
2026年3月時点のGemini API料金を見ると、テキストモデルの入力価格は100万Tokenあたり0.10ドルから2.00ドル、出力価格は0.40ドルから12.00ドルまで幅があります。最も安い安定版テキストモデルは依然としてGemini 2.5 Flash-Liteです。Gemini 3系に残りたいなら、現時点の低価格ルートはGemini 3.1 Flash-Lite Previewです。そして上位ラインはGemini 3.1 Pro Previewですが、200K Tokenを超える長いプロンプトでは料金が一段上がる点を見落とすべきではありません。
このページは、まず予算判断を早く終わらせるために使ってください。どのモデルを見積もりの基準に置くべきか、200K Token の閾値でどこから計算が変わるのか、そしてどの追加課金要素が実際の請求額を押し上げるのかを先に押さえるためです。ここでは Gemini Developer API の料金だけに絞り、Vertex やアプリ課金は混ぜず、Batch、caching、grounding、audio、長文脈閾値など、実費を動かす項目を順に整理します。
要点まとめ
- 最も安い安定版テキストモデル: Gemini 2.5 Flash-Lite。入力100万Tokenあたり0.10ドル、出力0.40ドル。
- Gemini 3系で最も安いテキストモデル: Gemini 3.1 Flash-Lite Preview。入力0.25ドル、出力1.50ドル。
- 現在の上位ライン: Gemini 3.1 Pro Preview。200K以下では2.00 / 12.00ドル、200K超では4.00 / 18.00ドル。
- 多くの本番アプリで無難な標準候補: Gemini 2.5 Flash。Liteより高いものの、Proほど高くなく、性能と価格のバランスがよい。
- 最も手早い節約方法: Batch。主要なテキストモデルでは標準料金のほぼ半額になります。
- 一番多い見落とし: input/output単価だけを見て、200K閾値、音声入力、context caching、cache storage、grounding料金を忘れること。
2026年3月のGemini API Token料金表
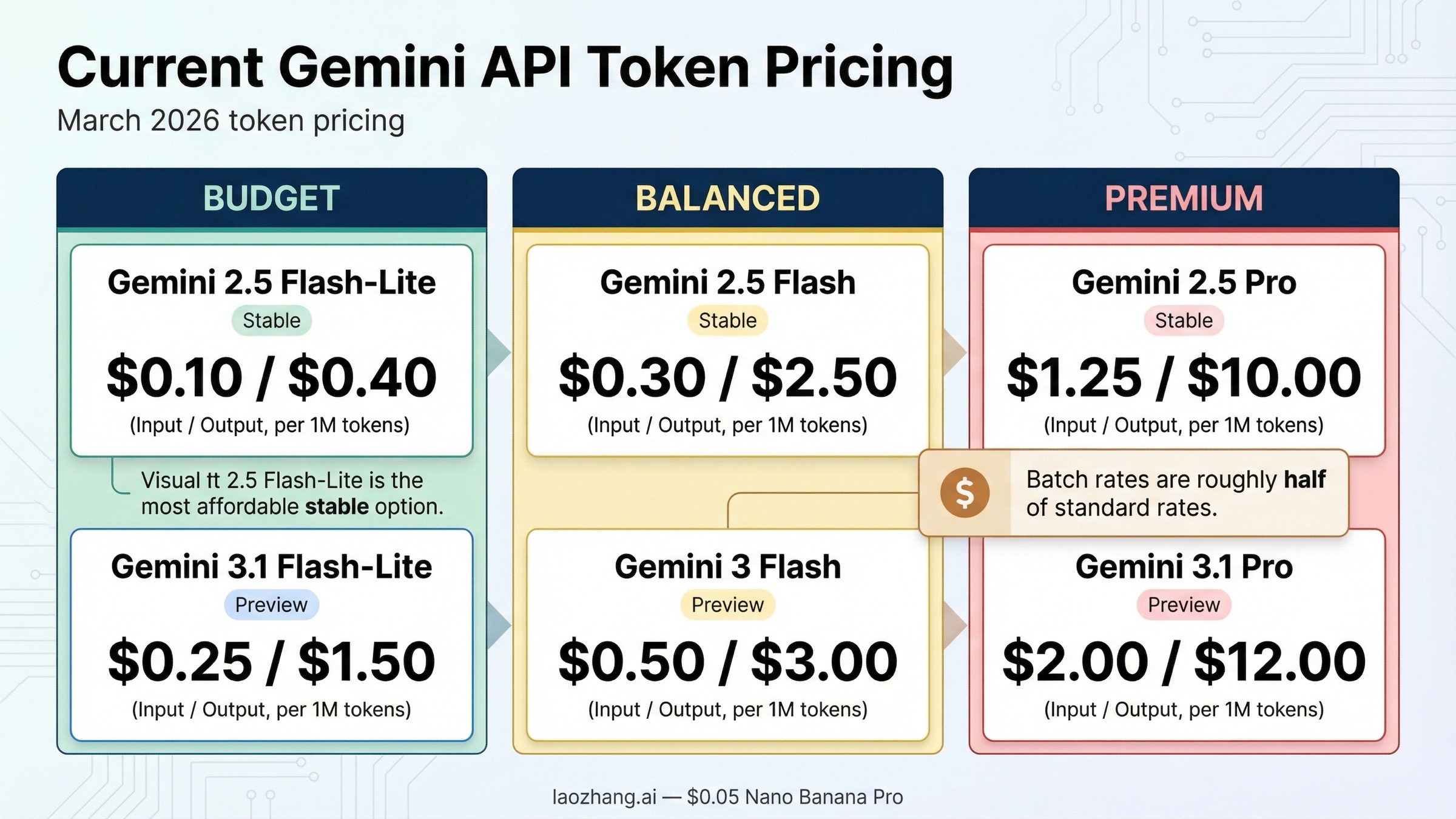
公式の Gemini Developer API pricing ページが一次情報ですが、主要なテキストモデルをすばやく比較するには少し読みづらい面があります。そこで、現在よく比較されるラインだけをまとめると次のようになります。
| モデル | 標準input料金 | 標準output料金 | Batch input | Batch output | 補足 |
|---|---|---|---|---|---|
| Gemini 3.1 Pro Preview | 200K以下で100万Tokenあたり2.00ドル、超過で4.00ドル | 200K以下で12.00ドル、超過で18.00ドル | 200K以下で1.00ドル、超過で2.00ドル | 200K以下で6.00ドル、超過で9.00ドル | paid専用、現行の上位テキストライン |
