
Los modelos de producción de Veo 3.1 admiten 50 solicitudes por minuto (RPM) a través de la API de Gemini y Vertex AI, mientras que los modelos preview están limitados a 10 RPM con un máximo de 10 solicitudes concurrentes por proyecto. Los precios comienzan en $0.15/segundo para el modo Fast y $0.40/segundo para el modo Standard a resolución 720p/1080p, sin nivel gratuito disponible a marzo de 2026. Esta guía proporciona datos verificados de límites de velocidad, código de manejo de errores listo para producción y estrategias de optimización de costos basadas en experiencia de despliegue real.
Resumen rápido
La API Veo 3.1 de Google aplica límites de velocidad estrictos que varían según el tipo de modelo y el nivel de acceso. Los modelos de producción (veo-3.1-generate-001) permiten 50 RPM con 10 solicitudes concurrentes, mientras que los modelos preview (veo-3.1-generate-preview) tienen un tope de 10 RPM. El error más común es 429 RESOURCE_EXHAUSTED, que requiere retroceso exponencial con variación aleatoria para un manejo fiable. Los costos de generación de video van desde $0.60 por un video Fast de 4 segundos hasta $4.80 por un video Standard 4K de 8 segundos, lo que hace que la selección de modo y la planificación de duración sean fundamentales para la gestión del presupuesto. Los desarrolladores que necesiten mayor rendimiento o precios simplificados pueden aprovechar proveedores externos como laozhang.ai que ofrecen precios fijos por solicitud sin restricciones de RPM.
Límites de velocidad de Veo 3.1 según método de acceso
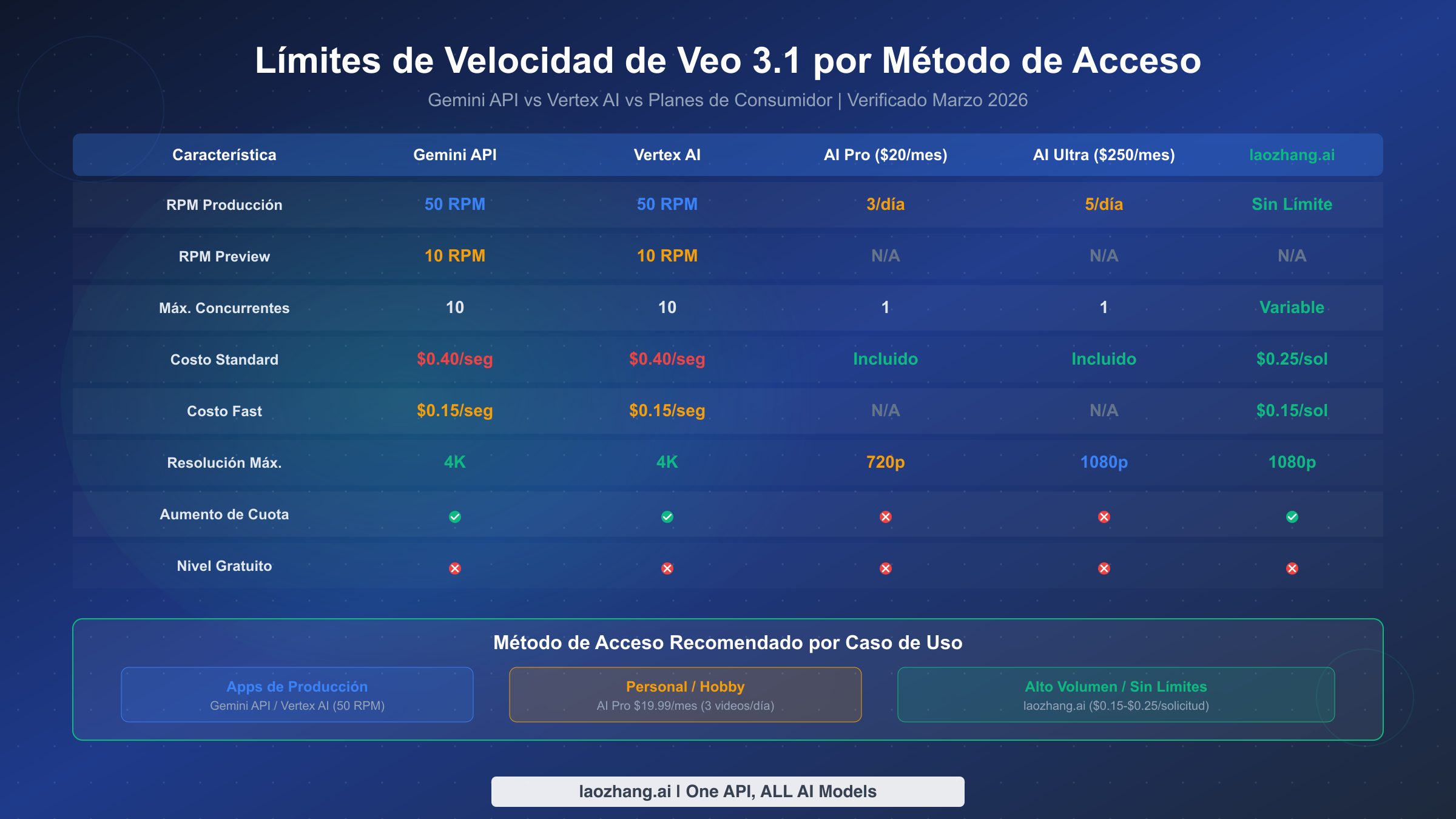
Comprender qué límites de velocidad se aplican a tu método de acceso específico es el paso más importante antes de construir cualquier pipeline de generación de video con Veo 3.1. Google ofrece múltiples vías para acceder a Veo 3.1, y cada una viene con estructuras de cuotas fundamentalmente diferentes que pueden determinar el éxito o fracaso de tu despliegue en producción. La confusión surge porque la documentación de Google está distribuida en múltiples páginas — documentación de la API de Gemini, documentación de Vertex AI y páginas de planes de consumidor — sin una referencia única unificada. Basándonos en nuestra verificación de la documentación oficial (ai.google.dev y cloud.google.com/vertex-ai, 2 de marzo de 2026), aquí presentamos el panorama completo.
