
Google's Gemini API offers a genuinely free tier that requires no credit card and provides developers with 5-15 requests per minute, 250,000 tokens per minute, and up to 1,000 requests per day depending on the model you choose. As of December 2025, the free tier includes access to Gemini 2.5 Pro, 2.5 Flash, 2.5 Flash-Lite, and the new Gemini 3 Pro Preview, with the standout feature being a 1 million token context window—8 times larger than ChatGPT's 128K limit. This comprehensive guide covers the December 7, 2025 quota adjustments, exact rate limits for every model, step-by-step API key setup, and proven strategies to maximize your free quota.
What's New: December 2025 Quota Changes
The Gemini API landscape shifted significantly on December 7, 2025, when Google announced adjustments to both the Free Tier and Paid Tier 1 quotas. These changes came without much fanfare, catching many developers off-guard with unexpected 429 (quota exceeded) errors. Understanding these updates is crucial for anyone building applications on the Gemini API, as the changes affect how you plan your request patterns and budget your daily API consumption.
According to the official Google documentation updated on December 10, 2025, the quota adjustment primarily impacts how rate limits are calculated and enforced across different usage patterns. The enforcement now operates more strictly on a per-minute basis, meaning burst requests that previously might have been tolerated are now more likely to trigger rate limiting. This change aligns with Google's broader strategy to ensure fair usage across their growing user base while maintaining system stability during peak demand periods.
What specifically changed includes several key areas. First, the rate limit enforcement algorithm now uses a more aggressive token bucket approach, where each dimension (RPM, TPM, RPD) maintains its own bucket that refills at a constant rate. When any bucket empties, subsequent requests receive HTTP 429 errors until tokens replenish. Second, the daily quota reset time remains at midnight Pacific Time, but the system now tracks usage more granularly, which means hitting limits earlier in the day results in longer wait times before limits reset.
For developers currently using the free tier, the practical impact varies based on your usage patterns. If you're making steady, spaced-out requests throughout the day, you likely won't notice significant differences. However, if your application relies on burst requests—sending many requests in quick succession—you'll need to implement more robust rate limiting logic on your end. The good news is that the actual quota numbers for free tier users haven't decreased; the change primarily affects how strictly those limits are enforced.
The December update also introduced some positive changes. Google has been more transparent about providing real-time quota information through AI Studio, and the error messages for 429 responses now include more detailed information about when you can resume making requests. This improved feedback loop helps developers build more resilient applications that can gracefully handle rate limiting scenarios.
Understanding Gemini's Free Tier Structure
Google structures the Gemini API around a tiered system that provides different levels of access and capabilities. The free tier sits at the foundation of this system, offering substantial value for developers who want to experiment, prototype, or build small-scale applications without any financial commitment. Understanding how this tier system works helps you plan your development journey and know exactly when upgrading might become necessary.
The free tier operates through Google AI Studio, which serves as the primary interface for developers accessing Gemini models without billing enabled. This is distinctly different from Vertex AI, which is Google Cloud's enterprise-focused platform that requires billing setup even for free tier access. The distinction matters because rate limits, available models, and usage tracking differ between these two platforms, leading to confusion among developers who don't realize they're accessing Gemini through different endpoints.
Google AI Studio provides the true "no credit card required" experience. When you create an API key through aistudio.google.com, you immediately get access to free tier quotas without entering any payment information. This makes it ideal for students, researchers, hobbyists, and developers evaluating the platform before committing to paid usage. The free tier through AI Studio includes access to all main model variants—Gemini 2.5 Pro, 2.5 Flash, 2.5 Flash-Lite, and even the new Gemini 3 Pro Preview—though with different rate limits for each.
Vertex AI takes a different approach. While it offers an "Express Mode" that doesn't require immediate billing, the setup process is more complex and the quotas can vary based on your account status. Vertex AI is designed for production workloads and enterprise integrations, offering features like fine-tuning, model deployment, and advanced monitoring that aren't available through the simpler AI Studio interface. For most developers starting out, AI Studio's free tier provides everything needed to explore Gemini's capabilities.
One crucial aspect of the free tier that many overlook is that it allows commercial use. Unlike some free API tiers from other providers that restrict usage to personal or educational purposes, Google explicitly permits using the free tier for commercial applications. However, the rate limits make it impractical for any high-volume production use case. Consider the free tier as a way to validate your product concept and demonstrate value before investing in paid capacity. For production applications, you'll want to explore options like detailed Gemini API pricing breakdown to understand the costs involved.
