
Usa GPT-5.4 cuando el resultado dependa de un razonamiento mas fuerte, menos retries o la ventana de contexto mucho mayor de 1.05M**. Usa GPT-5.4 mini cuando quieras un default mas barato, rapido y de mayor volumen para coding, computer use y agent workflows.**
Esto no es una historia de migracion viejo contra nuevo. Ambos son modelos actuales de la familia GPT-5.4. La pregunta es cuanta headroom de flagship necesita de verdad tu workflow y si esa headroom extra se paga sola.
Resumen rápido
Si solo quieres una regla operativa, quédate con esta:
- GPT-5.4 para la rama premium: más contexto, más techo, menos margen para fallar
- GPT-5.4 mini para la rama de escala: más barata, más throughput y suficientemente fuerte para muchos workers
| Categoría | GPT-5.4 | GPT-5.4 mini | Lectura práctica |
|---|---|---|---|
| Fecha de lanzamiento | 5 de marzo de 2026 | 17 de marzo de 2026 | Las dos son actuales |
| Rol oficial | Default principal de alta calidad | Ruta para coding y agentes de alto volumen | Es una división por trabajo, no por antigüedad |
| Precio de input | $2.50 / 1M | $0.75 / 1M | GPT-5.4 cuesta unas 3.3x veces más |
| Cached input | $0.25 / 1M | $0.075 / 1M | Mini gana claramente en contexto repetido |
| Precio de output | $15.00 / 1M | $4.50 / 1M | La diferencia también es grande |
| Contexto | 1,050,000 | 400,000 | GPT-5.4 gana en trabajos de contexto largo |
| Knowledge cutoff | 31 ago 2025 | 31 ago 2025 | No hay una historia de “mini más vieja” |
| Herramientas visibles | Amplio tool surface | El mismo amplio tool surface | Mini no es una versión recortada en herramientas |
| Top-tier caps publicados | 15,000 RPM / 40,000,000 TPM | 30,000 RPM / 180,000,000 TPM | Mini está mejor posicionada para escala |
La pregunta importante no es qué modelo es “mejor en abstracto”, sino qué quieres optimizar primero: calidad o economía + throughput.
La división real: inteligencia flagship frente a throughput de producción
La comparación se entiende mejor si cambias el marco.
GPT-5.4 sirve mejor cuando:
- el contexto de 400K no alcanza
- el coste del error es alto
- el workflow mezcla reasoning, coding y varios pasos con herramientas
GPT-5.4 mini sirve mejor cuando:
- el número de peticiones importa más que la perfección por solicitud
- tienes workers o subagentes en paralelo
- buscas mantener una tool surface moderna sin pagar precio de flagship en cada llamada
Por eso esta no es una decisión de “subir o bajar de categoría”. Es una decisión de qué modelo debe quedarse con la rama difícil y cuál con la rama escalable.
Qué benchmarks sí cambian la decisión
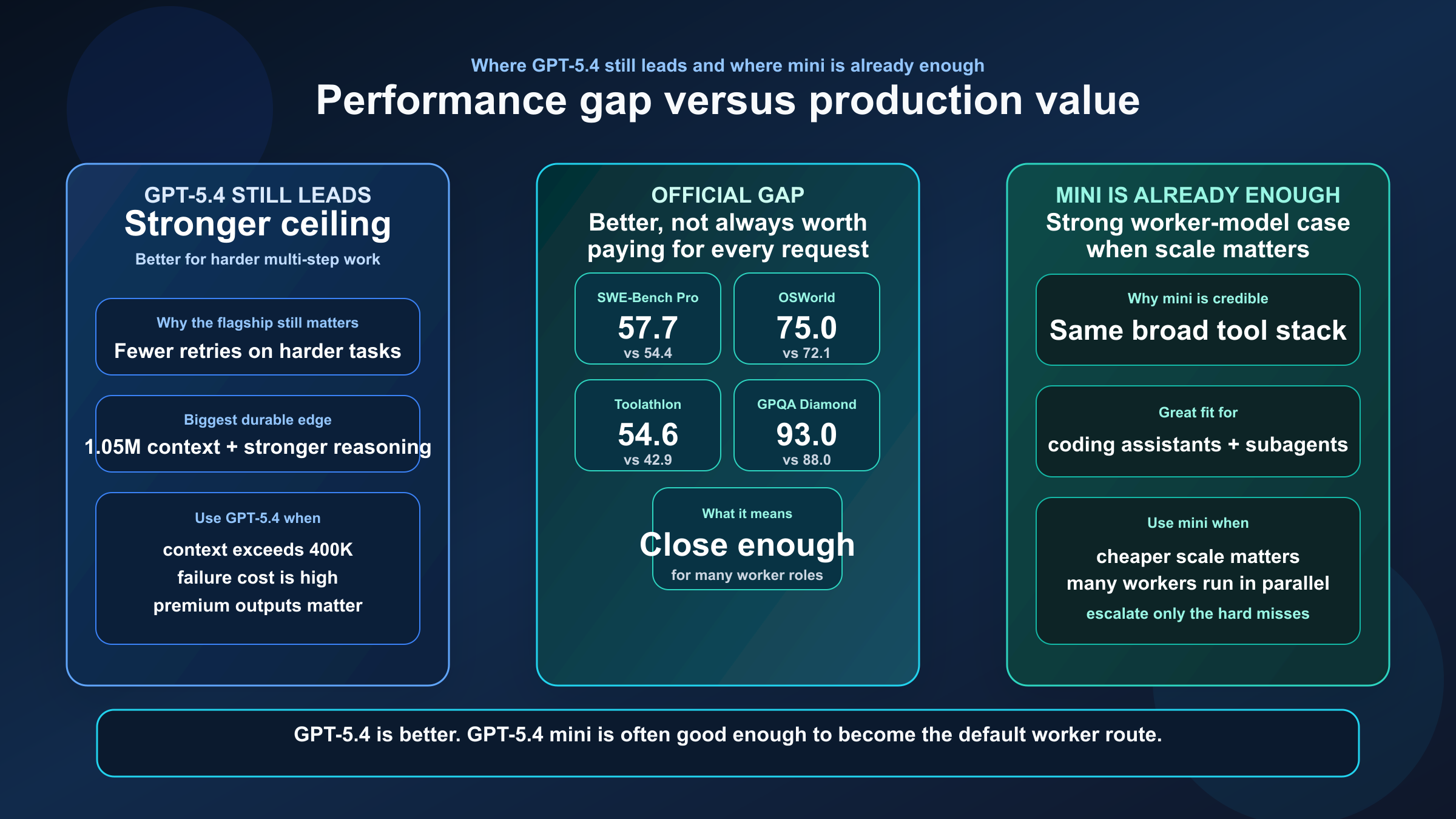
En el lanzamiento oficial de GPT-5.4 mini y nano, OpenAI compara ambas rutas en varios benchmarks que sí se parecen a trabajo real:
| Benchmark | GPT-5.4 | GPT-5.4 mini | Qué significa |
|---|---|---|---|
| SWE-Bench Pro | 57.7% | 54.4% | GPT-5.4 gana, pero mini sigue muy cerca |
| Terminal-Bench 2.0 | 75.1% | 60.0% | En tool-heavy workflows largos la ventaja de GPT-5.4 es mayor |
| Toolathlon | 54.6% | 42.9% | GPT-5.4 mantiene mejor la fiabilidad multi-herramienta |
| GPQA Diamond | 93.0% | 88.0% | GPT-5.4 conserva más techo de razonamiento |
| OSWorld-Verified | 75.0% | 72.1% | Mini ya es suficientemente fuerte para muchos computer-use loops |
Lo importante aquí no es solo que GPT-5.4 gane, sino que GPT-5.4 mini no queda tan lejos como para descartarla como ruta productiva.
Eso lleva a tres conclusiones:
Primero, GPT-5.4 sigue siendo la mejor cuando el flujo es más difícil o más caro de corregir. Segundo, GPT-5.4 mini ya ofrece nivel suficiente para mucha carga real de coding y agents. Tercero, pagar flagship en todas las peticiones suele ser mala idea si el grueso del tráfico puede ir por mini sin degradar demasiado el resultado.
La lectura práctica es que la tabla no te pide elegir "el más listo" para todo, sino decidir en qué tramo del sistema duele más el error. Si una mala decisión rompe al planner, obliga a rehacer varios pasos o dispara revisión humana, la ventaja de GPT-5.4 pesa mucho más que la diferencia de precio por token.
En cambio, cuando la tarea se puede reintentar barato, validar rápido o ejecutar en paralelo miles de veces, mini empieza a verse como una ruta claramente mejor. Por eso esta comparativa solo cobra sentido si la conectas con arquitectura, colas y coste operativo, no solo con benchmarks aislados.
