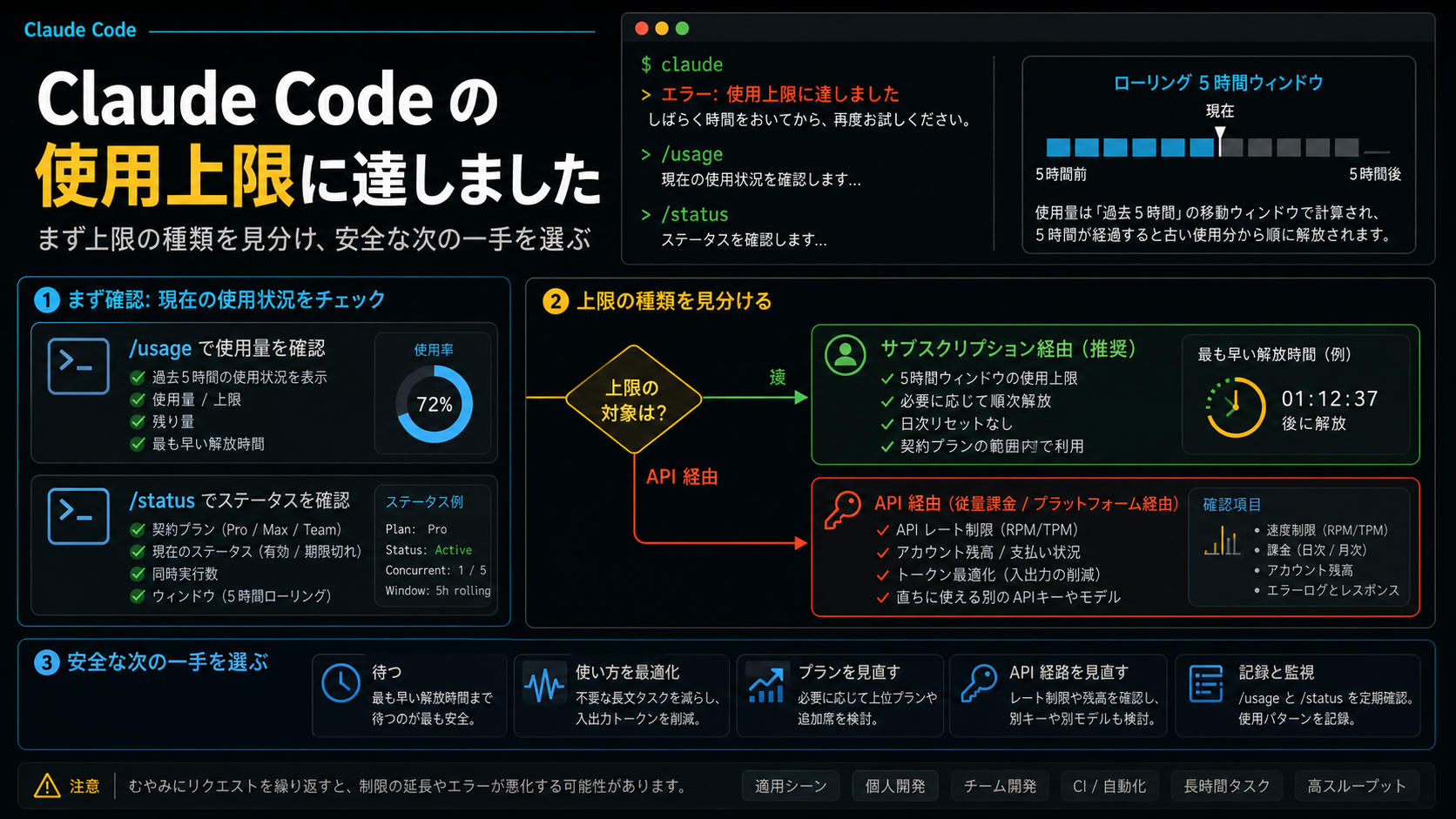
Claude Code が「使用上限に達しました」と出した瞬間に、いちばん避けたいのは、同じ長いセッションでさらに大きな依頼を投げることです。この表示は、現在のリクエスト経路がどこかの上限に当たったという停止信号であって、どの上限なのかまでは自動で説明してくれません。サブスクの5時間ローリング枠か、週次上限か、モデル別の制限か、組織プランの共有枠か、追加使用の残高か、API Key 側の rate limit かを分けないまま動くと、回復ではなく混乱が増えます。
最初にやることは派手ではありません。作業中の変更を保存し、/usage を見て、/status を確認し、reset time が表示されているなら記録し、ANTHROPIC_API_KEY が現在の Claude Code に影響していないかを確かめます。ここまでで、待つべきなのか、コンテキストを小さくすべきなのか、プランを見直すべきなのか、API 経路を直すべきなのかがかなり絞れます。
まず止血する
上限表示が出た直後は、追加のファイル探索や全体再スキャンを頼まないでください。Claude Code はコード、ログ、取得結果、diff、テスト出力をまとめて扱えるのが強みですが、その分だけセッション後半の1リクエストが重くなります。最後の入力が短くても、背後には長い履歴と tool output が付いていることがあります。
次に、現在の状態を残します。変更したファイル、失敗したコマンド、表示されたエラー文、使っていたモデル、作業開始のおおよその時刻、reset time、/usage の状態をメモします。サポートに出す場合にも、自分で再開する場合にも、「上限に達した」という一文だけでは判断できません。どの経路で止まったかを示す証拠が必要です。
そのうえで、最小で戻せる行動だけを選びます。待てるなら待つ。セッションが重いなら段階境界で小さくする。API Key の経路なら API 側を直す。継続的にサブスク枠が不足しているならプランや追加使用を検討する。順番を逆にすると、API の問題をサブスクのアップグレードで解こうとしたり、5時間枠の問題を API credits で解こうとしたりします。
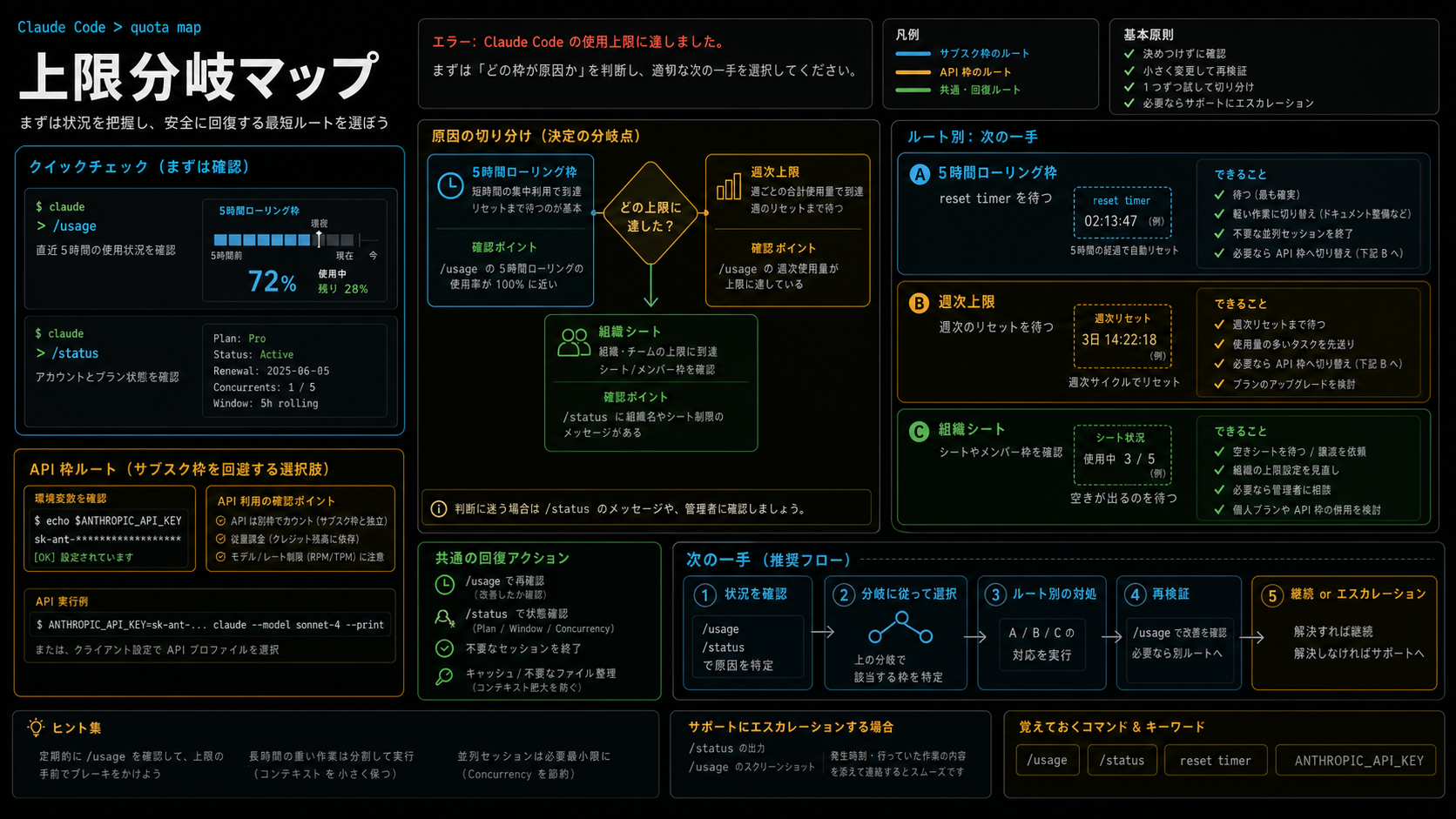
この表示が意味し得ること
日本語ユーザーの悩みでは、「突然の制限」「使用制限に達した」「リセットはいつか」「Claude Code 制限どれくらい」といった言い方が目立ちます。読者が本当に知りたいのは、言葉の定義よりも、今止まっている作業をどう安全に続けるかです。そのためには、まず上限の種類を分ける必要があります。
| 表示・状況 | 可能性が高い境界 | 先に見るもの | 安全な次の一手 |
|---|---|---|---|
| 数時間後の reset time が出る | 5時間ローリング枠 | /usage とエラー文の時刻 | 作業を保存して待つ、または小さい作業だけ進める |
