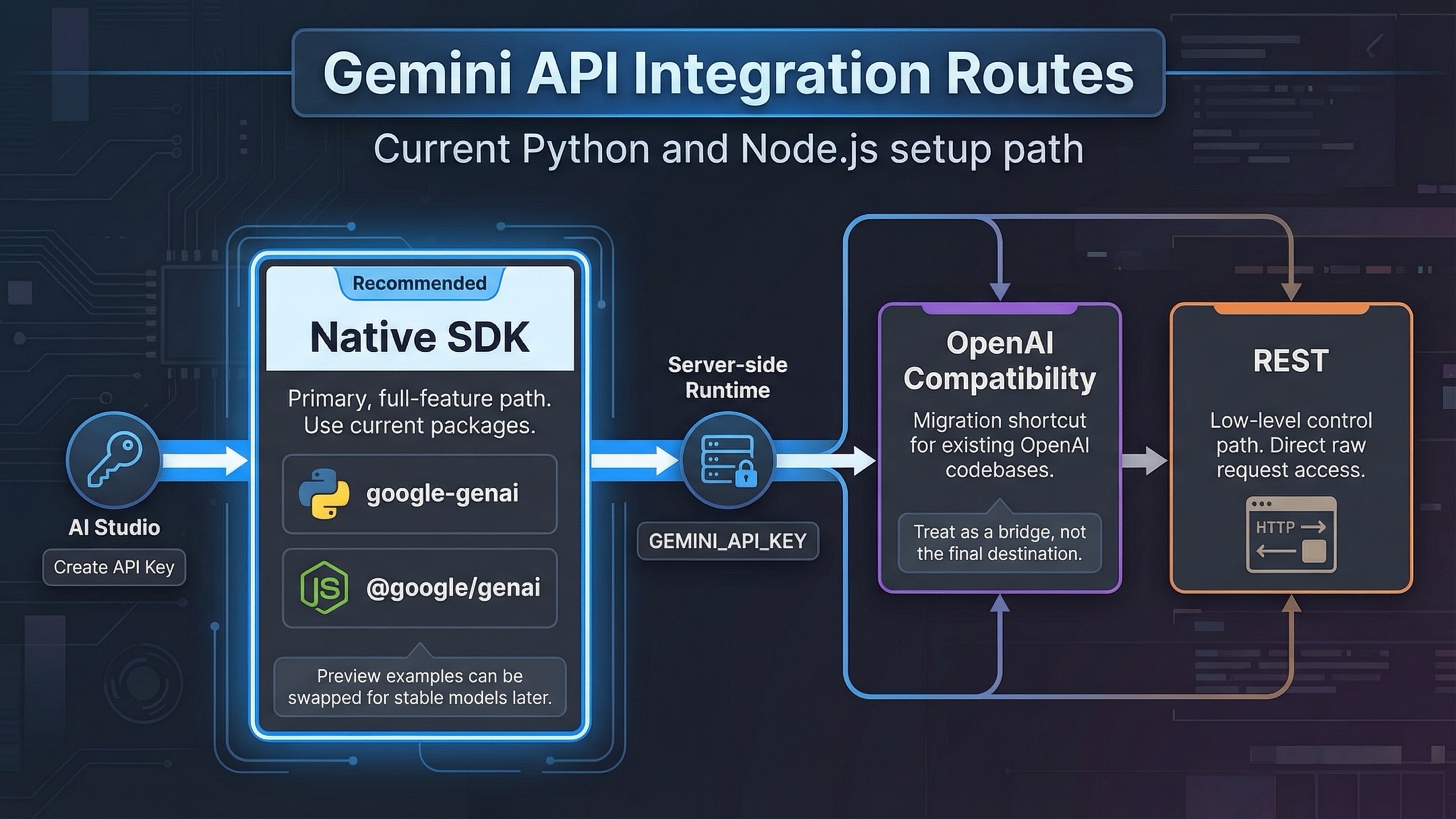
Si vas a empezar una integración nueva con Gemini API hoy, arranca con el SDK nativo de Google GenAI, guarda GEMINI_API_KEY en el servidor y consigue primero una petición mínima que funcione antes de añadir streaming, tools o archivos. La capa de compatibilidad de OpenAI solo debería ir primero cuando ya tengas una base de código con forma OpenAI y necesites un puente rápido de migración. Ese es el default más seguro porque el quickstart, la migration guide y los repositorios de ejemplo actuales de Google ya giran alrededor de google-genai para Python y @google/genai para JavaScript.
