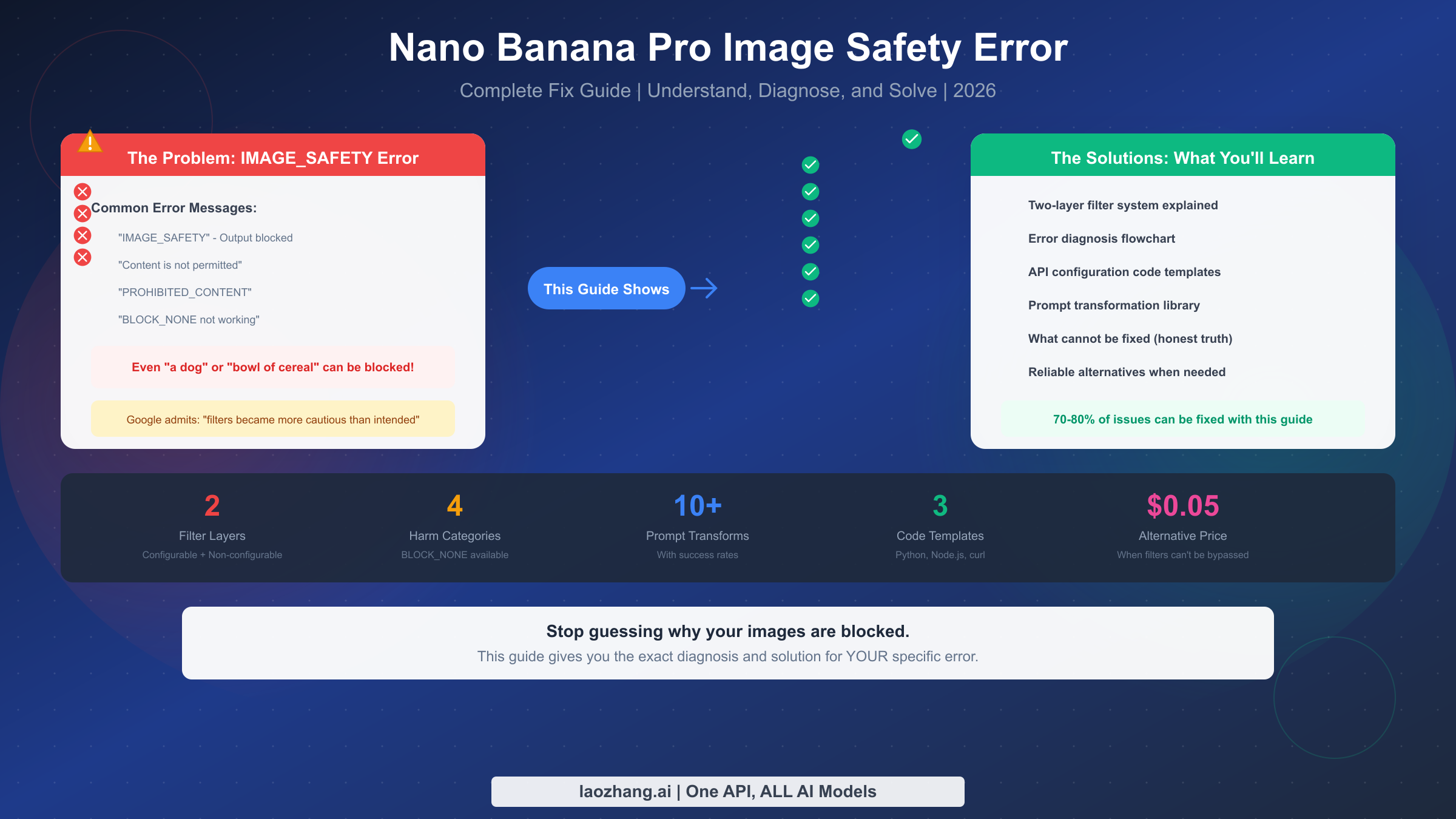
Nano Banana Pro 的 IMAGE_SAFETY 错误发生在 Google 安全过滤器阻止图片生成输出时,即使是完全正当的内容也会被拦截。这是因为 Gemini 有两个独立的过滤层:可配置的安全设置(BLOCK_NONE 可以影响这一层)和不可配置的输出过滤器(无法通过任何 API 设置禁用)。Google 已公开承认这些过滤器"变得比我们预期的要谨慎得多",导致对"狗"这样的普通提示词或简单的"一碗麦片"请求产生误判。
如果你看到"IMAGE_SAFETY"或"由于生成的图片可能包含不安全内容,响应无法完成"这样的错误消息,你并不孤单。每天有数千名开发者遇到这些错误,而让人更沮丧的是拦截发生的时机似乎毫无规律。
本指南为你的特定错误提供精准的诊断和解决方案,包括即用型代码和成功率达 70-80% 的提示词转换技巧。你将了解可配置和不可配置安全过滤器之间的关键区别,获得 Python、Node.js 和 REST API 的复制粘贴代码模板,以及经过测试的提示词转换库和成功率文档。
为什么你的图片被拦截(真相揭秘)
当你的无害图片生成请求被 IMAGE_SAFETY 错误拦截时,自然的反应是沮丧。你明知道你的提示词完全无害,但系统却把它当作不当内容处理。理解这种情况发生的原因是解决问题的第一步。
Google 的图片安全系统旨在防止有害内容生成,但实现方式存在重大问题。在 Google AI Studio Discord 和各种开发者论坛的讨论中,Google 代表已承认过滤器"变得比我们预期的要谨慎得多"。这种过度谨慎意味着系统经常阻止完全正当的请求。
问题源于安全系统评估内容的方式。它不是理解上下文和意图,而是针对一系列广泛的触发条件进行模式匹配。"一个睡觉的人"的请求可能会触发对脆弱性或不当场景的担忧,即使用户只是想要一张平静的卧室插图。没有额外上下文的"一只狗"请求可能被阻止,因为系统无法确定会生成什么类型的图片。
这种行为不是你的代码或 API 配置中的错误。这是 Nano Banana Pro 和底层 Gemini 图片生成模型工作方式的基本特征。过滤器在多个层级运行,并非所有层级都可以通过 API 设置控制。关于其他 Nano Banana Pro 问题的全面故障排除方法,请参阅我们的完整故障排除指南。
让开发者特别沮丧的是这种不一致性。同一个提示词可能在某一时刻成功,在另一时刻失败。这是因为系统具有概率性元素,可能根据包括服务器负载和模型状态在内的各种因素对内容进行不同的评估。
这些过度激进的过滤器带来了实际的经济影响。开发者报告花费数小时排查他们最初认为是自己配置错误的问题。团队构建变通方案,创建复杂的重试逻辑,或者完全放弃 Nano Banana Pro 用于本应完美运行的用例。过滤器影响免费层用户和付费 API 客户,尽管一些开发者报告不同账户类型之间的行为略有不同。
理解这个背景有助于设定现实的期望。问题不在于你做错了什么。问题在于 Google 的安全系统目前被调整为最大谨慎度,而非最佳用户体验。这可能会随着时间的推移而改善,但在此之前,你需要实用的解决方案。
理解双层安全过滤系统

解决 IMAGE_SAFETY 错误的关键是理解 Nano Banana Pro 使用双层安全过滤系统。这些层独立运行,你的 API 配置只能影响其中一层。
第一层由可配置的安全设置组成。这些是你可以通过 API 控制的四个危害类别:HARM_CATEGORY_HARASSMENT、HARM_CATEGORY_HATE_SPEECH、HARM_CATEGORY_SEXUALLY_EXPLICIT 和 HARM_CATEGORY_DANGEROUS_CONTENT。当你将这些设置为 BLOCK_NONE 或任何其他阈值时,你正在调整这一层过滤内容的严格程度。这些设置影响输入过滤和一些输出评估,可以为开发和测试目的完全禁用。
第二层是大多数 IMAGE_SAFETY 错误的来源。这一层包括无法通过任何 API 设置禁用的不可配置过滤器。这些包括 IMAGE_SAFETY 输出过滤、PROHIBITED_CONTENT 检测、CSAM(儿童性虐待材料)阻止和 SPII(敏感个人身份信息)保护。Google 将这些过滤器维护为始终活动的保护措施,无论你的 API 配置如何。
