
Claude API が HTTP 500 を返し、本文に error.type: "api_error" があるなら、最初にやることは API キーの作り直しでも prompt の書き換えでも provider の切り替えでもありません。リクエストは Claude 側に届き、内部サーバー分岐として返ってきています。まず request_id、またはレスポンスヘッダーの request-id、発生時刻、model、endpoint、auth owner、SDK または gateway、base URL、network path、request shape を同じ観測単位で残します。
2026年5月19日の確認時点では、Claude Status は全体として operational を示しつつ、直近の 5xx 系の解決済み履歴も見える状態でした。これは「今すぐ全員が障害中」という証拠ではなく、時刻付きの分岐材料です。緑の status は、あなたの model、organization、region、gateway、proxy、batch、または特定 workload が正常だと証明するものではありません。だからこそ、同じ経路の証拠を壊さずに小さく再試行する必要があります。
変更を入れる前に、次の表で枝を合わせます。一つの 500 表示だけを見て複数の変数を同時に動かすと、復旧しても原因が残りません。
| いま見えている症状 | 最初の行動 | 検証するもの | 停止ルール |
|---|---|---|---|
HTTP 500 の内部サーバー分岐が返った | request_id、時刻、model、endpoint、route を保存し、Claude Status を確認する | 同じ経路で回復するか、同じ branch が繰り返すか | 2-3回程度の小さな retry budget で止める |
529 overloaded_error | concurrency と自動 retry 圧を下げ、長めの backoff に寄せる | 負荷を下げた後に branch が変わるか解消するか | JSON、key、prompt の問題として扱わない |
429 rate_limit_error | usage、limit、token volume、pacing、batch size を確認する | pacing や quota 調整後に通るか | public incident 待ちだけで解決しようとしない |
504 timeout_error または長い処理 | request を小さくする、streaming や batch を使う、timeout 設計を見直す | 小さい request または streaming が同じ account で通るか | 返却された 500 なしに internal-server branch と呼ばない |
| DNS、proxy、TLS、SDK timeout で API 応答がない | network、proxy、firewall、VPN、base URL、SDK timeout を確認する | known-good の小さな request が API に届くか | api_error の retry ルールを接続失敗に流用しない |
| 同じ経路で clean 500 が繰り返す | request IDs、status timestamp、retry timeline、route、匿名化した payload shape をまとめる | platform owner が同じ経路をログで相関できるか | API key、auth header、private prompt、PII、raw file は送らない |
ここで重要なのは、枝が決まったら観測線を保つことです。model、key、gateway、proxy、prompt、SDK version を同時に変えて通ったとしても、元の障害が provider 側で自然回復したのか、経路を変えたから消えたのか、request shape が変わったから消えたのか判断できません。
クリーンな 500 api_error が示すもの
Anthropic の API エラー分類では、HTTP 500 は api_error に対応します。これは「何でも 500 と呼ぶ」ための曖昧なラベルではありません。API がレスポンスを返し、その本文に error.type、error.message、場合によっては request_id が含まれ、ヘッダー側にも request-id が出る可能性がある branch です。つまり、最初に守るべきものは再現条件と識別子です。
クリーンな 500 は、あなたのコードが完全に正しいことまでは証明しません。短い service fault、model 側の一時的な経路、platform 内部の dependency、gateway の upstream、または特定 route の問題が、呼び出し側には同じ HTTP status として見えることがあります。運用上の問いは「Claude が悪いか自分が悪いか」ではなく、「同じ経路で再現するか」「公開 status や直近 incident と時刻が重なるか」「一つずつ変数を変えたときに branch が変わるか」です。
API キーのローテーションから始めないでください。key が無効、workspace が違う、権限がない、billing 側で止まっている場合は、多くの場合 authentication、permission、billing、または別の 4xx 系 branch として現れます。prompt の書き換えから始めるのも危険です。schema や payload が不正なら validation 系に落ちるのが自然です。もちろん巨大な context、tool use、非決定的な添付、長い出力が二次的に関係することはありますが、それを調べるのは request_id と同じ経路を残した後です。