| Gemini 3 Flash Preview | text / image / videoは0.50ドル、audioは1.00ドル | 3.00ドル | text / image / videoは0.25ドル、audioは0.50ドル | 1.50ドル | Gemini 3の高速ライン、無料枠あり |
| Gemini 3.1 Flash-Lite Preview | text / image / videoは0.25ドル、audioは0.50ドル | 1.50ドル | text / image / videoは0.125ドル、audioは0.25ドル | 0.75ドル | Gemini 3系で最も安いテキストルート |
| Gemini 2.5 Pro | 200K以下で1.25ドル、超過で2.50ドル | 200K以下で10.00ドル、超過で15.00ドル | 200K以下で0.625ドル、超過で1.25ドル | 200K以下で5.00ドル、超過で7.50ドル | 3.1 Proより安い高推論代替 |
| Gemini 2.5 Flash | text / image / videoは0.30ドル、audioは1.00ドル | 2.50ドル | text / image / videoは0.15ドル、audioは0.50ドル | 1.25ドル | 安定したバランス型 |
| Gemini 2.5 Flash-Lite | text / image / videoは0.10ドル、audioは0.30ドル | 0.40ドル | text / image / videoは0.05ドル、audioは0.15ドル | 0.20ドル | 最も安い安定版 |
この表から最初に押さえるべきことは2つあります。
1つ目は、Googleの現行ラインアップは「新しいほど必ず安くて良い」という単純な階段ではないことです。最安の安定版テキストコストだけを見るならGemini 2.5 Flash-Liteが勝ちます。一方、Gemini 3ファミリーに残ることを前提にするなら、実際の低価格ルートはGemini 3.1 Flash-Lite Previewです。多くの比較ページはここを1つの“Gemini 3価格”に丸めてしまい、予算判断を難しくしています。
2つ目は、古い記事にまだGemini 3 Pro Previewが出てくることです。ですが、公式の modelsページ では、Gemini 3 Pro Previewは2026年3月9日に終了し、Gemini 3.1 Pro Previewへの移行が案内されています。いまでも旧モデルを現役として比較している記事は、他の価格情報も古い可能性が高いと考えた方が安全です。
どのGeminiモデルを予算に入れるべきか
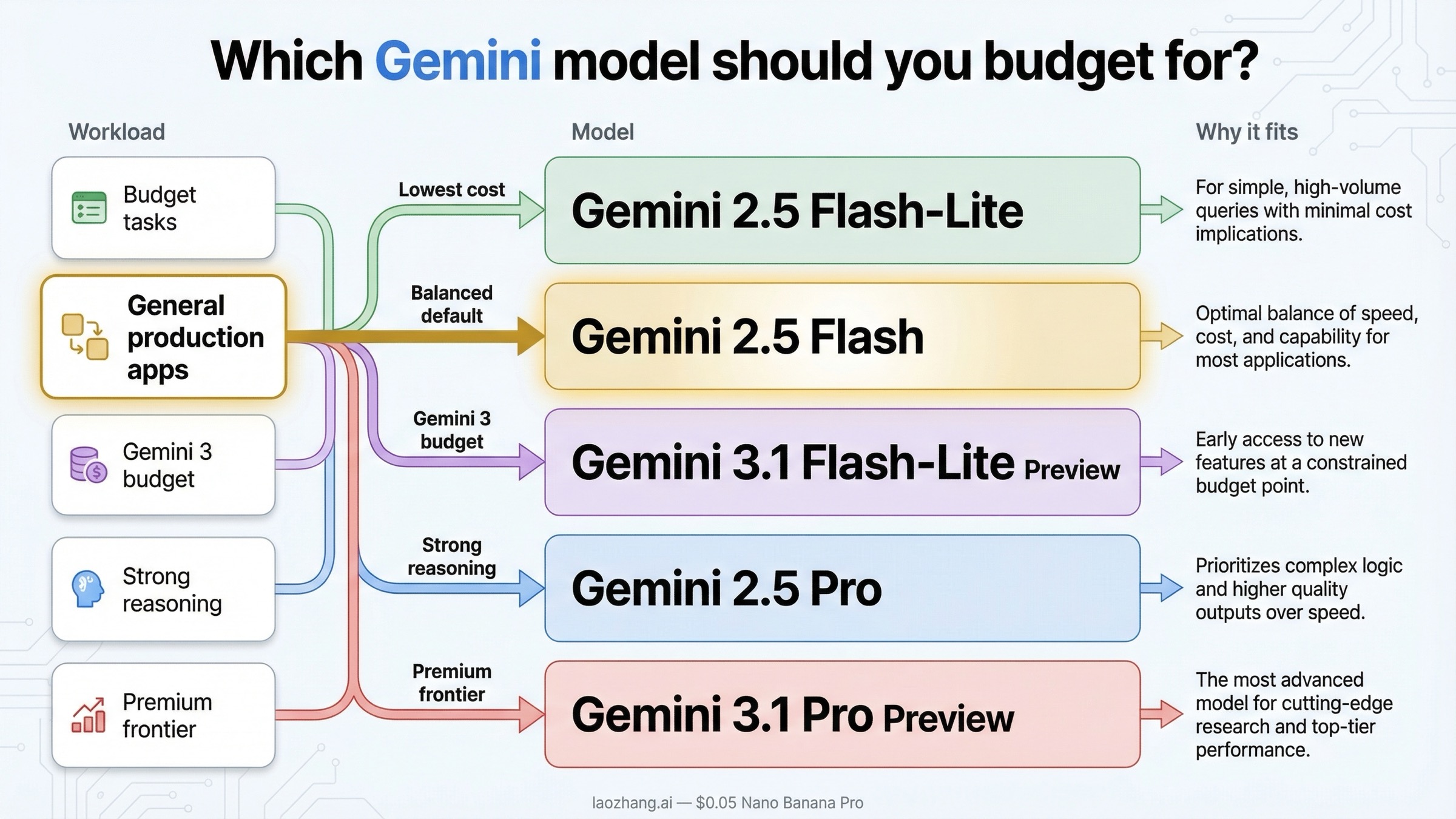
