
Cuando ChatGPT muestra “Error in message stream”, la respuesta se detuvo antes de terminar el flujo. La primera acción no debe ser recargar la página. Guarda el texto parcial y el prompt original. Después revisa OpenAI Status. Si el estado del servicio no explica el fallo, prueba una rama a la vez: conversación nueva, navegador o app, red y WebSocket, prompt demasiado largo, archivo o imagen, o integración por API.
El problema se vuelve lento cuando se mezclan soluciones. Recargar, borrar caché, desactivar extensiones, cambiar de red, activar VPN, acortar el prompt y volver a generar todo en la misma conversación deja muy poca evidencia. La ruta más rápida es conservar el trabajo, hacer una prueba de control y detenerse cuando una rama ya explicó el síntoma.
| Lo que ves | Primera acción | Cómo verificar | Regla de parada |
|---|---|---|---|
| OpenAI Status muestra un incidente relacionado con ChatGPT | guarda el texto parcial, espera y reintenta en un chat nuevo tras la recuperación | una pregunta corta termina después de mejorar Status | no quemes intentos ni cambies ajustes locales durante el incidente |
| La misma conversación vuelve a fallar | copia prompt y fragmento útil en un chat nuevo | el chat nuevo termina o muestra un fallo más concreto | no sigas pulsando regenerate en el hilo antiguo |
| Funciona en incógnito, otro navegador o móvil | corrige solo el perfil del navegador o la app | el mismo prompt corto termina en el entorno limpio | no reinicies todos los ajustes sin evidencia |
| Cambia al usar otra red | revisa VPN, proxy, firewall, inspección TLS y timeouts | hotspot o red doméstica completa el mismo flujo | escala a red o IT con datos concretos |
| Fallan prompts largos, contexto grande, archivos o imágenes | prueba un prompt corto sin adjuntos y divide la tarea | el prompt corto funciona y el request grande falla | deja de tratarlo como caída general |
| Falla el stream de una app propia | mira error class, request ID, logs, timeout y retries | web ChatGPT y API se comportan distinto | no apliques arreglos de navegador a una integración |
Status decide si conviene esperar o diagnosticar localmente
OpenAI Status es la primera bifurcación. En la revisión en vivo del 16 de mayo de 2026, el estado devolvió All Systems Operational. Eso todavía no demuestra que tu conversación, cuenta, modelo, ruta de subida o integración concreta esté sana. El estado público es una señal fechada: si ahora hay un incidente relevante, guarda el trabajo y espera; si no lo hay, pasa a pruebas locales.
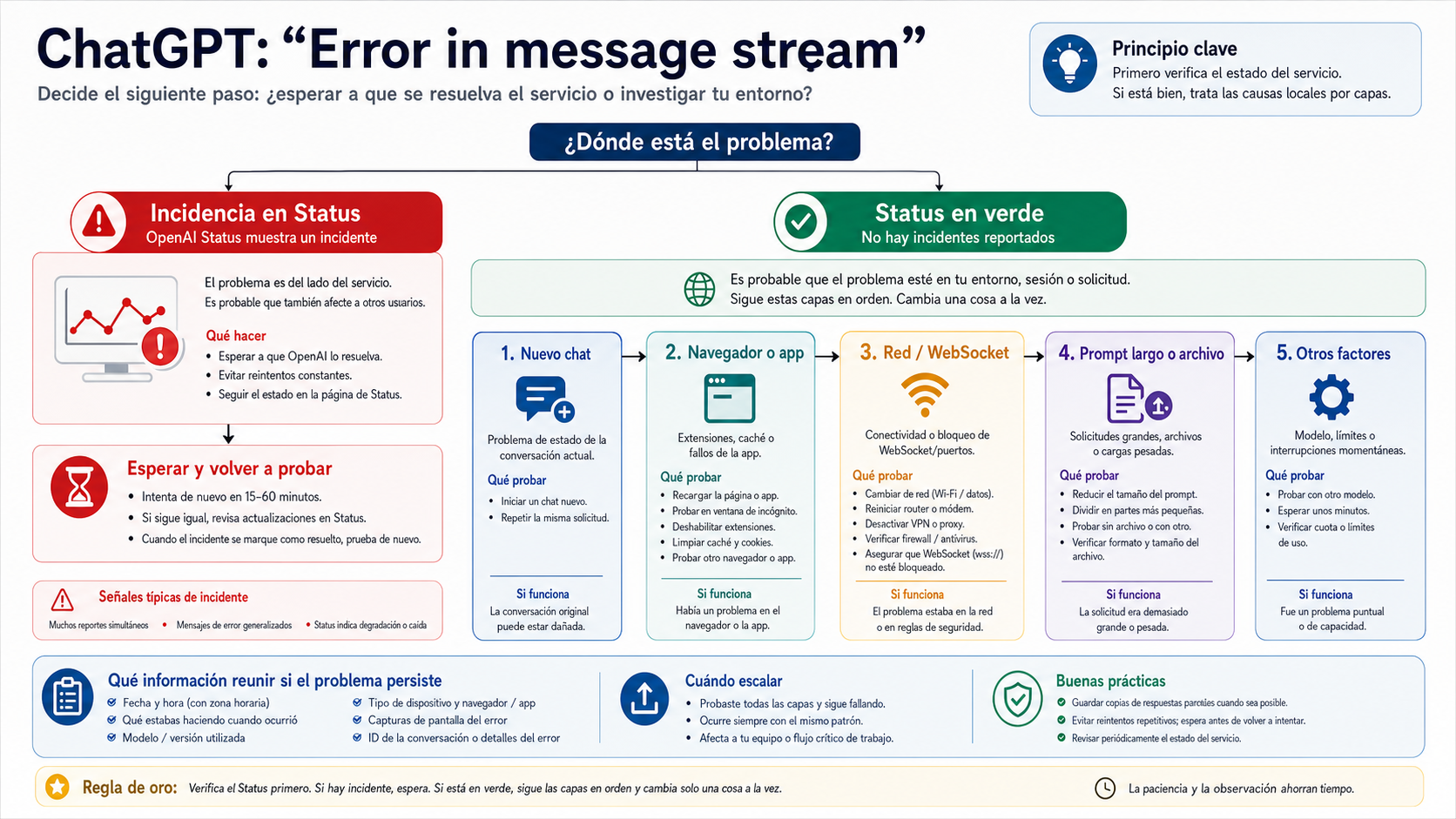
Un Status limpio tampoco prueba que tu conversación concreta esté sana. Puede haber diferencias por cuenta, workspace, modelo, superficie, subida de archivos o app integrada. Por eso un estado verde solo mueve el diagnóstico a pruebas de aislamiento: nuevo chat, prompt corto, otro navegador, otra red y request sin adjuntos.
