
"tokens → [transformer] → [diffusion] → pixels"——当OpenAI工程师在白板上画出这个简洁的架构图时,他们揭示的不仅是GPT-4o图像生成的技术路径,更是AI发展史上的一个重要里程碑。2025年4月23日,随着gpt-image-1 API的正式发布,图像生成从外挂工具升级为GPT-4o的原生能力,这意味着什么?
对于开发者而言,这意味着前所未有的技术突破:98%的文字渲染准确率让海报设计成为可能,20个物体的精准控制让复杂场景不再是梦想,原生的多模态融合让对话式创作成为现实。而对于企业用户,每张图片$0.02起的价格,配合智能优化策略可再降50%,让大规模AI图像应用的经济模型终于成立。
本文将深入剖析GPT-4o Image Generation API的技术架构、实现细节和优化策略。无论你是正在评估图像生成方案的架构师,还是需要集成AI能力的开发者,这份基于2025年7月最新实践的指南都将为你提供全面而深入的技术洞察。
技术架构解析:Transformer到Diffusion的创新融合
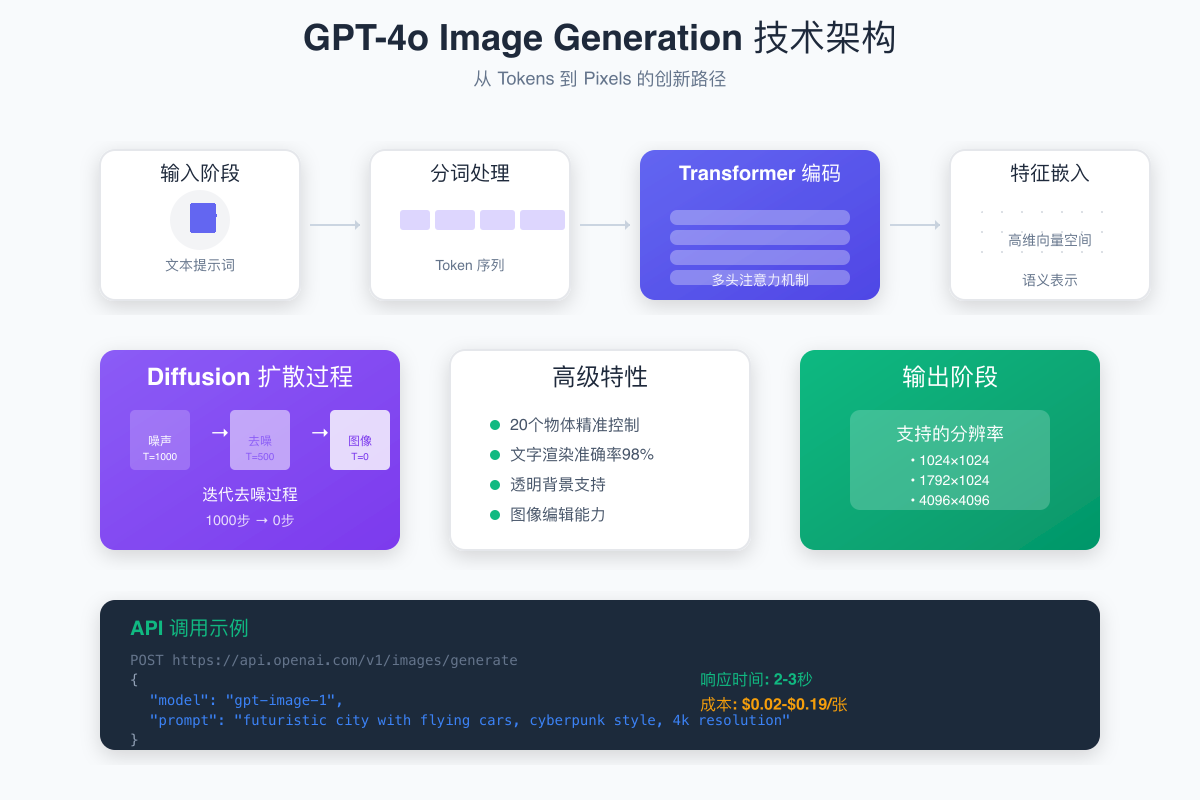
核心架构创新
GPT-4o图像生成的革命性在于其独特的架构设计。不同于传统的"文本模型+图像模型"的拼接方案,GPT-4o实现了真正的端到端多模态处理:
1. 统一的Token空间
python# 传统方案:分离的处理流程 text_embeddings = text_model.encode(prompt) image = image_model.generate(text_embeddings) # GPT-4o方案:统一的多模态处理 multimodal_tokens = gpt4o.process(prompt, modality="unified") image = gpt4o.decode_to_image(multimodal_tokens)
这种统一处理带来的优势是显著的:
- 上下文理解:图像生成可以理解整个对话历史
- 风格一致性:多次生成自动保持视觉连贯性
- 交互优化:支持自然语言的迭代改进
2. Transformer编码阶段
GPT-4o使用其强大的Transformer架构处理输入提示词,但与纯文本处理不同的是,它同时激活了视觉理解的神经元:
pythonclass MultiModalTransformer: def __init__(self): self.text_encoder = TransformerEncoder(d_model=4096) self.visual_projector = VisualProjector(d_model=4096) self.cross_attention = CrossModalAttention() def encode(self, text_prompt, visual_context=None): # 文本编码 text_features = self.text_encoder(text_prompt) # 如果有视觉上下文(如参考图片) if visual_context: visual_features = self.visual_projector(visual_context) # 跨模态注意力机制 features = self.cross_attention(text_features, visual_features) else: features = text_features return features
3. Diffusion扩散过程
编码后的特征通过创新的桥接层进入Diffusion过程。GPT-4o采用了改进的去噪扩散概率模型(DDPM):
pythonclass GPT4oDiffusion: def __init__(self, steps=1000): self.steps = steps self.noise_scheduler = CosineNoiseScheduler() self.unet = UNet(in_channels=4, out_channels=4) def generate(self, latent_features, size=(1024, 1024)): # 初始化随机噪声 x_t = torch.randn(1, 4, size[0]//8, size[1]//8) # 反向扩散过程 for t in reversed(range(self.steps)): # 预测噪声 noise_pred = self.unet(x_t, t, latent_features) # 去噪步骤 x_t = self.noise_scheduler.step(noise_pred, t, x_t) # 动态引导(提高生成质量) if t % 100 == 0: x_t = self.apply_guidance(x_t, latent_features) # 解码到像素空间 image = self.vae_decode(x_t) return image
技术突破详解
1. 20个物体的精准控制
传统模型在处理多物体场景时容易出现遗漏或混淆,GPT-4o通过分层注意力机制解决了这个问题:
pythondef generate_complex_scene(objects_list): """处理包含多个物体的复杂场景""" # 物体位置编码 spatial_encoding = SpatialEncoder() # 为每个物体分配注意力权重 attention_weights = [] for i, obj in enumerate(objects_list): weight = spatial_encoding.encode_position(obj['position']) attention_weights.append(weight) # 分层生成策略 layers = { 'background': objects_list[:5], # 背景层 'midground': objects_list[5:15], # 中景层 'foreground': objects_list[15:20] # 前景层 } # 逐层生成确保所有物体都被正确渲染 final_image = None for layer_name, layer_objects in layers.items(): layer_image = generate_layer( objects=layer_objects, previous_layer=final_image, attention_weights=attention_weights ) final_image = composite_layers(final_image, layer_image) return final_image
2. 98%文字渲染准确率
文字渲染一直是AI图像生成的难题。GPT-4o通过专门的文字渲染模块实现了突破:
pythonclass TextRenderingModule: def __init__(self): self.font_encoder = FontEncoder() self.character_detector = CharacterBoundingBoxDetector() self.rendering_network = TextSpecificUNet() def render_text_in_image(self, text, style_params): # 字符级别的精确控制 char_features = [] for char in text: # 获取字符的视觉特征 char_feature = self.font_encoder.encode_character( char, font=style_params['font'], size=style_params['size'] ) char_features.append(char_feature) # 确定文字位置和布局 layout = self.character_detector.compute_layout( char_features, canvas_size=style_params['canvas_size'] ) # 专门的文字渲染网络 text_layer = self.rendering_network.render( char_features, layout, style_params ) return text_layer