El trabajo útil de esta guía es fijar bien la ruta del primer día. Primero aseguras el SDK correcto, el límite correcto del secreto y la primera llamada exitosa; después añades streaming, structured output, tool calling, Files API y la revisión de billing y rate limits. Ese orden vale más que otro hello world genérico porque evita que te metas desde el principio en paquetes viejos, model IDs viejos o una frontera de producción equivocada.
Los ejemplos oficiales actuales siguen usando con frecuencia IDs preview como gemini-3-flash-preview, así que aquí los mantengo cuando reflejan la documentación viva. Pero la regla de producción es otra: si existe un modelo estable que encaja con tu caso, es más seguro usar el ID estable. La propia guía de modelos de Google dice que la mayoría de las apps de producción deberían usar un stable model específico cuando exista uno adecuado. En la práctica, eso significa que puedes prototipar con los ejemplos de esta guía y después cambiar a algo como gemini-2.5-flash si buscas menos churn.
Resumen rápido
- Para proyectos nuevos, usa
google-genaien Python y@google/genaien JavaScript. Esa es la ruta oficial actual y la guía de migración de Google recomienda dejar atrás las librerías Gemini antiguas. - Crea la key en Google AI Studio, guárdala en
GEMINI_API_KEYy llama a Gemini desde backend, worker o server route, no desde el navegador. - Primero haz funcionar una llamada nativa simple. Después aprende streaming. Luego añade una pieza de producción de verdad: salida estructurada, tool calling o Files API si el caso lo necesita.
- La compatibilidad OpenAI es útil para migrar una base de código existente, pero no es el mejor camino de largo plazo si necesitas funciones nativas de Gemini como Files API o flujos de herramientas más ricos.
- Si el tamaño total de la request supera 100 MB, o el PDF supera 50 MB, debes pasar a Files API. La guía oficial también indica 48 horas de retención, 20 GB por proyecto y 2 GB por archivo.
- En billing Google aclara que los errores 400 y 500 no se cobran, pero sí consumen cuota. Y en rate limits deja claro que los límites dependen del tier y se consultan en AI Studio.
| Ruta | Ideal para | Ventaja principal | Coste o límite principal |
|---|---|---|---|
| Google GenAI SDK nativo | Apps nuevas en Python o Node.js | Paquetes actuales, documentación viva y acceso directo a streaming, JSON estructurado, files y tools | Hay que aceptar la forma nativa de Gemini, no solo abstracciones estilo OpenAI |
| Compatibilidad OpenAI | Código existente con interfaz OpenAI | Migración más rápida: cambias base URL, API key y model name | Menor techo funcional y más fricción cuando necesitas capacidades nativas de Gemini |
| REST directo | Lenguajes no cubiertos, control fino, debugging | Máximo control y cero peso de SDK | Más boilerplate, más validación manual y menos helpers |
Si después quieres seguir por el ángulo de costes, la pieza vecina más útil es Gemini API token pricing. Si lo tuyo ya es troubleshooting operativo, el siguiente paso correcto es Gemini API error troubleshooting guide.