Claude Code も分けて扱います。Claude Code は raw API 5xx response body を端末に表示することがあり、利用者には API Error: 500 として見えます。これは CLI が同じ API branch を見せているという意味であって、ローカルの Claude Code 環境だけが原因だと決める材料ではありません。Claude Code の version、command、raw body、auth 状態、Workbench または direct API での小さな再現可否を別々に残すと、CLI 表面と API 表面を混ぜずに済みます。
まずエラー分岐を合わせる

復旧が遅くなる一番の理由は、正しい手順を間違った branch に適用することです。500 api_error、529 overloaded_error、429 rate_limit_error、504 timeout_error、connection failure、Claude Code 表面、chat UI 表面は、同じプロダクトの中で同時期に見えることがありますが、行動は違います。
500 api_error は、Claude から HTTP 応答が返り、その body が internal-server branch を示しているときに使います。証拠は status、request ID、model、endpoint、route、timestamp です。回復行動は status 確認と限定 retry であり、usage plan の計算や key rotation ではありません。
529 overloaded_error は容量や過負荷の branch です。ここでは自動 retry を強めるほど悪化します。concurrency を下げ、backoff を伸ばし、queue を保護し、retry storm を作らない設計に切り替えます。実際の branch が 529 に変わったなら、Claude 529 Overloaded Error のように容量圧と retry 負荷を中心に扱う方が筋が通ります。
429 rate_limit_error は account、organization、あるいは request pace の制限です。公開 status の緑赤よりも、usage、limit、token volume、batch size、同時実行数、retry header、組織内の共有利用が効きます。500 の incident runbook をここに当てると、limit を超えたまま待ち続けることになります。
504 timeout_error は処理が時間内に終わらない branch です。長い context、重い tool chain、大きな output、streaming なしの同期処理では、request design を小さくする、Message Batches を使う、timeout を見直す、途中経過を持てる構造にするなど、internal server error とは別の改善が必要です。
API 応答が返っていないなら connection branch です。DNS、TLS、corporate proxy、VPN、firewall、wrong base URL、SDK timeout、egress policy が Claude の手前で落としている可能性があります。この場合は、重い本番 payload を再送するより、known-good の小さな request を direct path と同じ network path で試す方が早く切り分けられます。
限定された復旧ループで処理する
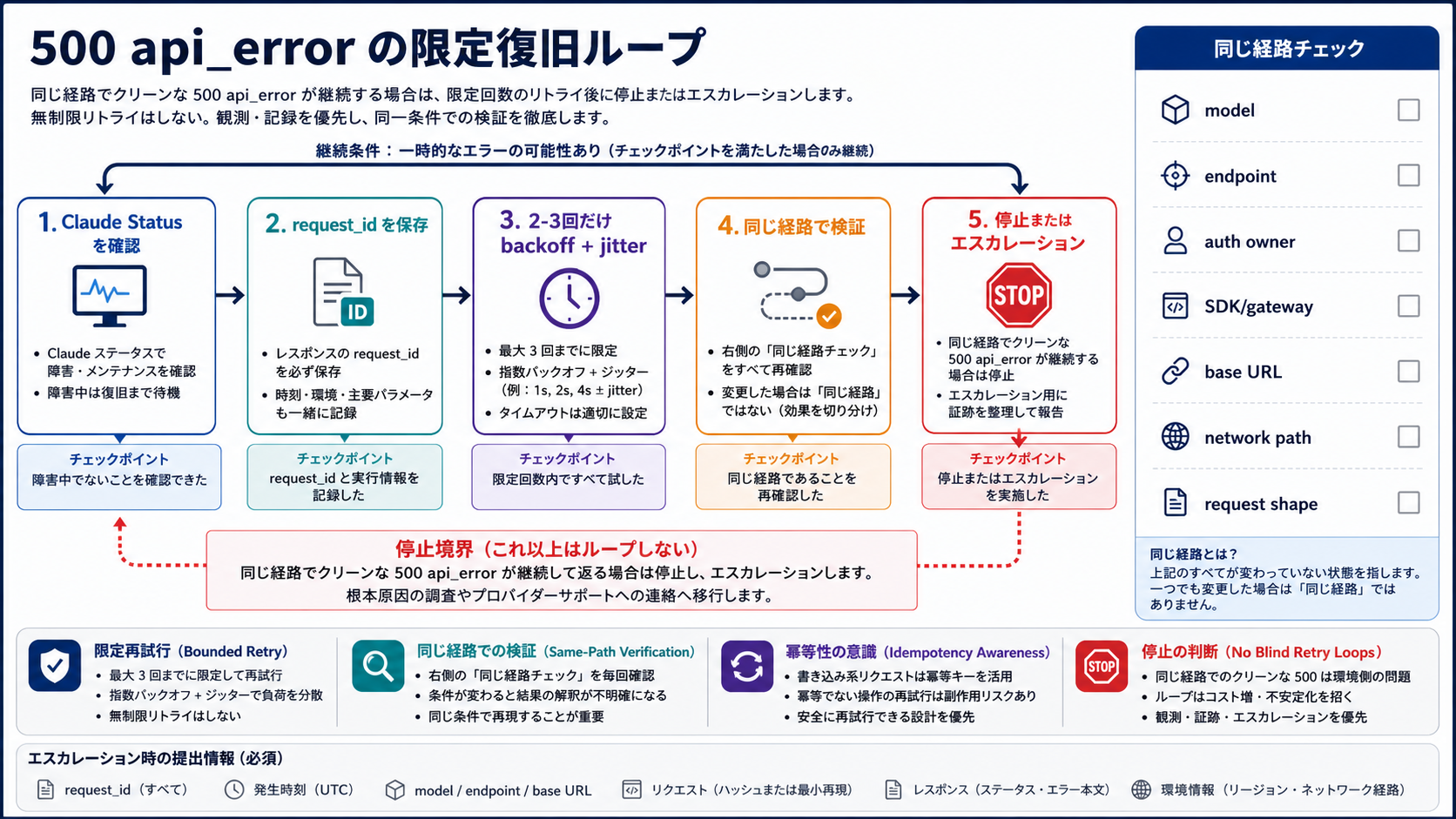
復旧ループは短くします。Status、evidence、bounded retry、same path、stop or escalate。この順番は、証拠を消さず、provider incident に余計な負荷をかけず、再現性を残すためのものです。
最初に Claude Status を開き、確認時刻を記録します。active incident があれば、ユーザー表示、queue、retry 圧、batch の投入、fallback の可否を incident mode に切り替えます。status が緑でも、あなたの route が local-only と決まるわけではありません。緑の場合は、むしろ同じ経路の再現条件が重くなります。
次に識別子を保存します。direct API では response body の request_id と header の request-id を取り、SDK では exception class、HTTP status、error.type、model、endpoint、base URL、SDK version、gateway name、attempt number、自社 correlation ID を残します。Claude Code では raw body、command、Claude Code version、auth state を添えます。ここまでで、単なる「また 500」ではなく、相関可能な event になります。
retry は小さくします。SDK が内部で既に一回または二回 retry している場合、application 側の外側ループは思った以上に request 数を増やします。2-3回の application-level retry、exponential backoff、jitter、総経過時間の cap、同じ clean 500 が続いたら停止、という形にします。復旧を急ぐほど、bounded であることが重要です。
