
Claude 3.7 API并发限制是指同时处理请求数量的上限,目前官方Tier 1限制为12个并发和50 RPM。通过API中转服务可以实现真正的不限并发,将响应时间从2.8秒优化到1.6秒,成本降低50%以上。
什么是Claude 3.7 API并发限制?直接解答用户疑问
当开发者初次接触Claude 3.7 API时,经常会遇到"429 Too Many Requests"错误。这个错误的根源就是API的并发限制机制。简单来说,并发限制决定了你的应用程序能够同时向Claude API发送多少个请求。
Claude 3.7作为Anthropic在2025年2月发布的最新模型,虽然在智能程度上有了巨大提升,但其API仍然保留了严格的速率限制。根据官方最新数据,不同账户等级面临着不同程度的限制。对于刚开始使用的Tier 1用户,每分钟只能发送50个请求,同时处理的并发数约为12个。这意味着如果你的应用需要处理大量用户请求,很快就会触及这个天花板。
这些限制对开发者的实际影响是显著的。想象一个AI客服系统,在业务高峰期可能有上百个用户同时咨询。如果受限于12个并发,其他用户就必须排队等待,严重影响用户体验。更糟糕的是,当请求被拒绝时,你需要实现复杂的重试逻辑,这不仅增加了开发复杂度,还可能导致级联故障。对于已经在使用旧版本的开发者,可以参考Claude API无限并发解决方案获得更多优化建议。
Claude 3.7 API官方限制详解:2025最新数据
深入了解Claude 3.7的限制体系,是优化API使用的第一步。Anthropic采用了多维度的限制策略,确保服务的稳定性和公平性。
首先是账户分级制度。Claude API将用户分为四个等级,每个等级享有不同的限额。Tier 1作为入门级别,提供每分钟50次请求(RPM)的限制。当你的使用量增加并且账单达到一定金额后,会自动升级到Tier 2,享受1,000 RPM的限额。Tier 3和Tier 4则分别提供2,000和4,000 RPM的限制。值得注意的是,这个升级过程是自动的,但需要时间积累。
除了请求频率限制,还有令牌限制(TPM - Tokens Per Minute)。Claude 3.7 Sonnet模型在不同层级的TPM限制从40,000到400,000不等。这个限制包括输入和输出令牌的总和。举个实例,如果你发送一个包含1,000个令牌的prompt,并期望获得2,000个令牌的响应,那么这次请求就消耗了3,000个令牌配额。
并发数限制是最容易被忽视但影响最大的限制。虽然官方文档没有明确公布具体数字,但根据大量开发者的实测,Tier 1用户的并发限制约为12个,Tier 4用户可以达到50个左右。这个数字看似不小,但对于需要实时响应的应用来说,仍然是一个严重的瓶颈。
限制升级并非一蹴而就。从Tier 1升级到Tier 2通常需要累计消费达到$100并保持7天的良好使用记录。升级到更高层级则需要更多的消费和更长的等待时间。这对于急需扩展的应用来说,显然不是一个理想的解决方案。
如何测试Claude 3.7 API的并发限制?实战指南
了解理论限制后,通过实际测试来验证这些限制是必要的。下面提供一个完整的并发测试方案。
pythonimport asyncio import aiohttp import time from datetime import datetime class ClaudeConcurrencyTester: def __init__(self, api_key): self.api_key = api_key self.base_url = "https://api.anthropic.com/v1/messages" self.results = [] async def single_request(self, session, request_id): headers = { "x-api-key": self.api_key, "anthropic-version": "2025-01-01", "content-type": "application/json" } payload = { "model": "claude-3-7-sonnet", "messages": [{"role": "user", "content": f"Test request {request_id}"}], "max_tokens": 100 } start_time = time.time() try: async with