Cómo hacer la primera request correcta a Gemini API
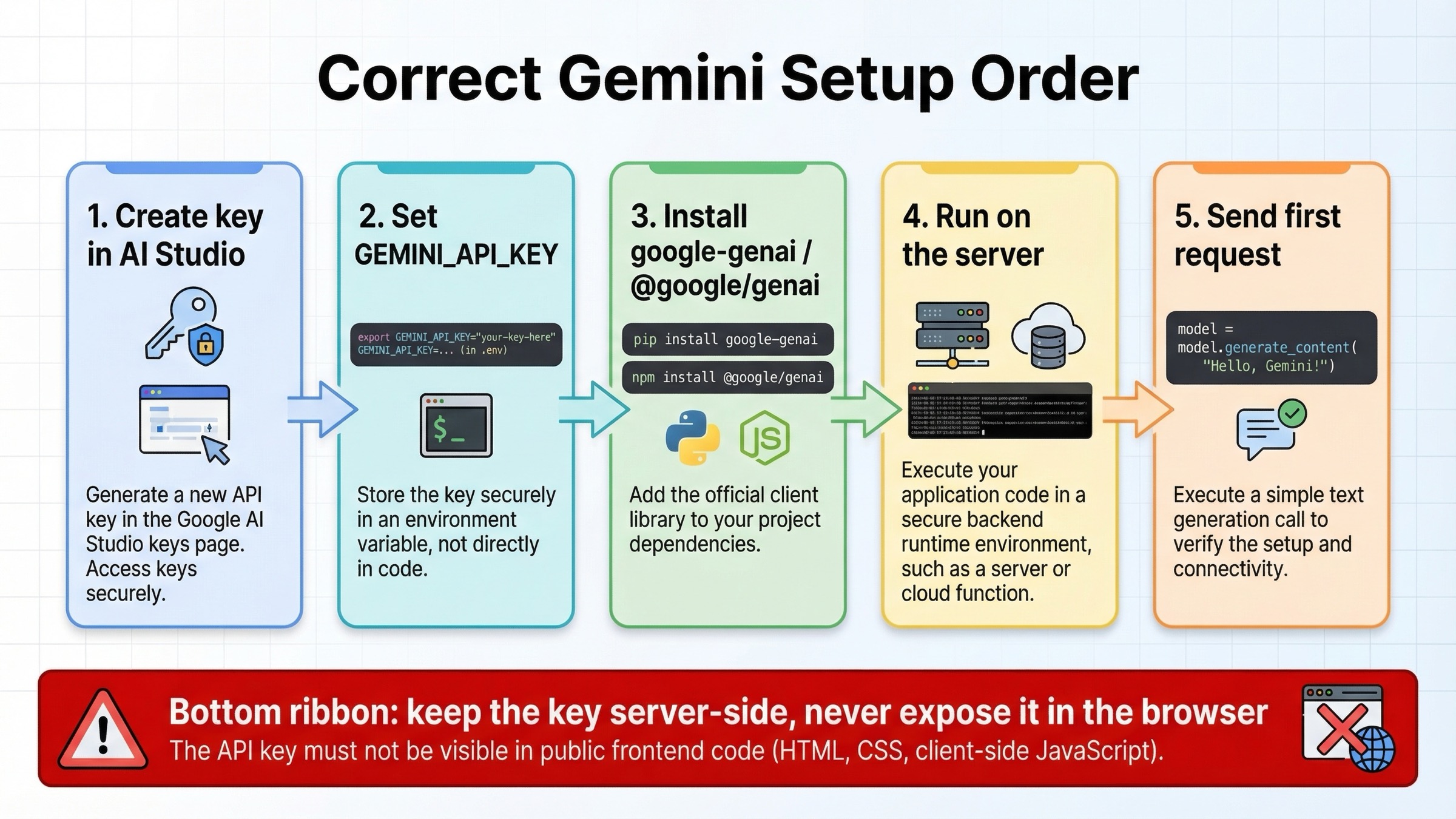
El inicio correcto está en AI Studio, no en el editor. Hoy Google gestiona la creación y administración de claves de Gemini API desde Google AI Studio, y cada key pertenece a un proyecto de Google Cloud. Para un usuario nuevo eso puede resultar cómodo porque AI Studio suele crear un proyecto y una key por defecto, pero también significa que conviene pensar antes en la propiedad del proyecto, el billing y los permisos del equipo.