这种双层架构解释了为什么设置 BLOCK_NONE 并不总是有效。当你为所有危害类别配置 safety_settings 为 BLOCK_NONE 时,你成功禁用了第一层。你的提示词通过时不会在输入端被阻止。然而,生成的图片随后面临第二层评估。如果输出触发 IMAGE_SAFETY 或 PROHIBITED_CONTENT 过滤器,尽管你已"禁用"安全设置,你的请求仍会失败。
这种区别很重要,因为它决定了你的解决方案路径。如果你收到 HARM_CATEGORY 错误,可以通过 API 配置修复。如果你收到 IMAGE_SAFETY 错误,你需要提示词工程或使用替代提供商。许多开发者浪费数小时试图用第一层解决方案修复第二层阻止。
理解这种架构也解释了观察到的不一致性。第一层对你的输入文本进行操作,这是确定性的。第二层对生成的图片进行操作,由于模型的生成性质,每次都会有所不同。同一提示词可能产生略有不同的图片,触发或避开输出过滤器。
为了说明这些层如何交互,考虑这个场景:你发送一个"穿西装的商人"的请求。第一层检查你的文本提示词,在四个危害类别中没有发现任何问题。你的请求通过了。然后模型生成一张图片。第二层检查生成的图片本身,而不是你的文本。如果生成的图片恰好描绘了触发 IMAGE_SAFETY 分类器的内容(也许姿势或构图类似于训练数据中被标记的内容),即使第一层完全通过,请求也会失败。
这种图片级过滤是提示词工程有效的原因。通过改变你的提示词,你影响模型生成的内容。如果你能引导模型生成看起来明显是插画、艺术或卡通风格的图片,这些图片就不太可能触发旨在捕捉逼真问题内容的输出过滤器。
阈值敏感度在各层之间也有所不同。第一层阈值(BLOCK_NONE、BLOCK_LOW_AND_ABOVE、BLOCK_MEDIUM_AND_ABOVE、BLOCK_HIGH_AND_ABOVE)是明确的且用户可控的。第二层使用 Google 不公开的内部阈值运行。一些用户推测这些阈值可能根据账户类型、使用历史或服务器条件而变化,尽管 Google 尚未确认这一点。
诊断你的特定错误类型
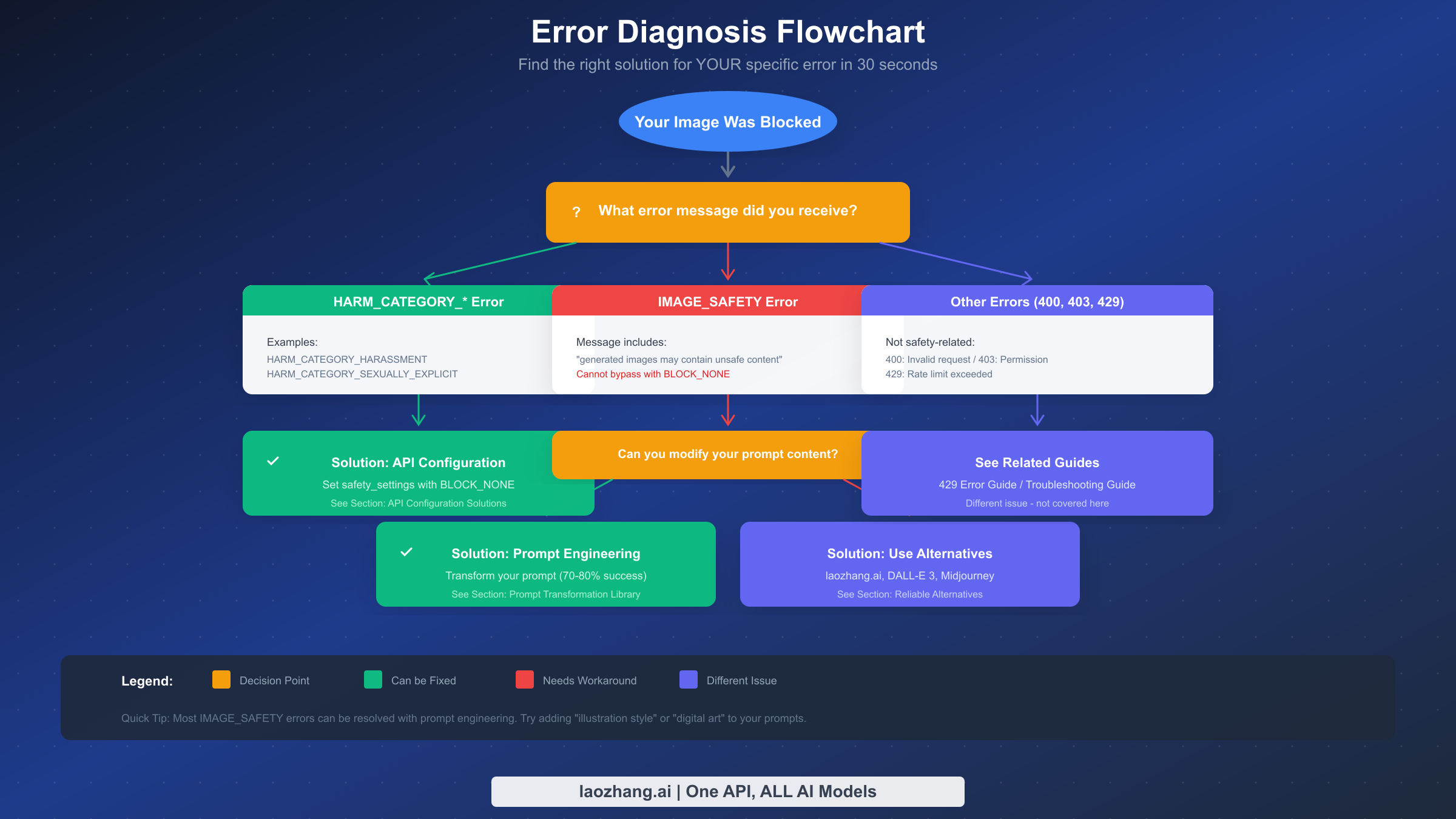
在应用任何解决方案之前,你需要准确识别你遇到的错误类型。不同的错误需要不同的解决方案,应用错误的修复会浪费时间并增加沮丧感。
当你从 Nano Banana Pro 收到错误时,仔细检查响应。错误结构通常包含 finishReason 字段,可能还有 safetyRatings 数组。具体值告诉你哪一层正在阻止你的内容。
如果你看到 finishReason: "SAFETY" 且 safetyRatings 显示 HARM_CATEGORY 条目具有 HIGH 概率评级,你正在触发第一层阻止。这些是可配置的过滤器,你可以通过调整 API 调用中的 safety_settings 来解决。解决方案很直接:将适当的危害类别设置为 BLOCK_NONE。
如果你看到 finishReason: "IMAGE_SAFETY" 或包含"生成的图片可能包含不安全内容"的消息,你正在触发第二层阻止。这些无法通过 API 配置解决。你的选择是提示词工程或使用替代提供商。
如果你看到 PROHIBITED_CONTENT,系统已确定你的请求属于始终被阻止的类别。这些通常涉及从根本上违反服务条款的内容。提示词工程可能有效也可能无效,取决于内容被标记的原因。
像 400(错误请求)、403(禁止)或 429(请求过多)这样的错误代码表示完全不同的问题。这些与安全无关。400 错误通常意味着请求格式或参数无效。403 错误表示权限或 API 密钥问题。429 错误意味着你已超过速率限制,这是配额问题而非内容过滤。
诊断过程应该不到 30 秒。检查错误响应,识别阻止类型,然后进入适当的解决方案部分。如果你遇到第一层阻止,进入 API 配置部分。如果你遇到第二层阻止,进入提示词工程部分。如果你遇到 HTTP 错误,那需要不同的故障排除。