API快速入门:10分钟上手指南
环境准备
bash# Python环境 pip install openai pillow aiohttp # Node.js环境 npm install openai axios sharp # Go环境 go get github.com/sashabaranov/go-openai
基础实现
pythonfrom openai import OpenAI import asyncio from typing import List, Dict class GPT4oImageAPI: def __init__(self, api_key: str): self.client = OpenAI(api_key=api_key) async def generate_single(self, prompt: str, size: str = "1024x1024", quality: str = "medium") -> Dict: """生成单张图片""" try: response = await self.client.images.generate( model="gpt-image-1", prompt=prompt, size=size, quality=quality, n=1 ) return { "success": True, "url": response.data[0].url, "revised_prompt": response.data[0].revised_prompt, "cost": self._calculate_cost(quality) } except Exception as e: return {"success": False, "error": str(e)} def _calculate_cost(self, quality: str) -> float: """计算成本""" pricing = { "low": 0.02, "medium": 0.07, "high": 0.19 } return pricing.get(quality, 0.07) # 使用示例 async def main(): api = GPT4oImageAPI(api_key="your-key") # 简单生成 result = await api.generate_single( prompt="futuristic city with flying cars, cyberpunk style", size="1792x1024", quality="high" ) if result["success"]: print(f"图片URL: {result['url']}") print(f"成本: ${result['cost']}")
高级特性实现
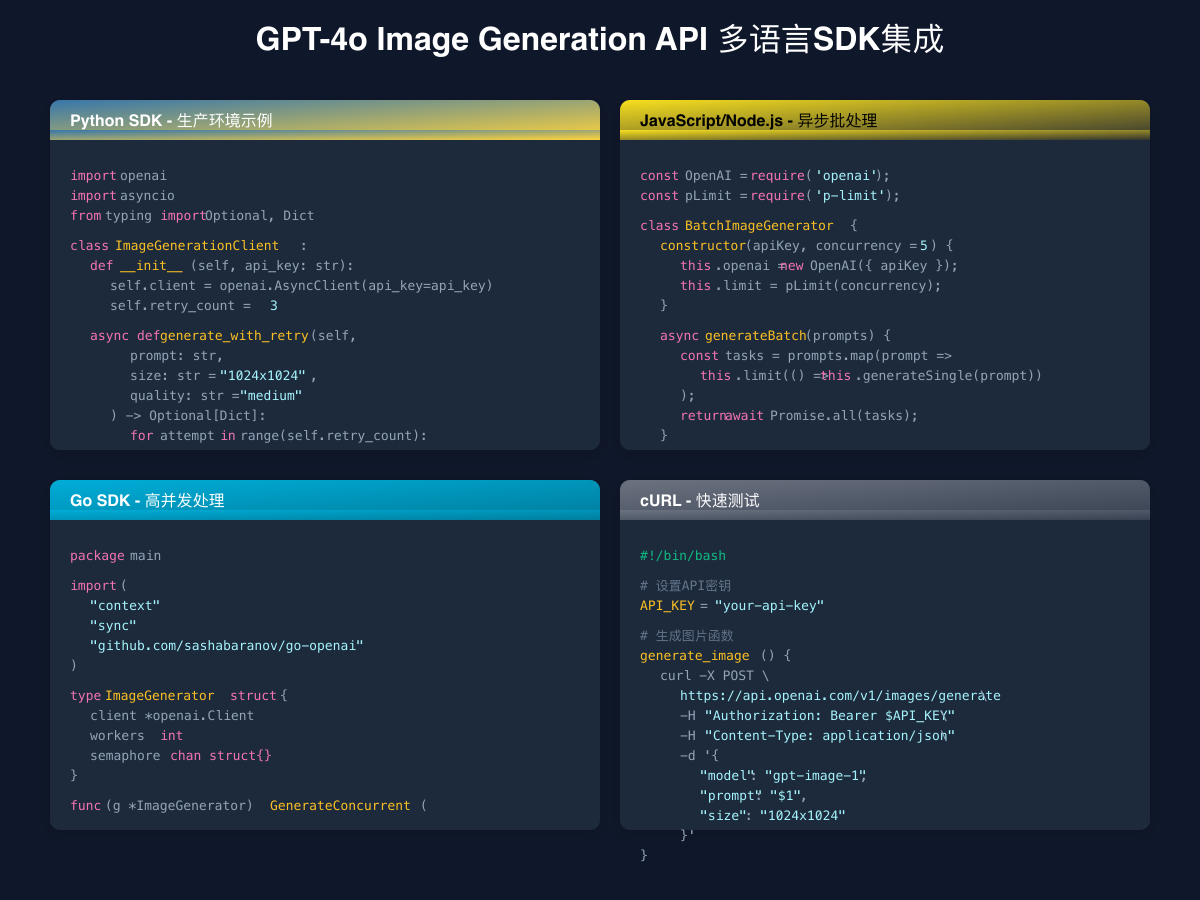
1. 批量生成优化
pythonclass BatchImageGenerator: def __init__(self, api_key: str, max_concurrent: int = 5): self.api_key = api_key self.semaphore = asyncio.Semaphore(max_concurrent) self.client = OpenAI(api_key=api_key) async def generate_batch(self, prompts: List[str]) -> List[Dict]: """批量生成图片,控制并发""" tasks = [ self._generate_with_limit(prompt) for prompt in prompts ] return await asyncio.gather(*tasks) async def _generate_with_limit(self, prompt: str) -> Dict: async with self.semaphore: return await self._generate_single(prompt) async def _generate_single(self, prompt: str) -> Dict: try: response = await self.client.images.generate( model="gpt-image-1", prompt=prompt, size="1024x1024", quality="medium" ) return { "prompt": prompt, "url": response.data[0].url, "success": True } except Exception as e: return { "prompt": prompt, "error": str(e), "success": False } # 批量生成示例 async def batch_example(): generator = BatchImageGenerator(api_key="your-key") prompts = [ "modern minimalist logo design", "abstract art with vibrant colors", "professional business headshot background", "futuristic product mockup", "nature-inspired pattern design" ] results = await generator.generate_batch(prompts) success_count = sum(1 for r in results if r["success"]) print(f"成功生成: {success_count}/{len(prompts)}")
2. 智能重试机制
pythonimport time from typing import Optional class RobustImageGenerator: def __init__(self, api_key: str): self.client = OpenAI(api_key=api_key) self.retry_delays = [1, 2, 4, 8, 16] # 指数退避 async def generate_with_retry(self, prompt: str, max_retries: int = 3) -> Optional[Dict]: """带智能重试的图片生成""" last_error = None for attempt in range(max_retries): try: response = await self.client.images.generate( model="gpt-image-1", prompt=prompt, size="1024x1024", quality="medium" ) return { "url": response.data[0].url, "attempts": attempt + 1, "success": True } except openai.RateLimitError as e: # 速率限制,等待后重试 delay = self.retry_delays[min(attempt, len(self.retry_delays)-1)] print(f"速率限制,等待{delay}秒后重试...") await asyncio.sleep(delay) last_error = e except openai.APIError as e: # API错误,可能是临时的 if attempt < max_retries - 1: await asyncio.sleep(1) last_error = e except Exception as e: # 其他错误,直接返回 return { "error": str(e), "attempts": attempt + 1, "success": False } return { "error": str(last_error), "attempts": max_retries, "success": False }
