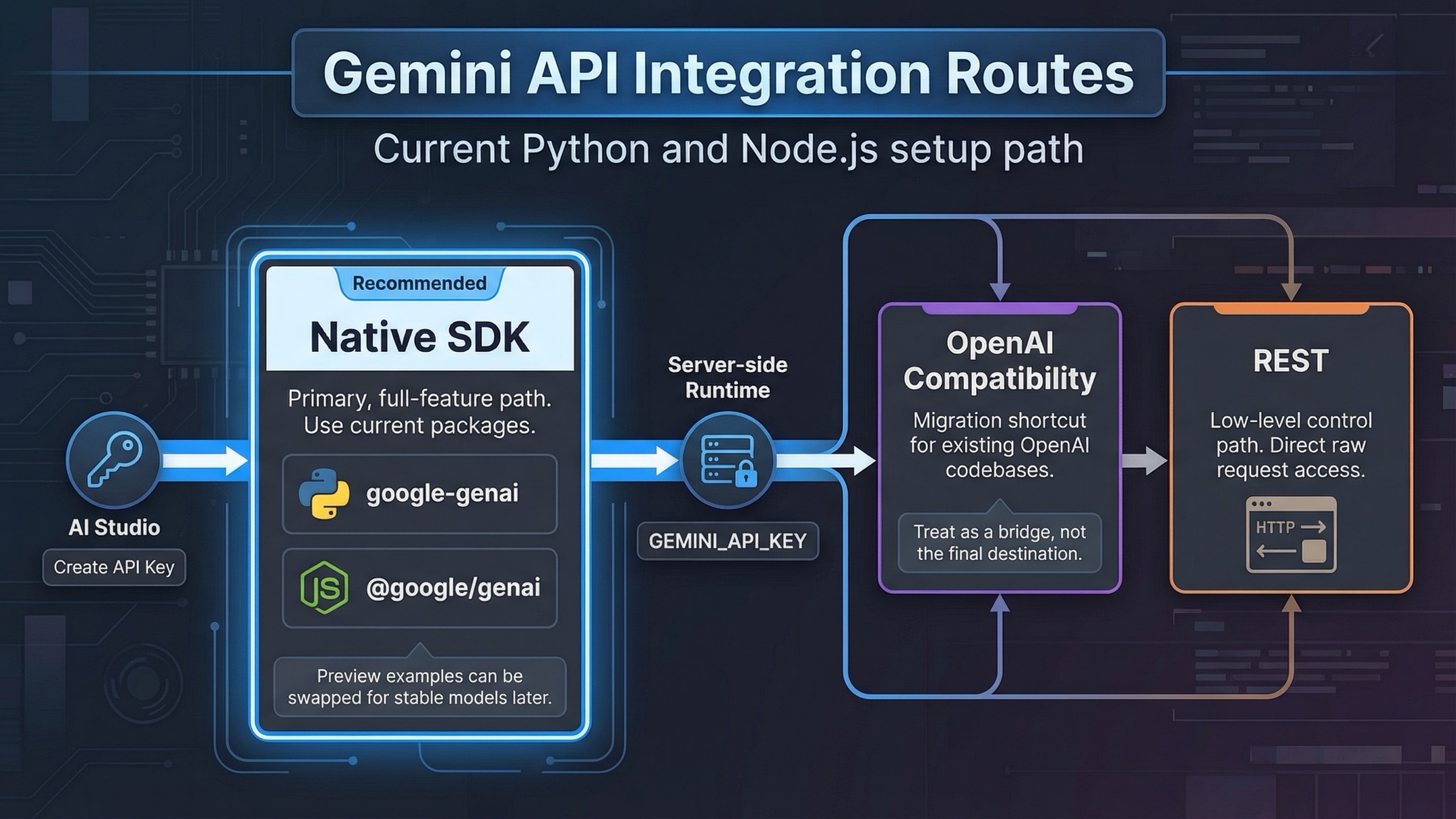
今から新しく Gemini API を組み込むなら、まずはネイティブの Google GenAI SDK を使い、GEMINI_API_KEY はサーバー側に置き、最初の 1 リクエストを確実に通してから streaming、tools、files を足していくのがいちばん安全です。OpenAI 互換レイヤーを先に使うべきなのは、すでに OpenAI 形状のコードベースがあって短期間で移行したいときだけです。現在の quickstart、migration guide、example repo はすでに google-genai(Python)と @google/genai(JavaScript)を中心に構成されています。
このガイドがまずやるべき仕事は、初日の実装ルートを正しく固定することです。正しい SDK、秘密情報の境界、最初の成功リクエストを押さえたうえで、次に streaming、structured output、function calling、Files API、billing と rate limits を順に足していく。その順番で進めれば、古いパッケージ名、古い model ID、間違った運用境界に引きずられて余計な手戻りを作らずに済みます。
なお、Google の現行サンプルは今でも gemini-3-flash-preview のような preview モデル ID を多く使っています。そのため以下のコード例でも同じ ID を残しています。ただし本番運用の原則は別です。models guide でも、適切な stable モデルがあるなら多くの production アプリは stable model ID を優先すべきだと案内されています。つまり、まずはサンプル通りに動かし、その後で gemini-2.5-flash のような安定版に切り替えるのが実務的です。
要点まとめ
- 新規統合では Python は
google-genai、JavaScript は@google/genaiを使うのが現在の標準です。Google の migration guide でも旧 Gemini ライブラリからの移行が推奨されています。 - キーは Google AI Studio で作成し、
GEMINI_API_KEYに保存して、サーバー、worker、API route、server action などのバックエンド面から呼び出します。 - 最初はネイティブ SDK で 1 回成功することを確認し、その次に streaming、その次に structured output や function calling を足していく順番が一番崩れにくいです。
- 既存の OpenAI 風コードを素早く移したいなら OpenAI compatibility は有効です。ただし Files API のような Gemini 固有機能を本格的に使うなら、長期的にはネイティブ SDK の方が自然です。
- リクエスト全体が 100 MB を超える場合、あるいは PDF が 50 MB を超える場合は Files API に切り替えます。公式では保存期間 48 時間、プロジェクトごとに 20 GB、ファイルごとに 2 GB と案内されています。
