野卡跑路震动了整个AI使用者社区,但这也许是一个契机,让我们重新思考AI服务的访问方式。本文将从技术架构角度深入分析各种替代方案,帮助您找到最适合的解决路径。
野卡时代的终结:技术变革的必然
野卡的消亡并非偶然,而是技术发展和监管演进的必然结果。从技术架构来看,野卡模式存在着根本性的缺陷。它本质上是在支付系统的灰色地带运作,通过虚拟卡号绕过地理限制。这种模式就像在沙滩上建造城堡,看似稳固,实则脆弱。
技术层面,野卡依赖的BIN(Bank Identification Number)池是有限的。当大量用户使用相同BIN段的虚拟卡时,很容易触发支付网关的风控系统。OpenAI和Stripe的机器学习模型能够快速识别出这些异常模式:相同的BIN、相似的交易金额、集中的时间分布。这就是为什么即使野卡还在运营时,成功率也在不断下降。
更深层的问题是合规风险。随着各国对金融科技监管的加强,虚拟卡平台面临越来越大的合规压力。野卡的突然跑路,很可能是监管压力达到临界点的结果。这给我们的启示是:依赖单一支付渠道,特别是游走在监管边缘的渠道,风险极大。
从用户需求演进来看,简单的支付代理已经不能满足需求。用户需要的不仅是能够付款订阅ChatGPT Plus,更需要灵活、高效、可控的AI访问方式。这推动了技术方案从"支付层"向"应用层"的转变,API调用模式应运而生。
替代方案全景图:技术架构对比

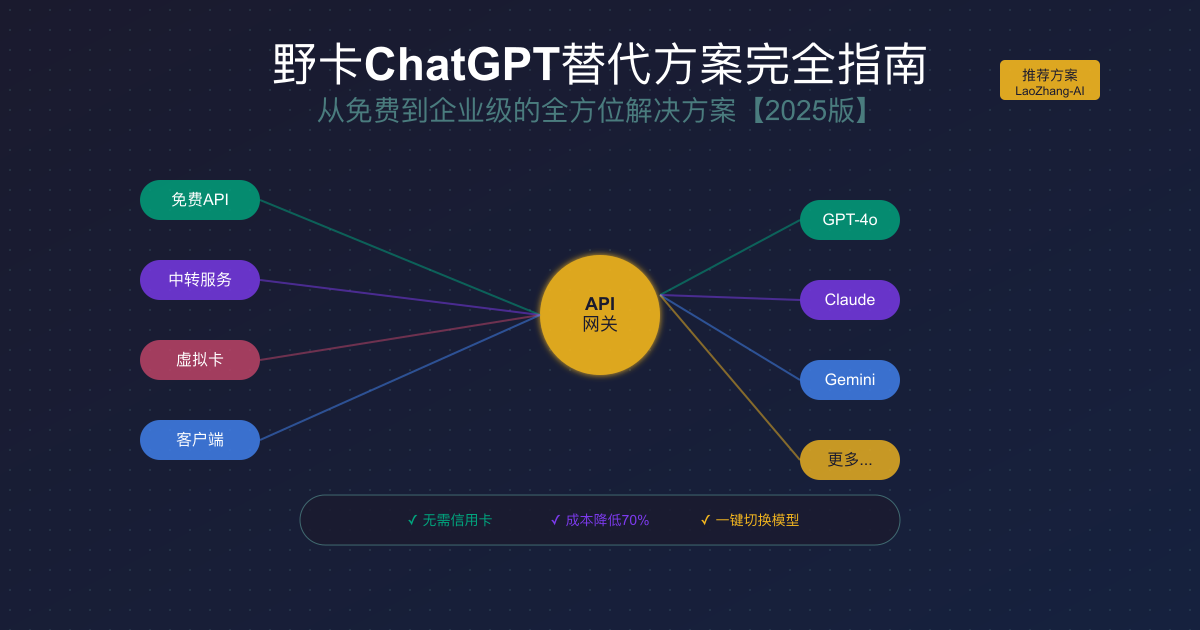
在后野卡时代,市场上涌现出多种替代方案。从技术架构角度,我们可以将它们分为四大类:支付代理类、账号共享类、免费资源类和API中转类。每种方案都有其独特的技术特征和适用场景。
支付代理类方案包括其他虚拟信用卡平台和代充值服务。技术上,它们与野卡类似,都是在支付层面解决问题。但随着OpenAI风控系统的升级,这类方案的成功率越来越低。更重要的是,它们同样面临合规风险,今天的替代者可能就是明天的野卡。
账号共享类方案通过多人共用一个ChatGPT Plus账号来降低成本。技术实现上,通常使用浏览器自动化工具(如Puppeteer)来管理会话,通过队列系统分配使用时间。但这种方案存在严重的安全隐患:共享账号意味着对话记录可能被他人看到,而且OpenAI的反作弊系统很容易检测到异常登录模式。
免费资源类主要是GitHub上的开源项目,通过逆向工程或使用免费额度提供服务。这些项目在技术上颇具创意,比如通过轮询多个免费端点、使用代理池绕过限制等。但免费的往往是最贵的——不稳定的服务、有限的功能、潜在的安全风险,这些隐性成本远超表面的节省。
API中转类方案是技术上最优雅的解决方案。它不是在支付层面打转,而是直接在应用层提供服务。通过聚合采购、智能路由、缓存优化等技术手段,API中转服务能够提供稳定、高效、低成本的AI访问。这种模式的优势在于:用户不需要担心支付问题,只需要关注如何使用API;服务商通过规模效应降低成本,实现多方共赢。
免费API深度解析:机遇与陷阱
免费API项目在GitHub上层出不穷,star数动辄上万。这些项目的技术实现各有特色,值得深入分析。最常见的实现方式是通过反向代理,将用户请求转发到多个免费端点。
javascript// 典型的免费API负载均衡实现 class FreeAPIBalancer { constructor() { this.endpoints = [ { url: 'https://api1.free-gpt.com', weight: 1, failures: 0 }, { url: 'https://api2.free-gpt.com', weight: 1, failures: 0 }, { url: 'https://api3.free-gpt.com', weight: 1, failures: 0 } ]; this.maxFailures = 3; } async selectEndpoint() { // 根据权重和失败次数选择端点 const available = this.endpoints.filter(e => e.failures < this.maxFailures); if (available.length === 0) { throw new Error('No available endpoints'); } const totalWeight = available.reduce((sum, e) => sum + e.weight, 0); let random = Math.random() * totalWeight; for (const endpoint of available) { random -= endpoint.weight; if (random <= 0) { return endpoint; } } } async request(messages) { const endpoint = await this.selectEndpoint(); try { const response = await fetch(`${endpoint.url}/v1/chat/completions`, { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify({ messages, model: 'gpt-3.5-turbo' }) }); if (!response.ok) throw new Error(`HTTP ${response.status}`); endpoint.failures = 0; // 重置失败计数 return await response.json(); } catch (error) { endpoint.failures++; endpoint.weight = Math.max(0.1, endpoint.weight * 0.8); // 降低权重 throw error; } } }
这种实现看似巧妙,但存在诸多问题。首先是稳定性,免费端点随时可能失效,即使有故障转移机制,用户体验也会受到影响。其次是性能,多次转发增加了延迟,而且免费端点通常有严格的速率限制。最严重的是安全问题,你的请求数据会经过多个不可控的节点,隐私泄露风险极高。