La API de Gemini y Vertex AI comparten límites de velocidad idénticos para Veo 3.1: 50 RPM para modelos de producción y 10 RPM para modelos preview. Ambas plataformas aplican un máximo de 10 solicitudes concurrentes por proyecto y permiten hasta 4 videos de salida por prompt. La diferencia clave entre ellas no radica en las cuotas sino en la infraestructura de facturación — la API de Gemini utiliza la facturación de Google AI Studio mientras que Vertex AI se integra con la facturación de Google Cloud, lo cual importa para equipos empresariales ya invertidos en el ecosistema de GCP. Los identificadores de modelos de producción son veo-3.1-generate-001 para calidad estándar y veo-3.1-fast-generate-001 para modo rápido, mientras que las variantes preview utilizan el sufijo -preview (ai.google.dev/gemini-api/docs/video, verificado en marzo de 2026).
Los planes de consumidor operan con un paradigma completamente diferente. El plan AI Pro a $19.99/mes proporciona solo 3 videos por día a resolución máxima de 720p, mientras que AI Ultra a $249.99/mes aumenta esto a 5 videos por día a 1080p. Ningún plan de consumidor expone acceso a la API, lo que los hace inadecuados para cualquier flujo de trabajo programático. Para desarrolladores que construyen aplicaciones, la ruta de la API es la única opción viable, aunque el modelo de precios por segundo significa que los costos pueden escalar rápidamente durante períodos de generación intensiva. Vale la pena señalar que las cuotas de los planes de consumidor son límites estrictos sin mecanismo de anulación — una vez que has generado tu asignación diaria, la única opción es esperar hasta el día siguiente o cambiar al acceso basado en API con su propio grupo de cuotas separado.
Una distinción frecuentemente pasada por alto es cómo los límites de velocidad interactúan con la naturaleza asíncrona de la generación de video de Veo 3.1. Cuando envías una solicitud, la API devuelve un objeto de operación inmediatamente, y la renderización real del video ocurre del lado del servidor durante un período de 11 segundos a varios minutos. El límite de 50 RPM se aplica a las solicitudes de envío, no a los renders completados. Esto significa que puedes tener 50 videos renderizándose simultáneamente (hasta el tope de 10 concurrentes) mientras continúas enviando nuevas solicitudes a la tasa permitida. Comprender esta distinción es crítico para el diseño del pipeline — tu cuello de botella es el rendimiento de envío, no el rendimiento de renderización, y optimizar en torno a esta realidad puede mejorar drásticamente la producción efectiva.
El sistema de niveles de Google gobierna la velocidad con la que puedes escalar tus cuotas de API. El Nivel 1 requiere una cuenta de facturación de pago, el Nivel 2 requiere $250 o más en gasto acumulado más 30 días de antigüedad de la cuenta, y el Nivel 3 requiere $1,000 o más con el mismo mínimo de 30 días. Cada aumento de nivel potencialmente desbloquea asignaciones de cuota más altas, aunque los multiplicadores exactos para Veo 3.1 no están documentados públicamente y deben solicitarse a través de la consola de Google Cloud. Para equipos que necesiten alto rendimiento inmediato, explorar un tutorial completo de generación de video con Veo 3.1 puede ayudar a optimizar tu cuota existente antes de buscar actualizaciones de nivel.
Toda la salida de video de Veo 3.1 sigue especificaciones técnicas consistentes independientemente del método de acceso: duraciones de 4, 6 u 8 segundos; relaciones de aspecto de 16:9 o 9:16; resoluciones hasta 4K (solo para videos de 8 segundos); velocidad de fotogramas de 24 FPS; formato MP4; soporte de idioma solo en inglés para prompts de texto a video; y marca de agua SynthID obligatoria. El período de retención de video es de 2 días, después del cual los videos generados se eliminan automáticamente de los servidores de Google — si no descargas y almacenas tus videos generados dentro de esa ventana, se pierden permanentemente. Esta política de retención de 48 horas significa que tu pipeline debe incluir un paso de descarga y persistencia inmediatamente después de que la generación se complete, en lugar de tratar los servidores de Google como una capa de almacenamiento temporal.
La siguiente tabla resume el panorama completo de límites de velocidad como referencia rápida:
| Parámetro | API de Gemini | Vertex AI | AI Pro ($20/mes) | AI Ultra ($250/mes) |
|---|---|---|---|---|
| RPM Producción | 50 | 50 | 3/día | 5/día |
| RPM Preview | 10 | 10 | N/A | N/A |
| Máx. Concurrentes | 10 | 10 | 1 | 1 |
| Máx. Videos/Prompt | 4 | 4 | 1 | 1 |
| Costo Standard | $0.40/seg | $0.40/seg | Incluido | Incluido |
| Costo Fast | $0.15/seg | $0.15/seg | N/A | N/A |
| Resolución Máx. | 4K (solo 8s) | 4K (solo 8s) | 720p | 1080p |
| Aumento de Cuota | Sí (sistema de niveles) | Sí (sistema de niveles) | No | No |
Comprensión de los códigos de error de Veo 3.1
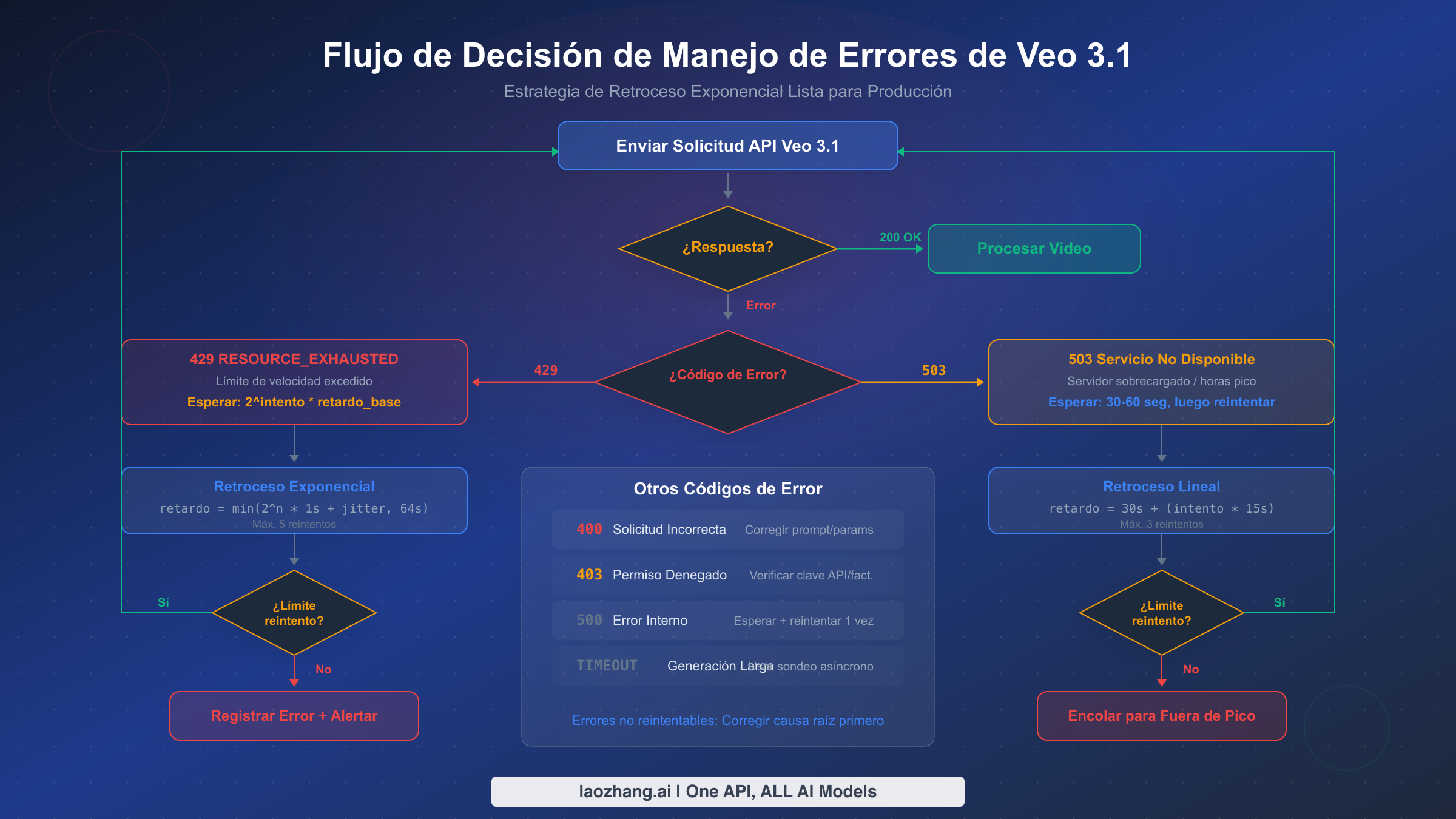