- billing では 400 / 500 エラーは課金されない一方で quota は消費すると明記されています。rate limits でも、制限は tier によって変わるため AI Studio で実値を確認すべきだとされています。
| ルート | 向いているケース | 強み | 主なトレードオフ |
|---|---|---|---|
| ネイティブ Google GenAI SDK | 新規の Python / Node.js アプリ | 現行パッケージ、現行ドキュメント、streaming・structured output・files・tools への直接アクセス | OpenAI 風の抽象ではなく Gemini ネイティブのクライアント形状を覚える必要がある |
| OpenAI 互換 | 既存の OpenAI 風コードベース | base URL、API key、model name を変えるだけで移行しやすい | Gemini 固有機能では抽象の損失が出やすい |
| 生 REST | 独自言語、依存制約、低レベルデバッグ | SDK に依存せずリクエストを細かく制御できる | boilerplate と手動処理が増える |
コスト面を先に整理したい場合は、ローカライズ済みの Gemini API Token料金ガイド が次の読み先です。運用上のエラーに入っているなら、先に Gemini API エラートラブルシューティングガイド を読む方が早いです。
最初の Gemini API リクエストを正しく作る
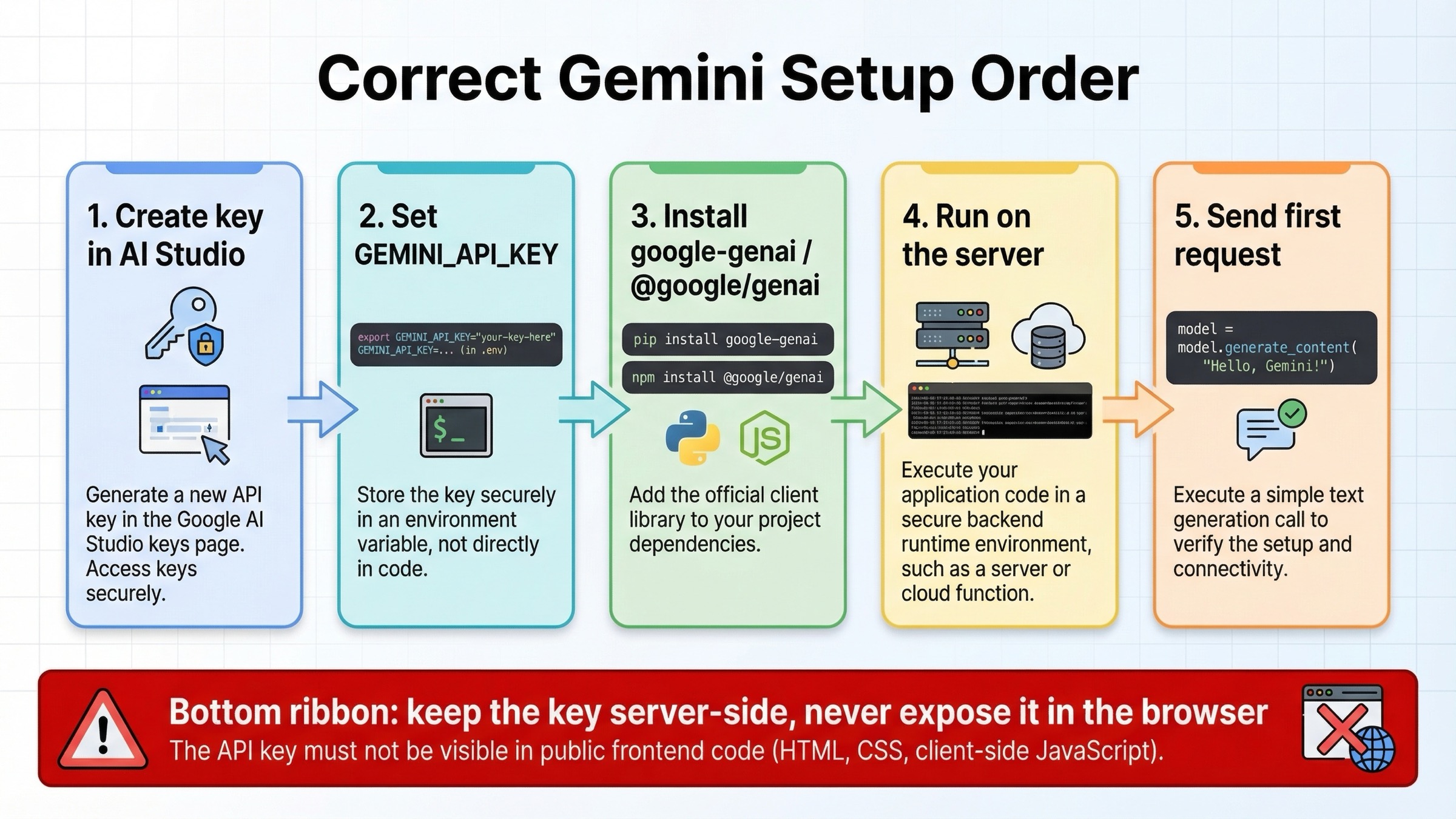
正しい開始地点は IDE ではなく AI Studio です。Gemini API のキーは現在 Google AI Studio で作成・管理され、キーは独立した文字列というより Google Cloud project に属する資格情報として扱われます。新規ユーザーでは AI Studio がデフォルトの project と key を自動で用意することが多いため、初回テストはすぐ通ります。しかしその便利さのせいで、project の所有、billing、チーム権限を後回しにしがちです。
実際にコードを書く前に、まず一つだけ絶対に固定しておくべきことがあります。GEMINI_API_KEY はサーバー側に置くことです。バックエンドサービスなら環境変数に入れる。Web アプリなら API route、server route、edge backend、worker などから Gemini を呼ぶ。公開フロントエンドに永続キーを置くのは避けるべきです。ここで境界を間違えると、SDK の選択以前の問題で integration 全体が不安定になります。
現在の公式 quickstart に沿ったインストールは次の通りです。
bashpip install -U google-genai npm install @google/genai
そのうえでキーを設定します。
bashexport GEMINI_API_KEY="your_real_key_here"
最初のリクエストは意図的に単純であるべきです。function calling、grounding、multimodal files から始める必要はありません。初回の役割は、キー、環境、runtime、ネットワーク経路が正常かどうかを確認することだけです。