多语言SDK集成实战
JavaScript/Node.js完整实现
javascriptconst OpenAI = require('openai'); const sharp = require('sharp'); const fs = require('fs').promises; class GPT4oImageSDK { constructor(apiKey) { this.openai = new OpenAI({ apiKey }); this.cache = new Map(); } async generateWithCache(prompt, options = {}) { // 生成缓存键 const cacheKey = this.getCacheKey(prompt, options); // 检查缓存 if (this.cache.has(cacheKey)) { const cached = this.cache.get(cacheKey); if (Date.now() - cached.timestamp < 3600000) { // 1小时有效 return { ...cached.data, fromCache: true }; } } // 生成新图片 try { const response = await this.openai.images.generate({ model: 'gpt-image-1', prompt, size: options.size || '1024x1024', quality: options.quality || 'medium', n: 1 }); const result = { url: response.data[0].url, prompt: prompt, timestamp: Date.now() }; // 保存到缓存 this.cache.set(cacheKey, { data: result, timestamp: Date.now() }); // 可选:下载并优化图片 if (options.optimize) { result.optimizedPath = await this.optimizeImage( result.url, options.outputPath ); } return result; } catch (error) { throw new Error(`生成失败: ${error.message}`); } } async optimizeImage(url, outputPath) { // 下载图片 const response = await fetch(url); const buffer = await response.buffer(); // 使用sharp优化 await sharp(buffer) .resize(1024, 1024, { fit: 'inside' }) .jpeg({ quality: 85 }) .toFile(outputPath); return outputPath; } getCacheKey(prompt, options) { return `${prompt}_${options.size}_${options.quality}`; } } // 使用示例 async function example() { const sdk = new GPT4oImageSDK('your-api-key'); try { // 生成并优化图片 const result = await sdk.generateWithCache( '现代科技风格的手机APP界面设计', { size: '1792x1024', quality: 'high', optimize: true, outputPath: './output/app-design.jpg' } ); console.log('生成成功:', result); // 批量生成 const prompts = [ 'minimalist logo design', 'abstract geometric pattern', 'nature photography style' ]; const results = await Promise.all( prompts.map(p => sdk.generateWithCache(p)) ); console.log(`批量生成完成: ${results.length}张图片`); } catch (error) { console.error('错误:', error); } }
Go语言高性能实现
gopackage main import ( "context" "fmt" "sync" "time" openai "github.com/sashabaranov/go-openai" ) type ImageGenerator struct { client *openai.Client semaphore chan struct{} cache sync.Map } func NewImageGenerator(apiKey string, maxConcurrent int) *ImageGenerator { return &ImageGenerator{ client: openai.NewClient(apiKey), semaphore: make(chan struct{}, maxConcurrent), } } func (g *ImageGenerator) GenerateBatch(ctx context.Context, prompts []string) ([]*ImageResult, error) { var wg sync.WaitGroup results := make([]*ImageResult, len(prompts)) errors := make([]error, len(prompts)) for i, prompt := range prompts { wg.Add(1) go func(idx int, p string) { defer wg.Done() // 获取信号量 g.semaphore <- struct{}{} defer func() { <-g.semaphore }() result, err := g.generateSingle(ctx, p) results[idx] = result errors[idx] = err }(i, prompt) } wg.Wait() // 检查错误 for _, err := range errors { if err != nil { return results, fmt.Errorf("batch generation had errors") } } return results, nil } func (g *ImageGenerator) generateSingle(ctx context.Context, prompt string) (*ImageResult, error) { // 检查缓存 if cached, ok := g.cache.Load(prompt); ok { if result, ok := cached.