
Claude API 응답이 HTTP 500이고 본문 type 값이 api_error라면, 먼저 요청이 Claude까지 도달한 뒤 내부 서버 분기에서 실패했다고 보고 움직이세요. 바로 key를 바꾸거나 prompt를 고치거나 provider를 갈아타기보다, 응답의 request_id 또는 request-id header, 실패 시각, model, endpoint, 인증 주체, SDK 또는 gateway 경로, base URL, network path, request shape를 보존해야 합니다.
2026년 5월 19일 기준 Claude Status는 전체 시스템 정상으로 표시되었고, 최근의 resolved 높은 실패율 incident도 함께 확인되었습니다. 이 상태 확인은 현재 공개 incident 분기를 좁혀 주는 신호일 뿐입니다. 독자의 model, 계정, region, gateway, workload가 모두 정상이라는 증명은 아니므로, 같은 경로의 증거를 남긴 뒤 작은 retry budget으로만 확인해야 합니다.
변수를 바꾸기 전에 아래 순서로 분기와 중단선을 맞추세요.
| 지금 보이는 신호 | 첫 행동 | 확인할 것 | 멈출 기준 |
|---|---|---|---|
HTTP 500의 내부 서버 분기가 반환됨 | request_id, 시각, model, endpoint, route를 저장하고 Claude Status를 확인 | 같은 경로가 회복되는지, 같은 분기로 반복되는지 | 작은 제한 재시도 뒤에도 반복되면 더 돌리지 않음 |
529 overloaded_error | capacity 압박으로 보고 재시도 압력과 동시성을 낮춤 | backoff와 부하 감소 뒤 사라지는지 | validation bug처럼 디버깅하지 않음 |
429 rate_limit_error | 사용량, quota, pacing, concurrency를 먼저 봄 | pace 조정 뒤 성공하는지 | 500 기본 대처처럼 key 교체하지 않음 |
504 timeout_error 또는 긴 작업 | streaming, batch, 요청 크기, timeout 설계를 조정 | 작은 요청 또는 streaming 요청이 끝나는지 | 반환된 500과 섞어 판단하지 않음 |
| 응답 전 connection, DNS, proxy, TLS, SDK timeout | base URL, proxy, firewall, VPN, SDK timeout을 별도로 검증 | 작은 known-good 요청이 API 응답을 받는지 | connection 실패에 500 재시도 규칙을 적용하지 않음 |
| 같은 경로에서 clean 500이 반복됨 | request ID, status timestamp, retry timeline, redacted request shape를 모아 에스컬레이션 | platform owner가 같은 event를 추적할 수 있는지 | secret, full prompt, auth header, private user data를 보내지 않음 |
하나의 분기가 충분한 증거를 주면 그 지점에서 멈추는 편이 낫습니다. 같은 경로에서 clean 500이 계속 나오는데 prompt, model, provider, gateway를 한꺼번에 바꾸면 다음 성공이 무엇 때문인지 알 수 없습니다.
깨끗한 500 api_error가 뜻하는 것
Anthropic API 오류 문서는 HTTP 500을 api_error로 매핑합니다. 이것은 인증 실패, billing 문제, permission 문제, malformed JSON, local network 실패를 기본 원인으로 가리키는 분기가 아닙니다. 요청이 API 계층까지 도달했고 Claude 쪽 내부 서버 분기로 반환되었다는 신호입니다.
응답에는 JSON body의 error.type, error.message, response-level request_id가 포함될 수 있고, API response header에는 request-id가 노출될 수 있습니다. 그래서 첫 번째 운영 습관은 "무엇을 바꿀까"가 아니라 "어떤 request가 실패했는지 보존할 수 있는가"입니다. ID가 없으면 support나 platform owner가 같은 event를 추적하기 어렵고, 내부 팀도 gateway, proxy, SDK, region 중 어디에서 달라졌는지 확인하기 어렵습니다.