| 何度も同じ日に止まる | 週次上限または重い会話 | /usage の週次情報、最近の作業量 | 長い会話を分割し、tool output を減らす |
| API の quota や rate limit に見える | API 経路 | ANTHROPIC_API_KEY、billing、Console usage | API 側を直す。サブスクを先に上げない |
| チーム全体で急に厳しい | 組織プランやシート | 管理者設定、seat、共有枠 | 管理者と組織側の使用状況を確認する |
| 大きな修正の1ターン後に止まる | コンテキスト肥大、モデル選択 | /status、モデル、直近のログとファイル読み込み | 圧縮、分割、次セッション用 handoff |
Anthropic のヘルプでは、使用量制限は一定期間内に Claude とやり取りできる量として説明されています。Claude Code については、Pro / Max、組織プラン、追加使用、API Key の扱いが分けて書かれています。つまり、上限表示を一つの現象としてまとめず、どの使用経路かを切り分けるのが出発点です。
2026年5月時点で古い説明をそのまま使わない
2026年春の Claude Code には、ピーク時の制限、急に消費が早くなったという報告、キャッシュに関する議論が多くありました。ただし、それを今日の最初の説明にしてはいけません。Anthropic は 2026年5月6日に Claude Code の5時間上限を引き上げ、Pro と Max のピーク時間帯の制限引き下げを取り除いたと発表しています。
だから、いま制限が出たときに「ピーク時間だから削られている」と決め打ちするのは危険です。現在も5時間枠、週次上限、モデル差、組織ポリシー、API の rate limit、長いコンテキストの負荷は残ります。しかし最初に見るべき根拠は、古い体験談ではなく、現在の /usage、/status、公式ヘルプ、実際のエラー文です。
この違いは実務上かなり大きいです。古い説明に寄せると、「バグっぽい」「高峰時間っぽい」「Max にすればよさそう」という曖昧な結論で止まります。現在の切り分けでは、どの境界が証拠で確認できるかを見ます。証拠がなければ、費用のかかる変更は後回しにします。
確認する順番

最初は /usage です。ここでは「何パーセント残っているか」だけではなく、どの種類の使用量なのか、reset time があるのか、週次上限の兆候があるのかを見ます。5時間ローリング枠は深夜に一斉リセットされるとは限りません。送信したメッセージが5時間後に窓から抜けるため、利用可能量は一日の中で少しずつ戻ることがあります。
次に /status です。現在のログイン状態、モデル、プロジェクト、接続経路を確認します。ここで、サブスクで使っているつもりが API Key 経由になっていた、または組織設定の影響を受けていた、といったズレに気づけます。Claude Code の制限診断では、エラー文だけよりも経路確認のほうが重要です。
