
En marzo de 2026, el precio de Gemini API para los modelos de texto se mueve entre 0,10 USD y 2,00 USD por cada 1 millón de tokens de entrada, y entre 0,40 USD y 12,00 USD por cada 1 millón de tokens de salida. Gemini 2.5 Flash-Lite sigue siendo la opción estable más barata para texto. Si necesitas quedarte dentro de la familia Gemini 3, hoy la vía económica real es Gemini 3.1 Flash-Lite Preview. Y Gemini 3.1 Pro Preview es la ruta premium actual, con una advertencia importante: en cuanto el prompt supera los 200K tokens, el coste sube de forma clara.
Usa esta página como una guía rápida de presupuesto. Primero necesitas decidir qué modelo meter en la previsión de costes, en qué punto el umbral de 200K tokens cambia la cuenta y qué modificadores pueden disparar la factura real aunque la tabla principal parezca barata. Por eso aquí me quedo solo en la superficie de Gemini Developer API y separo Batch, caching, grounding, audio y el umbral de contexto largo, que son los factores que más mueven el gasto real.
Resumen rápido
- Modelo de texto estable más barato: Gemini 2.5 Flash-Lite, 0,10 USD por 1M de tokens de entrada y 0,40 USD por 1M de tokens de salida.
- Modelo Gemini 3 más barato para texto: Gemini 3.1 Flash-Lite Preview, 0,25 USD por 1M de tokens de entrada y 1,50 USD por 1M de tokens de salida.
- Ruta premium actual: Gemini 3.1 Pro Preview, 2,00 / 12,00 USD por 1M de tokens hasta 200K y 4,00 / 18,00 USD por encima de ese umbral.
- La opción equilibrada para muchas apps en producción: Gemini 2.5 Flash sigue siendo la recomendación más sensata para empezar.
- La palanca de ahorro más rápida: el modo Batch, que en las rutas principales suele costar aproximadamente la mitad.
- El error más común: comparar solo el precio input/output y olvidar el umbral de 200K, el audio, el caching, el almacenamiento del cache y los cargos de grounding.
