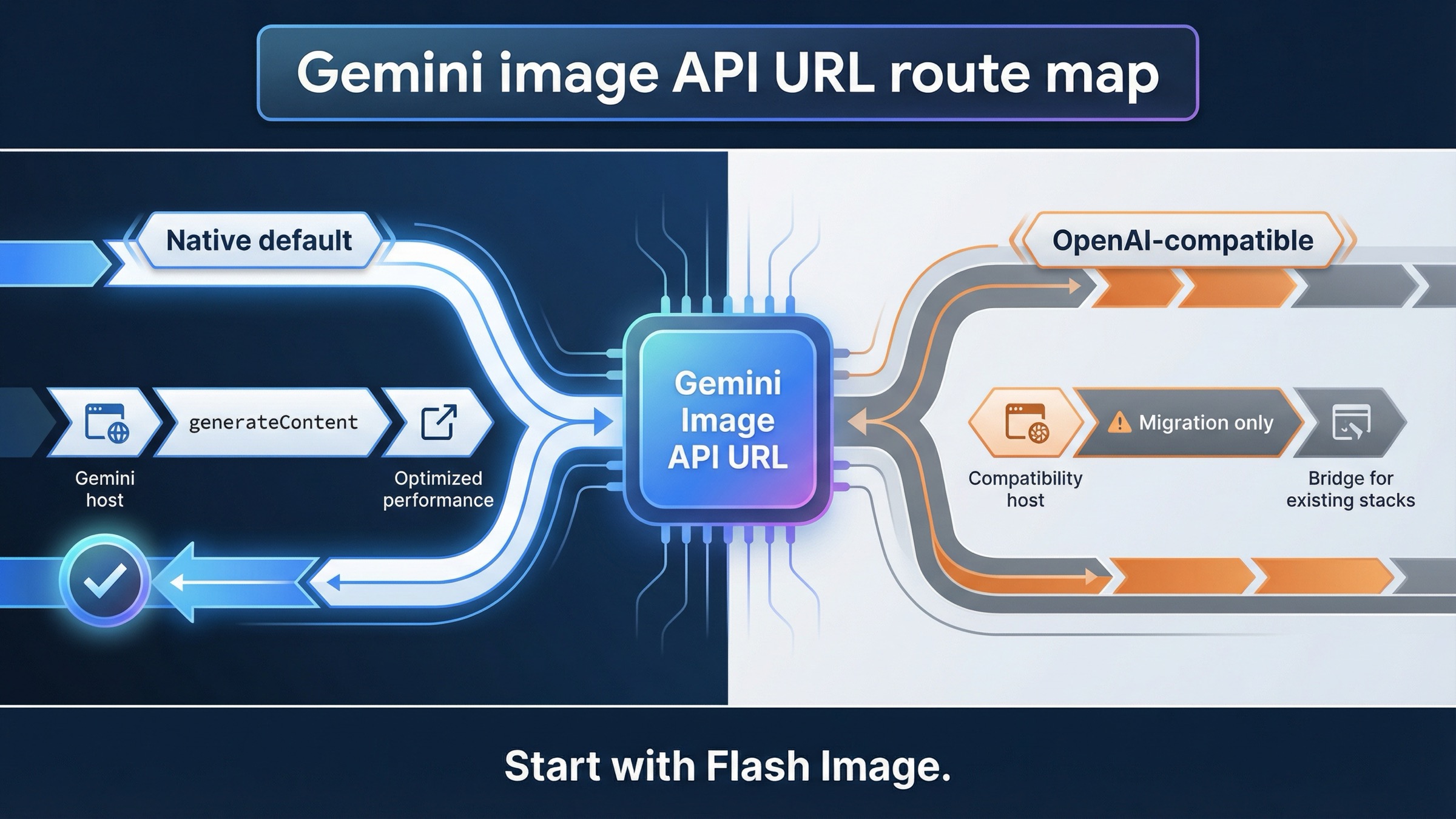
A 24 de marzo de 2026, la base URL nativa correcta para generar imágenes con Gemini es https://generativelanguage.googleapis.com/v1beta, y la primera ruta que la mayoría de desarrolladores debería probar es POST /models/gemini-3.1-flash-image-preview:generateContent. Usa https://generativelanguage.googleapis.com/v1beta/openai/ solo cuando de verdad estés manteniendo una capa compatible con OpenAI.