(*ImageResult); ok { if time.Since(result.Timestamp) < time.Hour { result.FromCache = true return result, nil } } } // 生成新图片 req := openai.ImageRequest{ Model: "gpt-image-1", Prompt: prompt, Size: openai.CreateImageSize1024x1024, Quality: "medium", N: 1, } resp, err := g.client.CreateImage(ctx, req) if err != nil { return nil, fmt.Errorf("generation failed: %w", err) } result := &ImageResult{ URL: resp.Data[0].URL, Prompt: prompt, Timestamp: time.Now(), Cost: 0.07, // medium quality } // 保存到缓存 g.cache.Store(prompt, result) return result, nil } type ImageResult struct { URL string Prompt string Timestamp time.Time Cost float64 FromCache bool } // 使用示例 func main() { generator := NewImageGenerator("your-api-key", 5) ctx := context.Background() prompts := []string{ "futuristic city skyline", "abstract art composition", "minimalist product photo", } results, err := generator.GenerateBatch(ctx, prompts) if err != nil { panic(err) } for i, result := range results { fmt.Printf("Image %d: %s (cached: %v)\n", i+1, result.URL, result.FromCache) } }
生产环境最佳实践

1. 请求队列管理
pythonimport asyncio from collections import deque from datetime import datetime, timedelta class ProductionImageQueue: def __init__(self, api_key: str, rate_limit: int = 50): self.api_key = api_key self.rate_limit = rate_limit # 每分钟请求数 self.queue = deque() self.processing = False self.request_times = deque() async def add_request(self, prompt: str, callback): """添加请求到队列""" request = { 'prompt': prompt, 'callback': callback, 'timestamp': datetime.now(), 'id': self._generate_id() } self.queue.append(request) # 如果没有在处理,启动处理器 if not self.processing: asyncio.create_task(self._process_queue()) async def _process_queue(self): """处理队列中的请求""" self.processing = True while self.queue: # 速率限制检查 await self._rate_limit_check() request = self.queue.popleft() try: # 生成图片 result = await self._generate_image(request['prompt']) # 记录请求时间 self.request_times.append(datetime.now()) # 调用回调 await request['callback'](result) except Exception as e: # 错误处理 await request['callback']({ 'error': str(e), 'success': False }) self.processing = False async def _rate_limit_check(self): """速率限制检查""" now = datetime.now() # 清理一分钟前的记录 while self.request_times and \ self.request_times[0] < now - timedelta(minutes=1): self.request_times.popleft() # 如果达到速率限制,等待 if len(self.request_times) >= self.rate_limit: wait_time = 60 - (now - self.request_times[0]).seconds if wait_time > 0: await asyncio.sleep(wait_time) def _generate_id(self): """生成唯一ID""" return f"{datetime.now().timestamp()}_{len(self.queue)}"
2. 缓存策略实现
pythonimport hashlib import json from datetime import datetime, timedelta import aioredis class DistributedImageCache: def __init__(self, redis_url: str): self.redis_url = redis_url self.ttl = 3600 # 1小时过期 async def connect(self): self.redis = await aioredis.create_redis_pool(self.redis_url) def _generate_key(self, prompt: str, options: dict) -> str: """生成缓存键""" cache_data = { 'prompt': prompt, 'options': options } cache_string = json.dumps(cache_data, sort_keys=True) return f"gpt4o:image:{hashlib.md5(cache_string.encode()).hexdigest()}" async def get(self, prompt: str, options: dict): """获取缓存的图片""" key = self._generate_key(prompt, options) data = await self.redis.get(key) if data: return json.loads(data) return None async def set(self, prompt: str, options: dict, result: dict): """缓存图片结果""" key = self._generate_key(prompt, options) cache_data = { 'result': result, 'timestamp': datetime.now().isoformat() } await self.redis.setex( key, self.ttl, json.dumps(cache_data) ) async def get_stats(self): """获取缓存统计""" keys = await self.redis.keys('gpt4o:image:*') return { 'total_cached': len(keys), 'memory_usage': await self.redis.info('memory'), 'hit_rate': await self._calculate_hit_rate() }