Tabla de precio por token de Gemini API en marzo de 2026
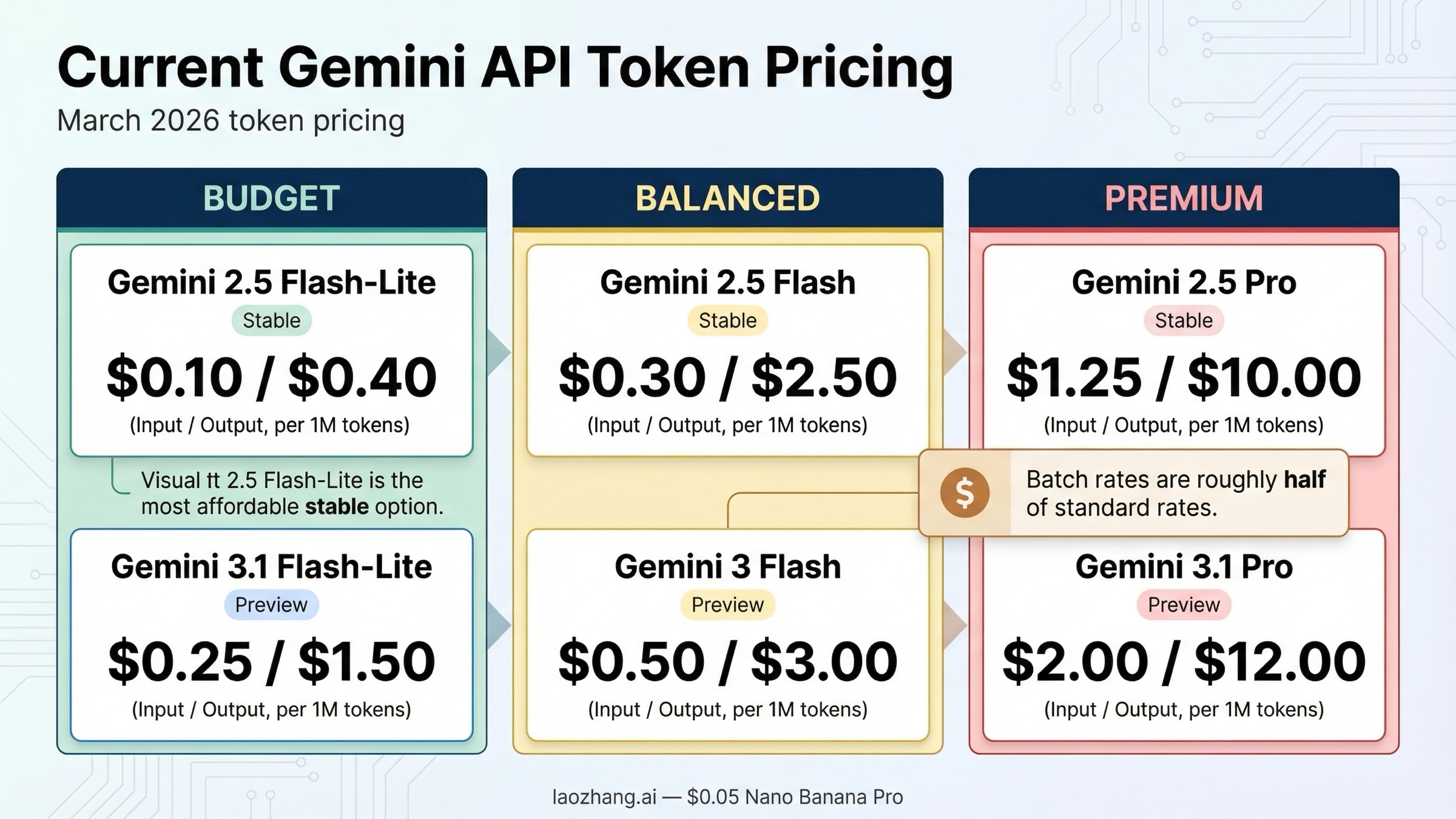
La página oficial de precios de Gemini Developer API es la fuente correcta, pero no siempre es la forma más rápida de entender el panorama si solo quieres comparar las rutas más relevantes. Esta tabla resume las líneas de texto que hoy importan más para la mayoría de desarrolladores.
| Modelo | Precio estándar input | Precio estándar output | Batch input | Batch output | Nota |
|---|---|---|---|---|---|
| Gemini 3.1 Pro Preview | 2,00 USD por 1M hasta 200K, 4,00 USD por encima | 12,00 USD hasta 200K, 18,00 USD por encima | 1,00 USD hasta 200K, 2,00 USD por encima | 6,00 USD hasta 200K, 9,00 USD por encima | Solo paid, ruta premium actual |
| Gemini 3 Flash Preview | 0,50 USD por text / image / video; 1,00 USD por audio | 3,00 USD | 0,25 USD por text / image / video; 0,50 USD por audio | 1,50 USD | Ruta rápida de Gemini 3, con free tier |
| Gemini 3.1 Flash-Lite Preview | 0,25 USD por text / image / video; 0,50 USD por audio | 1,50 USD | 0,125 USD por text / image / video; 0,25 USD por audio | 0,75 USD | La opción de texto más barata dentro de Gemini 3 |
| Gemini 2.5 Pro | 1,25 USD hasta 200K, 2,50 USD por encima | 10,00 USD hasta 200K, 15,00 USD por encima | 0,625 USD hasta 200K, 1,25 USD por encima | 5,00 USD hasta 200K, 7,50 USD por encima | Alternativa potente pero más barata que 3.1 Pro |
| Gemini 2.5 Flash | 0,30 USD por text / image / video; 1,00 USD por audio | 2,50 USD | 0,15 USD por text / image / video; 0,50 USD por audio | 1,25 USD | Ruta estable y equilibrada |
| Gemini 2.5 Flash-Lite | 0,10 USD por text / image / video; 0,30 USD por audio | 0,40 USD | 0,05 USD por text / image / video; 0,15 USD por audio | 0,20 USD | La opción estable más barata |
De esta tabla conviene sacar dos conclusiones rápidas.