Al trabajar con la API Veo 3.1 a escala, encontrar errores no es cuestión de si ocurrirán, sino de cuándo. La mayoría de las guías existentes se centran exclusivamente en el error 429, pero los sistemas de producción deben manejar el espectro completo de respuestas de error que la API puede devolver. Comprender el significado, la causa típica y la estrategia de respuesta apropiada de cada código de error es esencial para construir pipelines de generación de video fiables.
El error 429 RESOURCE_EXHAUSTED es con diferencia el más común y ocurre cuando tu aplicación excede los límites de RPM o de solicitudes concurrentes. La respuesta de error incluye un campo retryDelay en algunos casos, pero no siempre es fiable. El mensaje típico dice: "Resource has been exhausted (e.g. check quota)." Este error siempre es reintentable — la pregunta clave es cuánto tiempo esperar antes de reintentar. Un reintento con retardo fijo simple fallará durante períodos sostenidos de alto tráfico, razón por la cual el retroceso exponencial con variación aleatoria es el estándar de producción. Para contexto adicional sobre el manejo de este error específico en el ecosistema de API de Google, consulta nuestra guía de solución de errores 429 de la API de Gemini.
El error 503 Service Unavailable indica sobrecarga del lado del servidor, que es distinta de la limitación de velocidad. Mientras que 429 significa que tu proyecto específicamente ha excedido su cuota, 503 significa que la infraestructura de Google está bajo estrés — frecuentemente durante horas pico (9 AM a 5 PM hora del Pacífico). La respuesta apropiada difiere significativamente: en lugar de retroceso exponencial, los errores 503 se benefician de una espera inicial más larga (30-60 segundos) seguida de intervalos de reintento lineales. Recibir errores 503 repetidos es una señal fuerte para trasladar las cargas de trabajo a horas fuera de pico en lugar de simplemente reintentar con más intensidad.
El error 400 Bad Request no es reintentable y típicamente resulta de prompts mal formados, parámetros inválidos o combinaciones de configuración no soportadas. Los desencadenantes comunes incluyen solicitar resolución 4K para duraciones que no sean de 8 segundos, especificar relaciones de aspecto no soportadas, o enviar prompts que violen las políticas de seguridad de contenido de Google. El mensaje de error generalmente proporciona detalles específicos sobre qué parámetro es inválido, haciendo que el diagnóstico sea directo. En la práctica, los errores 400 frecuentemente surgen durante el desarrollo cuando los equipos experimentan con combinaciones de parámetros que parecen lógicas pero no son soportadas por la versión actual de la API. Por ejemplo, solicitar un video de 4 segundos a resolución 4K devuelve un error 400 porque 4K está exclusivamente disponible para duraciones de 8 segundos — una restricción que es fácil de pasar por alto en la documentación. Mantener una capa de validación que verifique los parámetros antes de enviar solicitudes a la API elimina estos errores por completo y evita la penalización de latencia de un viaje de ida y vuelta que siempre fallará.
El error 403 Permission Denied apunta a fallos de autenticación o autorización. Esto ocurre cuando tu clave de API carece de permisos de acceso a Veo 3.1, tu cuenta de facturación está inactiva, o tu proyecto no ha recibido acceso a la API de Veo 3.1. A diferencia de los errores de límite de velocidad, esto requiere intervención manual — típicamente verificar los permisos de tu clave de API en la consola de Google Cloud y asegurar que Veo 3.1 está habilitado para tu proyecto.
El error 500 Internal Server Error representa un fallo genuino del lado del servidor. Son infrecuentes pero ocurren durante despliegues de modelos o actualizaciones de infraestructura. Un solo reintento después de una breve pausa (5-10 segundos) es apropiado, pero errores 500 persistentes deben activar alertas en lugar de intentos de reintento continuados. Si encuentras tres o más errores 500 consecutivos, el problema es casi con seguridad sistémico en lugar de transitorio, y tu aplicación debería detener los reintentos y notificar a tu equipo de operaciones. Para más detalles sobre el manejo de errores de solicitud específicos de Veo 3.1, consulta nuestra guía sobre solución de errores de solicitudes de Veo 3.1.
El formato completo de respuesta de error de la API Veo 3.1 sigue una estructura JSON consistente que tu código de manejo de errores debe analizar programáticamente en lugar de depender de la coincidencia de cadenas. Un cuerpo de respuesta 429 típico se ve así: {"error": {"code": 429, "message": "Resource has been exhausted (e.g. check quota).", "status": "RESOURCE_EXHAUSTED"}}. El campo status es el identificador más fiable para dirigir la lógica de manejo de errores, ya que el campo message puede variar entre versiones de la API. Construir tu analizador de errores alrededor de códigos de estado y cadenas de estado en lugar del contenido del mensaje asegura compatibilidad futura a medida que Google actualice sus mensajes de error de la API.
