
먼저 결론부터 말하면, 대부분의 개발자에게 기본 모델은 GPT-5.4입니다. OpenAI는 2026년 3월 5일 GPT-5.4를 공개하면서 GPT-5.3-Codex의 최전선 코딩 역량을 흡수한 주력 추론 모델이라고 설명했습니다. 즉, 코드 작성뿐 아니라 긴 컨텍스트, 검색, 패치, 도구 사용, 여러 단계의 에이전트형 작업까지 한 모델로 처리하고 싶다면 GPT-5.4가 더 자연스러운 기본값입니다.
그렇다고 GPT-5.3-Codex가 의미를 잃은 것은 아닙니다. GPT-5.3-Codex는 2026년 2월 5일 공개되었고 지금도 두 가지 뚜렷한 장점을 남기고 있습니다. 하나는 입력 토큰 가격이 더 싸다는 점이고, 다른 하나는 Terminal-Bench 2.0에서 GPT-5.4보다 여전히 높다는 점입니다. 작업이 셸, CLI, CI, 파일 조작, 짧은 디버깅 루프에 치우쳐 있다면 GPT-5.3-Codex는 여전히 괜찮은 전문 경로입니다.
이 글은 2026년 3월 19일 기준으로 확인한 OpenAI 공식 출시 페이지, API 모델 문서, 가격 페이지를 바탕으로 작성했습니다. 커뮤니티 장애 보고는 일시적인 운영 신호로만 다루고, 장기적인 제품 방향을 판단하는 근거와는 분리합니다. 이 비교의 핵심 질문은 결국 하나입니다. 오늘 어떤 모델을 기본 경로로 두어야 하는가?
핵심 요약
한 줄 추천은 이렇습니다. 기본은 GPT-5.4, 예외 경로로 GPT-5.3-Codex를 유지하세요.
| 항목 | GPT-5.4 | GPT-5.3-Codex | 실무 해석 |
|---|---|---|---|
| 출시일 | 2026년 3월 5일 | 2026년 2월 5일 | GPT-5.4가 더 새롭고 기본값에 가깝다 |
| 제품 역할 | coding과 reasoning을 함께 맡는 mainline model | coding 특화 모델 | GPT-5.4는 넓고 Codex는 좁다 |
| Input 가격 | $2.50 / 1M | $1.75 / 1M | Codex가 입력 비용에서 유리하다 |
| Output 가격 | $15 / 1M | $14 / 1M | 출력 가격 차이는 작다 |
| Cached input | $0.25 / 1M | $0.175 / 1M | 반복 컨텍스트는 Codex가 더 싸다 |
| 컨텍스트 창 | 1,050,000 | 400,000 | GPT-5.4가 repo-scale 작업에 유리하다 |
| Max output | 128,000 | 128,000 | 사실상 동급 |
| 툴 지원 | search, hosted shell, apply patch, MCP, computer use 등 | coding 중심 포지셔닝 | GPT-5.4가 one-model default에 더 적합하다 |
| 가장 두드러진 강점 | GDPval, SWE-Bench Pro, OSWorld, Toolathlon, BrowseComp | Terminal-Bench 2.0 | 전체는 GPT-5.4, 좁은 CLI는 Codex |
| 추천 대상 | 기본 경로, 장문맥, mixed workflow | terminal-first, 비용 민감한 코딩 | 실제로는 둘 다 두는 경우가 많다 |
중요한 포인트는 GPT-5.4를 단순히 “더 새로운 GPT-5.3-Codex”로 보면 안 된다는 점입니다. 기본 추천은 GPT-5.4로 넘어갔지만, 워크플로우 형태에 따라 GPT-5.3-Codex를 남겨두는 편이 더 합리적일 수 있습니다.
GPT-5.4에서 실제로 달라진 점

가장 큰 변화는 제품 포지셔닝입니다. OpenAI의 GPT-5.4 소개 페이지는 GPT-5.4가 GPT-5.3-Codex의 coding capabilities를 흡수한 첫 번째 mainline reasoning model 이라고 설명합니다. 이 문장은 단순한 홍보 문구가 아니라, OpenAI가 이제 기본 경로를 GPT-5.4 쪽으로 옮겼다는 신호입니다.