Status tampoco decide qué ajuste local debes borrar. Solo ayuda a elegir entre esperar o seguir con pruebas reversibles. Si hay incidente, conserva el trabajo y cambia lo mínimo. Si no lo hay, empieza por pruebas pequeñas antes de tocar extensiones, cookies, VPN o red. Un estado limpio significa que no hay una razón pública clara para esperar, no que tu entorno local esté probado como culpable.
Un chat nuevo separa el hilo roto de un fallo general
Si la conversación actual se interrumpe varias veces, rescata el trabajo antes de tocar nada. Copia el prompt, el último párrafo completo, código útil o tabla parcial. Abre un chat nuevo y pide continuar desde ese punto. La primera prueba debe ser más pequeña que la tarea original; no pegues todos los archivos, contexto largo e instrucciones de una sola vez.
Si el chat nuevo termina la respuesta, la rama principal es el estado del hilo anterior. Una conversación larga puede acumular adjuntos, tools, contexto extenso, generación fallida o sesión debilitada. Continúa en el chat nuevo e incorpora solo el contexto necesario. Si el chat nuevo falla con el mismo mensaje, ya tienes una prueba más limpia y puedes pasar a navegador, app, red, complejidad del request o adjuntos.
Al migrar, no restaures todo el contexto antiguo de golpe. Pide primero un párrafo, una función, una tabla o una conclusión. Si eso funciona, añade contexto gradualmente. Así evitas llevar al chat nuevo el mismo attachment state o una carga de contexto que provocó el fallo.
Navegador y app se revisan después de un prompt de control
Borrar caché es familiar, pero cambia demasiadas cosas. Antes envía una pregunta corta en un chat nuevo sin archivos:
textExplica en tres frases por qué una respuesta en streaming puede detenerse antes de terminar.
Si termina, el streaming básico funciona. El problema original probablemente está en el hilo antiguo, un request demasiado largo, un archivo o la cantidad de salida. Si la pregunta corta también falla, prueba incógnito o un segundo navegador. Si incógnito funciona, mira extensiones, scripts bloqueados, datos del sitio, herramientas de privacidad, VPN/proxy o estado de sesión. Si la app de escritorio falla pero web funciona, la rama es la app. Si web falla pero móvil funciona, usa móvil para recuperar el contenido y corrige web después.
Red y WebSocket no son lo mismo que cargar la página
Que la página de ChatGPT abra no significa que una respuesta larga pueda mantenerse hasta el final. El flujo puede depender de secure WebSocket traffic, proxy, firewall, inspección TLS y límites de inactividad. En redes corporativas, un filtro puede permitir la página normal y cortar conexiones largas.