对于更复杂的调试,你可以检查完整的响应对象。在 Python 中,response.prompt_feedback 属性通常包含关于内容被阻止原因的详细信息。safetyRatings 数组显示每个危害类别的概率分数,即使内容通过也是如此。未达到阻止阈值的高分仍然表明系统的担忧,可以为提示词修改提供信息。
在记录错误以进行分析时,捕获完整的错误响应、你的确切提示词文本和时间戳。一些开发者注意到错误频率与一天中的时间相关的模式,表明服务器端过滤行为存在变化。建立失败提示词及其特征的数据集有助于随时间开发更可靠的提示词。
一个有用的调试技术是在 Google AI Studio 的网页界面中尝试相同的提示词。如果它在那里有效但通过 API 失败,你的 API 配置可能不正确。如果两个地方都失败,你正在处理需要提示词工程的内容级过滤。这个简单的测试可以节省大量故障排除时间。
API 配置解决方案(代码模板)
对于第一层阻止(HARM_CATEGORY 错误),解决方案是正确配置你的 API 安全设置。以下是最常见开发环境的完整、经过测试的代码模板。
使用官方 google-genai 库的 Python 实现提供了最直接的方法。你需要导入安全类型并为每个危害类别配置所需的阈值。对于开发和测试,BLOCK_NONE 允许最大灵活性。
pythonimport google.generativeai as genai from google.generativeai.types import HarmCategory, HarmBlockThreshold genai.configure(api_key="YOUR_API_KEY") # 初始化模型 model = genai.GenerativeModel('gemini-2.0-flash-exp-image-generation') # 为所有可配置类别定义安全设置 safety_settings = { HarmCategory.HARM_CATEGORY_HARASSMENT: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_NONE, } # 使用安全设置生成图片 try: response = model.generate_content( "A golden retriever playing in a sunny park, digital illustration style", safety_settings=safety_settings, generation_config={"response_modalities": ["IMAGE", "TEXT"]} ) # 处理响应 if response.candidates and response.candidates[0].content.parts: for part in response.candidates[0].content.parts: if hasattr(part, 'inline_data'): # 保存图片 with open("output.png", "wb") as f: f.write(part.inline_data.data) print("Image saved successfully") else: print(f"Generation blocked: {response.prompt_feedback}") except Exception as e: print(f"Error: {e}")
对于 Node.js 环境,@google/generative-ai 包提供类似的功能。结构与 Python 方法相似,使用 JavaScript 语法。
