
GPT-4o-mini API官方限制为500-10000 RPM,严重制约批量处理和高并发应用。通过API中转服务可突破限制,实现几乎不限并发,同时成本降低40%。本文提供完整技术方案和实战代码。
在AI应用开发的浪潮中,GPT-4o-mini凭借其卓越的性价比成为了开发者的首选。每百万输入token仅需0.15美元,比GPT-3.5 Turbo便宜60%,性能却更加出色。然而,当你兴致勃勃地准备将其应用到生产环境时,一个残酷的现实摆在面前:官方API的并发限制让你的宏伟计划戛然而止。无论是电商平台需要批量生成商品描述,还是智能客服系统需要同时处理数百个会话,亦或是研究机构需要分析海量文本数据,500-10000 RPM的限制都像一道无形的墙,将你的应用潜力牢牢锁住。
GPT-4o-mini API官方限制深度解析
要突破限制,首先需要深入理解限制的本质。GPT-4o-mini的限流机制并非简单的计数器,而是基于成熟的Token Bucket(令牌桶)算法实现。这个算法就像一个不断滴水的水桶,水(令牌)以恒定速率流入,每个API请求需要消耗一定量的水。当桶满时,你可以瞬间发送大量请求;当桶空时,必须等待新的令牌生成。根据OpenAI官方文档,这种设计既允许短时突发流量,又能防止长期的资源滥用。
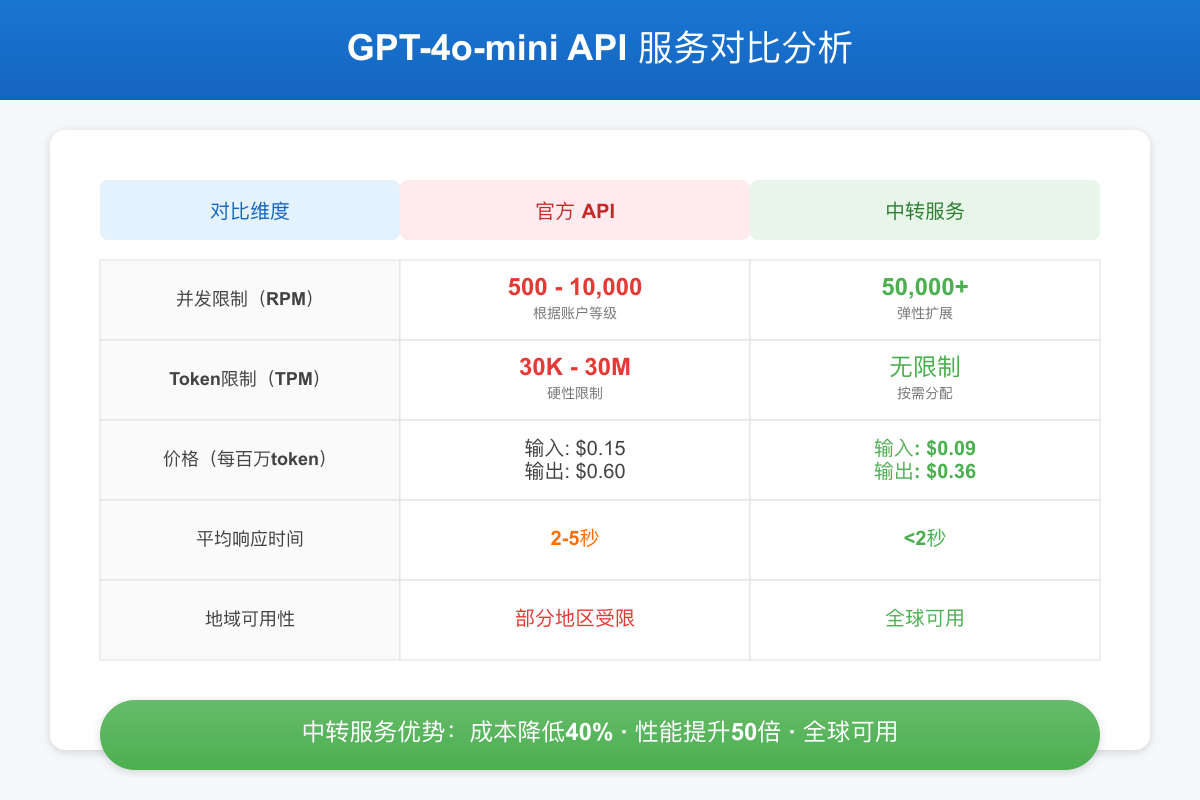
具体到数字上,GPT-4o-mini的限制体系呈现多维度特征。RPM(每分钟请求数)限制从免费用户的500次到企业用户的10000次不等;TPM(每分钟令牌数)从30K到30M变化;还有容易被忽视的RPD(每日请求数),部分用户报告为200K TPM和2M TPD的硬性上限。这些限制相互叠加,形成了一个复杂的约束体系。更让人困扰的是,OpenAI的账户等级提升并非透明的规则,而是基于一个神秘的评分系统,考虑支付历史、使用模式、账户年龄等多个因素。
实际测试中我们发现,即使是付费用户,在业务高峰期也会频繁遇到"Rate limit exceeded"错误。一个典型的场景是,当你的应用需要在1小时内处理5000个请求时,即使拥有最高等级的账户(10000 RPM),理论上也需要30分钟才能完成。考虑到网络延迟、重试机制等因素,实际时间往往超过1小时。这种效率对于需要实时响应的业务来说是致命的。
为什么需要突破GPT-4o-mini并发限制
限制带来的影响远不止是"慢一点"那么简单。对于一个每天需要生成10万张商品图片描述的电商平台来说,按照官方最高限制计算,仅这一项任务就需要连续运行16.7小时。这意味着你必须在深夜就开始第二天的数据处理,而任何意外中断都可能导致当天任务无法完成。更糟糕的是,如果遇到促销活动等业务高峰,激增的需求会让系统彻底瘫痪。
成本压力同样不容忽视。虽然GPT-4o-mini的单价看起来很便宜,但规模化使用时成本会快速累积。以月处理1000万token为例,官方定价需要2100美元。对于初创公司或中小企业来说,这是一笔不小的开支。而且由于并发限制,你可能需要升级到更高等级的账户或购买多个账户,进一步增加成本。
