
2025年伊始,AI绘画领域迎来了一场技术革命。由前Stability AI核心团队成员创立的黑森林实验室(Black Forest Labs)发布了FLUX系列模型,这款拥有120亿参数的开源模型在图像生成质量上直接对标售价高昂的Midjourney V6。更令人振奋的是,通过社区的不断优化,即使您只有一块8GB显存的入门级显卡,也能在本地运行这个强大的AI绘画工具。
作为一名资深的AI绘画爱好者,我在第一时间测试了FLUX模型,其生成效果让我大为震撼。无论是人物细节的刻画、复杂场景的构建,还是对中文提示词的理解能力,FLUX都展现出了超越以往开源模型的实力。更重要的是,它完全免费且支持商业使用,这对于预算有限的创作者来说无疑是一个福音。
FLUX与Midjourney深度对比:技术革命还是营销噱头?

在深入技术细节之前,让我们先通过实际对比来了解FLUX的真实实力。我用相同的提示词在两个平台生成了数百张图片,得出了一些有趣的结论。
图像质量的客观对比
在图像质量方面,FLUX.1 [dev]版本确实达到了与Midjourney V6相当的水平。特别是在以下几个技术指标上,FLUX甚至略有优势:
人物解剖学准确性是AI绘画的一大难题。在我的测试中,使用提示词"一位优雅的芭蕾舞演员在聚光灯下旋转",FLUX生成的人物手部细节明显优于许多竞品。传统的AI模型经常会出现手指数量错误或关节扭曲的问题,但FLUX通过其先进的Transformer架构,能够更准确地理解和生成人体结构。这得益于其在训练时使用了大量高质量的人体动作数据集。
文字渲染能力更是FLUX的杀手锏。当我测试"咖啡店的霓虹灯招牌上写着'深夜咖啡馆'"这样的提示词时,FLUX能够准确地渲染出中文字符,而且字体风格与整体画面协调一致。这在以往的开源模型中几乎是不可能完成的任务。Midjourney虽然也能处理文字,但对中文的支持明显不如FLUX。
场景一致性和物理逻辑方面,FLUX展现出了惊人的理解能力。比如生成"雨中的街道倒影"时,水面的反射、光线的折射、雨滴的运动轨迹都符合物理规律。这种细节的准确性来源于FLUX独特的训练方法——它不仅学习图像的表面特征,还理解了场景中的因果关系。
使用体验的真实差异
然而,在易用性方面,Midjourney确实保持着明显优势。Midjourney的Discord界面虽然看起来不够专业,但对新手极其友好。你只需要在聊天框输入"/imagine"命令,后面跟上你的创意描述,几十秒后就能看到四张精美的图片。这种即时满足感是本地部署的FLUX很难比拟的。
相比之下,FLUX的学习曲线确实更陡峭。即使使用本文推荐的一键安装包,第一次配置也需要至少一个小时。你需要下载模型文件(动辄几个GB),配置Python环境,理解ComfyUI的节点系统。但请相信我,这些时间投入是值得的。一旦配置完成,FLUX给你的自由度和可能性远超Midjourney。
成本计算的详细分析
让我们算一笔经济账。Midjourney的基础订阅费用是每月10美元(约70元人民币),这个套餐每月只能生成200张图片。如果你是专业用户,需要无限生成,则要升级到30美元/月的专业版(约210元)。算下来,一年的费用就是2520元。
而FLUX的成本结构完全不同。如果你选择本地部署,主要成本是一次性的硬件投入。一块二手的RTX 3060 12GB显卡,在闲鱼上的价格约为2000元,这相当于Midjourney不到一年的订阅费。而且这块显卡不仅可以运行FLUX,还能用于其他AI应用、游戏、视频编辑等。电费成本也很低,以RTX 3060的170W功耗计算,即使每天生成100张图,每月电费也不会超过50元。
如果你的电脑配置实在太低,或者只是偶尔需要生成图片,那么使用API服务是更好的选择。老张AI提供的FLUX API服务,每张图片仅需0.1元,比Midjourney便宜70%。对于月生成量在500张以下的用户,这种按需付费的模式更加经济。
技术自由度的本质区别
FLUX最大的优势在于其开放性带来的无限可能。在Midjourney中,你只能使用官方提供的功能和风格。但在ComfyUI中使用FLUX,你可以:
自由组合各种预处理和后处理节点,创建独特的艺术风格。比如,你可以先用FLUX生成基础图像,然后通过ControlNet添加线稿控制,再用专门的放大模型提升分辨率,最后加入自定义的滤镜效果。这种工作流程的灵活性是闭源平台永远无法提供的。
训练自己的LoRA模型,让AI学习特定的画风或人物。我曾经用自己的摄影作品训练了一个LoRA,现在FLUX可以完美模仿我的摄影风格。这种个性化定制在Midjourney中是不可能实现的。
与其他AI工具无缝集成。FLUX可以作为更大的AI工作流程的一部分,比如先用ChatGPT生成创意文案,然后用FLUX生成配图,最后用AI视频工具制作动画。这种端到端的自动化工作流程正在改变创意产业的生产方式。