同じ経路の検証は厳密に行います。同じ model、同じ endpoint、同じ auth owner、同じ SDK または gateway、同じ base URL、同じ network egress、secret を除いた同じ主要 headers、同じ request shape です。いくつも変数を動かしてから成功した場合、その成功は「復旧の証拠」ではなく「観測線を失った事実」になります。
最後に stop か escalation を決めます。idempotent な workflow で小さな retry が一度通ったなら、event を記録して監視を続けます。同じ path の clean 500 が小さな budget 後も続くなら、request を書き換える段階ではありません。証拠 packet を作り、platform owner、gateway owner、または Anthropic support が相関できる形にします。
リトライ前に副作用を止める
500 retry は、仕事の再実行が安全なときだけ安全です。read-only の要約、分類、分析、検索補助、テスト用 completion は比較的扱いやすい一方で、支払い、DB 書き込み、メール送信、ticket update、tool call、file creation、外部 webhook は idempotency を持たないと二重実行になります。
まず request を idempotency class に分けます。読み取り専用なら短い retry budget を許容できます。単一レコードの更新なら自社側の idempotency key、job ID、dedupe table、state transition guard が必要です。外部 side effect を伴うなら、Claude 呼び出しと side effect の境界を分け、Claude の応答が失敗したときに外部 action が既に走ったかどうかを独立して確認できるようにします。
streaming や tool use を使う場合、途中まで進んだ work unit をどう扱うかも決めます。部分出力を UI に出した後で 500 が来たのか、tool call の前で落ちたのか、tool result を返した後で落ちたのかで、再送すべき単位が違います。全 payload を blind retry するより、job state、tool call ID、checkpoint、own correlation ID を見て再開点を決める方が事故が少なくなります。
retry storm も止めます。ユーザー操作、frontend、backend job、SDK、gateway、queue worker がそれぞれ retry を持つと、一つの 500 が何十倍にも増えます。application retry を入れるなら、SDK retry 設定と gateway retry 設定を合わせて、全体の最大 attempt、総待ち時間、同時実行上限、circuit breaker を一つの設計として扱います。
fallback route は最後の手段ではなく、別の目的を持つ手段です。ユーザー体験を守るために一時 fallback を使うことはありますが、元 route の request_id と同じ経路の証拠を残す前に切り替えると、原因調査が難しくなります。fallback を使うなら、元 route の event、切り替え時刻、fallback の model/API 差分、失敗時の戻し条件を明示します。
直接 API、Claude Code、ゲートウェイを分ける
同じ 500 api_error でも、どこで見えているかによって必要な証拠が変わります。direct API、SDK、Claude Code、Workbench、gateway、proxy、internal service のどこで失敗したかを一つずつ分けないと、API branch と local route branch が混ざります。
Direct API では、HTTP status、body、headers、model、endpoint、region 相当の network egress、request body の匿名化 shape、auth owner が重要です。curl や small known-good request で同じ account と endpoint に到達できるなら、payload や route の重さも見られます。逆に small request も clean 500 なら、support が相関しやすい event です。
SDK では、SDK version、retry policy、timeout、transport、proxy 設定、exception wrapping が加わります。SDK が request ID を例外に載せるか、headers を取り出せるか、内部 retry 後の最後の応答だけを見ていないかを確認します。外側の retry loop を足す前に、SDK が既に何回投げているかをログで分かるようにします。
Claude Code では、terminal に出た raw response、command、working directory、Claude Code version、auth account、settings、proxy、ANTHROPIC_BASE_URL や gateway の有無を分けます。Claude Code docs の error reference は、5xx を API 側や infrastructure 側の failure として扱う文脈を持ちますが、CLI の local config が同時に絡む場合もあります。Claude Code だけで閉じず、可能なら Workbench または direct API の小さな request で branch を確認します。