Ese es el núcleo real de esta búsqueda. La guía oficial de generación de imágenes, la referencia de API y la documentación de compatibilidad con OpenAI muestran piezas del rompecabezas, pero ninguna responde de forma directa qué host debes usar por defecto para image generation con Gemini.
La ruta segura es más simple de lo que parece. Primero haz funcionar una request nativa de generateContent, confirma que realmente devuelve una imagen, y solo después decide si te conviene la capa compatible, otro modelo o un ajuste de cuotas. Si luego quieres la visión completa de app, AI Studio y API, puedes seguir con Gemini Image Generation Tutorial y Ejemplos de código para generar imágenes con Gemini.
Resumen rápido:
- Para trabajo nuevo de Gemini image generation, empieza por
https://generativelanguage.googleapis.com/v1beta. - La primera ruta completa que conviene probar es
/models/gemini-3.1-flash-image-preview:generateContent. - Cambia a
https://generativelanguage.googleapis.com/v1beta/openai/solo si tu stack depende de forma explícita de la compatibilidad con OpenAI.
Resumen rápido
| Tu situación | Base URL | Primera ruta que debes tener en mente | Cuándo usarla | Caveat principal |
|---|---|---|---|---|
| Nuevo trabajo nativo con Gemini | https://generativelanguage.googleapis.com/v1beta | /models/gemini-3.1-flash-image-preview:generateContent | Quieres la ruta más clara y más alineada con la documentación actual de Gemini | Image generation sigue viviendo bajo generateContent, no bajo un host separado de /images |
| Stack ya basado en OpenAI SDK o tooling parecido | https://generativelanguage.googleapis.com/v1beta/openai/ | Métodos tipo images.generate() | Quieres migrar con el menor cambio posible en el cliente | La capa compatible tiene una superficie de imagen más estrecha y algunos parámetros extra pueden ignorarse |
| AI Studio o Gemini App funciona pero tu código falla | Normalmente no es un problema de base URL | Revisa proyecto, key, modelo y cuotas | Estás copiando expectativas de una UI a una API | App, AI Studio y API no son la misma cosa |
| En realidad estás en Vertex AI | No asumas que aplica el host del Gemini Developer API | Usa la familia de endpoints de Vertex | Tu proyecto corre sobre Vertex AI | Depurar el host equivocado consume tiempo aunque el modelo sea correcto |
Quédate con esta regla: si empiezas hoy con Gemini image generation, la respuesta por defecto es la ruta nativa de Gemini, no la URL compatible con OpenAI.
En la práctica conviene fijar también un orden mental: primero valida host y ruta de modelo, después mira controles de imagen, cuotas y solo al final decide si de verdad necesitas la capa compatible. Ese orden reduce mucho el tiempo perdido en falsos problemas de base URL.