La primera regla importante no es sintáctica, sino operativa: mantén GEMINI_API_KEY en el servidor. Si construyes un backend, guárdala como variable de entorno. Si construyes una web app, llama a Gemini desde una API route, server action, edge backend o worker, no desde el navegador público. Ese hábito vale más que cualquier snippet brillante porque evita el error más repetido en integraciones LLM tempranas.
La instalación oficial actual es esta:
bashpip install -U google-genai npm install @google/genai
Y luego:
bashexport GEMINI_API_KEY="your_real_key_here"
La primera request debe ser aburrida a propósito. No empieces con function calling, grounding o archivos multimodales. El objetivo inicial es comprobar que key, runtime, red y cliente están bien.
pythonfrom google import genai client = genai.Client() response = client.models.generate_content( model="gemini-3-flash-preview", contents="Explain the purpose of an API integration tutorial in one sentence." ) print(response.text)
javascriptimport { GoogleGenAI } from "@google/genai"; const ai = new GoogleGenAI({}); const response = await ai.models.generateContent({ model: "gemini-3-flash-preview", contents: "Explain the purpose of an API integration tutorial in one sentence.", }); console.log(response.text);
Aquí lo importante no es el prompt, sino la forma del cliente. El nuevo SDK centraliza models, chats y files detrás de un único client. Por eso tantos tutoriales antiguos hoy se sienten confusos: no solo están viejos, sino que enseñan una estructura que Google ya dejó atrás como ruta principal.
Ejemplos de integración en Python que siguen vigentes en 2026
Python sigue siendo la ruta más cómoda cuando quieres ejemplos cortos y, al mismo tiempo, acceso a helpers potentes. La mejora más útil después de la request básica no es “más prompt engineering”, sino streaming. La guía oficial de text generation muestra generate_content_stream, y esa es la primera capacidad que realmente cambia la experiencia de producto.
pythonfrom google import genai client = genai.Client() stream = client.models.generate_content_stream( model="gemini-3-flash-preview", contents="Write three short tips for migrating from a legacy LLM SDK." ) for chunk in stream: print(chunk.text, end="")
Ese patrón importa porque muchas apps no necesitan una conversación compleja, pero sí necesitan bajar la latencia percibida. Un CLI, una web UI o una consola interna se sienten mucho mejor cuando la respuesta empieza a aparecer antes de que toda la generación termine.
La segunda capacidad que merece entrar pronto es la salida estructurada. La guía de structured outputs deja claro que Gemini puede seguir un JSON Schema, y la ruta Python además se integra bien con Pydantic. Para cualquier workflow donde la salida vaya a otra máquina y no solo a ojos humanos, esto es mucho más seguro que confiar en un “por favor responde en JSON”.
pythonfrom google import genai from google.genai import types from pydantic import BaseModel class IntegrationTicket(BaseModel): language: str task: str priority: str client = genai.Client() response = client.models.generate_content( model="gemini-3-flash-preview", contents="Python app, needs JSON output, shipping next week.", config=types.GenerateContentConfig( response_mime_type="application/json", response_schema=IntegrationTicket, ), ) print(response.text)
Una vez que el schema entra en la request, el prompt puede centrarse en significado y no en disciplina de formato. Ese cambio es una de las diferencias más claras entre un demo de laboratorio y una integración que empieza a tocar sistemas de verdad.
Python también tiene una ventaja específica en function calling: la guía oficial explica que puedes pasar funciones Python con type hints y docstring, y el SDK gestiona por ti la declaración, la ejecución y el ciclo de respuesta. Eso es excelente para herramientas internas, flujos operativos o agentes ligeros.
pythonfrom google import genai from google.genai import types def get_current_temperature(location: str) -> dict: """Gets the current temperature for a given location.""" return {"temperature": 25, "unit": "Celsius"} client = genai.Client() response = client.models.generate_content( model="gemini-3-flash-preview", contents="What's the temperature in Boston?", config=types.GenerateContentConfig(tools=[get_current_temperature]), ) print(response.text)
Eso sí: esa comodidad funciona mejor cuando Python controla realmente el entorno de ejecución. Si más adelante necesitas una capa de tooling compartida entre varios servicios o varios lenguajes, la comodidad automática ya no siempre equivale a la mejor arquitectura.
