
A 27 de marzo de 2026, la forma más segura de empezar con Gemini image generation por raw REST es POST https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent. Empieza por ahí, añade responseModalities e imageConfig, guarda la imagen que vuelve dentro de inlineData, y solo después decide si de verdad necesitas la capa compatible con OpenAI o un modelo distinto.
Ese orden importa porque Google sigue repartiendo la respuesta entre varias páginas. La guía oficial de image generation enseña la ruta nativa. La referencia de API fija generateContent e imageConfig. La documentación de compatibilidad con OpenAI enseña otra familia de endpoints. Si lees las tres deprisa, es fácil tratarlas como opciones equivalentes para empezar. Para un proyecto nuevo de raw REST no lo son.
Hay otro caveat importante desde el principio. Las rutas actuales de imágenes en Gemini 3 siguen siendo preview, y la superficie de modelos ha cambiado lo bastante rápido como para que los snippets viejos sigan causando confusión. En la documentación oficial compatible con OpenAI todavía aparece gemini-2.5-flash-image, mientras que la documentación nativa actual ya se apoya sobre gemini-3.1-flash-image-preview y gemini-3-pro-image-preview. Si no separas esas dos capas desde el inicio, acabarás mezclando un problema de endpoint con un problema de modelo o de acceso.
Resumen rápido
| Tu caso | Primera ruta que conviene probar | Modelo por defecto | Por qué esta es la respuesta actual | Caveat principal |
|---|---|---|---|---|
| Nuevo proyecto con raw REST | POST /v1beta/models/gemini-3.1-flash-image-preview:generateContent | gemini-3.1-flash-image-preview | Es la ruta más alineada con la documentación nativa actual y expone imageConfig de forma directa | Los modelos de imagen de Gemini 3 siguen en preview |
| Posters, gráficos con mucho texto o activos de más valor | La misma ruta nativa generateContent | gemini-3-pro-image-preview | Tiene más sentido como rama premium | Es más caro y sigue siendo preview |
| Debes conservar un cliente con semántica OpenAI | POST /v1beta/openai/images/generations | Lo que soporte hoy la capa compatible | Reduce al mínimo los cambios en el cliente | No es la ruta por defecto para trabajo nuevo con Gemini |
| En AI Studio funciona pero en cURL falla | Muchas veces no es solo un problema de URL | Comprueba el mismo proyecto y modelo | Billing, tier y acceso suelen ser el cuello de botella real | Google no publica una tabla fija de límites válida para todos |