반대로 GPT-5.3-Codex 소개 페이지는 coding-first 정체성을 강조합니다. 속도, agentic coding, 실제 software engineering task, Codex 같은 작업감이 중심입니다. 그래서 GPT-5.4가 나온 뒤에도 “terminal-heavy 상황에서는 아직 Codex가 더 맞다”는 반응이 남는 것입니다.
현재 OpenAI API 모델 개요도 같은 방향을 가리킵니다. 복잡한 reasoning, coding, agentic task 는 GPT-5.4부터 시작하라고 하고, GPT-5.3-Codex는 coding-specialized option 으로 남깁니다. 이 차이는 출시 당일의 마케팅이 아니라 지금 기준의 제품 구조를 반영합니다.
또 하나 중요한 점은 2026년 3월 5일 GPT-5.4 출시 페이지가 surface 차이를 꽤 구체적으로 적어 둔다는 것입니다. GPT-5.4 Thinking 은 그날부터 ChatGPT Plus, Team, Pro 에 rollout 되었고, GPT-5.4 Pro 는 Pro 와 Enterprise 에 제공되며, Codex 의 GPT-5.4 는 실험적 1M 컨텍스트 지원을 포함합니다. 같은 페이지는 Codex 에서 표준 272K 컨텍스트를 넘는 요청이 정상 사용량의 2배로 계산된다고도 밝힙니다. 즉 기본 추천은 이미 GPT-5.4 쪽으로 이동했지만, 표면별 체감이 아직 완전히 같지 않은 이유도 공식 문서 안에서 설명됩니다.
따라서 가장 정확한 해석은 이렇습니다. GPT-5.4는 GPT-5.3-Codex를 기본 추천 위치에서는 대체했지만, 모든 워크플로우에서 완전히 지운 것은 아니다. 긴 컨텍스트, 검색, 패치, 툴 사용, 혼합형 reasoning 이 섞인다면 GPT-5.4가 낫고, 작업이 terminal-first 로 좁아질수록 GPT-5.3-Codex가 다시 의미를 가집니다.
SERP가 혼란스러운 이유는 ChatGPT model picker, Codex surface, API catalog 를 하나의 이야기로 섞는 글이 많기 때문입니다. 하지만 이 셋은 업데이트 속도도 다르고 장애 양상도 다릅니다. 비교 기사라면 이 레이어를 분리해서 설명해야 합니다.
어떤 벤치마크가 실제 개발에 중요한가
숫자 자체보다 중요한 것은, 그 숫자가 어떤 업무 모양과 연결되는가입니다.
| 벤치마크 | GPT-5.4 | GPT-5.3-Codex | 실무 의미 |
|---|---|---|---|
| GDPval | 83.0% | 70.9% | GPT-5.4는 모호하고 혼합된 작업에서 더 안정적이다 |
| SWE-Bench Pro | 57.7% | 56.8% | 어려운 software engineering 과제에서 GPT-5.4가 약간 앞선다 |
| OSWorld-Verified | 75.0% | 74.0% | system operation 계열에서도 GPT-5.4가 조금 더 강하다 |
| Toolathlon | 54.6% | 51.9% | 툴을 섞어 쓰는 workflow 에서 GPT-5.4가 유리하다 |
| BrowseComp | 82.7% | 77.3% | 검색과 근거 수집이 들어가면 GPT-5.4가 더 낫다 |
| Terminal-Bench 2.0 | 75.1% | 77.3% | CLI-heavy 업무는 여전히 GPT-5.3-Codex가 앞선다 |
여기서 놓치면 안 되는 점은, GPT-5.3-Codex가 이기는 한 항목이 사소한 틈새가 아니라는 것입니다. Terminal-Bench는 shell script, 파일 조작, 환경 작업, terminal debugging 같은 실제 작업과 가깝습니다. 그래서 terminal 중심 엔지니어에게는 이 차이가 숫자 이상으로 크게 느껴집니다.
반대로 업무가 코드 작성만으로 끝나지 않는다면 GPT-5.4의 장점이 살아납니다. 큰 코드베이스 이해, 다중 도구 사용, 검색과 증거 정리, 긴 컨텍스트 유지, mixed-task reasoning 같은 장면에서는 GPT-5.4의 종합 우위가 기본 모델 가치로 이어집니다.