Ejemplos de integración para JavaScript y Node.js
En Node.js la forma del cliente es parecida a Python, pero el principal riesgo es la frontera de ejecución. Muchos desarrolladores JS trabajan sobre productos web y pueden caer demasiado pronto en el error de mezclar key, SDK y lógica del frontend. El paquete @google/genai actual está bien; lo importante es dónde se ejecuta: backend, API route, worker o superficie server-side.
La primera llamada debería verse así:
javascriptimport { GoogleGenAI } from "@google/genai"; const ai = new GoogleGenAI({}); const response = await ai.models.generateContent({ model: "gemini-3-flash-preview", contents: "Give me a one-line summary of why current SDK names matter.", }); console.log(response.text);
Y el siguiente paso lógico vuelve a ser streaming:
javascriptimport { GoogleGenAI } from "@google/genai"; const ai = new GoogleGenAI({}); const stream = await ai.models.generateContentStream({ model: "gemini-3-flash-preview", contents: "List three practical steps for hardening an API integration.", }); for await (const chunk of stream) { process.stdout.write(chunk.text ?? ""); }
Ese patrón es especialmente valioso en Next.js, Express o cualquier backend JS que sirva respuestas incrementales al cliente. Mantienes la key del lado servidor y, al mismo tiempo, mejoras mucho la experiencia del usuario.
JavaScript también soporta structured output y configuraciones de function calling, aunque con una ergonomía más explícita que la de Python. Eso no es necesariamente una desventaja. Para equipos TypeScript puede ser mejor porque encaja mejor con tipos, schemas y límites de servicio ya existentes.
Tampoco conviene ignorar el conteo de tokens hasta que llegue la factura. La guía oficial de tokens recomienda usar los métodos de count tokens y usage_metadata para medir el tamaño real de prompts y respuestas. En productos JS, donde el contexto tiende a crecer con rapidez, medir pronto es parte de integrar bien.