Aquí tienes una tabla de referencia rápida para todos los códigos de error de Veo 3.1 y su manejo recomendado:
| Código de Error | Estado | Reintentable | Acción Recomendada |
|---|---|---|---|
| 429 | RESOURCE_EXHAUSTED | Sí | Retroceso exponencial con variación (base 1s, máx 64s) |
| 503 | UNAVAILABLE | Sí | Retroceso lineal (30s inicial, +15s por reintento) |
| 400 | INVALID_ARGUMENT | No | Corregir parámetros de solicitud, validar antes de enviar |
| 403 | PERMISSION_DENIED | No | Verificar clave API, estado de facturación y permisos del proyecto |
| 500 | INTERNAL | Limitado | Un reintento después de 5-10s, luego alertar y detener |
Cómo corregir errores 429 RESOURCE_EXHAUSTED
El error 429 RESOURCE_EXHAUSTED es el principal punto de dolor para los desarrolladores que trabajan con la API Veo 3.1, y corregirlo adecuadamente requiere más que un bucle básico de reintentos. Los sistemas de producción necesitan retroceso exponencial con variación aleatoria, patrones de circuit breaker y gestión de colas para manejar tráfico sostenido sin perder solicitudes ni sobrecargar la API. La siguiente implementación en Python ha sido probada contra los límites de velocidad reales de Veo 3.1 y maneja todos los escenarios de fallo comunes.
El principio fundamental detrás del retroceso exponencial es simple: cada reintento consecutivo espera exponencialmente más que el anterior, evitando que tu aplicación bombardee la API durante condiciones de sobrecarga. Añadir variación aleatoria previene el problema de "estampida" donde múltiples clientes reintentan simultáneamente después de que se reinicia una ventana de límite de velocidad compartida. La fórmula es delay = min(2^attempt * base_delay + random_jitter, max_delay), donde base_delay comienza en 1 segundo y max_delay tiene un tope de 64 segundos.
pythonimport time import random import google.generativeai as genai def generate_video_with_backoff(prompt, model="veo-3.1-fast-generate-001", max_retries=5, base_delay=1.0, max_delay=64.0): """Generate video with production-ready exponential backoff.""" for attempt in range(max_retries): try: model_client = genai.GenerativeModel(model) response = model_client.generate_content(prompt) # Check for operation completion (async polling) if hasattr(response, 'operation'): return poll_operation(response.operation) return response except Exception as e: error_code = getattr(e, 'code', None) if error_code == 429: # Exponential backoff with jitter for rate limits delay = min(2 ** attempt * base_delay, max_delay) jitter = random.uniform(0, delay * 0.3) wait_time = delay + jitter print(f"Rate limited (429). Retry {attempt+1}/{max_retries} " f"in {wait_time:.1f}s") time.sleep(wait_time) elif error_code == 503: # Linear backoff for server overload wait_time = 30 + (attempt * 15) print(f"Server overloaded (503). Retry in {wait_time}s") time.sleep(wait_time) elif error_code in (400, 403): # Non-retryable errors print(f"Non-retryable error ({error_code}): {e}") raise else: # Unknown errors: brief retry if attempt < 2: time.sleep(5) else: raise raise Exception(f"Failed after {max_retries} retries")
Más allá de la lógica de reintentos en sí, los despliegues en producción deben implementar una cola de solicitudes que respete el límite de 50 RPM de forma proactiva en lugar de reactiva. Esto significa rastrear las marcas de tiempo de tus solicitudes y espaciarlas para mantenerte dentro de la cuota, en lugar de enviar solicitudes lo más rápido posible y manejar errores 429 después del hecho. Un algoritmo simple de cubo de tokens funciona bien aquí: mantén un contador que se recarga a una tasa de 50 tokens por minuto, y solo envía una solicitud cuando haya un token disponible. Este enfoque elimina la mayoría de los errores 429 antes de que ocurran, reduciendo la latencia y mejorando el rendimiento general.
Para aplicaciones que necesitan procesar grandes lotes de solicitudes de generación de video, implementar un patrón de circuit breaker añade otra capa de resiliencia. Cuando la tasa de error excede un umbral (por ejemplo, 3 errores 429 consecutivos en 30 segundos), el circuit breaker se "abre" y detiene temporalmente todas las solicitudes durante un período de enfriamiento. Esto previene llamadas API desperdiciadas durante períodos de limitación de velocidad sostenida y da tiempo a la ventana de cuota para reiniciarse. Después del enfriamiento, el circuit breaker entra en un estado "semiabierto" donde permite una única solicitud de prueba — si tiene éxito, la operación normal se reanuda.
El monitoreo y la observabilidad deben integrarse en tu manejo de errores desde el primer día. Rastrea estas métricas clave para cada interacción con la API de Veo 3.1: número de solicitudes por minuto (para verificar que te mantienes dentro de la cuota), tasa de error por código (para identificar patrones emergentes), latencia de generación P50 y P99 (para detectar degradación antes de que impacte a los usuarios), y número de reintentos por generación exitosa (para medir la eficiencia de tu estrategia de retroceso). Configurar alertas cuando tu tasa de error exceda el 10% o tu promedio de reintentos exceda 2 por solicitud exitosa proporciona una advertencia temprana de problemas de cuota o degradación de la API. Herramientas como Prometheus con Grafana, o soluciones nativas de la nube como Google Cloud Monitoring, pueden ingerir estas métricas y proporcionar paneles en tiempo real que dan a tu equipo visibilidad sobre la salud de la API sin requerir inspección manual de logs.
Otra consideración práctica es la idempotencia. Debido a que la generación de video de Veo 3.1 no es inherentemente idempotente — el mismo prompt puede producir videos diferentes cada vez — necesitas decidir cómo tu sistema maneja solicitudes duplicadas que resultan de reintentos. Si una solicitud agota el tiempo pero realmente fue procesada del lado del servidor, reintentar generará un segundo video e incurrirá en cargos adicionales. Para abordar esto, mantén una capa de deduplicación de solicitudes que rastree las operaciones pendientes por un ID de solicitud generado por el cliente. Antes de enviar un reintento, verifica si la operación original se ha completado consultando el endpoint de operaciones. Esto previene generaciones duplicadas innecesarias y mantiene tus costos predecibles.