실무 판단으로 옮기면 다음 두 문장으로 정리할 수 있습니다.
- 작업 대부분이 terminal-first 라면 GPT-5.3-Codex를 남길 가치가 있다.
- 작업이 mixed-task 라면 GPT-5.4를 기본으로 두는 편이 더 안전하다.
가격, 컨텍스트 창, 도구 폭의 차이

벤치마크 이후 실제 선택을 가르는 것은 얼마를 내고 무엇을 얻는가입니다.
| 항목 | GPT-5.4 | GPT-5.3-Codex | 중요한 이유 |
|---|---|---|---|
| Input | $2.50 / 1M | $1.75 / 1M | prompt-heavy 작업은 Codex가 훨씬 싸다 |
| Cached input | $0.25 / 1M | $0.175 / 1M | 반복 컨텍스트는 Codex가 유리하다 |
| Output | $15 / 1M | $14 / 1M | 이 차이만으로는 선택이 갈리지 않는다 |
| Context window | 1,050,000 | 400,000 | GPT-5.4가 큰 repo 와 긴 세션에 강하다 |
| 장문맥 주의 | 272K input 초과 시 2x input, 1.5x output | 비슷한 multiplier 공개 없음 | 큰 컨텍스트는 편하지만 공짜가 아니다 |
| Tools | search, file search, image generation, code interpreter, hosted shell, apply patch, skills, MCP, computer use, tool search | coding 중심 포지셔닝 | GPT-5.4가 broader default 역할을 수행하기 쉽다 |
비용 이야기에서 핵심은 output 이 아니라 input 입니다. 매일 큰 prompt 와 많은 코드 컨텍스트를 보내는 팀이라면 $2.50 대 $1.75 차이는 실제 운영비로 드러납니다. 반면 검색, 툴, 긴 문맥 reasoning 이 함께 필요한 팀이라면 GPT-5.4의 추가 비용이 설명 가능한 투자로 바뀝니다.
컨텍스트 차이도 단순히 “큰 쪽이 무조건 좋다”로 읽으면 안 됩니다. 1.05M 은 repo-scale 이해와 긴 세션에서 확실한 장점이지만, 272K input 을 넘기면 세션 전체가 더 비싸집니다. 즉 GPT-5.4는 필요할 때 크게 쓸 수 있는 default 일 뿐, 모든 큰 prompt 를 무작정 보내라는 신호는 아닙니다.