clean 500이 항상 같은 원인이라는 뜻도 아닙니다. 일시적인 내부 서버 실패, 특정 model path 문제, upstream dependency 문제, routed gateway wrapping, 조직 내부 proxy 경로가 모두 호출자에게는 500처럼 보일 수 있습니다. 그러므로 중요한 질문은 "Claude가 완전히 down인가"가 아니라 "동일한 model, endpoint, auth owner, SDK/gateway route, base URL, network path, request shape에서 같은 분기가 반복되는가"입니다.
key rotation은 기본 대처가 아닙니다. 잘못된 key나 권한 문제는 보통 authentication 또는 permission 계열로 드러납니다. prompt rewrite도 첫 행동이 아닙니다. 형식이 틀린 request라면 대개 4xx 분기입니다. 물론 지나치게 큰 payload, tool call shape, attachment class, streaming mode가 2차 원인이 될 수는 있지만, 그 점검은 status와 request evidence를 보존한 뒤에 해야 진단선이 끊기지 않습니다.
Claude Code를 쓰는 경우도 같은 원칙입니다. Claude Code 오류 문서는 Claude Code가 API의 raw 5xx response body를 표시할 수 있음을 설명합니다. terminal에 API Error: 500이 보인다고 해서 root cause가 자동으로 local CLI 설정이 되는 것은 아닙니다. Claude Code는 같은 API 분기가 드러나는 표면일 수 있고, local auth state, MCP, tool execution, CLI version은 별도의 층으로 분리해서 봐야 합니다.
먼저 오류 분기를 맞춘다
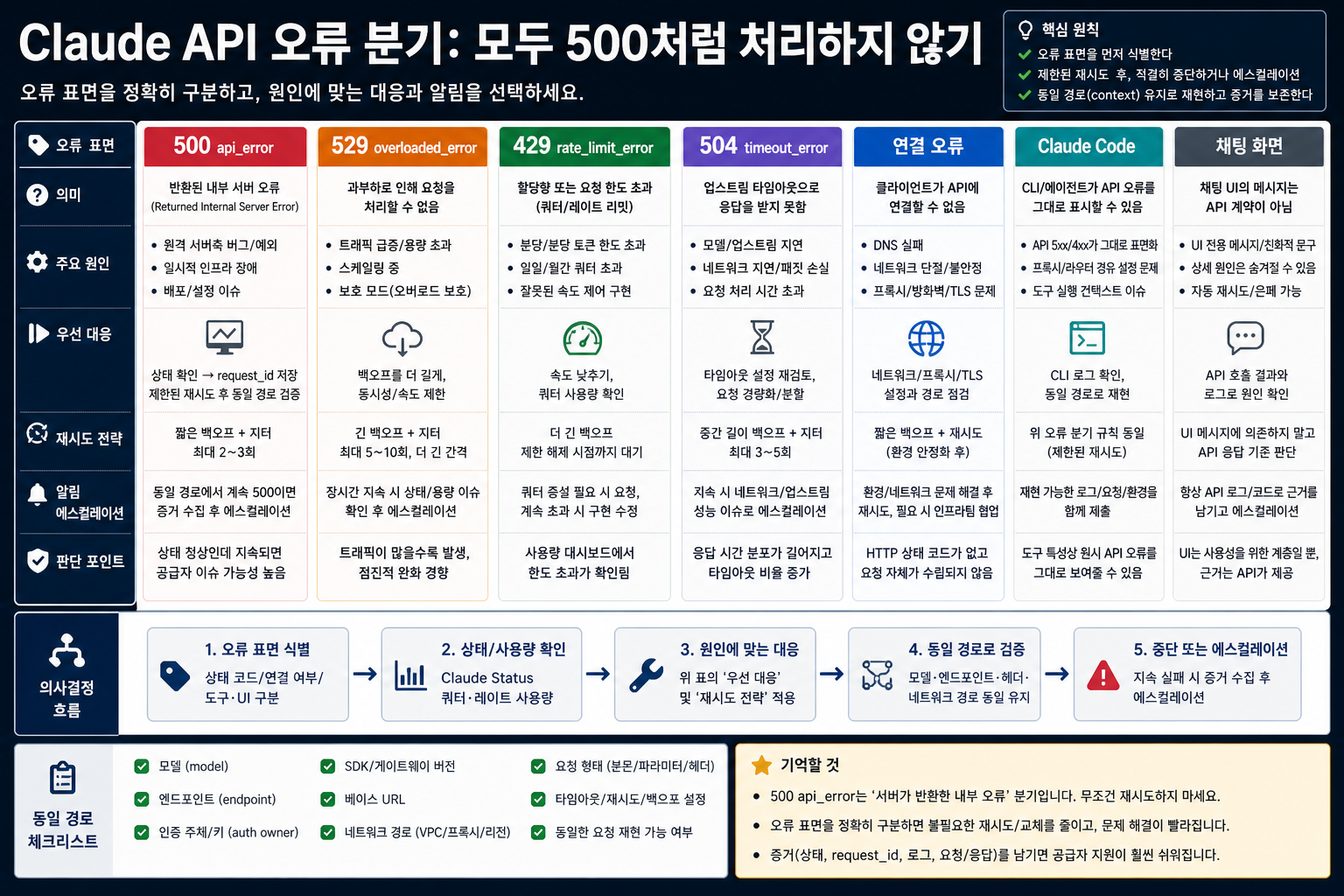
가장 빠른 복구는 가장 많은 행동을 하는 것이 아니라, 다른 분기를 섞지 않는 것입니다. 500 api_error, 529 overloaded_error, 429 rate_limit_error, 504 timeout_error, connection-layer failure는 모두 같은 제품 흐름을 멈추지만, 운영자가 해야 할 일은 다릅니다.