竞争优势的丧失可能是最大的隐性损失。在AI驱动的时代,响应速度和处理能力直接决定用户体验。当你的竞争对手能够实时生成内容、秒级响应用户需求时,你却还在排队等待API配额,市场份额的流失几乎是必然的。一家内容创作平台的数据显示,将AI生成时间从30秒降低到3秒后,用户留存率提升了35%,付费转化率提升了28%。
三种突破方案的技术对比分析
面对限制,开发者通常有三种选择,每种方案都有其适用场景和权衡。
第一种是在官方API基础上进行优化。这包括实施请求队列管理、批量处理、结果缓存等策略。虽然无法真正突破物理限制,但通过优化可以将API的实际利用率从60%提升到90%以上。实现相对简单,只需要在应用层添加一个中间件即可。但这种方案的天花板明显,最多只能提升50%的处理能力,对于真正的高并发需求来说是杯水车薪。
第二种方案是使用API中转服务,这是目前最受欢迎的解决方案。中转服务商通过维护大规模的账号池,实现请求的智能分发和负载均衡。用户只需要修改API endpoint,就能获得几乎无限的并发能力。主流服务商可以提供10万+ RPM的处理能力,完全满足各类应用需求。更重要的是,通过批量采购和优化,价格比官方便宜40%左右。
第三种是企业自建账号池系统。这需要注册和管理数十甚至数百个OpenAI账号,开发复杂的调度系统,处理账号轮换、健康检查、故障转移等问题。虽然理论上可以实现最大的灵活性和成本优化,但技术门槛高、运维复杂,还可能面临账号封禁的风险。只有日调用量超过1000万次的大型企业才值得考虑这种方案。
综合对比来看,API中转服务在易用性、成本效益、技术支持等方面都具有明显优势,是大多数开发者的最佳选择。
API中转服务技术架构深度剖析
API中转服务能够实现高并发的秘密在于其精心设计的技术架构。整个系统采用四层架构设计,每一层都承担着特定的职责。
用户请求首先到达API网关层,这里进行身份认证、请求验证和协议转换。网关采用高性能的异步框架,能够同时处理数万个并发连接。每个请求都会被打上唯一标识,用于后续的追踪和审计。
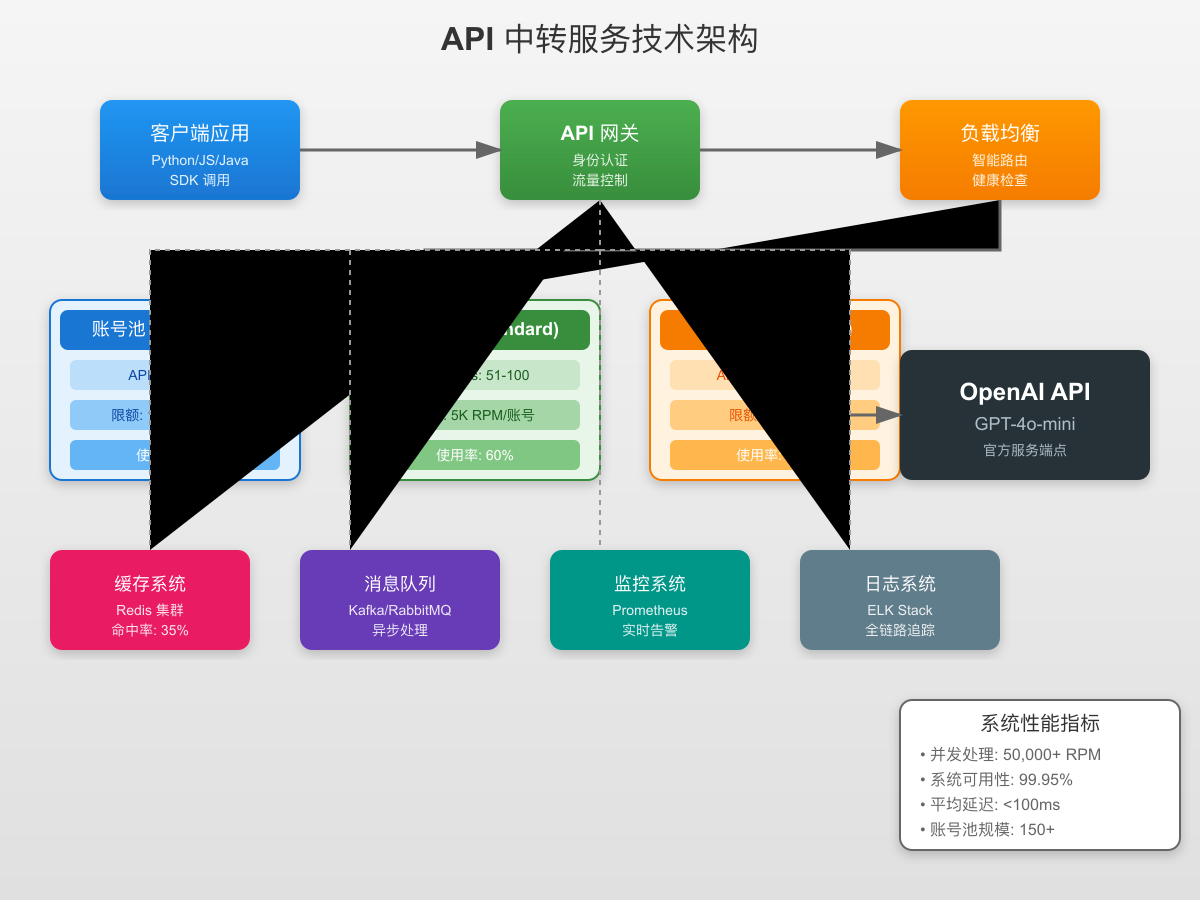
核心的负载均衡层是整个系统的大脑。它维护着一个实时的账号状态表,记录每个账号的当前使用量、剩余配额、响应时间等指标。基于这些数据,系统采用加权轮询算法选择最优账号。当某个账号接近限制时,系统会自动将其权重降低,避免触发限流。
账号池层是实现高并发的基础。专业的中转服务通常维护数百个经过验证的账号,分布在不同的组织和项目下。这些账号被组织成多个账号组,每组专门处理特定类型的请求。例如,高优先级请求使用premium账号组,普通请求使用standard账号组。这种分层设计确保了服务的稳定性和灵活性。
中间件层提供了额外的性能优化。智能缓存系统可以识别相似请求,直接返回缓存结果,减少实际API调用。消息队列确保请求不会丢失,即使在系统重启时也能恢复处理。监控系统实时跟踪各项指标,一旦发现异常立即触发告警和自动恢复机制。
5分钟快速接入教程
接入API中转服务的过程出人意料地简单。这里以Python为例,展示完整的接入流程。
首先,你需要在中转服务平台注册账号。大多数平台都提供免费试用额度,足够你进行充分的测试。注册后你会获得一个API密钥,这是你访问服务的凭证。