Cuándo sí conviene usar la compatibilidad OpenAI
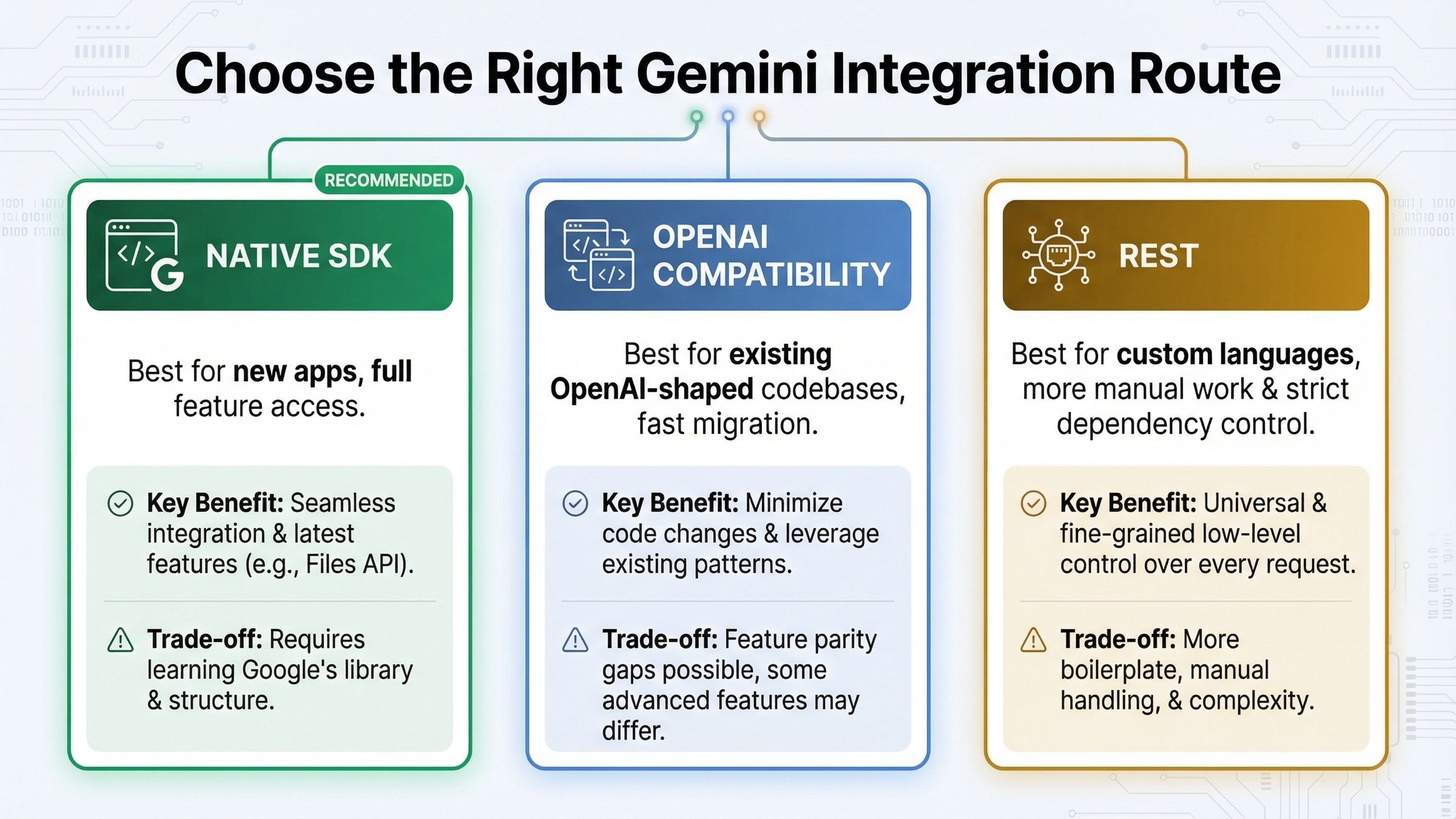
La compatibilidad OpenAI no es marketing vacío. Google documenta claramente que la ruta rápida consiste en cambiar la base URL, la API key y el model name. Si ya tienes una capa OpenAI bien integrada en un backend o gateway interno, esta es la forma más rápida de comprobar si Gemini encaja con tus flujos.
pythonfrom openai import OpenAI client = OpenAI( api_key="YOUR_GEMINI_API_KEY", base_url="https://generativelanguage.googleapis.com/v1beta/openai/", ) response = client.chat.completions.create( model="gemini-3-flash-preview", messages=[{"role": "user", "content": "Explain why compatibility layers are useful."}], ) print(response.choices[0].message.content)
Esta ruta gana por dos motivos. Primero, minimiza el cambio cuando ya existe una arquitectura con mensajes estilo OpenAI. Segundo, facilita pruebas de proveedor, BYOK y validaciones rápidas con el menor movimiento posible.
Pero no debería venderse como la mejor respuesta universal. La propia guía oficial para integradores dice que esta capa es excelente cuando priorizas portabilidad, pero se queda corta cuando necesitas más capacidad nativa: File API, herramientas específicas, o flujos más cercanos a la arquitectura real de Gemini. Cuanto más específica sea tu necesidad, más probable es que la compatibilidad se convierta en fricción.
La regla práctica es sencilla. Si migras rápido una base existente, empieza por compatibilidad. Si construyes una app nueva sobre Gemini, empieza por el SDK nativo. Eso te evita pagar una segunda migración más tarde solo por haber conservado una abstracción familiar al principio.