その後、シェル環境とプロジェクト設定を見ます。ANTHROPIC_API_KEY が設定されている場合、それ自体は問題ではありません。ただし、API 経路の quota、rate limit、billing は Pro / Max のサブスク枠とは別です。サブスクの問題ならサブスク側、API の問題なら API 側を見なければいけません。
最後に、直近の作業形態を確認します。巨大なログ、長いテスト出力、大きなファイル、広い grep、複数回の失敗コマンドをそのまま読ませていないか。長いコードセッションでは、1つ前の入力が短くても、実際には大量の履歴とツール出力が一緒に扱われます。
次に何を選ぶか

reset time がはっきりしていて、仕事が急ぎでないなら、待つのが最も低リスクです。待つ前に、次に再開するためのメモを残します。変更ファイル、落ちたコマンド、まだ試していない仮説、次の最小アクションを書いておけば、復帰後の最初の依頼を短くできます。
コンテキストが大きくなりすぎているなら、段階境界で圧縮または新しい小セッションに移ります。安全な境界は、テストの結果が出た、修正範囲が固まった、次のタスクが明確に分かれたタイミングです。危険な境界は、原因調査の途中で、細かい観察がまだ必要なときです。そこで無理に圧縮すると、また同じ調査をやり直すことになります。
Pro / Max へのアップグレードは、サブスク枠が継続的なボトルネックだと確認できる場合に意味があります。API 429、誤った環境変数、組織側の制限、巨大なセッション設計は、プランを上げても根本解決しません。毎日長時間のインタラクティブな開発をしているなら検討できますが、まずは自分の停止原因を証拠で分けます。
追加使用は、含まれる使用量を超えた後も有料で続けるための仕組みです。緊急時には助かりますが、無制限の無料枠ではありません。使う前に、どのプランで使えるのか、どの残高から課金されるのか、どこで使用状況を見られるのかを確認してください。
API への切り替えは、自動化や CI、社内ツール、バッチ処理のような再現性のある作業に向いています。API にも rate limit と費用はありますが、ログ、予算、リトライ、並列数をエンジニアリングで管理できます。対話的なコード相談はサブスク、繰り返し処理は API、という分け方が自然なことが多いです。
長いコード作業が上限に当たりやすい理由
Claude Code は単なるチャットではありません。コードを読み、ターミナルを使い、調査結果を持ち、修正履歴とテスト結果を見ながら次の判断をします。これは開発者にとって便利ですが、コンテキスト量の面では重い作業です。