Si quieres comparar mini con la rama legacy de bajo coste, sigue con GPT-5.4 mini vs GPT-5 mini.
Precio, contexto y throughput: dónde se siente de verdad la diferencia

La página actual de GPT-5.4 muestra:
- $2.50 por 1M input tokens
- $0.25 por 1M cached input tokens
- $15.00 por 1M output tokens
- 1,050,000 de context window
La página actual de GPT-5.4 mini muestra:
- $0.75 por 1M input tokens
- $0.075 por 1M cached input tokens
- $4.50 por 1M output tokens
- 400,000 de context window
La lectura más útil es esta:
- GPT-5.4 es mucho más cara
- GPT-5.4 compra bastante más headroom
- GPT-5.4 mini es mucho más fácil de escalar
Además, la página de GPT-5.4 añade un caveat que muchos artículos rápidos omiten: si el prompt supera 272K input tokens, la sesión completa se cobra a 2x input y 1.5x output. En otras palabras: el contexto de 1.05M es valioso, pero también es una función premium que conviene usar con intención.
En throughput también hay una diferencia muy práctica. En los top-tier caps públicos actuales, GPT-5.4 mini queda mucho mejor posicionada para cargas de gran volumen. Eso ayuda a explicar por qué mini tiene tanto sentido como modelo de workers.
Otro detalle importante: ambas páginas muestran el mismo cutoff, 31 de agosto de 2025. Por tanto, no conviene vender esta comparativa como si GPT-5.4 fuera “mucho más fresca” a nivel base. Aquí la diferencia real está en coste, contexto y capacidad de escala.
Hay una forma más útil de pensar el coste: no mirar solo el precio del token, sino el coste por tarea completada. Si mini necesita algún reintento extra pero permite procesar una cola mucho más grande por menos dinero, sigue siendo una mejor ruta por defecto para trabajo repetible.
Al revés, si tu sistema mete repos enormes, documentos largos y ramas multi-tool en una sola sesión, el contexto de 1.05M de GPT-5.4 deja de ser un lujo abstracto y pasa a ser una forma de bajar compaction, recortes y errores de coordinación. Ahí el sobreprecio suele estar mejor justificado.
Herramientas: mini no es una versión “recortada”
Este punto cambia mucho la decisión.
Las páginas actuales de GPT-5.4 y GPT-5.4 mini muestran el mismo conjunto amplio de herramientas en Responses API:
- web search
- file search
- image generation
- code interpreter
- hosted shell
- apply patch
- skills
- computer use
- MCP
- tool search
Eso significa que la comparación no es “modelo con herramientas” contra “modelo más barato pero limitado”. En realidad es:
- GPT-5.4 = más techo para trabajo difícil
- GPT-5.4 mini = una superficie de producto muy parecida, pero con mucha mejor economía
Por eso esta keyword necesita reglas de routing y no solo una tabla de specs.
Ese punto cambia mucho la decisión de compra. Cuando la superficie es casi la misma, dejar todo en manos de un único default suele ser más una comodidad psicológica que una buena política técnica. La comparación correcta es dónde conviene pagar headroom y dónde conviene pagar volumen.
Cuándo merece pagar por GPT-5.4
GPT-5.4 compensa cuando el coste de un fallo es mayor que el sobreprecio del token.
Normalmente eso incluye:
- análisis de repos grandes o documentación larga
- planner u orquestador principal
- tareas con varios pasos donde un fallo intermedio rompe toda la cadena
- outputs de cara al cliente o de negocio crítico
- trabajo donde menos reintentos ya mejora el coste total
La regla más simple es: si el error de mini te obliga a rehacer mucho, pasa esa rama a GPT-5.4.
Si necesitas una comparación del flagship con otra rama potente de OpenAI, también te puede servir GPT-5.4 vs GPT-5.3-Codex.
Cuándo GPT-5.4 mini es el default más inteligente
GPT-5.4 mini gana cuando el problema central es cómo correr mucho trabajo útil con menos coste.
Es especialmente buena como default para:
- subagentes y workers
- asistentes de coding de alto volumen
- computer-use loops con capturas
- pipelines de revisión, triage o procesamiento en segundo plano
- sistemas donde no quieres pagar precio de flagship en todo el tráfico
En muchos equipos, la mejor arquitectura práctica termina siendo:
- GPT-5.4 para planner, escalado y tareas difíciles
- GPT-5.4 mini para workers
Eso encaja mucho mejor con la línea actual de OpenAI que intentar obligar a una sola ruta para todo.
