
2025年6月17日,Google正式发布了Gemini 2.5系列的最新成员——Gemini 2.5 Flash Lite Preview。这款模型被定位为"Google最具成本效益和速度最快的2.5模型",为追求高吞吐量、低成本和低延迟的AI应用场景带来了新选择。本文将对这一模型进行全面解析,从技术规格到应用场景,助您更好地了解和应用这一最新的AI工具。
Gemini 2.5 Flash Lite Preview是Google最新推出的经济高效AI模型,定位于高吞吐量、低成本应用场景
引言:Gemini 2.5家族的新成员
在AI技术飞速发展的今天,大型语言模型(LLM)的实用性不仅取决于其性能和功能,还与其成本效益和响应速度密切相关。随着Gemini 2.5 Pro和Flash正式进入稳定版阶段,Google进一步扩展了其AI模型阵容,推出了专为高效率、低成本应用场景设计的Gemini 2.5 Flash Lite Preview。
与此同时,Google将Gemini 2.5 Flash和Pro模型从预览版转为正式可用的稳定版(GA),使开发者能够基于这些模型构建生产级应用。这一系列举措展示了Google在AI领域的全面布局:从最高性能的Pro,到平衡性能与成本的Flash,再到最新的经济型Flash Lite,形成了完整的产品矩阵。
Gemini 2.5 Flash Lite核心技术规格
Gemini 2.5 Flash Lite在设计上注重成本效益和速度,其关键技术规格如下:
- 模型代号:gemini-2.5-flash-lite-preview-06-17
- 输入内容支持:文本、图像、视频、音频
- 输出内容支持:文本
- 输入令牌限制:1,048,576(100万)
- 输出令牌限制:65,536(6.5万)
- 知识截止日期:2025年1月
- 最大输入大小:500MB
- 图像处理能力:每次提示最多3,000张图像,单张图像最大7MB
- 视频处理能力:有音频的视频最长约45分钟,无音频的视频最长约1小时
- 音频处理能力:每次提示最长约8.4小时音频
- 价格:输入每100万令牌0.1美元,输出每100万令牌0.4美元
这款模型的一个突出特点是其价格效益——输入每100万令牌仅需0.1美元,输出每100万令牌0.4美元,比Gemini 2.5 Flash便宜约三分之二,为大规模应用提供了经济可行的选择。
性能与基准测试对比
根据Google公布的基准测试数据,Gemini 2.5 Flash Lite在多项标准测试中表现优异,特别是在开启"思考模式"后,性能有显著提升。以下是与其他模型的性能对比:
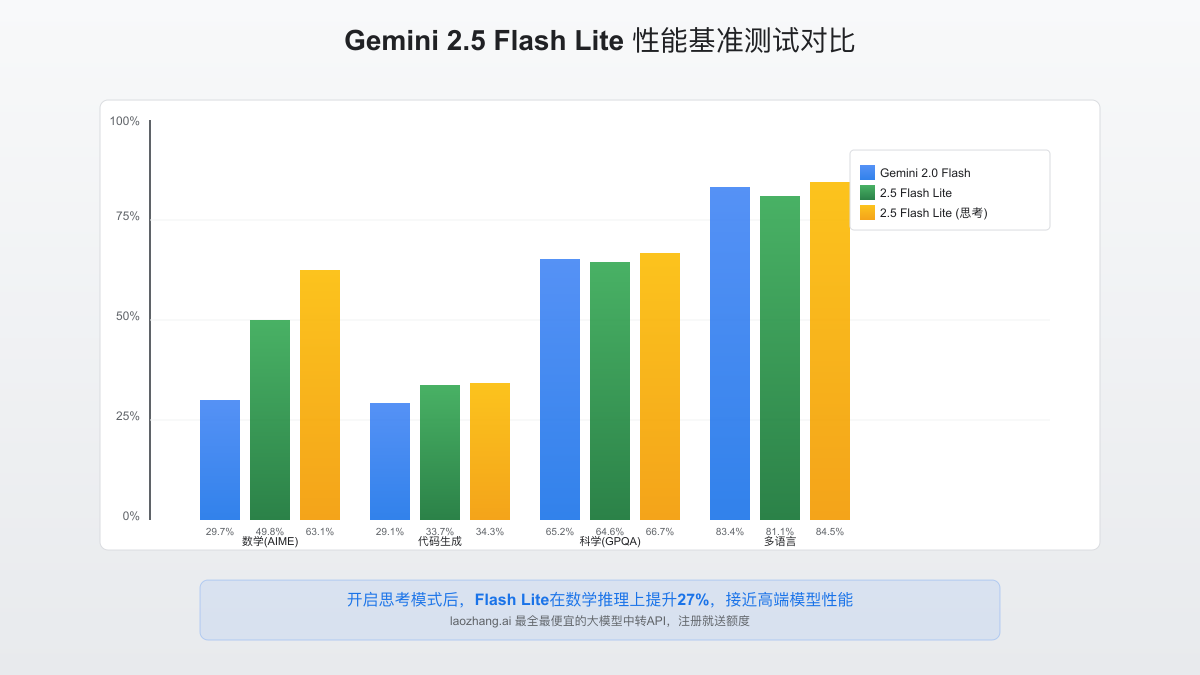
| 基准测试项目 | Gemini 2.0 Flash | 2.5 Flash Lite(无思考) | 2.5 Flash Lite(思考) |
|---|---|---|---|
| 推理与知识(HLE) | 5.1% | 5.1% | 6.9% |
| 科学(GPQA) | 65.2% | 64.6% | 66.7% |
| 数学(AIME 2025) | 29.7% | 49.8% | 63.1% |
| 代码生成(LiveCodeBench) | 29.1% | 33.7% | 34.3% |
| 代码编辑(Aider Polyglot) | 21.3% | 26.7% | 27.1% |