La primera es que la línea actual de Google no funciona como una escalera simple en la que lo más nuevo sea automáticamente lo más rentable. Si tu objetivo es el menor coste estable, la mejor opción sigue siendo Gemini 2.5 Flash-Lite. Si necesitas quedarte específicamente en Gemini 3, entonces el carril económico real es Gemini 3.1 Flash-Lite Preview. Muchas páginas de comparación reducen todo a “precio Gemini 3”, y eso hace más difícil tomar una decisión útil.
La segunda es que todavía aparecen páginas antiguas con Gemini 3 Pro Preview como si siguiera activo. En la página oficial de modelos, Google indica que Gemini 3 Pro Preview fue retirado el 9 de marzo de 2026 y que la migración correcta es a Gemini 3.1 Pro Preview. Si una guía no refleja ese cambio, es muy probable que también arrastre cifras viejas en el resto de la tabla.
Qué modelo Gemini deberías presupuestar
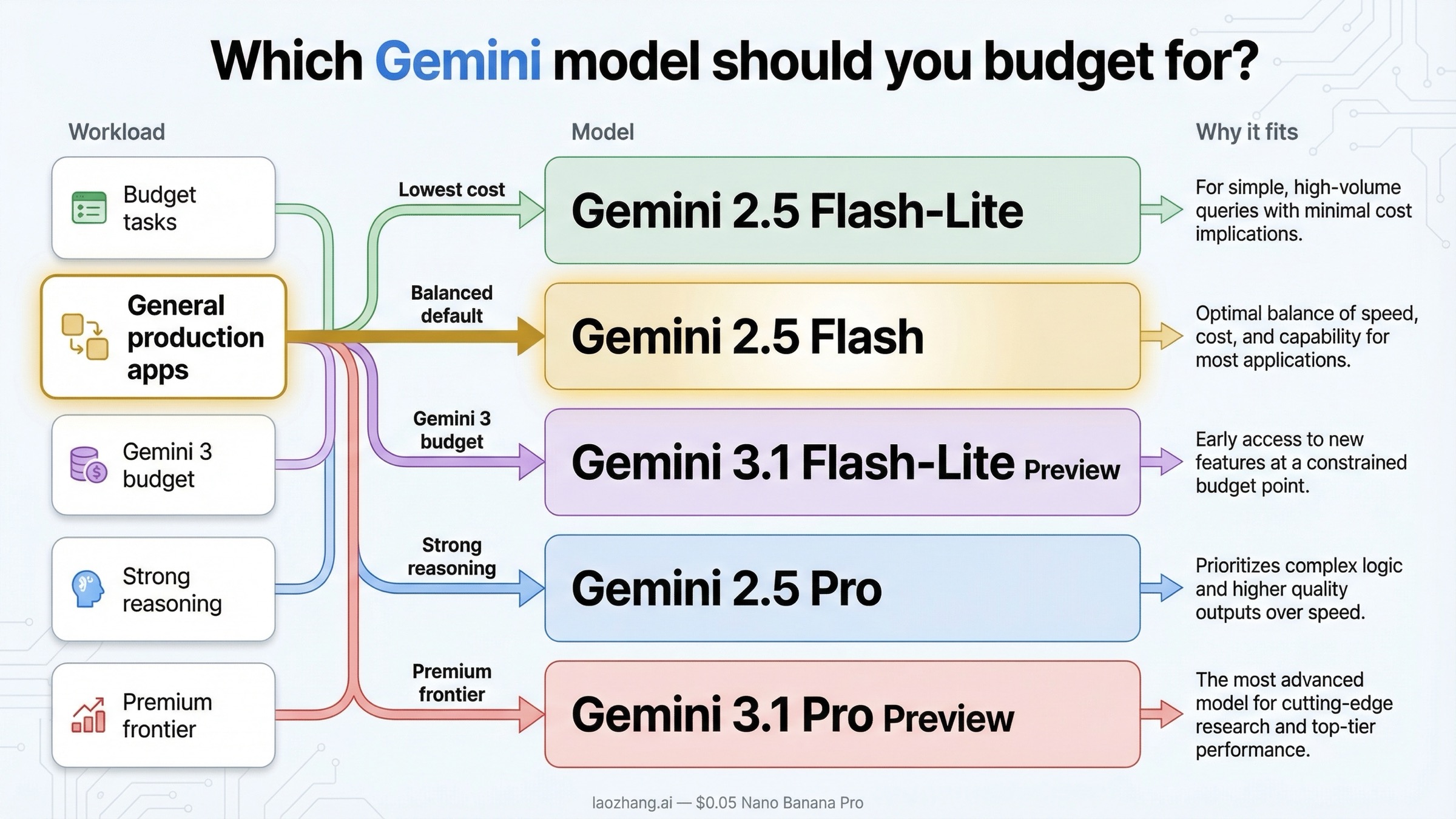
La pregunta útil aquí no es “qué modelo es el más potente”, sino qué carril de modelo encaja mejor con tu carga de trabajo. Si te limitas a seguir el nombre más nuevo, el presupuesto suele quedar mal calculado.