Además, esta división vuelve más explicable la operación del equipo. En vez de discutir petición por petición, puedes fijar reglas: ramas con contexto largo, decisiones difíciles y output crítico suben a GPT-5.4; ramas repetibles, de alto throughput y bajo coste de error se quedan en mini.
Ese tipo de routing también facilita medir. Puedes comparar tasa de reintentos, coste por tarea, tiempo total y porcentaje de escalados, y ajustar la frontera sin reabrir toda la estrategia cada semana.
También reduce discusiones internas bastante inútiles. En vez de debatir si "mini ya es suficientemente buena" en abstracto, el equipo puede mirar ramas concretas: planner, repair complejo, background triage, revisión masiva, computer use repetitivo. Cada una tiene un coste de error distinto y, por tanto, un modelo por defecto distinto.
Esa claridad importa porque la mayoría de equipos no falla por elegir el modelo "equivocado" una sola vez, sino por no tener una política consistente. Cuando el routing está escrito y medido, mover carga entre GPT-5.4 y GPT-5.4 mini deja de ser una discusión ideológica y se vuelve una decisión operativa.
En otras palabras, la comparación útil no termina en la tabla: termina en una política que cualquiera del equipo pueda aplicar sin improvisar.
Esa es la diferencia entre comparar modelos y diseñar una operación.
Y eso cambia bastante la decisión.
Mucho más de lo que parece.
API y Codex frente a la realidad de ChatGPT
Desde API y Codex la historia es relativamente limpia:
- GPT-5.4 es la ruta principal
- GPT-5.4 mini es la ruta más pequeña, rápida y barata
Desde ChatGPT la situación es menos limpia. En las release notes, OpenAI explica que a 18 de marzo de 2026 GPT-5.4 mini aparece en ChatGPT como ruta de Thinking para usuarios Free y Go y como fallback de GPT-5.4 Thinking para muchos usuarios de pago. Además, mini no aparece como modelo seleccionable estándar en el picker.
Eso importa porque mucha gente mezcla “lo que veo en ChatGPT” con “qué modelo debería elegir en API”. No es la misma decisión.
Reglas prácticas de routing para equipos
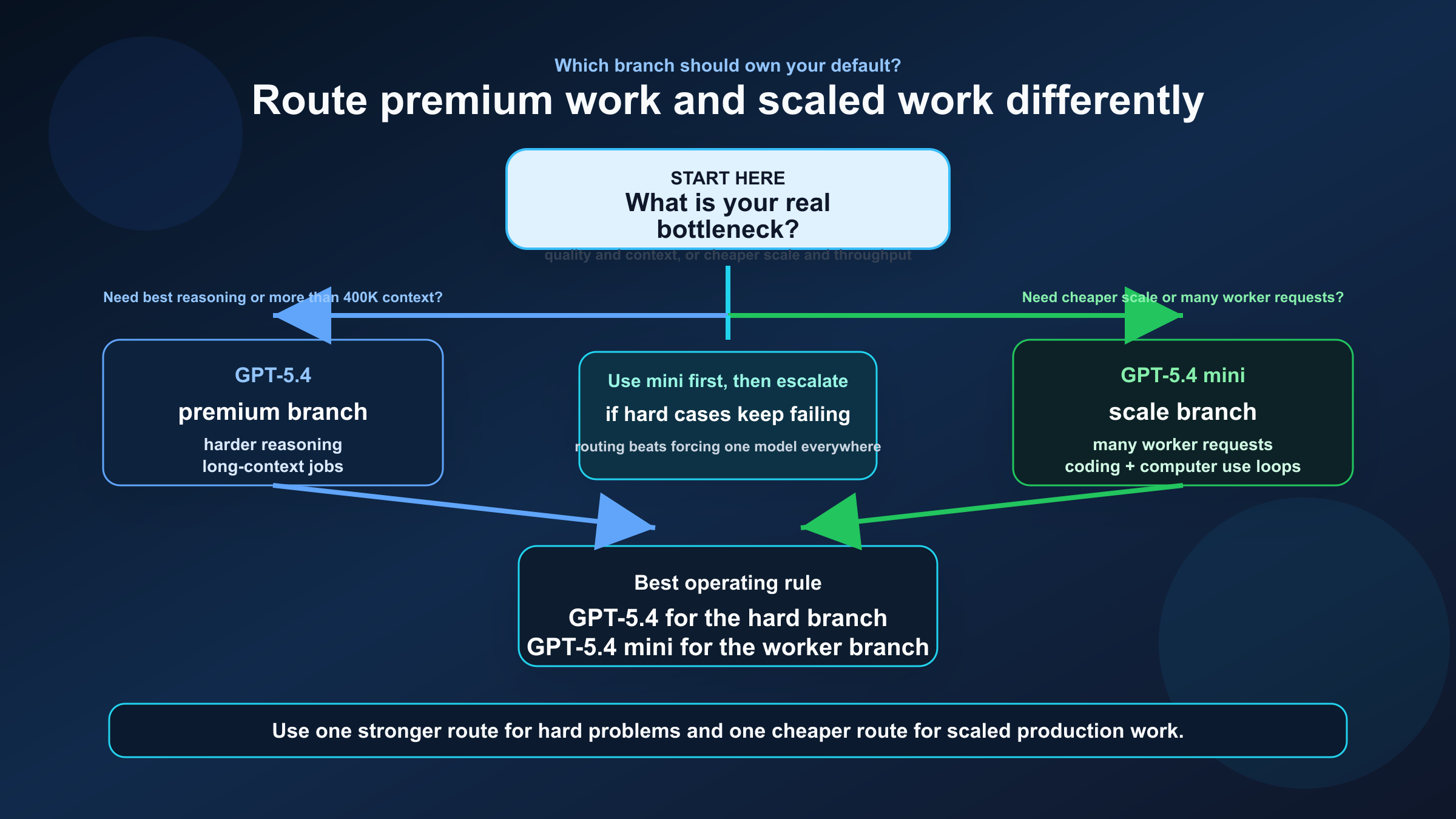
Si quieres una política simple para el equipo, usa esta:
| Tipo de carga | Modelo por defecto | Motivo | Cuándo cambiar |