ここで重要なのは、「どのモデルが一番強いか」ではなく、自分のワークロードに対してどの価格帯のモデルを選ぶべきかです。モデル名の新しさだけで決めると、だいたいコスト見積もりがぶれます。
とにかく価格を抑えたいなら、Gemini 2.5 Flash-Liteが今でも最もわかりやすい答えです。分類、抽出、軽い翻訳、ルーティング、軽量チャット、高スループットのテキスト処理のように、最大級の推論力よりコスト効率と処理量が重要な場面では特に相性がいいです。
より無難な本番デフォルトを探しているなら、Gemini 2.5 Flashが依然として最も実務的です。Flash-Liteよりは高いものの、Proラインほどの負担にはならず、内部アシスタント、サポートボット、ドキュメントQ&A、軽量なエージェント処理などには十分なケースが多いです。まだプロダクトの形を探っている段階なら、まずこのラインで予算を作るのが妥当です。
Gemini 3ファミリーを使いたいがPro料金までは出したくないなら、Gemini 3.1 Flash-Lite Previewが現行の低価格ルートです。2.5 Flash-Liteより安いわけではありませんが、Gemini 3系に留まりながらコストを抑えられるのが意味になります。previewリスクを受け入れつつ、新しい系列を前提にしたい組織にはこの選択肢が現実的です。
本当に重い推論が必要な場合は、Gemini 2.5 ProとGemini 3.1 Pro Previewの比較になります。2.5 Proでも十分高性能ですが、3.1 Pro Previewはさらに高いプレミアム帯です。コード生成、長文統合、複雑なagent planningなどでその差が事業価値に直結するなら支払う意味がありますが、そうでなければ2.5 Proの方が現実的なケースは多いです。
つまり、2026年3月時点の実務的な分岐は次の通りです。
- 最安重視: Gemini 2.5 Flash-Lite
- 安定バランス型: Gemini 2.5 Flash
- Gemini 3系の低コスト入口: Gemini 3.1 Flash-Lite Preview
- 強い推論を比較的安く: Gemini 2.5 Pro
- 最上位のプレミアムルート: Gemini 3.1 Pro Preview
AI Studioで無料に見えたからといって、そのまま本番コストの感覚にしてはいけません。Googleの billing FAQ は、AI Studioはpaid API keyを紐づけるまでは無料でも、paidプロジェクトに入ると課金ロジックが適用されることを明示しています。試用と本番は別物です。
実際のGemini請求額に含まれるもの
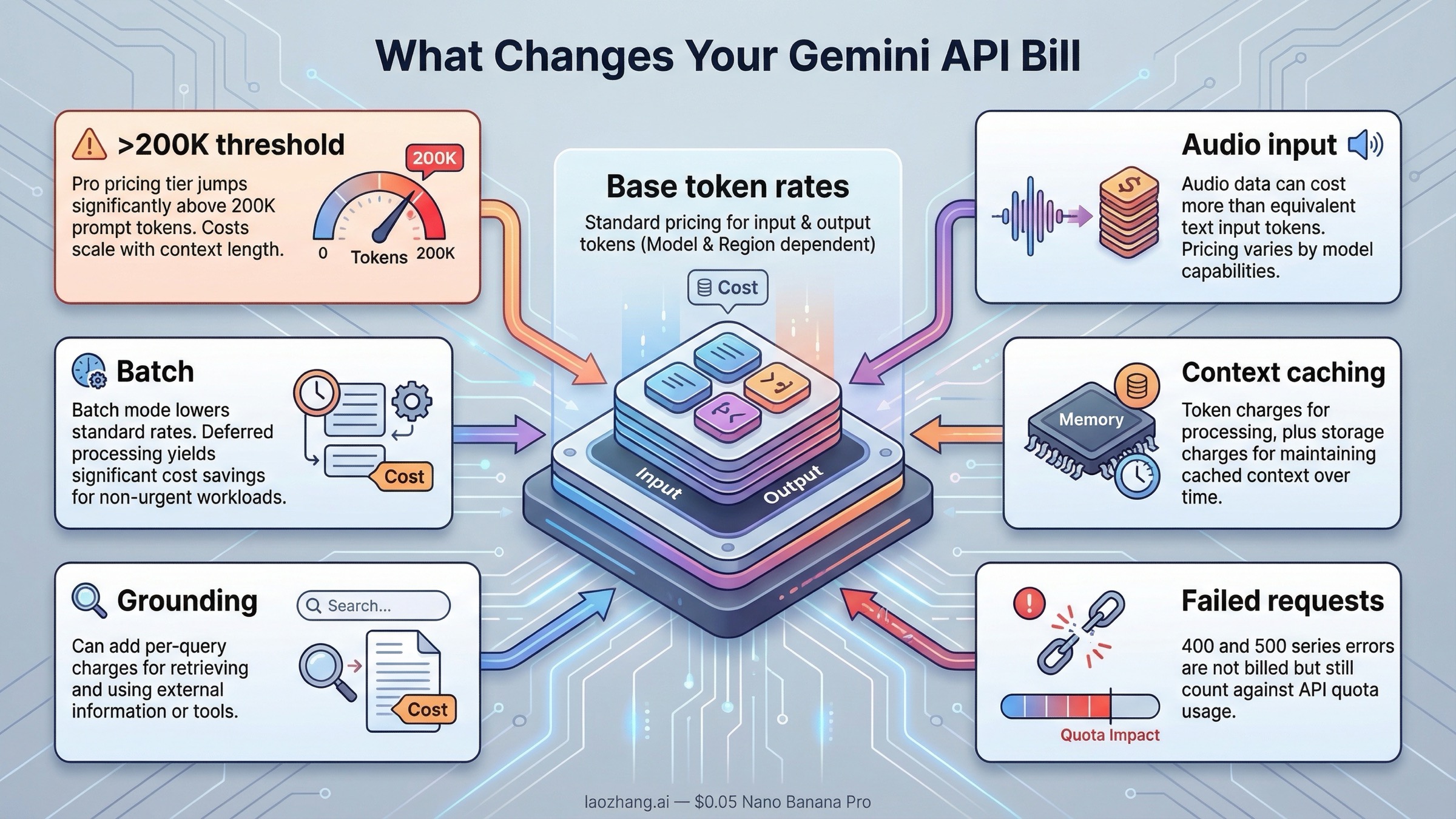