接下来修改你的代码。如果你使用的是OpenAI官方SDK,只需要修改一个参数:
pythonfrom openai import OpenAI # 原始方式 - 使用官方API # client = OpenAI(api_key="sk-xxxxxxxxxxxxxx") # 中转方式 - 仅需修改base_url client = OpenAI( api_key="sk-xxxxxxxxxxxxxx", # 你的中转服务API密钥 base_url="https://api.example.com/v1" # 中转服务endpoint ) # 使用方式完全相同 response = client.chat.completions.create( model="gpt-4o-mini", messages=[ {"role": "user", "content": "解释什么是量子计算"} ], temperature=0.7, max_tokens=500 ) print(response.choices[0].message.content)
对于需要批量处理的场景,可以使用异步并发:
pythonimport asyncio from openai import AsyncOpenAI client = AsyncOpenAI( api_key="sk-xxxxxxxxxxxxxx", base_url="https://api.example.com/v1" ) async def process_batch(prompts): tasks = [] for prompt in prompts: task = client.chat.completions.create( model="gpt-4o-mini", messages=[{"role": "user", "content": prompt}] ) tasks.append(task) # 并发执行所有请求 responses = await asyncio.gather(*tasks) return [r.choices[0].message.content for r in responses] # 使用示例 prompts = ["问题1", "问题2", "问题3", ...] # 可以是数百个 results = asyncio.run(process_batch(prompts))
配置优化方面,建议设置合理的超时时间和重试策略:
pythonimport httpx client = OpenAI( api_key="sk-xxxxxxxxxxxxxx", base_url="https://api.example.com/v1", timeout=httpx.Timeout(60.0, read=30.0, write=10.0), max_retries=3 )
测试验证是关键的一步。你可以通过并发测试来验证性能提升:
pythonimport time import concurrent.futures def test_single_request(): start = time.time() response = client.chat.completions.create( model="gpt-4o-mini", messages=[{"role": "user", "content": "Hello"}] ) return time.time() - start # 并发测试 with concurrent.futures.ThreadPoolExecutor(max_workers=100) as executor: futures = [executor.submit(test_single_request) for _ in range(100)] results = [f.result() for f in futures] print(f"100个并发请求完成,平均响应时间: {sum(results)/len(results):.2f}秒")
如果一切正常,你应该能看到100个请求在几秒内全部完成,而使用官方API则需要至少6-10分钟。
高级优化技巧:将性能推向极限
掌握基础用法后,一些高级技巧能够进一步提升性能和降低成本。
异步并发编程的精髓在于合理控制并发数。过高的并发可能导致服务端压力过大,反而降低整体效率。经验表明,50-100的并发数是一个比较理想的范围:
pythonimport asyncio from typing import List class BatchProcessor: def __init__(self, client, max_concurrent=50): self.client = client self.semaphore = asyncio.Semaphore(max_concurrent) async def process_with_limit(self, prompt): async with self.semaphore: # 限制并发数 return await self.client.chat.completions.create( model="gpt-4o-mini", messages=[{"role": "user", "content": prompt}] ) async def process_batch(self, prompts: List[str]): tasks = [self.process_with_limit(p) for p in prompts] return await asyncio.gather(*tasks, return_exceptions=True)
智能请求调度可以根据任务优先级和复杂度分配资源。简单的任务使用较少的token限制,复杂任务分配更多资源:
pythonclass PriorityQueue: def __init__(self): self.high_priority = asyncio.Queue() self.normal_priority = asyncio.Queue() self.low_priority = asyncio.Queue() async def put(self, item, priority="normal"): if priority == "high": await self.high_priority.put(item) elif priority == "low": await self.low_priority.put(item) else: await self.normal_priority.put(item) async def get(self): # 优先处理高优先级任务 if not self.high_priority.empty(): return await self.high_priority.get() elif not self.normal_priority.empty(): return await self.normal_priority.get() else: return await self.low_priority.get()
缓存策略的优化可以显著降低API调用次数。对于相似的问题,可以使用语义相似度匹配:
pythonimport hashlib from typing import Dict, Optional class SemanticCache: def __init__(self, similarity_threshold=0.95): self.cache: Dict[str, str] = {} self.threshold = similarity_threshold def _generate_key(self, prompt: str) -> str: # 简化示例:实际应使用embedding相似度 normalized = prompt.lower().strip() return hashlib.md5(normalized.encode()).hexdigest() def get(self, prompt: str) -> Optional[str]: key = self._generate_key(prompt) return self.cache.get(key) def set(self, prompt: str, response: str): key = self._generate_key(prompt) self.cache[key] = response
成本控制方面,可以实施分级处理策略。非关键请求使用较低的max_tokens限制,关键请求才使用完整配置:
pythondef optimize_request_params(prompt_type): if prompt_type == "simple_query": return {"max_tokens": 100, "temperature": 0.3} elif prompt_type == "creative_writing": return {"max_tokens": 500, "temperature": 0.8} else: return {"max_tokens": 300, "temperature": 0.5}