Usa esta base URL para Gemini image generation nativo
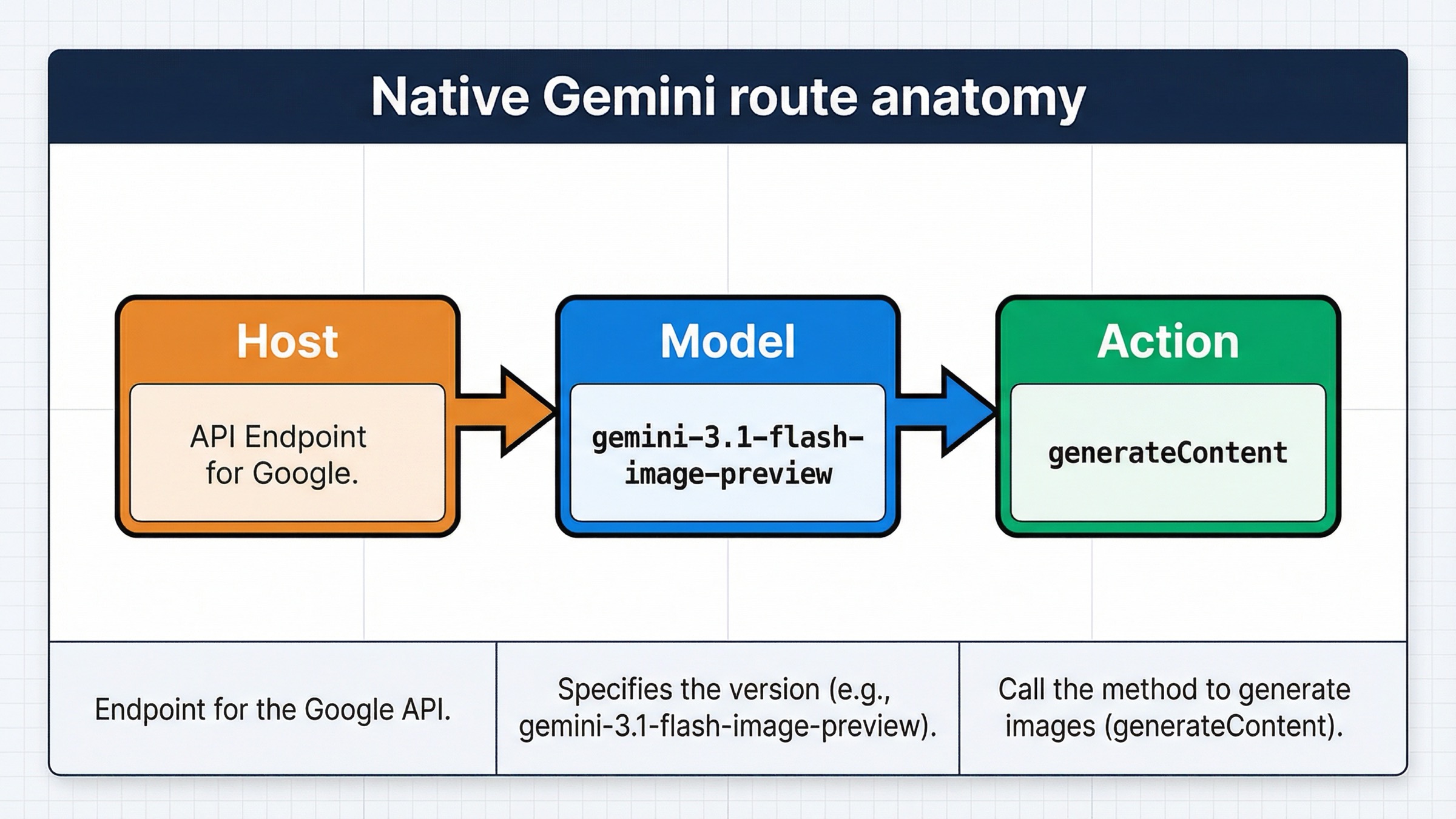
La referencia oficial de Gemini sigue definiendo la generación de imágenes dentro de la familia generateContent. Por eso la respuesta nativa parece menos obvia si esperabas una ruta clásica tipo /images/generations. En Gemini nativo, el host sigue siendo el del Gemini Developer API y la intención de generar imágenes vive en la combinación de modelo más generateContent.
La base es esta:
texthttps://generativelanguage.googleapis.com/v1beta
Y la primera ruta completa que la mayoría debería probar es:
texthttps://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent
La documentación actual de Google sigue colocando gemini-3.1-flash-image-preview como la vía rápida por defecto y gemini-3-pro-image-preview como la rama premium. Por eso aquí no parto de ejemplos viejos de la línea 2.5. Si estás integrando algo nuevo, la pregunta útil no es “qué ejemplo antiguo todavía sobrevive”, sino “qué contrato está enseñando Google ahora mismo como ruta principal”.
La otra razón para preferir la vía nativa es funcional. Ahí es donde imageSize, aspectRatio, edición de imágenes y flujos multi-turn tienen un significado más claro. Si te importa cómo se comporta hoy Gemini con imágenes, la ruta nativa sigue siendo el contrato más limpio.