Si tu duda real es el split entre host y path, empieza por Gemini Image Generation API Base URL. Si además quieres ejemplos con SDK y cURL, la continuación natural es Gemini image generation code examples.
Usa primero la ruta REST nativa de Gemini
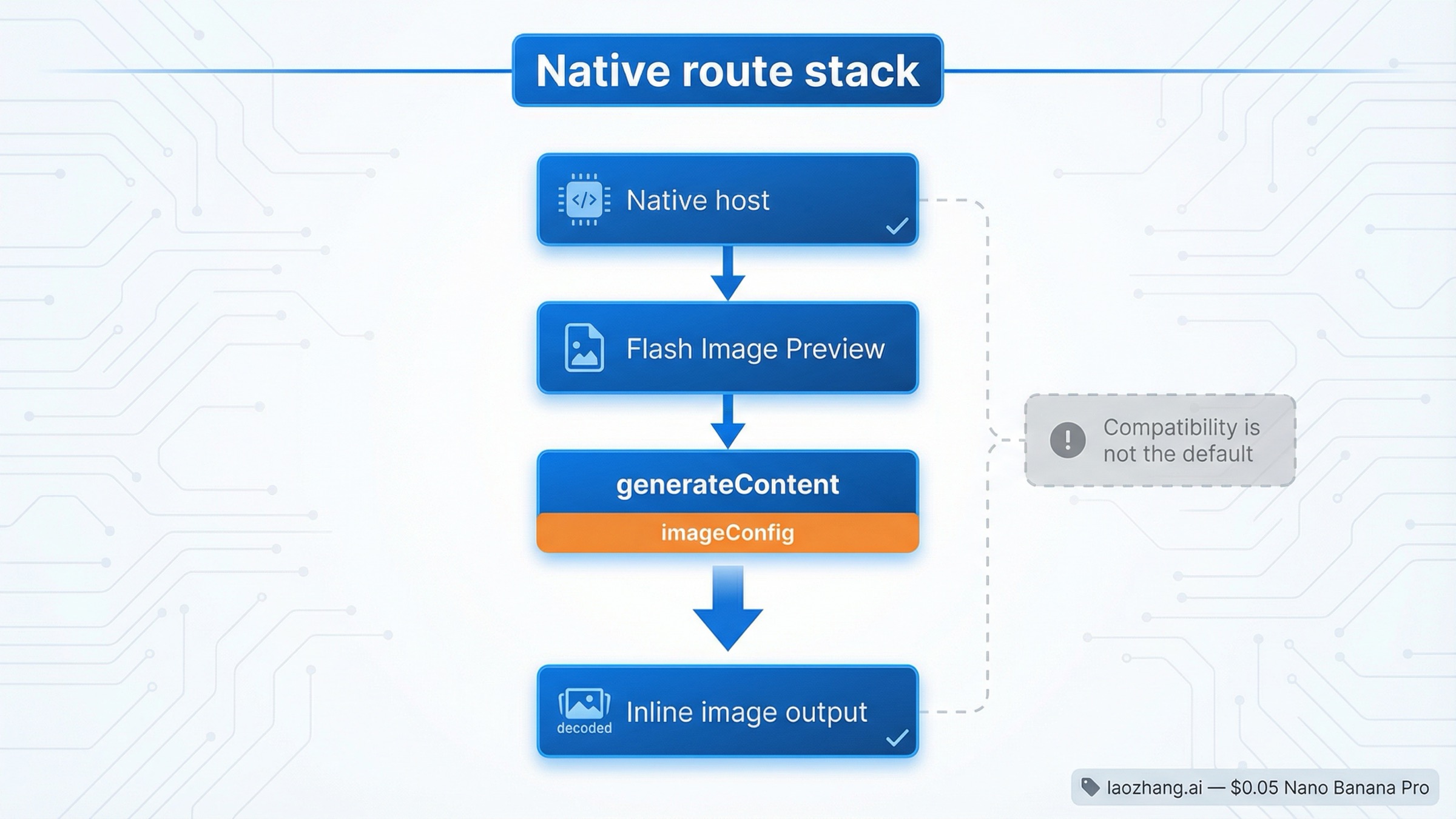
Para una integración nueva conviene fijar una idea sencilla: Gemini image generation no consiste en buscar un host secreto para imágenes, sino en llamar bien a una request nativa de Gemini que devuelve datos de imagen. La referencia oficial sigue definiendo este contrato dentro de generateContent, y la guía de imágenes sigue usando esa misma familia de métodos.
Eso es justo lo que necesita ver quien trabaja con raw REST, porque la primera request exitosa suele tener que responder tres preguntas:
- cuál es hoy el host correcto y qué model path toca usar
- dónde van los controles que sí cambian el resultado visual
- cómo se ve la respuesta real sin la abstracción de un SDK
La ruta nativa responde mejor a esas tres preguntas. El host es claro, la documentación está más actualizada y imageConfig vive en la misma request sin pasar por una traducción de compatibilidad. Para cURL, wrappers propios o lenguajes donde quieres controlar el JSON exacto, esa es la ruta más limpia.
El modelo práctico de arranque sigue siendo gemini-3.1-flash-image-preview. La página de modelos de Google lo mantiene como la vía de imagen más eficiente, mientras gemini-3-pro-image-preview queda como rama premium. gemini-2.5-flash-image todavía existe, pero la página de deprecations ya le marca fecha de apagado: 2 de octubre de 2026, con gemini-3.1-flash-image-preview como reemplazo recomendado.
Copia primero una request cURL que funcione
No empieces montando un pipeline entero. Primero demuestra host, modelo y respuesta de imagen. La primera request debe ser deliberadamente simple: un prompt, un modelo actual, un tipo de salida y una configuración explícita de aspectRatio e imageSize.
bashcurl -s -X POST \ "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent" \ -H "x-goog-api-key: $GEMINI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "contents": [{ "parts": [ { "text": "Create a clean 16:9 product image of a matte black travel mug on a light concrete surface with soft studio lighting and premium ecommerce styling." } ] }], "generationConfig": { "responseModalities": ["IMAGE"], "imageConfig": { "aspectRatio": "16:9", "imageSize": "2K" } } }'
Esa request sirve porque valida el path nativo, el modelo actual y los controles visuales a la vez. La API reference sigue indicando que imageConfig admite aspectRatio y que imageSize puede tomar 512, 1K, 2K y 4K.