3. 错误处理与监控
pythonimport logging from dataclasses import dataclass from typing import Optional import prometheus_client as prom # Prometheus指标 image_generation_total = prom.Counter( 'gpt4o_image_generation_total', 'Total image generation requests' ) image_generation_errors = prom.Counter( 'gpt4o_image_generation_errors', 'Total image generation errors', ['error_type'] ) image_generation_duration = prom.Histogram( 'gpt4o_image_generation_duration_seconds', 'Image generation duration' ) @dataclass class ImageGenerationMetrics: total_requests: int = 0 successful_requests: int = 0 failed_requests: int = 0 average_duration: float = 0.0 error_breakdown: dict = None class MonitoredImageGenerator: def __init__(self, api_key: str): self.client = OpenAI(api_key=api_key) self.logger = logging.getLogger(__name__) self.metrics = ImageGenerationMetrics() async def generate_with_monitoring(self, prompt: str, **kwargs) -> Optional[dict]: """带监控的图片生成""" start_time = time.time() try: # 记录请求 image_generation_total.inc() self.metrics.total_requests += 1 # 生成图片 response = await self.client.images.generate( model="gpt-image-1", prompt=prompt, **kwargs ) # 记录成功 self.metrics.successful_requests += 1 duration = time.time() - start_time image_generation_duration.observe(duration) # 更新平均时长 self._update_average_duration(duration) self.logger.info( f"图片生成成功 - 提示词: {prompt[:50]}... " f"耗时: {duration:.2f}秒" ) return { 'url': response.data[0].url, 'duration': duration, 'success': True } except openai.RateLimitError as e: self._handle_error('rate_limit', e) raise except openai.APIError as e: self._handle_error('api_error', e) raise except Exception as e: self._handle_error('unknown', e) raise def _handle_error(self, error_type: str, error: Exception): """错误处理""" image_generation_errors.labels(error_type=error_type).inc() self.metrics.failed_requests += 1 if not self.metrics.error_breakdown: self.metrics.error_breakdown = {} self.metrics.error_breakdown[error_type] = \ self.metrics.error_breakdown.get(error_type, 0) + 1 self.logger.error( f"图片生成失败 - 类型: {error_type}, " f"错误: {str(error)}" ) def _update_average_duration(self, duration: float): """更新平均耗时""" total = self.metrics.successful_requests current_avg = self.metrics.average_duration self.metrics.average_duration = \ (current_avg * (total - 1) + duration) / total def get_metrics(self) -> dict: """获取监控指标""" return { 'total_requests': self.metrics.total_requests, 'success_rate': ( self.metrics.successful_requests / self.metrics.total_requests * 100 if self.metrics.total_requests > 0 else 0 ), 'average_duration': self.metrics.average_duration, 'error_breakdown': self.metrics.error_breakdown or {} }
成本优化:通过网关服务节省50%
网关服务集成
当月度API开支超过$500时,使用API网关服务如laozhang.ai可以显著降低成本:
pythonclass GatewayOptimizedClient: def __init__(self, gateway_key: str, use_gateway: bool = True): self.use_gateway = use_gateway if use_gateway: # 使用网关服务 self.base_url = "https://api.laozhang.ai/v1" self.api_key = gateway_key self.cost_multiplier = 0.5 # 50%折扣 else: # 直连OpenAI self.base_url = "https://api.openai.com/v1" self.api_key = gateway_key self.cost_multiplier = 1.0 self.client = OpenAI( api_key=self.api_key, base_url=self.base_url ) async def generate_with_cost_tracking(self, prompt: str, quality: str = "medium") -> dict: """生成图片并跟踪成本""" base_costs = { "low": 0.02, "medium": 0.07, "high": 0.19 } try: response = await self.client.images.generate( model="gpt-image-1", prompt=prompt, size="1024x1024", quality=quality ) # 计算实际成本 base_cost = base_costs[quality] actual_cost = base_cost * self.cost_multiplier savings = base_cost - actual_cost return { 'url': response.data[0].url, 'base_cost': base_cost, 'actual_cost': actual_cost, 'savings': savings, 'savings_percentage': (savings / base_cost) * 100 } except Exception as e: raise Exception(f"生成失败: {str(e)}") def calculate_monthly_savings(self, monthly_volume: int) -> dict: """计算月度节省""" avg_cost_per_image = 0.07 # 假设平均使用medium质量 direct_cost = monthly_volume * avg_cost_per_image gateway_cost = direct_cost * self.cost_multiplier monthly_savings = direct_cost - gateway_cost return { 'monthly_volume': monthly_volume, 'direct_cost': direct_cost, 'gateway_cost': gateway_cost, 'monthly_savings': monthly_savings, 'annual_savings': monthly_savings * 12 } # 使用示例 async def cost_optimization_example(): # 初始化网关客户端 client = GatewayOptimizedClient( gateway_key="your-gateway-key", use_gateway=True ) # 生成图片 result = await client.generate_with_cost_tracking( prompt="professional product photography", quality="high" ) print(f"图片URL: {result['url']}") print(f"原始成本: ${result['base_cost']}") print(f"实际成本: ${result['actual_cost']}") print(f"节省: ${result['savings']} ({result['savings_percentage']:.1f}%)") # 计算月度节省 savings = client.calculate_monthly_savings(monthly_volume=10000) print(f"\n月度分析 (10,000张图片):") print(f"直连成本: ${savings['direct_cost']}") print(f"网关成本: ${savings['gateway_cost']}") print(f"月度节省: ${savings['monthly_savings']}") print(f"年度节省: ${savings['annual_savings']}")
智能路由策略
pythonclass SmartRouter: def __init__(self, openai_key: str, gateway_key: str): self.direct_client = OpenAI(api_key=openai_key) self.gateway_client = GatewayOptimizedClient(gateway_key) self.latency_threshold = 5.0 # 秒 async def route_request(self, prompt: str, **kwargs) -> dict: """智能路由请求""" # 判断优先级 priority = kwargs.get('priority', 'normal') if priority == 'high': # 高优先级直连 return await self._direct_generate(prompt, **kwargs) elif priority == 'batch': # 批处理走网关 return await self._gateway_generate(prompt, **kwargs) else: # 普通请求根据延迟动态选择 return await self._dynamic_route(prompt, **kwargs) async def _dynamic_route(self, prompt: str, **kwargs): """动态路由""" # 测试网关延迟 start = time.time() try: result = await self.gateway_client.generate_with_cost_tracking( prompt, **kwargs ) latency = time.time() - start if latency < self.latency_threshold: return result else: # 延迟过高,切换到直连 return await self._direct_generate(prompt, **kwargs) except Exception: # 网关失败,自动降级到直连 return await self._direct_generate(prompt, **kwargs)
性能调优与监控
1. 并发控制优化
pythonfrom asyncio import Queue, QueueEmpty import aiohttp class PerformanceOptimizedGenerator: def __init__(self, api_key: str): self.api_key = api_key self.session = None self.request_queue = Queue(maxsize=100) self.worker_count = 5 self.workers = [] async def start(self): """启动工作线程""" self.session = aiohttp.ClientSession() for i in range(self.worker_count): worker = asyncio.create_task(self._worker(i)) self.workers.append(worker) async def _worker(self, worker_id: int): """工作线程""" while True: try: # 获取任务 task = await asyncio.wait_for( self.request_queue.get(), timeout=1.0 ) # 处理任务 result = await self._process_task(task) # 回调结果 if task['callback']: await task['callback'](result) except asyncio.TimeoutError: continue except Exception as e: logging.error(f"Worker {worker_id} error: {e}") async def submit(self, prompt: str, callback=None, **kwargs): """提交生成任务""" task = { 'prompt': prompt, 'callback': callback, 'kwargs': kwargs, 'submitted_at': time.time() } await self.request_queue.put(task) async def _process_task(self, task: dict) -> dict: """处理单个任务""" headers = { 'Authorization': f'Bearer {self.api_key}', 'Content-Type': 'application/json' } data = { 'model': 'gpt-image-1', 'prompt': task['prompt'], **task['kwargs'] } async with self.session.post( 'https://api.openai.com/v1/images/generate', headers=headers, json=data ) as response: result = await response.json() return { 'url': result['data'][0]['url'], 'prompt': task['prompt'], 'processing_time': time.time() - task['submitted_at'] }
2. 性能监控仪表板
pythonfrom prometheus_client import Counter, Histogram, Gauge import psutil class PerformanceMonitor: def __init__(self): # Prometheus metrics self.request_counter = Counter( 'image_api_requests_total', 'Total API requests', ['status', 'quality'] ) self.latency_histogram = Histogram( 'image_api_latency_seconds', 'API latency distribution', buckets=[0.5, 1.0, 2.0, 3.0, 5.0, 10.0] ) self.active_requests = Gauge( 'image_api_active_requests', 'Currently active requests' ) self.cost_counter = Counter( 'image_api_cost_dollars', 'Total API cost in dollars' ) # 内存指标 self.memory_usage = Gauge( 'image_api_memory_usage_mb', 'Memory usage in MB' ) def record_request(self, quality: str, status: str, latency: float, cost: float): """记录请求指标""" self.request_counter.labels( status=status, quality=quality ).inc() self.latency_histogram.observe(latency) self.cost_counter.inc(cost) def update_memory_usage(self): """更新内存使用""" process = psutil.Process() memory_mb = process.memory_info().rss / 1024 / 1024 self.memory_usage.set(memory_mb) def get_stats(self) -> dict: """获取统计信息""" return { 'total_requests': self.request_counter._value.sum(), 'active_requests': self.active_requests._value.get(), 'memory_usage_mb': self.memory_usage._value.get(), 'total_cost': self.cost_counter._value.get() }
常见问题与解决方案
1. 提示词优化技巧
pythonclass PromptOptimizer: def __init__(self): self.style_templates = { 'photorealistic': "photorealistic, high detail, professional photography", 'artistic': "artistic style, creative interpretation, unique perspective", 'minimal': "minimalist design, clean lines, simple composition", 'technical': "technical diagram, precise details, professional illustration" } def optimize_prompt(self, base_prompt: str, style: str = 'photorealistic', enhance_details: bool = True) -> str: """优化提示词以获得更好的结果""" optimized_parts = [] # 基础描述 optimized_parts.append(base_prompt) # 添加风格 if style in self.style_templates: optimized_parts.append(self.style_templates[style]) # 增强细节 if enhance_details: optimized_parts.extend([ "highly detailed", "sharp focus", "professional quality" ]) # 技术参数 optimized_parts.extend([ "4k resolution", "perfect lighting", "award winning" ]) return ", ".join(optimized_parts) def fix_common_issues(self, prompt: str) -> str: """修复常见的提示词问题""" # 移除否定词(GPT-4o处理否定词效果不佳) negative_words = ['no', 'not', 'without', "don't", 'avoid'] for word in negative_words: prompt = prompt.replace(f" {word} ", " ") # 替换模糊描述 vague_terms = { 'nice': 'beautiful', 'good': 'high quality', 'bad': 'low quality', 'big': 'large scale', 'small': 'miniature' } for vague, specific in vague_terms.items(): prompt = prompt.replace(vague, specific) return prompt.strip()
2. 文字渲染问题解决
