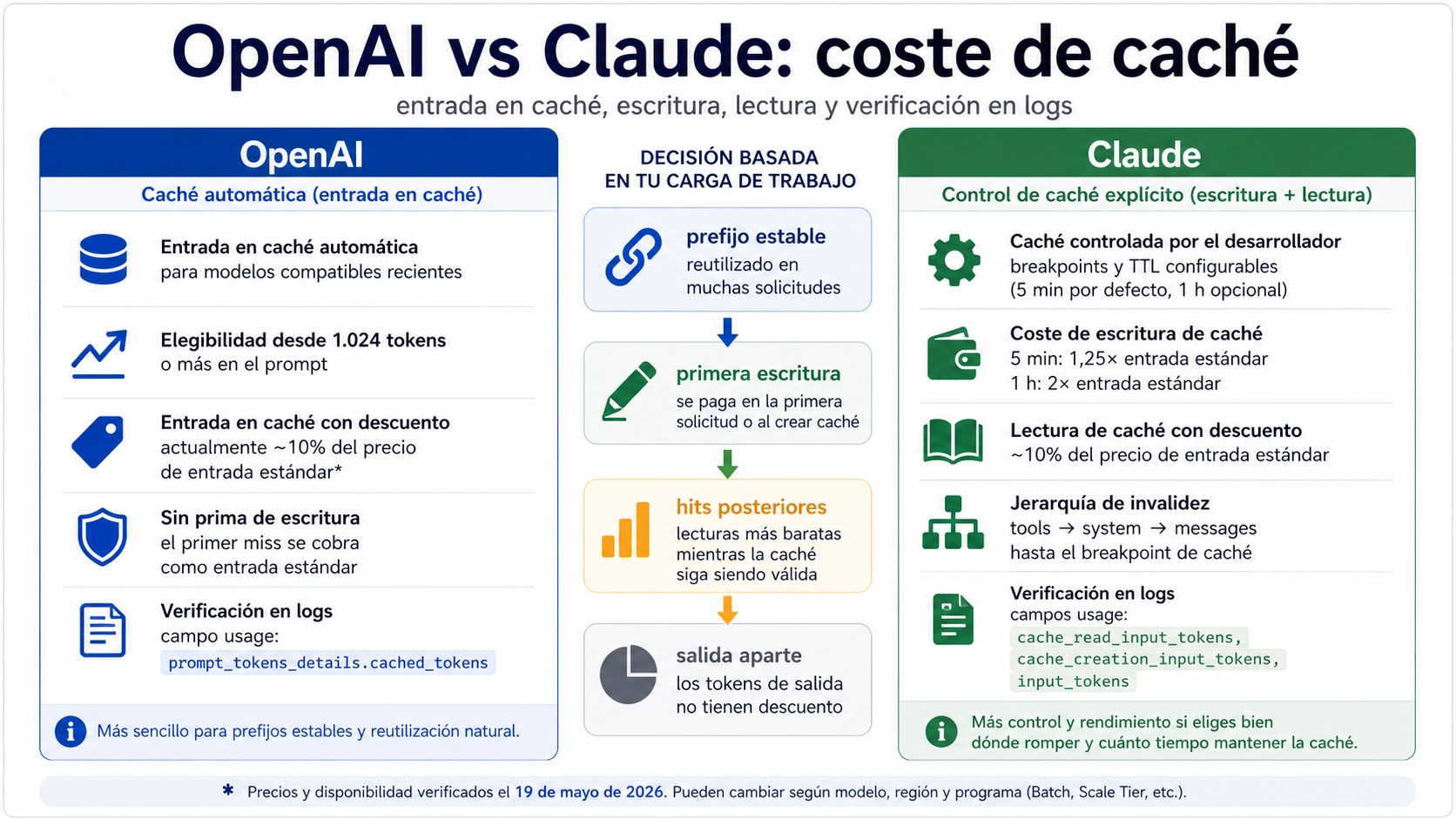
Prompt caching no es una única rebaja aplicada a toda la llamada. OpenAI y Claude pueden abaratar la parte repetida del prompt, pero la factura se mueve por líneas distintas. Con los precios oficiales revisados el 2026-05-19, las filas estándar de GPT-5.5, GPT-5.4 y GPT-5.4 mini en OpenAI muestran cached input a una décima parte del input normal y no añaden una prima separada por escribir la caché. Claude también cobra las lecturas de caché a 0,1x del input base, pero la primera creación de la caché tiene coste: 1,25x para la caché de 5 minutos y 2x para la caché de 1 hora.