pythonfrom google import genai client = genai.Client() response = client.models.generate_content( model="gemini-3-flash-preview", contents="Explain the purpose of an API integration tutorial in one sentence." ) print(response.text)
javascriptimport { GoogleGenAI } from "@google/genai"; const ai = new GoogleGenAI({}); const response = await ai.models.generateContent({ model: "gemini-3-flash-preview", contents: "Explain the purpose of an API integration tutorial in one sentence.", }); console.log(response.text);
ここで見るべきなのは prompt の巧さではなく client shape です。新しい SDK は models、chats、files などを一つのクライアントに集約しています。旧チュートリアルが今読むと分かりにくいのは、単に情報が古いだけではなく、Google がすでに中心ルートから外した構造を教えているからです。
2026年でも通用する Python 統合例
Python は今でも Gemini の入り口として最も扱いやすい言語の一つです。基本リクエストだけでも十分短いですが、その次に覚える価値が最も高いのは streaming です。Google の text-generation guide でも generate_content_stream が示されており、これは CLI、社内ツール、Web UI、対話的な運用画面で体感速度を大きく変えます。
pythonfrom google import genai client = genai.Client() stream = client.models.generate_content_stream( model="gemini-3-flash-preview", contents="Write three short tips for migrating from a legacy LLM SDK." ) for chunk in stream: print(chunk.text, end="")
streaming が重要なのは、Gemini のユースケースが必ずしもチャットアプリだけではないからです。レスポンスを少しずつ返せるだけで、ユーザー体験も運用の印象も大きく改善します。最初の hello world のあとに何を学ぶべきかと聞かれたら、まず streaming と答えてよい場面が多いです。