Cuándo sí tiene sentido /v1beta/openai/
La base URL compatible con OpenAI existe y sigue siendo oficial. Google todavía muestra:
texthttps://generativelanguage.googleapis.com/v1beta/openai/
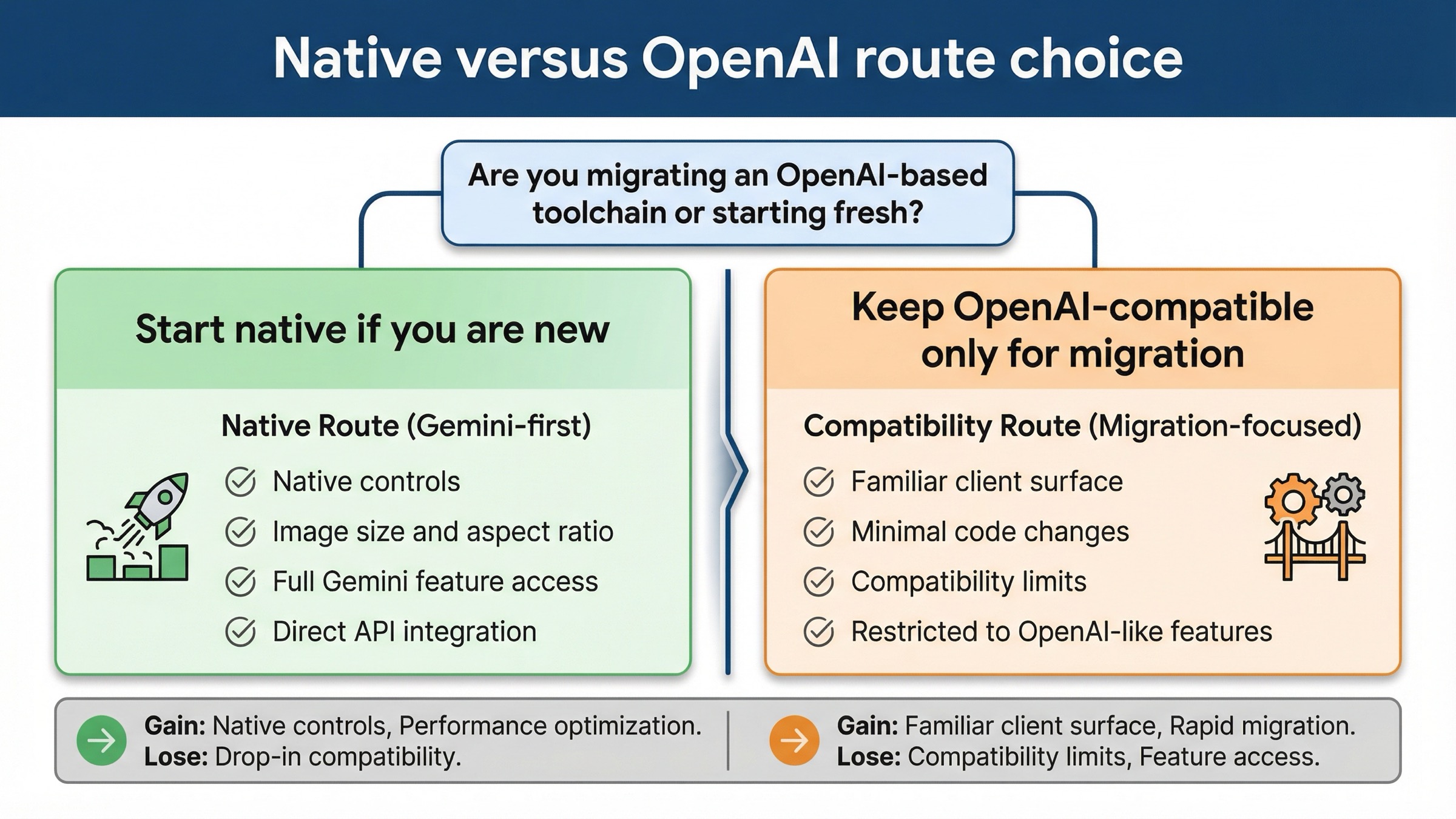
¿Cuándo es correcta? Cuando ya tienes una base de código apoyada en librerías o wrappers con semántica OpenAI y quieres migrar con el menor cambio posible. En ese caso, usar la capa compatible tiene sentido.