|---|---|---|---|
| Repo analysis con contexto largo | GPT-5.4 | Más contexto y más techo | Solo baja a mini si cabe sobradamente en 400K y el presupuesto manda |
| Planner / agente coordinador | GPT-5.4 | Mejora en trabajo difícil y multi-step | Baja a mini solo si el planner es muy ligero |
| Workers / subagentes | GPT-5.4 mini | Mejor coste y throughput | Sube a GPT-5.4 en los casos duros |
| Coding assistant a escala | GPT-5.4 mini | Bastante fuerte y mucho más barata | Usa GPT-5.4 para review o repair complejo |
En la práctica, la regla más defensible suele ser: una ruta premium para lo difícil y una ruta barata para lo masivo.
FAQ
¿GPT-5.4 mini es suficiente para agentes de coding serios?
En muchos casos sí. Está cerca de GPT-5.4 en varios benchmarks relevantes y además tiene mejor posición económica para alto volumen.
¿GPT-5.4 mini trae menos herramientas?
No según las páginas actuales del modelo. La gran diferencia está en contexto, headroom y coste, no en una ausencia de herramientas.
¿Vale la pena pagar por GPT-5.4?
Sí si el extra de calidad evita errores caros, rehacer trabajo o recortar demasiado el contexto. No si el grueso del tráfico ya funciona bien con mini y la diferencia apenas cambia el resultado.
¿La principal razón para elegir GPT-5.4 es el contexto de 1.05M?
Es una de las más fuertes, pero no la única. También importa el mejor comportamiento en tareas difíciles y tool-heavy.
¿Qué conviene para subagentes estilo Codex?
Muy a menudo GPT-5.4 mini. Deja GPT-5.4 para planner, escalado y ramas más complejas.
¿Conviene mover todo el tráfico a GPT-5.4 mini para ahorrar?
Solo si ya sabes que la mayor parte de tus ramas tienen bajo coste de error. En muchos equipos sale mejor mover primero workers, triage y background jobs, y dejar planner y outputs críticos en GPT-5.4.
¿Cuál es la mejor forma de empezar si hoy solo usas un modelo?
Normalmente conviene empezar separando dos rutas: una premium para contexto largo, decisiones difíciles y salida crítica; otra barata para trabajo repetible y de mucho volumen. Esa división ya te da métricas claras para decidir después cuánto tráfico puede bajar a mini sin romper calidad.
El resumen útil es este: GPT-5.4 se queda con la rama difícil y GPT-5.4 mini con la rama escalable.