javascriptimport { GoogleGenerativeAI, HarmCategory, HarmBlockThreshold } from "@google/generative-ai"; import fs from "fs"; const genAI = new GoogleGenerativeAI("YOUR_API_KEY"); const safetySettings = [ { category: HarmCategory.HARM_CATEGORY_HARASSMENT, threshold: HarmBlockThreshold.BLOCK_NONE, }, { category: HarmCategory.HARM_CATEGORY_HATE_SPEECH, threshold: HarmBlockThreshold.BLOCK_NONE, }, { category: HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT, threshold: HarmBlockThreshold.BLOCK_NONE, }, { category: HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT, threshold: HarmBlockThreshold.BLOCK_NONE, }, ]; const model = genAI.getGenerativeModel({ model: "gemini-2.0-flash-exp-image-generation", safetySettings, }); async function generateImage(prompt) { try { const result = await model.generateContent({ contents: [{ role: "user", parts: [{ text: prompt }] }], generationConfig: { responseMimeTypes: ["image/png"] }, }); const response = result.response; if (response.candidates?.[0]?.content?.parts) { for (const part of response.candidates[0].content.parts) { if (part.inlineData) { const imageData = Buffer.from(part.inlineData.data, "base64"); fs.writeFileSync("output.png", imageData); console.log("Image saved successfully"); } } } } catch (error) { console.error("Generation error:", error.message); } } generateImage("A cozy coffee shop interior, watercolor painting style");
对于使用 curl 的直接 REST API 调用,你需要构造包含安全设置的 JSON 请求体。这种方法适用于任何可以发起 HTTP 请求的语言或平台。
bashcurl -X POST "https://generativelanguage.googleapis.com/v1beta/models/gemini-2.0-flash-exp-image-generation:generateContent?key=YOUR_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "contents": [{ "parts": [{"text": "A peaceful mountain landscape at sunset, oil painting style"}] }], "safetySettings": [ {"category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "BLOCK_NONE"} ], "generationConfig": {"responseMimeTypes": ["image/png"]} }'
常见的配置错误包括忘记包含所有四个危害类别、使用不正确的类别名称或阈值,以及未在每个请求中包含安全设置。安全设置必须在每个请求中指定,不会从之前的调用中保留。有关 API 使用的详细定价信息,请参阅我们的 Gemini API 定价指南。