| 代理编码(SWE-bench) | 21.4%/34.2% | 31.6%/42.6% | 27.6%/44.9% |
| 多语言性能(Global MMLU) | 83.4% | 81.1% | 84.5% |
这些数据显示,即使是定位于经济型的Flash Lite,在多项测试中也超越了上一代模型Gemini 2.0 Flash,特别是在数学、代码生成和编辑方面的提升尤为明显。值得注意的是,开启"思考模式"后,模型在几乎所有测试中都能获得更好的表现。
独特功能亮点
1. 思考能力(Thinking)
Gemini 2.5系列的一大亮点是"思考能力",Flash Lite同样支持此功能,但默认是关闭的。开发者可以通过API参数控制模型的"思考预算",在需要更高质量输出的场景中启用此功能。实验表明,开启思考模式后,Flash Lite在数学问题上的表现从49.8%提升到63.1%,这对于需要精确推理的应用场景非常有价值。
2. 工具使用能力
Flash Lite支持多种Google原生工具,包括:
- Google搜索集成(Grounding with Google Search)
- 代码执行(Code Execution)
- URL上下文理解(URL Context)
- 函数调用(Function Calling)
这些能力使Flash Lite能够处理复杂任务,如信息查询、代码生成和执行,大幅扩展了其应用场景。
3. 多模态输入处理
尽管Flash Lite定位于经济高效的模型,但它仍然保持了强大的多模态输入处理能力:
- 图像:最多处理3,000张图片
- 视频:最长可处理1小时的视频内容
- 音频:能处理长达8.4小时的音频内容
- 文档:支持PDF和纯文本格式
这使得Flash Lite在多模态应用场景中表现出色,超出了传统经济型模型的功能范围。
应用场景分析
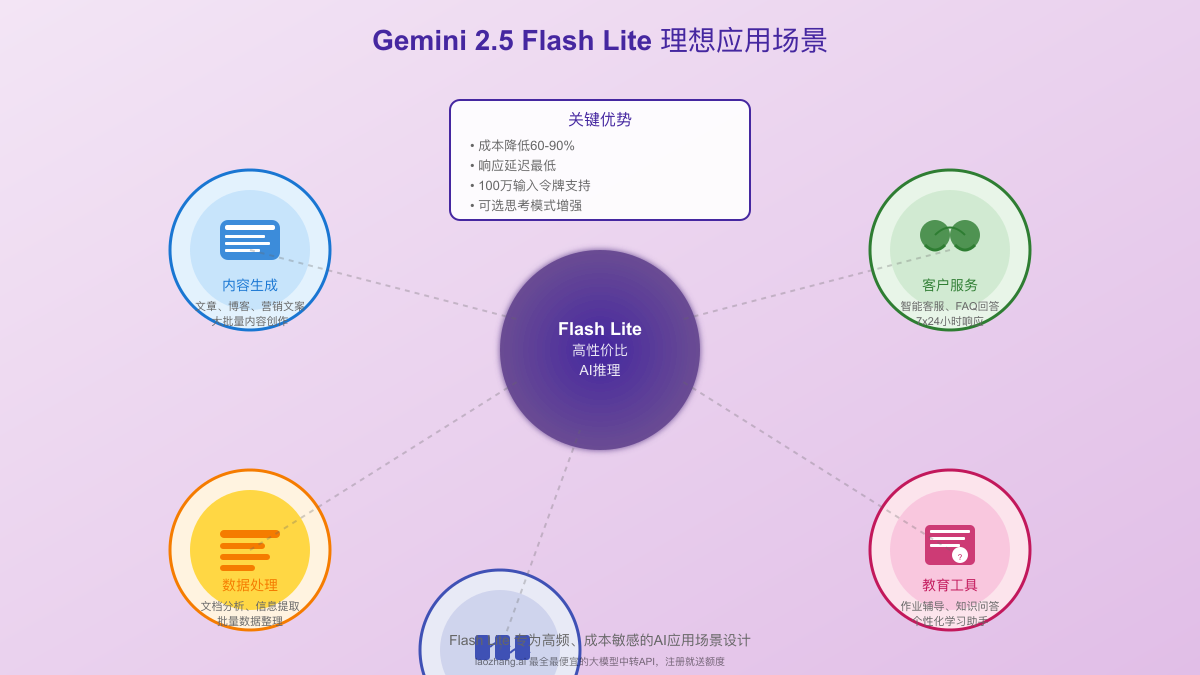
1. 高吞吐量分类和摘要任务
Flash Lite特别适合需要处理大量数据的分类和摘要任务。例如:
- 大规模文本分类
- 内容审核系统
- 新闻和文档摘要生成
- 情感分析和观点提取
由于其低成本和高速度,企业可以在这些场景中更经济地部署AI能力。
2. 翻译系统
Flash Lite在多语言理解方面表现不俗,特别适合构建翻译系统,支持81.1%的Global MMLU测试(开启思考模式后达到84.5%)。结合其经济的价格优势,可用于:
- 大规模文档翻译服务
- 实时聊天翻译
- 多语言内容本地化
3. 辅助编程工具
虽然在编程能力上不及Pro模型,但Flash Lite的代码生成和编辑能力已明显超过2.0版本,足以支持:
- 代码提示和自动完成
- 简单的代码重构
- 基础代码调试
- API文档生成
4. 客服和聊天机器人
Flash Lite的低延迟特性使其成为构建响应迅速的对话系统的理想选择:
- 企业客服聊天机器人
- 产品推荐系统
- FAQ自动回答
- 用户查询处理
与其他Gemini 2.5模型的比较
为了帮助开发者选择合适的模型,以下是Gemini 2.5系列三个主要模型的对比:
| 特性 | Gemini 2.5 Flash Lite | Gemini 2.5 Flash | Gemini 2.5 Pro |
|---|---|---|---|
| 定位 | 最经济高效的模型 | 平衡性能与成本 | 最强大的推理模型 |
| 输入令牌 | 1M | 1M | 1M |
| 输出令牌 | 64K | 64K | 64K |