그리고 기본 모델 선택을 가장 크게 바꾸는 것은 tool surface 입니다. 지금의 coding workflow 는 단순한 생성이 아니라 검색, 패치, 파일 조작, 근거 확인까지 포함합니다. 이런 mixed workflow 를 한 모델에 맡기려면 GPT-5.4 쪽이 훨씬 자연스럽습니다.
워크플로우별로 어떤 모델을 써야 하나
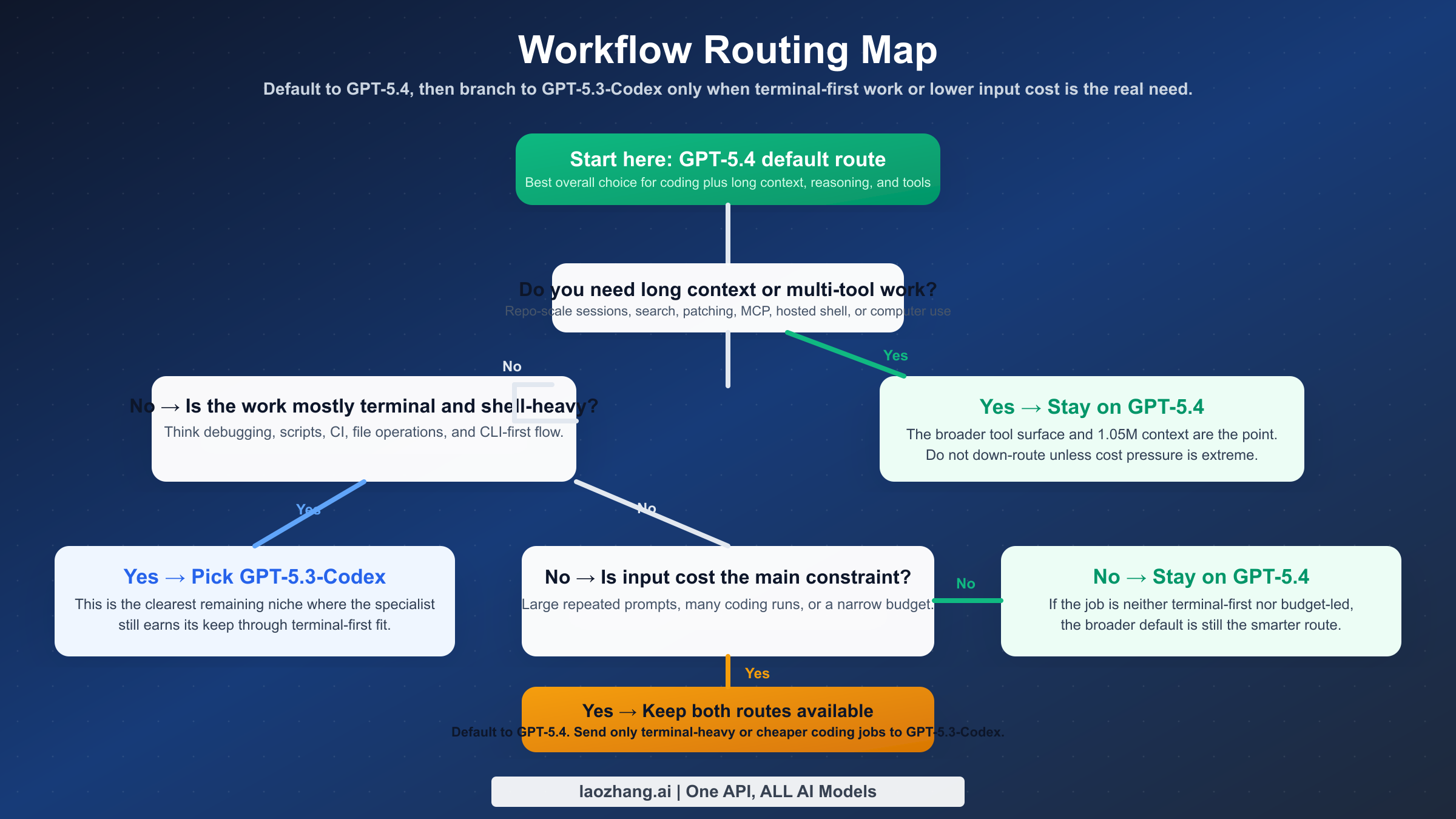
이 비교에서 사용자가 정말 알고 싶은 것은 “누가 더 강하냐”보다 “내 기본값은 무엇이냐”입니다.
| 워크플로우 | GPT-5.4 추천 | GPT-5.3-Codex 추천 | 이유 |
|---|---|---|---|
| 팀의 기본 모델 | 예 | 아니오 | GPT-5.4가 broader default 에 더 가깝다 |
| terminal-first 엔지니어링 | 조건부 | 예 | Codex는 CLI-heavy 에 아직 강하다 |
| 긴 repo 분석 | 예 | 드묾 | 1.05M context 차이가 크다 |
| multi-tool agentic workflow | 예 | 드묾 | GPT-5.4의 tool surface 가 넓다 |
| 입력 비용 민감한 코딩 | 조건부 | 예 | input 가격 차이가 실제로 크다 |
| 코드 밖의 일까지 섞인 작업 | 예 | 아니오 | GPT-5.4가 one-model default 역할을 잘한다 |
개인 개발자나 소규모 팀이라면 GPT-5.4를 기본으로 두는 것이 가장 무난합니다. 사전에 “이번 작업에 search 가 필요한가, patch 가 필요한가”를 계속 분기하지 않아도 되기 때문입니다.
platform, infra, DevOps 계열이라면 답이 더 갈립니다. shell script, CI, 로그 분석, terminal debugging 이 일상의 중심이라면 GPT-5.3-Codex가 체감상 더 잘 맞는 순간이 남아 있습니다. 게다가 input 비용도 낮아 유지하기 쉽습니다.
staff engineer, tech lead, 아키텍처 역할이라면 GPT-5.4의 기본값이 훨씬 설득력 있습니다. 이런 역할의 업무는 거의 항상 긴 문맥, 비교, 검색, 복합 reasoning 을 포함하기 때문입니다.