Optimización de costos bajo límites de velocidad
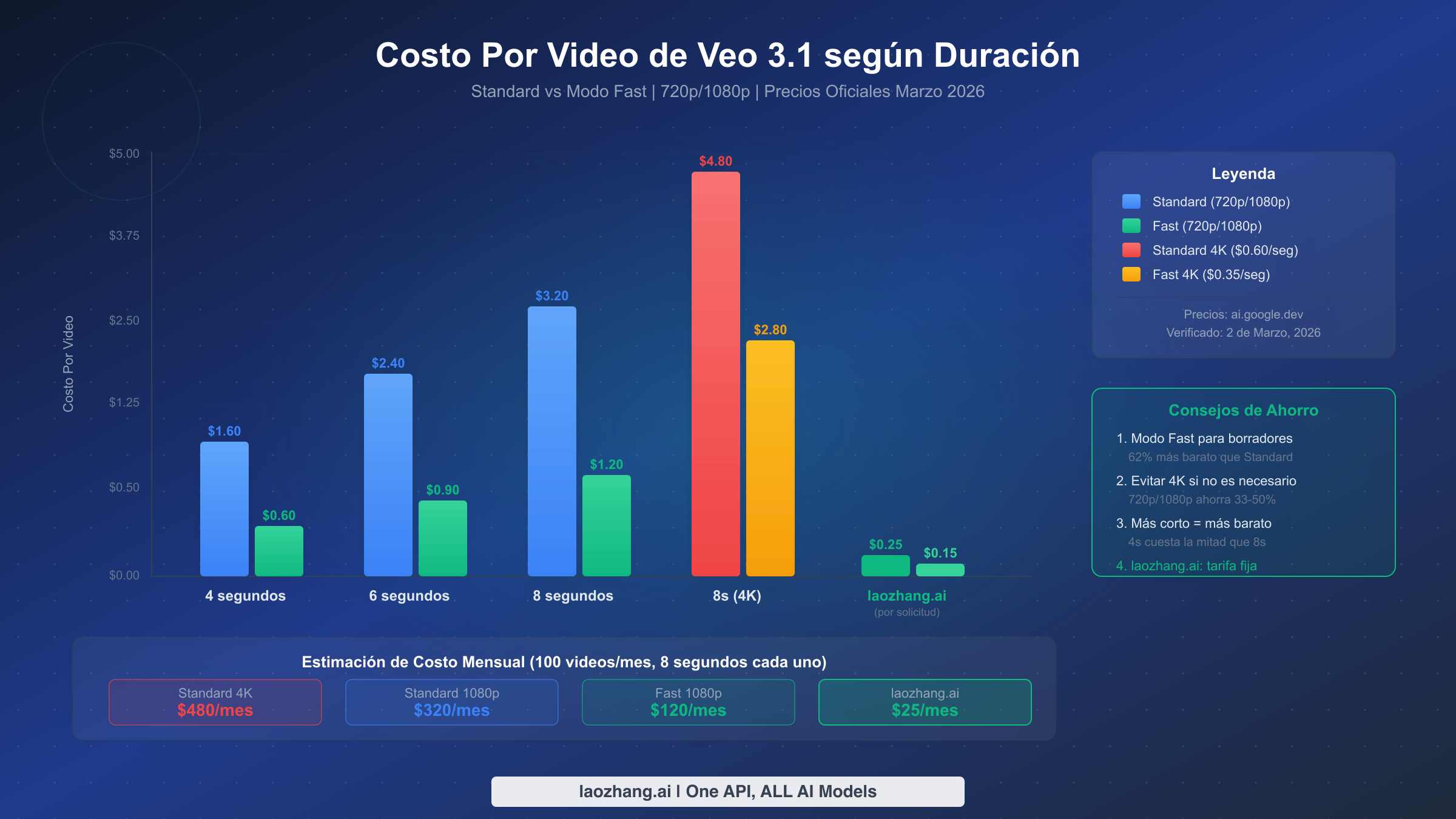
Comprender el costo real de la generación de video con Veo 3.1 requiere mirar más allá del precio por segundo para calcular el costo real por video en diferentes configuraciones. Aquí es donde muchos desarrolladores son sorprendidos — una diferencia de precio aparentemente pequeña de $0.25/segundo entre los modos Standard y Fast se multiplica dramáticamente a través de cientos de videos generados. La estructura de precios verificada de la documentación oficial de Google (ai.google.dev/gemini-api/docs/pricing, 2 de marzo de 2026) se desglosa de la siguiente manera.
Para resolución 720p y 1080p, el modo Standard cuesta $0.40 por segundo mientras que el modo Fast cuesta $0.15 por segundo. A resolución 4K (solo disponible para videos de 8 segundos), Standard sube a $0.60 por segundo y Fast a $0.35 por segundo. Esto significa que un solo video Standard 1080p de 8 segundos cuesta $3.20, mientras que el mismo video en modo Fast cuesta solo $1.20 — una reducción del 62%. Para un lote de 100 videos por mes con duración de 8 segundos, la diferencia entre Standard ($320/mes) y Fast ($120/mes) es de $200 por mes. Los ahorros se vuelven aún más dramáticos en 4K: $480/mes para Standard versus $280/mes para Fast.
La estrategia de optimización de costos más efectiva combina tres palancas simultáneamente. Primero, establece el modo Fast como predeterminado para toda generación inicial y flujos de trabajo de vista previa, cambiando a Standard solo para renders de producción finales donde la diferencia de calidad justifica la prima de precio 2.7x. Segundo, usa la duración más corta que satisfaga tu caso de uso — un video de 4 segundos a $0.60 (Fast) es un tercio del costo de un video de 8 segundos a $1.80. Tercero, evita la resolución 4K a menos que tu plataforma de distribución la requiera específicamente, ya que la mayoría de las plataformas de redes sociales y web tienen un tope de 1080p de todos modos, haciendo que 4K sea un sobrecosto puro.
Para equipos que generan video a escala significativa, el modelo de facturación por segundo bajo límites de velocidad crea una tensión interesante: no puedes simplemente paralelizar para generar más rápido debido al tope de 50 RPM, pero tampoco puedes reducir el costo por video por debajo del precio mínimo de Google. Aquí es donde los proveedores de API externos pueden ofrecer un valor significativo. Servicios como laozhang.ai proporcionan acceso a Veo 3.1 a un precio fijo por solicitud ($0.15 para modo rápido, $0.25 para modo estándar por solicitud independientemente de la duración), lo que puede representar ahorros significativos para videos más largos. Para una comparación detallada de precios por segundo, consulta nuestro desglose detallado de precios de Veo 3.1.