La decisión útil no es “qué proveedor anuncia más descuento”, sino “en qué línea de coste cae mi prefijo repetido”. Si tu API reenvía un system prompt largo, tools estables, políticas de producto, documentación, un resumen de código o ejemplos few-shot, OpenAI suele ser más fácil de probar porque la caché es automática. Claude tiene más sentido cuando quieres decidir explícitamente los límites de caché, precalentar contexto y controlar el TTL. En ambos casos, no presupuestes ahorro hasta ver usage.prompt_tokens_details.cached_tokens en OpenAI o cache_read_input_tokens, cache_creation_input_tokens e input_tokens en Claude.
| Situación | Mirar primero | Motivo | Señal obligatoria |
|---|---|---|---|
| Prefijo largo y estable que se repite | OpenAI | caché automática y sin prima de escritura | cached_tokens > 0 |
| Necesitas breakpoints y TTL controlados | Claude | escritura y lectura se diseñan de forma explícita | cache_creation_input_tokens y cache_read_input_tokens |
| Solo hay una o dos repeticiones | no asumir ahorro | la escritura, los misses y la salida pueden dominar | hit rate y output share |
| El inicio del prompt cambia en cada llamada | arreglar layout | un prefijo inestable destruye la caché | prefix hash |
| Usas Batch, long context o cloud marketplace | calcular aparte | la tabla base no cubre todo | precio oficial vigente |
Veredicto rápido: compara líneas de factura
OpenAI encaja bien cuando el prefijo repetido ya es estable. En modelos recientes compatibles, el sistema intenta aplicar la caché automáticamente; el prompt debe tener suficiente longitud, y la parte inicial debe coincidir. La primera petición que no acierta la caché se cobra como input normal; las siguientes peticiones con hit usan la fila de cached input. Para un servicio con el mismo system prompt y preguntas de usuario diferentes, la primera mejora práctica es registrar los campos de uso y comprobar si cached_tokens crece.