500 api_error는 반환된 HTTP response가 있고, body나 SDK exception이 내부 서버 분기를 가리킬 때 사용합니다. 이때 중요한 evidence는 status, request ID, model, endpoint, route입니다. usage plan 계산이나 prompt rewrite보다 status 확인과 제한 재시도가 먼저입니다.
529 overloaded_error는 capacity 압박입니다. 이 분기는 retry storm을 만들지 않도록 동시성을 줄이고 backoff를 길게 잡아야 합니다. 반환 branch가 529로 바뀌었다면 한국어 sibling인 Claude 529 Overloaded Error로 이동해 capacity 중심으로 다루는 편이 맞습니다.
429 rate_limit_error는 account 또는 organization의 pacing 문제입니다. quota, token volume, concurrency, batching, retry header를 확인해야 하며, 공개 status가 녹색이라는 이유만으로 local bug라고 확정하지도, 500처럼 무작정 retry하지도 않습니다.
504 timeout_error는 요청이 제때 끝나지 않은 분기입니다. 긴 작업은 streaming, Message Batches, 작은 request shape, timeout-aware client handling이 더 중요할 수 있습니다. 반환된 500 response가 아니라 timeout이면 "서버 내부 오류"라는 이름으로 덮지 말고 실행 방식부터 바꿔야 합니다.
connection branch는 API response 자체가 없을 때입니다. DNS, TLS, corporate proxy, firewall, VPN, wrong base URL, SDK timeout이 Claude 응답 전 단계에서 실패할 수 있습니다. 이때는 작은 known-good request, 다른 network path, base URL 검증이 먼저이고, 500 api_error retry budget을 적용하면 진단이 흐려집니다.