Si tu caso son gráficos más exigentes, posters o composiciones donde una mala primera salida cuesta más dinero, cambia solo el model path a gemini-3-pro-image-preview. Si la siguiente duda ya no es REST sino precio, lo más útil es ir a Gemini image generation API pricing.
Guarda la imagen que viene dentro de la respuesta REST
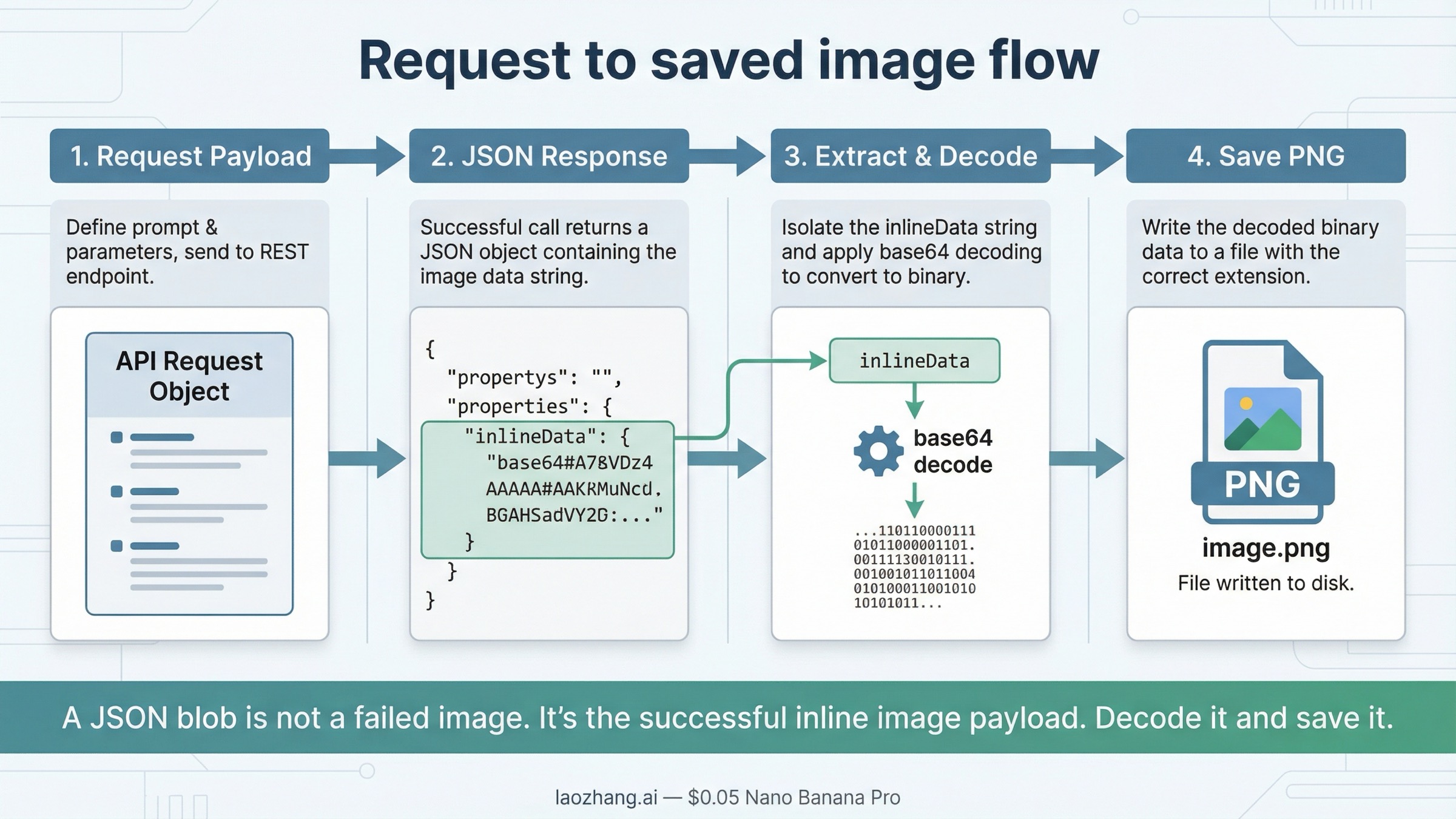
Aquí es donde muchos artículos de REST se quedan cortos. La respuesta nativa de Gemini no te da un archivo final ya montado; devuelve los bytes de la imagen dentro de inlineData en el JSON.