二つ目に早く覚えるべきなのは structured output です。structured output guide では Gemini が JSON Schema に従えることが説明されており、Python SDK では Pydantic とも自然につながります。実運用では「文章を書かせる」より「後続システムが処理できる構造を返させる」方がはるかに重要です。
pythonfrom google import genai from google.genai import types from pydantic import BaseModel class IntegrationTicket(BaseModel): language: str task: str priority: str client = genai.Client() response = client.models.generate_content( model="gemini-3-flash-preview", contents="Python app, needs JSON output, shipping next week.", config=types.GenerateContentConfig( response_mime_type="application/json", response_schema=IntegrationTicket, ), ) print(response.text)
schema を与えてしまえば、prompt の役割は「JSON で返して」と祈ることではなく、必要な意味を正確に抽出することへ移ります。これは demo と production integration の違いとしてかなり大きいです。
Python は function calling でも強みがあります。公式 guide では、type hints と docstring を持つ Python 関数をそのまま tool として渡し、宣言・実行・レスポンスの往復を SDK が処理できると説明されています。社内オペレーションツールや軽量 agent 的な用途では、これがかなり高速に効きます。
pythonfrom google import genai from google.genai import types def get_current_temperature(location: str) -> dict: """Gets the current temperature for a given location.""" return {"temperature": 25, "unit": "Celsius"} client = genai.Client() response = client.models.generate_content( model="gemini-3-flash-preview", contents="What's the temperature in Boston?", config=types.GenerateContentConfig(tools=[get_current_temperature]), ) print(response.text)
ただし、この便利さは Python が実行環境の中心であるときに最も輝きます。複数言語で共有する tool layer や厳格な監査境界が必要な場合は、もう少し明示的なオーケストレーションの方が長期的には扱いやすいこともあります。
