プロダクトがより強い coding、computer use、重い agent behavior を必要とするなら GPT-5.4 mini を選ぶべきです。cheap で high-throughput な仕事のほうが workflow depth より重要なら GPT-5.4 nano が合います。
両モデルとも 400,000 の context window と 128,000 の max output を共有しているので、本当の tradeoff は context size ではありません。mini の stronger tool / benchmark profile に、実 workflow で追加費用を払う価値があるかどうかです。
要点まとめ
まずは結論を短くまとめます。
| モデル | 向いている仕事 | 選ぶ主な理由 | 選ばない主な理由 |
|---|---|---|---|
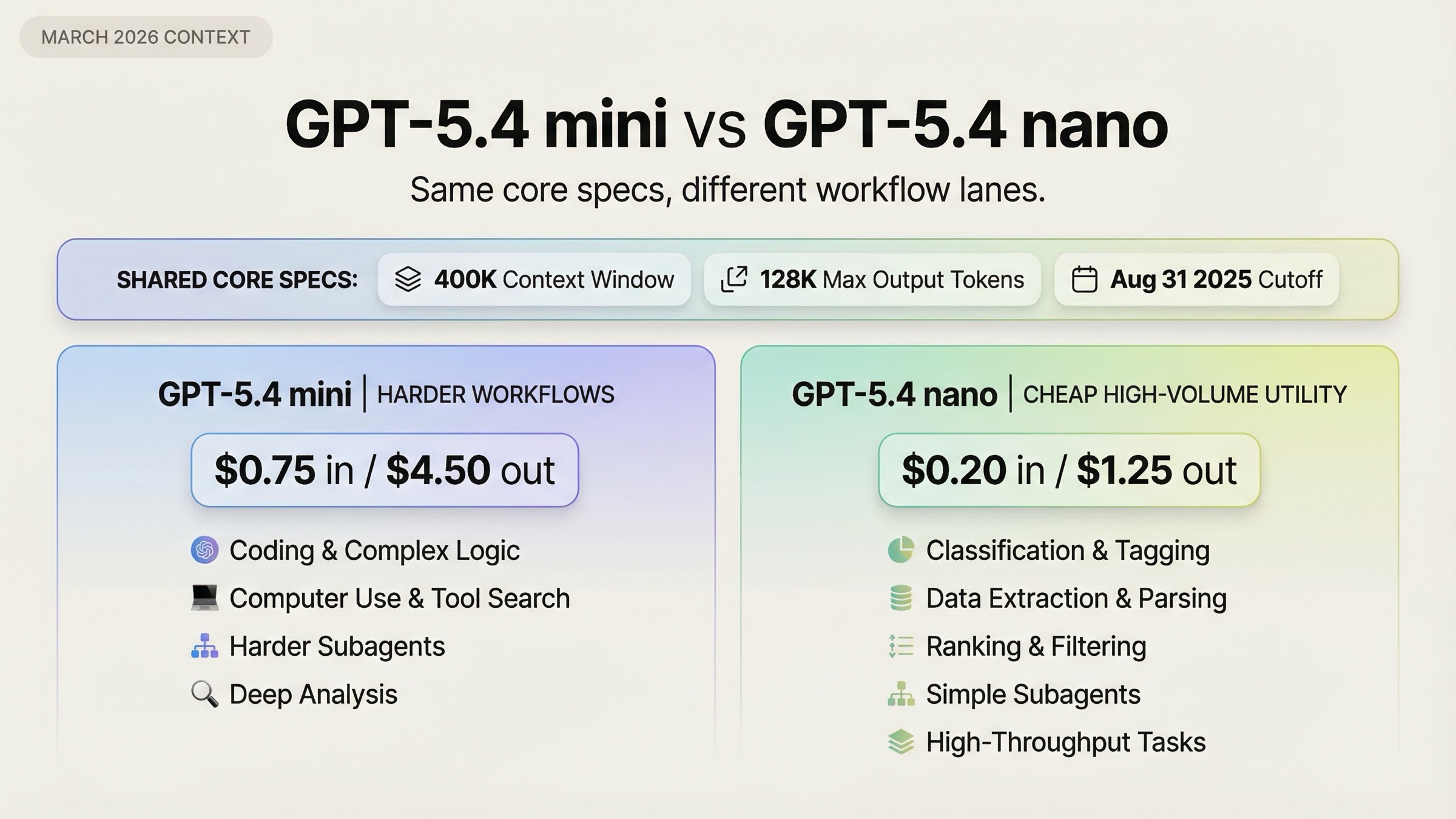
| GPT-5.4 mini | coding assistant、スクリーンショット中心の flow、browser/desktop automation、重めの subagents | coding・tool use・computer use が強く、computer use と tool search も使える | 1M tokens あたり input $0.75 / output $4.50 と高い |
| GPT-5.4 nano | classification、extraction、ranking、安価な routing、単純な subagents | input $0.20 / output $1.25 と安く、context と cutoff は mini と同じ | computer use と tool search がなく、重い workflow では弱い |
判断ルールをさらに短くすると次の通りです。
- コードを読んで動き、tool failure から復帰し、UI を扱う worker なら GPT-5.4 mini。
- 分類、抽出、並べ替え、ルーティング、安価な supporting task なら GPT-5.4 nano。
- 混在するシステムなら「どちらか一方」より「mini は重い lane、nano は安い lane」という分担が強い。
- ChatGPT の表示名だけで API 選定をしない。ChatGPT availability と API recommendation は別の面です。
本当の分岐点は context ではなく workflow の深さ
多くの比較記事は price、context、cutoff から入ります。ですが、このキーワードではそこだけ見ても実務判断になりません。
OpenAI の current model pages では、GPT-5.4 mini と GPT-5.4 nano はどちらも次を共有しています。
- 400K context window