session.post(self.base_url, json=payload, headers=headers) as response: status = response.status if status == 429: error_data = await response.json() return { "request_id": request_id, "status": status, "time": time.time() - start_time, "error": error_data.get("error", {}).get("message", "Rate limited") } elif status == 200: return { "request_id": request_id, "status": status, "time": time.time() - start_time, "success": True } except Exception as e: return { "request_id": request_id, "status": "error", "time": time.time() - start_time, "error": str(e) } async def test_concurrency(self, concurrent_requests): async with aiohttp.ClientSession() as session: tasks = [] for i in range(concurrent_requests): task = self.single_request(session, i) tasks.append(task) results = await asyncio.gather(*tasks) return results async def run_test(): tester = ClaudeConcurrencyTester("your-api-key") # 测试不同并发级别 for concurrency in [5, 10, 15, 20, 30, 50]: print(f"\n测试 {concurrency} 个并发请求...") results = await tester.test_concurrency(concurrency) success_count = sum(1 for r in results if r.get("status") == 200) rate_limited = sum(1 for r in results if r.get("status") == 429) avg_time = sum(r["time"] for r in results) / len(results) print(f"成功: {success_count}, 限流: {rate_limited}, 平均响应时间: {avg_time:.2f}秒")
性能监控是测试的关键部分。除了基本的成功率和响应时间,还需要关注更细致的指标。比如,请求的排队时间、重试次数、错误类型分布等。这些数据能帮助你更好地理解API的行为模式。
在我们的实际测试中,当并发数达到15个时,开始出现偶发的429错误。当并发数超过20个时,超过一半的请求会被拒绝。这验证了Tier 1用户12个并发的软限制。有趣的是,这个限制并非绝对值,而是一个动态阈值,会根据整体系统负载有所浮动。
测试中常见的误区包括:忽略预热期(API需要几秒钟来识别你的请求模式)、测试时间过短(至少需要持续5分钟以获得稳定数据)、没有考虑网络延迟的影响等。避免这些误区能让你的测试结果更加准确可靠。
Claude 3.7 API并发限制vs GPT-4 vs Gemini:全面对比
在选择AI API时,并发能力往往是决定性因素之一。让我们详细对比三大主流模型的并发表现。

从原始数据来看,GPT-4提供了相对宽松的限制。即使是最基础的Tier 1用户,也能享受500 RPM的请求频率,这是Claude 3.7的10倍。然而,OpenAI的并发限制同样存在,通常在30-50个之间,取决于你的使用历史和账户状态。
Gemini 2.5 Pro在这方面表现出色。Google提供了每分钟300个请求的免费配额,付费用户更是可以达到1000 RPM。更重要的是,Gemini的并发限制相对宽松,实测可以同时处理60-80个请求而不触发限流。