The tier progression from Free to Paid works seamlessly. When you enable billing on your Google Cloud project, you automatically upgrade to Tier 1, which dramatically increases your rate limits. No manual application or waiting period is required—the upgrade happens immediately upon payment method verification. This smooth transition path means you can develop your entire application on the free tier and flip the switch to production capacity when you're ready to launch.
Complete Rate Limits by Model (2025)
Understanding the exact rate limits for each Gemini model enables you to choose the right model for your use case and plan your application architecture accordingly. The free tier provides surprisingly generous limits compared to competitors, though the specific numbers vary significantly between model variants.

Gemini 2.5 Pro delivers the highest reasoning capabilities with the most conservative free tier limits: 5 requests per minute (RPM), 250,000 tokens per minute (TPM), and 100 requests per day (RPD). These limits reflect the computational intensity required for Pro's maximum quality outputs. The 5 RPM restriction means you can make approximately one request every 12 seconds, which suits complex analytical tasks, detailed code generation, and sophisticated reasoning problems where response quality matters more than throughput.
Gemini 2.5 Flash strikes the balance between performance and speed, offering 10 RPM, 250,000 TPM, and 250 RPD. This model serves as the recommended starting point for most applications. The doubled request rate compared to Pro makes it suitable for interactive applications, chatbots, and content generation workflows. Flash maintains strong capabilities across diverse tasks while providing the headroom needed for responsive user experiences.
Gemini 2.5 Flash-Lite prioritizes throughput above all else, providing the most generous free tier limits: 15 RPM, 250,000 TPM, and an impressive 1,000 RPD. This model is optimized for high-volume, simpler tasks where speed matters more than maximum reasoning capability. For prototyping, bulk content processing, or applications where you need to serve many concurrent users on a budget, Flash-Lite offers the best value proposition in the free tier.
Gemini 3 Pro Preview represents Google's latest advancement, available with variable limits that depend on your account age and region—typically 10-50 RPM and 100+ RPD. As a preview model, these limits may change as Google gathers usage data and prepares for general availability. Early access to Gemini 3 Pro through the free tier provides developers an opportunity to experiment with cutting-edge capabilities before committing resources to production deployment.
| Model | RPM | TPM | RPD | Context | Best For |
|---|---|---|---|---|---|
| Gemini 2.5 Pro | 5 | 250,000 | 100 | 1M | Complex reasoning, analysis |
| Gemini 2.5 Flash | 10 | 250,000 | 250 | 1M | General tasks, chat |
| Gemini 2.5 Flash-Lite | 15 | 250,000 | 1,000 | 1M | High-volume, prototyping |
| Gemini 3 Pro Preview | 10-50 | 250,000 | 100+ | 1M+ | Latest features, testing |
The rate limiting system operates at the project level, not the individual API key level. This architectural decision has important implications: all API keys within a single Google Cloud project share the same rate limit pool. If you're building multiple applications, creating separate projects for each allows independent quota allocation. Conversely, if you want to consolidate monitoring and billing, keeping everything in one project simplifies administration at the cost of shared limits.
All models share the same 250,000 TPM limit, which means you can process approximately 62,500 words per minute (using the roughly 4:1 token-to-word ratio). This generous token allowance supports substantial context in each request, enabling applications that process documents, maintain long conversation histories, or analyze extensive datasets within single API calls.
For developers needing higher limits without committing to full pricing, services like laozhang.ai offer access to all Gemini models with significantly elevated quotas at a fraction of the cost—typically providing 10x the free tier limits while maintaining 70% lower pricing than direct API access.
The 1M Context Window Advantage
The 1 million token context window stands as Gemini's most significant technical differentiator in the free tier landscape. While competitors limit context to 128K tokens (ChatGPT) or 200K tokens (Claude), Gemini's massive context window opens possibilities that simply aren't feasible with other models—and this capability is fully available in the free tier.
Understanding what 1M tokens means in practical terms helps illustrate this advantage. One million tokens translates to approximately 750,000 words, or roughly 1,500 pages of typical text. This capacity enables processing entire codebases, complete research papers with all their citations, full-length books, or extensive conversation histories—all within a single API request. Where other APIs require you to chunk large documents and manage context across multiple calls, Gemini handles it natively.