Si tu prioridad absoluta es bajar el coste, Gemini 2.5 Flash-Lite sigue siendo la respuesta más directa. Es una opción muy sólida para clasificación, extracción, traducción ligera, enrutamiento, chat sencillo y procesamiento de alto volumen, donde importa más el throughput que la máxima profundidad de razonamiento. En muchos casos, pagar más simplemente no devuelve suficiente valor.
Si quieres una opción más segura como punto de partida para producción, Gemini 2.5 Flash sigue siendo la recomendación más equilibrada. Cuesta más que Flash-Lite, pero no se acerca al nivel de Pro. Para asistentes internos, bots de soporte, preguntas sobre documentos, automatización operativa y flujos ligeros con agentes, suele ser suficiente. Por eso sigue siendo el default más práctico.
Si tu equipo quiere mantenerse en Gemini 3 pero no pagar ya el precio de Pro, la ruta lógica es Gemini 3.1 Flash-Lite Preview. No es más barata que 2.5 Flash-Lite, pero sí es el punto de entrada de bajo coste dentro de la familia Gemini 3. Tiene sentido cuando tu organización prioriza el stack más nuevo y acepta el riesgo natural de los modelos preview.
Si el trabajo realmente requiere razonamiento fuerte, entonces la comparación real pasa a ser Gemini 2.5 Pro frente a Gemini 3.1 Pro Preview. Gemini 2.5 Pro ya no es barato, pero sigue siendo sensiblemente más accesible que 3.1 Pro. Para generación de código, síntesis compleja, planificación agentic o análisis de documentos largos, pagar la prima de 3.1 Pro solo tiene sentido si el incremento de calidad compensa el coste.
Esa es precisamente la parte que muchas páginas genéricas no formulan con claridad. La decisión práctica hoy es:
- coste mínimo: Gemini 2.5 Flash-Lite
- equilibrio estable: Gemini 2.5 Flash
- presupuesto dentro de Gemini 3: Gemini 3.1 Flash-Lite Preview
- razonamiento fuerte sin precio máximo: Gemini 2.5 Pro
- ruta premium de frontera: Gemini 3.1 Pro Preview
Si todavía estás en fase de pruebas, no conviertas automáticamente la experiencia gratuita de AI Studio en una estimación de coste de producción. El billing FAQ deja claro que AI Studio puede seguir siendo gratuito hasta que conectas una paid API key a funciones de pago. Probar algo gratis no significa que la misma carga vaya a costar cero en producción.
