
workload が本当に難しく、tool-sensitive で、engineering-heavy なら Gemini 3.1 Pro Preview にお金を払う価値があります。Pro-level reasoning が要らない high-volume、latency-sensitive、cost-sensitive な仕事なら Gemini 3.1 Flash-Lite を default にするべきです。
これはまず routing の問題です。Pro は単なる 'benchmark が高いラベル' ではなく、Flash-Lite も単なる cheap copy ではありません。別々の production lane のために作られているので、答えはあなたが本当に必要な lane に依存します。
要点まとめ
実務向けに一文で言うなら、こうです。
- 難しいエージェント処理、ソフトウェアエンジニアリング、ツール精度が重要な処理は Gemini 3.1 Pro Preview。
- 翻訳、抽出、分類、軽量ルーティング、高頻度の安い処理は Gemini 3.1 Flash-Lite。
- 負荷が混在するなら、どちらか一方に寄せずに分流する。
2026年3月20日時点の公式情報は次の通りです。
| 項目 | Gemini 3.1 Pro Preview | Gemini 3.1 Flash-Lite | 実務上の意味 |
|---|---|---|---|
| 現在の状態 | Preview | Preview | どちらも無条件の GA 既定盤ではない |
| 無料枠 | なし | あり | Flash-Lite は検証やステージングに向く |
| 標準 input 価格 | $2.00 / 1M tokens | $0.25 / 1M tokens | Pro は 8 倍高い |
| 標準 output 価格 | $12.00 / 1M tokens | $1.50 / 1M tokens | output も 8 倍差 |
| Batch 価格 | $1.00 in / $6.00 out | 無料枠あり、その後 $0.125 in / $0.75 out | Flash-Lite は安い非同期処理向き |
| 入力上限 | 1,048,576 tokens | 1,048,576 tokens | コンテキストサイズでは差がつかない |
| 最大 output | 65,536 tokens | 65,536 tokens | 出力上限でも差はつかない |
| Tier 1 Batch queue 上限 | 5,000,000 tokens | 10,000,000 tokens | 大規模 queue は Flash-Lite の方が扱いやすい |
| 向いている用途 | 難しい Agent、software engineering、精密な tool flow | 翻訳、抽出、分類、軽量エージェント、大量トラフィック | ここが本当の分担ポイント |