제한 복구 루프로 처리한다
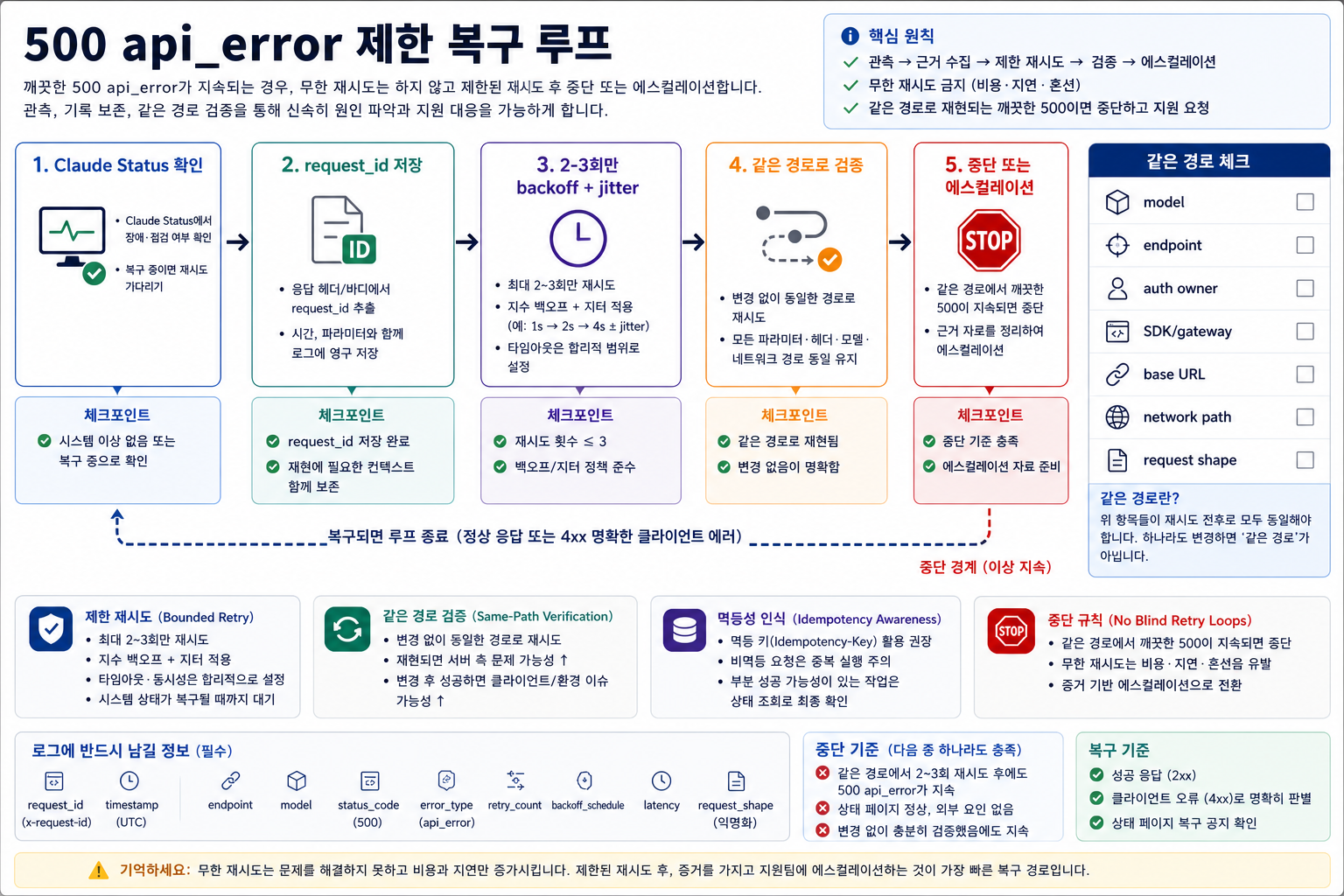
복구 루프는 짧아야 합니다. Status, evidence, bounded retry, same path, stop or escalation. 각 단계는 흔한 운영 실수를 막기 위해 존재합니다.
첫째, Claude Status를 확인하고 시각을 남깁니다. active incident가 있으면 반복 호출을 줄이고, 사용자-facing workflow를 degrade mode로 보호하고, 불필요한 retry 압력을 낮추는 것이 우선입니다. status가 정상이어도 독자의 exact model, account, region, gateway가 정상이라는 뜻은 아니므로 같은 경로 재현이 더 중요해집니다.
둘째, request evidence를 저장합니다. direct API call에서는 response body의 request_id와 header의 request-id를 모두 노립니다. SDK에서는 exception class, HTTP status, model, endpoint, base URL, SDK version, 경로 담당 층, internal correlation ID까지 남깁니다. Claude Code나 gateway workflow라면 raw response body, gateway trace ID, command context도 별도로 둡니다.