Gateway や proxy を挟む場合、upstream が Claude なのか、gateway が独自に 500 を返しているのか、gateway が Anthropic の request-id を保持しているのか、body を書き換えていないかを見ます。gateway logs、upstream status、base URL、route name、provider selection、timeout、retry setting、header pass-through を保存します。ここで「Claude が 500」と言えるのは、upstream response と request ID が残っている場合です。
Workbench や dashboard 側だけで再現しない場合、本番 route の gateway、network、payload、headers、SDK retry のどれかが差分です。逆に Workbench の小さな request でも 500 が出るなら、account/model/endpoint 側の相関材料として強くなります。route ごとに証拠を分けると、support への報告も内部 incident の切り分けも短くなります。
エスカレーション用の証拠を揃える

同じ経路で clean 500 が繰り返す場合、さらに retry するより、相関できる証拠を作る方が速いです。support や platform owner が必要とするのは「動きません」ではなく、どの時刻に、どの model と endpoint で、どの route を通り、どの request IDs が、どの retry timeline で失敗したかです。
提出する情報は絞ります。Claude Status を確認した時刻、request_id または request-id、HTTP 500 と api_error の raw branch、model、endpoint、SDK/gateway/base URL、region または network egress、attempt number、retry interval、同じ経路の再現条件、匿名化した request shape、影響範囲、ユーザー影響、fallback の有無をまとめます。
匿名化した request shape は、full prompt のコピーではありません。message 数、概算 token volume、tool use の有無、添付の種類、streaming かどうか、batch か同期か、system prompt が長いか、output length が大きいか、non-idempotent side effect があるか、という構造だけで十分な場面が多いです。private prompt、PII、API key、auth header、raw file、customer data は送らないでください。
内部 escalation では owner を分けます。application owner は user impact と retry budget を見る。platform owner は gateway、queue、route selection、provider selection を見る。security または privacy owner は送れる log と伏せる log を確認する。support contact owner は request IDs と status timestamp を持って外部に出す。役割を分けると、誰かが再び prompt を書き換えて観測線を壊すことを防げます。
エスカレーション後も retry policy は止めたままにします。support へ送った後に別 route を何度も試すと、provider 側ログには新しい失敗が増え、元の同じ経路の再現が薄くなります。必要なら user-facing fallback と diagnostic route を分け、fallback は体験維持、diagnostic は同じ経路検証と明示します。
反復する 500 を運用イベントにする
単発の 500 は transient event として終わることがあります。反復する 500 は運用イベントです。ログ、alert、circuit breaker、retry budget、fallback、support packet、post-incident review を一つの流れに入れると、次回の対応速度が大きく変わります。
ログには branch を構造化して入れます。http_status=500、error_type=api_error、request_id、request_id_header、model、endpoint、route、gateway、SDK version、attempt、latency、token estimate、streaming、tool use、job ID、user-visible impact、own correlation ID を分けます。自由記述だけでは、あとから 529、429、504、connection failure と混ざります。
