Image 1.5 for the best experience を推していますが、もしあなたの優先順位が lower cost なら、まず mini を最短 route で benchmark するのが自然です。
最初の request は intentionally boring で構いません。square image、quality: "medium"、そして draw から始まる prompt。保存まで確認してから aspect ratio、transparency、streaming のような追加要素に進めば十分です。
| Parameter | Safe first value | 変更するタイミング |
|---|---|---|
size | 1024x1024 | 実際に別の縦横比が必要だと分かったとき |
quality | medium | low では足りない、または high が本当に回収できると判断できたとき |
output_format | jpeg | downstream 側で別の file type が必要なとき |
output_compression | 80 | file size か圧縮 artifact が問題になったとき |
current mini model page では 1024x1024 の price ladder が low $0.005、medium $0.011、high $0.036 です。ここまで差があるなら、high を初手にする理由は「安心そう」だけでは足りません。cheap benchmark なら medium から始める方が rational です。
Example 2: input_fidelity を使った直接編集
すでに source image があるなら、ここでも Images API に残る方が自然です。current docs は one-shot edit を Responses の必須ケースとして扱っていません。mini edit の問題は “Responses でないとできないか” ではなく、どうすれば preserving rule をちゃんと使えるか です。
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.edit({ model: "gpt-image-1-mini", image: [ fs.createReadStream("product-photo.jpg"), fs.createReadStream("brand-logo.png"), ], prompt: "Edit the first image by placing the logo from the second image onto the coffee cup label. Preserve the cup shape, lighting, camera angle, and table texture.", input_fidelity: "high", size: "1024x1024", quality: "medium", }); const imageBase64 = result.data[0].b64_json; fs.writeFileSync( "product-photo-edited.png", Buffer.from(imageBase64, "base64") );
この section で重要なのは、OpenAI の current input fidelity docs が、gpt-image-1 と gpt-image-1-mini では最初の input image がより強く preserve される と書いていることです。顔、商品、logo のように最も守りたい asset があるなら、それを slot one に置くべきです。
この detail が、wrapper pages で最も抜け落ちやすい部分です。「edit ができる」と書くだけでは不十分で、何が結果を変えるか まで書いて初めて useful になります。mini edit では、次の三つを覚えておけばかなり違います。
- いちばん大事な asset を first image に置く。
input_fidelity: "high"は detail preservation が本当に重要な場合だけ使う。- prompt は “何を変えるか” だけでなく “何を維持するか” を明示する。
mask を使う場合も、これは still prompt-driven edit であって、Photoshop 的な deterministic patching ではありません。guide が言うように image と mask は size と format を揃え、mask には alpha channel が必要です。control は増えますが、pixel-perfect surgery を期待しすぎるべきではありません。
SDK から raw HTTP に移ったとたん edit request が壊れるケースも多いです。理由は大抵 simple で、multipart form-data を正しく送っていないからです。SDK が隠していた upload mechanics を、自分でちゃんと再現しないといけません。
edit 自体をもっと深く見たいなら、次は GPT Image 1 Mini edit が向いています。ここでは example choice にとどめています。
Example 3: Responses を使うのは multi-turn workflow のときだけ
この example は “より新しいから先に使う” ものではありません。product が本当に会話状態や follow-up refinement を必要とする場合だけ、初めて値打ちが出ます。
理由ははっきりしています。Responses API では top-level の model に gpt-image-1-mini を入れません。current docs が説明している通り、hosted image_generation tool の下で使われるのは GPT Image family ですが、model field 自体は gpt-4.1 や gpt-5 のような text-capable mainline model です。