- 128K max output
- 2025年8月31日の knowledge cutoff
- text と image input
つまり、決定は「どちらが大きい context を持つか」ではありません。紙の上の specs はかなり近いです。
本当の違いは、production の中で何をさせるかにあります。
GPT-5.4 guide は GPT-5.4 mini を high-volume coding、computer use、strong reasoning が必要な agent workflows 向けとし、GPT-5.4 nano を speed と cost が最重要の simple high-throughput tasks 向けとしています。この framing のほうが、実際の選定にはずっと役立ちます。
整理すると次のようになります。
| 質問 | Yes なら | 向くモデル |
|---|---|---|
| 実際の coding や codebase 作業が必要か | coding benchmark と agent reliability が重要 | GPT-5.4 mini |
| built-in computer use や UI ベースの操作が必要か | スクリーンショットや UI を軸に動く | GPT-5.4 mini |
| extraction、ranking、classification が中心で量も多いか | throughput と cost が最優先 | GPT-5.4 nano |
| 大きい planner 配下の cheap worker が欲しいか | 安価でも十分使える worker が欲しい | GPT-5.4 nano |
この整理を使うと、価格差の意味も見えます。mini は context が大きいから高いのではなく、より強い tool-and-agent worker として課金されているのです。
価格・rate limits・ツール対応を横並びで見る
ベンチマークの前に、まず価格差を正面から見ておくべきです。
2026年3月20日時点で確認した GPT-5.4 mini model page と GPT-5.4 nano model page の主要情報は次の通りです。
| 項目 | GPT-5.4 mini | GPT-5.4 nano |
|---|---|---|
| Input 価格 | $0.75 / 1M tokens | $0.20 / 1M tokens |
| Cached input | $0.075 / 1M tokens | $0.02 / 1M tokens |
| Output 価格 | $4.50 / 1M tokens | $1.25 / 1M tokens |
| Context window | 400K | 400K |
| Max output | 128K | 128K |
| Knowledge cutoff | 2025-08-31 | 2025-08-31 |