Claude encaja cuando la caché forma parte del diseño. Puedes indicar qué bloque se guarda, cuánto tiempo se reutiliza y dónde está el cache breakpoint. El TTL de 5 minutos sirve para una ventana corta de conversación o pasos de agent; el TTL de 1 hora sirve si vas a precalentar contexto y reutilizarlo durante más tiempo. El coste inicial es la diferencia clave: si hay pocas lecturas después de la escritura, el descuento de lectura no compensa.
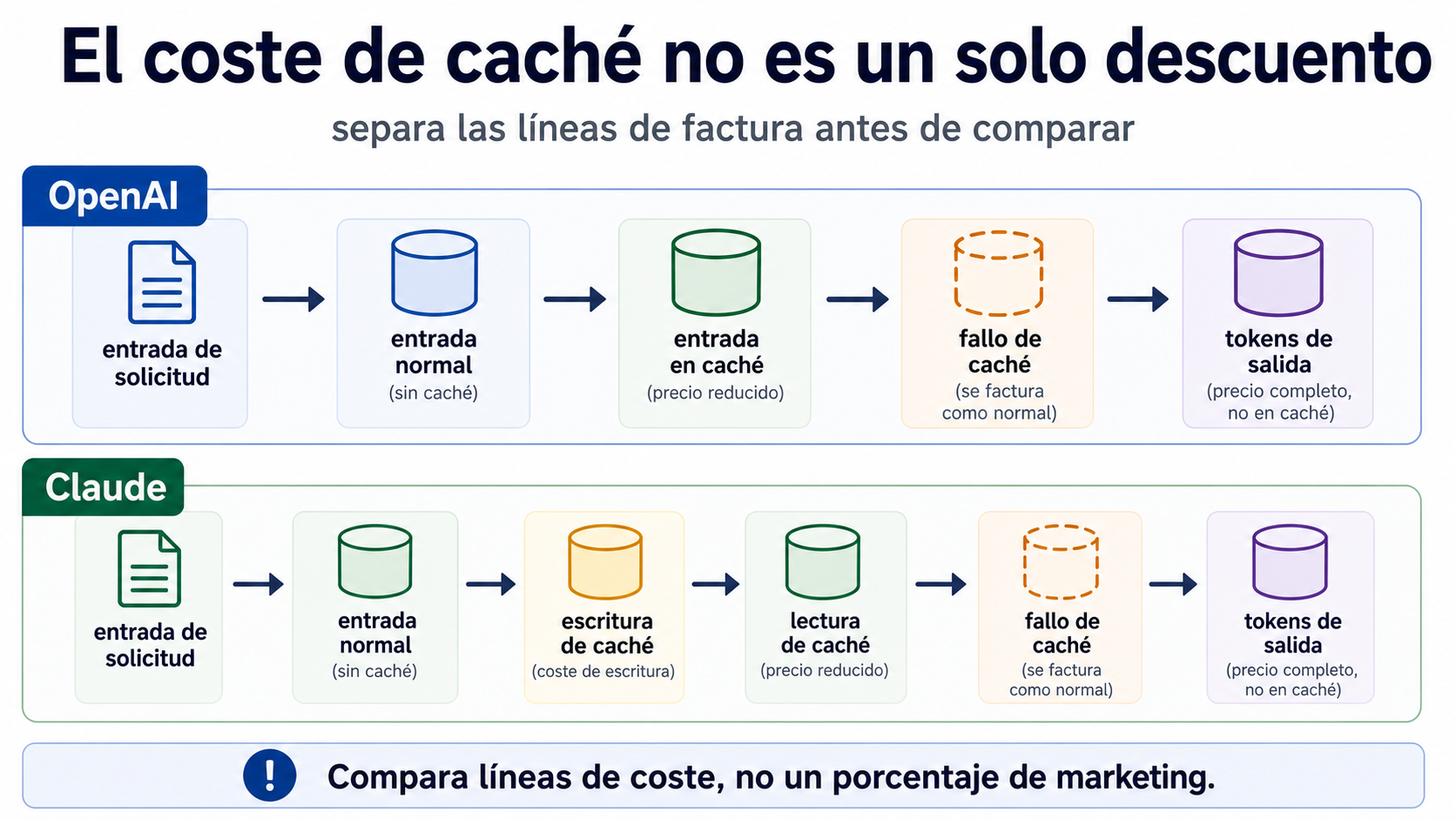
Las frases “ahorrar 90%” o “OpenAI rebaja 50%” no bastan para una factura real. El 50% procede de filas y comunicados antiguos; el 90% suele describir solo la parte de lectura o cached input; y los tokens de salida no se descuentan por prompt caching. El cálculo debe separar entrada normal, entrada en caché, escritura, lectura, miss y salida.
Vocabulario de coste
En OpenAI, cached input es una fila de precio para la parte del prompt que el sistema puede reutilizar. No necesitas marcar manualmente un bloque ni pagar una prima separada por escribirlo en la caché. Si el prefijo es elegible y coincide, esa parte se factura a la fila de cached input en peticiones posteriores.
En Claude, el modelo contable es más explícito. Cache write es el coste de crear o refrescar la caché. Cache read es la lectura barata de una caché existente. Además siguen existiendo input normal, misses y output. Por eso no conviene comparar OpenAI y Claude con un solo porcentaje: hay que saber cuántas veces lees el mismo bloque después de crearlo.
| Línea de coste | OpenAI | Claude | Implicación |
|---|---|---|---|
| Input normal | misses, entrada nueva o parte no elegible | entrada nueva y misses | siempre puede aparecer |
| Escritura de caché | sin prima separada en la fila estándar | 1,25x para 5m, 2x para 1h | coste inicial de Claude |
| Lectura de caché | cached input | cache read 0,1x | solo aparece con hit |
| Miss | vuelve a input normal | input normal o nueva escritura | explica desviaciones |
| Output | se cobra aparte | se cobra aparte | puede dominar el total |
Esta separación cambia la forma de trabajar. Antes de elegir proveedor, pregunta si tu prefijo es estable, si se repite dentro de la ventana de caché, si la salida no domina el coste y si tus logs pueden demostrar hits reales.