另一类免费API是通过"薅羊毛"的方式,利用各平台的免费试用额度。这需要不断注册新账号,使用自动化脚本管理账号池。虽然技术上可行,但违反了服务条款,而且维护成本极高。对于个人学习使用可以尝试,但绝不适合任何正式项目。
使用免费API就像在走钢丝,看似省钱,实则处处是坑。对于真正需要稳定AI服务的用户,付费方案才是正道。毕竟,时间成本和机会成本往往比直接的金钱成本更高。
虚拟信用卡2.0:技术升级但风险依旧
野卡之后,新一代虚拟信用卡平台号称进行了技术升级。它们采用了更先进的BIN轮换策略、3DS验证支持、智能地址匹配等技术。让我们深入分析这些"创新"是否真的解决了根本问题。
BIN轮换是新平台的主打功能。通过与多家银行合作,平台能够提供更多样化的BIN资源。当某个BIN段被识别后,系统会自动切换到新的BIN。这种"打一枪换一个地方"的策略短期内确实能提高成功率,但这是一场猫鼠游戏。支付网关的机器学习模型也在不断进化,它们不仅看BIN,还会分析IP地址、设备指纹、交易模式等多维度数据。
3DS(3D Secure)验证是另一个技术亮点。通过模拟真实的银行验证流程,虚拟卡能够通过更严格的安全检查。但这也意味着更复杂的技术实现和更高的成本。而且,3DS验证本身就是为了防止欺诈交易,用技术手段绕过安全机制,本质上是在挑战整个支付体系的底线。
地址验证系统(AVS)是虚拟卡面临的另一个挑战。新平台通过提供真实的美国地址、配套的电话号码甚至是虚拟邮箱来提高通过率。但这种做法的合规风险更大,涉嫌身份欺诈。而且,随着KYC(Know Your Customer)要求的加强,简单的地址匹配已经不够,可能需要提供更多的身份证明。
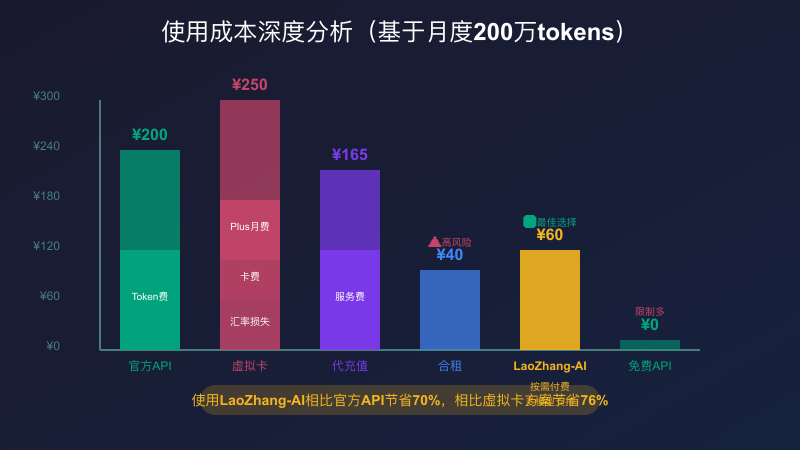
从成本角度看,使用虚拟卡订阅ChatGPT Plus的总成本包括:月费20美元、卡片维护费5-10美元、充值手续费2-3%、汇率损失2-3%。算下来,实际成本可能达到30美元以上。相比之下,使用 LaoZhang-AI 这样的API服务,相同使用量的成本可能只需要10美元,而且没有任何合规风险。
更重要的是信任问题。野卡的跑路给整个虚拟卡行业蒙上了阴影。用户不得不问:下一个跑路的会是谁?在这种不确定性下,继续使用虚拟卡无异于赌博。技术升级解决不了信任危机,只有转变思路,从支付工具转向技术服务,才能找到真正的出路。
API中转服务:技术架构的革新
API中转服务代表了AI访问方式的范式转变。它不再纠结于如何绕过支付限制,而是直接提供技术服务。这种模式的核心是一个高性能的反向代理系统,配合智能路由、负载均衡、缓存优化等技术组件。
pythonclass APIGateway: def __init__(self): self.providers = { 'openai': OpenAIProvider(), 'anthropic': AnthropicProvider(), 'google': GoogleAIProvider() } self.cache = RedisCache() self.rate_limiter = TokenBucketLimiter() self.load_balancer = ConsistentHashBalancer() async def process_request(self, request: APIRequest) -> APIResponse: # 1. 认证和授权 user = await self.authenticate(request.api_key) if not self.authorize(user, request.model): raise UnauthorizedError() # 2. 速率限制 if not await self.rate_limiter.try_acquire(user.id): raise RateLimitError() # 3. 缓存检查 cache_key = self.generate_cache_key(request) cached = await self.cache.get(cache_key) if cached: return cached # 4. 智能路由 provider = self.select_provider(request.model) endpoint = await self.load_balancer.select_endpoint(provider) # 5. 请求转换 provider_request = self.transform_request(request, provider) # 6. 执行请求 try: response = await endpoint.execute(provider_request) # 7. 响应转换 unified_response = self.transform_response(response, provider) # 8. 缓存更新 await self.cache.set(cache_key, unified_response, ttl=300) return unified_response except ProviderError as e: # 故障转移 return await self.failover(request, provider)
这个架构的优势在于其灵活性和可扩展性。用户只需要关心统一的API接口,不需要了解底层的复杂性。服务商可以通过批量采购获得更低的价格,通过技术优化降低成本,最终让利给用户。
安全性是API中转服务的另一个优势。所有请求都经过TLS加密,敏感数据不会被存储。用户的API密钥与上游服务商的密钥完全隔离,即使中转服务出现问题,也不会影响用户在其他平台的使用。同时,完善的审计日志确保所有操作可追溯。
性能优化是技术实力的体现。通过智能缓存,相同的请求可以直接返回结果,大幅降低延迟和成本。负载均衡确保请求分布到最优的节点,避免单点故障。预测性扩容能够应对突发流量,保证服务稳定性。