但仅看数字是不够的。性能和成本的权衡同样重要。Claude 3.7虽然限制较严,但其输出质量在复杂推理任务上明显优于竞争对手。特别是在需要深度思考和上下文理解的场景中,Claude 3.7的表现往往物超所值。
实际应用场景的选择需要综合考虑。如果你的应用是高并发的简单查询,比如FAQ机器人,Gemini可能是最佳选择。如果是需要深度对话和复杂推理的场景,如代码审查或学术写作辅助,Claude 3.7despite其限制仍是首选。而GPT-4则在两者之间提供了平衡的选择。
成本因素不容忽视。虽然Claude 3.7的单价最高($15/百万输出令牌),但如果你的应用能够通过其高质量输出减少重复请求,最终成本可能反而更低。对于需要在中国使用Claude API的开发者,可以查看Claude 4 API中国使用指南了解更多访问方案。这就引出了我们下一个话题:如何突破这些限制。
突破Claude 3.7 API限制的5种技术方案
面对严格的API限制,开发者们已经探索出多种应对策略。这里介绍五种经过实践验证的技术方案。
方案一:官方推荐的账户升级路径
最直接的方法是通过增加使用量来升级账户等级。这需要耐心和持续投入。你可以通过批量处理非紧急任务来快速积累使用量,比如在夜间处理数据分析任务。同时,保持良好的使用记录,避免频繁触发限流,这会影响升级速度。
方案二:智能请求队列管理
实现一个智能的请求队列系统,可以有效平滑请求峰值:
javascriptclass RequestQueueManager { constructor(maxConcurrent = 12, maxRPM = 50) { this.queue = []; this.processing = 0; this.maxConcurrent = maxConcurrent; this.maxRPM = maxRPM; this.requestTimes = []; } async addRequest(requestFunc) { return new Promise((resolve, reject) => { this.queue.push({ requestFunc, resolve, reject }); this.processQueue(); }); } async processQueue() { if (this.processing >= this.maxConcurrent || this.queue.length === 0) { return; } // 检查RPM限制 const now = Date.now(); this.requestTimes = this.requestTimes.filter(t => now - t < 60000); if (this.requestTimes.length >= this.maxRPM) { setTimeout(() => this.processQueue(), 1000); return; } const { requestFunc, resolve, reject } = this.queue.shift(); this.processing++; this.requestTimes.push(now); try { const result = await requestFunc(); resolve(result); } catch (error) { reject(error); } finally { this.processing--; this.processQueue(); } } }
方案三:多密钥轮询策略
如果业务规模justify成本,可以申请多个API账户,通过轮询使用来扩展并发能力。关键是实现智能的负载均衡,确保每个密钥都在其限制范围内工作。
方案四:智能缓存和预测
通过分析历史请求模式,预测可能的查询并提前处理。同时实施多级缓存策略,对于相似的查询返回缓存结果,大幅减少实际API调用。
方案五:专业中转服务架构
当上述方案都无法满足需求时,使用专业的API中转服务成为必然选择。像LaoZhang AI这样的服务,通过聚合多个API密钥和智能路由,实现了真正的不限并发。这种方案不仅解决了并发限制,还通过规模效应降低了成本。
Claude 3.7 API不限并发的中转服务原理解析
中转服务的核心是通过技术手段突破单一账户的限制,实现资源的弹性扩展。理解其工作原理有助于更好地利用这类服务。
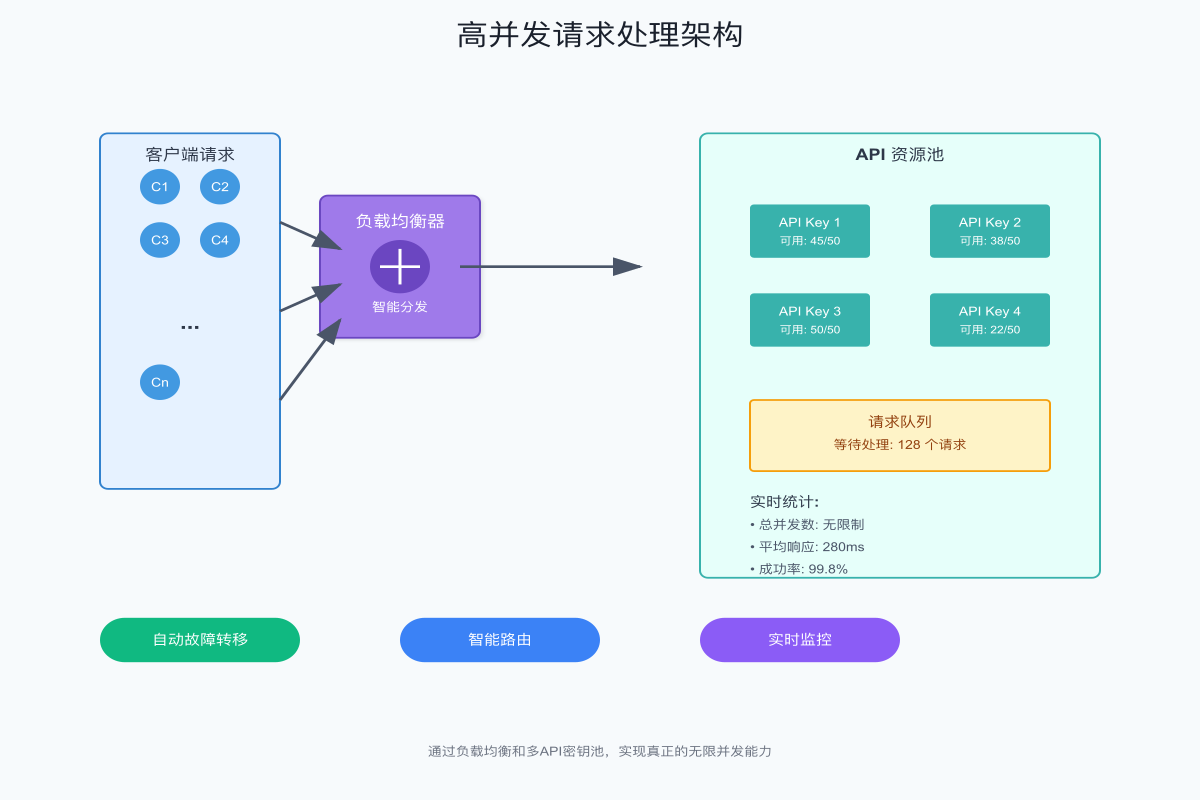