pythonclass TextRenderingSolver: def __init__(self): self.font_suggestions = { 'title': 'bold sans-serif font, clear typography', 'body': 'readable font, proper spacing', 'logo': 'distinctive font, brand appropriate', 'artistic': 'decorative font, stylized text' } def enhance_text_prompt(self, text_content: str, text_type: str = 'title') -> str: """增强文字渲染的提示词""" font_hint = self.font_suggestions.get(text_type, '') enhanced_prompt = f''' Text clearly showing "{text_content}", {font_hint}, legible and properly rendered, no spelling errors, correct character spacing ''' return enhanced_prompt.strip() def create_text_layout_prompt(self, texts: list) -> str: """创建多文字布局提示词""" layout_parts = [] for i, text_info in enumerate(texts): position = text_info.get('position', 'center') size = text_info.get('size', 'medium') content = text_info['content'] layout_parts.append( f"{size} text saying '{content}' positioned at {position}" ) return ", ".join(layout_parts) + ", well-organized layout"
3. 批量处理优化
pythonimport asyncio from typing import List, Callable class BatchProcessor: def __init__(self, api_client, max_batch_size: int = 10): self.api_client = api_client self.max_batch_size = max_batch_size self.pending_batches = [] async def process_large_batch(self, prompts: List[str], progress_callback: Callable = None) -> List[dict]: """处理大批量请求""" total = len(prompts) results = [] # 分批处理 for i in range(0, total, self.max_batch_size): batch = prompts[i:i + self.max_batch_size] # 并发处理当前批次 batch_results = await asyncio.gather(*[ self.api_client.generate(prompt) for prompt in batch ]) results.extend(batch_results) # 进度回调 if progress_callback: progress = len(results) / total * 100 await progress_callback(progress, len(results), total) # 避免速率限制 if i + self.max_batch_size < total: await asyncio.sleep(2) # 批次间延迟 return results async def process_with_retry_pool(self, prompts: List[str], max_retries: int = 3) -> List[dict]: """带重试池的批处理""" results = {} retry_pool = [(p, 0) for p in prompts] # (prompt, retry_count) while retry_pool: # 取出待处理的提示词 current_batch = [] remaining = [] for prompt, retry_count in retry_pool[:self.max_batch_size]: if retry_count < max_retries: current_batch.append((prompt, retry_count)) else: # 超过重试次数,标记为失败 results[prompt] = {'error': 'Max retries exceeded'} retry_pool = retry_pool[self.max_batch_size:] # 处理当前批次 if current_batch: batch_results = await asyncio.gather(*[ self._process_with_tracking(prompt, retry_count) for prompt, retry_count in current_batch ], return_exceptions=True) # 处理结果 for (prompt, retry_count), result in zip(current_batch, batch_results): if isinstance(result, Exception) or \ (isinstance(result, dict) and not result.get('success')): # 需要重试 retry_pool.append((prompt, retry_count + 1)) else: # 成功 results[prompt] = result return [results[p] for p in prompts]
未来展望与技术路线图
即将推出的功能
根据OpenAI的开发计划,以下功能值得期待:
- 图像编辑API - 支持局部修改和inpainting
- 风格迁移 - 保持内容的同时改变艺术风格
- 3D渲染支持 - 生成具有深度信息的图像
- 视频生成 - 从静态到动态的扩展
架构演进方向
python# 未来可能的API接口 class FutureGPT4oAPI: async def edit_image(self, image_url: str, edit_prompt: str, mask_url: Optional[str] = None): """编辑现有图像""" pass async def generate_3d(self, prompt: str, output_format: str = "obj"): """生成3D模型""" pass async def generate_video(self, prompt: str, duration: int = 5, fps: int = 30): """生成视频""" pass
总结
GPT-4o Image Generation API代表了AI图像生成技术的重大飞跃。通过将图像生成能力原生集成到语言模型中,它不仅解决了文字渲染、多物体控制等技术难题,更重要的是改变了人机交互的范式——从单向的指令执行到双向的创意对话。
对于开发者而言,掌握GPT-4o Image API意味着:
- 技术优势:98%的文字准确率和20个物体的精准控制
- 成本可控:通过优化策略和网关服务实现50%以上的成本节省
- 生产就绪:完善的SDK支持和成熟的最佳实践
更重要的是,通过laozhang.ai等网关服务,中小团队也能以可承受的成本享受到企业级的AI图像生成能力。这不仅是技术民主化的体现,更是AI应用普及的关键一步。
随着技术的持续演进,GPT-4o Image Generation API将在更多领域展现其价值。从电商到教育,从娱乐到工业设计,原生的多模态能力正在开启无限可能。现在正是拥抱这项技术的最佳时机。