LaoZhang-AI 是这类服务的优秀代表。它不仅提供了稳定的API访问,还通过技术创新实现了成本优化。新用户注册即送10美元额度,足够体验各种AI模型的强大功能。相比传统的订阅模式,API按需付费更加灵活,避免了资源浪费。
从零开始:API集成实战教程
理论说得再多,不如实际操作一遍。让我们通过一个完整的示例,展示如何将API集成到你的项目中。整个过程只需要5分钟,但能为你打开AI应用的新世界。
首先是环境准备。无论你使用Python、Node.js还是其他语言,都需要安装相应的HTTP客户端库。这里以Python为例:
bash# 安装依赖 pip install openai httpx python-dotenv # 创建项目结构 mkdir my-ai-project cd my-ai-project touch .env config.py main.py
配置文件是关键。永远不要将API密钥硬编码在代码中:
python# config.py import os from dotenv import load_dotenv load_dotenv() class Config: # 使用LaoZhang-AI的配置 API_KEY = os.getenv('LAOZHANG_API_KEY') BASE_URL = os.getenv('API_BASE_URL', 'https://api.laozhang.ai/v1' ) # 模型配置 DEFAULT_MODEL = 'gpt-4o' MAX_TOKENS = 2000 TEMPERATURE = 0.7 # 性能配置 TIMEOUT = 30 MAX_RETRIES = 3
接下来是核心的API客户端实现:
python# main.py import asyncio from openai import AsyncOpenAI from typing import List, Dict, AsyncGenerator import logging logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__) class AIClient: def __init__(self, config: Config): self.client = AsyncOpenAI( api_key=config.API_KEY, base_url=config.BASE_URL, timeout=config.TIMEOUT, max_retries=config.MAX_RETRIES ) self.config = config async def chat(self, messages: List[Dict[str, str]], **kwargs) -> str: """简单的聊天接口""" try: response = await self.client.chat.completions.create( model=kwargs.get('model', self.config.DEFAULT_MODEL), messages=messages, max_tokens=kwargs.get('max_tokens', self.config.MAX_TOKENS), temperature=kwargs.get('temperature', self.config.TEMPERATURE) ) return response.choices[0].message.content except Exception as e: logger.error(f"API调用失败: {e}") raise async def stream_chat(self, messages: List[Dict[str, str]], **kwargs) -> AsyncGenerator[str, None]: """流式聊天接口""" try: stream = await self.client.chat.completions.create( model=kwargs.get('model', self.config.DEFAULT_MODEL), messages=messages, stream=True, **kwargs ) async for chunk in stream: if chunk.choices[0].delta.content: yield chunk.choices[0].delta.content except Exception as e: logger.error(f"流式API调用失败: {e}") raise # 使用示例 async def main(): config = Config() client = AIClient(config) # 简单对话 messages = [ {"role": "system", "content": "你是一个有帮助的助手"}, {"role": "user", "content": "解释一下什么是API中转服务"} ] response = await client.chat(messages) print(f"AI回复: {response}") # 流式对话 print("\n流式回复: ", end="") async for chunk in client.stream_chat(messages): print(chunk, end="", flush=True) print() if __name__ == "__main__": asyncio.run(main())
错误处理和重试机制是生产环境的必需品:
pythonimport backoff from openai import APIError, APIConnectionError, RateLimitError class RobustAIClient(AIClient): @backoff.on_exception( backoff.expo, (APIConnectionError, RateLimitError), max_tries=3, max_time=60 ) async def chat_with_retry(self, messages: List[Dict[str, str]], **kwargs) -> str: """带有自动重试的聊天接口""" return await self.chat(messages, **kwargs) async def chat_with_fallback(self, messages: List[Dict[str, str]], models: List[str]) -> str: """带有模型降级的聊天接口""" for model in models: try: return await self.chat(messages, model=model) except APIError as e: logger.warning(f"模型 {model} 调用失败: {e}") continue raise Exception("所有模型都失败了")
性能优化是进阶话题,但即使是简单的缓存也能带来巨大提升:
pythonfrom functools import lru_cache import hashlib import json class CachedAIClient(RobustAIClient): def __init__(self, config: Config): super().__init__(config) self.cache = {} def _generate_cache_key(self, messages: List[Dict[str, str]], **kwargs) -> str: """生成缓存键""" content = json.dumps({"messages": messages, **kwargs}, sort_keys=True) return hashlib.md5(content.encode()).hexdigest() async def cached_chat(self, messages: List[Dict[str, str]], **kwargs) -> str: """带缓存的聊天接口""" cache_key = self._generate_cache_key(messages, **kwargs) if cache_key in self.cache: logger.info("缓存命中") return self.cache[cache_key] response = await self.chat_with_retry(messages, **kwargs) self.cache[cache_key] = response return response
通过这个实战教程,你已经掌握了API集成的核心技术。从简单的调用到错误处理,从性能优化到缓存策略,这些都是生产环境中的实用技能。记住,好的代码不是一次写成的,而是不断迭代优化的结果。
多模型协同:超越单一AI的局限
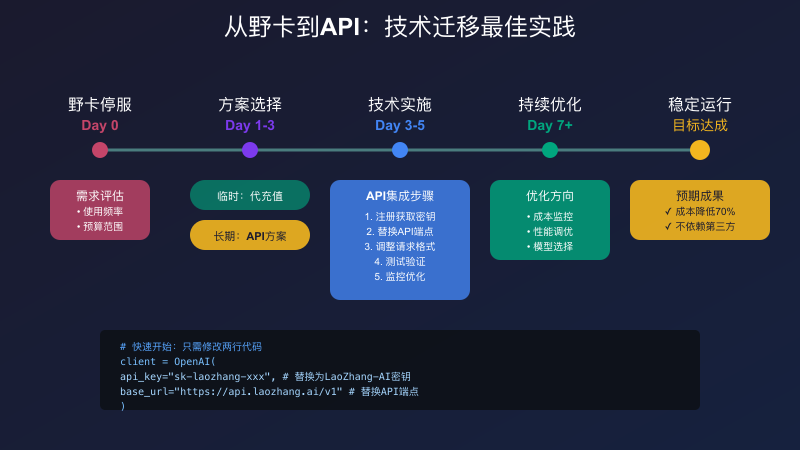
ChatGPT并非唯一选择。2025年的AI领域已经形成了多强并立的格局:OpenAI的GPT系列、Anthropic的Claude、Google的Gemini,每个模型都有独特的优势。通过API的方式,我们可以轻松实现多模型协同,发挥各自所长。
不同模型的技术特点决定了它们的最佳使用场景。GPT-4o在创意写作和代码生成方面表现卓越,其强大的few-shot学习能力使它特别适合处理新颖的任务。Claude 3.5 Sonnet在长文本理解和逻辑推理方面更胜一筹,200K的上下文窗口使它能够处理整本书的内容。Gemini Pro则在多模态理解上独树一帜,能够同时处理文本、图像和代码。
实现多模型协同的关键是智能路由。根据任务特征自动选择最合适的模型:
pythonclass ModelRouter: def __init__(self): self.model_features = { 'gpt-4o': { 'strengths': ['creativity', 'code_generation', 'general_knowledge'], 'context_window': 128000, 'cost_per_1k_tokens': 0.01 }, 'claude-3.5-sonnet': { 'strengths': ['reasoning', 'long_context', 'analysis'], 'context_window': 200000, 'cost_per_1k_tokens': 0.008 }, 'gemini-pro': { 'strengths': ['multimodal', 'speed', 'cost_effective'], 'context_window': 100000, 'cost_per_1k_tokens': 0.005 } } def select_model(self, task_type: str, context_length: int, budget_priority: bool) -> str: """根据任务特征选择最优模型""" candidates = [] for model, features in self.model_features.items(): # 检查上下文长度 if context_length > features['context_window']: continue # 评分系统 score = 0 # 任务匹配度 if task_type in features['strengths']: score += 10 # 成本考虑 if budget_priority: score += (10 - features['cost_per_1k_tokens'] * 100) candidates.append((model, score)) # 返回最高分的模型 return max(candidates, key=lambda x: x[1])[0] if candidates else 'gpt-4o'