셋째, 작은 budget으로만 retry합니다. SDK가 이미 내부적으로 retry를 수행할 수 있으므로 application layer에서 다시 무제한 loop를 덧붙이면 side effect와 traffic pressure가 커질 수 있습니다. backoff와 jitter를 넣고, total elapsed time과 attempt 수를 제한하고, 같은 clean 500이 반복되면 멈춥니다.
넷째, 같은 경로로 확인합니다. 같은 model, endpoint, auth owner, SDK 또는 gateway route, base URL, network path, header shape, request shape를 유지해야 합니다. 한 번에 여러 변수를 바꾸고 성공하면 Claude가 회복된 것인지, gateway가 달라진 것인지, request가 더 작아진 것인지 알 수 없습니다.
다섯째, 멈출지 에스컬레이션할지 결정합니다. 한 번의 bounded retry로 회복되고 workflow가 idempotent라면 event를 기록하고 monitoring합니다. 같은 path에서 clean 500이 계속되면 더 이상 prompt나 key를 바꾸지 말고 evidence packet을 만듭니다.
tsasync function callClaudeWith500Budget(runClaude: () => Promise<unknown>) { const maxAttempts = 3; const baseDelayMs = 800; for (let attempt = 1; attempt <= maxAttempts; attempt += 1) { try { return await runClaude(); } catch (error: any) { const status = error?.status || error?.statusCode; const type = error?.error?.type || error?.type; if (status !== 500 || type !== "api_error") { throw error; } recordClaude500Evidence({ attempt, requestId: error?.request_id || error?.headers?.["request-id"], status, type, }); if (attempt === maxAttempts) { throw error; } const jitter = Math.floor(Math.random() * 400); await sleep(baseDelayMs * 2 ** (attempt - 1) + jitter); } } }
핵심은 delay 숫자가 아닙니다. handler가 모든 실패를 retryable로 취급하지 않고, sleep 전에 request evidence를 저장하며, 작은 횟수 뒤에는 반드시 멈춘다는 점입니다.
재시도 전에 부작용을 막는다
500 retry가 안전한지는 작업의 성격에 따라 달라집니다. read-only 요약, classification, 분석 job은 다시 실행해도 상대적으로 안전합니다. 반대로 결제, record write, 메시지 전송, ticket update, file creation, tool call을 포함하는 workflow는 retry 전에 idempotency protection이 필요합니다.
사용자-facing application에서는 "model call이 실패했다"와 "workflow side effect가 이미 일어났다"를 분리해야 합니다. model call 전 database write가 있었다면 replay 시 중복되지 않게 job ID를 고정해야 합니다. tool call이 email을 보내거나 구매를 실행할 수 있다면 final model response가 500이었다는 이유로 whole chain을 다시 돌리면 안 됩니다.
retry policy는 운영자가 읽을 수 있어야 합니다. 최소한 네 가지 숫자가 필요합니다: 최대 attempt 수, initial delay, backoff shape, maximum elapsed time. 짧은 transient failure는 그 안에서 회복될 수 있고, 지속 failure는 stop rule을 밟아야 합니다. 이 숫자가 없으면 "backoff로 재시도"가 팀마다 다르게 구현되는 모호한 말이 됩니다.
queue 기반 workflow라면 pending job과 completed side effect를 따로 저장하세요. user가 버튼을 두 번 누르거나 retry worker가 다시 실행되어도 같은 외부 action이 두 번 나가지 않아야 합니다. 비동기 batch라면 failed item만 replay하고, 이미 성공한 item의 output을 덮어쓰지 않는 방식이 필요합니다.
직접 API, Claude Code, 게이트웨이를 분리한다
route가 섞이면 500 대응은 금방 흐려집니다. direct Anthropic API call, Claude Code terminal flow, Workbench test, hosted gateway, corporate proxy, internal backend, browser chat surface는 모두 사용자에게 "Claude가 실패했다"처럼 보일 수 있습니다. 하지만 운영 evidence와 담당 층은 다릅니다.
direct API에서는 Anthropic service response와 application retry policy가 분리됩니다. Anthropic 쪽 request ID와 내부 correlation ID를 함께 보존해야 합니다. Claude Code에서는 terminal이 raw API response를 보여줄 수 있지만, local auth, MCP server, tool permission, CLI update가 별도의 실패층을 추가할 수 있습니다. gateway route에서는 base URL, provider selection, auth handoff, logging, pre-provider retry가 gateway에 의해 바뀔 수 있습니다.