JavaScript と Node.js の統合例
Node.js 側も client shape はほぼ同じですが、実務で一番多い失敗は実行境界の置き方です。JavaScript 開発者はフロントエンドとバックエンドを近い場所で触れるため、気づかないうちに key、SDK、ページコードを混ぜてしまいがちです。現在の @google/genai 自体は問題ありません。大切なのは、それをどこで実行するかです。Node プロセス、API route、server action、edge backend など、サーバー側の面に置くべきです。
最初の JavaScript 呼び出しは次の形です。
javascriptimport { GoogleGenAI } from "@google/genai"; const ai = new GoogleGenAI({}); const response = await ai.models.generateContent({ model: "gemini-3-flash-preview", contents: "Give me a one-line summary of why current SDK names matter.", }); console.log(response.text);
次の一歩はやはり streaming です。
javascriptimport { GoogleGenAI } from "@google/genai"; const ai = new GoogleGenAI({}); const stream = await ai.models.generateContentStream({ model: "gemini-3-flash-preview", contents: "List three practical steps for hardening an API integration.", }); for await (const chunk of stream) { process.stdout.write(chunk.text ?? ""); }
このパターンは Next.js、Express、Nest などのバックエンドで特に相性が良いです。キーはサーバーに置いたまま、クライアントには chunk 単位でレスポンスを返せるため、UX を大きく改善できます。UI を速く見せながら secret boundary を崩さない、という意味で最も実務的な次の一手です。
JavaScript でも structured output や function calling は使えますが、Python よりやや明示的です。Google の例では Zod や functionCallingConfig などを使い、開発者が request shape をより直接コントロールします。TypeScript 中心のチームにとっては、これはむしろ利点です。既存の型、schema、サービス境界に自然に合わせやすいからです。