Gemini料金の記事の多くは料金表で止まりますが、実際の予算差が生まれるのはその先です。Googleの billingページ では、Gemini APIの課金対象として input token count、output token count、cached token count、cached token storage duration が明示されています。つまり、送信したテキストと受け取ったテキストだけが請求対象ではありません。
Tokenそのものの感覚も必要です。公式の tokenガイド によれば、Geminiでは1 Tokenはおよそ4文字、100 Tokenで英語60〜80語程度です。これは厳密な会計式ではありませんが、ざっくりした見積もりには十分です。短いプロンプトは大きな問題になりにくく、本当にコストを押し上げるのは、長いシステム指示、RAGで毎回付ける大量の文脈、ツールログ、長い会話履歴です。
さらに重要なのは、すべてのinputが同じ単価ではないことです。モデルによってはaudio inputがtext inputより高いですし、Proラインでは単一リクエストのpromptが200Kを超えると、より高い価格帯に移ります。cachingやgrounding、多モーダル入力が入ると、頭の中にある“基本単価”だけでは実際の請求額を説明できなくなります。
そこで、実際の請求を変える主な修正要素をまとめると次のようになります。
| 修正要素 | 何が変わるか | なぜ重要か |
|---|---|---|
| Proで200K超 | Gemini 3.1 Pro Previewは2.00 / 12.00から4.00 / 18.00へ、Gemini 2.5 Proは1.25 / 10.00から2.50 / 15.00へ上がる | 長文コンテキストで急に高くなる |
| 音声入力 | Flash系はaudio inputの単価がtextより高い | 音声ワークロードは過小見積もりされやすい |
| Batch | 主要テキストモデルで標準料金のほぼ半額になる | 非同期処理では最重要の節約策 |
| Context caching | cached tokenと保存時間に課金される | 安くなることもあるが、無料ではない |
| Grounding | 検索や地図のクエリ課金が加わる | 請求がtoken-onlyではなくなる |
| 400/500エラー | 料金はかからないがquotaは消費する | 請求は増えなくても運用上の損失が出る |
特に重要なのはBatchとContext cachingです。
Batchは、レポート生成、夜間集計、非同期評価、大量リライトなど、リアルタイム応答が不要な仕事ではまず確認すべき最初の節約手段です。プロンプト最適化やモデル移行より先に、そもそもこの処理をBatchにできないかを見る方が、すぐに効くことが多いです。
Context cachingも、Geminiの価格説明で誤解されやすい機能です。確かに同じ文脈を繰り返し送るコストは下げられますが、Googleはcached tokenとstorage durationにも課金します。つまり、cachingは“無料のメモリ”ではなく、“正しく使えば安くなる最適化機能”です。free tierやquotaの観点を補足で見たいなら、関連する Gemini API free quota 2026 も合わせて読む価値があります。