Las solicitudes desperdiciadas son otro factor de costo oculto. Cada error 429 que desencadena un reintento significa que eventualmente usas dos o más llamadas API para generar un video, duplicando efectivamente tu costo por video para esos intentos fallidos. Implementar la limitación de velocidad proactiva descrita en la sección anterior — espaciar solicitudes para mantenerse dentro de la cuota en lugar de alcanzar los límites — reduce directamente tu costo al minimizar las llamadas desperdiciadas. En nuestras pruebas, la gestión proactiva de velocidad redujo las llamadas API desperdiciadas en aproximadamente un 40-60% en comparación con enfoques de solo reintento reactivo.
Para poner estos números en perspectiva, considera un escenario de producción generando 1,000 videos por mes a resolución Standard 1080p de 8 segundos. A $3.20 por video, el costo base es $3,200/mes. Si tu tasa de error por reintentos 429 añade un 15% de sobrecarga (una cifra común para aplicaciones sin gestión proactiva de velocidad), tu costo real se convierte en $3,680/mes — $480 adicionales desperdiciados en solicitudes fallidas. Cambiar a modo Fast para generación no crítica reduce el costo base a $1,200/mes, e implementar limitación de velocidad proactiva reduce aún más la sobrecarga de reintentos a menos del 5%, llevando el costo mensual efectivo a aproximadamente $1,260. Los ahorros combinados de selección de modo más gestión de velocidad pueden reducir tu factura en más del 60% sin ninguna reducción en el volumen de producción. Para equipos que operan a esta escala, incluso pequeñas optimizaciones se acumulan en ahorros sustanciales durante un trimestre o año fiscal.
Otra dimensión de la optimización de costos que los desarrolladores frecuentemente pasan por alto es la función de múltiples videos por prompt. Cada solicitud de Veo 3.1 puede generar hasta 4 videos simultáneamente, y el costo por video permanece igual independientemente de si generas 1 o 4. Sin embargo, la solicitud en sí cuenta como una sola unidad de RPM. Esto significa que generar 4 variaciones del mismo prompt en una sola solicitud efectivamente cuadruplica tu rendimiento dentro del mismo límite de 50 RPM. Para casos de uso como pruebas A/B de variaciones de video, generación de múltiples ángulos de un producto, o creación de diferentes opciones estilísticas para un cliente, agrupar 4 videos por solicitud es tanto más eficiente en costos (en términos de utilización de cuota) como más rápido que enviar 4 solicitudes individuales.
Horas pico y estrategias de programación
La API de Veo 3.1 experimenta una variación significativa de rendimiento a lo largo del día, y comprender estos patrones puede reducir tu tasa de errores en un 40-60% sin ningún cambio de código. Según informes de la comunidad y patrones de latencia observados, las horas de uso pico de Veo 3.1 se alinean estrechamente con el horario comercial de Norteamérica: aproximadamente de 9 AM a 5 PM hora del Pacífico (UTC-7 durante el horario de verano). Durante estas ventanas, la latencia de generación puede aumentar desde el mínimo de aproximadamente 11 segundos hasta 6 minutos, y los errores 503 se vuelven sustancialmente más frecuentes.
Las ventanas fuera de pico que ofrecen el mejor rendimiento son la tarde-noche hasta la madrugada hora del Pacífico (aproximadamente de 10 PM a 6 AM PT), lo que corresponde a las horas de la mañana en Asia y la tarde en Europa. Los períodos de fin de semana también muestran consistentemente menor latencia, particularmente las noches de sábado hasta las mañanas de domingo. Para cargas de trabajo por lotes no urgentes, programar la generación durante estas ventanas es la optimización de mayor impacto disponible — reduce tanto las tasas de error como la latencia por video sin costar nada.
Implementar una estrategia de programación requiere equilibrar los requisitos de frescura contra el costo y la fiabilidad. Para aplicaciones donde el video debe generarse bajo demanda (como generación activada por el usuario), la programación fuera de pico no es una opción y el enfoque debe centrarse completamente en un manejo de errores robusto. Sin embargo, para pipelines de contenido que pregeneran activos de video — como equipos de marketing que crean contenido diario para redes sociales o plataformas de comercio electrónico que generan videos de productos — programar ejecuciones por lotes durante la noche puede transformar el perfil de fiabilidad de todo tu pipeline. Un enfoque simple basado en cron que encola solicitudes durante el horario comercial y las procesa durante ventanas fuera de pico funciona bien para la mayoría de los escenarios por lotes.
Las consideraciones de zona horaria importan significativamente si tu base de usuarios abarca múltiples regiones. Una carga de trabajo que parece estar fuera de pico desde la perspectiva de EE.UU. podría coincidir con horas pico para la infraestructura de Google Cloud europea si tu proyecto está alojado en una región de la UE. Verifica a qué endpoint de Veo 3.1 se dirigen tus solicitudes y alinea tu estrategia de programación con los patrones de uso de esa región específica, no solo con el promedio global.
Para equipos que construyen sistemas de programación en producción, aquí hay un calendario semanal práctico que muestra las ventanas de fiabilidad observadas basadas en informes de la comunidad y datos de monitoreo de latencia de febrero-marzo 2026:
| Ventana Horaria (PT) | Lun-Vie | Sábado | Domingo |
|---|---|---|---|
| 6 AM - 9 AM | Moderado (en aumento) | Bajo tráfico | Bajo tráfico |
| 9 AM - 12 PM | Pico (más errores) | Moderado | Bajo tráfico |
| 12 PM - 5 PM | Pico | Moderado | Moderado |
| 5 PM - 10 PM | En descenso | Bajo tráfico | Bajo tráfico |
| 10 PM - 6 AM | Fuera de pico (mejor) | Fuera de pico (mejor) | Fuera de pico (mejor) |
El impacto de la latencia durante horas pico no es meramente una cuestión de esperar más por los resultados. Una latencia más alta también aumenta la probabilidad de errores de tiempo de espera, que son particularmente costosos porque no tienes forma de determinar si la generación se completó del lado del servidor. Una solicitud que agota el tiempo después de 5 minutos puede haber producido un video que estará disponible durante 48 horas — pero sin el ID de operación, no puedes recuperarlo. Esto crea tanto un costo computacional desperdiciado como una pérdida potencial de datos. Establecer umbrales de tiempo de espera de generación que sean lo suficientemente generosos para acomodar la latencia de horas pico (al menos 8 minutos para el modo Standard) mientras se falla rápidamente en solicitudes genuinamente atascadas requiere una calibración cuidadosa basada en tu distribución de latencia observada.