この結論は、公式の pricing、Gemini 3.1 Pro Preview モデルページ、Gemini 3.1 Flash-Lite モデルページ、公開 rate limits ページ、そして DeepMind の Gemini 3.1 Pro と Gemini 3.1 Flash-Lite の model card をもとにしています。
これはコンテキスト勝負ではなく、ルーティング勝負
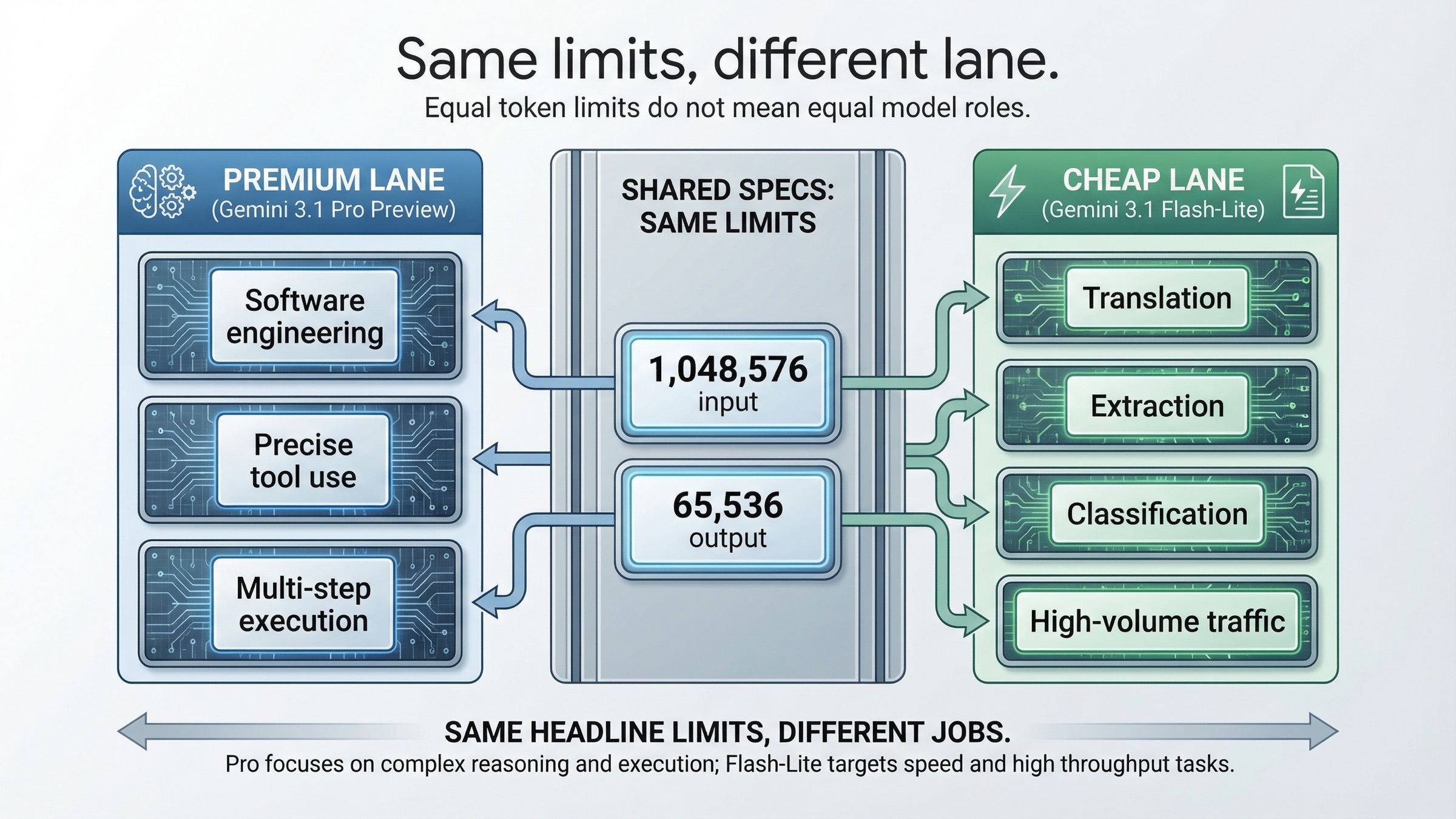
この比較で最もありがちな誤解は、Pro の方が高いのだから全部 Pro に寄せるべきだ、あるいは Flash-Lite はただの縮小版だ、というものです。どちらも現行ドキュメントの読み方としては雑です。
まず共通点を見ると、両方のモデルページに 1,048,576 input tokens と 65,536 output tokens が明記されています。つまり、ここでは「より大きいコンテキストを買う」のでも「より長い output を買う」のでもありません。だからこそ、この比較は上限値比較として書くべきではありません。
本当の違いは、より高い価格で何を買っているのか、より安いモデルを選ぶことで何を捨てているのかにあります。
Gemini 3.1 Pro Preview のページ は、thinking、token efficiency、factual consistency、software engineering behavior、precise tool usage、reliable multi-step execution を前面に出しています。これは明らかに高付加価値タスク向けの言い方です。
Gemini 3.1 Flash-Lite のページ は別のことを言っています。高頻度の軽量タスク、翻訳、分類、単純抽出、低遅延、high-volume agentic tasks。つまり、Pro の廉価版ではなく、安いレーンを担当する別最適化です。
だから役に立つ問いはこうです。
- 強い reasoning と安定した tool behavior が本当に必要な処理はどれか。
- 安いレーンで十分な処理はどれか。
- ワークロードは単一か、Flash-Lite を既定盤にして難しいものだけ Pro に上げるべきか。
この見方を取ると、公式の価格・上限・用途の情報がずっと整理しやすくなります。
2026年3月20日時点の価格、Batch 経済性、公開限度の現実

この比較で最も重い事実は価格です。
公式 pricing ページ では、Gemini 3.1 Pro Preview には無料枠がありません。200k prompt tokens までは $2.00 / 1M input、$12.00 / 1M output。200k を超えると $4.00 input、$18.00 output に上がります。Batch では安くなりますが、それでも $1.00 input、$6.00 output です。
Flash-Lite はまったく別の価格帯です。無料枠があり、標準価格は $0.25 input、$1.50 output。Batch では $0.125 input、$0.75 output まで下がります。