Qué aprender justo después del hello world
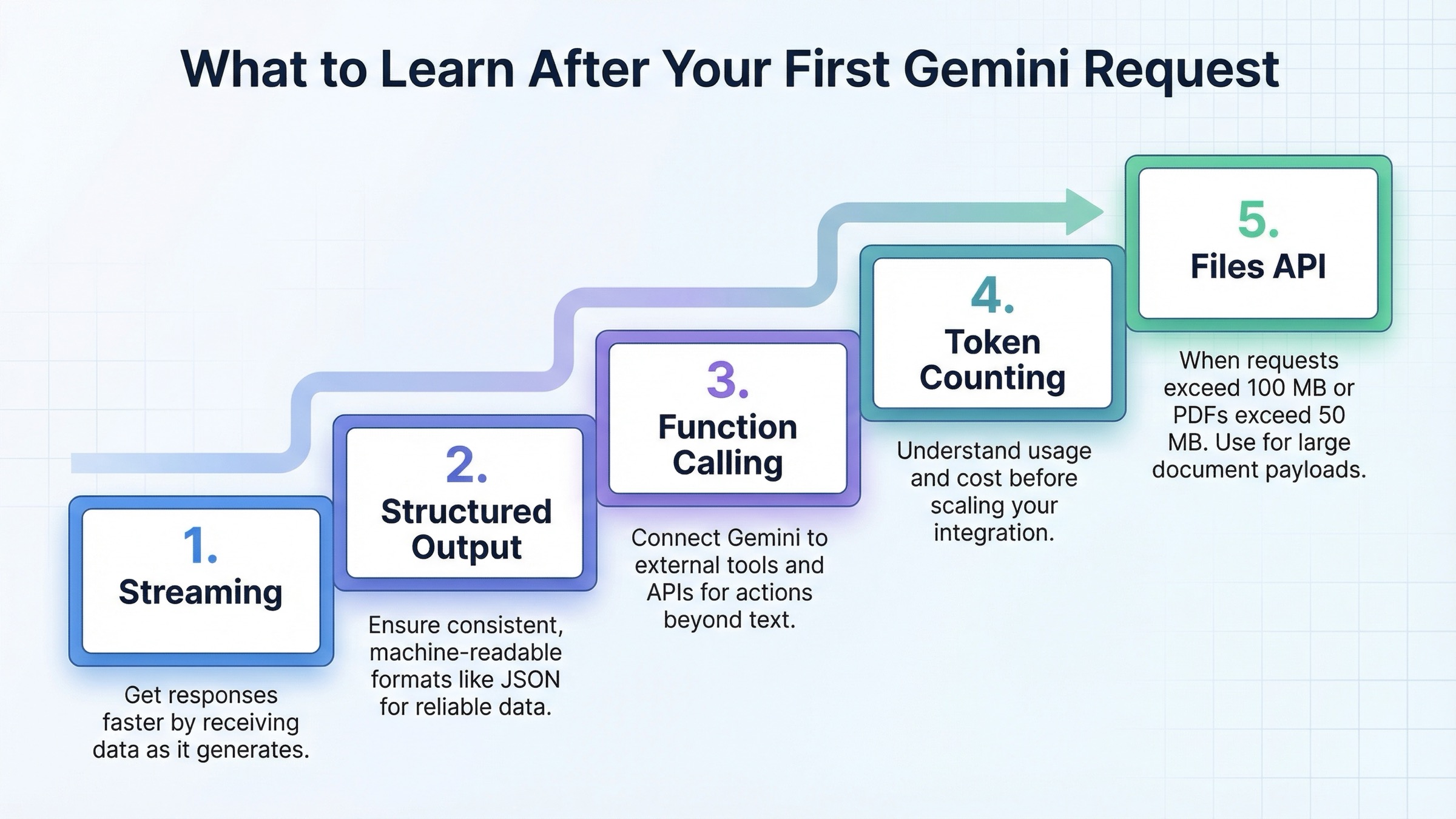
Después de la primera request exitosa, el error típico es intentar aprender todo Gemini de golpe. La mejor secuencia suele ser otra: streaming, structured output, function calling, token counting y, cuando haga falta, Files API.
Streaming mejora la sensación de rapidez. Structured output mejora la fiabilidad cuando otra pieza de software depende del resultado. Function calling abre la puerta a flujos donde Gemini coordina acciones con tu código. Token counting te da visibilidad de coste antes de que el tráfico crezca. Files API entra cuando de verdad trabajas con cargas grandes o multimodales.