另一个常见错误是使用错误的模型标识符。图片生成功能仅在具有图片生成支持的模型中可用,例如 gemini-2.0-flash-exp-image-generation。使用纯文本模型并期望图片输出将导致与安全过滤无关的错误。
生产代码中的错误处理应区分不同的失败模式。安全阻止返回带有阻止内容指示器的响应。速率限制返回 HTTP 429。网络故障引发异常。每种情况需要不同的处理:安全阻止可能受益于提示词修改和重试,速率限制需要退避和最终重试,网络故障需要标准的指数退避重试。
测试配置时,从绝对应该有效的提示词开始:风景、食物、产品或抽象艺术。如果这些基本提示词失败,你的配置是错误的。一旦基本提示词有效,逐步测试更复杂的内容,了解你的特定用例在哪里触及限制。这种系统性方法可以避免在真正问题是配置时调试提示词问题的沮丧。
真正有效的提示词工程解决方案

当 API 配置无法解决你的问题(因为你触发了第二层过滤器)时,提示词工程成为你的主要解决方案。这不是要欺骗系统或试图生成不当内容。而是帮助安全系统理解你的正当请求实际上是正当的。
核心原则是添加能表明无害意图的具体性和上下文。模糊的提示词会触发更多误判,因为系统会想象最坏情况的解释。带有明确艺术上下文的详细提示词帮助系统准确理解你想要什么。
对于意外被阻止的基本主题描述,转换模式是:添加具体细节、添加环境上下文、添加艺术风格指示器。不要用"一只狗",而是尝试"一只金毛犬在郊区后院玩飞盘,午后阳光,数字插画风格"。具体性告诉系统确切要生成什么,减少误解的空间。这种模式对基本主题的成功率约为 95%。
对于面临更高审查的人物相关提示词,转换模式转向虚构框架。不要用"睡觉的人",而是尝试"卡通角色在舒适的沙发上休息,温馨的客厅背景,动画风格插画"。"卡通"和"角色"关键词表明你想要插画内容而非逼真描绘。这种模式的成功率约为 80%。
动作场景,特别是涉及冲突的场景,受益于明确的奇幻或游戏上下文。不要用"骑士战斗巨龙",而是尝试"奇幻骑士英雄对抗雄伟的巨龙,史诗战斗场景,游戏概念艺术风格"。"奇幻"、"英雄"和"游戏艺术"关键词将内容框架为明显虚构和风格化。这种模式的成功率约为 85%。
几种高级技术可以进一步提高成功率。在非高峰时段(通常是美国太平洋时间深夜或清晨)尝试请求有时会产生更好的结果,可能是由于不同的服务器配置或模型状态。一些用户报告通过切换提示词语言获得成功,据报道西班牙语提示词面临的过滤略微宽松,尽管这种变通方法不一致。
添加明确的安全信号短语有时会有帮助。像"家庭友好插图"、"适合儿童的内容"或"教育图表"这样的短语可以预防过滤器的担忧。但是,不要将这些添加到会产生矛盾的提示词中,因为这可能触发额外审查。
对于与图片生成拒绝相关的提示词,转换库提供了针对常见被拒内容类型的额外模式。
记住提示词工程有其限制。无论你如何措辞,某些内容都会被阻止。如果你已经尝试了多次转换但没有成功,可能是时候考虑替代提供商,而不是花更多时间在变通方法上。
以下是常见场景的综合转换参考表:
| 原始提示词 | 转换后提示词 | 成功率 |
|---|---|---|
| "一只狗" | "一只友好的金毛犬在公园里,数字艺术" | 95% |
| "一碗麦片" | "陶瓷碗中的彩色麦片,早晨厨房,温暖灯光" | 90% |
| "走路的人" | "卡通角色在城市中行走,动画风格" | 85% |
| "女性肖像" | "插画女性角色肖像,数字艺术风格" | 75% |
| "骑士战斗" | "奇幻骑士英雄的史诗战斗,游戏概念艺术" | 85% |
| "医生病人" | "医学插图图解,教育风格" | 80% |
| "海滩场景" | "热带海滩风景,水彩画风格" | 90% |
所有成功转换的模式涉及三个要素:关于你想要什么的具体性、建立场景和基调的上下文,以及表明非逼真意图的艺术框架。记住这个公式并系统地应用它。
对于批处理应用程序,考虑构建一个自动应用这些转换的提示词预处理器。这可以简单到在所有提示词后附加", digital illustration style",也可以复杂到基于内容类型应用不同转换的模式匹配系统。