La prueba útil es una segunda ruta. Si el mismo prompt corto falla en Wi-Fi de oficina y funciona con hotspot del teléfono, la causa probable no es el prompt. Registra VPN apagada, VPN encendida, otra red y tiempo aproximado de corte. Para IT, es más útil decir que un prompt corto falla en la red corporativa pero completa fuera de ella, junto con hora, navegador y error de consola, que enviar un reporte genérico de “ChatGPT no funciona”.
Los prompts largos se convierten en pasos recuperables
Un prompt muy largo, mucho contexto pegado, varios archivos, código extenso o una petición de documento completo mezclan demasiadas variables. Si el prompt corto funciona y la tarea grande falla, deja de tratararlo como caída global.
Divide la tarea. Pide primero un esquema, luego una sección. Para código, limita a un archivo o una función. Para escritura, pega el último párrafo completo y pide continuar sin reescribir lo anterior. Para análisis, primero valida la estructura de entrada y después pide conclusiones. El objetivo es que cada intento tenga una salida recuperable y que el fallo señale una variable: longitud, adjunto, hilo antiguo, red o timeout.
Adjuntos, imágenes y archivos usan otra rama
Un archivo o una imagen puede producir el mismo mensaje visible, pero el origen cambia. Puede ser tamaño, formato, límite de upload, storage, política de workspace, estado temporal de procesamiento o una superficie de image generation/editing. Primero envía un prompt corto sin adjuntos. Si funciona, quita el archivo y prueba la versión en texto. Después usa un archivo pequeño conocido en un chat nuevo.

Si el fallo pertenece a imágenes, usa la ruta adecuada. Para generación o edición, revisa la recuperación de generación de imágenes en ChatGPT. Si ChatGPT no acepta la imagen, revisa diagnóstico de subida de imágenes. La prueba sin adjuntos evita que un límite, archivo o workspace se oculte detrás de una lista genérica de navegador.
API y aplicaciones propias necesitan otra evidencia
En una integración, lo importante no es la caché del navegador sino error class, request ID, endpoint, model, client timeout, retry policy, proxy buffering, SSE handling, server logs y request mínimo reproducible. APIConnectionError, APITimeoutError, InternalServerError, RateLimitError y BadRequestError piden rutas distintas.
Compara dos señales. ¿La misma cuenta completa una respuesta corta en ChatGPT web? ¿Tu app falla con request ID y error class en un streaming request mínimo? Si web funciona y la app falla, depura integración. Si ambas superficies fallan durante un incidente relevante, guarda logs y espera recuperación. Si solo fallan streams largos en tu app, mira timeout, buffering, reverse proxy, ejecución serverless y reintentos.
Recoge evidencia antes de seguir probando
Cuando ninguna rama da respuesta clara, un paquete pequeño de evidencia vale más que otro intento. Incluye hora y zona horaria, superficie de ChatGPT, navegador o app, modelo o modo, estado público, conversation URL, captura, qué ramas pasaron o fallaron y si había adjuntos. Para fallos web persistentes, consola o HAR pueden ayudar, pero no compartas cookies, tokens, archivos privados, prompts sensibles o datos de clientes. Para API, añade request IDs, endpoint, model, error class, librería, timeout, retries y request mínimo.
La prevención también ayuda. Pide salidas largas por secciones, guarda trabajo importante fuera del chat, prueba archivos con muestras pequeñas y documenta qué red funciona en entornos corporativos. Así, la próxima interrupción no empieza desde cero.
Preguntas frecuentes
¿Qué significa “Error in message stream”?
Significa que la respuesta no terminó de transmitirse al chat. Es un síntoma visible, no un código oficial estable. La causa puede ser servicio, conversación rota, navegador, app, red, prompt largo, adjunto o integración API.
¿Debo recargar ChatGPT cuando aparece?
Guarda primero la respuesta parcial y el prompt. Después puedes recargar, pero hacerlo como primer paso puede borrar la única copia del trabajo incompleto.
¿Cómo sé si ChatGPT está caído?
Revisa OpenAI Status y busca incidentes relacionados con ChatGPT, modelos, uploads, imágenes o API. Un incidente activo puede hacer que esperar sea la acción correcta. Si Status está limpio, pasa a pruebas locales.
¿Por qué incógnito puede arreglarlo?
Incógnito reduce extensiones, datos del sitio, bloqueadores de scripts, herramientas de privacidad y algunos efectos de sesión. Si ahí funciona, la rama probable es el perfil del navegador.
¿Un prompt largo puede causarlo?
Sí. Si un prompt corto sin adjuntos funciona y el request largo falla, divide la tarea, continúa desde el texto guardado y reduce contexto, adjuntos o salida.
¿Qué deben hacer los desarrolladores?
Revisar error class, request ID, logs, timeout, retries, endpoint, model y transporte. El comportamiento de ChatGPT web sirve como comparación, pero la corrección de API empieza en la integración y el request mínimo.