なぜGeminiのコストは急に高くなりやすいのか
実際の請求額が記憶していた価格より高くなる原因は、だいたい3つに集約されます。
1つ目は200K prompt閾値です。長い文書、大きなコードベース、RAGの大量チャンク、長い会話履歴を扱うと、この閾値を超えるのは珍しくありません。すると、Proラインの“覚えていた価格”はそのまま適用されません。長文が前提のユースケースでは、Proにする前に retrievalや圧縮の設計を見直した方が、コスト面では合理的なことがあります。
2つ目は無料枠の錯覚です。AI Studioで試せたという事実と、API本番運用でも同じコスト感になるという話は別です。モデルごとにfree tierの条件は違い、paid projectに入れば課金ロジックも変わります。ここを混同すると、予算計画はかなり狂います。
3つ目は価格と制限の相互作用です。コストだけでは本番の運用は決まりません。Googleの rate limitsページ では、制限はAPI key単位ではなくproject単位でかかり、modelやusage tierによって変わると説明されています。つまり、本番では「最安の行はどれか」だけでなく、「必要なスループットをどのラインなら維持できるか」も同時に考える必要があります。
要するに、Geminiのコスト差を大きく動かすのは、単価の細かな差よりも、モデル選択、長文コンテキスト、Batch利用、プロンプト設計の方です。
Gemini Developer API、Vertex AI、AI Studioの料金の違い
このキーワードが分かりにくくなる大きな理由の1つが、検索結果でGemini Developer API、Vertex AI、AI Studioが同じ話として扱われがちなことです。
しかし、開発者の実務ではこれは別の価格面です。
- Gemini Developer API: この記事が扱う中心。Gemini APIを直接使う開発者のための価格面。
- Vertex AI: Google Cloud上のエンタープライズ文脈でGeminiを使うための面。
- AI Studio: 実験や検証のためのUIであり、そのまま本番価格モデルではない。
多くの広い記事は、さらにGeminiアプリのサブスクやWorkspaceの課金まで混ぜてしまいます。その結果、ページは長くなっても、「APIのToken単価を知りたい」という意図にはむしろ答えにくくなります。
実務的な判断ルールはシンプルです。
- 直接APIコールのコストを見積もるなら Gemini Developer API pricing を見る。
- Google Cloudで実際に運用するなら Vertex AI pricing を見る。
- AI Studioは検証用の入口として扱い、本番予算の最終基準にしない。