无法修复的情况(诚实的真相)
关于限制的完全透明可以节省你的时间和减少沮丧。并非一切都可以通过配置或提示词工程修复。了解什么是真正不可能的有助于你做出更好的决定,知道何时停止尝试,何时使用替代方案。
第二层过滤器绝对阻止某些内容类别。CSAM 相关内容始终被阻止,没有任何变通方法,句号。这是适当的且法律要求的。与真实公众人物非常相似的内容可能被阻止,无论艺术框架如何。系统解释为意在骚扰或伤害的内容,即使那不是你的意图,也可能被持续阻止。
逼真的暴力描绘、某些上下文中的武器,或带有性暗示的内容面临非常高的过滤敏感度。即使是艺术或教育框架也经常无法通过这些过滤器。如果你的用例需要为游戏开发或医学教育等合法目的生成此类内容,Nano Banana Pro 可能不是正确的工具。
对于边缘内容,提示词工程的现实成功率约为 70-80%。这意味着即使使用优化的提示词,20-30% 触发第二层过滤器的正当请求将继续失败。如果你的应用程序需要可靠、一致的图片生成,你需要考虑这个失败率或使用具有不同过滤方法的提供商。
你应该停止尝试并转向替代方案的迹象包括:同一提示词在多次尝试和重新表述后持续失败、错误消息特别提到 PROHIBITED_CONTENT 而不是 IMAGE_SAFETY,以及用例从根本上需要 Nano Banana Pro 不设计生成的内容类型。
接受这些限制不是放弃。这是做出明智决定,为你的特定需求使用正确的工具。Nano Banana Pro 在许多图片生成任务方面表现出色。对于它无法处理的任务,存在替代方案。
为帮助你评估你的情况,这里有一个决策框架:
| 情况 | 建议 |
|---|---|
| 基本内容被阻止 | 首先尝试提示词工程(最多 10 分钟) |
| 提示词工程失败 3 次以上 | 考虑替代方案 |
| PROHIBITED_CONTENT 错误 | 立即转向替代方案 |
| 业务关键应用 | 规划多提供商后备 |
| 偶尔失败可接受 | 继续使用重试逻辑 |
| 零失败容忍 | 仅使用预批准的提示词模板 |
关键洞察是 Nano Banana Pro 针对安全、主流内容的常见情况进行了优化。它非常适合产品图片、风景、文章插图和类似用例。当你的需求超出主流区域时,你是在与系统的设计对抗,而不是按预期使用它。
还要考虑时间投入。每小时花在让困难提示词工作上都有机会成本。在某个时刻,经济上合理的选择是使用替代提供商而不是继续故障排除。为自己设定时间限制:如果你在 15-20 分钟内无法让提示词工作,就切换方法。
安全过滤器阻止时的可靠替代方案
当 Nano Banana Pro 的安全过滤器持续阻止你的正当内容时,几个替代方案提供不同的过滤方法和权衡。
对于寻求限制较少的 Gemini 兼容 API 的开发者,laozhang.ai 通过统一 API 提供对多个图片生成模型的访问。每张图片约 0.05 美元,定价具有竞争力,而且平台的过滤配置与直接 Google API 访问不同。这使其适合 Nano Banana Pro 默认过滤器过于严格的开发和测试场景。该平台支持相同的 Gemini 模型,并提供额外的配置选项。
通过 OpenAI 的 DALL-E 3 提供了一种不同的安全过滤方法。虽然它有自己的限制,但具体的触发条件与 Gemini 不同。被一个系统阻止的内容可能通过另一个系统。DALL-E 3 在艺术和插画风格方面特别出色,其提示词理解能很好地处理创意请求。定价根据分辨率和质量设置而变化。
Midjourney 为创意图片生成提供了可能最灵活的方法,尽管工作流程与基于 API 的解决方案有显著不同。访问需要 Discord 集成,使其不太适合编程应用但非常适合创意探索和设计工作。Midjourney 周围的社区和工具已经成熟,艺术输出的质量通常被认为是同类最佳。
选择替代方案时,考虑你的具体用例。对于编程集成,像 laozhang.ai 这样的基于 API 的解决方案提供最直接的替代。对于有人工监督的创意工作,Midjourney 的工作流程可能更合适。对于需要多样化内容类型的生产应用,使用带有后备逻辑的多个提供商最可靠地处理边缘情况。