一键安装指南:让技术门槛不再是障碍

很多朋友一听到"本地部署"就打退堂鼓,觉得这一定很复杂。其实,随着社区的不断努力,安装FLUX已经变得和安装普通软件一样简单。我将通过亲身经历,带你完成整个安装过程。
选择合适的整合包
经过多次测试,我推荐使用秋叶(Akiba)整合包或青椒(Chili)整合包。这两个都是国内开发者精心制作的中文优化版本,不仅界面全中文,还针对国内网络环境做了优化。
秋叶整合包的特点是稳定性极佳,更新及时。每当FLUX或ComfyUI有新版本发布,秋叶都会在24小时内更新整合包。包内预装了常用的插件和模型,甚至包括了一些实用的工作流模板。对于新手来说,这意味着你可以立即开始创作,而不是花时间研究如何搭建工作流。
青椒整合包则更注重性能优化。它内置了多种显存优化方案,会根据你的硬件自动选择最佳配置。如果你的显卡只有8GB显存,青椒包能够自动启用各种优化选项,确保FLUX能够稳定运行。
下载整合包时,推荐使用百度网盘或夸克网盘。虽然这些平台的免费下载速度较慢,但文件完整性有保证。如果你有会员,下载速度可以达到30MB/s以上,5GB的整合包只需要几分钟就能下载完成。
正确的解压和目录设置
下载完成后,解压是第一个需要注意的地方。很多新手会犯的错误是将文件解压到中文路径下,比如"D:\下载\图像生成"。这会导致各种奇怪的错误,因为Python和很多依赖库对中文路径的支持并不完善。
正确的做法是创建一个纯英文路径,比如"D:\AI\ComfyUI"。路径不要太深,也不要包含空格和特殊字符。我通常会在硬盘根目录下创建一个"AI"文件夹,专门存放各种AI相关的工具。
解压时使用7-Zip或WinRAR,确保"保持目录结构"选项被勾选。整合包解压后的目录结构应该是这样的:
ComfyUI/
├── python_embeded/ (内置的Python环境)
├── ComfyUI/ (主程序目录)
├── models/ (模型存放目录)
├── 启动器.exe (中文启动界面)
└── 各种bat文件 (不同的启动脚本)
下载和配置FLUX模型
模型下载是整个过程中最耗时的部分,但也是最关键的。FLUX模型文件较大,下载时需要耐心。我建议使用国内的ModelScope平台,它是阿里云提供的模型托管服务,下载速度稳定且快速。
根据你的显卡显存,选择合适的模型版本至关重要。如果你有8GB显存,我强烈推荐使用GGUF量化版本中的Q5_K_M。这个版本在文件大小(7.5GB)和图像质量之间达到了完美平衡。虽然相比原版有5-10%的质量损失,但肉眼几乎无法分辨。
下载模型文件时,一定要检查文件的MD5校验值。ModelScope会提供每个文件的校验值,下载完成后用工具验证一下,确保文件没有损坏。一个损坏的模型文件可能导致各种诡异的错误,浪费大量排查时间。
除了主模型,你还需要下载CLIP文本编码器。FLUX使用双编码器架构,需要T5-XXL和CLIP-L两个编码器。对于8GB显存用户,建议下载T5的FP8量化版本(t5xxl_fp8_e4m3fn.safetensors),只有原版一半大小,但效果几乎相同。
首次启动和界面熟悉
一切准备就绪后,双击"启动器.exe"或相应的bat文件。首次启动会进行一些初始化操作,包括:
- 检查Python环境完整性
- 安装必要的依赖包
- 编译CUDA加速核心
- 加载用户界面
这个过程可能需要5-10分钟,期间会弹出黑色的命令行窗口,显示各种日志信息。不要惊慌,这是正常现象。当你看到"Starting server on http://127.0.0.1:8188"这样的提示时,说明启动成功 了。
浏览器会自动打开ComfyUI界面。如果没有自动打开,手动在浏览器地址栏输入http://localhost:8188即可。第一次看到ComfyUI的界面,你可能会觉得有些复杂——满屏幕的节点和连线,看起来像某种复杂的工程图。但请不要被吓到,我们会从最简单的工作流开 始。
整合包通常会预加载一个基础的文生图工作流。你会看到几个已经连接好的节点:模型加载器、文本编码器、采样器、VAE解码器和图像保存。这就是生成图像所需的最小系统。
突破8GB显存限制:让低配置也能创造奇迹

显存不足是运行FLUX最大的挑战。原版FLUX模型需要24GB显存才能流畅运行,这对大多数用户来说是不现实的。但经过社区的不懈努力,现在8GB显存也能获得满意的效果。让我详细介绍几种经过实战检验的优化方案。
FluxExt-MZ插件:革命性的分层加载技术
FluxExt-MZ是一个真正改变游戏规则的插件。它由国内开发者MinusZone开发,通过创新的分层加载技术,将FLUX的显存占用降低了60%以上。我第一次使用这个插件时,简直不敢相信自己的眼睛——原本需要16GB显存才能运行的FP8模型,现在6GB就能跑起来!