2026年3月時点では、Vertex AI側も主要な単価構造はほぼ同じですが、priorityやFlex / Batchの見せ方が強く、企業向け価格面とDeveloper APIの一般向け価格面が混ざりやすいです。第三者記事がどの価格面を引用しているか明示していない場合、その数字は一度公式で確認した方がいいです。
よくあるワークロードの月額コスト例
単価を実際の予算判断に変えるには、典型的な使用量に当てはめるのが一番わかりやすいです。
ケース1: Gemini 2.5 Flashで小規模サポートボット
月に入力3000万Token、出力1000万Token使うとします。
- input: 30 × 0.30 = 9.00ドル
- output: 10 × 2.50 = 25.00ドル
- 月額見積もり: 34.00ドル
だからこそ2.5 Flashは今でも強い標準候補です。安すぎて性能不足というほどでもなく、Proほど重くもありません。
ケース2: Gemini 2.5 Flash-Liteで高スループット抽出・ルーティング
月に入力2億Token、出力4000万Token使うとします。
- input: 200 × 0.10 = 20.00ドル
- output: 40 × 0.40 = 16.00ドル
- 月額見積もり: 36.00ドル
この例は、出力単価も同じくらい重要だと教えてくれます。Flash-Liteはinputだけでなくoutputも安いので、大量処理で強いのです。
ケース3: Gemini 3.1 Pro Previewで高難度コード生成や統合
月に入力2000万Token、出力400万Token、かつ各promptは200K以下に収めるとします。
- input: 20 × 2.00 = 40.00ドル
- output: 4 × 12.00 = 48.00ドル
- 月額見積もり: 88.00ドル
同じ量をGemini 2.5 Proで回すと、
- input: 20 × 1.25 = 25.00ドル
- output: 4 × 10.00 = 40.00ドル
- 月額見積もり: 65.00ドル
つまり、3.1 Proのプレミアムは実際に効いてきます。小さな差とは言えません。
ケース4: Batchで非同期バックフィル
ケース1をBatchで回すと、
- input: 30 × 0.15 = 4.50ドル
- output: 10 × 1.25 = 12.50ドル
- 月額見積もり: 17.00ドル
ほぼ半額です。だから、プロバイダ移行や複雑な最適化に入る前に、「この処理はBatch化できるか」を見る価値があります。
free tierや制限面の方がいま気になるなら、補助記事として Gemini API free quota 2026 を読むと全体像がつながります。ただ、このページの結論はとてもシンプルです。
Gemini API Token料金で本当に答えるべきことは、「100万Tokenがいくらか」だけではありません。どのモデルラインを選ぶべきか、そしてどの課金修正要素が最終請求額を変えるのか、そこまで含めて初めて役に立つ答えになります。