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const response = await client.responses.create({ model: "gpt-5", input: "Generate an image of a gray tabby cat reading a newspaper at a cafe table.", tools: [{ type: "image_generation" }], }); const firstImage = response.output .filter((item) => item.type === "image_generation_call") .map((item) => item.result)[0]; fs.writeFileSync("cat-cafe.png", Buffer.from(firstImage, "base64")); const followUp = await client.responses.create({ model: "gpt-5", previous_response_id: response.id, input: "Now make it look like a realistic magazine photo.", tools: [{ type: "image_generation" }], }); const secondImage = followUp.output .filter((item) => item.type === "image_generation_call") .map((item) => item.result)[0]; fs.writeFileSync("cat-cafe-realistic.png", Buffer.from(secondImage, "base64"));
Responses に進むべきなのは、画像生成が single request ではなく larger assistant workflow の一部になったときです。current docs も Responses の価値として、multi-turn editing と、bytes 以外の image input handling を挙げています。逆に言えば、simple generation や direct edit だけなら、最初からこの抽象化を背負う理由はありません。
ここでありがちな mistake は、「Responses の方が modern に見えるから correct default だ」と思ってしまうことです。OpenAI の docs はそこをもっと厳密に分けています。正しい route は “新しそうな方” ではなく、job に合っている方 です。
examples を疑う前に先に済ませる setup checks
mini は cheap lane ですが、free lane ではありません。2026年3月29日時点 で current mini model page は、1024x1024 の output 価格を $0.005 / $0.011 / $0.036 とし、さらに Free not supported、Tier 1 を 100,000 TPM と 5 IPM から始まると書いています。
このキーワードで本当に多いのは、“example が悪い” のではなく account state がまだ整っていない ケースです。OpenAI の current model availability article は、gpt-image-1 と gpt-image-1-mini が API users の tiers 1 through 5 で利用可能だとしつつ、一部 access が organization verification に依存すると説明しています。さらに organization verification article は、verification の反映に up to 30 minutes かかることと、new API key が lingering error を消すことがあると補足しています。
つまり debug order は次の通りです。
- API key が正しい project と organization に属しているか確認する。
- current tier が mini image access を含んでいるか確認する。
- access error が続くなら organization verification を確認する。
- verification を終えた直後なら 30 分待つ。
- working example を書き換える前に新しい API key を発行する。
もし本当の blocker が example ではなく access state なら、次に読むべきは OpenAI image generation API verification です。
よくある gpt-image-1-mini example failure をどう切り分けるか
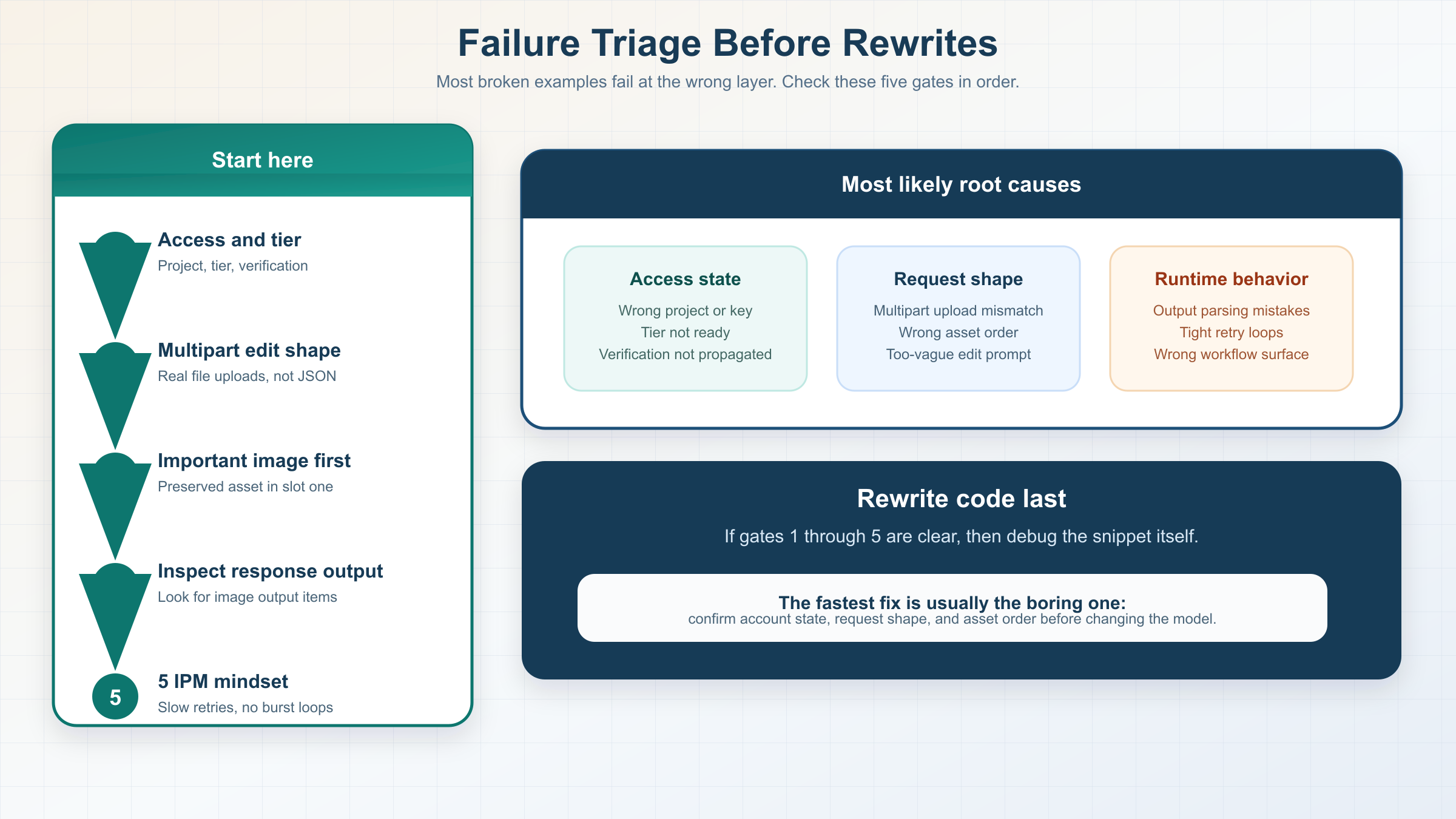
copied example が失敗するとき、root cause は SERP の雰囲気よりずっと mundane です。間違った surface、間違った request shape、あるいは遅すぎる account-state check。この三つでほとんど説明できます。
| 症状 | ありがちな原因 | 最初に確認すること |
|---|---|---|
| generation example が access / availability error を返す | project、tier、verification が未準備 | org と tier と verification state、そして key を作ったタイミング |
| edit example は動くが reference asset を無視する | 重要な image が first ではない、または prompt が曖昧 | preserve したい image を first にし、prompt を “change + keep” に書き直す |
| SDK を外したら edit request が壊れた | multipart file upload を正しく送れていない | multipart form-data と real file parts を再確認する |