Por eso mucha gente ve “solo JSON” y asume que la generación falló. La mayoría de veces no ha fallado nada. Lo que falta es el último paso: extraer, decodificar y guardar.
En la ruta nativa, la secuencia suele ser esta:
- leer
candidates[0].content.parts - localizar el part que contiene
inlineData - extraer
.inlineData.data - hacer base64 decode y escribir el archivo
En shell, una forma directa es esta:
bashcurl -s -X POST \ "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent" \ -H "x-goog-api-key: $GEMINI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "contents": [{ "parts": [ { "text": "Create a square studio photo of a red ceramic teacup on a white background." } ] }], "generationConfig": { "responseModalities": ["IMAGE"], "imageConfig": { "aspectRatio": "1:1", "imageSize": "1K" } } }' \ | jq -r '.candidates[0].content.parts[] | select(.inlineData) | .inlineData.data' \ | base64 --decode > gemini-image.png
En macOS quizá necesites base64 -D. Lo importante no es el flag concreto, sino entender que una respuesta nativa correcta todavía necesita un paso explícito de decode-to-file.
Cuándo sí encaja la ruta de imagen compatible con OpenAI
La capa compatible con OpenAI existe y tiene su uso. La documentación actual de compatibilidad mantiene:
texthttps://generativelanguage.googleapis.com/v1beta/openai/
y el endpoint de imagen:
text/v1beta/openai/images/generations
Si ya tienes un cliente con forma OpenAI y tu objetivo es migrar con el menor cambio posible, esa ruta puede ser razonable. Te permite probar Gemini sin rehacer toda la superficie del cliente.
Lo que no conviene es tratarla como respuesta por defecto para “gemini image generation rest api”. Quien llega con esa búsqueda normalmente quiere el contrato REST nativo actual de Gemini, no la ruta de migración más cómoda para una base de código OpenAI.
La diferencia aparece tanto en la documentación como en la fricción real. A 27 de marzo de 2026, el ejemplo oficial compatible con OpenAI todavía usa gemini-2.5-flash-image, mientras que la documentación nativa actual ya gira en torno a los modelos de imagen de Gemini 3. En el foro también se ven casos de 404 o payload inválido cuando alguien intenta meter expectativas nativas de imagen dentro de la ruta compatible.
La regla práctica se resume así:
- proyecto nuevo, cURL, raw REST y documentación actual: native Gemini
- stack OpenAI ya existente y decisión explícita de mantenerlo: compatibility route
- no mezcles ambos contratos en la misma primera ronda de depuración
Qué cambian de verdad el modelo, el precio y el estado actual
Que la sintaxis REST sea correcta no significa que la elección de implementación también lo sea. El modelo, el estado preview, el billing y los límites reales cambian la mejor ruta.
| Modelo | Papel actual | Cuándo usarlo | Caveat |
|---|---|---|---|
gemini-3.1-flash-image-preview | Default para raw REST nuevo | La mayoría de escenarios actuales de generación y edición | Sigue en preview |
gemini-3-pro-image-preview | Rama premium | Cuando importan más el layout, el texto en imagen y el valor del activo final | Más caro y también preview |
gemini-2.5-flash-image | Línea antigua que aún aparece en ejemplos compatibles | Solo para ejemplos viejos o migraciones deliberadas | Google ya marca apagado el 2 de octubre de 2026 |
La página de billing sigue diciendo que las cuentas nuevas empiezan en Free Tier y que solo ciertos modelos entran en ese marco. La página de rate limits deja claro que los límites dependen del tier y que la referencia real está en AI Studio, no en una tabla estática común para todos.