| Snapshot | gpt-5.4-mini-2026-03-17 | gpt-5.4-nano-2026-03-17 |
つまり mini は input で約 3.75 倍、cached input でも約 3.75 倍、output で 3.6 倍ほど高い計算です。これは設計判断に入れるべきレベルの差です。
rate limits は想像ほど離れていません。OpenAI の compare models page では、主な差は lower paid tiers に集中しています。
| Tier | GPT-5.4 mini TPM | GPT-5.4 nano TPM |
|---|---|---|
| Tier 1 | 500,000 | 200,000 |
| Tier 2 | 2,000,000 | 2,000,000 |
| Tier 3 | 4,000,000 | 4,000,000 |
| Tier 4 | 10,000,000 | 10,000,000 |
| Tier 5 | 180,000,000 | 180,000,000 |
したがって paid production では、rate limit 差よりも task fit と unit cost のほうが本質的です。
より重要なのは tools です。
| 機能 | GPT-5.4 mini | GPT-5.4 nano |
|---|---|---|
| Web search | Yes | Yes |
| File search | Yes | Yes |
| Image generation tool | Yes | Yes |
| Code interpreter | Yes | Yes |
| Hosted shell | Yes | Yes |
| Apply patch | Yes | Yes |
| Skills | Yes | Yes |
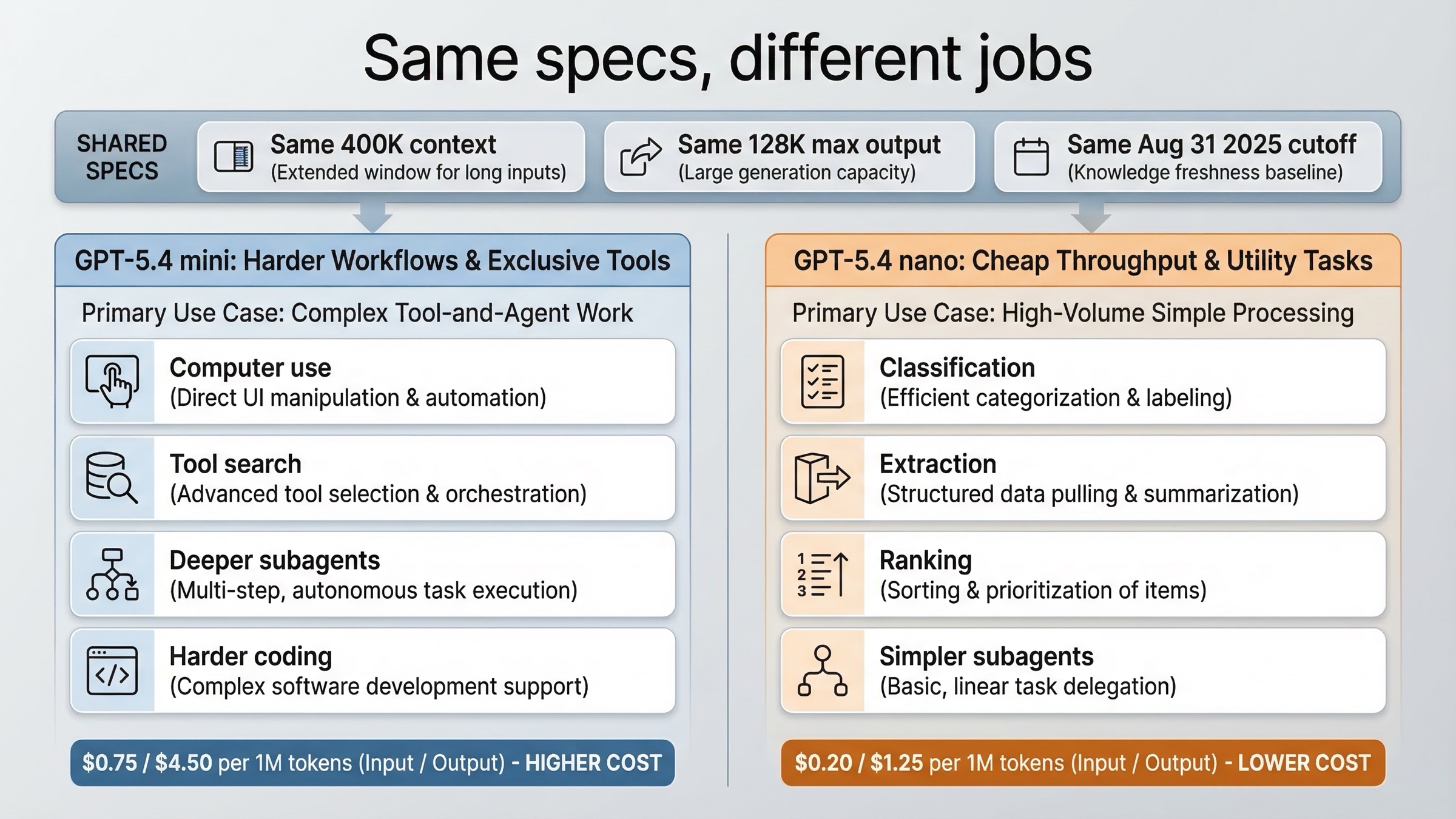
| Computer use | Yes | No |
| MCP | Yes | Yes |
| Tool search | Yes | No |
ここが実務上かなり重要です。
nano は「極端に削られた cheap model」ではありません。hosted shell、apply patch、skills、image generation まで使えるので、狭い agent task の worker としては十分に戦えます。
ただし mini は、より重い agent workflow を決定的に分ける 2 つの capability を持っています。computer use と tool search です。スクリーンショットを見ながら software を扱う、または広い tool surface の中で適切な道具を選ぶ必要があるなら、この差はそのままアーキテクチャ差になります。