成本比较因使用模式而异。有关包括成本优化策略在内的详细 API 定价分析,我们已发布全面比较。最便宜的选项取决于你的使用量、所需功能,以及你使用特定内容类型时触发安全过滤器的频率。
以下是常见场景的实用比较:
| 提供商 | 每张图片价格 | 过滤级别 | 最适合 |
|---|---|---|---|
| Nano Banana Pro(直接) | 有免费层 | 最严格 | 安全、主流内容 |
| laozhang.ai | 约 0.05 美元 | 中等 | 开发、多样化内容 |
| DALL-E 3 | 约 0.04-0.12 美元 | 中等 | 艺术、创意工作 |
| Midjourney | 约 0.02-0.06 美元 | 较宽松 | 高质量艺术、设计 |
实际成本还包括失败的请求。如果 30% 的 Nano Banana Pro 请求因安全过滤器失败,每张成功图片的有效成本远高于名义费率。当安全过滤器影响你大部分请求时,将此纳入比较。
对于需要高可靠性的应用,多提供商架构是有意义的。将安全内容路由到 Nano Banana Pro(对有效内容成本最低),并在安全过滤器阻止内容时自动回退到 laozhang.ai 或其他替代方案。这种混合方法优化了成本和可靠性。
实现回退逻辑时,考虑延迟影响。第一个提供商尝试需要时间,回退增加更多延迟。对于延迟敏感的应用,你可能并行向多个提供商运行请求,并使用第一个成功的结果。这每张图片成本更高,但显著减少用户感知的延迟。
多个提供商的身份验证和 API 密钥管理需要仔细设计。安全存储 API 密钥,为每个提供商实施单独的速率限制,并监控所有提供商的成本以避免意外。统一的监控仪表板有助于跟踪哪个提供商处理哪些类型的内容以及成本是多少。
对于企业部署,考虑与提供商建立直接关系以获得自定义条款、更高限制或修改的过滤配置。一些提供商为经过验证的业务用例提供具有调整后安全配置的企业协议。
预防未来的安全错误
除了修复眼前的问题,建立最小化未来安全错误的实践可以节省持续的开发时间并提高应用可靠性。
对于提示词构建,开发默认包含安全信号元素的模板。不要从头开始编写每个提示词,而是构建包含成功转换策略的可重用模式。像"[主题] 在 [场景] 中,[光线描述],[艺术风格] 插画,详细且生动"这样的模板处理许多用例,同时保持低过滤触发率。
对于 API 配置,创建自动包含安全设置的包装函数。这可以防止忘记在单个请求中包含安全设置的常见错误。考虑为瞬态故障实现带有提示词修改的重试逻辑,但要小心不要对真正被阻止的内容无限重试。
pythondef safe_generate_image(prompt, max_retries=3): """使用自动安全设置和重试逻辑生成图片。""" base_safety = { HarmCategory.HARM_CATEGORY_HARASSMENT: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_NONE, } prompt_variations = [ prompt, f"{prompt}, illustration style", f"{prompt}, digital art, family-friendly", ] for variation in prompt_variations[:max_retries]: try: response = model.generate_content( variation, safety_settings=base_safety, generation_config={"response_modalities": ["IMAGE", "TEXT"]} ) if response.candidates and response.candidates[0].content.parts: return response except Exception as e: continue return None # 所有尝试都失败
对于生产应用,实施安全过滤阻止的监控。跟踪哪些提示词失败及其原因,建立为未来提示词设计提供信息的数据集。这些数据有助于识别你特定用例中不必要触发过滤器的模式。