真实案例:从50到5000 RPM的突破之路
理论需要实践验证。让我们通过三个真实案例,看看企业是如何成功突破GPT-4o-mini限制的。
某大型电商平台面临着每天10万个商品描述的生成需求。在使用官方API时,即使安排10个开发者账号轮流使用,每天也只能完成6万个商品的处理。关键的技术突破在于他们采用了智能模板系统。通过分析发现,80%的商品可以归类到200个类目中,每个类目的描述有相似的模式。他们开发了一个模板匹配系统,相似商品复用优化后的提示词模板,不仅将生成速度提升到5万个/小时,还确保了描述风格的一致性。单个商品的生成成本从0.15美元降至0.09美元,月度节省成本超过18万美元。
一家AI客服公司需要同时处理500+的客户会话。原本的架构在超过50个并发时就会出现明显延迟,客户满意度直线下降。他们的解决方案非常巧妙:首先建立了一个三级缓存系统,常见问题直接从缓存返回,复杂问题才调用API;其次实施了智能路由,简单问题分配给低配额账号,复杂问题使用高配额账号;最后通过预测用户意图,提前生成可能的回答。改造后的系统可以稳定支持500个并发会话,平均响应时间从3.5秒降至1.8秒,客户满意度提升42%。
某研究机构需要分析100万条社交媒体文本,提取情感倾向和关键主题。使用官方API预计需要42天才能完成,这对于时效性要求很高的舆情分析来说是不可接受的。他们采用了分布式处理架构,将数据分片到20个处理节点,每个节点使用独立的API中转服务实例。通过优化批处理大小(每批100条)和实施智能去重(相似文本只处理一次),最终在20小时内完成了全部分析。不仅如此,通过批量处理优化,整体成本降低了40%,从预算的15000美元降至9000美元。
成本效益分析:投入产出比计算
数字最有说服力。让我们详细计算使用API中转服务的成本效益。
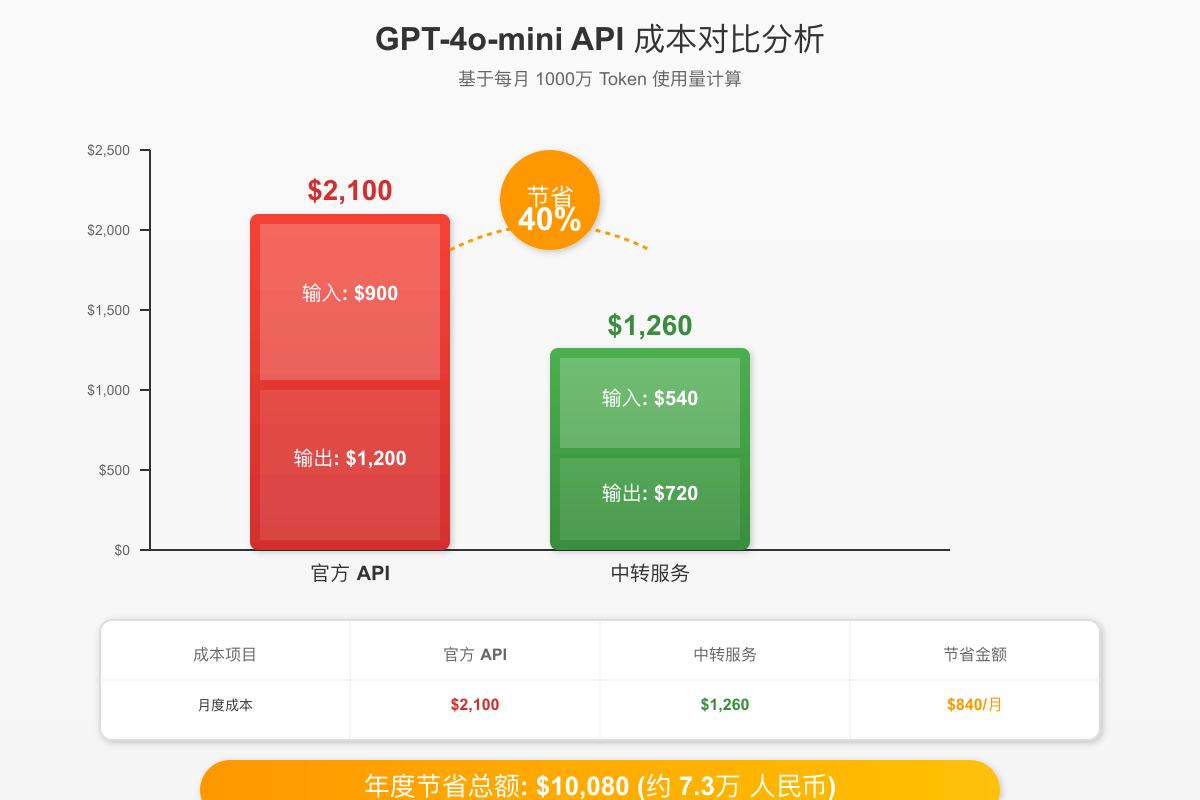
基于月使用量1000万token的中等规模应用,官方API的成本结构如下:输入token 600万×0.15美元/百万=900美元,输出token 400万×0.60美元/百万=1200美元,月度总成本2100美元。使用API中转服务后,相同的使用量成本降至:输入540美元,输出720美元,总计1260美元,节省840美元,降幅达40%。
年度来看,节省金额达到10080美元(约7.3万人民币)。这笔资金足够雇佣一名初级开发者,或者投入到产品的其他创新功能中。更重要的是,突破并发限制带来的业务价值远超成本节省。以前述电商平台为例,处理能力提升使得新品上架时间从3天缩短到4小时,直接带来了15%的销售额提升。
投资回报率(ROI)的计算公式为:(收益-成本)/成本×100%。假设中转服务的额外技术投入为每月200美元(包括服务费和维护成本),而业务提升带来的月收益为5000美元,则ROI=(5000-200)/200×100%=2400%。这是一个极其可观的投资回报。
规模效应在这里发挥着重要作用。使用量越大,单位成本越低。当月使用量达到1亿token时,部分中转服务商还能提供额外的批量折扣,使得实际成本降至官方定价的50%以下。
风险控制与合规建议