また、費用の見積もりを後回しにしないことも重要です。Google の token guide は count-tokens 系メソッドや usage metadata を使うことを勧めています。JavaScript 製品では system prompt、履歴、RAG コンテキスト、tool logs が積み上がりやすいため、早い段階で測定を組み込む方が安全です。
OpenAI 互換レイヤーを使うべき場面
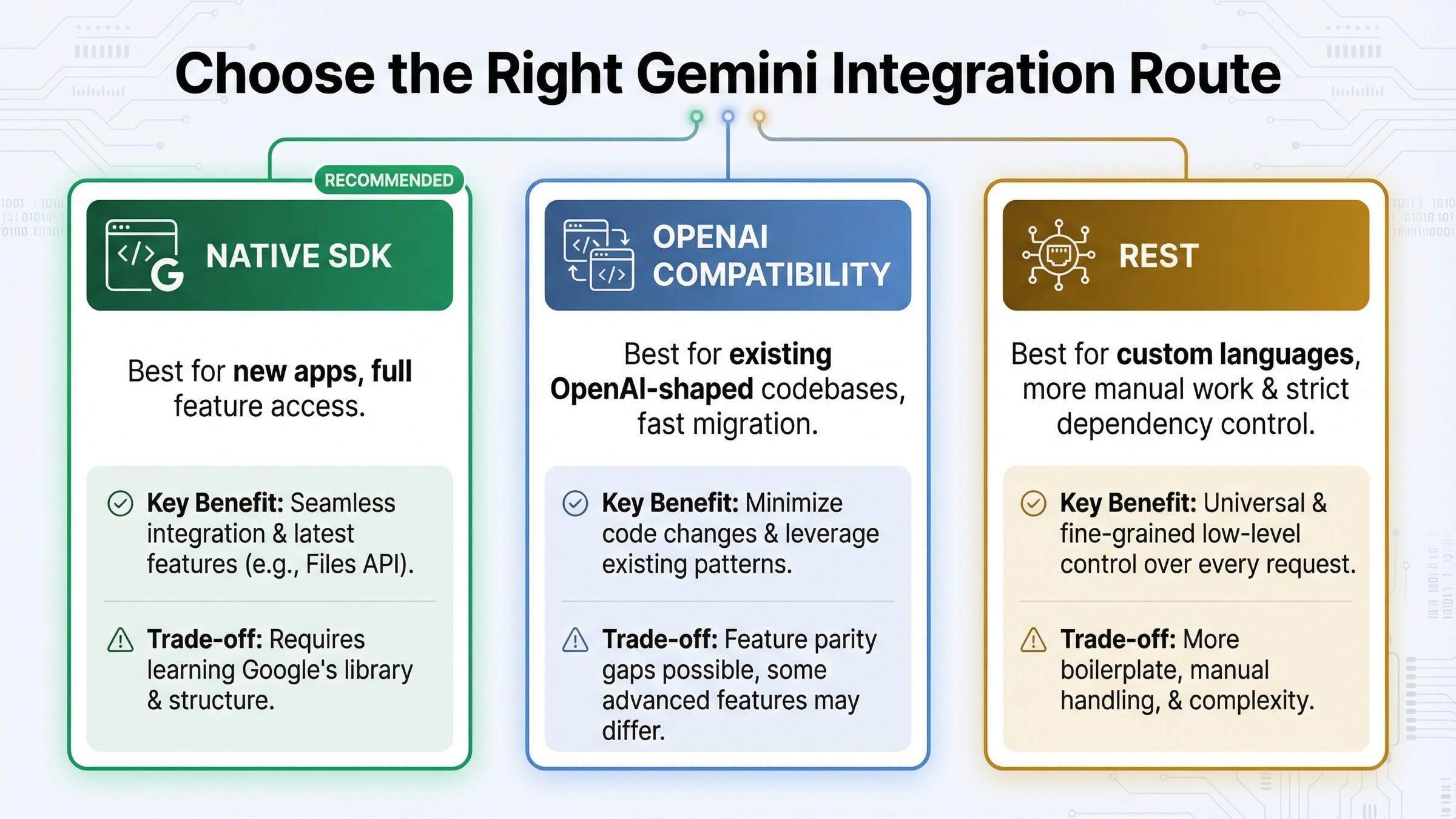
OpenAI 互換レイヤーは実在する有用な移行手段ですが、万能の正解ではありません。Google の互換ガイドを見ると、基本的には base URL、API key、model name を差し替えるだけで既存の OpenAI クライアントから Gemini を試せます。すでに OpenAI messages 形式に寄せた内部サービスやプロダクトバックエンドがあるなら、最短で Gemini 適性を検証する方法です。
pythonfrom openai import OpenAI client = OpenAI( api_key="YOUR_GEMINI_API_KEY", base_url="https://generativelanguage.googleapis.com/v1beta/openai/", ) response = client.chat.completions.create( model="gemini-3-flash-preview", messages=[{"role": "user", "content": "Explain why compatibility layers are useful."}], ) print(response.choices[0].message.content)
このルートが便利なのは、チーム全体の client shape を一気に学び直さずに済むこと、そして provider comparison や BYOK の設計を既存の OpenAI ベースの上で動かしやすいことです。移行速度が最重要なら、互換レイヤーはかなり合理的です。
ただし長期のデフォルトにすべきかという問いには別の答えになります。Google の関連資料でも、OpenAI compatibility は migration bridge としては強い一方、Files API や Gemini 固有の tool flow のようなネイティブ機能を厚く使うなら最終的にはネイティブ SDK の方が適していると読み取れます。Gemini 特有の surface に依存するほど、互換層は便利な橋ではなく翻訳コストになります。
実務的な判断ルールは単純です。新規アプリならネイティブ。既存 OpenAI 風コードの短期移行なら compatibility。これだけで大半の迷いは減ります。
Hello World の直後に学ぶべき本番機能
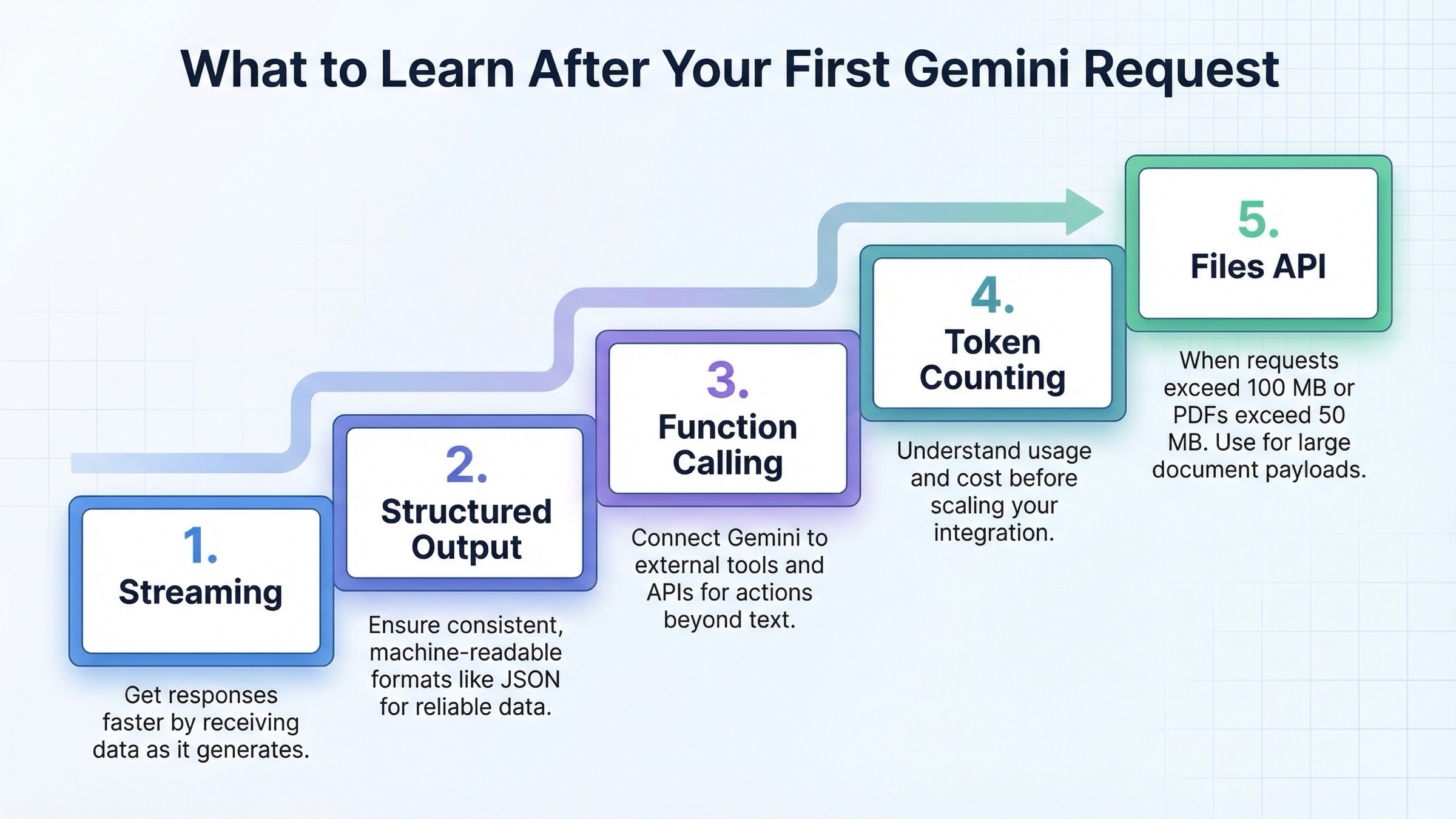
最初のリクエストが通ったあとにやるべきことは、「Gemini の全機能を一気に覚える」ことではありません。実際のアプリ挙動を変える少数の機能を、順番に覚えることです。多くの場合、その順番は streaming、structured output、function calling、token counting、そして Files API です。