つまり、標準 input も output も Pro は 8 倍 高いということです。したがって Pro は「確かに高いが、そのぶん人手や失敗を減らして元が取れる」場面でしか既定盤になるべきではありません。普通の翻訳、抽出、分類、定型処理まで全部 Pro に乗せるのは、ほとんどの場合やりすぎです。
公開 rate limits ページ も同じ方向を示します。現在のページは RPM や TPM を 1 枚の固定表で示さず、AI Studio で現在値を確認するよう案内しています。つまり、記事に「永久不変の公開 RPM」を書き切るのは正確ではありません。ただし、依然として役立つ公開情報があります。Tier 1 Batch enqueued token limit です。
そこでは現在、
- Gemini 3.1 Pro Preview: 5,000,000
- Gemini 3.1 Flash-Lite: 10,000,000
とされています。
これは、実運用で大量の非対話処理を回すチームにはかなり重要です。翻訳、抽出、分類、要約、ルーティングなど、多くの本番負荷はチャットではなくバックグラウンドで流れています。そういう処理では、Flash-Lite は安いだけでなく queue にも強いということです。
grounding も Pro に有利ではありません。pricing ページでは、両モデルとも 月 5,000 grounding prompts まで無料、その後は Search も Maps も $14 / 1,000 queries です。したがって経済面の結論は変わりません。
要するに、安いレーン向けの仕事は Flash-Lite に残すのが基本です。
Gemini 3.1 Pro Preview が本当に元を取る場面
この話を「安い方がいつも正しい」と読むのもまた間違いです。Pro が高くても十分に価値を出す仕事は確実にあります。
Gemini 3.1 Pro Preview のページは、software engineering、precise tool use、reliable multi-step execution を強く打ち出しています。DeepMind の Gemini 3.1 Pro model card は 2026年2月19日 公開で、Humanity's Last Exam、GPQA Diamond、Terminal-Bench 2.0、SWE-Bench Verified、APEX-Agents などの難しい評価で上位寄りの物語を与えています。
もちろん、これらの benchmark はそのまま自分の production に比例移植できるものではありません。ただ、方向性は十分です。次のような仕事では Pro の価値が出やすいです。
- 多段の Agent plan
- tool-heavy な coding workflow
- 1 回の誤った tool decision が連鎖失敗を起こす処理
- 難しい reasoning が必要で、安い再試行でも結局高くつく処理
- 1 回目の回答品質がそのまま人間のレビュー時間に直結する engineering タスク