그래서 같은 경로 검증에 route가 들어갑니다. direct Anthropic call은 clean 500인데 같은 payload가 gateway에서 성공한다면, 그 사실은 useful evidence입니다. 하지만 그 자체만으로 Anthropic 전체가 healthy라거나 unhealthy라고 결론 내릴 수는 없습니다. original failing request ID, gateway request ID, base URL, timestamp를 분리해야 각 담당자가 추적할 수 있습니다.
provider switch는 첫 번째 fix가 아닙니다. production availability를 위해 fallback route를 둘 수는 있지만, original route evidence를 보존하기 전에 전환하면 diagnostic line이 끊깁니다. 먼저 original failure를 저장하고, 그다음 business continuity가 필요하면 fallback을 사용하세요. fallback은 panic click이 아니라 운영 설계여야 합니다.
에스컬레이션 증거를 준비한다

반복되는 clean 500을 에스컬레이션할 때는 길고 감정적인 설명보다 짧고 추적 가능한 packet이 낫습니다. API key, bearer token, auth header, full private prompt, customer PII, raw file, confidential business data는 보내지 않습니다. metadata, redacted shape, request identifier만 보내도 correlation에는 충분한 경우가 많습니다.
| 항목 | 왜 필요한가 |
|---|---|
| status 확인 시각 | 공개 incident window와 맞는지 판단 |
request_id 또는 request-id | provider 또는 platform owner가 specific response를 추적 |
HTTP status와 error.type | 500 branch인지, 429/529/504/connection branch인지 확인 |
| model과 endpoint | model-specific 문제와 route 문제를 분리 |
| SDK, gateway, base URL, region | wrapper나 routed path가 개입했는지 확인 |
| retry timeline | bounded backoff 뒤에도 반복됐는지 확인 |
| 같은 경로 재현 | 변수를 바꾸지 않아도 failure가 반복되는지 확인 |
| redacted payload shape | request size, tool use, streaming, attachment class를 secret 없이 전달 |
| impact와 frequency | one-off noise인지 production degradation인지 판단 |
Claude Code에서 발생했다면 Claude Code version, command shape, terminal에 raw 5xx body가 보였는지, 같은 작업이 Workbench나 direct API에서도 실패하는지, auth/login symptom이 동시에 있었는지를 포함하세요. gateway 또는 internal service라면 gateway trace ID와 노출 가능한 Anthropic request ID를 둘 다 남깁니다.
packet은 짧아야 읽히고, 충분해야 추적됩니다. first failure time, status check time, attempts, same-path reproduction, current impact, recent changes를 시간순으로 적는 편이 좋습니다.
반복되는 500을 운영 이벤트로 다룬다
Claude에 의존하는 팀은 incident가 난 뒤에야 500 정책을 정하면 늦습니다. 첫 번째 control은 structured logging입니다. 실패한 요청마다 status, type, request ID, model, endpoint, route, elapsed time, attempt number, internal correlation ID가 남아야 합니다. 이 필드가 없으면 incident review는 기억에 의존하게 됩니다.
두 번째 control은 circuit breaker입니다. clean 500이 threshold 이상으로 늘어나면 high-volume non-critical job을 잠시 멈추고, 사용자-facing workflow는 명확한 degraded-state message로 보호하며, 반복 retry pressure를 줄입니다. 목표는 Claude를 한 번의 internal failure 뒤에 포기하는 것이 아니라, provider-side problem을 내 traffic storm으로 만들지 않는 것입니다.