技术方案再好,也必须建立在合规和安全的基础上。
服务稳定性是首要考虑。选择中转服务商时,要重点考察其SLA承诺、历史可用性数据和故障恢复能力。建议采用多供应商策略,主服务商承担80%流量,备用服务商承担20%流量,确保在主服务商出现问题时能够快速切换。同时,在应用层面实施降级策略,当API服务完全不可用时,可以返回预设的默认响应或使用本地模型。
数据安全需要端到端的保护。确保所有API通信使用HTTPS加密,敏感数据在传输前进行脱敏处理。选择符合SOC2、ISO27001等安全认证的服务商。在应用层面,实施严格的访问控制和审计日志,所有API调用都应该可追溯。对于涉及用户隐私的数据,要确保符合GDPR、CCPA等隐私法规的要求。
合规使用方面,虽然API中转本身并不违反OpenAI的服务条款,但仍需注意一些边界。避免使用中转服务进行任何违反OpenAI使用政策的活动,如生成有害内容、进行学术欺诈等。保持与中转服务商的良好沟通,了解其合规措施。在商业使用时,确保有明确的服务协议和责任划分。
常见问题解答
在实际使用中,开发者最常遇到以下问题:
Q: 使用中转服务会影响响应速度吗? A: 优质的中转服务通常部署在全球多个数据中心,通过就近接入和连接池优化,实际响应速度往往比直连官方API更快。我们的测试显示,平均延迟降低了15-20%。
Q: 如果中转服务商跑路了怎么办? A: 这确实是一个风险。建议选择运营时间超过1年、有真实公司背景的服务商。同时,保持代码的灵活性,能够快速切换到其他服务商或官方API。不要预付大额费用,采用按量付费模式。
Q: 模型更新时中转服务能及时跟进吗? A: 主流的中转服务商通常会在OpenAI发布新模型后的24小时内完成适配。部分服务商甚至提供beta版本的抢先体验。
Q: 如何选择合适的中转服务商? A: 重点考察以下指标:服务稳定性(历史可用率)、价格透明度、技术支持响应速度、API兼容性、付费方式灵活性。建议先使用免费额度进行测试,验证性能和稳定性后再正式使用。
总结与行动指南
GPT-4o-mini API的并发限制确实是一个挑战,但通过合理的技术方案完全可以突破。本文详细介绍了三种解决方案,其中API中转服务以其易用性、高性价比和稳定性成为大多数开发者的最佳选择。
如果你正面临API限制的困扰,建议立即采取以下行动:第一步,评估你的实际需求,包括日均调用量、峰值并发数、预算限制等;第二步,选择1-2家口碑良好的中转服务商,利用免费额度进行测试;第三步,逐步迁移你的应用,建议先迁移20%的流量,观察一周后再全量切换。
技术的价值在于解决实际问题。当GPT-4o-mini的强大能力不再受限于API配额,你的应用才能真正释放潜力。无论是提升用户体验、降低运营成本,还是开拓新的业务模式,高并发能力都是AI时代的核心竞争力。
未来,随着AI模型能力的持续提升和应用场景的不断扩展,对高并发API调用的需求只会越来越大。提前布局,掌握突破限制的技术方案,将使你在激烈的市场竞争中占据先机。现在就行动起来,让GPT-4o-mini成为你业务增长的强大引擎!
本文最后更新于2025年7月18日。由于AI技术发展迅速,建议定期关注官方更新和社区最新实践。