Lo que no conviene es tratar esa URL como la respuesta por defecto para cualquier duda sobre Gemini image generation. La propia documentación de compatibilidad dice que, si no estás usando ya librerías OpenAI, es preferible llamar a la Gemini API directamente. Y eso importa mucho en imágenes, porque aquí la diferencia no es cosmética. La documentación compatible sigue hablando de imagen con gemini-2.5-flash-image o gemini-3-pro-image-preview, y además avisa de que otros parámetros fuera del conjunto documentado pueden ignorarse en silencio.
Ahí nace gran parte de la confusión. La URL compatible puede ser válida y aun así no ser la mejor ruta por defecto. Si necesitas controles nativos de imagen o quieres seguir la documentación actual de Gemini de la forma más directa, empieza por la ruta nativa.
La forma práctica de decidir es esta:
- Si estás empezando desde cero, depuras raw REST o sigues la documentación actual de Gemini, usa la ruta nativa.
- Si estás preservando a propósito un stack de OpenAI, entonces la compatibilidad sí puede ser la mejor opción.
- No mezcles ambas familias en la misma ronda de depuración si no sabes exactamente qué comportamiento estás comparando.
Copia primero una request REST que funcione
Antes de optimizar nada, prueba una request nativa mínima. La idea es comprobar host, modelo y respuesta de imagen, no montar todavía un pipeline entero.
bashcurl -s -X POST \ "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent" \ -H "x-goog-api-key: $GEMINI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "contents": [{ "parts": [ { "text": "Create a clean 16:9 product hero image of a matte black travel mug on a light concrete surface with soft studio lighting." } ] }], "generationConfig": { "responseModalities": ["IMAGE"], "imageConfig": { "aspectRatio": "16:9", "imageSize": "2K" } } }'
Esa request valida tres cosas a la vez: que el host es correcto, que el modelo es el adecuado y que los controles nativos de imagen realmente están en juego. Si luego necesitas la rama premium, cambia la ruta del modelo a:
text/models/gemini-3-pro-image-preview:generateContent
Reserva esa rama para casos donde la calidad del texto dentro de la imagen, una composición más compleja o un activo más caro justifiquen el cambio. Si tu siguiente pregunta ya no es la URL sino el coste, la guía adecuada es Gemini image generation API pricing.