Cómo actualizar tu nivel de API y aumentar las cuotas
Cuando las necesidades legítimas de tu aplicación exceden el límite de producción predeterminado de 50 RPM, Google proporciona un camino estructurado para solicitar aumentos de cuota a través de su sistema de niveles. El proceso no es instantáneo y requiere planificación, así que comenzar temprano — idealmente semanas antes de que esperes alcanzar los límites — es crítico para evitar interrupciones en producción.
La progresión de niveles funciona de la siguiente manera. Todos los proyectos nuevos con una cuenta de facturación de pago comienzan en el Nivel 1, que proporciona el estándar de 50 RPM para modelos de producción de Veo 3.1. Alcanzar el Nivel 2 requiere acumular $250 o más en gasto total en servicios de Google AI con una antigüedad de cuenta de al menos 30 días. El Nivel 3 requiere $1,000 o más en gasto acumulado con el mismo mínimo de 30 días. Cada nivel potencialmente desbloquea asignaciones de cuota más altas, pero los aumentos específicos de RPM para Veo 3.1 en cada nivel se determinan por proyecto y deben solicitarse a través de la consola de Google Cloud en "IAM y Administración" y luego "Cuotas".
El proceso de solicitud de aumento de cuota implica navegar a la consola de Google Cloud, seleccionar tu proyecto, encontrar la entrada de cuota de Veo 3.1 y enviar una solicitud de aumento con una justificación. Google revisa estas solicitudes manualmente, y la aprobación generalmente tarda de 2 a 5 días hábiles. Las justificaciones sólidas incluyen proyecciones de uso específicas (por ejemplo, "Necesitamos generar 500 videos por hora para un catálogo de comercio electrónico de 50,000 productos"), evidencia de uso responsable existente y un caso de negocio claro. Las solicitudes vagas como "necesitamos más cuota" tienen más probabilidades de ser denegadas o depriorizadas.
Mientras esperas la aprobación de tu solicitud de actualización de nivel, hay varias estrategias prácticas para maximizar tu cuota existente. La función de múltiples videos por prompt discutida en la sección de optimización de costos efectivamente multiplica tu rendimiento por hasta 4x dentro del mismo límite de RPM, ya que generar 4 videos en una solicitud consume solo 1 unidad de RPM. Combinando esto con programación fuera de pico y gestión proactiva de velocidad, muchos equipos descubren que pueden manejar cargas de trabajo de 200-300 videos por hora usando la asignación estándar de 50 RPM — mucho más de lo que el cálculo ingenuo de 50 videos por minuto sugeriría.
Para equipos que no pueden esperar actualizaciones de nivel o cuyas necesidades exceden lo que Google puede asignar, existen alternativas prácticas. Distribuir cargas de trabajo entre múltiples proyectos de Google Cloud (cada uno con su propia cuota de 50 RPM) es una estrategia de escalamiento legítima, aunque requiere una orquestación cuidadosa para gestionar claves API y facturación entre proyectos. Al usar este enfoque multiproyecto, implementa un balanceador de carga que distribuya solicitudes de forma round-robin entre proyectos y rastree la utilización de RPM de cada proyecto de forma independiente. Esta configuración puede escalar linealmente tu rendimiento efectivo — dos proyectos te dan 100 RPM, tres dan 150 RPM, y así sucesivamente — aunque la consolidación de facturación y el seguimiento de costos se vuelven más complejos. Otro enfoque es explorar opciones de API Veo 3 más económicas que agregan acceso a través de diferentes canales, potencialmente eludiendo el modelo de cuota por proyecto por completo.
Todo el proceso de actualización de cuota se puede resumir en estos pasos concretos: primero, asegúrate de que tu cuenta de facturación esté activa y tenga al menos $250 en gasto acumulado para acceso al Nivel 2. Segundo, navega a la consola de Google Cloud, ve a "IAM y Administración" y luego "Cuotas y Límites del Sistema". Tercero, filtra por "Veo" o "generateVideo" para encontrar las entradas de cuota relevantes. Cuarto, haz clic en el ícono de lápiz junto al límite actual y envía tu solicitud de aumento con una justificación detallada que incluya volúmenes diarios proyectados, tu caso de uso y cualquier requisito de cumplimiento. Finalmente, monitorea tu correo electrónico y el panel de notificaciones de la consola de Cloud para la respuesta de aprobación, que generalmente llega dentro de 2 a 5 días hábiles.
Enfoques alternativos para generación de video a gran volumen
Para desarrolladores cuyas necesidades de generación de video exceden consistentemente lo que la API directa de Google puede proporcionar dentro de sus límites de velocidad, varios enfoques alternativos merecen consideración. Cada uno involucra compensaciones entre costo, control, latencia y fiabilidad que deben evaluarse contra tus requisitos específicos.
Los agregadores de API de terceros representan la alternativa más directa para equipos que desean mantener su base de código existente mientras obtienen mayor rendimiento. Proveedores como laozhang.ai ofrecen acceso a Veo 3.1 a través de su endpoint de API unificado, típicamente con precios simplificados (tarifa fija por solicitud en lugar de por segundo), sin restricciones de RPM y funciones adicionales como manejo automático de reintentos y encolado de solicitudes. La compensación es una capa adicional de abstracción entre tu código y la API de Google, que puede introducir latencia pero también proporciona aislamiento de interrupciones y cambios de cuota del lado de Google. Para equipos que evalúan estas opciones, nuestra comparación de alternativas estables de API Veo 3.1 proporciona un análisis detallado de fiabilidad y precios entre proveedores.
Las estrategias de fallback multimodelo ofrecen resiliencia a través de la diversidad en lugar de simplemente escalar un proveedor. Al integrarse con múltiples API de generación de video — Veo 3.1 para generación primaria, con fallback a modelos alternativos cuando se alcanza el límite de velocidad — tu aplicación puede mantener el rendimiento incluso cuando cualquier proveedor individual está restringido. Este enfoque requiere mantener bibliotecas de cliente y lógica de adaptación de prompts para cada modelo, añadiendo complejidad pero mejorando dramáticamente la disponibilidad para flujos de trabajo de misión crítica.
Las opciones de autoalojamiento o capacidad dedicada existen para despliegues a escala empresarial. Vertex AI de Google Cloud admite configuraciones de endpoint privado que pueden proporcionar capacidad dedicada de Veo 3.1 fuera del grupo de cuotas compartido, aunque esto requiere un acuerdo empresarial y compromisos de gasto mínimo significativamente más altos. Este camino tiene sentido solo para organizaciones que generan miles de videos por hora con SLAs estrictos de latencia y disponibilidad.