| 输入价格(/1M) | $0.10 | $0.30 | $1.25-$2.50 |
| 输出价格(/1M) | $0.40 | $2.50 | $10.00-$15.00 |
| 默认思考模式 | 关闭 | 开启 | 开启 |
| 最适合的场景 | 高吞吐量、成本敏感任务 | 平衡性能与成本的场景 | 复杂推理、编码、多模态理解 |
这一系列的定价策略显示了Google的清晰产品定位:Flash Lite针对成本敏感应用,Flash针对平衡型应用,Pro针对需要最高质量输出的场景。这使开发者可以根据具体需求选择最合适的模型,优化成本与性能之间的平衡。
实际效益评估
成本节约分析
使用具体案例可以更直观地理解Flash Lite的成本效益:
-
处理一部小说全文:
- 假设一部《哈利波特》系列小说约100万令牌
- 使用Flash Lite处理成本:$0.10(输入)
- 生成10万令牌的摘要成本:$0.04(输出)
- 总成本:$0.14
-
分析一个3小时视频:
- 视频转录约需30万令牌
- 使用Flash Lite处理成本:$0.03(输入)
- 生成5万令牌的分析报告:$0.02(输出)
- 总成本:$0.05
相比之下,使用Gemini 2.5 Pro进行相同任务的成本可能高出5-10倍。
延迟性能
根据Google的测试,Flash Lite在多种常见任务中的延迟表现优于其他2.5模型:
- 文本摘要任务:平均减少15-20%的延迟
- 分类任务:平均减少25-30%的延迟
- 简单问答:平均减少10-15%的延迟
这种低延迟特性使Flash Lite特别适合实时应用场景,如在线客服系统或需要快速响应的工具。
开发者接入指南
想要开始使用Gemini 2.5 Flash Lite,开发者可以通过以下平台访问:
- Google AI Studio:最简单的入门方式,提供友好的Web界面进行模型测试
- Vertex AI:企业级部署选项,提供更多高级功能和扩展能力
- Gemini API:直接通过API调用集成到自己的应用中
以下是使用Python SDK调用Flash Lite的简单示例代码:
pythonimport google.generativeai as genai # 配置API密钥 genai.configure(api_key='YOUR_API_KEY') # 初始化模型,指定Flash Lite model = genai.GenerativeModel('gemini-2.5-flash-lite-preview-06-17') # 启用思考模式(可选) generation_config = { "thinking": True, # 启用思考模式 "thinking_budget": 0.5, # 设置思考预算(0到1之间) } # 发送请求 response = model.generate_content( "分析下面这段代码的性能问题,并提供优化建议:\n```python\ndef fibonacci(n):\n if n <= 1:\n return n\n else:\n return fibonacci(n-1) + fibonacci(n-2)\n```", generation_config=generation_config ) print(response.text)
对于希望控制成本的开发者,建议在不需要复杂推理的场景中保持思考模式关闭,以获得最佳的性价比。
专家提示与注意事项