だからこの比較は、単なる「安い vs 強い」に落とし込むべきではありません。あなたの product が、その追加 workflow capability に本当にお金を払う価値があるか。そこが本質です。
意思決定に効く benchmark の差
OpenAI の 2026年3月17日の launch post は、mini と nano の最もわかりやすい公式比較です。
| Launch post の benchmark | GPT-5.4 mini | GPT-5.4 nano | 実務上の意味 |
|---|---|---|---|
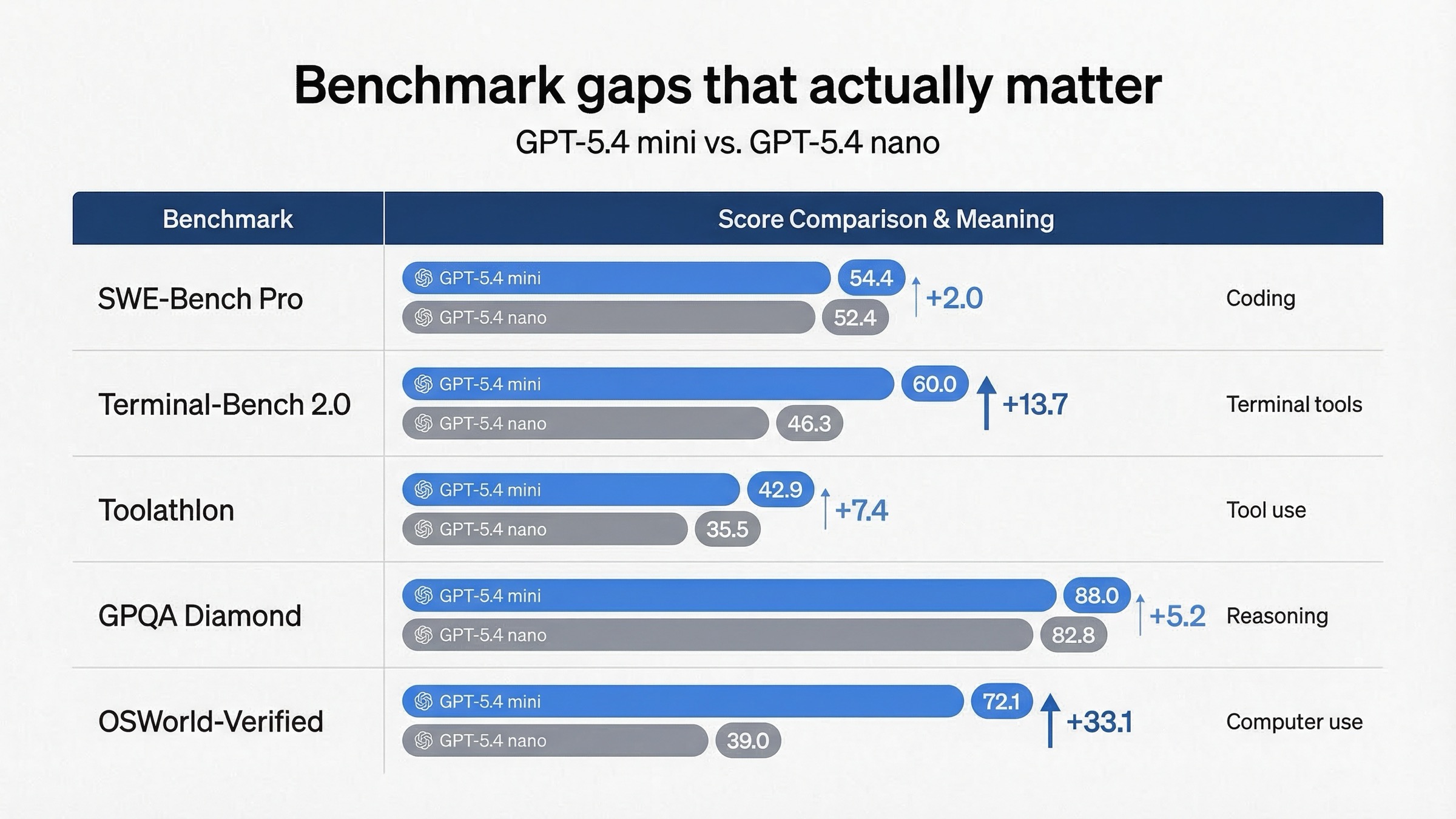
| SWE-Bench Pro (Public) | 54.4% | 52.4% | real software issue 解決では mini がやや強い |
| Terminal-Bench 2.0 | 60.0% | 46.3% | terminal-heavy な tool work では mini がかなり有利 |
| Toolathlon | 42.9% | 35.5% | tool use reliability は mini が高い |
| GPQA Diamond | 88.0% | 82.8% | 難しい reasoning で mini に余裕がある |
| OSWorld-Verified | 72.1% | 39.0% | computer-use 系 workflow は mini が別格に近い |
ここで大事なのは 3 つです。
1 つ目は、mini の優位が全方向で同じ重さではないことです。SWE-Bench の差は実在しますが、すべての coding task が自動的に mini 必須になるほどではありません。軽い補助作業なら nano でも成り立つ余地があります。
2 つ目は、mini が本当に差を広げているのは terminal-heavy、tool-heavy、computer-use-heavy な仕事だということです。これは tool-support の差と同じ方向を向いています。
3 つ目は、nano が弱いのではなく、cheap lane のために十分高い capability floor を持っていることです。OpenAI のメッセージは明確で、「簡単な supporting task を安く大量に回すなら nano、subtask でも重くなるなら mini」です。
現在の SERP が弱いのは、ここを言語化していない点です。数字はあっても、どの数字が budget decision を動かすかが書かれていません。
実務ルールとしては次で十分です。
- tool failure や slow recovery が直接 UX や engineering cost を傷つけるなら mini に払う価値が高い。
- task が安く、狭く、反復的で、mini の追加余力をほとんど使わないなら nano が正しい。
GPT-5.4 mini に追加コストを払うべき場面