| Responses example が text だけ返して image がない | response parsing が違う、または workflow がまだ複雑すぎる | response.output の image_generation_call を確認し、本当に Responses が必要か見直す |
| rate limit にすぐ当たる | image endpoint の cadence を text endpoint と同じ感覚で叩いている | current IPM を見直し、burst retry を止める |
最後の行は特に重要です。Tier 1 の 5 IPM は、chat や text endpoint に慣れた開発者には驚くほど小さい数字です。同じ example を短時間に何度も回すと、ランダム failure に見えても、実際には minute-level throughput が原因ということが普通にあります。
もし Example 1 は通るのに Example 2 が通らないなら、最初に疑うべきは mini 自体ではなく asset order、prompt scope、multipart shape です。Images API の例は通るのに Responses だけ不安定なら、architecture complexity を早く持ち込みすぎた可能性が高いです。
gpt-image-1-mini で十分な場面と、GPT Image 1.5 の例を先にコピーした方が安全な場面

exact examples pages が一番曖昧にしがちなのは、ここです。コードが動くこと と そのモデル選択が正しいこと は同じではありません。
OpenAI の current image guide は gpt-image-1.5 が latest and most advanced GPT Image model だとし、best experience を求めるなら GPT Image 1.5 を勧めています。そのうえで gpt-image-1-mini は、より cost-effective で、image quality が最優先ではない場合の選択肢だと説明しています。
だから honest rule はシンプルです。
- cost が first constraint なら mini examples から始める。
- output quality、harder edits、retry cost が重要なら GPT Image 1.5 の同じ route を先にコピーする。
mini が向くのは、internal concepts、low-stakes variants、cheap prompt benchmarking、volume-first batch generation のような仕事です。逆に GPT Image 1.5 が safer default になるのは、higher-value output、edit failure の代償が大きい仕事、品質そのものがコストに直結する仕事です。
さらに current API pricing page は Batch API が input と output を 50% 割引する と書いています。これは mini の優位を消しはしませんが、asynchronous job では “単価だけで即決する” 危険を増やします。結局のところ、最も安い model が最も安い workflow になるとは限りません。
価格だけを深掘りしたいなら GPT Image 1 Mini pricing、より広い qualitative judgment が必要なら GPT Image 1 Mini review が次に向いています。
wrapper page が今も広げている誤解
一つ目は、wrong abstraction をコピーしてしまうこと。1つの prompt と1枚の output image だけが欲しいのに、Responses から始める必要はありません。current docs はそこをまだはっきり分けています。
二つ目は、Responses の model field に wrong model を入れること。hosted image_generation tool を使うなら、top-level model は gpt-5 や gpt-4.1 のような mainline model であって、gpt-image-1-mini ではありません。
三つ目は、mini edit の first-image rule を忘れること。顔、商品、logo のように最も守りたいものを first input に置かないと、結果の読みがズレます。
四つ目は、“最安 = best default” と考えること。OpenAI が mini に与えている role は budget lane であって、quality-first default ではありません。
五つ目は、account state より先に code を疑うこと。tier、verification、propagation window がずれていれば、正しい example でも failure に見えます。
六つ目は、gateway product の vocabulary をそのまま official API に持ち込むこと。third-party page の abstraction は、その product の中では有効でも、OpenAI-native code と一対一対応するとは限りません。
結論
gpt-image-1-mini examples を探しているなら、今コピーする価値が高いのはこの三つです。one-shot generation には Images API。direct edit にも Images API。そして multi-turn image workflow が必要になったときだけ Responses。
最後に残すべき判断は一つだけです。mini は cheaper lane であって universal lane ではない。 examples が動いて quality も足りるなら mini に残ればいいし、retry や cleanup が増え始めたら、同じ route を GPT Image 1.5 でコピーし直す方がむしろ安い判断になります。