Qué incluye realmente tu factura de Gemini
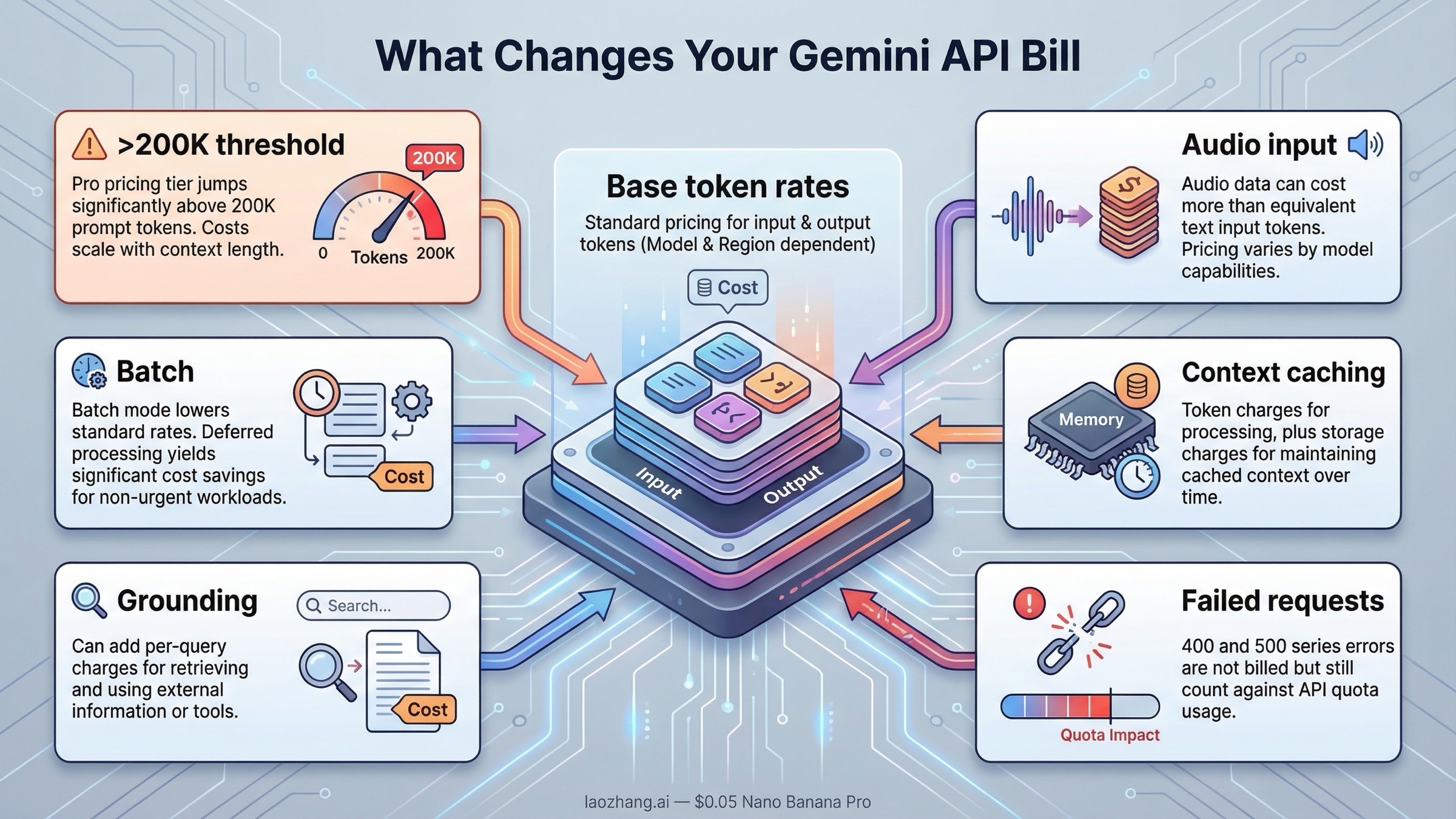
Muchas guías de “precio Gemini” se quedan en la tabla principal, pero la parte más importante empieza después. En la página de billing, Google explica que Gemini API factura según el número de tokens de entrada, tokens de salida, cached tokens y duración del almacenamiento del cache. Es decir, no pagas solo por lo que escribes ni solo por lo que el modelo responde.
También importa entender qué es un token en la práctica. Según la guía oficial de tokens, un token equivale aproximadamente a 4 caracteres, y 100 tokens equivalen a unas 60–80 palabras en inglés. No es una fórmula exacta de contabilidad, pero sí una referencia útil para no presupuestar mal. Un prompt corto rara vez sale caro; lo que dispara la factura suele ser el contexto repetido, las instrucciones largas de sistema, los fragmentos RAG excesivos o el historial acumulado.