GPT-5.4 mini が本当に効くのは、モデルが cheap classifier ではなく、より強い operator のように振る舞うべき場面です。
最もわかりやすいのは coding assistants です。OpenAI は mini を coding workflows 向けに置いており、benchmark もそれを支えています。codebase を横断し、複数ファイルを見て、failed tool call から立て直し、diff を理解し、coding harness 内で安定して働く必要があるなら、mini のほうが defensible な default です。
次は computer use や screenshot-heavy workflows です。ここは mini が最も大きく差を付けている領域です。UI を読み、software 越しに操作し、密度の高いスクリーンショットを理解するなら、mini は単なる上位互換ではなく、このペアの中で唯一 built-in computer use を持つモデルです。
3 つ目は heavier subagent tasks。launch post は Codex 的な委譲構造を明示しています。大きいモデルが planning を担当し、小さいモデルが subtasks を並列処理する。その subtasks がそれでも coding judgement や tool choice を要するなら、mini のほうが worker として向いています。
4 つ目はより複雑な tool ecosystem。tool search は見落としやすいですが、tools や namespaces や MCP surfaces が増えると一気に効いてきます。toolset が小さく固定なら nano でも良いですが、複雑になるほど mini が安全です。
以下の条件が多いなら、GPT-5.4 mini を選ぶ価値が高いです。
- モデルが本格的な coding 作業をする。
- computer use や screenshot-grounded reasoning が必要。
- tool failure がそのまま retries、latency、trust loss になる。
- agent system の worker だが、subtask 自体も簡単ではない。
- token 単価より hidden engineering cost のほうが重い。
最後の点はとても重要です。再試行、fallback、複雑な prompts、手動介入、ユーザー待ち時間もコストです。mini はそうした hidden cost を下げられるときに価値が出ます。
GPT-5.4 nano が正しい default になる場面
GPT-5.4 nano は「予算不足だから選ぶモデル」ではありません。もともと cheap lane に置くべき job に対して、正しい default になるモデルです。