Troubleshooting
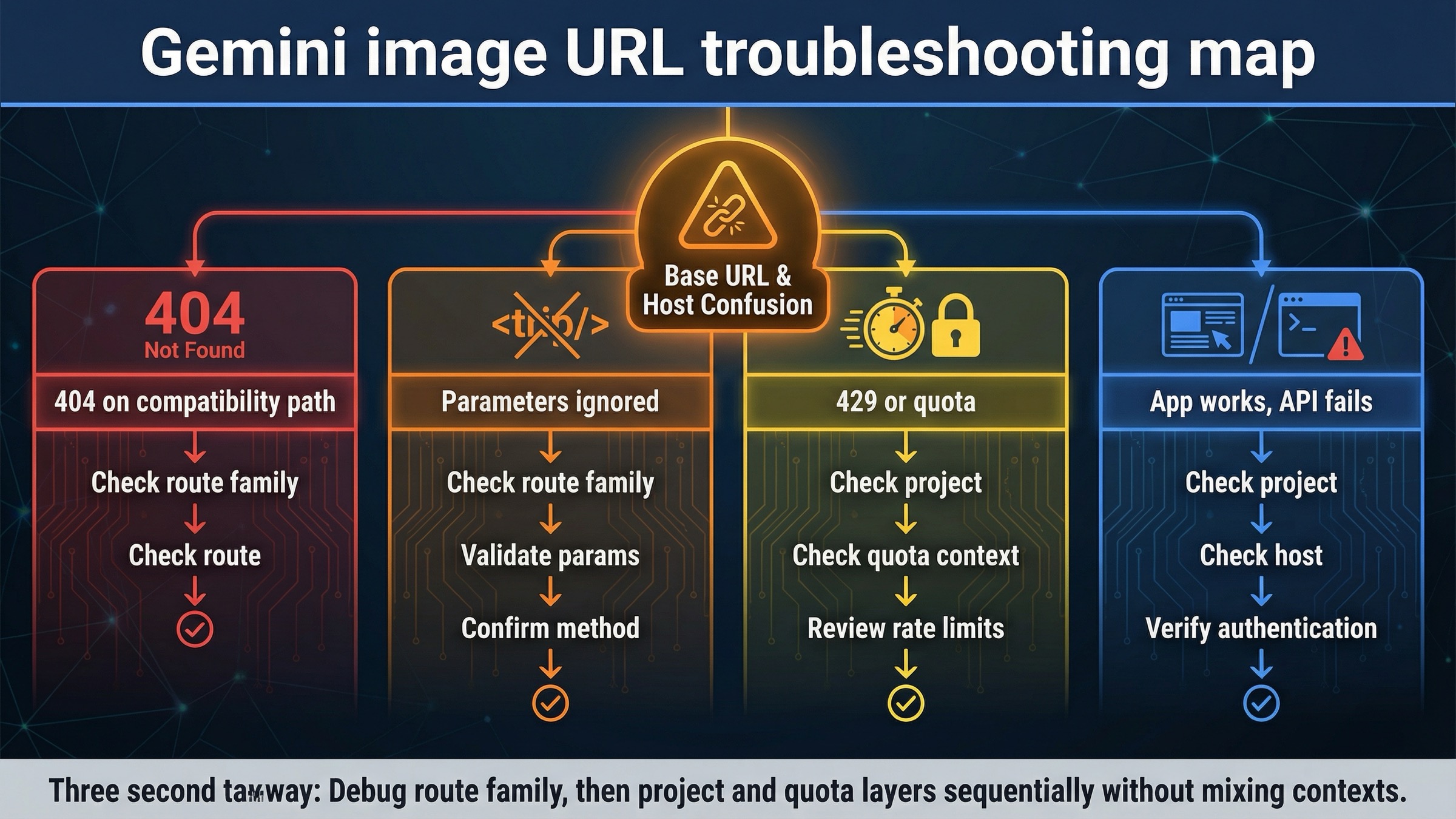
No todos los errores de image generation son culpa de la base URL. Los hilos recientes del foro lo dejan claro: muchos desarrolladores ven 404, model not found o parámetros ignorados y asumen que todo el host está mal. Muy a menudo el problema real es más específico.
| Lo que ves | Lo que suele significar | Qué hacer después |
|---|---|---|
| 404 o model not found en una ruta compatible con OpenAI | Estás usando la familia de endpoints equivocada para un modelo o comportamiento que encaja mejor en la ruta nativa generateContent | Repite la misma tarea con el host nativo de Gemini |
imageSize o aspectRatio parecen ignorados | Estás dentro de la capa compatible y esos controles no forman parte del conjunto de imagen documentado allí | Si esos controles importan, vuelve a la Gemini API nativa |
| En AI Studio o en la app funciona, pero en código no | El comportamiento de la UI y el del proyecto API no son idénticos | Confirma key, proyecto y disponibilidad del modelo antes de tocar el host |
| Corriges la URL y luego aparece un 429 | El host ya es correcto, pero el límite real está en el proyecto o en el tier | Mira las cuotas y límites actuales del proyecto |
| Todo parece parecido, pero el resultado sigue siendo inconsistente | Estás mezclando ejemplos viejos de 2.5, docs nativas de Gemini y supuestos de OpenAI en una sola depuración | Fija una ruta, un modelo y una forma de request hasta obtener la primera imagen |
Aquí la gran trampa suele ser la cuota. La documentación de rate limits dice que los límites se aplican por proyecto, no por API key, y que los requests por día se reinician a medianoche hora del Pacífico. También recuerda que los modelos preview son más restrictivos. Por eso una URL correcta puede seguir fallando si no revisas el contexto del proyecto.
La segunda trampa es la propia capa compatible. El foro de Google ya tiene casos donde una request de imagen sobre la ruta OpenAI-compatible devuelve 404, mientras la misma idea sí funciona cuando se mueve a generateContent. Eso no significa que la compatibilidad sea falsa, sino que la secuencia más segura para depurar sigue siendo: primero demuestra la ruta nativa, luego decide si la capa compatible merece la pena como capa de migración.