Por eso esta guía no vende un relato de “Gemini image REST totalmente gratis para cualquiera”. La realidad actual es más condicionada: puedes tener una request correcta y fallar igualmente por access, por tier o por límites de un modelo preview.
Troubleshooting: separa primero qué capa está fallando
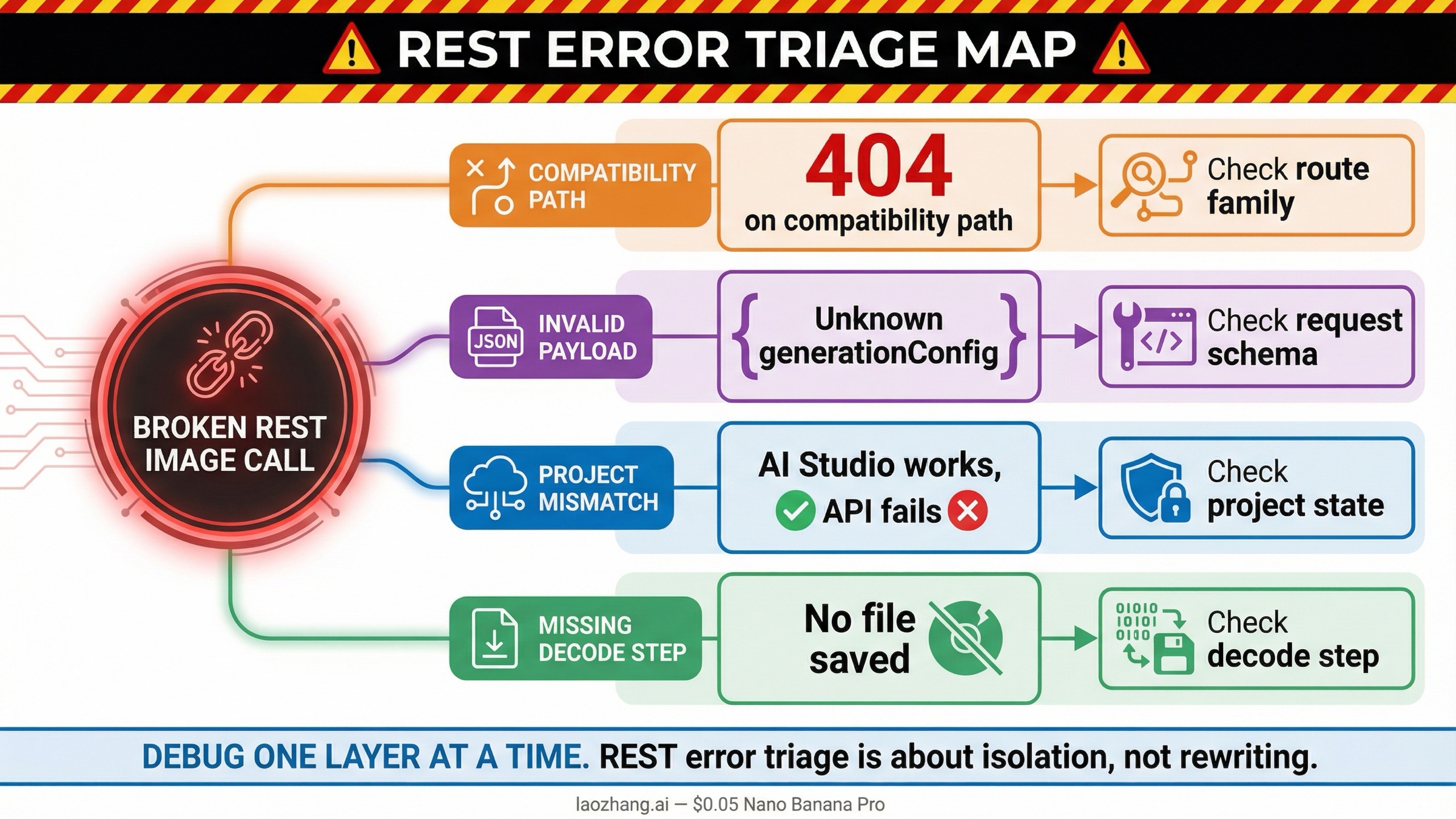
Este keyword tiene una clara intención de soporte. Mucha gente no lo busca al diseñar la integración, sino después del primer fallo. La ventaja es que los fallos más comunes se repiten bastante.