OpenAI は nano を classification、data extraction、ranking、そして simpler coding subagents 向けと明示しています。これを production task に言い換えると、例えば次のようなものです。
- user intent や support ticket の分類
- テキストから構造化フィールドを抜く extraction
- 候補結果の ranking や filtering
- 後続システムへの routing
- 大きい planner の下で動く安価な supporting task
こうした仕事では、より高い benchmark ceiling よりも、低コスト・高 throughput のほうが product value に直結しやすくなります。
nano は、システム全体は複雑でも、その task 自体は浅いときにも向いています。例えば、より大きい planner や強い worker が難しい部分を担当し、nano に次のような仕事だけを任せるケースです。
- tool output の要約を planner に返す
- candidate documents を絞り込む
- downstream rule engine のための field extraction
- cheap validation や routing
つまり nano は「弱い万能モデル」ではなく、「単純 lane に置く安い specialist」と考えると理解しやすいです。
以下の条件が多いなら、GPT-5.4 nano を選ぶべきです。
- task が狭く、反復的で、構造的に単純。
- edge-case capability より unit economics を優先。
- built-in computer use は不要。
- 大きい tool surface に対する tool search は不要。
- より大きい coordinator 配下の supporting worker を設計している。
要するに、あなたの問いが「どちらが強いか」ではなく、「最も安く、なおかつ十分に役立つのはどちらか」なら、nano が答えになります。
多くの system では、正解は片方ではなく両方
このパートこそ、多くの comparison page が落としているのに、実務では最も効く部分です。
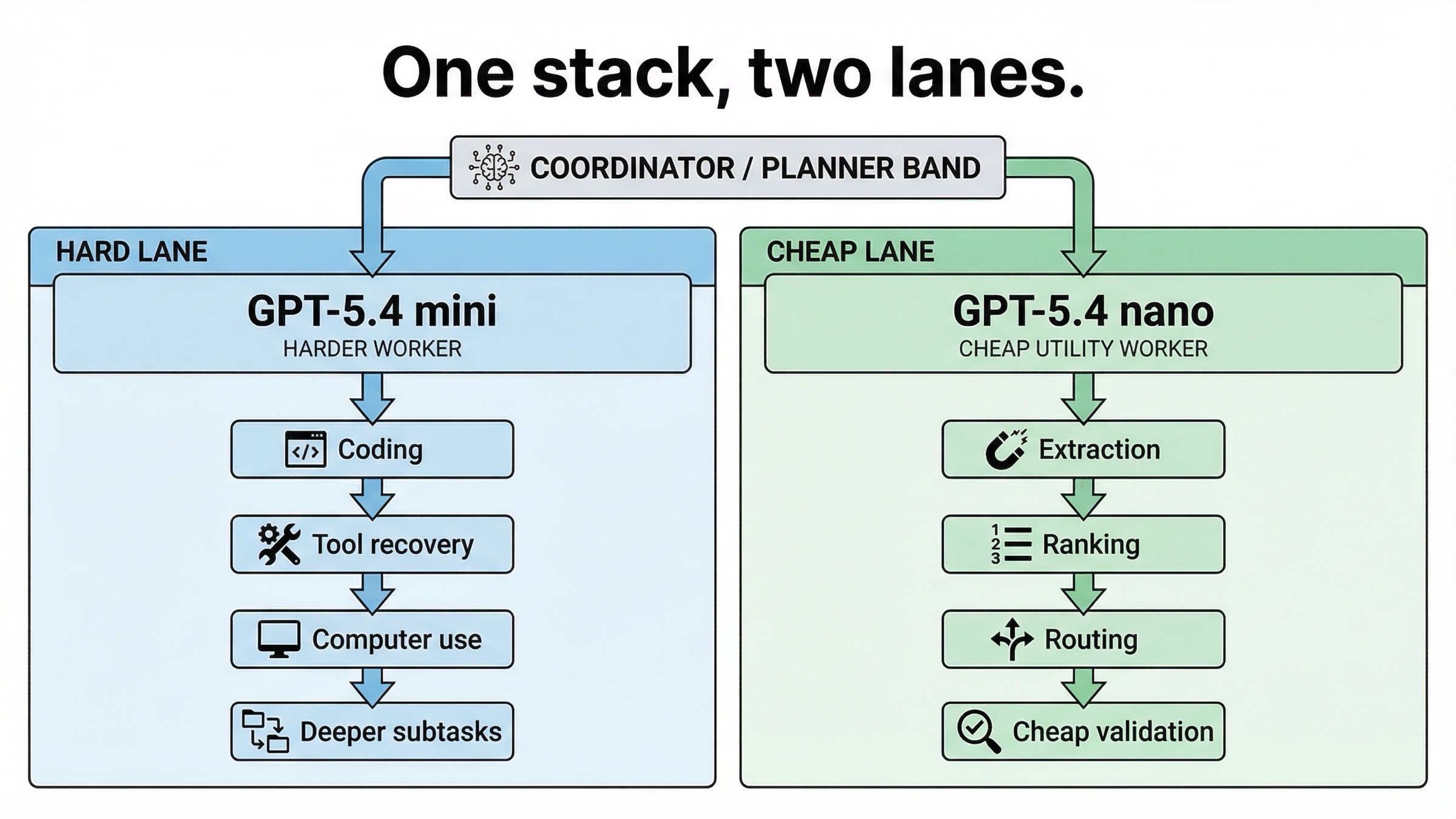
もし product に request type が 1 種類しかないなら、mini か nano を選べばいいでしょう。ですが実際の system は少なくとも 2 本の lane を持つことが多いです。
- coding、tool recovery、screenshot interpretation、より深い reasoning が入る heavy lane
- extraction、ranking、classification、support task が中心の cheap lane