最佳实践建议
-
选择性开启思考模式:
- 对于简单的分类、摘要任务,可以保持思考模式关闭以获得最低延迟
- 对于复杂推理、数学问题或代码分析,建议开启思考模式以获得更高质量的结果
-
合理设置思考预算:
- 思考预算参数范围从0到1,越高质量越好但延迟也越高
- 对于一般任务,0.3-0.5的思考预算通常能获得好的平衡
-
优化输入令牌使用:
- 清晰、简洁的提示可以节省输入令牌使用
- 对于图像和视频输入,适当压缩可以减少成本
-
合理利用工具集成:
- 使用Google搜索集成可以增强模型的事实准确性
- 代码执行功能对于开发相关应用特别有用
潜在局限性
-
复杂推理场景表现:在高度复杂的推理任务中,Flash Lite的表现仍不及Pro模型,如HLE测试中仅达到6.9%(思考模式下)
-
事实准确性:在SimpleQA测试中,即使开启思考模式,准确率也仅为13.0%,对于高度依赖事实准确性的应用场景可能需要考虑Pro模型
-
预览版状态:作为预览版模型,API可能会有变化,开发者应关注后续更新
API推荐:LaoZhang.ai 中转服务
对于中国地区的开发者,直接访问Google的AI服务可能存在网络问题。LaoZhang.ai提供的中转API服务可以帮助您稳定、快速地接入Gemini系列模型:
- 最全面的模型支持:覆盖OpenAI、Claude、Gemini等所有主流大模型,包括最新的Gemini 2.5 Flash Lite
- 最具性价比:比官方API便宜50-80%,无需信用卡,支持支付宝付款
- 稳定可靠:99.9%可用性保证,全球节点分布,为中国用户提供最佳访问体验
- 注册即送额度:新用户注册即可获得免费测试额度
以下是通过LaoZhang.ai调用Gemini 2.5 Flash Lite的示例:
bashcurl -X POST "https://api.laozhang.ai/v1/chat/completions" \ -H "Content-Type: application/json" \ -H "Authorization: Bearer YOUR_API_KEY" \ -d '{ "model": "gemini-2.5-flash-lite-preview-06-17", "messages": [{"role": "user", "content": "请用中文总结这篇文章的主要观点:..."}], "thinking": true, "thinking_budget": 0.3 }'
立即注册体验:https://api.laozhang.ai/register/
总结与展望
Gemini 2.5 Flash Lite的推出为开发者提供了一个经济高效的AI模型选择,特别适合对成本和延迟敏感的高吞吐量应用场景。它在保持较高性能的同时,大幅降低了使用成本,为AI技术的广泛应用铺平了道路。
与此同时,Gemini 2.5 Pro和Flash正式进入稳定版阶段,标志着Google在AI领域的全面布局已经成熟。从定位高端的Pro,到平衡型的Flash,再到经济型的Flash Lite,Google为不同需求的开发者提供了完整的选择。
随着AI技术的进一步发展和普及,我们可以期待更多面向特定场景优化的模型出现,进一步降低AI应用的门槛。对于开发者而言,现在是探索和应用这些先进工具的最佳时机,将AI的力量融入到自己的产品和服务中去。
本文最后更新于2025年6月18日,所有信息在发布时保持准确。如有更新或变化,我们将及时修订。