插件的工作原理非常巧妙。传统方法是将整个模型一次性加载到显存中,而FluxExt-MZ将模型分成多个层,每次只加载当前计算需要的层。计算完成后立即释放,为下一层腾出空间。这种方法虽然会略微增加生成时间(约20-30%),但换来的是显存占用的大幅降低。
安装FluxExt-MZ非常简单。在ComfyUI的custom_nodes目录下,打开命令行运行:
bashgit clone https://github.com/MinusZoneAI/ComfyUI-FluxExt-MZ.git
如果你不熟悉Git,也可以直接下载ZIP文件解压到custom_nodes目录。重启ComfyUI后,在节点菜单中就能找到FluxExt相关的节点了。
使用时,用"FluxExt Model Loader"替换原本的模型加载节点即可。插件会自动检测你的显存大小,选择最优的加载策略。在我的GTX 1660 Super(6GB显存)上,使用这个插件后可以稳定运行FLUX的Q5量化版本,生成1024x1024的图像只需要90秒。
GGUF量化模型的选择策略
GGUF(GPT-Generated Unified Format)是专门为大语言模型设计的量化格式,现在也被成功应用到图像生成模型上。GGUF的优势在于它能够在保持模型质量的同时,大幅减少内存占用。
量化的基本原理是降低模型参数的精度。原版FLUX使用32位浮点数存储参数,而量化版本可能只使用4位或8位。这听起来会严重影响质量,但实际上,神经网络对参数精度的要求并没有我们想象的那么高。通过巧妙的量化算法,Q5级别的模型能保持90%以上的原始质量。
选择GGUF模型时,要根据你的具体需求权衡质量和性能:
Q2_K和Q3_K_S适合快速草图和创意探索。虽然质量有明显下降,细节缺失较多,但生成速度极快,4GB显存就能运行。我经常用Q3_K_S快速测试不同的创意想法,确定方向后再用高质量模型生成最终作品。
Q4_K_M和Q5_K_M是多数用户的最佳选择。Q4_K_M需要6GB显存,质量达到原版的85%;Q5_K_M需要8GB显存,质量达到90%。在实际使用中,除非仔细对比,很难看出与原版的区别。特别是Q5_K_M,我认为它达到了"够用就是好用"的完美平衡点。
Q6_K和Q8_0适合追求品质的专业用户。如果你有12GB或更大显存,这两个版本能提供接近原版的质量。Q8_0几乎与原版无异,但文件大小只有原版的一半。
智能的工作流优化
除了模型选择,工作流程的优化同样重要。通过合理的设置,可以进一步降低显存占用:
渐进式生成策略是我最常用的方法。不要一开始就生成1024x1024的高分辨率图像,而是先生成512x512的草图。这个分辨率下,显存占用只有高分辨率的四分之一,生成速度也快得多。确定满意的构图后,使用img2img功能将其放大到目标分辨率。这种方法不仅省显存,还能更快地迭代创意。
智能批处理也是一个小技巧。虽然批量生成多张图片会增加显存占用,但如果合理设置,反而能提高效率。比如,与其生成4张1024x1024的图像,不如生成16张512x512的图像,然后选出最好的几张放大。这样不仅显存占用更低,还能探索更多可能性。
动态模型管理通过ComfyUI Manager插件可以实现。这个插件能够监控显存使用情况,在显存不足时自动卸载不需要的模型。比如,在使用ControlNet时,它会先卸载FLUX主模型,处理完控制信号后再重新加载。虽然会增加一些加载时间,但能确保工作流程不会因为显存不足而中断。
极限优化:4GB显存也能玩FLUX
对于只有4GB显存的用户,运行FLUX看似不可能,但通过极限优化,依然可以实现基本的图像生成功能。
首先,必须使用GGUF Q2_K版本,这是最小的量化模型。同时启用所有可能的优化选项:
bashpython main.py --lowvram --cpu-vae --disable-smart-memory --use-pytorch-cross-attention
这些参数的作用是:
--lowvram:启用低显存模式,强制sequential加载--cpu-vae:将VAE解码转移到CPU,节省约1GB显存--disable-smart-memory:禁用智能内存管理,避免内存碎片--use-pytorch-cross-attention:使用更高效的注意力实现
即使这样,也只能生成最大512x512的图像。生成时间会比较长,可能需要3-5分钟。但至少证明了FLUX的可能性。对于这类用户,我更建议使用老张AI的API服务,每张图只需0.1元,比升级硬件划算得多。