模型组合策略可以实现1+1>2的效果。比如,使用Claude进行初步分析,提取关键信息;然后用GPT-4o进行创意扩展;最后用Gemini进行成本优化的批量处理。这种pipeline式的处理方式,既保证了质量,又控制了成本。
成本优化是多模型策略的重要考量。通过合理的模型选择,可以在保证效果的前提下显著降低成本。比如,对于简单的分类任务,使用Gemini Pro就足够了,成本只有GPT-4o的一半。而对于需要深度推理的复杂任务,Claude可能是更好的选择。
LaoZhang-AI 的优势在于,它提供了统一的接口访问所有这些模型。你不需要分别注册多个平台,管理多个API密钥,学习不同的接口规范。一个账号,一个接口,就能使用所有主流AI模型。这种便利性对于需要多模型协同的项目来说,价值无法估量。
企业级部署:可扩展的AI基础设施
当AI应用从实验阶段走向生产环境,企业级的部署方案变得至关重要。这不仅涉及技术架构,还包括安全合规、成本控制、团队协作等多个维度。
微服务架构是企业级AI应用的首选。将AI调用、用户管理、计费系统、日志审计等功能拆分为独立的服务,通过API网关统一对外提供服务:
yaml# docker-compose.yml - 企业级AI服务部署 version: '3.8' services: api-gateway: image: kong:latest environment: - KONG_DATABASE=postgres - KONG_PG_HOST=postgres - KONG_PROXY_ACCESS_LOG=/dev/stdout - KONG_ADMIN_ACCESS_LOG=/dev/stdout ports: - "8000:8000" - "8443:8443" depends_on: - postgres ai-service: build: ./ai-service environment: - API_PROVIDER=laozhang - API_KEY=${LAOZHANG_API_KEY} - REDIS_URL=redis://redis:6379 deploy: replicas: 3 resources: limits: memory: 2G reservations: memory: 1G auth-service: build: ./auth-service environment: - JWT_SECRET=${JWT_SECRET} - DATABASE_URL=postgresql://user:pass@postgres/auth billing-service: build: ./billing-service environment: - DATABASE_URL=postgresql://user:pass@postgres/billing - WEBHOOK_SECRET=${WEBHOOK_SECRET} postgres: image: postgres:15 environment: - POSTGRES_PASSWORD=${DB_PASSWORD} volumes: - postgres-data:/var/lib/postgresql/data redis: image: redis:7-alpine command: redis-server --appendonly yes volumes: - redis-data:/data prometheus: image: prom/prometheus volumes: - ./prometheus.yml:/etc/prometheus/prometheus.yml - prometheus-data:/prometheus grafana: image: grafana/grafana environment: - GF_SECURITY_ADMIN_PASSWORD=${GRAFANA_PASSWORD} ports: - "3000:3000" volumes: - grafana-data:/var/lib/grafana volumes: postgres-data: redis-data: prometheus-data: grafana-data:
Kubernetes部署提供了更强大的编排能力。通过HPA(Horizontal Pod Autoscaler)实现自动扩缩容,确保服务在高峰期也能稳定运行:
yaml# ai-service-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: ai-service spec: replicas: 3 selector: matchLabels: app: ai-service template: metadata: labels: app: ai-service spec: containers: - name: ai-service image: your-registry/ai-service:latest resources: requests: memory: "1Gi" cpu: "500m" limits: memory: "2Gi" cpu: "1000m" env: - name: API_PROVIDER value: "laozhang" - name: API_KEY valueFrom: secretKeyRef: name: ai-service-secrets key: api-key --- apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: ai-service-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: ai-service minReplicas: 3 maxReplicas: 20 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 70 - type: Resource resource: name: memory target: type: Utilization averageUtilization: 80