もうひとつ実務的なシグナルとして、Pro のドキュメントには gemini-3.1-pro-preview-customtools というラインがあります。これは「すべてのエージェントは Pro であるべき」という意味ではありませんが、Google 自身がより重いツールワークフローを Pro 側に置いていることを示します。
Reddit の "I had to switch to 3.1 Pro Preview Custom Tools for my Agent" も、公式仕様ではないにせよ、どんな悩みがこの比較の裏にあるかをよく表しています。多くの検索者は benchmark の数字遊びではなく、実際の tool workflow をどう安定させるかで悩んでいます。
だから Pro の正しい理解はこうです。
悪い回答のコストがトークンコストよりはるかに高いときにだけ、Pro を使う。
これが成り立たないなら、Pro は既定盤ではなく昇格レーンであるべきです。
Gemini 3.1 Flash-Lite を安い既定レーンとして残すべき理由
Flash-Lite が過小評価されやすいのは、多くの比較記事が「より賢いモデルを既定盤にする」という発想で書かれているからです。しかし、Google の現行ドキュメントは Flash-Lite をそういう位置には置いていません。Flash-Lite は、安く大量に回す現実的な仕事のためのモデルです。
Gemini 3.1 Flash-Lite Preview と Gemini 3.1 Flash-Lite model card が共通して示している代表用途は、
- 翻訳
- 分類
- 単純抽出
- 低遅延処理
- 高頻度呼び出し
- 大規模非同期 queue
- 軽量エージェント
です。これは本番トラフィックのかなり大きな割合を占めます。
入力が比較的素直で、出力もある程度制約される処理が中心なら、Flash-Lite は「安い代替案」ではなく「正しい既定盤」です。抽出、ラベリング、翻訳、定型要約、単純なルーティングなどでは、Pro の能力は高価すぎることが多いからです。
無料枠もこの結論をさらに強めます。多くのチームにとって無料枠は「お試し」ではなく、
- プロンプトテンプレートの確認
- staging の smoke test
- routing 変更の検証
- 小規模回帰テスト
を安く回すための運用レーンです。そう考えると、Flash-Lite は単なる廉価版ではなく、実務上かなり重要な役割を持っています。
つまり Flash-Lite は「予算が厳しい時の妥協案」ではなく、安いレーン向きの仕事に対する本命の既定盤です。
全面置換か、既定維持か、分流か
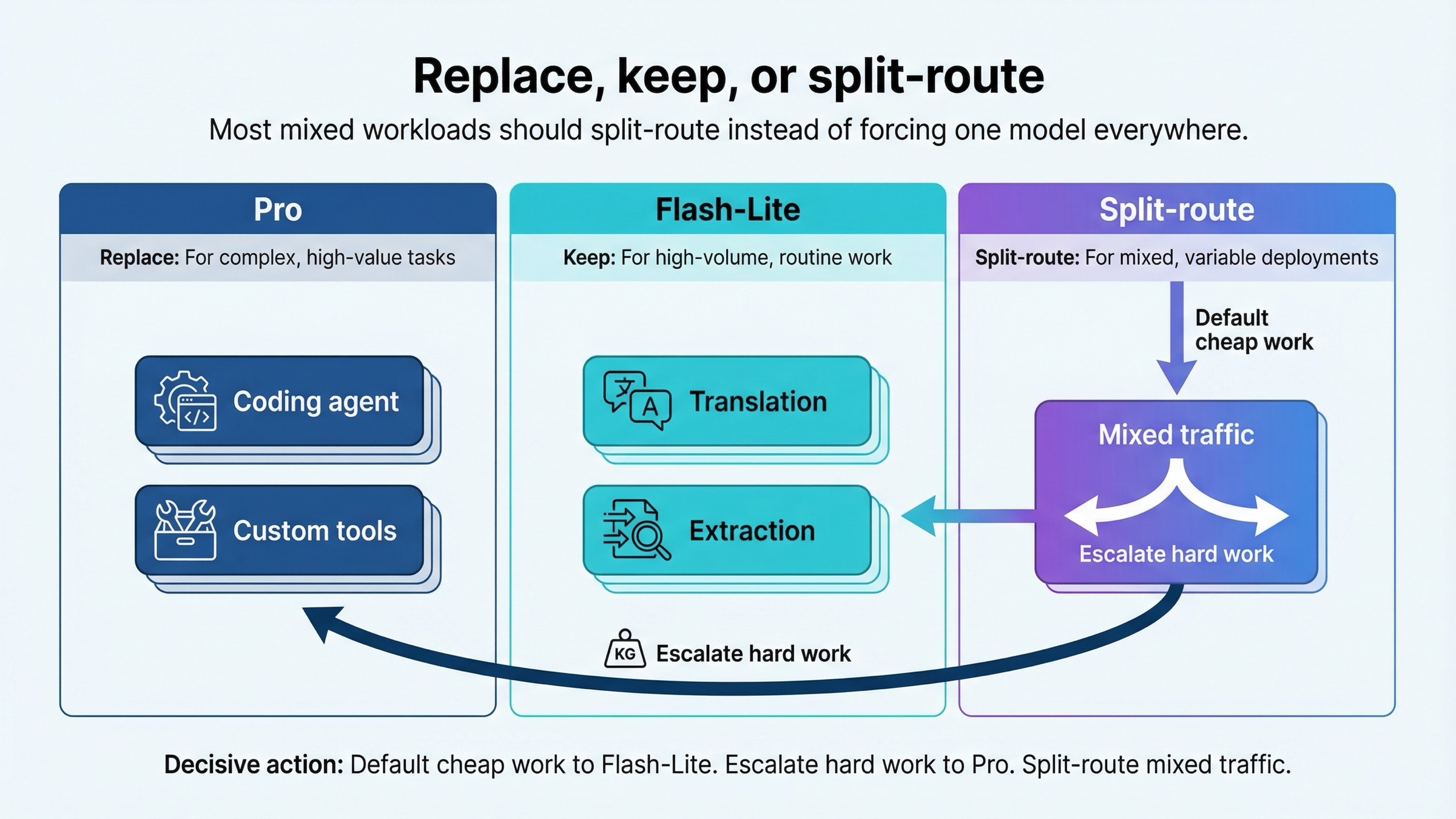
多くのチームにとって、正しい答えは極端な単一選択ではありません。
全部 Pro に寄せれば、ルーティン処理でほぼ確実に払いすぎます。全部 Flash-Lite に寄せれば、最も難しい処理で品質不足にぶつかります。だから、負荷が混ざっているなら split-routing が最も自然です。
実務で使いやすい整理は次の通りです。
| ワークロード | 向いている既定モデル | 理由 |