Real-world applications of this massive context window include several compelling use cases. Software development teams can feed entire repository codebases into Gemini for comprehensive code review, architectural analysis, or refactoring suggestions. Legal professionals can analyze complete contracts without losing important context from earlier sections. Researchers can process entire paper collections for literature reviews. Content creators can maintain extensive character profiles and story continuity across long-form fiction projects.
The comparison with ChatGPT's 128K limit becomes stark when handling larger documents. A 500-page technical manual requires careful chunking and context management with ChatGPT, often losing important cross-references between sections. With Gemini, the same document processes in a single request, maintaining all internal references and providing more coherent analysis. For applications processing documents like annual reports, legal briefs, or technical documentation, this difference often determines feasibility.
Consider this practical example: processing a 300-page software specification document. With ChatGPT's 128K context, you'd need to split the document into multiple chunks, make separate API calls for each, and somehow reconcile the analysis across those fragments. Each call loses context from other parts of the document. With Gemini's 1M context, you submit the entire specification in one request, and the model can reference any section while analyzing another—producing more coherent, accurate results.
The context window also benefits conversational applications differently than you might expect. Instead of just maintaining longer chat histories, the extended context enables richer few-shot learning. You can provide more examples within your prompt, demonstrate more complex patterns, and include more detailed instructions without worrying about context truncation. This capability often produces better results than fine-tuning would achieve with smaller models.
For developers exploring Gemini's context capabilities in depth, the comprehensive Gemini 2.5 Pro free API guide provides detailed implementation examples and optimization strategies specifically for large-context applications.
How to Get Your Free API Key (5 Minutes)
Obtaining a Gemini API key requires only a Google account and typically takes less than five minutes. The process is streamlined for developers, with no credit card verification, phone confirmation, or approval delays. Here's the exact process to get started.
Step 1: Navigate to Google AI Studio. Open your browser and go to aistudio.google.com. This is Google's official interface for Gemini API access and model experimentation. You'll see options to try models directly in the playground or manage your API keys.
Step 2: Sign in with your Google account. Use your existing Google account or create a new one. Unlike some AI platforms that require corporate email addresses, any standard Gmail or Google Workspace account works. If you manage multiple Google accounts, consider which one you want associated with your API usage for organizational purposes.
Step 3: Access the API Keys section. Once signed in, look for "Get API Key" in the left sidebar or top navigation. This takes you to the key management interface where you can view existing keys or create new ones.
Step 4: Create a new API key. Click "Create API Key" and you'll see options to either create a key in a new project or select an existing Google Cloud project. For most users starting fresh, creating a new project keeps things simple. Give your project a memorable name that reflects its purpose—this helps later when you have multiple projects.
Step 5: Copy and secure your API key. Once generated, your API key appears on screen. Copy it immediately and store it securely. Google displays this key only once during creation; while you can always generate new keys, you cannot retrieve the original key text later. Store your key in a password manager or secure configuration system—never in source code that might be committed to version control.
Security best practices matter from day one. Never hardcode API keys directly in your application code. Instead, use environment variables or secret management services. For development, create a .env file (added to .gitignore) containing your key:
bashexport GEMINI_API_KEY="your-api-key-here"
For production, use your platform's secret management—AWS Secrets Manager, Google Cloud Secret Manager, or similar services.
Validating your API key ensures everything works correctly. The quickest test uses cURL from your terminal:
bashcurl "https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash:generateContent?key=$GEMINI_API_KEY" \ -H 'Content-Type: application/json' \ -d '{"contents":[{"parts":[{"text":"Hello, Gemini!"}]}]}'
A successful response confirms your key works and you're ready to integrate Gemini into your applications. If you receive an error, double-check that you copied the complete key and that your API is enabled in the Google Cloud Console.
Python integration follows naturally from there. Install the official library with pip install google-generativeai and use this minimal example:
pythonimport google.generativeai as genai import os genai.configure(api_key=os.environ["GEMINI_API_KEY"]) model = genai.GenerativeModel('gemini-2.5-flash') response = model.generate_content("Explain quantum computing in simple terms.") print(response.text)
Gemini vs ChatGPT API: Real Cost Comparison
The most striking difference between Gemini and ChatGPT at the API level isn't capability—it's that Gemini offers a genuine ongoing free tier while ChatGPT provides none. This fundamental distinction shapes how developers approach AI integration, particularly for projects at the exploratory or early growth stages.