その 2 つの性格がはっきり違うなら、1 つのモデルで両方を無理に抱えるより、lane ごとに分けたほうが良いことが多いです。
実務的な split は次のようになります。
| Lane | 向くモデル | 理由 |
|---|---|---|
| planner の近くで動く stronger worker | GPT-5.4 mini | coding depth、tool reliability、computer-use 系の仕事に強い |
| cheap helper / support worker | GPT-5.4 nano | 狭くて繰り返しの多い task で economics が良い |
これは launch post が subagents で示している設計にも一致します。mini はより強い worker、nano はより安い utility lane を担当する。subtask が十分に単純なら、この分担が最も筋が通っています。
したがって、チームが「mini に統一するか、nano に統一するか」で悩んでいるなら、より良い答えは routing logic を先に決め、その後に model-per-lane を固定する ことです。
API、Codex、ChatGPT を混同しない
この keyword は、異なる product surface から検索が流れてくるため、混乱が生まれやすいです。
API については公式の答えはシンプルです。
- GPT-5.4 mini は API で利用可能。
- GPT-5.4 nano も API で利用可能。
Codex については launch post がもっと具体的です。GPT-5.4 mini は Codex app、CLI、IDE extension、web にわたって利用可能で、Codex は GPT-5.4 mini subagents に subtasks を委譲できます。GPT-5.4 nano は同じように Codex の主要 surface model としては説明されていません。
ChatGPT はさらに誤読しやすい領域です。launch post には GPT-5.4 mini が一部 ChatGPT path で使えるとありますが、現在の Help Center article では、logged-in users の default line は GPT-5.3、paid tiers が手動で選ぶのは GPT-5.4 Thinking と説明されています。つまり ChatGPT で見える名前を、そのまま API recommendation に重ねるべきではありません。
本当に API model を選ぶなら、model pages と launch post を基準にする。ChatGPT 側の availability や picker を知りたいなら Help Center を基準にする。名前は似ていても、意思決定面は別です。
FAQ
GPT-5.4 mini は常に GPT-5.4 nano より良いですか?