Además, no todos los tipos de input se cobran igual. En varios modelos, el audio input cuesta más que el texto. En las líneas Pro, cruzar el umbral de 200K tokens en el prompt cambia el precio a una banda superior. Y si además usas caching, grounding o multimodalidad, el número que recordabas de la primera fila deja de representar el coste real.
Esta es la tabla corta que conviene tener en mente:
| Modificador de facturación | Qué cambia | Por qué importa |
|---|---|---|
| Prompts Pro por encima de 200K | Gemini 3.1 Pro Preview sube de 2,00 / 12,00 a 4,00 / 18,00; Gemini 2.5 Pro de 1,25 / 10,00 a 2,50 / 15,00 | Las cargas con contexto largo pueden salir mucho más caras de lo previsto |
| Audio input | Flash y Flash-Lite cobran más por audio que por texto | Las apps de voz suelen infrapresupuestarse |
| Modo Batch | En las líneas principales, el precio baja aproximadamente a la mitad | Es la palanca más directa para workloads asíncronos |
| Context caching | Hay coste por cached tokens y por almacenamiento | El caching ahorra, pero no es memoria gratuita |
| Grounding | Puede añadir cargos por consulta | La factura deja de ser solo “precio por token” |
| Errores 400/500 | No se facturan, pero siguen consumiendo cuota | No suben el coste directo, pero sí afectan la capacidad del sistema |
Dos puntos merecen atención especial.
El primero es Batch. Si tu flujo no necesita respuesta inmediata, casi siempre merece la pena presupuestar primero con tarifas batch. Procesamiento nocturno, evaluación offline, reescritura masiva, análisis diferido o grandes backfills suelen beneficiarse más de batch que de cualquier micro-optimización del prompt.
El segundo es Context caching. En Gemini se habla mucho de caching como si bastara con guardar un prompt grande para abaratarlo indefinidamente. En realidad, Google también cobra por cached tokens y por almacenamiento. Por tanto, conviene pensar en caching como una herramienta de optimización y no como memoria gratuita. Si reutilizas mucho el mismo contexto, el ahorro puede ser importante. Si no, no conviene forzarlo. Si además quieres revisar el ángulo de límites y cuotas, la guía localizada sobre Gemini API free quota 2026 es el siguiente paso natural.
Por qué el precio de Gemini puede subir más de lo esperado
Hay tres causas que explican la mayoría de desviaciones entre el precio recordado y la factura real.
La primera es el umbral de 200K tokens en los modelos Pro. En cuanto procesas documentos largos, bases de código amplias, resultados RAG pesados o historiales de conversación muy extensos, puedes entrar en el tramo caro. Por eso, algunas cargas que intuitivamente “parecen de Pro” siguen saliendo mejor en Flash si mejoras la estrategia de recuperación y compactación del contexto.
La segunda es la confusión con la capa gratuita. Mucha gente mezcla “lo pude probar gratis en AI Studio” con “el API seguirá teniendo ese coste”. Pero el comportamiento del free tier depende del modelo, y la lógica de facturación de producción es otra. Basar un presupuesto serio en esa experiencia es una receta para equivocarse.
La tercera es la interacción entre precio y límites. El coste es solo una parte. En la página de rate limits, Google recuerda que los límites se aplican por proyecto, no por API key, y que dependen del modelo y del tier. Cuando ya estás en producción, la pregunta deja de ser solo “qué fila es más barata” y pasa a ser “qué fila me da el throughput que necesito sin romperse”. Si ya te estás peleando con 429, la diferencia de unos céntimos por millón de tokens deja de ser el problema principal.
En otras palabras, los grandes cambios de coste en Gemini suelen venir del carril de modelo, de la longitud del contexto, de si usas Batch o no y de la disciplina con la que gestionas prompts y contexto, no de una pequeña diferencia entre dos filas parecidas.