たとえば、最初の数ターンで設定ファイル、主要コンポーネント、テストログ、依存関係のエラーを読ませたとします。その後に「では直して」と短く入力しても、そのリクエストは短いとは限りません。モデルは前の材料を踏まえて応答する必要があるため、見えていない履歴が消費に効きます。
これが「一回のプロンプトで急に減った」と感じる理由の一つです。もちろん本当に異常な消費の可能性もゼロではありません。ただし、まず疑うべきは、長いセッション、広すぎるファイル読み込み、大量の tool output、重いモデル選択です。証拠を残していれば、異常か通常の重さかを後で分けられます。
中断しにくい使い方に変える
Claude Code に依頼するときは、最初から作業境界を指定します。目標、触ってよいファイル、確認コマンド、やってはいけない変更、止まる条件を短く書きます。いきなり「プロジェクト全体を見て全部直して」ではなく、「このテスト失敗をこの範囲で調べ、必要なら読むファイルを提案して」と始めるほうが、消費も判断も安定します。
大きな作業は、調査、最小修正、検証、周辺整理、最終確認に分けます。各段階の終わりに handoff を作ります。良い handoff は、変更ファイル、理由、未解決点、次のコマンド、守るべき制約を含みます。これがあれば、reset 後や新しいセッションでも、古い会話を丸ごと持ち込まずに再開できます。
ログやファイルの読み込みも絞ります。失敗ログはまずエラー周辺だけで十分なことが多いです。大きな JSON、lockfile、ビルドログを丸ごと渡すのは、必要性がはっきりしてからにします。大量の材料は有効ですが、問いが狭いときだけ価値があります。
実務では、復帰用の短いテンプレートを持っておくと効果があります。テンプレートには、現在のブランチまたは作業名、触っているファイル、最後に失敗したコマンド、今わかっている結論、次の最小リクエストだけを書きます。上限が戻ったあとにこのテンプレートを渡せば、前の長い会話をそのまま再現しなくても作業を続けられます。これは token 節約だけでなく、古い仮説を次のセッションに持ち込みすぎないためにも役立ちます。
チームで使う場合は、issue や pull request の単位にも同じ考え方を入れます。最初のコメントでは調査だけ、次のコメントでは最小修正だけ、その次で対象テストだけ、最後に広い検証を行う、といった分け方です。各段階に終了条件があると、上限に当たっても「どこまで終わったか」が残ります。単に長いチャット履歴がある状態より、別の人や新しいセッションが引き継ぎやすくなります。
また、Claude Code に読ませる情報を“念のため全部”にしないことも重要です。巨大なログや全ファイル検索は、原因が広いときには有効ですが、毎回の初手にすると上限を早めます。まず小さな証拠で仮説を立て、足りないときだけ読み取り範囲を広げます。この順番にするだけで、使える時間の体感はかなり変わります。
証拠を残すと判断が速くなる