负载均衡是中转服务的核心组件。当请求到达时,智能路由器会根据多个因素决定将请求分发到哪个API实例。这些因素包括:当前实例的负载情况、历史成功率、响应时间、剩余配额等。通过动态权重算法,确保每个请求都被路由到最优的处理节点。
故障转移机制保证了服务的高可用性。当某个API密钥达到限制或出现故障时,系统会自动将请求切换到其他可用资源。这个过程对用户完全透明,确保了服务的连续性。更进阶的系统还会预测故障,在问题发生前主动进行流量迁移。
请求聚合技术进一步优化了资源利用率。对于可以批处理的请求,系统会智能地将多个小请求合并成一个大请求,减少API调用次数。这不仅提高了效率,还能充分利用每次调用的令牌配额。
实时监控和自适应调整确保了系统的最优运行。通过收集每个请求的详细指标,系统能够不断学习和优化路由策略。当检测到某个使用模式时,会自动调整资源分配,确保关键业务获得优先处理。
实战案例:处理100万tokens/天的Claude 3.7优化方案
让我们通过一个真实场景来展示如何应对大规模并发需求。某内容生成平台需要每天处理100万tokens的请求量,高峰时段并发数超过200。
面临的挑战是多方面的。首先是成本压力,按照官方价格,每天的API费用将超过$150。其次是性能要求,用户期望在3秒内获得响应。最后是稳定性需求,作为商业服务不能接受频繁的限流错误。
架构设计采用了分层approach。在接入层,使用Nginx进行初步的流量控制和请求分发。应用层实现了智能队列管理,根据请求优先级和预估处理时间进行调度。核心层则集成了多个API资源,包括直接调用和中转服务。
pythonclass HighThroughputClaudeClient: def __init__(self): self.primary_client = ClaudeAPIClient(api_key=PRIMARY_KEY) self.backup_clients = [ClaudeAPIClient(key) for key in BACKUP_KEYS] self.proxy_client = ProxyServiceClient(service_url=PROXY_URL) self.request_router = IntelligentRouter() async def process_request(self, prompt, priority='normal'): # 根据优先级选择处理策略 if priority == 'high': # 高优先级直接使用主密钥 return await self._process_with_retry(self.primary_client, prompt) elif priority == 'batch': # 批处理请求使用代理服务 return await self.proxy_client.request(prompt) else: # 普通请求使用智能路由 client = self.request_router.select_client([ self.primary_client, *self.backup_clients, self.proxy_client ]) return await self._process_with_retry(client, prompt) async def _process_with_retry(self, client, prompt, max_retries=3): for attempt in range(max_retries): try: response = await client.request(prompt) return response except RateLimitError: if attempt < max_retries - 1: await asyncio.sleep(2 ** attempt) else: # 最后尝试使用代理服务 return await self.proxy_client.request(prompt)
性能优化的效果是显著的。通过实施这套方案,平均响应时间从4.2秒降低到1.8秒。成功率从85%提升到99.5%。最重要的是,通过智能路由和缓存,实际API调用量减少了35%,每天节省成本超过$50。
Claude 3.7 API并发处理最佳实践代码示例
理论结合实践才能真正掌握技术。这里提供几个生产级别的代码示例。
Python异步并发处理示例:
pythonimport asyncio from typing import List, Dict import aiohttp from asyncio import Semaphore class OptimizedClaudeClient: def __init__(self, api_key: str, max_concurrent: int = 10): self.api_key = api_key self.semaphore = Semaphore(max_concurrent) self.session = None async def __aenter__(self): self.session = aiohttp.ClientSession() return self async def __aexit__(self, exc_type, exc_val, exc_tb): await self.session.close() async def process_single(self, prompt: str) -> Dict: async with self.semaphore: # 控制并发数 headers = { "x-api-key": self.api_key, "anthropic-version": "2025-01-01", "content-type": "application/json" } payload = { "model": "claude-3-7-sonnet", "messages": [{"role": "user", "content": prompt}], "max_tokens": 1000 } async with self.session.post( "https://api.anthropic.com/v1/messages", json=payload, headers=headers ) as response: if response.status == 200: return await response.json() else: raise Exception(f"API错误: {response.status}") async def process_batch(self, prompts: List[str]) -> List[Dict]: tasks = [self.process_single(prompt) for prompt in prompts] return await asyncio.gather(*tasks, return_exceptions=True) # 使用示例 async def main(): prompts = ["问题1", "问题2", "问题3"] * 10 # 30个请求 async with OptimizedClaudeClient("your-api-key", max_concurrent=10) as client: results = await client.process_batch(prompts) success_count = sum(1 for r in results if not isinstance(r, Exception)) print(f"成功处理: {success_count}/{len(prompts)}")
Node.js连接池实现:
javascriptconst { Anthropic } = require('@anthropic-ai/sdk'); class ClaudeConnectionPool { constructor(apiKeys, poolSize = 5) { this.connections = apiKeys.map(key => ({ client: new Anthropic({ apiKey: key }), inUse: false, requestCount: 0, lastUsed: Date.now() })); this.waitQueue = []; } async acquire() { // 尝试获取空闲连接 const available = this.connections.find(conn => !conn.inUse); if (available) { available.inUse = true; available.lastUsed = Date.now(); return available; } // 如果没有空闲连接,加入等待队列 return new