Precios actuales como fotografía
Los importes de esta sección son una fotografía de 2026-05-19. En la tabla de OpenAI, GPT-5.5 estándar en short context mostraba $5,00 de input, $0,50 de cached input y $30,00 de output por 1M tokens. GPT-5.4 mostraba $2,50, $0,25 y $15,00. GPT-5.4 mini mostraba $0,75, $0,075 y $4,50. El punto operativo es que cached input está a una décima parte del input normal y no hay una línea separada de escritura.
La tabla de Claude muestra input, escritura de caché, lectura de caché y output. Opus 4.7, 4.6 y 4.5 mostraban $5 de input, $6,25 de escritura 5m, $10 de escritura 1h, $0,50 de lectura y $25 de output. Sonnet 4.6 y 4.5 mostraban $3, $3,75, $6, $0,30 y $15. Haiku 4.5 mostraba $1, $1,25, $2, $0,10 y $5. Ese desglose obliga a separar la primera petición de las lecturas posteriores.
No generalices estos precios. Las filas Pro, el long context, Batch, Scale Tier, data residency, cloud marketplace y contratos empresariales pueden cambiar la cuenta. Si el dato afecta a presupuesto, guarda la fecha de revisión junto a la tabla.
Ejemplo de prefijo repetido
Supongamos un prefijo estable de 100k tokens y 10 peticiones dentro de la ventana de reutilización. Ignoramos por un momento la entrada nueva y la salida. Con GPT-5.4, input normal cuesta $2,50 por 1M tokens y cached input $0,25. La primera petición sin hit cuesta unos $0,25 por ese prefijo. Las 9 lecturas posteriores, si aciertan, cuestan unos $0,025 cada una, $0,225 en total. El prefijo repetido suma aproximadamente $0,475 en 10 peticiones.
Con Claude Sonnet 4.6 y caché de 5 minutos, input cuesta $3 por 1M, write $3,75 y read $0,30. La primera escritura de 100k tokens cuesta aproximadamente $0,375. Nueve lecturas cuestan $0,03 cada una, $0,27 en total. El prefijo repetido suma unos $0,645. Con TTL de 1 hora la escritura inicial sube, pero el bloque puede sobrevivir más tiempo.