세 번째 control은 idempotent job design입니다. 기다릴 수 있는 작업은 queue에 두고, replay 가능한 job은 deduplicate하며, non-repeatable action은 model call 전후 상태를 분리합니다. model call이 큰 workflow의 한 단계일 뿐이라면, final response가 500이라는 이유만으로 전체 workflow를 자동 재실행하지 마세요.
네 번째 control은 route별 dashboard입니다. direct API, gateway, Claude Code, browser product, internal service를 하나의 "Claude failure" 그래프로만 보면 실제 빨간 선을 찾기 어렵습니다. 한 route의 녹색 신호가 다른 route의 장애를 가리지 않도록 status, type, 경로 담당 층을 나누어 봐야 합니다.
다섯 번째 control은 escalation owner입니다. 누가 Claude Status를 확인하는지, 누가 support ticket을 여는지, 누가 concurrency를 줄일 수 있는지, 누가 fallback route를 켤 수 있는지, 누가 사용자에게 degraded-state를 설명하는지 정해 두어야 합니다. 다섯 명이 다섯 변수를 동시에 바꾸고 아무도 첫 request ID를 보존하지 않는 상황을 피하는 것이 핵심입니다.
자주 묻는 질문
Claude API 500이면 prompt가 잘못된 건가요?
보통은 아닙니다. clean HTTP 500과 api_error는 내부 서버 분기입니다. invalid prompt, malformed JSON, auth failure, permission issue는 대개 다른 branch로 드러납니다. 먼저 request evidence를 보존하고, 그다음 prompt size, tool shape, attachment class를 2차로 확인하세요.
API key를 바로 바꿔야 하나요?
기본 대처가 아닙니다. key rotation은 auth, permission, secret exposure가 의심될 때의 행동입니다. clean 500에서 key를 먼저 바꾸면 useful evidence가 사라지고 변수만 하나 더 늘어납니다. request ID와 같은 경로 검증을 먼저 하세요.
몇 번까지 retry해도 안전한가요?
작은 bounded budget을 쓰세요. SDK가 이미 retry하는지 확인한 뒤 application layer에서는 두세 번 정도의 attempt, backoff, jitter, maximum elapsed time을 명시하는 방식이 출발점입니다. non-idempotent workflow라면 더 빨리 멈추고, repeated clean 500이면 에스컬레이션으로 넘어갑니다.
Claude Status가 green이면 우리 쪽 버그인가요?
아닙니다. green status는 dated branch signal이지, exact model, account, region, route, gateway, workload가 모두 정상이라는 증거가 아닙니다. status가 green이면 public incident 가능성은 낮아지지만, 같은 경로 evidence가 더 중요해집니다.
500 api_error와 529 overloaded_error는 같은가요?
다릅니다. 둘 다 provider-side처럼 느껴질 수 있지만 official branch가 다릅니다. 500 api_error는 내부 서버 분기이고, 529 overloaded_error는 capacity 또는 overload 분기입니다. 529가 보이면 concurrency와 retry pressure를 먼저 다룹니다.
Claude Code에서도 같은 문제가 보일 수 있나요?
가능합니다. Claude Code는 raw API 5xx response body를 표시할 수 있습니다. terminal에서 500이 보이면 raw body, request ID가 있다면 그 값, command context, Claude Code version, route evidence를 남기고, local auth나 MCP symptom과 underlying API response를 분리하세요.
언제 support나 내부 platform owner에게 에스컬레이션해야 하나요?
같은 경로에서 clean 500이 반복되고 작은 retry budget 뒤에도 회복되지 않거나, 사용자-facing 영향이 크면 에스컬레이션합니다. status timestamp, request ID, model, endpoint, route, retry timeline, redacted request shape, impact를 포함하고 secret이나 full private prompt는 보내지 않습니다.
500이 나오면 다른 provider로 바꾸는 게 낫나요?
원래 실패 evidence를 저장한 뒤에만 그렇게 판단하세요. fallback route는 production continuity에 도움이 될 수 있지만, 최초 evidence 없이 전환하면 diagnosis가 끊깁니다. 먼저 request ID, status, same-path reproduction을 남기고, fallback은 운영 정책으로 사용해야 합니다.