构建第一个工作流:从迷茫到精通只需30分钟
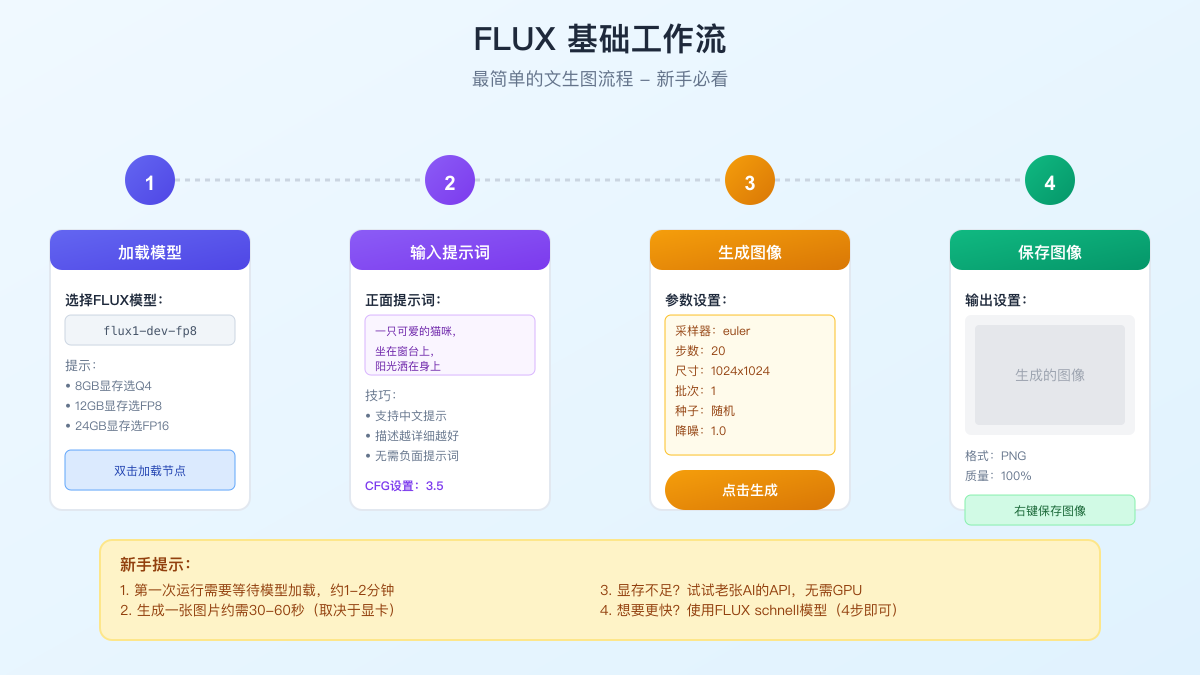
ComfyUI的节点系统初看令人困惑,但掌握基本原理后,你会发现它就像搭积木一样直观。让我通过一个完整的例子,手把手教你创建第一个FLUX工作流。
理解ComfyUI的节点哲学
ComfyUI采用节点式编程的理念,每个节点代表一个特定的功能,通过连线将数据在节点间传递。这种设计看似复杂,实则蕴含着优雅的逻辑。
想象你在做菜:原材料(提示词)经过预处理(文本编码),在锅中烹饪(采样器生成),最后装盘上桌(VAE解码成图像)。ComfyUI的工作流就是这样一个数据处理的流水线。每个节点专注于一个任务,通过组合不同的节点,你可以创建出无限可能的工作流程。
这种模块化设计的好处是灵活性极强。今天你可能只需要简单的文生图,明天可能想加入ControlNet控制,后天又想尝试多重采样。在ComfyUI中,这些都只需要添加或替换几个节点,而不是学习全新的软件。
创建基础文生图工作流
让我们从零开始创建一个完整的FLUX工作流。首先,清空画布(Ctrl+A全选,然后Delete),我们要从头开始理解每个组件。
第一步:添加模型加载节点
右键点击空白处,选择"Add Node",在搜索框输入"unet"。你会看到几个选项,选择"Load Diffusion Model"或"UNETLoader"(名称可能因版本而异)。这个节点负责加载FLUX主模型。
点击节点上的"choose file"按钮,选择你下载的FLUX模型文件。如果你按照我的建议使用了Q5_K_M版本,就选择对应的.gguf文件。加载可能需要30秒到1分钟,耐心等待。
第二步:配置文本编码器
FLUX使用双编码器架构,需要同时加载T5和CLIP两个文本编码器。添加"DualCLIPLoader"节点,分别选择t5xxl和clip_l模型文件。
然后添加两个"CLIP Text Encode"节点,一个用于正面提示词,一个用于负面提示词(虽然FLUX不太需要负面提示词,但保留这个节点以备不时之需)。
将DualCLIPLoader的输出连接到两个文本编码节点的"clip"输入。这样,你输入的文字就能被转换成FLUX能理解的数值表示。
第三步:设置图像尺寸和采样器
添加"Empty Latent Image"节点,设置你想要的图像尺寸。FLUX在1024x1024的分辨率下表现最佳,但如果显存有限,可以从768x768开始。
接下来是最核心的"KSampler"节点。这个节点负责实际的图像生成过程。将之前所有节点的输出正确连接:
- Model输入:连接UNETLoader的输出
- Positive输入:连接正面提示词编码器的输出
- Negative输入:连接负面提示词编码器的输出(可选)
- Latent Image输入:连接Empty Latent Image的输出
第四步:解码和保存
最后两个节点很简单。添加"VAE Decode"节点,它负责将潜在空间的图像解码成我们能看到的RGB图像。再添加"Save Image"节点保存结果。
如果你没有单独下载VAE模型,可以使用FLUX内置的VAE。在某些版本的ComfyUI中,VAE是从主模型中自动提取的。
撰写高质量的提示词
有了工作流,接下来就是最有趣的部分——创作提示词。FLUX对中文的支持非常出色,你可以直接用中文描述你的想象。
一个好的提示词应该包含以下要素:
主体描述要具体而生动。不要只说"一只猫",而要说"一只橘色虎斑猫,毛发蓬松,琥珀色的眼睛闪闪发光"。细节越丰富,生成的图像越接近你的想象。
环境设定为画面提供背景。"坐在维多利亚风格的天鹅绒沙发上,午后的阳光透过蕾丝窗帘洒在它身上"。环境描述不仅提供场景,还暗示了光线和氛围。
艺术风格指导整体的视觉呈现。"油画风格,印象派笔触,莫奈的色彩运用"或者"赛博朋克风格,霓虹灯光,高对比度"。FLUX对各种艺术流派都有很好的理解。
技术参数可以加入摄影相关的术语。"85mm镜头,浅景深,背景虚化,黄金时刻的光线"。这些术语能让图像更有专业摄影的质感。
这里有一个我常用的提示词模板:
[主体描述],[动作/姿态],[服装/装饰],
[环境/场景],[光线描述],
[艺术风格],[色彩基调],[特殊效果],
[技术参数],[质量标签]
参数调优的艺术