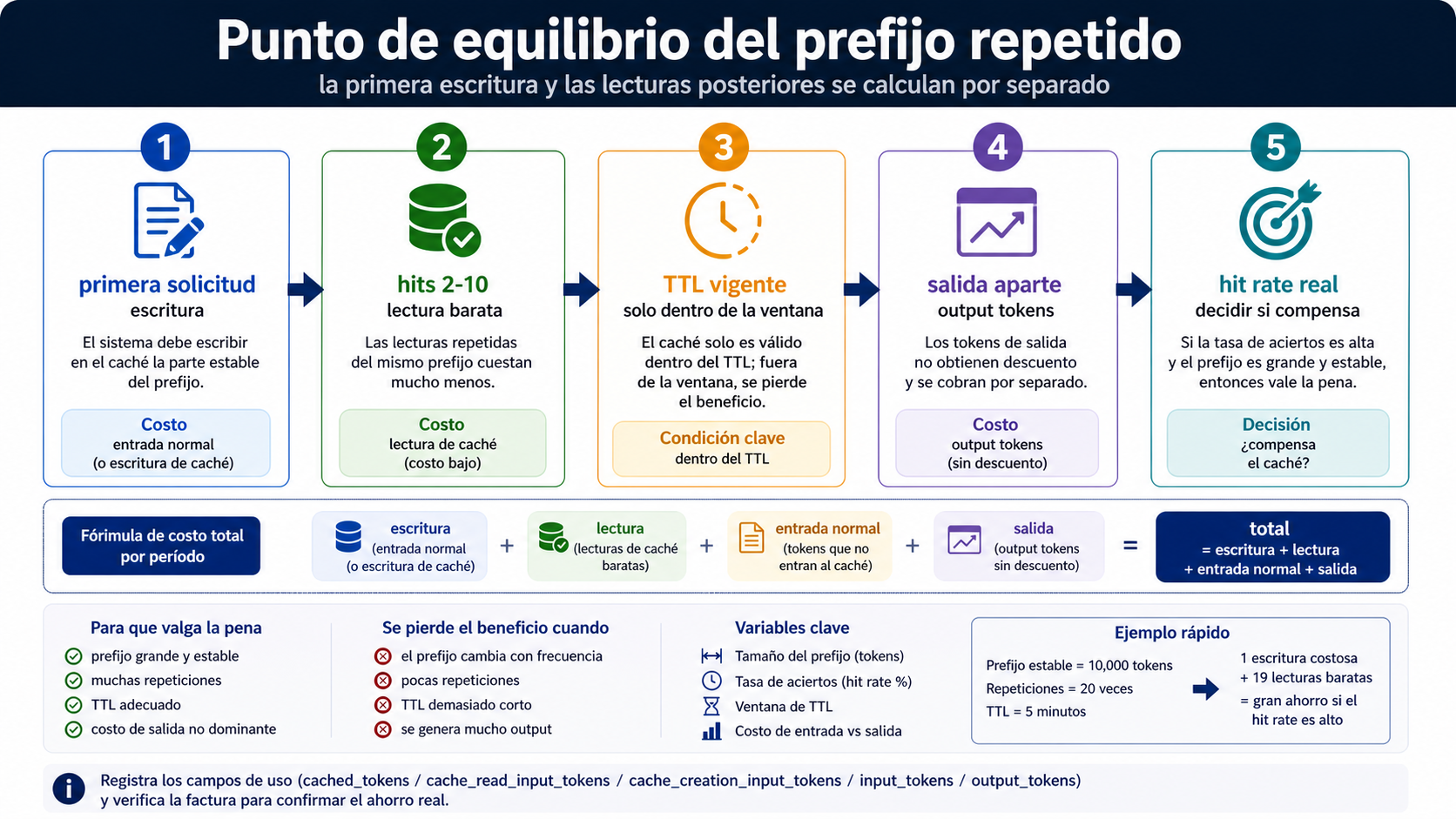
El ejemplo no dice que OpenAI sea siempre más barato. Dice que OpenAI desplaza el coste hacia una primera entrada normal y lecturas automáticas, mientras Claude hace visible la escritura y la lectura. El coste real depende de hit rate, número de repeticiones, TTL, output y misses.
El layout del prompt crea o destruye hits
La caché no se activa por “parecido semántico”. En OpenAI, lo importante es que el prefijo inicial se repita. Pon primero el system prompt, tools, políticas, esquemas, documentación estable y ejemplos. Mueve después el texto de usuario, timestamps, trace ids, datos externos y valores que cambian. prompt_cache_key puede ayudar a enrutar prefijos comunes, pero no arregla un prefijo que cambia en los primeros tokens.
En Claude, el orden de tools, system y messages hasta el cache breakpoint es crucial. Un cambio en una capa temprana puede invalidar segmentos posteriores. Si insertas datos dinámicos en tools o system, puedes pagar escrituras repetidas en lugar de lecturas baratas. Diseña capas: lo inmóvil delante, lo variable detrás.
Registra un prefix hash para cada versión. Añade model, endpoint, región, versión de tools, versión de system prompt y política de caché. Si el hash cambia, no atribuyas la factura a una subida de precios antes de comprobar el shape de la petición.
Logs antes que intuición
En OpenAI, el campo mínimo es usage.prompt_tokens_details.cached_tokens. Si es cero, esa petición no tuvo entrada en caché aunque el texto te pareciera repetido. Guarda también model, endpoint, request_id, total input, output, prefix hash y prompt_cache_key si lo usas.
En Claude, necesitas mirar tres campos a la vez. cache_creation_input_tokens indica escritura. cache_read_input_tokens indica lectura desde caché. input_tokens indica entrada fresca o no cacheada. La suma de esos campos explica si una petición fue hit, write, miss o una mezcla.