使用上限に関する不満は、「少ししか使っていないのに」「急に厳しくなった」「何かがおかしい」という形になりがちです。気持ちは自然ですが、そのままでは次の行動を決められません。判断に必要なのは、発生時刻、モデル、reset time、/usage の変化、/status、API Key の有無、直近に読ませたファイルやログの量です。
この証拠があると、通常の長いセッション消費なのか、問い合わせる価値がある異常なのかを分けられます。大きなリポジトリを読んだあとに止まったなら、まず作業設計を見直すほうが早いでしょう。軽い確認だけで usage が不自然に跳ねた、reset time が矛盾する、サブスクと API の表示が食い違う、といった材料があれば、サポートに説明できる形になります。
記録は自分の癖も見せてくれます。毎回ビルドログ全体を渡したあとに止まるのか、広い検索のあとに止まるのか、同じ会話で設計、実装、テスト、ドキュメントまで一気に頼んだときに止まるのか。原因が見えれば、プランを変える前に task scope を直せます。
reset 時刻と再開方法を一緒に読む
reset time が表示されている場合、それは単なる待ち時間ではありません。少なくとも、その回の停止が時間窓に近い性質を持つことを示す手がかりです。待っている間に手動でできる作業、整理できる失敗ログ、分割できる次タスクがあるなら、無理に同じセッションで続ける必要はありません。復帰後の最初の依頼は、できるだけ一つの検証や一つのファイルに絞ります。
逆に reset time が見えない場合は、より丁寧に経路を見ます。API Key、組織設定、モデル制限、billing の問題は、同じ形式で時刻を出すとは限りません。そこでアップグレードや追加使用を先に選ぶと、別の経路には効かない支払いをする可能性があります。/status と環境変数を確認してから、費用がかかる選択肢に進みます。
再開方法も上限対策の一部です。ほぼ終わった修正なら、reset 後に対象テストだけを頼みます。原因調査の序盤なら、新しいセッションで範囲を狭く定義し直します。中断を「前の会話を続ける合図」ではなく、「次の依頼を小さく作り直す合図」と見ると、同じ失敗を繰り返しにくくなります。
また、まだ上限に達していなくても、会話が十分に重くなったら自分から区切る判断が必要です。古い仮説、失敗した修正、長いログ、もう使わないファイルパスが同じセッションに残り続けると、次の一手の精度も落ちます。上限対策は、ブロックされてから始めるものではなく、作業が一段落した瞬間に始まります。
上限は作業失敗そのものではありません。失敗になるのは、再開できる状態が残っていないときです。diff、失敗コマンド、判断根拠、次の小さな依頼が残っていれば、reset は待ち時間で済みます。
アップグレード、追加使用、API の判断
アップグレードが妥当なのは、あなたの主な作業がインタラクティブな Claude Code 開発で、/usage が一貫してサブスク枠不足を示しているときです。単発の上限表示だけで判断する必要はありません。数日分の使い方を見て、長いコンテキストの癖も直したうえでまだ足りないなら、上位プランの価値があります。