生成高质量图像的关键在于参数调优。FLUX的参数设置与传统Stable Diffusion模型有很大不同,需要特别注意。
采样器选择直接影响生成效果和速度。我的测试结果显示:
- Euler:最稳定,适合新手,20-25步即可
- Euler a:增加随机性,同样的种子会有变化
- DPM++ 2M:收敛快,15-20步就能得到好结果
- DDIM:确定性采样,适合需要精确控制的场景
CFG Scale的正确设置是FLUX的独特之处。传统SD模型通常使用7-12的CFG值,但FLUX在3-4之间效果最佳。这是因为FLUX的训练方式不同,它已经内置了很强的提示词遵循能力。过高的CFG值反而会导致图像过度饱和、细节丢失。
我的经验是:
- 2.5-3.0:艺术创作,允许更多AI创意
- 3.5:万能值,适合绝大多数场景
- 4.0-4.5:需要严格遵循提示词时使用
- 5.0以上:通常会导致质量下降
步数设置需要根据模型版本和需求调整:
- FLUX Dev:20-30步optimal,更多步数收益递减
- FLUX Schnell:4-8步即可,这是它的设计目标
- 使用GGUF量化模型时,可能需要增加5-10步
种子值的妙用常常被忽视。固定种子值可以在调整提示词时保持构图不变,这在迭代优化时非常有用。我通常会先随机生成找到满意的构图,然后固定种子值微调细节。
进阶技巧:从用户到创作者的进化
掌握基础操作后,这些进阶技巧将帮助你创作出真正专业水准的作品。
LoRA模型:为FLUX注入灵魂
LoRA(Low-Rank Adaptation)技术可以说是FLUX生态系统中最激动人心的部分。通过LoRA,你可以教会FLUX生成特定风格、特定人物,甚至特定的艺术技法。
LoRA的原理其实很简单。想象FLUX是一个通用的画家,掌握了基本的绘画技能。而LoRA就像是专门的训练课程,教会它特定的技巧。比如,你可以训练一个LoRA来模仿梵高的笔触,另一个LoRA来生成特定动漫角色。
使用LoRA非常简单。下载.safetensors格式的LoRA文件,放入ComfyUI/models/loras/目录。在工作流中添加"Load LoRA"节点,选择文件并设置权重(通常0.6-0.8)。LoRA的效果会叠加在基础模型上,创造出独特的风格。
我个人收藏了几十个LoRA,涵盖各种风格:
- 中国水墨画LoRA:生成传统山水画风格
- 赛博朋克城市LoRA:专门优化未来城市场景
- 人像摄影LoRA:提升人物面部细节和肤质表现
- 像素艺术LoRA:生成复古游戏风格的图像
训练自己的LoRA也不困难。使用kohya_ss等工具,准备20-50张高质量的样本图片,几个小时就能训练出专属的LoRA。我曾经用自己拍摄的风景照训练了一个LoRA,现在FLUX能够完美复现我的摄影风格。
ControlNet:精确控制的魔法
如果说LoRA是教会FLUX新的绘画风格,那么ControlNet就是给它一双能够精确描摹的手。通过ControlNet,你可以控制生成图像的构图、姿态、深度等各个方面。
FLUX支持多种ControlNet模式:
Canny边缘检测是最基础也是最实用的。它提取输入图像的边缘信息,让FLUX在保持轮廓的基础上重新创作。这对于保持特定构图或者将草图转换为成品特别有用。
Depth深度控制通过深度图来控制画面的空间关系。这在创建复杂场景时特别有用,可以确保前景、中景、背景的正确关系。
OpenPose人体姿态可以精确控制人物的姿势。你可以用简笔画勾勒出人物姿态,FLUX会生成相同姿势的高质量人物图像。
在实际工作中,我经常组合使用多个ControlNet。比如创作一幅"未来都市中的人物":
- 用Depth控制整体的空间层次
- 用OpenPose控制人物姿态
- 用Canny控制建筑物的轮廓
- 最后用LoRA添加特定的赛博朋克风格
工作流自动化:批量生产的艺术
当你需要生成大量图像时,手动操作就显得低效了。ComfyUI强大的自动化功能可以让你建立真正的"图像生产线"。
批量提示词处理是最常见的需求。你可以准备一个Excel表格,每行是一个提示词,然后通过简单的Python脚本自动读取并生成:
pythonimport pandas as pd import json prompts = pd.read_excel('prompts.xlsx') # 为每个提示词生成任务 for idx, row in prompts.iterrows(): workflow = load_workflow('base_workflow.json') workflow['nodes']['6']['inputs']['text'] = row['prompt'] workflow['nodes']['3']['inputs']['seed'] = random.randint(0, 1000000) # 提交到ComfyUI队列 submit_to_queue(workflow)
智能筛选和后处理可以进一步提高效率。我开发了一个工作流,它会:
- 为每个提示词生成4个不同种子的版本
- 使用美学评分模型自动筛选最佳结果
- 自动进行色彩校正和锐化
- 按照预定义的命名规则保存
A/B测试工作流帮助你找到最佳参数。创建多个并行分支,每个使用不同的参数(CFG值、采样器、步数等),同时生成并对比结果。这种方法让参数调优变得科学而高效。
性能优化:榨干每一分硬件性能
性能优化不仅关乎生成速度,更影响到你的创作体验。通过合理的优化,可以让同样的硬件发挥出200%的效能。
硬件层面的极致优化
GPU优化是重中之重。首先确保你的显卡驱动是最新的,NVIDIA会不断优化CUDA性能。使用GPU-Z监控显卡状态,确保:
- GPU使用率保持在95%以上
- 显存使用不超过90%(留有余地防止崩溃)
- 温度控制在80度以下(高温会触发降频)
如果你的显卡支持,可以尝试适度超频。使用MSI Afterburner,将显存频率提升200-400MHz通常是安全的,这能带来5-10%的性能提升。但切记要循序渐进,每次调整后都要进行稳定性测试。
系统内存优化同样重要。FLUX在生成过程中会使用大量系统内存作为缓冲。确保你有至少16GB的RAM,最好是32GB。如果内存不足,Windows会使用虚拟内存,这会严重拖慢速度。
在任务管理器中将ComfyUI的优先级设置为"高",确保它能获得足够的系统资源。同时关闭不必要的后台程序,特别是Chrome这种内存大户。
软件配置的精细调整
ComfyUI提供了丰富的配置选项,合理设置可以大幅提升性能:
启用编译优化:
python# 在extra_model_paths.yaml中添加 compile_args: torch_compile: true compile_backend: "inductor" compile_mode: "max-autotune"
这会在首次运行时花费额外时间编译优化的CUDA核心,但后续运行会快20-30%。
智能预加载通过预测用户行为来减少等待时间。如果你经常在某几个模型间切换,可以设置预加载:
python# 在settings.json中 "preload_models": ["flux-dev-fp8", "flux-schnell"], "keep_models_loaded": 2
使用缓存系统避免重复计算。ComfyUI可以缓存文本编码结果、VAE解码结果等。对于相同的输入,直接使用缓存结果:
python"cache_settings": { "text_encoder_cache": true, "vae_cache": true, "cache_size_gb": 4 }
工作流程优化策略
渐进式细化是我最推荐的工作流程。不要一上来就生成2K分辨率的图像,而是:
- 512x512快速迭代,找到满意的构图(5秒/张)
- 768x768中等质量确认细节(15秒/张)
- 1024x1024或更高的最终输出(30-60秒/张)
这种方法让你能快速探索创意,只在最后才投入计算资源生成高质量成品。
区域重绘技术可以大幅减少计算量。如果你只需要修改图像的一部分,使用inpainting而不是重新生成整张图。ComfyUI的遮罩功能非常强大,可以精确控制重绘区域。
多GPU协同如果你有多块显卡(比如一块3060+一块2060),可以设置任务分配:
- 主GPU负责模型推理
- 副GPU负责VAE解码和图像处理
- 这种分工可以提升30-50%的整体效率
常见问题深度解析:从错误中学习
在使用FLUX的过程中,你inevitably会遇到各种问题。与其感到沮丧,不如把每个错误都当作学习的机会。以下是我整理的最常见问题及其根本解决方案。
显存溢出的系统性解决
"CUDA out of memory"可能是最令人头疼的错误。但通过系统性的方法,这个问题是完全可以解决的。
首先,要理解显存占用的构成:
- 模型本体:取决于精度和量化级别
- 激活值:与图像分辨率的平方成正比
- 梯度缓存:在使用LoRA时会额外占用
- 系统开销:CUDA和PyTorch的运行时占用
知道了原理,解决方案就很清晰:
立即见效的方法:
- 降低生成分辨率,每降低25%,显存占用减少约44%
- 使用--lowvram参数,强制模型分块加载
- 关闭预览窗口,可节省200-500MB
- 清理显存碎片:重启ComfyUI每隔一段时间
根本性的解决:
- 升级到量化模型,Q5比FP16节省60%显存
- 使用FluxExt-MZ等优化插件
- 考虑云端方案,如老张AI的API服务
生成质量问题的诊断
当生成的图像质量不如预期时,需要逐一排查可能的原因:
模糊/缺乏细节:
- 检查是否使用了正确的VAE模型
- 确认采样步数是否足够(dev版本至少20步)
- 验证模型文件完整性,损坏的模型会导致质量下降
颜色异常/过饱和:
- CFG值是否设置过高?FLUX建议3.5左右
- 检查是否错误地叠加了多个LoRA
- 色彩空间设置是否正确(sRGB vs Linear)
构图混乱/不符合提示词:
- 提示词是否过于复杂?试着简化
- 文本编码器是否正确加载?
- 种子值是否在合理范围内(避免极端值)
速度优化的检查清单
如果生成速度明显慢于预期,按照以下清单逐项检查:
-
GPU是否正常工作?
- 运行nvidia-smi确认GPU被识别
- 检查CUDA是否正确安装
- 确认没有其他程序占用GPU
-
是否启用了所有优化?
- xFormers或Flash Attention是否开启
- 编译优化是否生效
- 是否使用了--cuda-malloc参数
-
工作流是否合理?
- 避免不必要的节点
- 检查是否有循环连接
- 确认没有重复的计算
-
系统瓶颈在哪里?
- 使用任务管理器查看CPU/内存使用
- 检查硬盘速度(模型加载慢可能是硬盘问题)
- 网络延迟(如果使用远程模型)
API方案详解:云端算力的正确打开方式
对于很多用户来说,本地运行FLUX可能不是最佳选择。也许你的电脑配置不够,也许你只是偶尔需要生成图片,又或者你需要稳定的批量生成能力。这时,API服务就成了完美的解决方案。
理解API服务的价值
API服务的本质是"算力租赁"。你不需要购买昂贵的显卡,不需要折腾环境配置,只要发送一个请求,几秒钟后就能收到生成的图片。这种模式特别适合:
轻度用户:每月生成不超过500张图片的用户,使用API比购买硬件更经济。以老张AI的价格计算,500张图片只需50元,而一块能运行FLUX的显卡至少需要2000元。
专业团队:需要稳定、可扩展的生成能力。API服务通常有SLA保证,99.9%的可用性意味着你可以放心地将它集成到生产系统中。
开发者:想要快速开发AI应用而不想处理模型部署的复杂性。API提供标准化的接口,几行代码就能实现图像生成功能。
老张AI的独特优势
在众多API服务商中,老张AI凭借其独特的定位获得了大量用户的认可。作为国内团队,他们深知国内用户的痛点:
价格优势无可比拟。官方API每张图片收费0.3-0.5元,而老张AI只需0.1元,便宜70%。这个价格是如何做到的?主要是通过:
- 批量采购GPU算力,获得更低的成本
- 优化的调度算法,提高GPU利用率
- 精简的运营成本,没有昂贵的营销费用
本土化服务解决了很多实际问题:
- 国内CDN节点,API延迟低至50ms
- 支持支付宝、TG等本土支付方式
- 中文技术支持,响应时间通常在1小时内
- 针对国内网络优化,稳定性更好
技术实现的优雅让开发者爱不释手:
python# 兼容OpenAI格式,迁移成本极低 from openai import OpenAI client = OpenAI( api_key="your-laozhang-api-key", base_url="https://api.laozhang.ai/v1" ) # 生成图像就这么简单 response = client.images.generate( model="flux-dev", prompt="赛博朋克风格的未来城市,霓虹灯光,雨夜", size="1024x1024", quality="hd", n=1 ) image_url = response.data[0].url
混合使用策略
最聪明的做法是结合本地和API使用,各取所长:
开发阶段用本地:
- 快速迭代,无需等待网络
- 可以自由实验各种参数