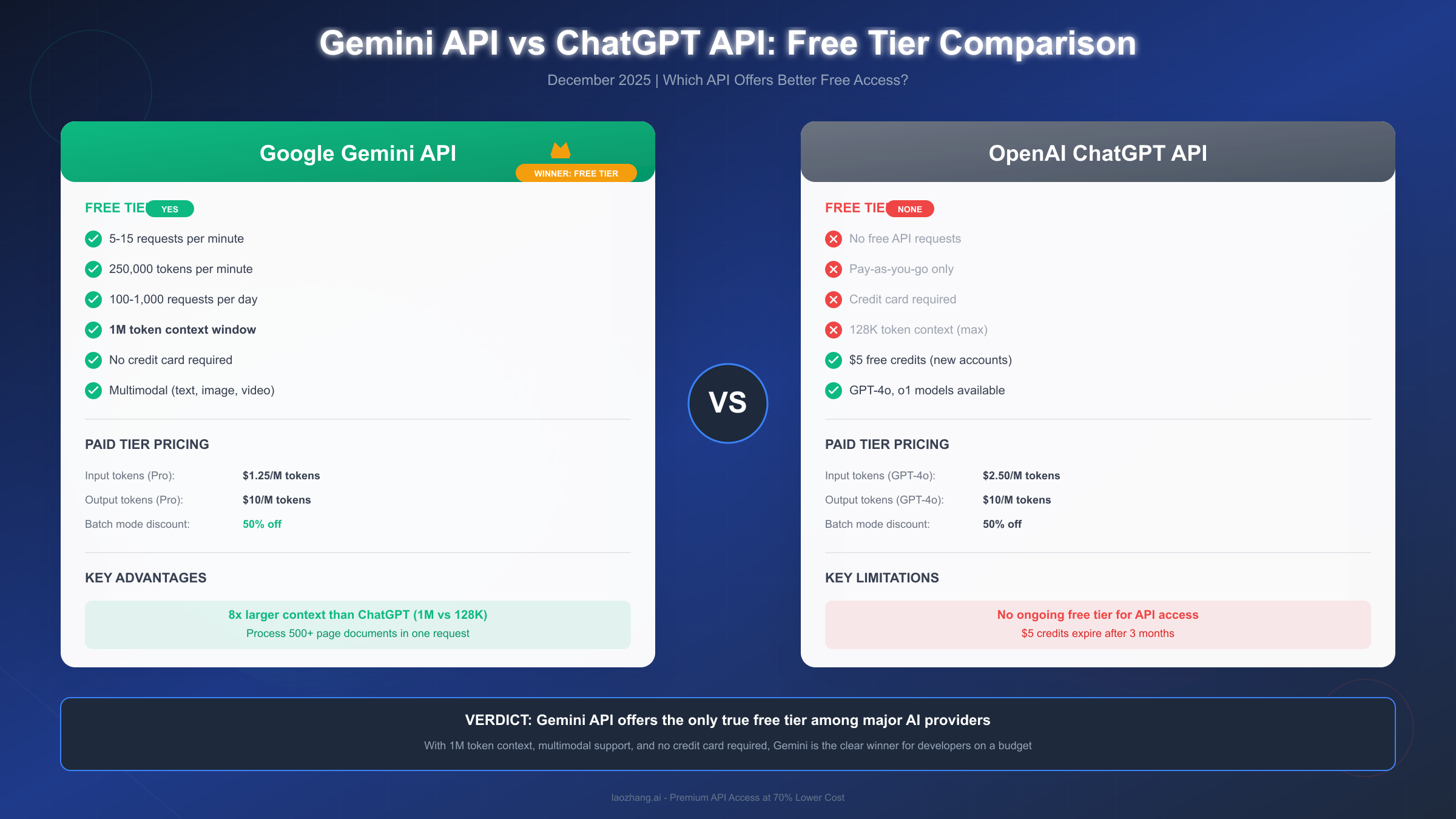
ChatGPT's API model is strictly pay-as-you-go. New accounts receive a one-time $5 credit that expires after three months, but beyond that, every API call costs money. There's no free tier, no ongoing free quota, no way to experiment indefinitely without billing. For developers testing ideas, learning the API, or building projects that don't yet generate revenue, this creates an immediate barrier. Understanding ChatGPT's free tier restrictions reveals that even the free web interface has significant limitations compared to API access.
Gemini's free tier removes this barrier entirely. You can make 100-1,000 requests daily (depending on model choice) indefinitely, with no credit card required and no expiring credits. For learning, prototyping, and validating product concepts, this ongoing free access proves invaluable. Many developers report running their side projects entirely on Gemini's free tier for months before needing to consider paid options.