強さでは上ですが、常に正しい choice とは限りません。単純な high-volume task では、OpenAI 自身が nano をその lane 向けに推しているので、nano のほうが正しい場合があります。
coding にはどちらを使うべきですか?
本格的な coding work なら mini です。より大きい coding system の中の単純な supporting subagent なら nano でも足りる場合があります。task が重くなるほど答えは mini に寄ります。
extraction や ranking にはどちらですか?
OpenAI は nano を classification、data extraction、ranking 向けに明示しています。したがって、まず nano からテストするのが合理的です。
GPT-5.4 nano は tools を使えますか?
使えます。nano でも web search、file search、image generation、code interpreter、hosted shell、apply patch、skills、MCP は使えます。mini との差で大きいのは computer use と tool search です。
新しいチームは mini と nano のどちらから始めるべきですか?
名前ではなく task から始めるべきです。coding-heavy や agent-heavy なら mini、cheap throughput なら nano、両方あるなら両方を lane ごとに使うのが正解です。
最終提案
チームに 1 行で伝えるなら、こうです。重い coding と agent workflow には GPT-5.4 mini、安価な high-volume utility work には GPT-5.4 nano が正しい default です。
この結論は、2026年3月20日時点で確認した次の 5 点に基づきます。
- 両モデルは同じ context window、max output、knowledge cutoff を共有する。
- nano は大幅に安い。
- mini は coding、tool use、computer use に関わる benchmarks で強い。
- mini は computer use と tool search を持ち、nano は持たない。
- OpenAI は nano を classification、extraction、ranking、より単純な supporting subagents に推奨している。
したがって、本当の問いは「どちらが強いか」ではありません。強いのは mini です。判断すべきなのは、あなたの task が mini を必要とするほど重いのか、それとも nano で十分なほど単純なのかです。多くの production system では、正解はそれぞれに別の lane を持たせることです。