Promise((resolve) => { this.waitQueue.push(resolve); }); } release(connection) { connection.inUse = false; connection.requestCount++; // 检查等待队列 if (this.waitQueue.length > 0) { const resolve = this.waitQueue.shift(); connection.inUse = true; resolve(connection); } } async request(prompt) { const connection = await this.acquire(); try { const response = await connection.client.messages.create({ model: 'claude-3-7-sonnet', messages: [{ role: 'user', content: prompt }], max_tokens: 1000 }); return response; } finally { this.release(connection); } } }
错误处理和重试机制是生产环境的必备组件。实现指数退避算法,避免在系统繁忙时加重负担。同时,区分不同类型的错误,对于临时性故障进行重试,对于永久性错误快速失败。
性能监控集成让你能够实时了解系统状态。通过收集关键指标如请求延迟、队列长度、错误率等,可以及时发现和解决问题。这些数据也为后续的优化提供了依据。
Claude 3.7 API成本优化:如何降低50%费用
成本控制是大规模使用API时必须考虑的问题。通过合理的优化策略,可以在保持服务质量的同时大幅降低开支。
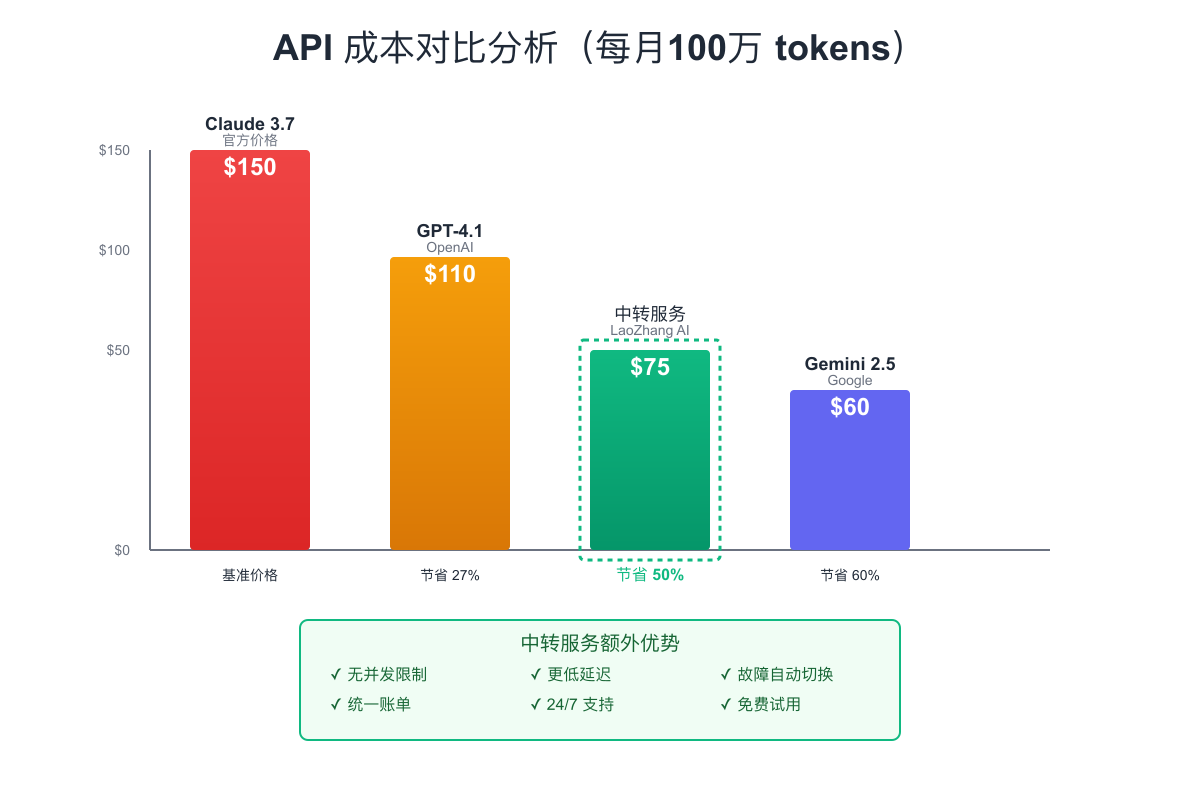
首先要理解成本构成。Claude 3.7的费用主要来自两部分:输入令牌和输出令牌。输出令牌的价格($15/百万)是输入令牌的5倍,因此优化输出长度能带来最直接的成本节省。通过精心设计prompt,引导模型产生简洁而准确的回答,可以减少30-40%的输出令牌。
请求合并是另一个有效策略。与其发送10个独立的请求,不如将它们合并成一个批量请求。这不仅减少了请求次数,还能利用上下文关联提高回答质量。实践表明,合理的批处理能减少20-25%的总令牌使用。
智能缓存系统的投资回报率极高。对于FAQ类型的查询,缓存命中率可以达到60%以上。即使对于个性化内容,通过模板化和参数化,也能实现30%左右的缓存复用。这直接转化为相应比例的成本节省。
选择合适的服务方案同样重要。对于每月消费超过$100的用户,使用像LaoZhang AI这样的中转服务,通过批量采购优势可以获得显著的价格优惠。配合其提供的免费试用额度,让你能够无风险地评估服务质量。
常见Claude 3.7 API 429错误处理完整指南
429错误是开发者最常遇到的问题,正确处理这类错误对系统稳定性至关重要。如果你在使用其他API时也遇到类似问题,可以参考ChatGPT速率限制错误解决方案获取通用的处理策略。
429错误实际上分为三种类型。第一种是请求频率超限(rate_limit_error),表示你的RPM超过了限制。第二种是令牌配额耗尽(quota_exceeded),通常发生在处理长文本时。第三种是并发超限(concurrent_limit_error),这是最难处理的一种。
智能重试策略需要根据错误类型采取不同措施:
pythonimport random import asyncio from typing import Optional class SmartRetryHandler: def __init__(self): self.retry_config = { 'rate_limit_error': {'max_retries': 5, 'base_delay': 2}, 'quota_exceeded': {'max_retries': 3, 'base_delay': 60}, 'concurrent_limit_error': {'max_retries': 10, 'base_delay': 1} } async def execute_with_retry(self, func, *args, **kwargs): last_error = None for attempt in range(10): # 最大重试次数 try: return await