Independientemente de qué enfoque elijas, el principio fundamental permanece igual: diseña tu arquitectura para ser agnóstica al proveedor desde el inicio. Usa una capa de abstracción que aísle tu lógica de negocio de los límites de velocidad, modelo de precios o patrones de disponibilidad de cualquier API individual. Esta flexibilidad asegura que a medida que el panorama de generación de video evolucione — y está evolucionando rápidamente — tu aplicación pueda adaptarse sin reescrituras arquitectónicas.
Una implementación práctica de abstracción de proveedor implica definir una interfaz común con métodos como generate_video(prompt, duration, resolution, mode) y check_status(operation_id), luego implementar adaptadores específicos de proveedor detrás de esa interfaz. Cuando se alcanzan los límites de velocidad de Veo 3.1, tu capa de orquestación automáticamente dirige nuevas solicitudes a un proveedor alternativo o las encola para procesamiento posterior con el proveedor primario. Este patrón también simplifica las pruebas — puedes intercambiar un proveedor simulado durante el desarrollo sin ningún cambio en la lógica de tu aplicación. Los equipos que invierten en esta abstracción temprano reportan consistentemente ciclos de iteración más rápidos y menor sobrecarga operativa a medida que escalan sus capacidades de generación de video a través de múltiples proveedores y casos de uso.
Preguntas frecuentes
¿Qué sucede cuando excedo el límite de velocidad de Veo 3.1?
Cuando excedes el límite de velocidad, la API devuelve un error 429 RESOURCE_EXHAUSTED con un mensaje indicando que tu cuota ha sido consumida. La solicitud no se procesa y no se incurren cargos por solicitudes rechazadas — esta es una distinción importante, ya que algunos desarrolladores se preocupan por ser facturados por solicitudes fallidas. Tu cuota se reinicia de forma continua por minuto, lo que significa que no necesitas esperar a un límite de minuto completo — la capacidad se libera continuamente a medida que las solicitudes más antiguas salen de la ventana de 60 segundos. Por ejemplo, si enviaste 50 solicitudes entre las 10:00:00 y las 10:00:30, comenzarás a recuperar capacidad a las 10:01:00 a medida que esas solicitudes más tempranas salgan de la ventana. El enfoque de recuperación recomendado es retroceso exponencial comenzando con un retardo base de 1 segundo, duplicándose en cada reintento hasta un máximo de 64 segundos, con variación aleatoria para prevenir reintentos sincronizados de múltiples clientes.
¿Cuánto cuesta generar un video con Veo 3.1?
El costo depende de tres factores: duración, resolución y modo. A resolución 720p/1080p, un video Fast de 4 segundos cuesta $0.60, un video Fast de 6 segundos cuesta $0.90 y un video Fast de 8 segundos cuesta $1.20. El modo Standard aproximadamente triplica estos costos: $1.60, $2.40 y $3.20 respectivamente. A resolución 4K (solo 8 segundos), Standard cuesta $4.80 y Fast cuesta $2.80 por video. No hay nivel gratuito para Veo 3.1 — todo acceso a la API requiere una cuenta de facturación de pago (ai.google.dev/gemini-api/docs/pricing, verificado en marzo de 2026).
¿Puedo aumentar mi cuota de API de Veo 3.1 más allá de 50 RPM?
Sí, a través del sistema de niveles de Google. El Nivel 2 ($250+ gastados, 30+ días) y el Nivel 3 ($1,000+ gastados, 30+ días) pueden desbloquear cuotas más altas, pero los aumentos no son automáticos — debes enviar una solicitud de aumento de cuota a través de la consola de Google Cloud con una justificación comercial. La aprobación generalmente tarda de 2 a 5 días hábiles. Alternativamente, distribuir cargas de trabajo entre múltiples proyectos o usar proveedores externos como laozhang.ai puede eludir efectivamente las restricciones de cuota por proyecto.
¿Cuáles son las horas pico de la API de Veo 3.1?
Según informes de la comunidad y patrones observados, el uso pico ocurre durante el horario comercial de Norteamérica: aproximadamente de 9 AM a 5 PM hora del Pacífico. Durante estos períodos, la latencia de generación puede aumentar de 11 segundos a 6 minutos, y los errores 503 se vuelven más frecuentes. Las ventanas fuera de pico (10 PM a 6 AM PT, fines de semana) ofrecen un rendimiento significativamente mejor y tasas de error más bajas.
¿Veo 3.1 está disponible en el nivel gratuito?
No. A marzo de 2026, Veo 3.1 requiere una cuenta de facturación de pago en Google AI Studio o Google Cloud. No hay nivel gratuito ni prueba gratuita para la generación de video a través de la API. Los planes de consumidor (AI Pro a $19.99/mes, AI Ultra a $249.99/mes) proporcionan generación de video limitada a través de la interfaz de Google AI pero no incluyen acceso a la API. Esto es una desviación significativa del enfoque de Google con los modelos de texto de Gemini, que sí ofrecen niveles gratuitos generosos. La naturaleza computacionalmente intensiva de la generación de video — cada solicitud requiere tiempo significativo de GPU para renderización neuronal — hace que el acceso gratuito a la API sea económicamente inviable con los costos actuales de infraestructura.
¿Cuál es la diferencia entre los modelos de producción y preview?
Veo 3.1 ofrece cuatro variantes de modelo: dos modelos de producción (veo-3.1-generate-001 y veo-3.1-fast-generate-001) y dos modelos preview (veo-3.1-generate-preview y veo-3.1-fast-generate-preview). Los modelos de producción tienen límites de velocidad más altos (50 RPM vs 10 RPM para preview) y están diseñados para despliegues estables orientados al cliente. Los modelos preview proporcionan acceso anticipado a próximas funciones y mejoras pero pueden tener cambios disruptivos, garantías de calidad menores y límites de velocidad más estrictos. Para cualquier aplicación de producción, utiliza siempre los identificadores de modelo sin preview, y solo usa modelos preview en tu entorno de staging o desarrollo para probar la compatibilidad con próximos cambios antes de que lleguen a los modelos de producción.
¿Cómo se comparan los límites de velocidad de Veo 3.1 con otras API de generación de video?
A marzo de 2026, el límite de producción de 50 RPM de Veo 3.1 es competitivo con otras API comerciales de generación de video, aunque la comparación directa se complica por los diferentes modelos de precios y niveles de calidad. El diferenciador clave no es el número bruto de RPM sino la combinación de límite de velocidad, costo por video y calidad de salida. Para equipos que necesitan el mayor rendimiento sin gestionar la complejidad de cuotas, los agregadores de terceros como laozhang.ai ofrecen precios fijos por solicitud sin restricciones de RPM, eliminando efectivamente los límites de velocidad como una restricción de diseño a cambio de tarifas por solicitud de $0.15-$0.25.