| Lo que ves | Lo que suele significar | Qué hacer después |
|---|---|---|
404 en /v1beta/openai/images/generations | Estás en la ruta compatible y el modelo o la forma de la request no encaja con esa surface | Repite la misma tarea con generateContent nativo |
Unknown name "generationConfig" o generation_config | Has enviado campos nativos de Gemini dentro del contrato compatible con OpenAI | Vuelve a native o adapta por completo el payload a la schema compatible |
model not found con un modelo antiguo | Copiaste un model ID viejo desde un snippet o un hilo del foro | Revisa primero la página actual de modelos y deprecations |
| AI Studio funciona pero cURL falla | API key, billing o acceso al modelo no coinciden con el contexto del navegador | Comprueba el mismo proyecto, key y modelo |
| Llega JSON pero no aparece archivo de imagen | La request sí funcionó, pero aún no hiciste el decode de inlineData | Extrae .inlineData.data y haz base64 decode |
Aquí el mayor ahorro de tiempo viene de cambiar una sola capa cada vez. No cambies host, modelo, prompt y lógica de guardado a la vez. Primero demuestra la request nativa, luego el guardado del archivo, y solo después mira cuotas, wrappers o compatibilidad.
Si tu problema ya está más allá de la elección del endpoint y ahora es un 429, 400 o 500, lo siguiente más útil es Gemini API error fix 2026: 429, 400, 500.
FAQ
¿/v1beta/openai/images/generations está mal?
No. Esa ruta existe y tiene sentido cuando ya tienes un cliente con semántica OpenAI y tu prioridad es migrar con el menor cambio posible. Lo que no conviene es tomarla como respuesta por defecto para trabajo nuevo con raw REST. Si estás empezando una integración nueva, validar primero native generateContent suele ahorrar mucho más tiempo. Ese orden también te deja ver enseguida si el problema está en la familia de endpoint, en el payload o en la propia capa de compatibilidad.
¿Por qué la API me devuelve JSON y no un archivo listo?
Porque en la ruta nativa eso es precisamente lo esperado. Los bytes de la imagen vuelven dentro de inlineData en el JSON. Normalmente no hay fallo de generación: lo que falta es el último paso. Debes extraer .inlineData.data, hacer base64 decode y guardar el resultado como archivo de imagen.
¿Con qué modelo conviene empezar hoy?
El default práctico sigue siendo gemini-3.1-flash-image-preview, porque es la línea que mejor encaja con la documentación nativa actual y con la página de modelos. Si tu caso son posters, diagramas o composiciones con mucho texto donde el error cuesta más dinero, ahí sí compensa mirar gemini-3-pro-image-preview. gemini-2.5-flash-image todavía aparece en ejemplos compatibles, pero Google ya le marca apagado el 2 de octubre de 2026.
Si AI Studio funciona pero cURL falla, ¿qué reviso primero?
Antes de cambiar el endpoint, comprueba el contexto: mismo proyecto, misma API key y mismo acceso al modelo. Después mira billing, tier y límites activos. Muchas veces el problema parece un error de REST cuando en realidad es una diferencia entre el contexto del navegador y el de la llamada API real. Si el mismo prompt funciona en AI Studio pero no en cURL, suele ser más productivo comparar proyecto, permisos y cuota efectiva que reescribir toda la request desde cero.
Conclusión
Para la generación actual de imágenes por raw HTTP, empieza por la Gemini Developer API nativa:
textPOST https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent
Usa responseModalities e imageConfig, guarda la imagen desde inlineData, y solo pasa a /v1beta/openai/images/generations cuando tu stack realmente necesite conservar una semántica compatible con OpenAI.
Ese sigue siendo el default más seguro porque coincide con la documentación nativa actual de Gemini, mantiene más claro el contrato de imagen y evita el error más común detrás de esta búsqueda: asumir que la ruta de imagen compatible con OpenAI es el punto de partida universal para cualquier Gemini image REST workflow.
En la práctica, eso significa validar primero la ruta nativa, luego el guardado del archivo y solo después la capa compatible.