Let's compare actual costs for a realistic scenario: 10,000 API requests processing an average of 1,000 input tokens and generating 500 output tokens each.
| Provider | Model | Input Cost | Output Cost | Total (10K requests) |
|---|---|---|---|---|
| Gemini | 2.5 Flash | $0.075/M | $0.30/M | $1.05 |
| Gemini | 2.5 Pro | $1.25/M | $10/M | $17.50 |
| OpenAI | GPT-4o | $2.50/M | $10/M | $30.00 |
| OpenAI | GPT-4o-mini | $0.15/M | $0.60/M | $4.50 |
Gemini's pricing advantage extends beyond the free tier. Even at paid tiers, Gemini 2.5 Flash costs significantly less than GPT-4o for comparable capabilities. The 50% batch mode discount that Gemini offers (versus ChatGPT's equivalent discount) further widens the gap for non-real-time workloads. For applications processing documents, generating content, or running analysis jobs where immediate responses aren't critical, batch mode pricing makes Gemini dramatically more economical.
The context window difference adds another dimension to this comparison. While ChatGPT's GPT-4 models max out at 128K tokens, Gemini's 1M context means you can often accomplish in one API call what would require multiple ChatGPT calls with careful context management. Fewer API calls mean lower costs, simpler code, and more coherent results.
When does ChatGPT make more sense despite the cost difference? Specific use cases favor ChatGPT's strengths: applications requiring function calling with complex tool use, projects needing the extensive OpenAI ecosystem integrations, or situations where GPT-4's particular reasoning patterns better match your requirements. The recently released OpenAI's API pricing structure provides detailed breakdowns if you need to make a careful comparison for your specific use case.
For budget-conscious developers who want Gemini access at even lower costs, API aggregators like laozhang.ai provide access to all major AI models through a unified interface at approximately 70% lower than direct API pricing—making the already affordable Gemini models even more accessible.
Maximizing Your Free Quota (Pro Tips)
Strategic optimization of your free tier quota can dramatically extend what you accomplish before needing paid capacity. These techniques, drawn from real-world developer experiences, help you get the most value from Gemini's generous free tier.
Request batching transforms how far your quota stretches. Instead of making individual API calls for each prompt, combine multiple related prompts into single requests. A single API call asking Gemini to analyze ten items costs one request from your quota, while making ten separate calls would cost ten. For applications processing lists of items—product descriptions, support tickets, code files—batching provides nearly linear scaling of effective quota.
pythonprompts = ["Analyze item 1", "Analyze item 2", ..., "Analyze item 10"] # Batch into one call: batched_prompt = """Analyze each of the following items. Return your analysis as a JSON array. Items: 1. [item 1 content] 2. [item 2 content] ... 10. [item 10 content] """ response = model.generate_content(batched_prompt)
Response caching eliminates redundant API calls. Many applications repeatedly request similar or identical information. Implementing a caching layer—whether simple in-memory caching for development or Redis/Memcached for production—can reduce your actual API calls by 40-60% depending on your application's patterns. Even simple caching of static content like system prompts or frequently requested explanations provides meaningful savings.
Model selection based on task complexity optimizes quota usage. Not every request needs Gemini 2.5 Pro's full reasoning capabilities. Route simpler tasks—formatting, basic Q&A, straightforward extraction—to Flash-Lite (with its 1,000 RPD limit) while reserving Pro's 100 daily requests for genuinely complex analysis. This tiered approach can increase your effective daily capacity significantly.
Prompt engineering reduces token consumption. Concise, well-structured prompts generate better results with fewer tokens. Remove unnecessary context, use clear formatting that guides the model efficiently, and specify desired output formats explicitly. A prompt that clearly states "Return only the JSON object with keys: name, category, confidence" produces cleaner output than one asking to "explain your analysis and provide structured data."
Rate limit handling prevents lost work. Implement exponential backoff when you encounter 429 errors:
pythonimport time import google.generativeai as genai def generate_with_retry(prompt, max_retries=5): for attempt in range(max_retries): try: response = model.generate_content(prompt) return response except Exception as e: if "429" in str(e): wait_time = (2 ** attempt) + random.random() print(f"Rate limited. Waiting {wait_time:.2f} seconds...") time.sleep(wait_time) else: raise raise Exception("Max retries exceeded")
Strategic timing spreads load effectively. If your application allows flexible scheduling, distribute API calls throughout the day rather than concentrating them during peak hours. The RPD quota resets at midnight Pacific Time, so planning your heaviest processing to start shortly after reset ensures full daily quota availability.