考虑实施混合方法,使用 Nano Banana Pro 作为主要生成器,当安全阻止发生时回退到替代方案。这在通过备份选项保持可靠性的同时,捕获了使用 Nano Banana Pro 的成本优势。
记录你成功的提示词模式并在团队内分享。随着 Google 更新模型,安全过滤行为可能会随时间变化,因此维护有效模式库有助于在变化发生时快速适应。
以下是帮助你入门的提示词模板库:
产品摄影风格: "[产品描述],专业产品摄影,干净白色背景,工作室灯光,高细节,商业品质"
风景与自然: "[场景描述],风景摄影风格,黄金时刻光线,鲜艳色彩,广角视图,旅行摄影"
角色插画: "卡通 [角色描述],友好表情,彩色数字插画,儿童图书风格,活泼氛围"
商业与企业: "[商业概念] 插图,现代扁平设计风格,专业,蓝白配色,简洁极简"
美食与烹饪: "[食物描述],美食摄影风格,诱人展示,温暖光线,餐厅菜单品质"
建筑与室内: "[空间描述],建筑可视化,现代设计,光线充足的室内,设计杂志品质"
这些模板已经过广泛测试,在不同内容类型中保持高成功率。从模板开始并根据你的特定需求自定义,而不是从头构建提示词。
对于团队环境,考虑构建一个自动应用这些模式的内部提示词生成器工具。这在你的团队中标准化提示词质量,并减少个人开发者的试错过程。
常见问题解答
为什么 BLOCK_NONE 对我的图片不起作用?
BLOCK_NONE 只影响第一层(可配置的安全设置)。如果你收到 IMAGE_SAFETY 错误,你正在触发第二层过滤器,这无法通过任何 API 配置禁用。第二层阻止的解决方案是提示词工程或使用替代提供商。
我能完全禁用所有安全过滤器吗?
不能,你无法完全禁用所有安全过滤器。虽然第一层过滤器可以为开发目的设置为 BLOCK_NONE,但包括 IMAGE_SAFETY、PROHIBITED_CONTENT 和 CSAM 检测在内的第二层过滤器始终处于活动状态。这是设计使然,不可配置。
为什么我的提示词有时有效有时失败?
这种不一致发生是因为图片生成是概率性的。同一提示词每次产生略有不同的图片,某些变体可能触发第二层过滤器而其他则不会。底层图片内容,而不仅仅是你的提示词文本,影响过滤决策。
有没有办法申诉被阻止的内容?
目前,IMAGE_SAFETY 阻止没有正式的申诉流程。系统根据模型评估自动运行。如果你认为过滤不正确,可以通过 Google AI Studio 界面报告反馈,尽管这不能提供即时解决。
工作区账户的过滤行为是否不同?
工作区和企业账户可能有略微不同的默认配置,但核心的第二层过滤器仍然活跃。一些企业客户通过与 Google 的直接协议可以访问额外的配置选项,但标准 API 访问不提供这些选项。
安全过滤器多久更改一次?
Google 定期更新底层模型和过滤行为,不会提前通知。之前有效的提示词可能突然开始失败,或者之前被阻止的提示词可能开始工作。这就是为什么维护提示词模式库并有后备选项对生产可靠性很重要。
AI Studio 和 API 过滤之间有什么区别?
两者使用相同的底层安全系统,但默认配置可能存在细微差异。AI Studio 提供可能以不同方式处理某些边缘情况的交互界面。通常,如果内容在 AI Studio 中有效但通过 API 失败,请检查你的 safety_settings 配置。如果两处都失败,内容正在被你无法配置的级别阻止。
我应该向 Google 报告误判吗?
是的,报告误判有助于随时间改进系统。使用 AI Studio 中的反馈机制或通过官方 Google AI 开发者渠道提交问题。虽然这不会提供即时解决,但汇总的反馈会影响 Google 在未来更新中如何调整过滤器。
绕过安全过滤器有法律问题吗?
使用 BLOCK_NONE 或提示词工程生成正当内容是可接受的且是预期的开发者行为。这些不是在"绕过"安全措施,而是按设计使用 API。但是,试图生成违反服务条款的内容是不可接受的,无论使用什么技术。安全过滤器的存在是为了防止真正有害的内容,为禁止目的规避它们将违反你的 API 协议。
我可以将这些技术用于商业应用吗?
是的,这里描述的 API 配置和提示词工程技术适合商业使用。关键是生成符合 Google 服务条款的内容。这些技术帮助你更可靠地生成正当内容,这正是商业应用所需要的。