streaming は応答性を改善します。structured output は downstream automation を安全にします。function calling は Gemini と自分のコードや外部システムをつなぎます。token counting はコスト見積もりと prompt 成長の監視に役立ちます。Files API は本当に大きい入力や multimodal ワークロードで必要になります。Files guide では、総リクエストサイズが 100 MB を超える場合、PDF では 50 MB を超える場合に Files API を使うよう案内されています。保存期間 48 時間、1 project あたり 20 GB、1 file あたり 2 GB という条件も設計に直結します。
javascriptimport { GoogleGenAI, createPartFromUri, createUserContent, } from "@google/genai"; const ai = new GoogleGenAI({}); const myfile = await ai.files.upload({ file: "path/to/sample.mp3", config: { mimeType: "audio/mpeg" }, }); const response = await ai.models.generateContent({ model: "gemini-3-flash-preview", contents: createUserContent([ createPartFromUri(myfile.uri, myfile.mimeType), "Describe this audio clip", ]), }); console.log(response.text);
Files API は必要なときだけ使えば十分です。小さなテキストプロンプトなら、最も単純なリクエストの方がよいことは変わりません。ただし、大きな添付や multimodal 入力が出てきた瞬間に file lifecycle と request-size 制限は避けて通れない知識になります。
| 機能 | 学ぶタイミング | 重要な理由 | 公式アンカー |
|---|---|---|---|
| Streaming | 最初の成功直後 | 体感速度とインタラクティブ UX を改善する | Text generation |
| Structured output | 他サービスが Gemini 出力に依存し始めたら | JSON ハックを減らし自動処理を安定させる | Structured outputs |
| Function calling | Gemini にアプリロジックや外部ツールを呼ばせるとき | agent 的なフローを現実的にする | Function calling |
| Token counting | 本番トラフィック前 | prompt 成長とコストを早めに可視化できる | Token counting |
| Files API | リクエストが 100 MB 超、PDF が 50 MB 超になったら | 大きな multimodal 入力を安全に扱える | Files API |