자동 라우팅이 가능한 환경이라면 최적해는 둘 중 하나가 아니라 둘 다 유지하는 것입니다. GPT-5.4를 기본 경로로 두고, terminal-heavy 또는 input-sensitive 작업만 GPT-5.3-Codex로 보내면 됩니다.
그래도 GPT-5.3-Codex를 남겨둘 이유
“GPT-5.4가 Codex를 흡수했으니 이제 Codex는 필요 없다”는 식의 결론은 제품 포지셔닝 수준에서는 맞아 보여도, 실제 engineering workflow 수준에서는 너무 거칩니다.
GPT-5.3-Codex를 남겨둘 이유는 적어도 네 가지입니다. 첫째, terminal-first 작업. 둘째, 입력 비용을 엄격히 관리해야 하는 경우. 셋째, search 나 computer use 가 필요 없는 좁은 coding workflow. 넷째, fallback route 입니다. 강한 coding model 을 두 줄로 갖는 것 자체가 시스템 안정성에 도움이 됩니다.
2026년 3월 커뮤니티에서 GPT-5.4 와 GPT-5.3-Codex 접근성이 일시적으로 흔들렸다는 보고도 있었습니다. 이런 내용은 operational friction 을 보여주지만, 장기 제품 방향이 바뀌었다는 증거는 아닙니다. 비교 글에서는 이 둘을 섞지 않는 편이 독자의 판단에 더 도움이 됩니다.
따라서 지금의 운영 규칙은 간단합니다. 주 경로는 GPT-5.4, 예외 경로는 GPT-5.3-Codex 입니다.
GPT-5.3-Codex에서 GPT-5.4로 옮길 때 체크리스트
이미 Codex 를 기본값으로 쓰고 있다면, 이행은 한 번에 갈아타기보다 단계적으로 하는 편이 낫습니다.
- 긴 문맥, 복잡한 reasoning, multi-tool task 의 기본 경로를 GPT-5.4로 바꾼다.
- GPT-5.3-Codex는 terminal-heavy debugging 과 저렴한 coding lane 으로 남긴다.
- 272K input 을 넘는 GPT-5.4 세션에는 비용 모니터링을 붙인다.
- 대표 작업 세 가지를 다시 테스트한다. repo-scale 분석, terminal workflow, multi-tool workflow 를 각각 비교한다.
- 일시적 access regression 을 대비한 fallback rule 을 문서화한다.
이 방식은 OpenAI 의 현재 방향을 따라가면서도 Codex 의 narrow advantage 를 버리지 않는 방법입니다.
FAQ
GPT-5.4가 GPT-5.3-Codex보다 완전히 낫나요
아닙니다. 전체적으로는 더 낫지만, terminal-heavy workflow 와 input 비용에서는 GPT-5.3-Codex가 여전히 의미가 있습니다. 특히 CLI 중심 업무라면 Codex의 장점은 아직 실무적입니다.
GPT-5.4의 가격 상승은 그만한 가치가 있나요
대부분의 경우 그렇습니다. 긴 컨텍스트, 넓은 tool surface, mixed-task reasoning 을 실제로 활용한다면 추가 비용은 설명 가능합니다. 반대로 짧은 coding run 과 shell work 만 한다면 차액의 의미는 작아집니다.
Codex와 API 기준으로 GPT-5.4가 사실상 후속 모델인가요
OpenAI의 포지셔닝 기준으로는 그렇습니다. 하지만 실제 workflow 에서는 GPT-5.3-Codex를 좁은 specialist 로 남겨둘 여지가 있습니다.
최근 접근 장애를 모델 선택에 반영해야 하나요
운영상 참고는 해야 하지만 과대평가할 필요는 없습니다. 핵심 판단 기준은 공식 모델 사양과, 당신의 작업이 terminal-first 인지 mixed-task 인지입니다.