La guía oficial de Files API da umbrales concretos que sí importan en arquitectura: usa Files API cuando el tamaño total de la request supera 100 MB, o cuando el PDF supera 50 MB. Además, fija reglas operativas claras: 48 horas de almacenamiento, 20 GB por proyecto y 2 GB por archivo.
javascriptimport { GoogleGenAI, createPartFromUri, createUserContent, } from "@google/genai"; const ai = new GoogleGenAI({}); const myfile = await ai.files.upload({ file: "path/to/sample.mp3", config: { mimeType: "audio/mpeg" }, }); const response = await ai.models.generateContent({ model: "gemini-3-flash-preview", contents: createUserContent([ createPartFromUri(myfile.uri, myfile.mimeType), "Describe this audio clip", ]), }); console.log(response.text);
La idea no es subir archivos “porque sí”. Si el prompt es pequeño y textual, la request simple sigue siendo la mejor request. Pero si realmente vas a mover documentos, audio o entradas grandes, entender desde temprano los límites y el ciclo de vida de Files API ahorra muchos errores tontos más adelante.
| Capacidad | Cuándo aprenderla | Por qué cambia de verdad la integración | Referencia oficial |
|---|---|---|---|
| Streaming | Justo después de la primera request | Mejora UX y latencia percibida | Text generation |
| Structured Output | Cuando otro sistema consume la salida | Es mucho más seguro que “devuélveme JSON” | Structured outputs |
| Function Calling | Cuando Gemini debe disparar lógica o tools | Permite workflows agentic más controlables | Function calling |
| Token Counting | Antes de escalar tráfico | Mide coste y crecimiento real del contexto | Token counting |
| Files API | Cuando la request supera 100 MB o el PDF 50 MB | Soporta cargas grandes y multimodales | Files API |
El valor de esta secuencia es precisamente que evita dos extremos: quedarse en el hello world para siempre, o convertir la primera semana de integración en una enciclopedia de features.
Errores típicos y troubleshooting al integrar Gemini
El error más común es arrancar desde la guía equivocada. Si ves tutoriales que todavía presentan google-generativeai o @google/generative-ai como la opción actual por defecto, detente y compáralos con la migration guide oficial. El problema no es solo que estén viejos, sino que te empujan hacia una forma de cliente que Google ya dejó atrás.
El segundo error frecuente es tratar los modelos preview como si fueran contratos estables. La guía de modelos de Google deja claro que se pueden usar en producción, pero suelen traer más riesgo de cambio y límites más agresivos. Eso no significa “nunca uses preview”; significa “úsalo sabiendo por qué y con un plan de cambio si luego necesitas fijarte en un stable model”.
El tercer error es leer mal billing y quota. La página oficial de billing dice con claridad que se cobra por input tokens, output tokens, cached token count y cached token storage duration. También aclara que 400 y 500 no se cobran, pero siguen descontando cuota. Eso importa mucho: una request fallida puede no costarte dinero y aun así costarte capacidad.
Por eso 429 no siempre se resuelve solo con exponential backoff. La página de rate limits explica que los límites dependen del tier y se ven en AI Studio, y los hilos de comunidad muestran una realidad más incómoda: a veces el problema no es RPM visible, sino cuotas de proyecto, batch enqueued tokens o capacidad más inestable en superficies preview.
El cuarto error es intentar dominar todas las capacidades en la primera semana. No necesitas streaming, tools, files, caching y chat history el primer día. Necesitas una request simple que funcione, una frontera de secreto correcta y la siguiente capacidad que realmente cambie el producto que estás construyendo.
Si ya estás en fase de errores operativos, la continuación más útil es Gemini API error troubleshooting guide. Si la duda principal pasó a ser coste o estructura de tokens, el mejor complemento es Gemini API token pricing. El resumen operativo de esta guía cabe en una línea: empieza nativo, deja la key en el servidor, mide tokens pronto y añade capacidades en el orden correcto.