监控和告警是企业级部署的生命线。通过Prometheus收集指标,Grafana展示仪表板,AlertManager发送告警,形成完整的可观测性体系。关键指标包括:API调用延迟、错误率、token使用量、成本消耗等。
成本控制需要精细化管理。通过设置部门配额、项目预算、模型使用策略等手段,确保AI使用成本可控。同时,通过数据分析找出成本优化的机会,比如识别重复请求、优化prompt长度等。
团队协作方面,需要建立清晰的权限体系。不同角色(开发者、数据科学家、产品经理)有不同的访问权限。通过API密钥的分级管理,既保证了安全性,又提供了必要的灵活性。
安全合规:数据保护最佳实践
在AI应用中,数据安全和隐私保护不是可选项,而是必需品。特别是在处理敏感信息时,任何安全漏洞都可能造成严重后果。
API密钥管理是第一道防线。永远不要将密钥硬编码在代码中,也不要提交到版本控制系统。使用专业的密钥管理服务:
python# 使用 AWS Secrets Manager 的示例 import boto3 from botocore.exceptions import ClientError class SecureAPIKeyManager: def __init__(self): self.client = boto3.client('secretsmanager') self.cache = {} def get_api_key(self, secret_name: str) -> str: """安全地获取API密钥""" # 检查缓存 if secret_name in self.cache: return self.cache[secret_name] try: response = self.client.get_secret_value(SecretId=secret_name) secret = response['SecretString'] # 缓存密钥(设置过期时间) self.cache[secret_name] = secret return secret except ClientError as e: if e.response['Error']['Code'] == 'ResourceNotFoundException': raise ValueError(f"Secret {secret_name} not found") raise def rotate_api_key(self, secret_name: str, new_key: str): """轮换API密钥""" try: self.client.update_secret( SecretId=secret_name, SecretString=new_key ) # 清除缓存 self.cache.pop(secret_name, None) except ClientError as e: raise
请求加密确保数据在传输过程中的安全。除了标准的HTTPS,还可以实现应用层的加密:
pythonfrom cryptography.fernet import Fernet import json class EncryptedAPIClient: def __init__(self, api_client, encryption_key: bytes): self.api_client = api_client self.cipher = Fernet(encryption_key) async def encrypted_chat(self, messages: List[Dict[str, str]], **kwargs): """加密聊天内容""" # 加密敏感内容 encrypted_messages = [] for msg in messages: if msg['role'] == 'user': encrypted_content = self.cipher.encrypt( msg['content'].encode() ).decode() encrypted_messages.append({ 'role': msg['role'], 'content': f"ENCRYPTED:{encrypted_content}" }) else: encrypted_messages.append(msg) # 调用API response = await self.api_client.chat(encrypted_messages, **kwargs) # 如果需要,解密响应 return response
审计日志是合规的重要要求。每个API调用都应该被记录,包括谁、什么时候、调用了什么、结果如何:
pythonimport structlog from datetime import datetime logger = structlog.get_logger() class AuditedAPIClient: def __init__(self, api_client, user_id: str): self.api_client = api_client self.user_id = user_id async def chat_with_audit(self, messages: List[Dict[str, str]], **kwargs): """带审计的聊天接口""" request_id = generate_request_id() start_time = datetime.utcnow() # 记录请求 logger.info( "api_request_started", request_id=request_id, user_id=self.user_id, model=kwargs.get('model', 'default'), message_count=len(messages), timestamp=start_time.isoformat() ) try: response = await self.api_client.chat(messages, **kwargs) # 记录成功 logger.info( "api_request_completed", request_id=request_id, user_id=self.user_id, duration_ms=(datetime.utcnow() - start_time).total_seconds() * 1000, tokens_used=response.usage.total_tokens if hasattr(response, 'usage') else None ) return response except Exception as e: # 记录失败 logger.error( "api_request_failed", request_id=request_id, user_id=self.user_id, error_type=type(e).__name__, error_message=str(e), duration_ms=(datetime.utcnow() - start_time).total_seconds() * 1000 ) raise
数据脱敏是处理敏感信息的必要手段。在发送给AI之前,需要将个人身份信息、财务数据等敏感内容进行脱敏处理。处理完成后,再将结果还原。这样即使API提供商也无法获取真实的敏感信息。
性能优化:让AI飞起来
性能优化不仅能提升用户体验,还能显著降低成本。一个优化良好的AI应用,可以用一半的资源处理双倍的请求。
缓存是最有效的优化手段。对于确定性的查询,缓存可以避免重复的API调用:
pythonimport hashlib from typing import Optional import aioredis class SmartCache: def __init__(self, redis_url: str, ttl: int = 3600): self.redis = None self.redis_url = redis_url self.ttl = ttl async def connect(self): self.redis = await aioredis.create_redis_pool(self.redis_url) def _generate_key(self, messages: List[Dict], model: str) -> str: """生成缓存键""" content = json.dumps({ 'messages': messages, 'model': model }, sort_keys=True) return f"chat:{hashlib.sha256(content.encode()).hexdigest()}" async def get(self, messages: List[Dict], model: str) -> Optional[str]: """获取缓存""" if not self.redis: return None key = self._generate_key(messages, model) value = await self.redis.get(key) if value: # 更新过期时间 await self.redis.expire(key, self.ttl) return value.decode() return None async def set(self, messages: List[Dict], model: str, response: str): """设置缓存""" if not self.redis: return key = self._generate_key(messages, model) await self.redis.setex(key, self.ttl, response) async def invalidate_pattern(self, pattern: str): """批量失效缓存""" if not self.redis: return cursor = b'0' while cursor: cursor, keys = await self.redis.scan( cursor, match=f"chat:*{pattern}*" ) if keys: await self.redis.delete(*keys)
并发控制避免资源耗尽。通过信号量限制同时进行的API调用数:
pythonimport asyncio from asyncio import Semaphore class ConcurrencyControlledClient: def __init__(self, api_client, max_concurrent: int = 10): self.api_client = api_client self.semaphore = Semaphore(max_concurrent) self.queue = asyncio.Queue() async def chat_with_concurrency_control(self, messages: List[Dict], **kwargs): """带并发控制的聊天接口""" async with self.semaphore: return await self.api_client.chat(messages, **kwargs) async def batch_process(self, tasks: List[Dict]) -> List[str]: """批量处理请求""" async def process_task(task): try: return await self.chat_with_concurrency_control( task['messages'], **task.get('kwargs', {}) ) except Exception as e: return f"Error: {str(e)}" # 并发执行所有任务 results = await asyncio.gather( *[process_task(task) for task in tasks], return_exceptions=True ) return results