alert は「一回 500 が出た」ではなく、同じ route での率、連続回数、対象 model、user impact、retry amplification を見る方が実用的です。小さな spike なら bounded retry と monitoring、広い spike なら circuit breaker と user messaging、同じ account/model だけなら targeted escalation、と対応を変えられます。
circuit breaker は user experience と provider protection の両方に効きます。同じ branch が閾値を超えたら自動 retry を止める、queue をゆっくり消化する、noncritical job を後回しにする、idempotent job だけ再投入する、manual approval が必要な side effect を止める、といった制御が必要です。何もしない retry loop は、障害を早く直すのではなく、証拠と負荷を悪くします。
post-incident review では、最初の 10 分で何を保存できたかを見ます。request IDs は取れたか。status timestamp は残ったか。SDK と gateway の retry 回数は分かったか。same-path reproduction はできたか。fallback の開始時刻と終了条件はあったか。support に secrets を送らない boundary は守れたか。次の runbook はここから短くできます。
よくある質問
500 api_error は prompt が悪いという意味ですか?
通常はそう決めません。HTTP 500 と api_error は internal-server branch です。prompt や payload shape が二次的に関係することはありますが、最初の判断は status、request ID、model、endpoint、route、同じ経路の再現です。schema が明確に不正なら、多くの場合 4xx 系や validation branch を期待します。
API キーを作り直すべきですか?
最初の手ではありません。key が原因なら authentication、permission、billing、workspace などの別 branch が出るのが自然です。key を変える前に、request_id、status timestamp、同じ auth owner、同じ endpoint での小さな再現を残します。key rotation は security reason がある場合と、auth branch が確認された場合に分けて扱います。
何回まで retry してよいですか?
安全な上限を先に決めます。多くの application workflow では 2-3回の bounded retry、exponential backoff、jitter、総経過時間の cap が現実的な出発点です。ただし SDK や gateway が既に retry しているなら、合計 attempt を数えます。non-idempotent work は retry 以前に dedupe と side-effect guard が必要です。
Claude Status が緑なら自分の実装ミスですか?
緑の status は、その時刻の公開状態を狭める材料です。あなたの exact model、organization、region、gateway、proxy、network path、payload shape、SDK retry が正常だと証明するものではありません。緑のときほど、同じ経路の evidence と小さな再現が大事になります。
500 と 529 は同じように待てばよいですか?
同じではありません。529 overloaded_error は過負荷 branch なので、concurrency を下げ、retry pressure を抑え、長めの backoff を取ります。500 api_error は internal-server branch なので、request ID と同じ経路の証拠がより重要です。実際の branch が 529 なら、500 として一括処理しないでください。
Claude Code で API Error: 500 が出た場合も同じですか?
同じ API branch が Claude Code 表面に出ている可能性があります。ただし Claude Code には CLI version、auth 状態、settings、proxy、gateway、working directory、command という追加の差分があります。raw body と api_error を保存し、可能なら direct API または Workbench の小さな request で branch を確認します。
support に何を送れば相関しやすいですか?
Status 確認時刻、request_id または request-id、HTTP 500 と api_error、model、endpoint、SDK/gateway/base URL、network/region、retry timeline、同じ経路の再現条件、匿名化した request shape、影響範囲です。API key、auth header、full private prompt、PII、raw files は送らないでください。
provider や gateway をすぐ切り替えるべきですか?
ユーザー体験を守る目的で fallback を使うことはあります。ただし、元 route の証拠を残す前に切り替えると、原因調査が難しくなります。fallback は continuity 用、same-path reproduction は診断用と分け、切り替え時刻、差分、戻し条件を記録します。