この順番が大切なのは、弱いチュートリアルが両極端に走りやすいからです。単純な text prompt で止まってしまうか、逆にすべての機能を一度に見せてしまうか。実務で役立つのはその中間で、ひとつの確実なリクエストを基点に、運用結果を変える機能だけを順番に増やす流れです。
よくある統合ミスとトラブルシューティング
最も多いミスは、間違ったチュートリアルから始めることです。もし google-generativeai や @google/generative-ai が現在の標準ルートとして紹介されていたら、その時点で一度止まり、Google の migration guide と照合した方が安全です。旧ライブラリの例が完全に使えないわけではありませんが、2026年の新規統合の基準としてはもはや最もきれいな出発点ではありません。
二つ目のミスは、preview model ID を安定契約のように扱うことです。Google の models guide でも、preview モデルは production で使える場合がある一方、制限が厳しかったり deprecation リスクが高かったりします。preview を避けろという話ではなく、なぜそれを使うのかを理解し、後で切り替える前提を持てという話です。最新 preview 専用の面が不要なら stable model の方が安全です。
三つ目は quota と billing の誤解です。Google の billing page では input tokens、output tokens、cached token count、cached token storage duration が課金対象だと説明されています。同時に、400 / 500 エラーは課金されなくても quota は消費すると明記されています。つまり「課金されていない」ことは「無料だった」ことと同義ではありません。失敗リクエストでも capacity は燃えます。
これは特に 429 で重要です。rate-limit docs やコミュニティの事例を見ると、見えている RPM より十分低いのに、enqueued token、project mismatch、free-tier exhaustion、preview モデルの収容制限などで詰まることがあります。429 が出たら単純に exponential backoff を強くする前に、どの種類の制限に当たっているのかを切り分けるべきです。広いエラー地図が必要なら Gemini API エラートラブルシューティングガイド を見てください。
最後の典型的な失敗は、統合の最初の一週間を複雑にしすぎることです。初日から streaming、tools、files、structured output、cache、chat history の全部は要りません。必要なのは、ひとつの成功したサーバー側リクエスト、ひとつの秘密情報の境界、そして次の本当に必要な機能だけです。この順番を守るチームの方が、全部を先に学ぼうとするチームより速く動くことが多いです。
要するに、運用ルールは一行で足ります。まずネイティブで始める。キーはサーバーに置く。トークンは早めに測る。機能追加は実際のプロダクト要件が出てから行う。 これだけで、多くの大きなサンプル集より実務では役に立ちます。