流式响应优化用户体验。用户不需要等待完整响应,可以看到AI逐字输出:
pythonclass StreamingOptimizedClient: def __init__(self, api_client): self.api_client = api_client async def stream_with_buffer( self, messages: List[Dict], buffer_size: int = 10, **kwargs ): """带缓冲的流式输出""" buffer = [] async for chunk in self.api_client.stream_chat(messages, **kwargs): buffer.append(chunk) # 当缓冲区满或遇到标点符号时输出 if len(buffer) >= buffer_size or chunk in '.!?。!?': yield ''.join(buffer) buffer = [] # 输出剩余内容 if buffer: yield ''.join(buffer)
请求优化可以减少token使用量。通过压缩prompt、移除冗余信息、使用更高效的表达方式,可以在不影响效果的前提下降低成本:
pythonclass PromptOptimizer: def __init__(self): self.compression_rules = [ # 移除多余空格 (r'\s+', ' '), # 简化常见表达 (r'请你帮我', '请'), (r'你能不能', '能否'), # 移除语气词 (r'[啊呢吧呀]', ''), ] def optimize_prompt(self, prompt: str) -> str: """优化prompt以减少token使用""" optimized = prompt for pattern, replacement in self.compression_rules: optimized = re.sub(pattern, replacement, optimized) # 移除首尾空白 optimized = optimized.strip() # 记录优化效果 original_tokens = count_tokens(prompt) optimized_tokens = count_tokens(optimized) if original_tokens > optimized_tokens: logger.info( f"Prompt优化: {original_tokens} -> {optimized_tokens} tokens " f"(节省 {(1 - optimized_tokens/original_tokens)*100:.1f}%)" ) return optimized
通过这些优化技术的组合使用,可以构建一个高性能、低成本的AI应用。记住,优化是一个持续的过程,需要根据实际使用情况不断调整和改进。
未来展望:AI服务的下一个五年
站在2025年的时间节点,我们可以清晰地看到AI服务发展的几个重要趋势。理解这些趋势,有助于我们做出更明智的技术选择。
开源大模型的崛起是最引人注目的变化。Meta的Llama系列、Mistral AI的开源模型,以及众多社区驱动的项目,正在打破商业模型的垄断。这些模型虽然在某些指标上还略逊于GPT-4,但差距正在快速缩小。更重要的是,开源意味着完全的控制权——你可以在自己的硬件上运行,按需定制,没有任何使用限制。
边缘计算和本地部署成为新的热点。随着模型量化技术的进步,在消费级硬件上运行大语言模型已经成为可能。Apple的M系列芯片、NVIDIA的RTX显卡,都能运行数十亿参数的模型。这对于注重隐私的企业用户来说,是一个巨大的福音。数据不出本地,延迟降到最低,成本完全可控。
Web3与去中心化AI的结合带来了新的可能性。通过区块链技术,可以构建去中心化的AI服务网络。用户贡献算力获得代币奖励,使用服务消耗代币,形成一个自运转的生态系统。这种模式避免了中心化平台的各种问题:审查、隐私泄露、服务中断等。
模型专业化是另一个重要趋势。通用模型试图解决所有问题,但在特定领域的表现往往不如专业模型。我们将看到更多针对特定行业、特定任务的模型出现。医疗AI、法律AI、金融AI,每个领域都会有自己的"GPT"。
API标准化正在推进。OpenAI的接口已经成为事实标准,大多数AI服务都提供兼容的API。这降低了切换成本,增加了用户的选择自由。未来,可能会出现行业标准,就像HTTP协议统一了Web一样。
对于开发者来说,这是最好的时代。AI不再是少数大公司的专利,而是每个开发者都能使用的工具。无论是通过API调用云端模型,还是在本地运行开源模型,选择从未如此丰富。关键是要保持学习,跟上技术发展的步伐。
结语
野卡的跑路,表面上是一次危机,实际上是一次机遇。它迫使我们跳出支付工具的局限,从更高的维度思考AI服务的访问方式。从虚拟信用卡到API调用,从单一模型到多模型协同,从中心化服务到去中心化网络,技术的演进为我们提供了更多更好的选择。
回顾本文,我们深入分析了四大类替代方案的技术特征,详细讲解了API集成的实战技巧,探讨了企业级部署的最佳实践。无论你是个人开发者还是企业用户,都能找到适合自己的解决方案。
如果要给出一个建议,那就是:拥抱API时代。相比传统的订阅模式,API提供了更大的灵活性、更低的成本、更好的可控性。通过 LaoZhang-AI 这样的优质服务商,你可以轻松接入所有主流AI模型,享受技术进步带来的红利。
技术在变,但创新的精神不变。在这个AI驱动的时代,保持开放的心态,持续学习新技术,才能在变革中把握机遇。野卡已成历史,但AI的未来才刚刚开始。让我们一起,用技术的力量,创造更美好的明天。