|---|---|---|
| tool-heavy coding agent | Gemini 3.1 Pro Preview | software engineering と多段実行の品質が重要 |
| custom tools orchestration | Gemini 3.1 Pro Preview | ツールワークフローの文脈がより強い |
| 大量翻訳 | Gemini 3.1 Flash-Lite | 価格と volume に強い |
| 構造化抽出と分類 | Gemini 3.1 Flash-Lite | 典型的な安いレーン仕事 |
| 大規模 batch queue | Gemini 3.1 Flash-Lite | Batch 価格も queue ceiling も有利 |
| 混在した production traffic | split-route | Flash-Lite を既定、難しいものだけ Pro へ |
実装の流れとしては、
- 新しい大量トラフィックはまず Flash-Lite に置く。
- Pro は難しい coding、複雑なツールフロー、難度の高い reasoning にだけ試す。
- そこで明確な ROI が出たら、そのリクエスト群だけ Pro のレーンに分ける。
これが「Pro は高品質、Lite は低価格」という雑な言い方よりはるかに実務的です。運用ルールとしては次の一文が最も使えます。
安いルーティン仕事は Flash-Lite を既定にし、難しく高価な仕事だけ Pro に昇格させる。混在負荷は分流する。
Flash-Lite をより強い高速モデルと比べて見たいなら Gemini 3.1 Flash-Lite vs Gemini 3 Flash も参考になります。Pro をより安定した上位モデルと比べたいなら Gemini 3.1 Pro vs Gemini 2.5 Pro も読んでください。
FAQ
Gemini 3.1 Pro Preview は常に Gemini 3.1 Flash-Lite より良いですか?
難しいタスクではそうです。ただし、安いルーティン処理では Flash-Lite の方が既定盤として合理的です。
どちらが安いですか?
Flash-Lite です。2026年3月20日時点で、Pro は $2.00 input / $12.00 output、Flash-Lite は $0.25 input / $1.50 output です。
トークン上限は同じですか?
はい。両方とも 1,048,576 input tokens と 65,536 output tokens です。だからこの比較はコンテキスト上限の話ではありません。
coding agents にはどちらを使うべきですか?
複雑でツール依存が高いなら Pro から始めるのが無難です。軽量で反復的な処理なら Flash-Lite を baseline にできます。
翻訳や抽出を大規模に回すならどちらですか?
Flash-Lite です。公式の用途説明、価格、Batch 経済性のどれを見ても、この用途では Flash-Lite が自然です。