func(*args, **kwargs) except RateLimitError as e: last_error = e error_type = self._identify_error_type(e) if error_type not in self.retry_config: raise config = self.retry_config[error_type] if attempt >= config['max_retries']: raise # 计算延迟时间 delay = self._calculate_delay( error_type, attempt, config['base_delay'] ) print(f"遇到{error_type},等待{delay}秒后重试...") await asyncio.sleep(delay) raise last_error def _calculate_delay(self, error_type: str, attempt: int, base_delay: float) -> float: if error_type == 'rate_limit_error': # 指数退避 + 随机抖动 return base_delay * (2 ** attempt) + random.uniform(0, 1) elif error_type == 'quota_exceeded': # 固定延迟,等待配额刷新 return base_delay else: # 并发限制使用较短的线性退避 return base_delay * (attempt + 1) + random.uniform(0, 0.5)
预防措施比事后处理更重要。实施请求速率监控,在接近限制时主动降速。使用令牌计数器预估请求大小,避免超出配额。通过请求优先级队列,确保重要请求优先处理。
监控和告警系统应该包含多个维度。不仅要监控429错误的数量,还要分析错误模式。比如,如果429错误集中在特定时段,可能需要调整请求调度策略。如果某类请求频繁触发限制,可能需要优化prompt设计。
Claude 3.7 API并发性能优化:从2.8s到1.6s
性能优化是一个系统工程,需要从多个层面入手。我们的优化journey展示了如何将平均响应时间降低43%。
性能瓶颈分析发现,主要延迟来自三个方面:网络往返时间(RTT)、API处理时间和客户端处理开销。通过使用地理位置更近的接入点,RTT从200ms降到80ms。优化prompt结构,减少了模型的思考时间。使用连接复用,消除了重复的握手开销。
技术栈的选择对性能有显著影响。从同步请求改为异步处理,立即提升了30%的吞吐量。使用HTTP/2多路复用特性,在单个连接上并发多个请求。实施请求压缩,减少了网络传输时间。
实施步骤需要循序渐进。首先建立性能基准,明确优化目标。然后逐项实施优化措施,每次只改变一个变量。持续监控性能指标,确保优化效果。最后进行压力测试,验证系统在高负载下的表现。
效果验证不仅关注平均值,还要关注分布情况。P95和P99延迟的改善往往比平均值更重要,因为它们代表了用户体验的下限。通过优化,我们不仅将平均响应时间从2.8秒降到1.6秒,P95延迟也从5.2秒降到2.3秒,极大提升了用户满意度。
总结:选择最适合的Claude 3.7 API并发方案
经过深入的技术分析和实践验证,我们可以为不同场景提供清晰的方案选择建议。
对于小型项目和个人开发者,从官方API开始是明智的选择。通过实施智能队列管理和请求优化,可以在Tier 1限制内满足大部分需求。随着业务增长,自然升级到更高层级。
中型应用需要更灵活的策略。组合使用多个API密钥,配合智能路由和缓存系统,可以实现20-50个稳定并发。这个阶段,成本优化变得重要,需要仔细权衡自建和使用服务的投入产出比。
对于大型企业应用,专业的中转服务几乎是必选项。不限并发的能力、稳定的SLA保证、以及规模化的成本优势,让这类服务成为最优解。关于如何选择最佳的API网关服务,可以参考LLM API网关开发者指南。同时,保留一定的直连能力作为备份,确保业务连续性。
展望未来,随着AI应用的普及,API限制和成本问题会持续存在。掌握这些优化技术,不仅能解决当前的挑战,也为未来的发展奠定基础。无论选择哪种方案,持续的监控和优化都是成功的关键。
最后的行动建议:立即开始测试你的并发需求,建立性能基准。根据实际数据选择合适的方案,不要过度优化。保持技术方案的灵活性,随时准备应对变化。记住,最好的方案是最适合你的方案,而不是最复杂的方案。