Si tu problema ya no es la URL sino un 429, 400 o 500, la continuación lógica es Gemini API error fix 2026: 429, 400, 500.
Qué revisar antes de la primera request
Si quieres evitar varias rondas de depuración inútil, conviene fijar algunas cosas antes de lanzar la primera request real de imagen. Gran parte de la confusión con la base URL no nace de una falta total de documentación, sino de comparar a la vez hosts distintos, modelos distintos y proyectos distintos, como si todos fueran el mismo experimento.
Lo primero es separar Gemini Developer API de Vertex AI. Son productos cercanos, pero no comparten la misma familia de endpoints. Mientras esa frontera no esté clara, un 404 o un model not found se interpreta demasiado fácil como “la base URL está mal”, cuando en realidad el problema puede ser que estás probando sobre el contrato equivocado.
Lo segundo es mantener mínima la superficie de prueba: un host, un modelo, una forma de autenticación y una request corta. No mezcles ?key= con x-goog-api-key, ni hagas saltos entre la ruta nativa y la capa compatible en la misma tanda de pruebas. Cuantas menos variables cambien a la vez, más rápido sabrás cuál está rompiendo la respuesta.
También merece la pena guardar en el repo o en tu runbook interno el endpoint exacto que ya devolvió una imagen válida. Muchos equipos pierden tiempo no por un problema nuevo, sino porque alguien copia una ruta vieja de un hilo del foro, de una issue antigua o de una migración pasada, y la discusión sobre “cuál era la URL correcta” vuelve a empezar desde cero.
Por último, deja proxies, wrappers de SDK, reintentos y capas de compatibilidad para después de validar una request nativa limpia. Cuando la llamada básica ya funciona, cada capa adicional se puede probar de forma aislada. Eso sale mucho más barato que intentar adivinar al mismo tiempo si el fallo está en la URL, el modelo, el proyecto o tu propia abstracción.
La idea de fondo es simple: primero fija un contrato mínimo que ya sabes que responde, y solo después amplía la complejidad. Cuando todo el equipo sigue ese mismo orden, desaparecen muchas discusiones repetidas sobre si el problema estaba en la base URL o en otra capa distinta.
Además, ese método deja una referencia verificable para onboarding, soporte interno y futuras migraciones, en lugar de depender de memoria o de capturas sueltas de la documentación.
No mezcles Gemini Developer API, AI Studio y la app
Este keyword se enreda porque Google muestra productos relacionados pero distintos en la misma primera página.
El Gemini Developer API es donde pertenece el host generativelanguage.googleapis.com. Ese es el contrato que responde esta guía.
AI Studio es una UI y una superficie de proyecto cercana a la API, pero no convierte el problema en “copiar lo que ves en la interfaz”. Siguen importando el proyecto, el billing y la disponibilidad del modelo. La FAQ oficial de billing dice que AI Studio sigue siendo gratuito salvo que se vincule una API key de pago para funciones de pago, pero eso no cambia qué host es el correcto para una request nativa de imágenes.
La Gemini app está todavía más lejos de la pregunta sobre base URL. Sirve para generar y editar imágenes de forma manual, pero la experiencia de la app no es el contrato real que ejecutará tu código. Por eso ayuda a entender límites de producto, no a responder la ruta endpoint.
Si en realidad estás sobre Vertex AI, para y confirma ese punto primero. Vertex AI tiene su propia familia de endpoints, y copiar el host del Gemini Developer API a un proyecto de Vertex es perder tiempo en la capa equivocada.
Conclusión
Para la generación actual de imágenes con el Gemini Developer API, la respuesta por defecto es:
texthttps://generativelanguage.googleapis.com/v1beta
Y la primera ruta que deberías probar es:
text/models/gemini-3.1-flash-image-preview:generateContent
Cambia a:
texthttps://generativelanguage.googleapis.com/v1beta/openai/
solo cuando tu stack de verdad necesite seguir sobre la capa compatible con OpenAI.
Ese sigue siendo el mejor punto de partida porque coincide con la documentación nativa actual de Gemini, aclara mejor el contrato de imagen y evita el error más común detrás de esta consulta: asumir que la URL compatible con OpenAI es la respuesta universal para cualquier request de imágenes en Gemini.