When the free tier isn't enough, consider intermediate options. Before jumping to full paid pricing, services like laozhang.ai offer middle ground—significantly higher limits than the free tier at a fraction of direct API costs. This stepping stone helps validate that your application needs the capacity before committing to higher expenses.
FAQ: Your Questions Answered
Is Gemini API really completely free?
Yes, the free tier requires no payment information and provides ongoing access indefinitely. You get 100-1,000 requests daily depending on model choice, with the full 1M token context window available. Unlike trials that expire, this free access continues as long as you stay within the limits.
Can I use the free tier for commercial applications?
Google explicitly permits commercial use of the free tier. However, the rate limits (5-15 RPM, 100-1,000 RPD) make it impractical for any application serving significant user volume. Use the free tier to validate your concept, then plan for paid capacity when launching commercially.
What happens when I exceed my quota?
The API returns a 429 error with information about when you can resume requests. For RPM limits, waiting a minute typically resolves the issue. For RPD limits, you'll need to wait until midnight Pacific Time for the reset. Implementing proper error handling prevents your application from failing ungracefully.
How do I get more quota beyond the free tier?
Enable billing on your Google Cloud project to automatically upgrade to Tier 1, which provides 300+ RPM, 1M+ TPM, and 1,000+ RPD. Higher tiers require spending thresholds ($250 for Tier 2, $1,000 for Tier 3). Alternatively, API gateways like laozhang.ai offer elevated limits at reduced pricing.
Does playground usage in AI Studio count against my API quota?
Yes, interactive playground sessions in Google AI Studio consume the same free tier quotas as API calls. If you're testing prompts in the playground, that usage counts toward your daily limits. For heavy experimentation, consider that this impacts your available API quota.
What's the difference between AI Studio and Vertex AI?
AI Studio offers the simpler, no-credit-card-required free tier ideal for development and small projects. Vertex AI is Google Cloud's enterprise platform, offering additional features like fine-tuning and advanced deployment options but requiring billing setup. For most developers starting out, AI Studio provides everything needed.
How does Gemini's free tier compare to Claude or other alternatives?
Gemini offers the most generous ongoing free tier among major AI providers. Claude provides approximately 20-40 messages through its free web interface but no free API tier. OpenAI's $5 credit expires after three months with no ongoing free access. Gemini's combination of free access, high limits, and 1M context window is unmatched.
Are there regional restrictions for the free tier?
The free tier is available in 180+ countries but excluded in certain regions including China, Russia, and some Middle Eastern countries. VPN usage to bypass restrictions violates terms of service. If you're in a restricted region, you might explore API aggregators that provide access through different routing.
Conclusion: Is Gemini's Free Tier Worth It?
Gemini's free tier represents the most accessible entry point into serious AI development available today. The combination of no credit card requirement, generous rate limits (up to 1,000 daily requests), 1 million token context window, and access to multiple model variants creates genuine value for developers at every level—from students learning AI integration to startups validating product concepts.
The December 2025 quota changes, while requiring attention to rate limiting, don't diminish the core value proposition. The free tier remains functional for exploration, prototyping, and small-scale production use cases. The improved error messaging and quota tracking actually make development easier by providing clearer feedback when limits are approached.
The path forward depends on your specific needs. For learning and experimentation, the free tier provides everything needed—start with Gemini 2.5 Flash for general tasks and explore Pro for complex reasoning problems. For production applications, begin development on the free tier, validate your approach, then transition to paid capacity when your application demands it.
Practical next steps to get started include: First, create your free API key at aistudio.google.com (takes 5 minutes). Second, experiment with different models in the playground to understand their strengths. Third, implement basic rate limiting in your code from the start—it's easier than retrofitting later. Fourth, monitor your usage patterns to understand which tier makes sense as you scale.
For developers who need capacity between the free tier and full paid pricing, services like laozhang.ai provide an intermediate option—access to all Gemini models with elevated quotas at significantly reduced costs. This stepping stone helps bridge the gap between experimentation and production without requiring immediate commitment to full pricing.
The AI landscape continues evolving rapidly, but Gemini's commitment to maintaining a genuinely useful free tier sets it apart from competitors. Whether you're building the next breakthrough application or simply exploring what AI can do, the free tier provides a no-risk starting point. Your only investment is time—and with the capabilities available, that time investment pays dividends.