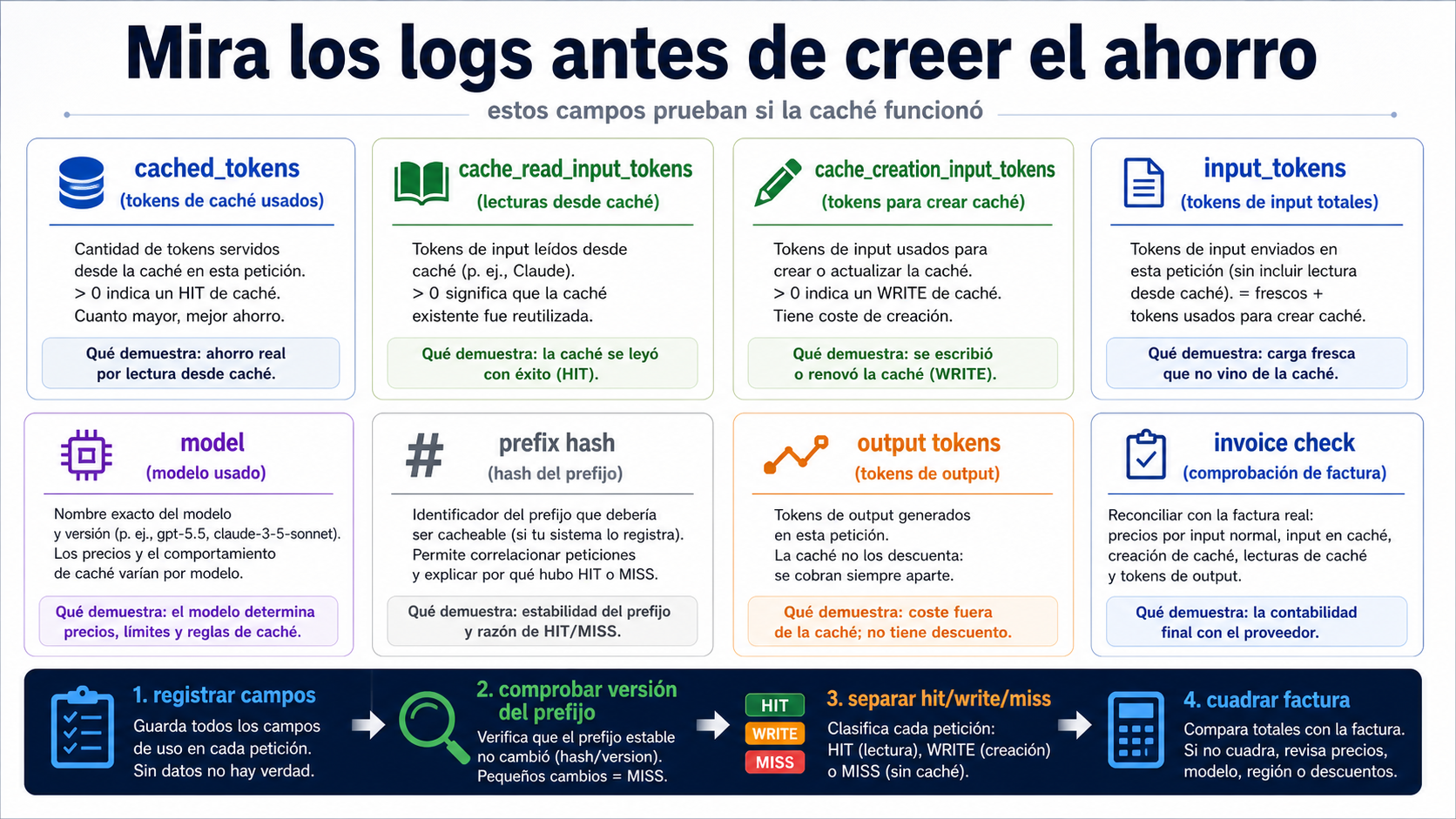
Una tabla mínima de observabilidad incluye provider, model, request_id, endpoint, prefix_hash, cache policy, cached/read/creation/input/output tokens, retries, latency, invoice period, estimated cost y actual invoice cost. Con un día de datos puedes decidir si vale la pena rediseñar el prompt.
Modificadores y límites
La matemática base no cubre todos los caminos. Batch puede bajar precio pero cambiar latencia. Scale Tier o acuerdos empresariales pueden tener reglas distintas. Data residency y cloud marketplace pueden alterar el coste. Long context puede tener filas separadas. Claude 1-hour cache aumenta la ventana de lectura, pero también la escritura inicial. OpenAI extended retention depende de modelos compatibles y documentación vigente.