追加使用が妥当なのは、締め切り中の作業や重要な修正をその場で続けたいときです。ただし、毎日のように追加使用が必要なら、ワークフローかプランの設計を見直すべきです。追加使用は応急処置であって、予算管理を不要にするものではありません。
API が妥当なのは、繰り返し実行する処理です。CI の補助、定期的なコード分析、内部ツール、バッチ変換、長期運用するエージェントは、API のほうが監視しやすいです。キー管理、上限、費用、リトライを自分で持つ必要はありますが、そのぶん制御可能です。
よくある質問
reset time が出たら待つしかありませんか?
必ずしもそうではありません。待つのが最も安全ですが、作業が急ぎなら、状態を保存したうえで、追加使用、アップグレード、API のどれが今の経路に効くかを確認します。経路を確認しないまま支払い系の変更をすると、別の上限には効果がありません。
/usage では残っているのに止まるのはなぜですか?
別の境界が効いている可能性があります。モデル別制限、週次上限、組織ポリシー、API rate limit、環境変数の経路違いなどです。/usage は入口であり、/status、環境変数、エラー文と合わせて判断します。
Pro / Max と API credits は同じですか?
同じではありません。Pro / Max はサブスク製品側の使用枠で、API credits は API 課金経路の残高です。Claude Code がどちらを使っているかを確認してから、プラン変更や残高追加を考えてください。
コンテキスト圧縮はいつ使うべきですか?
段階が終わったときに使うのが安全です。修正の途中で原因の細部がまだ重要な場合、先に handoff を作ってから圧縮します。圧縮は中断を減らす道具であり、調査途中の記憶を安全に保つ保証ではありません。
2026年3月のキャッシュ問題は今も前提にすべきですか?
前提にはしません。異常消費を疑うなら、時刻、モデル、コマンド、usage の変化、エラー文を記録します。ただし、現在の記事や判断では、2026年5月時点の公式情報と自分の CLI 出力を優先します。
外部の使用量モニターは必要ですか?
たまに止まる程度なら、内蔵コマンドで十分です。毎日長時間使うなら、ローカルログを分析するツールは役に立つことがあります。ただし、秘密鍵や非公開コードを外部サービスへ送るタイプのツールは慎重に扱ってください。
確認すべき公式情報
制限、追加使用、プランの扱いは変わるため、最新の判断は公式情報で確認します。Anthropic Help Center の Claude Code のモデル、使用量、制限、使用量と長さの制限、Pro または Max で Claude Code を使う方法、有料プランの追加使用、そして 2026年5月6日の Claude Code 使用制限引き上げの発表 を確認してください。