Diferencia entre Gemini Developer API, Vertex AI y AI Studio
Este keyword genera mucho ruido porque los resultados de búsqueda suelen mezclar varias superficies distintas bajo la misma etiqueta “Gemini pricing”.
Pero, para un desarrollador, no es lo mismo:
- Gemini Developer API es la superficie que importa si estás calculando el coste de llamadas directas al API.
- Vertex AI es la vía corporativa dentro de Google Cloud, con la misma familia de modelos pero dentro de un contexto enterprise más amplio.
- AI Studio es una herramienta de experimentación, no un sustituto directo del modelo de precio de producción.
Muchas páginas amplían el tema añadiendo suscripciones de la app Gemini, Workspace o incluso otros productos de Google. Eso las hace más largas, pero no necesariamente más útiles para una consulta concreta sobre precio por token.
La regla práctica es:
- usa la tabla de Gemini Developer API si estás presupuestando llamadas directas;
- usa Vertex AI pricing si tu carga realmente va por Vertex;
- usa AI Studio solo como superficie de prueba, no como modelo definitivo de coste.
A marzo de 2026, Vertex AI replica en gran medida las mismas rutas principales de precio, pero hace más visible el contexto enterprise, priority y Flex / Batch. Si un artículo externo no aclara qué pricing-surface está usando, conviene desconfiar de sus conclusiones hasta comprobar la fuente oficial.
Ejemplos de coste mensual en cargas habituales
El precio por millón de tokens solo se vuelve útil de verdad cuando lo traduces a cargas concretas.
Escenario 1: bot pequeño de soporte con Gemini 2.5 Flash
Supón 30 millones de tokens de entrada y 10 millones de tokens de salida al mes:
- input: 30 × 0,30 = 9,00 USD
- output: 10 × 2,50 = 25,00 USD
- coste mensual estimado: 34,00 USD
Por eso Gemini 2.5 Flash sigue siendo una recomendación tan sólida: lo bastante barata para producción temprana, sin forzar todavía el nivel más bajo de coste.
Escenario 2: servicio de extracción o enrutamiento con Gemini 2.5 Flash-Lite
Supón 200 millones de tokens de entrada y 40 millones de salida al mes:
- input: 200 × 0,10 = 20,00 USD
- output: 40 × 0,40 = 16,00 USD
- coste mensual estimado: 36,00 USD
Este caso deja claro que el precio de salida también importa mucho. En cargas de alto volumen, Flash-Lite no solo gana por input barato, sino también por output barato.
Escenario 3: coding o síntesis premium con Gemini 3.1 Pro Preview
Supón 20 millones de tokens de entrada y 4 millones de salida, manteniendo cada prompt por debajo de 200K:
- input: 20 × 2,00 = 40,00 USD
- output: 4 × 12,00 = 48,00 USD
- coste mensual estimado: 88,00 USD
La misma carga en Gemini 2.5 Pro:
- input: 20 × 1,25 = 25,00 USD
- output: 4 × 10,00 = 40,00 USD
- coste mensual estimado: 65,00 USD
La prima de 3.1 Pro existe de verdad. No es una diferencia pequeña que puedas ignorar por defecto.
Escenario 4: backfill asíncrono en modo Batch
Si tomas el primer escenario y lo pasas a Batch:
- input: 30 × 0,15 = 4,50 USD
- output: 10 × 1,25 = 12,50 USD
- coste mensual estimado: 17,00 USD
Es casi la mitad. Por eso, antes de pensar en cambiar de proveedor o rediseñar todo el prompt stack, conviene preguntar si la carga puede ejecutarse en modo batch.
Si en este momento te preocupa más el comportamiento del free tier que el coste de producción, el mejor complemento sigue siendo la guía sobre Gemini API free quota 2026. Pero el resumen de esta página es sencillo:
La consulta “Gemini API token pricing” no se resuelve solo diciendo cuánto vale 1 millón de tokens. Se resuelve aclarando qué carril de modelo debes elegir y qué modificadores de facturación cambian el número final. Cuando respondes a esa pregunta, el sistema de precios de Gemini deja de parecer confuso.