Los límites tampoco son iguales. OpenAI indica que cached tokens siguen contando para TPM, así que un menor coste de input no equivale a capacidad ilimitada. Claude documenta efectos específicos de cache hit en algunos contextos de rate limit. Mantén una tabla de coste y otra de capacidad: requests por minuto, input, cache read, output, retries y errores.
Cuándo empezar por OpenAI
Empieza por OpenAI si ya tienes un prefijo largo y estable, no necesitas varios segmentos de caché y quieres validar con pocos cambios. Casos típicos: bot de soporte con políticas fijas, análisis con el mismo esquema, workflows de agent con tools constantes, o API que siempre envía un system prompt grande.
No lo trates como descuento mágico. Si la entrada es corta, el prefijo cambia, la salida es larga, el modelo no soporta la fila esperada o el hit rate es bajo, el ahorro real será pequeño. La razón para elegir OpenAI debe ser “nuestros logs muestran cached input”, no “la caché es automática”.
Cuándo empezar por Claude
Empieza por Claude si el control de límites de caché es parte de la arquitectura. Tools largos, system estable, resúmenes de codebase, agentes por etapas y contexto precalentado son buenos candidatos. Puedes decidir qué bloque se conserva 5 minutos, qué bloque necesita 1 hora y cuándo conviene refrescar.
El coste es más disciplina. Hay que contar write, escoger TTL, respetar la jerarquía de invalidación y evitar datos dinámicos en capas tempranas. Sin cache_creation_input_tokens y cache_read_input_tokens, Claude parece más barato en teoría que en la factura.
Checklist de implementación
- Mueve contenido estable al prefijo: system, tools, esquemas, ejemplos y contexto fijo.
- Deja datos dinámicos después del bloque estable.
- Calcula y registra prefix hash.
- En OpenAI, mira
cached_tokens; en Claude, separa creation/read/input. - Compara primera petición y hits posteriores en el mismo test.
- Cuenta output tokens fuera del ahorro de caché.
- Recalcula al cambiar model, endpoint, TTL, price row o ruta cloud.
Para una comparación más amplia de costes entre OpenAI, Claude y Gemini, consulta la guía de costes API por proveedor. La factura de prompt caching debe leerse aparte de una comparación de calidad, latencia o capacidad del modelo.
Preguntas frecuentes
¿OpenAI prompt caching sigue siendo un 50% de descuento?
No como regla general. El 50% aparece en publicaciones antiguas asociadas a modelos y filas anteriores. El 2026-05-19, las filas estándar de GPT-5.5, GPT-5.4 y GPT-5.4 mini mostraban cached input a una décima parte del input normal. Revisa siempre la tabla vigente.
¿Por qué Claude cobra escritura de caché?
Porque Claude separa crear la caché y leerla. La escritura ocurre al crear o renovar el bloque; la lectura ocurre cuando una petición posterior reutiliza ese bloque. Ese control permite diseños más explícitos, pero exige calcular el punto de equilibrio.
¿Los output tokens tienen descuento?
No. Prompt caching reduce la parte repetida de la entrada. Los tokens de salida se cobran aparte. Si generas respuestas largas, el porcentaje de ahorro total será menor que el descuento aplicado al input.
¿Sirve la caché por debajo de 1024 tokens?
OpenAI documenta 1024 tokens como umbral de elegibilidad para prompt caching. Claude tiene mínimos que varían por modelo. No conviertas el umbral de un modelo en una regla universal.
¿Claude solo funciona con cache_control manual?
No. La documentación actual incluye control automático de nivel superior y breakpoints explícitos. La diferencia práctica es que Claude sigue esperando que diseñes qué parte del prompt merece sobrevivir entre peticiones.
¿Qué reviso si la factura no coincide con el cálculo?
Prefix hash, model, endpoint, TTL, misses, escrituras repetidas de Claude, cached_tokens de OpenAI, output tokens y modificadores de precio. Si solo miras total tokens, no encontrarás la línea que se desvió.
¿Tiene sentido cambiar de proveedor solo por la caché?
Solo si tienes prefijo largo, alto hit rate, suficientes repeticiones, output controlado y logs que demuestran ahorro. Primero corrige layout y observabilidad; después compara el coste real de OpenAI y Claude.