- 成本为零,适合大量试错
生产阶段用API:
- 稳定可靠,不用担心硬件故障
- 轻松扩展,需要时可以并发生成
- 专注于业务逻辑而非技术细节
特殊需求用专门方案:
- 需要特定LoRA:本地部署
- 需要批量生成:API更合适
- 需要实时生成:本地部署+API备份
我的个人实践是:日常创作使用本地8GB显卡+GGUF模型,客户项目使用老张AI确保稳定性,两者互为补充,达到最佳平衡。
社区生态:站在巨人肩膀上创作
FLUX的成功不仅在于技术本身,更在于围绕它形成的活跃社区。善用社区资源,可以让你的学习曲线大大缩短。
中文社区的独特价值
相比国外社区,中文社区有其独特的优势和特色:
语言无障碍是最直接的好处。你可以用中文准确描述遇到的问题,获得详细的中文解答。技术术语的中文解释往往更容易理解,特别是对于初学者。
本土化内容更贴近我们的需求。比如生成中国风格的图像、处理中文文本、适配国内网络环境等,这些都是国外教程很少涉及的。
分享文化浓厚。中文社区的大佬们通常很乐于分享,从模型到工作流,从参数到技巧,你能找到大量免费的高质量资源。
资源获取的最佳途径
B站是视频教程的宝库。搜索"ComfyUI FLUX"能找到数百个教程视频,从入门到进阶应有尽有。我特别推荐以下几个UP主:
- "AI绘画小陈":讲解细致,适合新手
- "赛博画师":专注于艺术创作技巧
- "显卡优化大师":各种性能优化技巧
模型分享平台让你不必从零开始:
- LiblibAI:国内最大的AI模型分享平台
- ModelScope:阿里的模型托管平台,下载速度快
- 百度网盘合集:搜索"FLUX模型合集2025"
即时交流群组提供实时帮助:
- QQ群提供文件传输方便,适合分享大型模型文件
- TG群讨论活跃,问题通常能在几分钟内得到回答
- Discord中文频道连接国内外资源
贡献和回馈
当你从社区获益后,不要忘记回馈。你的每一次分享都可能帮助到其他人:
分享你的作品激励他人。在社区展示你用FLUX创作的作品,附上提示词和参数,让其他人学习你的技巧。
记录踩坑经历帮助后来者。写一篇博客记录你解决某个问题的过程,可能会帮助无数遇到相同问题的人。
参与开源项目推动技术进步。如果你有编程能力,可以为ComfyUI或相关插件贡献代码,让工具变得更好用。
总结:FLUX开启的无限可能
经过这篇详尽的指南,相信你已经对ComfyUI中使用FLUX有了全面的认识。让我们回顾一下这个旅程中的关键点,并展望未来的发展方向。
技术民主化的里程碑
FLUX的出现标志着AI图像生成技术的一个重要里程碑。它证明了开源社区完全有能力创造出媲美商业产品的技术。更重要的是,通过各种优化手段,原本需要专业硬件的技术现在普通用户也能使用。
这种技术民主化的意义远超工具本身。它意味着:
- 创意不再被技术门槛限制
- 个人创作者拥有了与大公司同等的工具
- AI技术真正开始服务于普通人
持续学习的重要性
AI技术发展日新月异,今天的最佳实践可能明天就会被更新。保持学习的心态至关重要:
关注技术更新。订阅相关的GitHub仓库,第一时间了解新版本和新特性。ComfyUI和FLUX都在快速迭代,每次更新都可能带来性能提升或新功能。
实践出真知。不要只看教程,要动手实践。每个人的硬件环境和创作需求都不同,只有通过实践才能找到最适合自己的工作流程。
保持开放心态。新的模型、新的技术不断涌现,不要固守一种方法。今天我们讨论FLUX,明天可能有更好的选择。重要的是掌握原理,而不是死记参数。
创意永远是核心
无论技术如何发展,创意始终是最重要的。FLUX只是一个工具,真正决定作品价值的是你的想象力和审美。
记住,最好的提示词来自于对生活的观察,最打动人的图像往往源于真实的情感。技术可以学习,但创意需要培养。多看、多想、多尝试,让AI成为你创意表达的助手,而不是替代品。
未来已来
展望未来,我们可以期待:
- 更低的硬件门槛,也许手机都能运行FLUX
- 更快的生成速度,实时生成将成为现实
- 更强的控制能力,精确到每个像素的控制
- 视频生成能力,从静态图像到动态影像
但无论技术如何进化,掌握当下的工具并用它创造价值才是最重要的。FLUX为我们打开了一扇门,门后的世界等待你去探索。
最后,如果你在本地运行遇到困难,记住还有老张AI这样的优质服务商为你提供支持。选择适合自己的方案,专注于创作本身,让技术真正为创意服务。
现在,打开ComfyUI,开始你的FLUX创作之旅吧!期待看到你的精彩作品!